- Сортировка данных

Содержание
- 2. В широком смысле сортировкой называют перестановку элементов множества в определенном порядке. Задачей сортировки является преобразование исходной
- 3. Рассматривают две категории сортировки:
- 4. Поговорим о некоторые простых видах внутренней сортировки
- 5. Сортировка простыми включениями Этот метод обычно используют игроки в карты. Элементы (карты) условно разделяют на готовую
- 6. Процесс сортировки простыми включениями показан на примере восьми случайно взятых чисел
- 7. Алгоритмы сортировки простыми включениями В графическом виде На С++ #include template void insertion_sort( Iterator first, Iterator
- 8. Сортировка простым выбором Этот метод основан на следующем правиле: выбираем (выделяем) элемент с наименьшим ключом,он меняется
- 9. Этот метод продемонстрирован на тех же восьми ключах
- 10. Алгоритмы сортировки простым выбором В графическом виде На С++ #include template void selection_sort( Iterator first, Iterator
- 11. Данный метод, в некотором смысле противоположен cортировке прямыми включениями; при сортировке простыми включениями на каждом шаге
- 12. Сортировка простым обменом Классификация методов сортировки не всегда четко определена. Методы простого включения и простого выбора
- 13. Этот метод широко известен как сортировка методом пузырька Данный алгоритм легко оптимизировать. Пример преобразования ключей, приведенный
- 14. Пример сортировки пузырьком списка случайных чисел
- 15. Алгоритмы сортировки простым обменом (пузырьковая) В графическом виде На С++ #include template void bubble_sort( Iterator First,
- 16. Сортировка методом Шелла Сортировка Шелла получила свое название по имени ее создателя Д.Л.Шелла. Однако, это название
- 17. Пример сортировки Шелла списка случайных чисел
- 18. Алгоритмы сортировки Шелла В графическом виде На С++ procedure Shell(var item: DataArray; count:integer); const t =
- 19. Быстрая сортировка Быстрая сортировка, часто называемая qsort по имени реализации в стандартной библиотеке языка Си —
- 20. Краткое описание алгоритма выбрать элемент, называемый опорным. сравнить все остальные элементы с опорным, на основании сравнения
- 21. Подробное описание алгоритма Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы: Выбираем в массиве
- 22. Пример быстрой сортировки списка случайных чисел
- 23. Если, например, выбрать средний ключ, равный 42, из массива ключей 44, 55, 12, 42, 94, 06,
- 24. В графическом виде procedure QuickSort(var item: DataArray; count:integer); procedure qs(l, r: integer; var it: DataArray); var
- 25. Сортировка выбором с помощью бинарного дерева По-другом турнирная сортировка. Бинарные деревья находят применение в качестве деревьев
- 26. Рассмотрим алгоритм турнирной сортировки на следующем примере: Пусть имеется массив из 8-ми элементов A[8]={35, 25, 50,
- 27. Процесс продолжается до тех пор, пока все листья не будут удалены. Последний (наибольший) узел играет серию
- 28. Пирамидальная сортировка Является усовершенствованным методом простого выбора и входит в число наиболее эффективных методов внутренней сортировки
- 29. Простейший алгоритм Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево — это такое двоичное дерево, у которого
- 30. Пример сортирующего дерева
- 31. Алгоритмы пирамидальной сортировки на C++ #include template void adjust_heap( Iterator first , typename std::iterator_traits ::difference_type current
- 32. Анимированная схема алгоритма
- 34. Скачать презентацию

В широком смысле сортировкой называют перестановку элементов множества в определенном порядке.
В широком смысле сортировкой называют перестановку элементов множества в определенном порядке.

Рассматривают две категории сортировки:
Рассматривают две категории сортировки:

Поговорим о некоторые простых видах внутренней сортировки
Поговорим о некоторые простых видах внутренней сортировки

Сортировка простыми включениями
Этот метод обычно используют игроки в карты. Элементы (карты)
Сортировка простыми включениями
Этот метод обычно используют игроки в карты. Элементы (карты)

Процесс сортировки простыми включениями показан на примере восьми случайно взятых чисел
Процесс сортировки простыми включениями показан на примере восьми случайно взятых чисел

Алгоритмы сортировки простыми включениями
В графическом виде
На С++
#include
template< typename Iterator
Алгоритмы сортировки простыми включениями
В графическом виде
На С++
#include
template< typename Iterator

Сортировка простым выбором
Этот метод основан на следующем правиле:
выбираем (выделяем) элемент с
Сортировка простым выбором
Этот метод основан на следующем правиле:
выбираем (выделяем) элемент с

Этот метод продемонстрирован на тех же восьми ключах
Этот метод продемонстрирован на тех же восьми ключах

Алгоритмы сортировки простым выбором
В графическом виде
На С++
#include
template< typename Iterator >
Алгоритмы сортировки простым выбором
В графическом виде
На С++
#include
template< typename Iterator >

Данный метод, в некотором смысле противоположен cортировке прямыми включениями; при сортировке

Сортировка простым обменом
Классификация методов сортировки не всегда четко определена. Методы
Сортировка простым обменом
Классификация методов сортировки не всегда четко определена. Методы
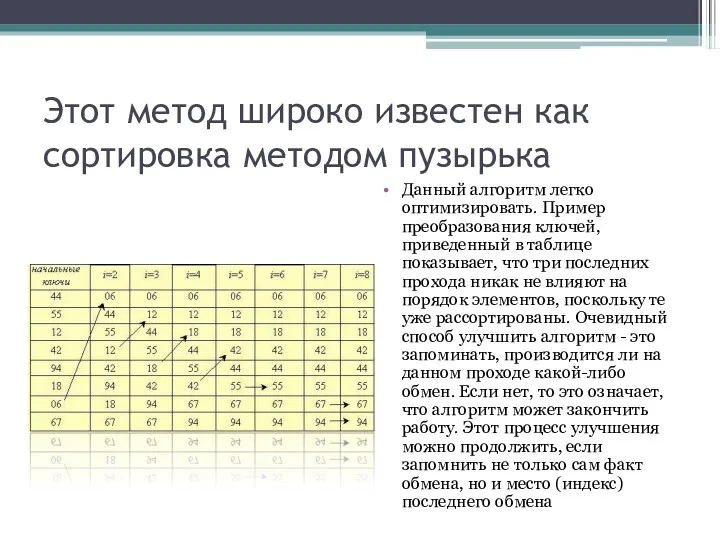
Этот метод широко известен как сортировка методом пузырька
Данный алгоритм легко оптимизировать.
Этот метод широко известен как сортировка методом пузырька
Данный алгоритм легко оптимизировать.

Пример сортировки пузырьком списка случайных чисел
Пример сортировки пузырьком списка случайных чисел

Алгоритмы сортировки простым обменом (пузырьковая)
В графическом виде
На С++
#include
template< typename Iterator
Алгоритмы сортировки простым обменом (пузырьковая)
В графическом виде
На С++
#include
template< typename Iterator

Сортировка методом Шелла
Сортировка Шелла получила свое название по имени ее создателя
Сортировка методом Шелла
Сортировка Шелла получила свое название по имени ее создателя

Пример сортировки Шелла списка случайных чисел
Пример сортировки Шелла списка случайных чисел

Алгоритмы сортировки Шелла
В графическом виде
На С++
procedure Shell(var item: DataArray; count:integer);
Алгоритмы сортировки Шелла
В графическом виде
На С++
procedure Shell(var item: DataArray; count:integer);

Быстрая сортировка
Быстрая сортировка, часто называемая qsort по имени реализации в стандартной
Быстрая сортировка
Быстрая сортировка, часто называемая qsort по имени реализации в стандартной

Краткое описание алгоритма
выбрать элемент, называемый опорным.
сравнить все остальные элементы с опорным,
Краткое описание алгоритма
выбрать элемент, называемый опорным.
сравнить все остальные элементы с опорным,

Подробное описание алгоритма
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма
Подробное описание алгоритма
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма

Пример быстрой сортировки списка случайных чисел
Пример быстрой сортировки списка случайных чисел

Если, например, выбрать средний ключ, равный 42, из массива ключей
44,
Если, например, выбрать средний ключ, равный 42, из массива ключей
44,
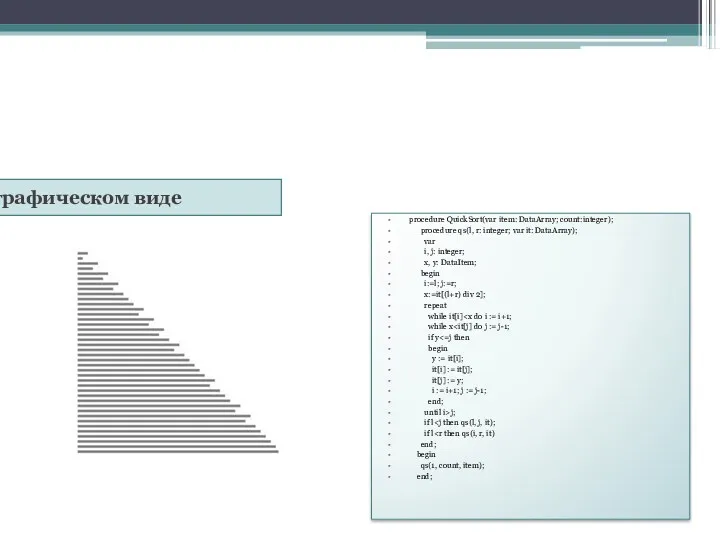
В графическом виде
procedure QuickSort(var item: DataArray; count:integer);
procedure qs(l, r:
В графическом виде
procedure QuickSort(var item: DataArray; count:integer);
procedure qs(l, r:

Сортировка выбором с помощью бинарного дерева
По-другом турнирная сортировка. Бинарные деревья находят
Сортировка выбором с помощью бинарного дерева
По-другом турнирная сортировка. Бинарные деревья находят
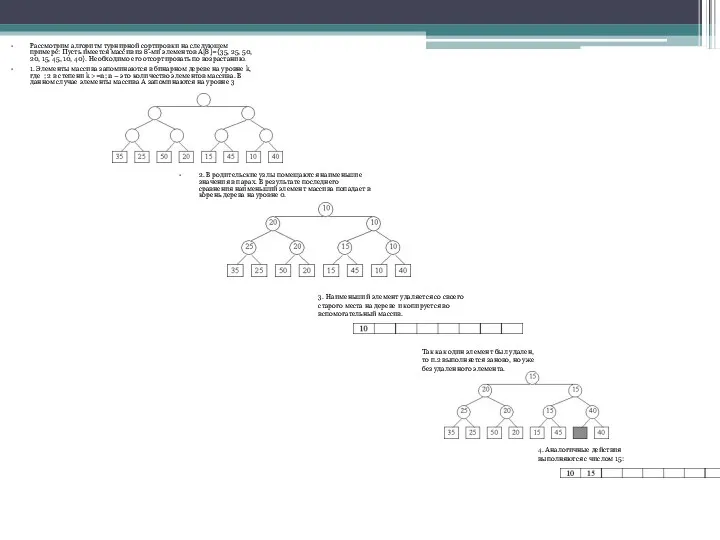
Рассмотрим алгоритм турнирной сортировки на следующем примере: Пусть имеется массив из
Рассмотрим алгоритм турнирной сортировки на следующем примере: Пусть имеется массив из
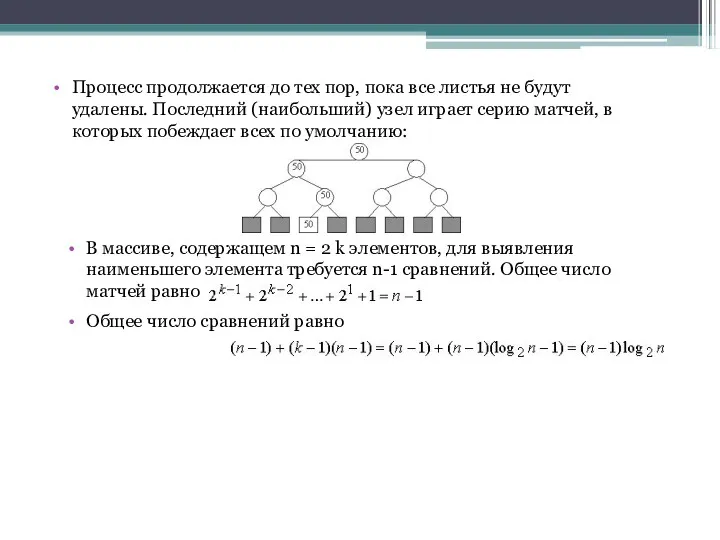
Процесс продолжается до тех пор, пока все листья не будут удалены.
Процесс продолжается до тех пор, пока все листья не будут удалены.

Пирамидальная сортировка
Является усовершенствованным методом простого выбора и входит в число наиболее
Пирамидальная сортировка
Является усовершенствованным методом простого выбора и входит в число наиболее

Простейший алгоритм
Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево — это такое
Простейший алгоритм
Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево — это такое
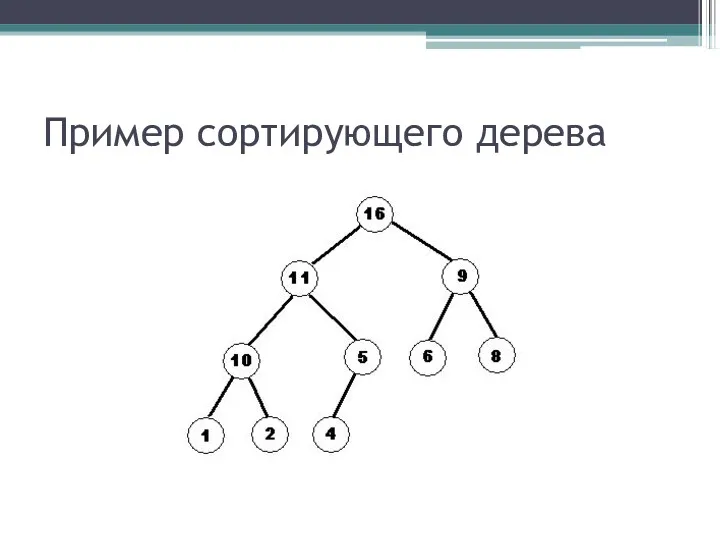
Пример сортирующего дерева
Пример сортирующего дерева

Алгоритмы пирамидальной сортировки на C++
#include
template< typename Iterator >
void adjust_heap( Iterator
Алгоритмы пирамидальной сортировки на C++
#include
template< typename Iterator >
void adjust_heap( Iterator

Анимированная схема алгоритма
Анимированная схема алгоритма
 Развивающие компьютерные игры для детей
Развивающие компьютерные игры для детей Проектирование информационных систем. Обследование и анализ информационной системы предприятия. (Лекция 1)
Проектирование информационных систем. Обследование и анализ информационной системы предприятия. (Лекция 1) Mac OS — семейство операционных систем производства корпорации Apple
Mac OS — семейство операционных систем производства корпорации Apple Учет межпредметных связей на уроках информатики
Учет межпредметных связей на уроках информатики Инструкция подключения учеников к видеоконференции через программу ZOOM
Инструкция подключения учеников к видеоконференции через программу ZOOM Урок по созданию диаграмм в Excel для финансовых отчетов
Урок по созданию диаграмм в Excel для финансовых отчетов Види і типи сайтів. Цільова аудиторія (урок 1)
Види і типи сайтів. Цільова аудиторія (урок 1) Презентация У истоков компьютерной революции
Презентация У истоков компьютерной революции Тестирование и жизненный цикл ПО. CMM. Лекция 2
Тестирование и жизненный цикл ПО. CMM. Лекция 2 Путешествие в страну информатики
Путешествие в страну информатики Действия с информацией. Тест
Действия с информацией. Тест Классы вычислительных машин (тема 1.1)
Классы вычислительных машин (тема 1.1) Как создать свой сайт?
Как создать свой сайт? Кодирование текстовой информации
Кодирование текстовой информации Общие сведения о языке программирования Паскаль. Начала программирования. Информатика. 8 класс
Общие сведения о языке программирования Паскаль. Начала программирования. Информатика. 8 класс Аддитивные технологии
Аддитивные технологии Разработка информационной системы для учета продаж билетов в авиакассах
Разработка информационной системы для учета продаж билетов в авиакассах Введение в web-программирование
Введение в web-программирование Сапр AutoCAD - основные понятия и приемы работы
Сапр AutoCAD - основные понятия и приемы работы Алгоритм создания и развития интернет ресурса
Алгоритм создания и развития интернет ресурса Виды графики
Виды графики Интересные факты в сфере информационных технологий
Интересные факты в сфере информационных технологий 20231004_prilozhenie_1
20231004_prilozhenie_1 Компьютерные технологии в обучении: определение, разновидности, этапы
Компьютерные технологии в обучении: определение, разновидности, этапы Лайфхаки Word
Лайфхаки Word Алгоритмы и исполнители
Алгоритмы и исполнители Все программы от Adobe
Все программы от Adobe Сеть Ethernet. Построение коммутируемой сети
Сеть Ethernet. Построение коммутируемой сети