- Работа со строками в python

Содержание
- 2. Введение Строки в языке Python являются типом данных, специально предназначенным для обработки текстовой информации. Строка может
- 3. Форматирование строк в Python "Старый стиль" форматирования строк (оператор %) "Новый стиль" форматирования строк (str.format) Интерполяция
- 4. "Старый стиль" форматирования строк (оператор %)
- 5. "Старый стиль" форматирования строк (оператор %) Во многом аналогичен функции printf в C. Подробнее можно прочитать
- 6. Если переменных много, что код быстро становиться плохо читаемым: first_name = "Eric" last_name = "Idle" age
- 7. Можно использовать спецификатор формата %x для преобразования значения int в строку и представления его в виде
- 8. Также можно производить подстановку переменных по имени: 'Hey %(name)s, there is a 0x%(errno)x error!' % {"name":
- 9. К сожалению, этот вид форматирования не очень хорош, потому что он многословен и приводит к ошибкам,
- 10. Официальная документация Python 3 не рекомендует форматирование «старого стиля» и говорит о нем не слишком любезно:
- 11. "Новый стиль" (str.format)
- 12. "Новый стиль" (str.format) str.format () - это улучшение % форматирования. Он использует обычный синтаксис вызова функции
- 13. Можно ссылаться на переменные в любом порядке, используя их индекс: "Hello, {1}. You are {0}.".format(age, name)
- 14. Но если вы вставите имена переменных, вы получите дополнительную возможность передавать объекты, а затем ссылаться на
- 15. Недостатки: Хотя код, использующий str.format (), гораздо легче читается, в сравнении с %-форматированием, однако str.format ()
- 16. f-Strings / Интерполяция строк
- 17. f-Strings: новый и улучшенный способ форматирования строк в Python Поддержка добавлена начиная с Python 3.6. Вы
- 18. Произвольные выражения: Поскольку f-строки вычисляются во время выполнения, в них можно поместить все допустимые выражения Python.
- 19. Можно вызвать метод напрямую: print( f"{name.lower()} is funny." ) eric idle is funny.
- 20. Другой пример: print(f'Если поделить торт на трех человек, каждый из них получит {1/3*100:.2f} %') Если поделить
- 21. Пример с классом: class Comedian: def __init__(self, first_name, last_name, age): self.first_name = first_name self.last_name = last_name
- 22. Многострочные f-строки name = "Eric" profession = "comedian" affiliation = "Monty Python" message = ( f"Hi
- 23. Важно, чтобы f было перед каждой строкой многострочной строки. Следующий код не будет работать: message =
- 24. При использовании """ строк: message = f""" Hi {name}. You are a {profession}. You were in
- 25. Скорость Символ f в f-string также может означать «быстро» (fast). f-строки быстрее, чем %-форматирование и str.format().
- 26. Может быть потенциально небезопасно, если строка получается от пользователя. # Это наш супер секретный ключ: SECRET
- 27. Шаблонные строки (Стандартная библиотека Template Strings)
- 28. Шаблоны (Standard Library) Еще один инструмент для форматирования строк в Python: шаблоны. Был добавлен в Python
- 29. Нужно импортировать класс Template из встроенного строкового модуля Python. Шаблонные строки не являются основной функцией языка,
- 30. Каким методом форматирования строк стоит пользоваться? Если строки получены от пользователя, используйте шаблонные строки (способ 4),
- 31. Другое отличие состоит в том, что строки шаблона не допускают спецификаторов формата. templ_string = 'Hey $name,
- 32. Отступы и выравнивание строк
- 33. Добавить отступы слева: test = 'test' print('%10s' % (test,)) print('{:>10}'.format(test)) print(f'{test:>10}') test test test
- 34. Добавить отступы справа: test = 'test' print('{:_ print(f'{test:_ test______ test______
- 35. Выравнивание по центру: Eсли при выравнивании по центру получается нечетное количество отступов, то нечетный будет добавлен
- 36. Усечение длинных строк print('%.5s' % ('xylophone',)) print('{:.5}'.format('xylophone')) print(f'{"xylophone":.5}') xylop xylop xylop print(f'"{"xylophone":10.5}"') "xylop "
- 37. Целые числа: print('%d' % (42,)) print('{:d}'.format(42)) print(f'{42:d}') 42 42 42
- 38. Целые числа: print(f'Показывать знак, даже если число положительное: {42:_>+6d}') print(f'{-42:_>+54d}') Показывать знак, даже если число положительное:
- 39. Floats: print('%f' % (3.141592653589793,)) print('{:f}'.format(3.141592653589793)) print(f'{3.141592653589793:f}') 3.141593 3.141593 3.141593 pi = 3.141592653589793 print('%06.2f' % (pi)) print('{:06.2f}'.format(pi))
- 40. print(f'{42:_^+10.2f}') __+42.00__
- 41. Пробел означает, что для отрицательного значения будет отображен минус, а для положительного пробел. print('{: d}'.format((- 23)))
- 42. points = 19.5 total = 22 print('Correct answers: {:.2%}'.format(points/total)) print(f'Correct answers: {points/total:.2%}') Correct answers: 88.64% Correct
- 43. Datetime: from datetime import datetime s = '{:%Y-%m-%d %H:%M}'.format(datetime(2001, 2, 3, 4, 5)) print(s) 2001-02-03 04:05
- 44. Datetime (f-строки): from datetime import datetime dt = datetime(2001, 2, 3, 4, 5) s = f'{dt:%Y-%m-%d
- 45. Встроенные методы строк в python
- 46. string.capitalize() приводит первую букву в верхний регистр, остальные в нижний. Возвращает копию s с первым символом,
- 47. string.lower() преобразует все буквенные символы в строчные. Возвращает копию s со всеми буквенными символами, преобразованными в
- 48. string.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот: s = 'everyTHing
- 49. string.title() преобразует первые буквы всех слов в заглавные. возвращает копию, s в которой первая буква каждого
- 50. string.upper() преобразует все буквенные символы в заглавные. Возвращает копию s со всеми буквенными символами в верхнем
- 51. Найти и заменить подстроку в строке Эти методы предоставляют различные способы поиска в целевой строке указанной
- 52. Каждый метод в этой группе поддерживает необязательные аргументы и аргументы. Они задают диапазон поиска: действие метода
- 53. string.count( [, [, ]]) подсчитывает количество вхождений подстроки в строку. Возвращает количество точных вхождений подстроки в
- 54. string.endswith( [, [, ]]) определяет, заканчивается ли строка заданной подстрокой. Возвращает, True если s заканчивается указанным
- 55. Например, метод endswith() можно использовать для проверки окончания файла. filenames = ["file.txt", "image.jpg", "str.txt"] for fn
- 56. string.find( [, [, ]]) ищет в строке заданную подстроку. Возвращает первый индекс в s который соответствует
- 57. string.index( [, [, ]]) ищет в строке заданную подстроку. Этот метод идентичен .find(), за исключением того,
- 58. string.rfind( [, [, ]]) ищет в строке заданную подстроку, начиная с конца. Возвращает индекс последнего вхождения
- 59. string.rindex( [, [, ]]) ищет в строке заданную подстроку, начиная с конца. Этот метод идентичен .rfind(),
- 60. string.startswith( [, [, ]]) определяет, начинается ли строка с заданной подстроки. Возвращает, True если s начинается
- 61. Классификация строк Методы в этой группе классифицируют строку на основе символов, которые она содержит.
- 62. string.isalnum() определяет, состоит ли строка из букв и цифр. Возвращает True, если строка s не пустая,
- 63. string.isalpha() определяет, состоит ли строка только из букв. Возвращает True, если строка s не пустая, а
- 64. string.isdigit() определяет, состоит ли строка из цифр (проверка на число). Возвращает True когда строка s не
- 65. string.isidentifier() определяет, является ли строка допустимым идентификатором Python. Возвращает True, если s валидный идентификатор (название переменной,
- 66. string.islower() определяет, являются ли буквенные символы строки строчными. возвращает True, если строка s не пустая, и
- 67. string.isprintable() определяет, состоит ли строка только из печатаемых символов. возвращает, True если строка s пустая или
- 68. string.isspace() определяет, состоит ли строка только из пробельных символов. возвращает True, если s не пустая строка,
- 69. string.istitle() определяет, начинаются ли слова строки с заглавной буквы. возвращает True когда s не пустая строка
- 70. Выравнивание строк, отступы Методы в этой группе влияют на вывод строки.
- 71. string.center( [, ]) выравнивает строку по центру. Возвращает строку, состоящую из s выровненной по ширине .
- 72. string.lstrip([ ]) обрезает пробельные символы слева. Возвращает копию s в которой все пробельные символы с левого
- 73. string.replace( , [, ]) заменяет вхождения подстроки в строке. Возвращает копию s где все вхождения подстроки
- 74. string.rjust( [, ]) выравнивание по правому краю строки в поле. возвращает строку s, выравненную по правому
- 75. string.rstrip([ ]) обрезает пробельные символы справа Возвращает копию s без пробельных символов, удаленных с правого края:
- 76. string.strip([ ]) удаляет символы с левого и правого края строки. Эквивалентно последовательному вызову s.lstrip()и s.rstrip(). Без
- 77. Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
- 78. string.zfill( ) дополняет строку нулями слева. Возвращает копию s дополненную '0' слева для достижения длины строки
- 79. .zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если
- 80. Методы преобразование строки в список
- 81. Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Многие из этих методов
- 82. string.join( ) объединяет список в строку. Возвращает строку, которая является результатом конкатенации объекта с разделителем s.
- 83. string.partition( ) делит строку на основе разделителя. Отделяет от s подстроку длиной от начала до первого
- 84. s.rpartition( ) делит строку на основе разделителя, начиная с конца. Работает как s.partition( ), за исключением
- 85. string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок. Без аргументов делит s на подстроки, разделенные любой
- 86. string.rsplit(sep=None, maxsplit=-1) Если = None, строка разделяется пробелами, как если бы не был указан вообще. Когда
- 87. string.rsplit(sep=None, maxsplit=-1) Если указан необязательный параметр , выполняется максимальное количество разделений, начиная с правого края s:
- 88. string.rsplit(sep=None, maxsplit=-1) Значение по умолчанию для — -1. Это значит, что все возможные разделения должны быть
- 89. string.splitlines([ ]) делит текст на список строк. Любой из следующих символов или последовательностей символов считается границей
- 90. string.splitlines([ ]) Если необязательный аргумент указан и его булевое значение True, то символы границы строк сохраняются
- 92. Скачать презентацию

Введение
Строки в языке Python являются типом данных, специально предназначенным для обработки
Введение
Строки в языке Python являются типом данных, специально предназначенным для обработки

Форматирование строк в Python
"Старый стиль" форматирования строк (оператор %)
"Новый стиль" форматирования
Форматирование строк в Python
"Старый стиль" форматирования строк (оператор %)
"Новый стиль" форматирования

"Старый стиль" форматирования строк
(оператор %)
"Старый стиль" форматирования строк
(оператор %)

"Старый стиль" форматирования строк
(оператор %)
Во многом аналогичен функции printf в C.
Подробнее
"Старый стиль" форматирования строк
(оператор %)
Во многом аналогичен функции printf в C.
Подробнее

Если переменных много, что код быстро становиться плохо читаемым:
first_name = "Eric"
last_name
Если переменных много, что код быстро становиться плохо читаемым:
first_name = "Eric"
last_name
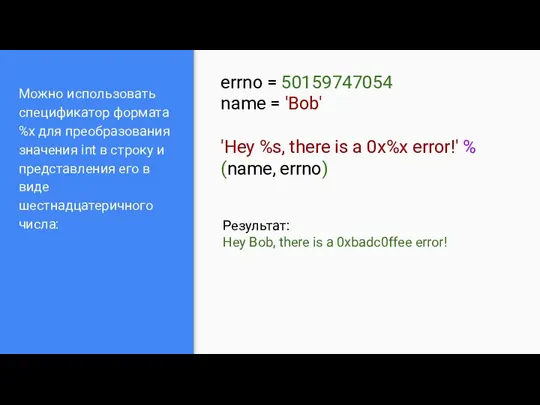
Можно использовать спецификатор формата %x для преобразования значения int в строку
Можно использовать спецификатор формата %x для преобразования значения int в строку

Также можно производить подстановку переменных по имени:
'Hey %(name)s, there is a
Также можно производить подстановку переменных по имени:
'Hey %(name)s, there is a

К сожалению, этот вид форматирования не очень хорош, потому что он
К сожалению, этот вид форматирования не очень хорош, потому что он

Официальная документация Python 3 не рекомендует форматирование «старого стиля» и говорит
Официальная документация Python 3 не рекомендует форматирование «старого стиля» и говорит

"Новый стиль" (str.format)
"Новый стиль" (str.format)

"Новый стиль" (str.format)
str.format () - это улучшение % форматирования. Он использует
"Новый стиль" (str.format)
str.format () - это улучшение % форматирования. Он использует

Можно ссылаться на переменные в любом порядке, используя их индекс:
"Hello, {1}.
Можно ссылаться на переменные в любом порядке, используя их индекс:
"Hello, {1}.

Но если вы вставите имена переменных, вы получите дополнительную возможность передавать
Но если вы вставите имена переменных, вы получите дополнительную возможность передавать
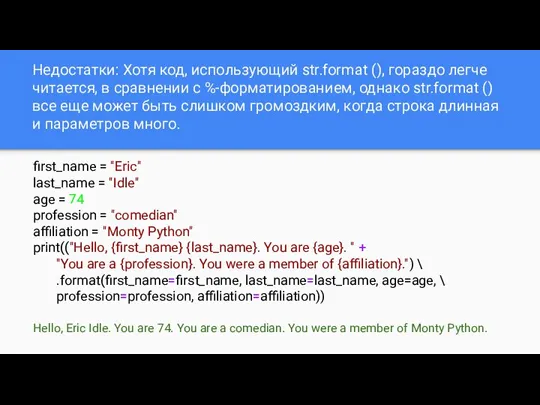
Недостатки: Хотя код, использующий str.format (), гораздо легче читается, в сравнении
Недостатки: Хотя код, использующий str.format (), гораздо легче читается, в сравнении

f-Strings / Интерполяция строк
f-Strings / Интерполяция строк
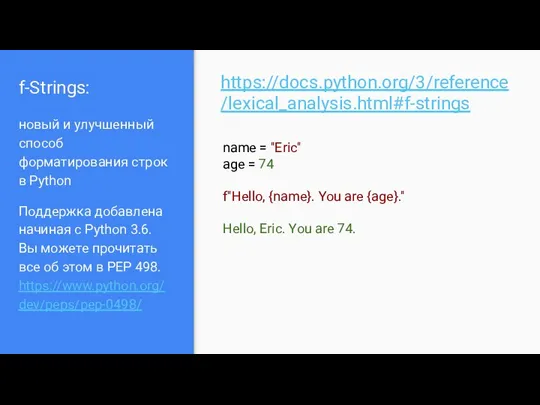
f-Strings:
новый и улучшенный способ форматирования строк в Python
Поддержка добавлена начиная с
f-Strings:
новый и улучшенный способ форматирования строк в Python
Поддержка добавлена начиная с

Произвольные выражения:
Поскольку f-строки вычисляются во время выполнения, в них можно поместить
Произвольные выражения:
Поскольку f-строки вычисляются во время выполнения, в них можно поместить

Можно вызвать метод напрямую:
print( f"{name.lower()} is funny." )
eric idle is funny.
Можно вызвать метод напрямую:
print( f"{name.lower()} is funny." )
eric idle is funny.

Другой пример:
print(f'Если поделить торт на трех человек, каждый из них получит
Другой пример:
print(f'Если поделить торт на трех человек, каждый из них получит

Пример с классом:
class Comedian:
def __init__(self, first_name, last_name, age):
self.first_name =
Пример с классом:
class Comedian:
def __init__(self, first_name, last_name, age):
self.first_name =
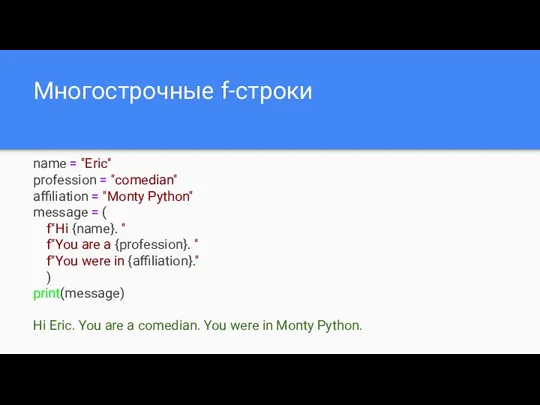
Многострочные f-строки
name = "Eric"
profession = "comedian"
affiliation = "Monty Python"
message = (
Многострочные f-строки
name = "Eric"
profession = "comedian"
affiliation = "Monty Python"
message = (
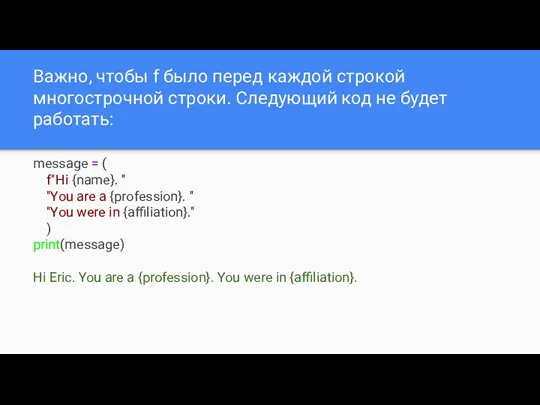
Важно, чтобы f было перед каждой строкой многострочной строки. Следующий код
Важно, чтобы f было перед каждой строкой многострочной строки. Следующий код
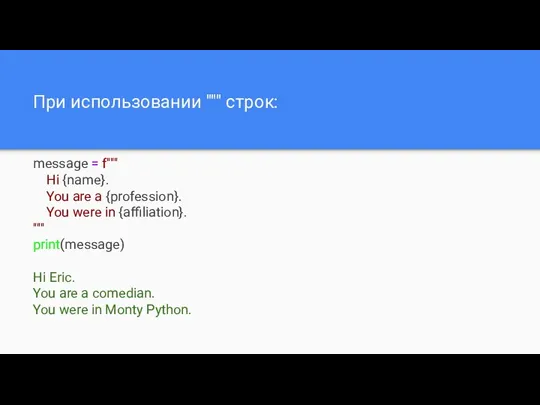
При использовании """ строк:
message = f"""
Hi {name}.
You are
При использовании """ строк:
message = f"""
Hi {name}.
You are

Скорость
Символ f в f-string также может означать «быстро» (fast).
f-строки быстрее, чем
Скорость
Символ f в f-string также может означать «быстро» (fast).
f-строки быстрее, чем
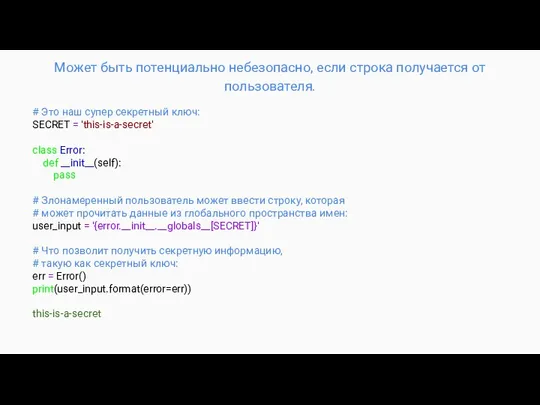
Может быть потенциально небезопасно, если строка получается от пользователя.
# Это наш
Может быть потенциально небезопасно, если строка получается от пользователя.
# Это наш

Шаблонные строки (Стандартная библиотека Template Strings)
Шаблонные строки (Стандартная библиотека Template Strings)

Шаблоны (Standard Library)
Еще один инструмент для форматирования строк в Python: шаблоны.
Шаблоны (Standard Library)
Еще один инструмент для форматирования строк в Python: шаблоны.

Нужно импортировать класс Template из встроенного строкового модуля Python. Шаблонные строки
Нужно импортировать класс Template из встроенного строкового модуля Python. Шаблонные строки
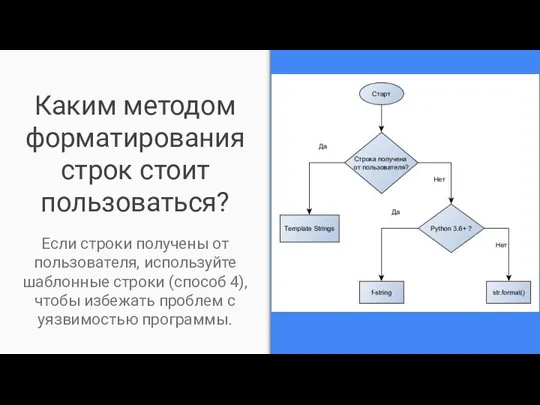
Каким методом форматирования строк стоит пользоваться?
Если строки получены от пользователя, используйте
Каким методом форматирования строк стоит пользоваться?
Если строки получены от пользователя, используйте
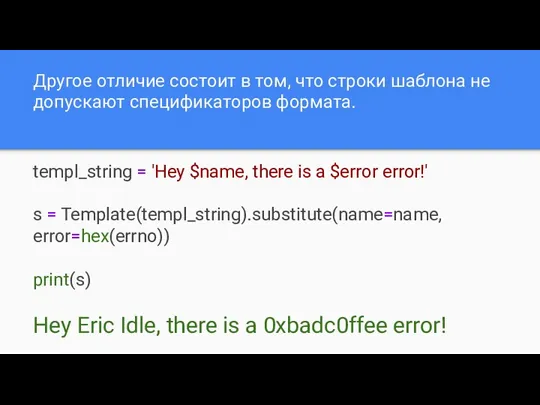
Другое отличие состоит в том, что строки шаблона не допускают спецификаторов
Другое отличие состоит в том, что строки шаблона не допускают спецификаторов

Отступы и выравнивание строк
Отступы и выравнивание строк

Добавить отступы слева:
test = 'test'
print('%10s' % (test,))
print('{:>10}'.format(test))
print(f'{test:>10}')
test
test
test
Добавить отступы слева:
test = 'test'
print('%10s' % (test,))
print('{:>10}'.format(test))
print(f'{test:>10}')
test
test
test

Добавить отступы справа:
test = 'test'
print('{:_<10}'.format(test))
print(f'{test:_<10}')
test______
test______
Добавить отступы справа:
test = 'test'
print('{:_<10}'.format(test))
print(f'{test:_<10}')
test______
test______

Выравнивание по центру:
Eсли при выравнивании по центру получается нечетное количество отступов,
Выравнивание по центру:
Eсли при выравнивании по центру получается нечетное количество отступов,

Усечение длинных строк
print('%.5s' % ('xylophone',))
print('{:.5}'.format('xylophone'))
print(f'{"xylophone":.5}')
xylop
xylop
xylop
print(f'"{"xylophone":10.5}"')
"xylop "
Усечение длинных строк
print('%.5s' % ('xylophone',))
print('{:.5}'.format('xylophone'))
print(f'{"xylophone":.5}')
xylop
xylop
xylop
print(f'"{"xylophone":10.5}"')
"xylop "

Целые числа:
print('%d' % (42,))
print('{:d}'.format(42))
print(f'{42:d}')
42
42
42
Целые числа:
print('%d' % (42,))
print('{:d}'.format(42))
print(f'{42:d}')
42
42
42

Целые числа:
print(f'Показывать знак, даже если число положительное: {42:_>+6d}')
print(f'{-42:_>+54d}')
Показывать знак, даже если
Целые числа:
print(f'Показывать знак, даже если число положительное: {42:_>+6d}')
print(f'{-42:_>+54d}')
Показывать знак, даже если
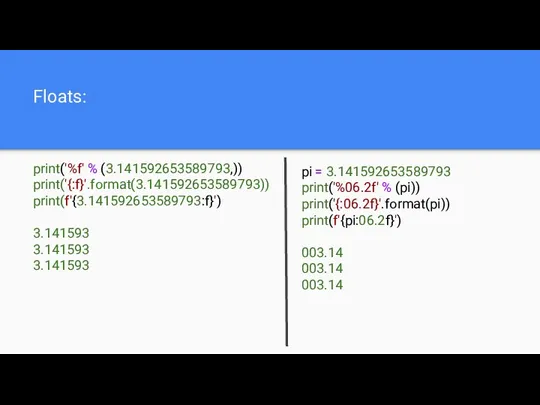
Floats:
print('%f' % (3.141592653589793,))
print('{:f}'.format(3.141592653589793))
print(f'{3.141592653589793:f}')
3.141593
3.141593
3.141593
pi = 3.141592653589793
print('%06.2f' % (pi))
print('{:06.2f}'.format(pi))
print(f'{pi:06.2f}')
003.14
003.14
003.14
Floats:
print('%f' % (3.141592653589793,))
print('{:f}'.format(3.141592653589793))
print(f'{3.141592653589793:f}')
3.141593
3.141593
3.141593
pi = 3.141592653589793
print('%06.2f' % (pi))
print('{:06.2f}'.format(pi))
print(f'{pi:06.2f}')
003.14
003.14
003.14

print(f'{42:_^+10.2f}')
__+42.00__
print(f'{42:_^+10.2f}')
__+42.00__

Пробел означает, что для отрицательного значения будет отображен минус, а для
Пробел означает, что для отрицательного значения будет отображен минус, а для

points = 19.5
total = 22
print('Correct answers: {:.2%}'.format(points/total))
print(f'Correct answers: {points/total:.2%}')
Correct answers: 88.64%
Correct
points = 19.5
total = 22
print('Correct answers: {:.2%}'.format(points/total))
print(f'Correct answers: {points/total:.2%}')
Correct answers: 88.64%
Correct
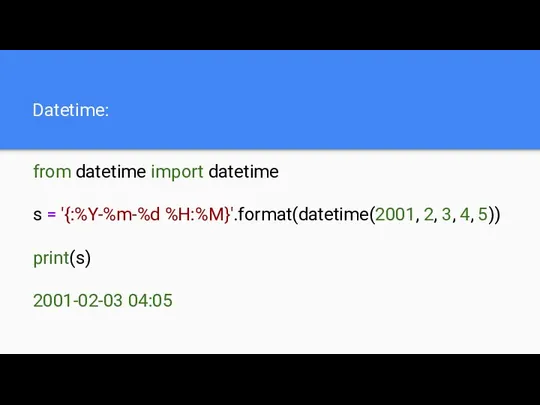
Datetime:
from datetime import datetime
s = '{:%Y-%m-%d %H:%M}'.format(datetime(2001, 2, 3, 4, 5))
print(s)
2001-02-03
Datetime:
from datetime import datetime
s = '{:%Y-%m-%d %H:%M}'.format(datetime(2001, 2, 3, 4, 5))
print(s)
2001-02-03
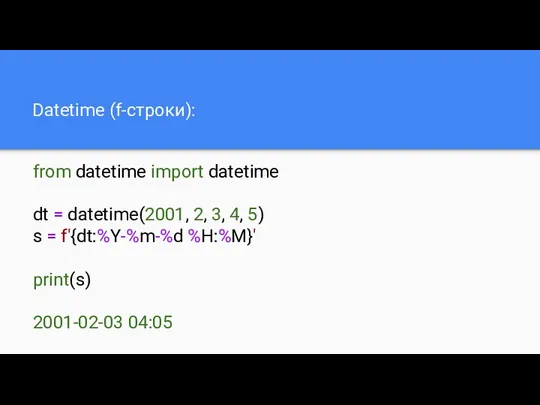
Datetime (f-строки):
from datetime import datetime
dt = datetime(2001, 2, 3, 4, 5)
s
Datetime (f-строки):
from datetime import datetime
dt = datetime(2001, 2, 3, 4, 5)
s

Встроенные методы строк в python
Встроенные методы строк в python

string.capitalize()
приводит первую букву в верхний регистр, остальные в нижний.
Возвращает копию s
string.capitalize()
приводит первую букву в верхний регистр, остальные в нижний.
Возвращает копию s

string.lower()
преобразует все буквенные символы в строчные.
Возвращает копию s со всеми буквенными
string.lower()
преобразует все буквенные символы в строчные.
Возвращает копию s со всеми буквенными

string.swapcase()
возвращает копию s с заглавными буквенными символами, преобразованными в строчные и
string.swapcase()
возвращает копию s с заглавными буквенными символами, преобразованными в строчные и

string.title()
преобразует первые буквы всех слов в заглавные.
возвращает копию, s в которой
string.title()
преобразует первые буквы всех слов в заглавные.
возвращает копию, s в которой

string.upper()
преобразует все буквенные символы в заглавные.
Возвращает копию s со всеми буквенными
string.upper()
преобразует все буквенные символы в заглавные.
Возвращает копию s со всеми буквенными

Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска

Каждый метод в этой группе поддерживает необязательные аргументы и
Каждый метод в этой группе поддерживает необязательные аргументы
![string.count( [, [, ]]) подсчитывает количество вхождений подстроки в строку.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-52.jpg)
string.count([, [, ]])
подсчитывает количество вхождений подстроки в строку.
Возвращает количество точных вхождений
string.count([, подсчитывает количество вхождений подстроки в строку.
Возвращает количество точных вхождений
![string.endswith( [, [, ]]) определяет, заканчивается ли строка заданной подстрокой.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-53.jpg)
string.endswith([, [, ]])
определяет, заканчивается ли строка заданной подстрокой.
Возвращает, True если s
string.endswith( определяет, заканчивается ли строка заданной подстрокой.
Возвращает, True если s

Например, метод endswith() можно использовать для проверки окончания файла.
filenames = ["file.txt",
Например, метод endswith() можно использовать для проверки окончания файла.
filenames = ["file.txt",
![string.find( [, [, ]]) ищет в строке заданную подстроку. Возвращает](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-55.jpg)
string.find([, [, ]])
ищет в строке заданную подстроку.
Возвращает первый индекс в s
string.find([, ищет в строке заданную подстроку.
Возвращает первый индекс в s
![string.index( [, [, ]]) ищет в строке заданную подстроку. Этот](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-56.jpg)
string.index([, [, ]])
ищет в строке заданную подстроку.
Этот метод идентичен .find(), за
string.index([, ищет в строке заданную подстроку.
Этот метод идентичен .find(), за
![string.rfind( [, [, ]]) ищет в строке заданную подстроку, начиная](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-57.jpg)
string.rfind([, [, ]])
ищет в строке заданную подстроку, начиная с конца.
Возвращает индекс
string.rfind([, ищет в строке заданную подстроку, начиная с конца.
Возвращает индекс
![string.rindex( [, [, ]]) ищет в строке заданную подстроку, начиная](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-58.jpg)
string.rindex([, [, ]])
ищет в строке заданную подстроку, начиная с конца.
Этот метод
string.rindex([, ищет в строке заданную подстроку, начиная с конца.
Этот метод
![string.startswith( [, [, ]]) определяет, начинается ли строка с заданной](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-59.jpg)
string.startswith([, [, ]])
определяет, начинается ли строка с заданной подстроки.
Возвращает, True если
string.startswith( определяет, начинается ли строка с заданной подстроки.
Возвращает, True если

Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые

string.isalnum()
определяет, состоит ли строка из букв и цифр.
Возвращает True, если строка
string.isalnum()
определяет, состоит ли строка из букв и цифр.
Возвращает True, если строка

string.isalpha()
определяет, состоит ли строка только из букв.
Возвращает True, если строка s
string.isalpha()
определяет, состоит ли строка только из букв.
Возвращает True, если строка s

string.isdigit()
определяет, состоит ли строка из цифр (проверка на число).
Возвращает True когда
string.isdigit()
определяет, состоит ли строка из цифр (проверка на число). Возвращает True когда

string.isidentifier()
определяет, является ли строка допустимым идентификатором Python.
Возвращает True, если s валидный
string.isidentifier()
определяет, является ли строка допустимым идентификатором Python.
Возвращает True, если s валидный

string.islower()
определяет, являются ли буквенные символы строки строчными.
возвращает True, если строка s
string.islower()
определяет, являются ли буквенные символы строки строчными.
возвращает True, если строка s

string.isprintable()
определяет, состоит ли строка только из печатаемых символов.
возвращает, True если строка
string.isprintable()
определяет, состоит ли строка только из печатаемых символов.
возвращает, True если строка

string.isspace()
определяет, состоит ли строка только из пробельных символов.
возвращает True, если s
string.isspace()
определяет, состоит ли строка только из пробельных символов.
возвращает True, если s

string.istitle()
определяет, начинаются ли слова строки с заглавной буквы.
возвращает True когда s
string.istitle()
определяет, начинаются ли слова строки с заглавной буквы.
возвращает True когда s

Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
![string.center( [, ]) выравнивает строку по центру. Возвращает строку, состоящую](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-70.jpg)
string.center([, ])
выравнивает строку по центру.
Возвращает строку, состоящую из s выровненной по
string.center( выравнивает строку по центру.
Возвращает строку, состоящую из s выровненной по
![string.lstrip([ ]) обрезает пробельные символы слева. Возвращает копию s в](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-71.jpg)
string.lstrip([])
обрезает пробельные символы слева.
Возвращает копию s в которой все пробельные символы
string.lstrip([ обрезает пробельные символы слева.
Возвращает копию s в которой все пробельные символы
![string.replace( , [, ]) заменяет вхождения подстроки в строке. Возвращает](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-72.jpg)
string.replace(, [, ])
заменяет вхождения подстроки в строке.
Возвращает копию s где
string.replace( заменяет вхождения подстроки в строке.
Возвращает копию s где
![string.rjust( [, ]) выравнивание по правому краю строки в поле.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-73.jpg)
string.rjust([, ])
выравнивание по правому краю строки в поле.
возвращает строку s, выравненную
string.rjust( выравнивание по правому краю строки в поле.
возвращает строку s, выравненную
![string.rstrip([ ]) обрезает пробельные символы справа Возвращает копию s без](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-74.jpg)
string.rstrip([])
обрезает пробельные символы справа
Возвращает копию s без пробельных символов, удаленных с
string.rstrip([ обрезает пробельные символы справа
Возвращает копию s без пробельных символов, удаленных с
![string.strip([ ]) удаляет символы с левого и правого края строки.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-75.jpg)
string.strip([])
удаляет символы с левого и правого края строки.
Эквивалентно последовательному вызову s.lstrip()и
string.strip([ удаляет символы с левого и правого края строки.
Эквивалентно последовательному вызову s.lstrip()и

Важно: Когда возвращаемое значение метода является другой строкой, как это часто
Важно: Когда возвращаемое значение метода является другой строкой, как это часто

string.zfill()
дополняет строку нулями слева.
Возвращает копию s дополненную '0' слева для достижения
string.zfill( дополняет строку нулями слева.
Возвращает копию s дополненную '0' слева для достижения
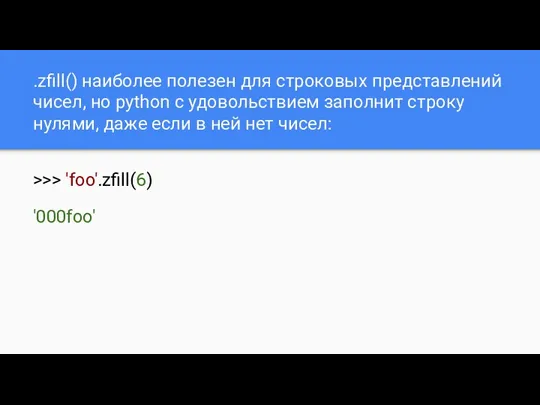
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием

Методы преобразование строки в список
Методы преобразование строки в список

Методы в этой группе преобразовывают строку в другой тип данных и
Методы в этой группе преобразовывают строку в другой тип данных и

string.join()
объединяет список в строку.
Возвращает строку, которая является результатом конкатенации объекта
string.join( объединяет список в строку.
Возвращает строку, которая является результатом конкатенации объекта

string.partition()
делит строку на основе разделителя.
Отделяет от s подстроку длиной от начала
string.partition( делит строку на основе разделителя.
Отделяет от s подстроку длиной от начала

s.rpartition()
делит строку на основе разделителя, начиная с конца.
Работает как s.partition(), за
s.rpartition( делит строку на основе разделителя, начиная с конца.
Работает как s.partition(

string.rsplit(sep=None, maxsplit=-1)
делит строку на список из подстрок.
Без аргументов делит s на
string.rsplit(sep=None, maxsplit=-1)
делит строку на список из подстрок.
Без аргументов делит s на
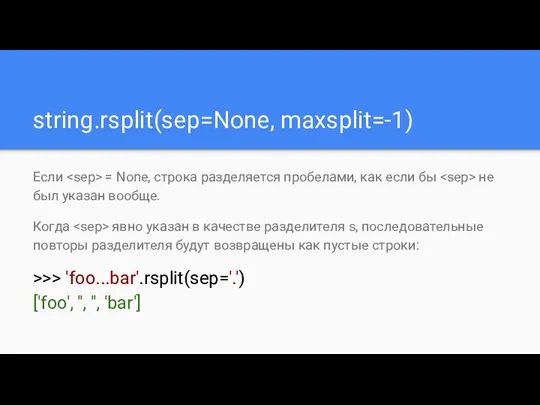
string.rsplit(sep=None, maxsplit=-1)
Если = None, строка разделяется пробелами, как если бы
string.rsplit(sep=None, maxsplit=-1)
Если
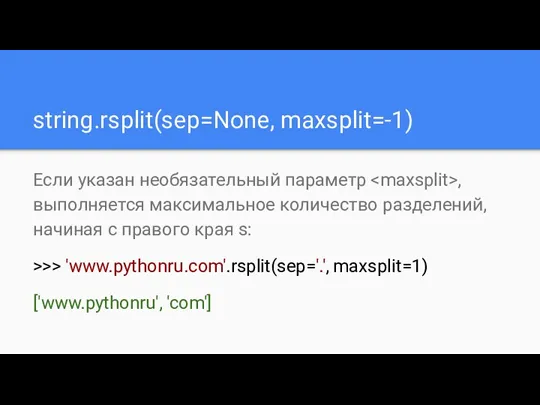
string.rsplit(sep=None, maxsplit=-1)
Если указан необязательный параметр , выполняется максимальное количество разделений, начиная
string.rsplit(sep=None, maxsplit=-1)
Если указан необязательный параметр

string.rsplit(sep=None, maxsplit=-1)
Значение по умолчанию для — -1. Это значит, что
string.rsplit(sep=None, maxsplit=-1)
Значение по умолчанию для
![string.splitlines([ ]) делит текст на список строк. Любой из следующих](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-88.jpg)
string.splitlines([])
делит текст на список строк.
Любой из следующих символов или последовательностей символов
string.splitlines([ делит текст на список строк.
Любой из следующих символов или последовательностей символов
![string.splitlines([ ]) Если необязательный аргумент указан и его булевое значение](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/327378/slide-89.jpg)
string.splitlines([])
Если необязательный аргумент указан и его булевое значение True, то
string.splitlines([ Если необязательный аргумент
 Электронная система здравохранения РК
Электронная система здравохранения РК Электронная трудовая книжка
Электронная трудовая книжка Средства мультимедиа
Средства мультимедиа Проектирование. Типология объектов графического дизайна
Проектирование. Типология объектов графического дизайна Применение BI-систем для анализа
Применение BI-систем для анализа Классификация ЧМ интерфейсов
Классификация ЧМ интерфейсов Истинность высказываний. Логические операции
Истинность высказываний. Логические операции Информационная безопасность
Информационная безопасность Логические операции и логические выражения
Логические операции и логические выражения Фирмы - разработчики систем программирования
Фирмы - разработчики систем программирования Двоичное кодирование. 7 класс
Двоичное кодирование. 7 класс Сбор информации
Сбор информации Microsoft Excel
Microsoft Excel Функции. Объявление функции
Функции. Объявление функции Классы памяти и область действия объектов
Классы памяти и область действия объектов Компьютерные сети и топологии локальных сетей
Компьютерные сети и топологии локальных сетей Слово хак (hack), несколько разных значений. Движение хакеры
Слово хак (hack), несколько разных значений. Движение хакеры Использование технических средств для работы с информацией
Использование технических средств для работы с информацией Виды данных и информации. Формы представления информации и передачи данных
Виды данных и информации. Формы представления информации и передачи данных Решение задач с использованием условного оператора
Решение задач с использованием условного оператора Перегрузка операторов. Индексаторы. Операторы приведения типов (лекция 6)
Перегрузка операторов. Индексаторы. Операторы приведения типов (лекция 6) Использование методов неявного перебора для решения экстремальных задач на графах
Использование методов неявного перебора для решения экстремальных задач на графах САПР АССОЛЬ. Технология Вашего успеха
САПР АССОЛЬ. Технология Вашего успеха Welcome. Anti-virus
Welcome. Anti-virus Методы визуального анализа и проектирования систем. Диаграммы UML. Диаграммы классов
Методы визуального анализа и проектирования систем. Диаграммы UML. Диаграммы классов Лазерный гравер на базе Arduino
Лазерный гравер на базе Arduino Сущность и значение комплектования государственных архивов. Технотронные документы
Сущность и значение комплектования государственных архивов. Технотронные документы Основы Информационной безопасности. (Безопасность экономической информации)
Основы Информационной безопасности. (Безопасность экономической информации)