- Презентация Поиск информации в Интернете

Содержание
- 2. Количество информации в мире растет: Калифорнийский университет подсчитал , что в 2002 году в мире произведено
- 3. 1 терабайт – 1024 Гб Для сравнения: объем информации библиотеки Конгресса США, где хранится 19 млн.
- 4. Объем информации в интернете увеличивается в геометрической прогрессии: 1998 г. – количество web-сайтов – около 1
- 5. На июль 2006 года: По данным аналитической службы Netcraft, в интернете зарегистрировано 88 166 395 сайтов
- 6. Кривая роста числа сайтов Октябрь 1995 г. – июль 2006 г. http://news.netcraft.com
- 7. Русскоязычный интернет Аналитики Nigma.Ru в мае 2005 года оценили объем русскоязычного интернета в 1,052 млрд. web-страниц
- 8. Русскоязычный интернет В поисковой системе Яндекс на июль 2006 года проиндексировано: сайтов: 2 832 533, web-страниц:
- 9. Возникает проблема: Переизбыток информации В США получил распространение «синдром информационной усталости». По данным исследования Reuters 38%
- 10. Переизбыток информации По данным экспертов Reuters, 79% журналистов обращаются к интернету в поисках новостей и лишь
- 11. Что необходимо для эффективного поиска информации? Представление о структуре интернета. Представление о способах и методах поиска
- 12. Структура информационного пространства интернета
- 13. Благодаря кому в интернете возникает информация? Как искать, учитывая эти знания? Как она располагается в интернете?
- 14. Источники информации Мы рассмотрим основные источники информации интернета Особое внимание уделим трем критериям: тематика, оперативность, достоверность.
- 15. Источники информации #1 Компании и организации (юридические лица), создающие собственные сайты в интернете. Тематика, достоверность и
- 16. Источники информации #2 Обычные граждане (физические лица) Чаще всего сайты посвящены увлечению владельца Достоверность и оперативность
- 17. Источники информации #2 Они же выступают как участники форумов, конференций, блогов Тематика – самая разнообразная Оперативность
- 18. Источники информации #3 Журналисты и редакторы сетевых СМИ и информагентств Тематика – самая разнообразная Оперативность –
- 19. Источники информации #4 Сотрудники информационных и консалтинговых компаний, создающие специализированные базы данных Тематика – самая разнообразная
- 20. Схема информационных потоков Сайты компаний Личные сайты Форумы, блоги Информ. агентства Сетевые СМИ Компании и организации
- 21. Схема информационных потоков Сайты компаний Личные сайты Форумы, блоги Информ. агентства Сетевые СМИ Поисковые системы Специализированные
- 22. Парадокс интернета: Полезной информации становится все больше, а найти что-то необходимое – все сложнее.
- 23. Модель web-пространства
- 24. Для эффективного поиска в интернете необходимо учитывать архитектуру всего информационного пространства интернета. Гиперссылки могут стать основой
- 25. Модель web-пространства Впервые создана в 1999 году в Институте поиска и анализа текстов (США). Модель опровергла
- 26. Модель web-пространства Проследив с помощью поискового механизма 200 млн. web-страниц и несколько миллиардов ссылок ученые пришли
- 27. Модель web-пространства «Отправные» web-страницы IN 22% «Конечные» web-страницы OUT 22% Центральное ядро SCC 28% web-страниц «Отростки»
- 28. Центральное ядро – 28% web-страниц Компоненты сильной связности (SCC). Сюда относятся web-страницы, связанные так тесно, что,
- 29. «Отправные» web-страницы - 22% Web-страницы, которые содержат гиперссылки, ведущие в конечном счете к ядру. Но! Из
- 30. «Конечные» web-страницы – 22% К этим web-страницам можно прийти по ссылкам из ядра. Но! Вернуться по
- 31. «Отростки» - 22% Web-страницы, полностью изолированные от центрального ядра. Это либо «отростки», связанные в одностороннем порядке
- 32. «Острова» - около 10% Web-страницы, которые вообще не пересекаются с остальными ресурсами интернета. Единственный способ обнаружить
- 33. Пропорции модели Ученые обнаружили, что пропорции четырех основных категорий web-страниц в течение времени остаются неизменными, несмотря
- 34. Интернет – это фрактал Топология и характеристики модели Bow Tie оказались примерно одинаковыми и для различных
- 35. Связь между ресурсами интернет Эксперимент выявил сложную картину: значительная часть web-пространства отделена от других крупных частей.
- 36. Связь между web-страницами В случае, если между страницами существует односторонний путь, то среднее количество щелчков для
- 37. Связь между web-страницами Если путь между web-страницами двусторонний, то количество щелчков сократится до 7 7
- 38. Скрытый Web
- 39. «Острова» - скрытый Web Недостаток модели Bow Tie – недооценка размеров «островов», то есть web-страниц, «не
- 40. Скрытый Web В 1994 web-ресурсы, недоступные поисковым системам, получили название deep Web или «скрытый Web». Другое
- 41. Скрытый Web Какие это web-ресурсы? Динамически генерируемые страницы Информация из баз данных Файлы нераспознаваемых форматов Системы
- 42. Платные сайты Сайты, защищенные паролем и берущие плату за доступ, по некоторым оценкам, составляют всего 10%
- 43. Крупнейшие базы данных Одними из самых больших известных ресурсов «скрытого» Web’a являются базы данных служб Dialog
- 44. Dialog www.dialog.com Создана в 1965 году. Dialog содержит 900 баз данных, доступных 700 тыс. пользователей, которые
- 45. LexisNexis www.lexisnexis.com Основана в 1973 году. Представляет пользователям юридическую, политическую, коммерческую, новостную и т.п. информацию. В
- 46. LexisNexis www.lexisnexis.com Служба охватывает 35 000 источников информации 4,6 млрд. документов с глубиной ретроспективы 200 лет.
- 47. Пример рускоязычной базы данных Сайт компании «Кодекс» о российском законодательстве www.kodeks.ru Тысячи документов будут доступны только
- 48. Как искать в «скрытом» Web’e? Крупнейший каталог скрытых ресурсов – www.completeplanet.com. Он содержит более 100 тыс.
- 49. Как искать в «скрытом» Web’e? Крупнейшая поисковая система для скрытых ресурсов – SurfWax www.surfwax.com Подавляющее большинство
- 51. Скачать презентацию

Количество информации в мире растет:
Калифорнийский университет подсчитал , что в 2002
Количество информации в мире растет:
Калифорнийский университет подсчитал , что в 2002

1 терабайт – 1024 Гб
Для сравнения: объем информации библиотеки Конгресса США,
1 терабайт – 1024 Гб
Для сравнения: объем информации библиотеки Конгресса США,

Объем информации в интернете увеличивается в геометрической прогрессии:
1998 г. – количество
Объем информации в интернете увеличивается в геометрической прогрессии:
1998 г. – количество

На июль 2006 года:
По данным аналитической службы Netcraft, в интернете зарегистрировано
На июль 2006 года:
По данным аналитической службы Netcraft, в интернете зарегистрировано
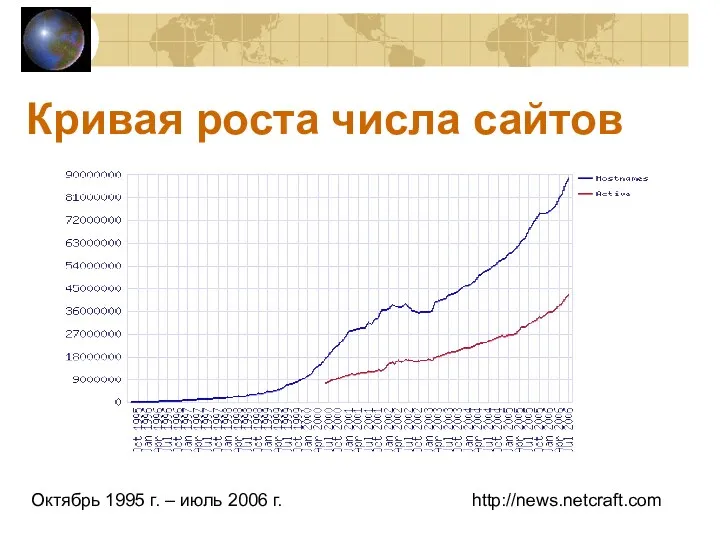
Кривая роста числа сайтов
Октябрь 1995 г. – июль 2006 г.
Кривая роста числа сайтов
Октябрь 1995 г. – июль 2006 г.

Русскоязычный интернет
Аналитики Nigma.Ru в мае 2005 года оценили объем русскоязычного интернета
Русскоязычный интернет
Аналитики Nigma.Ru в мае 2005 года оценили объем русскоязычного интернета

Русскоязычный интернет
В поисковой системе Яндекс на июль 2006 года проиндексировано:
сайтов: 2
Русскоязычный интернет
В поисковой системе Яндекс на июль 2006 года проиндексировано:
сайтов: 2

Возникает проблема:
Переизбыток информации
В США получил распространение «синдром информационной усталости».
По данным исследования
Возникает проблема:
Переизбыток информации
В США получил распространение «синдром информационной усталости».
По данным исследования

Переизбыток информации
По данным экспертов Reuters,
79% журналистов обращаются к интернету в поисках
Переизбыток информации
По данным экспертов Reuters,
79% журналистов обращаются к интернету в поисках

Что необходимо для эффективного поиска информации?
Представление о структуре интернета.
Представление о способах
Что необходимо для эффективного поиска информации?
Представление о структуре интернета.
Представление о способах

Структура информационного пространства интернета
Структура информационного пространства интернета

Благодаря кому в интернете возникает информация?
Как искать, учитывая эти знания?
Как она
Благодаря кому в интернете возникает информация?
Как искать, учитывая эти знания?
Как она

Источники информации
Мы рассмотрим основные источники информации интернета
Особое внимание уделим трем критериям:
тематика,
оперативность,
достоверность.
Источники информации
Мы рассмотрим основные источники информации интернета
Особое внимание уделим трем критериям:
тематика,
оперативность,
достоверность.

Источники информации
#1 Компании и организации (юридические лица), создающие собственные сайты в
Источники информации
#1 Компании и организации (юридические лица), создающие собственные сайты в

Источники информации
#2 Обычные граждане (физические лица)
Чаще всего сайты посвящены увлечению владельца
Достоверность
Источники информации
#2 Обычные граждане (физические лица)
Чаще всего сайты посвящены увлечению владельца
Достоверность

Источники информации
#2 Они же выступают как участники форумов, конференций, блогов
Тематика –
Источники информации
#2 Они же выступают как участники форумов, конференций, блогов
Тематика –

Источники информации
#3 Журналисты и редакторы сетевых СМИ и информагентств
Тематика – самая
Источники информации
#3 Журналисты и редакторы сетевых СМИ и информагентств
Тематика – самая

Источники информации
#4 Сотрудники информационных и консалтинговых компаний, создающие специализированные базы данных
Тематика
Источники информации
#4 Сотрудники информационных и консалтинговых компаний, создающие специализированные базы данных
Тематика
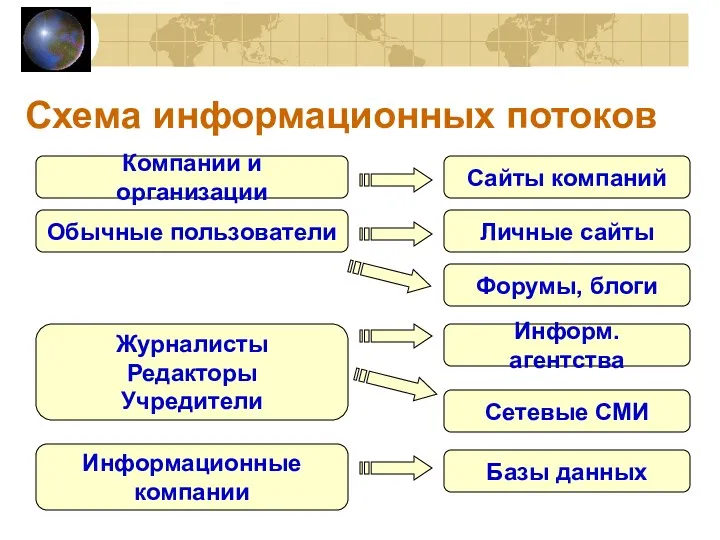
Схема информационных потоков
Сайты компаний
Личные сайты
Форумы, блоги
Информ. агентства
Сетевые СМИ
Компании и
Схема информационных потоков
Сайты компаний
Личные сайты
Форумы, блоги
Информ. агентства
Сетевые СМИ
Компании и
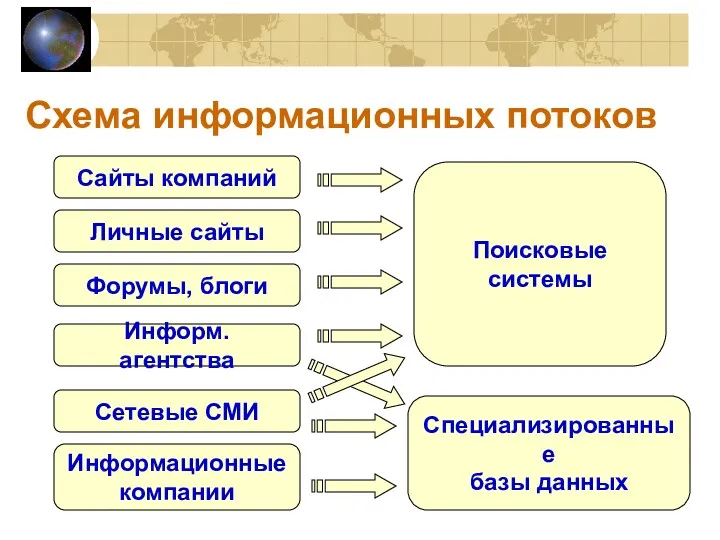
Схема информационных потоков
Сайты компаний
Личные сайты
Форумы, блоги
Информ. агентства
Сетевые СМИ
Поисковые
системы
Специализированные
базы
Схема информационных потоков
Сайты компаний
Личные сайты
Форумы, блоги
Информ. агентства
Сетевые СМИ
Поисковые
системы
Специализированные
базы

Парадокс интернета:
Полезной информации становится все больше, а найти что-то необходимое –
Парадокс интернета:
Полезной информации становится все больше, а найти что-то необходимое –

Модель
web-пространства
Модель
web-пространства

Для эффективного поиска в интернете
необходимо учитывать архитектуру всего информационного пространства интернета.
Гиперссылки
Для эффективного поиска в интернете
необходимо учитывать архитектуру всего информационного пространства интернета.
Гиперссылки

Модель web-пространства
Впервые создана в 1999 году в Институте поиска и анализа
Модель web-пространства
Впервые создана в 1999 году в Институте поиска и анализа

Модель web-пространства
Проследив с помощью поискового механизма 200 млн. web-страниц и несколько
Модель web-пространства
Проследив с помощью поискового механизма 200 млн. web-страниц и несколько
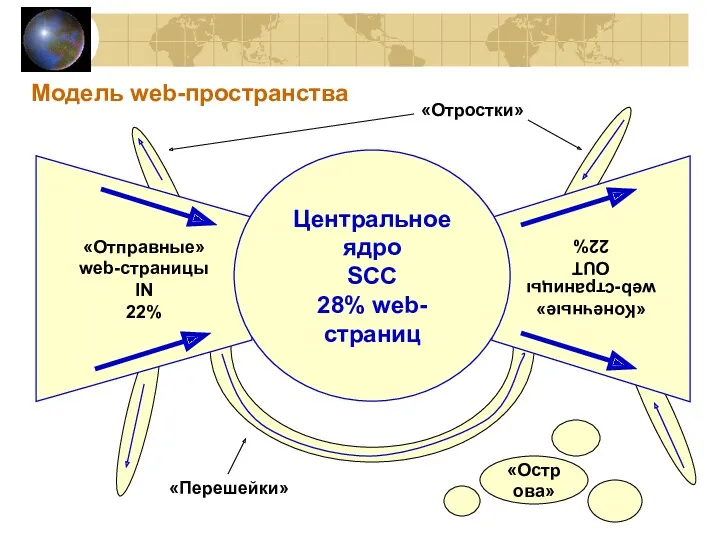
Модель web-пространства
«Отправные»
web-страницы
IN
22%
«Конечные»
web-страницы
OUT
22%
Центральное ядро
SCC
28% web-страниц
«Отростки»
«Перешейки»
«Острова»
Модель web-пространства
«Отправные»
web-страницы
IN
22%
«Конечные»
web-страницы
OUT
22%
Центральное ядро
SCC
28% web-страниц
«Отростки»
«Перешейки»
«Острова»

Центральное ядро – 28% web-страниц
Компоненты сильной связности (SCC).
Сюда относятся web-страницы, связанные
Центральное ядро – 28% web-страниц
Компоненты сильной связности (SCC).
Сюда относятся web-страницы, связанные

«Отправные» web-страницы - 22%
Web-страницы, которые содержат гиперссылки, ведущие в конечном счете
«Отправные» web-страницы - 22%
Web-страницы, которые содержат гиперссылки, ведущие в конечном счете

«Конечные» web-страницы – 22%
К этим web-страницам можно прийти по ссылкам из
«Конечные» web-страницы – 22%
К этим web-страницам можно прийти по ссылкам из

«Отростки» - 22%
Web-страницы, полностью изолированные от центрального ядра.
Это либо «отростки», связанные
«Отростки» - 22%
Web-страницы, полностью изолированные от центрального ядра.
Это либо «отростки», связанные

«Острова» - около 10%
Web-страницы, которые вообще не пересекаются с остальными ресурсами
«Острова» - около 10%
Web-страницы, которые вообще не пересекаются с остальными ресурсами

Пропорции модели
Ученые обнаружили, что пропорции четырех основных категорий web-страниц в течение
Пропорции модели
Ученые обнаружили, что пропорции четырех основных категорий web-страниц в течение

Интернет – это фрактал
Топология и характеристики модели Bow Tie оказались примерно
Интернет – это фрактал
Топология и характеристики модели Bow Tie оказались примерно

Связь между ресурсами интернет
Эксперимент выявил сложную картину:
значительная часть web-пространства отделена от
Связь между ресурсами интернет
Эксперимент выявил сложную картину:
значительная часть web-пространства отделена от

Связь между web-страницами
В случае, если между страницами существует односторонний путь, то
Связь между web-страницами
В случае, если между страницами существует односторонний путь, то
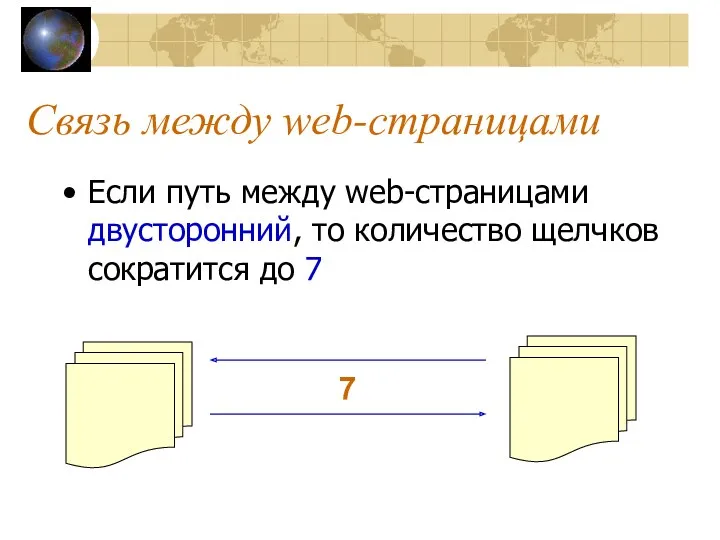
Связь между web-страницами
Если путь между web-страницами двусторонний, то количество щелчков сократится
Связь между web-страницами
Если путь между web-страницами двусторонний, то количество щелчков сократится

Скрытый Web
Скрытый Web

«Острова» - скрытый Web
Недостаток модели Bow Tie – недооценка размеров «островов»,
«Острова» - скрытый Web
Недостаток модели Bow Tie – недооценка размеров «островов»,

Скрытый Web
В 1994 web-ресурсы, недоступные поисковым системам, получили название deep Web
Скрытый Web
В 1994 web-ресурсы, недоступные поисковым системам, получили название deep Web

Скрытый Web
Какие это web-ресурсы?
Динамически генерируемые страницы
Информация из баз данных
Файлы нераспознаваемых форматов
Системы
Скрытый Web
Какие это web-ресурсы?
Динамически генерируемые страницы
Информация из баз данных
Файлы нераспознаваемых форматов
Системы

Платные сайты
Сайты, защищенные паролем и берущие плату за доступ, по некоторым
Платные сайты
Сайты, защищенные паролем и берущие плату за доступ, по некоторым

Крупнейшие базы данных
Одними из самых больших известных ресурсов «скрытого» Web’a являются
Крупнейшие базы данных
Одними из самых больших известных ресурсов «скрытого» Web’a являются

Dialog www.dialog.com
Создана в 1965 году.
Dialog содержит 900 баз данных, доступных 700
Dialog www.dialog.com
Создана в 1965 году.
Dialog содержит 900 баз данных, доступных 700

LexisNexis www.lexisnexis.com
Основана в 1973 году.
Представляет пользователям юридическую, политическую, коммерческую, новостную и
LexisNexis www.lexisnexis.com
Основана в 1973 году.
Представляет пользователям юридическую, политическую, коммерческую, новостную и

LexisNexis www.lexisnexis.com
Служба охватывает 35 000 источников информации
4,6 млрд. документов с глубиной
LexisNexis www.lexisnexis.com
Служба охватывает 35 000 источников информации
4,6 млрд. документов с глубиной

Пример рускоязычной базы данных
Сайт компании «Кодекс» о российском законодательстве
www.kodeks.ru
Тысячи документов будут
Пример рускоязычной базы данных
Сайт компании «Кодекс» о российском законодательстве
www.kodeks.ru
Тысячи документов будут

Как искать в «скрытом» Web’e?
Крупнейший каталог скрытых ресурсов – www.completeplanet.com. Он
Как искать в «скрытом» Web’e?
Крупнейший каталог скрытых ресурсов – www.completeplanet.com. Он

Как искать в «скрытом» Web’e?
Крупнейшая поисковая система для скрытых ресурсов –
Как искать в «скрытом» Web’e?
Крупнейшая поисковая система для скрытых ресурсов –
 Умовний оператор мовою програмування. Повна та скорочена форма оператора розгалуження. Урок 10
Умовний оператор мовою програмування. Повна та скорочена форма оператора розгалуження. Урок 10 Представление чисел в памяти компьютера. 10 класс
Представление чисел в памяти компьютера. 10 класс Comodo Internet Security Premium. Мои настройки
Comodo Internet Security Premium. Мои настройки Обработка текстовой и графической информации
Обработка текстовой и графической информации Интерактивные решения
Интерактивные решения Талдау және синтез
Талдау және синтез Операционные системы и среды. История развития компьютерных вирусов
Операционные системы и среды. История развития компьютерных вирусов Технологічні засоби та забезпечення для побудови інформаційних систем на підприємствах
Технологічні засоби та забезпечення для побудови інформаційних систем на підприємствах Информационная культура современного человека
Информационная культура современного человека Структура программы на Си/Си++
Структура программы на Си/Си++ Программирование на WinAPI. Интерактивная компьютерная графика. (Часть 7.3)
Программирование на WinAPI. Интерактивная компьютерная графика. (Часть 7.3) Программирование на языке Паскаль. Алфавит языка. Структура программы
Программирование на языке Паскаль. Алфавит языка. Структура программы Нормализация данных
Нормализация данных Представление архитектуры ИС
Представление архитектуры ИС Разработка ПО. Базовые компетенции
Разработка ПО. Базовые компетенции Основи інформаційних технологій
Основи інформаційних технологій Высказывание. Логические операции
Высказывание. Логические операции Сетевые технологии
Сетевые технологии Исполнитель Паркетчик
Исполнитель Паркетчик Основні тренди у веб-дизайні. Градієнт .Фон сторінки, виконаний в враження свіжості і унікальності
Основні тренди у веб-дизайні. Градієнт .Фон сторінки, виконаний в враження свіжості і унікальності Разработка сайтов. Lieshen Web Dev
Разработка сайтов. Lieshen Web Dev Прогностические системы США
Прогностические системы США Технология Спайдер планирования проектов
Технология Спайдер планирования проектов Биометрическая система контроля и управления доступом БиоСКУД Сонда Эксперт
Биометрическая система контроля и управления доступом БиоСКУД Сонда Эксперт Безопасность детей в интернете
Безопасность детей в интернете Компьютерные сети. §44. Основные понятия
Компьютерные сети. §44. Основные понятия Календарное и сетевое планирование. Лекция 1
Календарное и сетевое планирование. Лекция 1 Автоматизированное проектирование ИС. (Лекция 5)
Автоматизированное проектирование ИС. (Лекция 5)