- Scikit-Learn (самая известная библиотека Python для машинного обучения)

Содержание
- 2. Jupyter Notebook, JupyterLab Интерактивная среда для запуска программного кода в браузере. Инструмент для анализа данных, Позволяет
- 3. SciPy Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация, обработка сигналов, статистика. SCIKIT-LEARN использует
- 4. SciPy # Массив NumPy преобразуем в разреженную матрицу SciPy в формате CSR # Compressed Sparse Row
- 5. Matplotlib Основная библиотека для построения графиков. Включает функции для создания высококачественных визуализаций типа линейных диаграмм, гистограмм,
- 6. Pandas Библиотека для обработки и анализа данных. Построена на основе структуры данных DataFrame (таблицы, похожие на
- 7. Современные методы анализа данных Байесовский классификатор линейный дискриминант Фишера; метод парзеновского окна; разделение смеси вероятностных распределений,
- 8. Вспомнить: class (target, цель) Есть ли на фото тигр? Болен ли пациент таким-то заболеванием? Продается ли
- 9. 2. Метод ближайших соседей в задаче классификации 2.1 Классификация с использованием библиотеки scikit-learn Объект iris -
- 10. 2. Метод ближайших соседей в задаче классификации 2.1 Классификация с использованием библиотеки scikit-learn # Сами данные
- 11. # Массив target содержит сорта измеренных цветов, записанные в виде массива NumPy # и представляет собой
- 12. Для решения задачи классификации с учителем надо иметь 2 набора данных: обучающие данные (training data, training
- 13. Качественный анализ данных: матрица диаграмм рассеяния Для пары признаков – на плоскости (scatter plot). Если признаков
- 14. Задание3: сделать вывод по матрицам рассеяния Признаки позволяют относительно хорошо разделить три класса Модель машинного обучения,
- 15. Для решения задачи классификации с учителем (построения классификатора) используем метод k ближайших соседей Библиотека scikit-learn, где
- 16. Создать объект-экземпляр класса, задав параметры модели: количество соседей k (установим k = 1) # Создать объект-экземпляр
- 17. Для обучения вызывать метод fit объекта knn, который принимает в качестве аргументов массивы NumPy: X_train и
- 18. 2.1 Классификация с использованием библиотеки scikit-learn Выбор n_neighbor правильная классификация – Круг. Но т.к. ближайший сосед
- 19. 2.1 Классификация с использованием библиотеки scikit-learn Евклидова метрика Манхеттеновское расстояние Косинусное сходство Когда значительная разница в
- 20. Оценка качества работы классификатора (валидация) Оценка правильности (accuracy) выполняется на тестовых данных # Валидация классификатора на
- 21. Пример работы классификатора Установить: длина ч. 5 см, ширина ч. 2.9 см, длина л. 1 см,
- 22. Полный код классификатора import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from
- 23. Пример # Пример для пояснения нормализации данных X_broken = np.array(X) # создаем массив новый X_broken[:,0] /=
- 24. Нормализация выполняется функцией fit_transform (не меняет shape исходного массива) из модуля MinMaxScaler библиотеки sklearn.preprocessing # нормализация
- 25. 2.2 OneR (One Rule) алгоритм классификации 2. Метод ближайших соседей в задаче классификации Реализуется алгоритм: расчет
- 26. Задание 1 по теме 2 Загрузить код OneR алгоритма из файла «ex2_iris_OneR_code.ipynb». При необходимости выполнить коррекцию.
- 27. Задание 2 по теме 2 Загрузить матрицу из файла «ex2.data», csv-формат, где: кол-во строк = кол-ву
- 28. Задание 3 по теме 2 Загрузить файлы «ionosphere.data», «ionosphere.names» выполнить анализ качества данных в Excel; пояснить
- 29. Задание 3 по теме 2 help В файле data представлены данные измерений от комплекса радаров Goose
- 30. Задать n (количество соседей) от 1 до 20, рассчитать точности ( в т.ч. средние значения) avg_scores
- 32. Скачать презентацию

Jupyter Notebook, JupyterLab
Интерактивная среда для запуска программного кода в браузере.
Jupyter Notebook, JupyterLab
Интерактивная среда для запуска программного кода в браузере.

SciPy
Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация,
SciPy
Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация,

SciPy
# Массив NumPy преобразуем в разреженную матрицу SciPy в формате
SciPy
# Массив NumPy преобразуем в разреженную матрицу SciPy в формате
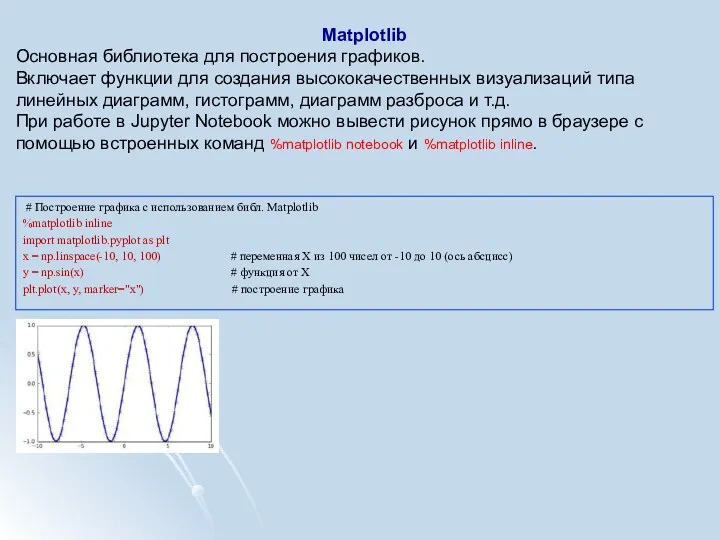
Matplotlib
Основная библиотека для построения графиков.
Включает функции для создания высококачественных
Matplotlib
Основная библиотека для построения графиков.
Включает функции для создания высококачественных

Pandas
Библиотека для обработки и анализа данных.
Построена на основе структуры
Pandas
Библиотека для обработки и анализа данных.
Построена на основе структуры
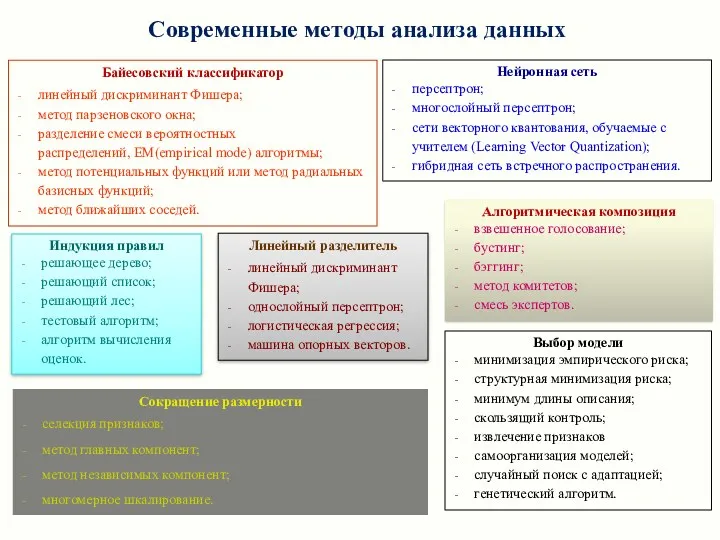
Современные методы анализа данных
Байесовский классификатор
линейный дискриминант Фишера;
метод парзеновского окна;
разделение смеси вероятностных
Современные методы анализа данных
Байесовский классификатор
линейный дискриминант Фишера;
метод парзеновского окна;
разделение смеси вероятностных

Вспомнить:
class (target, цель)
Есть ли на фото тигр?
Болен ли пациент
Вспомнить:
class (target, цель)
Есть ли на фото тигр?
Болен ли пациент

2. Метод ближайших соседей в задаче классификации
2.1 Классификация с использованием библиотеки
2. Метод ближайших соседей в задаче классификации
2.1 Классификация с использованием библиотеки
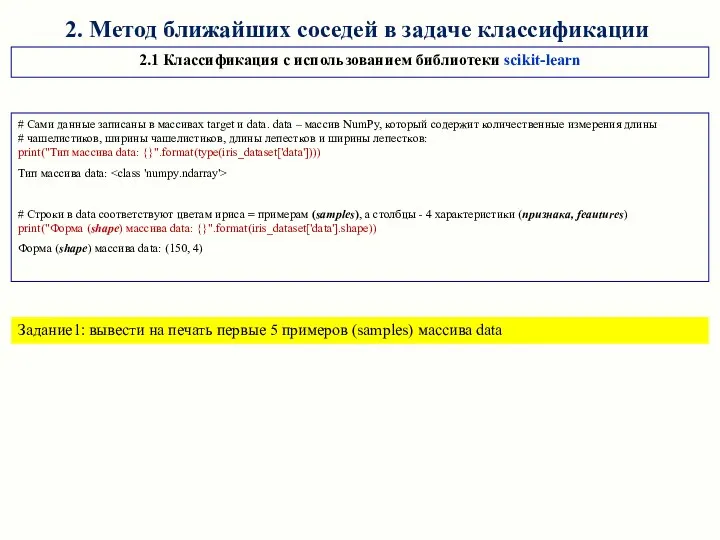
2. Метод ближайших соседей в задаче классификации
2.1 Классификация с использованием библиотеки
2. Метод ближайших соседей в задаче классификации
2.1 Классификация с использованием библиотеки
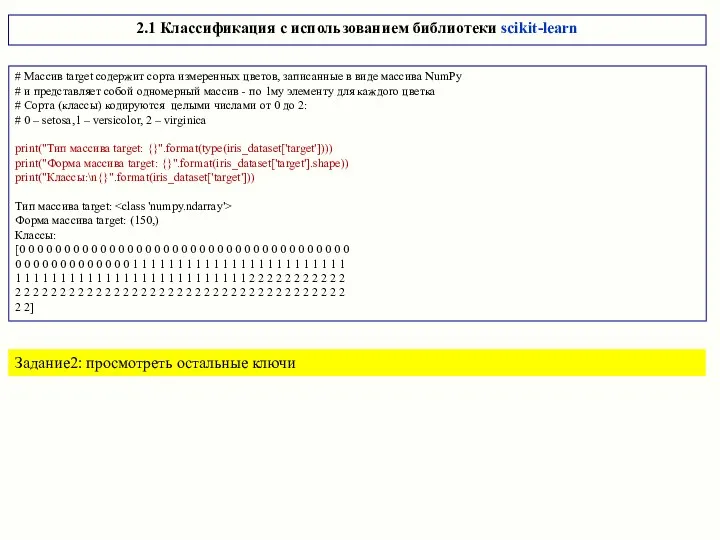
# Массив target содержит сорта измеренных цветов, записанные в виде массива
# Массив target содержит сорта измеренных цветов, записанные в виде массива
Для решения задачи классификации с учителем надо иметь 2 набора данных:
обучающие
Для решения задачи классификации с учителем надо иметь 2 набора данных:
обучающие

Качественный анализ данных: матрица диаграмм рассеяния
Для пары признаков – на плоскости
Качественный анализ данных: матрица диаграмм рассеяния
Для пары признаков – на плоскости
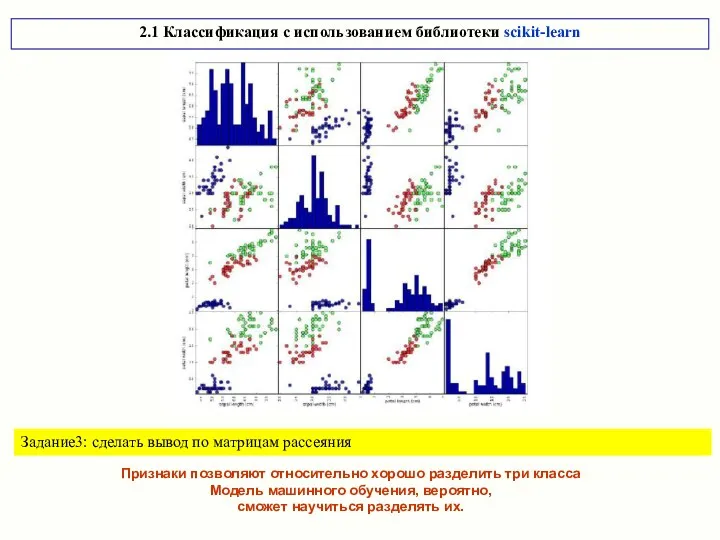
Задание3: сделать вывод по матрицам рассеяния
Признаки позволяют относительно хорошо разделить три
Задание3: сделать вывод по матрицам рассеяния
Признаки позволяют относительно хорошо разделить три

Для решения задачи классификации с учителем (построения классификатора) используем метод k
Для решения задачи классификации с учителем (построения классификатора) используем метод k

Создать объект-экземпляр класса, задав параметры модели: количество соседей k (установим k
Создать объект-экземпляр класса, задав параметры модели: количество соседей k (установим k
Для обучения вызывать метод fit объекта knn, который принимает в качестве
Для обучения вызывать метод fit объекта knn, который принимает в качестве
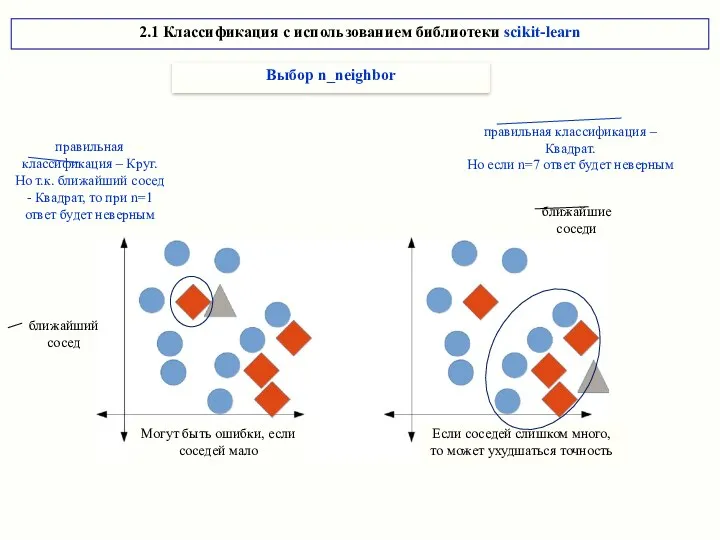
2.1 Классификация с использованием библиотеки scikit-learn
Выбор n_neighbor
правильная классификация – Круг.
Но
2.1 Классификация с использованием библиотеки scikit-learn
Выбор n_neighbor
правильная классификация – Круг.
Но
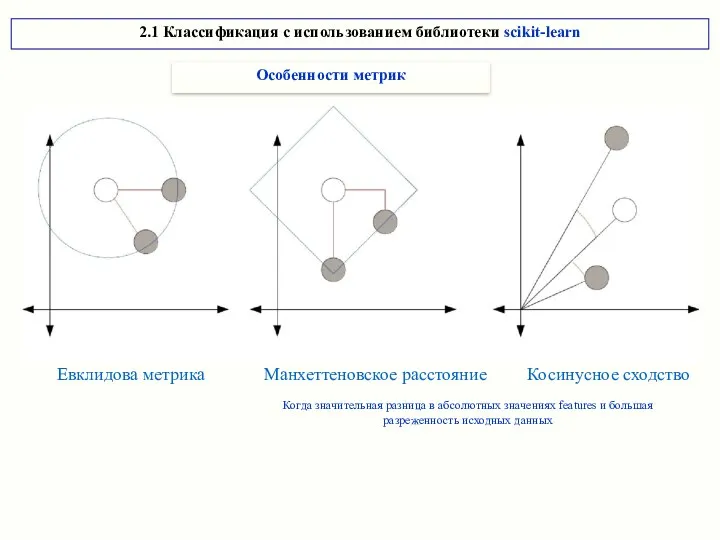
2.1 Классификация с использованием библиотеки scikit-learn
Евклидова метрика Манхеттеновское расстояние Косинусное
2.1 Классификация с использованием библиотеки scikit-learn
Евклидова метрика Манхеттеновское расстояние Косинусное

Оценка качества работы классификатора (валидация)
Оценка правильности (accuracy) выполняется на тестовых данных
#
Оценка качества работы классификатора (валидация)
Оценка правильности (accuracy) выполняется на тестовых данных
#

Пример работы классификатора
Установить: длина ч. 5 см, ширина ч. 2.9 см,
Пример работы классификатора
Установить: длина ч. 5 см, ширина ч. 2.9 см,
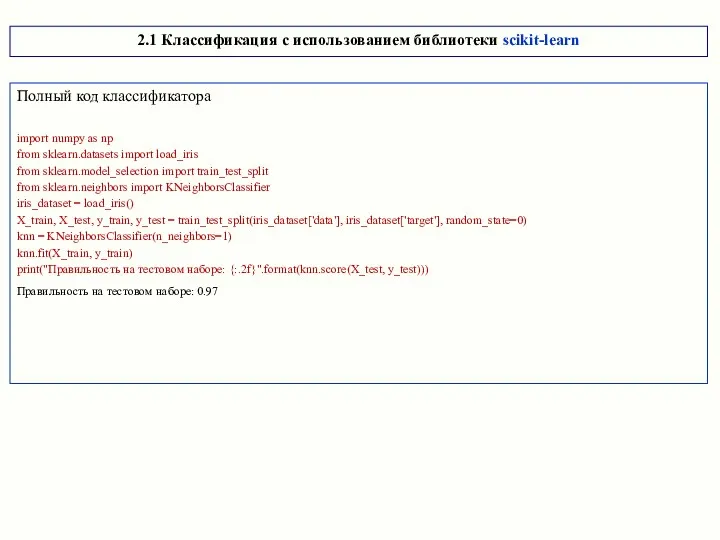
Полный код классификатора
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import
Полный код классификатора
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import
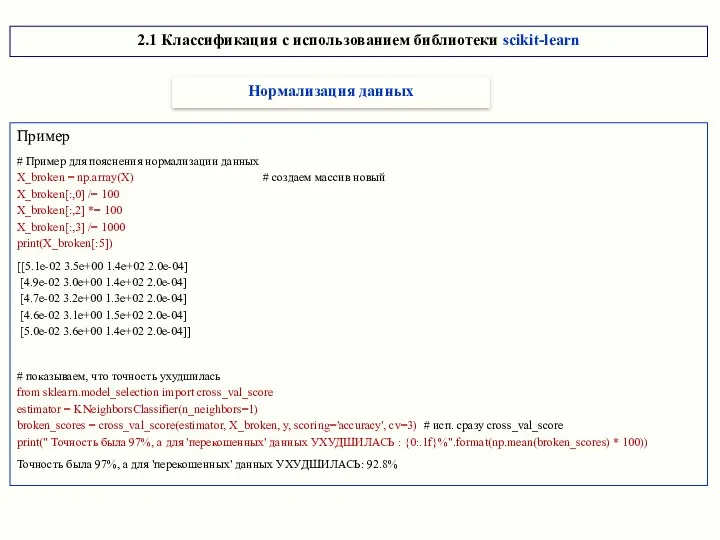
Пример
# Пример для пояснения нормализации данных
X_broken = np.array(X) # создаем массив
Пример
# Пример для пояснения нормализации данных
X_broken = np.array(X) # создаем массив

Нормализация выполняется функцией fit_transform (не меняет shape исходного массива) из модуля
Нормализация выполняется функцией fit_transform (не меняет shape исходного массива) из модуля

2.2 OneR (One Rule) алгоритм классификации
2. Метод ближайших соседей в задаче
2.2 OneR (One Rule) алгоритм классификации
2. Метод ближайших соседей в задаче
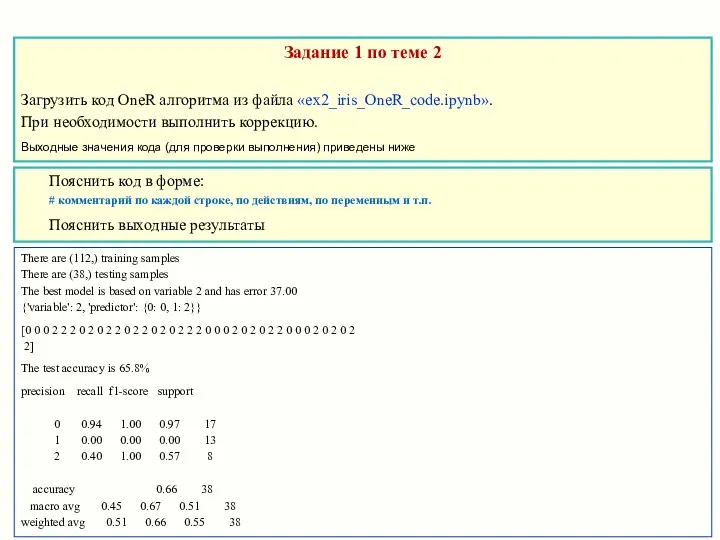
Задание 1 по теме 2
Загрузить код OneR алгоритма из файла «ex2_iris_OneR_code.ipynb».
Задание 1 по теме 2
Загрузить код OneR алгоритма из файла «ex2_iris_OneR_code.ipynb».

Задание 2 по теме 2
Загрузить матрицу из файла «ex2.data», csv-формат, где:
Задание 2 по теме 2
Загрузить матрицу из файла «ex2.data», csv-формат, где:

Задание 3 по теме 2
Загрузить файлы «ionosphere.data», «ionosphere.names»
выполнить анализ качества
Задание 3 по теме 2
Загрузить файлы «ionosphere.data», «ionosphere.names»
выполнить анализ качества

Задание 3 по теме 2 help
В файле data представлены данные измерений
Задание 3 по теме 2 help
В файле data представлены данные измерений
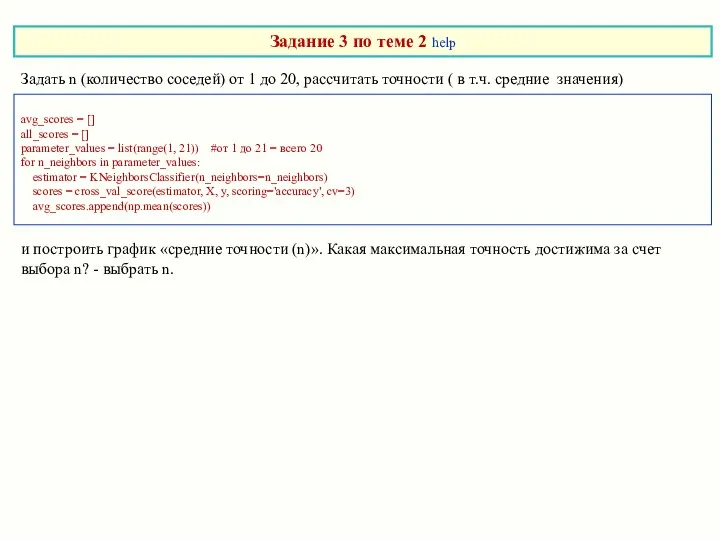
Задать n (количество соседей) от 1 до 20, рассчитать точности (
Задать n (количество соседей) от 1 до 20, рассчитать точности (
 Lecture02
Lecture02 Файлы и файловая система
Файлы и файловая система Что такое JSP?
Что такое JSP? Текстуры. Текстурирование. Детализация поверхностей цветом и формой
Текстуры. Текстурирование. Детализация поверхностей цветом и формой Средства автоматизации делопроизводства
Средства автоматизации делопроизводства 76b627bf-7290-404f-a6d9-eb0302d28c3f
76b627bf-7290-404f-a6d9-eb0302d28c3f Многообразие схем. Информационные модели на графах
Многообразие схем. Информационные модели на графах Парадигми програмування
Парадигми програмування Информация. Свойства, кодирование, измерение информации
Информация. Свойства, кодирование, измерение информации Объектно-ориентированное программирование
Объектно-ориентированное программирование Построение и анализ эффективных алгоритмов
Построение и анализ эффективных алгоритмов Интернет желілері және телекоммуникациялар
Интернет желілері және телекоммуникациялар Циклы с параметром
Циклы с параметром Простые структуры данных
Простые структуры данных Логические основы компьютеров
Логические основы компьютеров Технология деятельностного метода как средство реализации современных целей образования
Технология деятельностного метода как средство реализации современных целей образования Internet
Internet Работа с файлами. Классы для работы с файлами
Работа с файлами. Классы для работы с файлами Основные типы и форматы данных
Основные типы и форматы данных Компьютерлік желілер
Компьютерлік желілер Операционные системы. Управление памятью
Операционные системы. Управление памятью Инструкция для торгового представителя по работе с программой salesworks на мобильном устройстве
Инструкция для торгового представителя по работе с программой salesworks на мобильном устройстве Стандартные программы Windows 10
Стандартные программы Windows 10 Понятие информационной системы, БД и СУБД,
Понятие информационной системы, БД и СУБД, Программирование на Java. Объектная модель Java. (Лекция 3.1)
Программирование на Java. Объектная модель Java. (Лекция 3.1) Базовое администрирование Linux
Базовое администрирование Linux Безопасная дорога в интернет
Безопасная дорога в интернет Таблиці, електронні таблиці. Табличний процесор, його призначення. Відкривання, перегляд і збереження електронної книги
Таблиці, електронні таблиці. Табличний процесор, його призначення. Відкривання, перегляд і збереження електронної книги