- Scikit-learn

Содержание
- 2. Jupyter Notebook, JupyterLab Интерактивная среда для запуска программного кода в браузере. Инструмент для анализа данных, Позволяет
- 3. SciPy Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация, обработка сигналов, статистика. SCIKIT-LEARN использует
- 4. SciPy # Массив NumPy преобразуем в разреженную матрицу SciPy в формате CSR # Compressed Sparse Row
- 5. Matplotlib Основная библиотека для построения графиков. Включает функции для создания высококачественных визуализаций типа линейных диаграмм, гистограмм,
- 6. Pandas Библиотека для обработки и анализа данных. Построена на основе структуры данных DataFrame (таблицы, похожие на
- 7. Вспомнить: class (target, цель) Есть ли на фото тигр? Болен ли пациент таким-то заболеванием? Продается ли
- 8. 2. Задача классификации. OneR (one rule) алгоритм Загрузить файл данных из модуля datasets библиотеки scikit-learn, вызвав
- 9. 2. Задача классификации. OneR (one rule) алгоритм # Массив target содержит сорта уже измеренных цветов, записанные
- 10. 2. Задача классификации. OneR (one rule) алгоритм Для решения задачи классификации с учителем надо иметь 2
- 11. 2. Задача классификации. OneR (one rule) алгоритм Задание3: сделать вывод по матрицам рассеяния Признаки позволяют относительно
- 12. 2. Задача классификации. OneR (one rule) алгоритм Для решения задачи классификации с учителем (построения классификатора) используем
- 14. Скачать презентацию

Jupyter Notebook, JupyterLab
Интерактивная среда для запуска программного кода в браузере.
Jupyter Notebook, JupyterLab
Интерактивная среда для запуска программного кода в браузере.

SciPy
Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация,
SciPy
Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация,

SciPy
# Массив NumPy преобразуем в разреженную матрицу SciPy в формате
SciPy
# Массив NumPy преобразуем в разреженную матрицу SciPy в формате
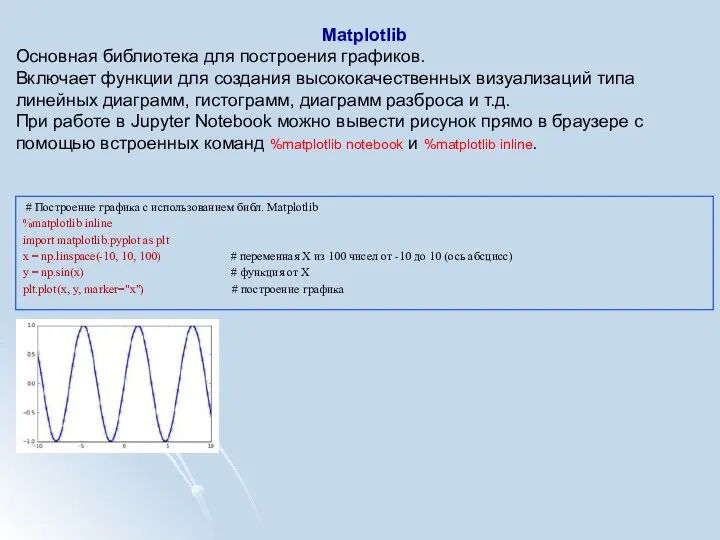
Matplotlib
Основная библиотека для построения графиков.
Включает функции для создания высококачественных
Matplotlib
Основная библиотека для построения графиков.
Включает функции для создания высококачественных

Pandas
Библиотека для обработки и анализа данных.
Построена на основе структуры
Pandas
Библиотека для обработки и анализа данных.
Построена на основе структуры

Вспомнить:
class (target, цель)
Есть ли на фото тигр?
Болен ли пациент
Вспомнить:
class (target, цель)
Есть ли на фото тигр?
Болен ли пациент

2. Задача классификации. OneR (one rule) алгоритм
Загрузить файл данных из модуля
2. Задача классификации. OneR (one rule) алгоритм
Загрузить файл данных из модуля

2. Задача классификации. OneR (one rule) алгоритм
# Массив target содержит сорта
2. Задача классификации. OneR (one rule) алгоритм
# Массив target содержит сорта

2. Задача классификации. OneR (one rule) алгоритм
Для решения задачи классификации с
2. Задача классификации. OneR (one rule) алгоритм
Для решения задачи классификации с
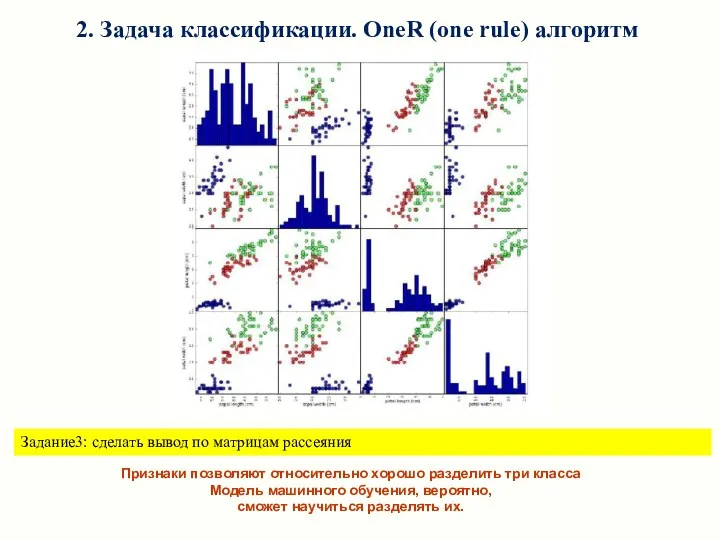
2. Задача классификации. OneR (one rule) алгоритм
Задание3: сделать вывод по матрицам
2. Задача классификации. OneR (one rule) алгоритм
Задание3: сделать вывод по матрицам

2. Задача классификации. OneR (one rule) алгоритм
Для решения задачи классификации с
2. Задача классификации. OneR (one rule) алгоритм
Для решения задачи классификации с
 Понятие программы. Лекция 1
Понятие программы. Лекция 1 Интегрированный урок по информатике Кодирование информации 3 класс
Интегрированный урок по информатике Кодирование информации 3 класс Компьютерная графика. Растровая графика
Компьютерная графика. Растровая графика Автоматическая обработка информации 10 класс (базовый уровень)
Автоматическая обработка информации 10 класс (базовый уровень) Линейные структуры данных. Лекция 2
Линейные структуры данных. Лекция 2 E-Learning электрондық оқыту әдістемесі мен жүйесі
E-Learning электрондық оқыту әдістемесі мен жүйесі Food helper. Контроль над їжею
Food helper. Контроль над їжею OTT Video over IP
OTT Video over IP Общая характеристика табличного процессора
Общая характеристика табличного процессора Оформление начальных и концевых полос
Оформление начальных и концевых полос Периодические регистры сведений
Периодические регистры сведений Паттерны проектирования (Design patterns)
Паттерны проектирования (Design patterns) Различные варианты программирования циклического алгоритма
Различные варианты программирования циклического алгоритма Создание чертежа в программе AutoCAD
Создание чертежа в программе AutoCAD Базы данных-2
Базы данных-2 Выбор данных с использованием команды SELECT языка SQL
Выбор данных с использованием команды SELECT языка SQL Чистый код: создание, анализ и рефакторинг
Чистый код: создание, анализ и рефакторинг Одномерные массивы (последовательности)
Одномерные массивы (последовательности) Архітектура комп’ютера та організація комп’ютерних мереж
Архітектура комп’ютера та організація комп’ютерних мереж Серверные и клиентские сценарии Web-приложений
Серверные и клиентские сценарии Web-приложений Алгебра высказываний
Алгебра высказываний Report. Lorem Ipsum
Report. Lorem Ipsum Алгоритмы и структуры данных. Поиск. Тема 08
Алгоритмы и структуры данных. Поиск. Тема 08 Вставка гиперссылок для управления презентацией в среде программы MS PowerPoint 2010
Вставка гиперссылок для управления презентацией в среде программы MS PowerPoint 2010 Я выбираю профессию в IT. Системный администратор
Я выбираю профессию в IT. Системный администратор Основные этапы развития информационного общества
Основные этапы развития информационного общества Урок по информатике в 9 классе
Урок по информатике в 9 классе Сетевая модель OSI
Сетевая модель OSI