- SQL. Базовый курс

Содержание
- 2. Содержание ● Часть 1. Введение в SQL ● Часть 2. Data Defenition Language ● Часть 3.
- 3. Часть 1. Введение в SQL SQL. Базовый курс
- 4. Введение в SQL SQL (англ. Structured Query Language – «язык структурированных запросов») – универсальный компьютерный язык,
- 5. Введение в SQL База данных – список или множество связанных списков с информацией Система управления базами
- 6. Реляционные и нереляционные БД Реляционная БД – база данных, основанная на реляционной модели данных: Данные в
- 7. Чем БД отличаются от электронных таблиц 1. Хранение большого количества строк В электронных таблицах количество строк
- 8. Таблица (table) Строка(row) – горизонтальный ряд ячеек, отведенный для каждого объекта таблицы. Запись (record) – данные
- 9. Основы интерфейса SQL
- 10. Различия синтаксиса функций СУБД
- 11. Синтаксис SQL Функции и названия объектов нечуствительны к регистру: SELECT = sELeCt. Однако при поиске по
- 12. Типы данных CHAR(n) – строки постоянной длины (до 256 байтов в MS SQL Server), т.е. ввели
- 13. Тип DATE По умолчанию можно представлять в базе данных дату в формате DD-MON-YYYY (например, ‘01-FEB-1900’): INSERT
- 14. Преобразование типов данных в MSSQL CONVERT(тип данных, строка, стиль) – преобразование одного формата данных в другой
- 15. Преобразование типов данных в Oracle TO_CHAR(входное значение, формат) – преобразование даты, числа, времени в строку. Формат:
- 16. Другие объекты базы данных Представление (view) – это объекты БД, которые не содержат собственных таблиц, но
- 17. Другие объекты базы данных Хранимая процедура (stored procedure) – объект базы данных, представляющий собой набор SQL-инструкций.
- 18. Разделы языка SQL DDL - Data Defenition Language (язык определения объектов БД). CREATE, ALTER, DROP и
- 19. Часть 2. Data Defenition Language SQL. Базовый курс
- 20. Data Defenition Language CREATE TABLE (создание таблиц) Общий синтаксис: CREATE TABLE имя_таблицы ( поле1 Тип поля1,
- 21. Data Defenition Language 2. ALTER TABLE (изменение таблиц) ALTER TABLE имя_таблицы {ADD }| {MODIFY }| {DROP
- 22. Часть 3. Data Manipulation Language SQL. Базовый курс
- 23. Data Manipulation Language 1. INSERT - Вставка отдельной записи. INSERT INTO имя_таблицы VALUES (значение поля1, значение
- 24. Data Manipulation Language Вставка группы записей INSERT INTO имя_таблицы SELECT…; CREATE TABLE t2 ( first_1 VARCHAR(15),
- 25. Data Manipulation Language INSERT INTO person_info VALUES (2, 'Sara', 'Doe', 'F', '9-OCT-1986', 29789.56); INSERT INTO person_info
- 26. Data Manipulation Language Целостность данных Целостность сущностей - определяет строку таблицы как уникальный экземпляр некоторой сущности.
- 27. Data Manipulation Language
- 28. Data Manipulation Language Первичный ключ ALTER TABLE имя_таблицы ADD PRIMARY KEY (имя_столбца); ALTER TABLE person_info ADD
- 29. Внешний ключ ALTER TABLE имя_подчиненной_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY (имя_столбца подчиненной таблицы) REFERENCES имя_главной_таблицы; CREATE
- 30. Data Manipulation Language INSERT INTO person_address VALUES (1, 'Moscow, Arbat street, 67-14'); INSERT INTO person_address VALUES
- 31. Связывание таблиц при создании Как мы уже рассмотрели ранее, широко используется создание первичного (PRIMARY KEY) и
- 32. Data Manipulation Language 2. UPDATE - Изменение значений столбцов таблицы A)Изменение всех значений столбца таблицы UPDATE
- 33. Data Manipulation Language 3. DELETE - Удаление строк из таблицы А) Удаление всех значений столбца таблицы
- 34. Практическое задание № 1 1. Создать БД, изображенную на рис.1 (создать таблицы и внешний ключ) 2.
- 35. Практическое задание № 1 (продолжение) 5. Увеличьте на 15% зарплату сотруднику Smith. 6. Убедитесь, что в
- 36. Часть 4. DRL. Простые запросы SQL. Базовый курс
- 37. Наша учебная БД
- 38. Data Retrieval Language SELECT – выборка данных. Этот раздел является обязательным в запросе и позволяет: SELECT
- 39. Data Retrieval Language Определение списка выходных столбцов Список выходных столбцов может быть указан несколькими способами: Указать
- 40. Конкатенация Соединение двух и более частей текста. SELECT product_name + ' was sold by ' +
- 41. Data Retrieval Language Включение вычисляемых столбцов В качестве вычисляемых столбцов запроса могут выступать: Результаты простейших арифметических
- 42. Data Retrieval Language 3. Включение констант В качестве столбцов могут выступать константы числового и символьного типов.
- 43. Data Retrieval Language 4. Переименование выходных столбцов Вычисляемым, а также любым другим столбцам, при желании, можно
- 44. Data Retrieval Language 5. Указывание принципа обработки дублей DISTINCT – запрещает появление строк-дублей в выходном множестве.
- 45. Data Retrieval Language 6. Включение агрегатных функций Функции агрегирования (функции над множествами, статистические или базовые) предназначены
- 46. Data Retrieval Language WHERE – выборка данных, которые удовлетворяют определенным условиям. SELECT поле1,…полеN FROM таблица1, ..,
- 47. Data Retrieval Language Примеры: SELECT * FROM product WHERE laststockdate IS NULL; SELECT * FROM product
- 48. Data Retrieval Language Есть и более сложные условия: Попадания во множество [NOT] IN ( | )
- 49. Data Retrieval Language Принадлежности диапазону [NOT] BETWEEN AND Предикат BETWEEN сходен с предикатом IN, но вместо
- 50. Data Retrieval Language Булевы операторы {AND|OR|NOT} Примечания: булевы оператора связывают один или несколько предикатов, образуя единственное
- 51. Data Retrieval Language Оператор примерного поиска LIKE SELECT список полей FROM список таблиц WHERE проверяемое значение
- 52. Data Retrieval Language Оператор примерного поиска LIKE … where отчество like ‘%ов%’ … where отчество like
- 53. Data Retrieval Language Оператор примерного поиска LIKE select product_name from purchase select product_name from purchase where
- 54. Data Retrieval Language Сортировка SELECT список столбцов FROM список таблиц WHERE условие ORDER BY список столбцов
- 55. Практическое задание № 2 1. Напишите запрос, полностью показывающий таблицу purchase. 2. Напишите запрос, выбирающий столбцы
- 56. Практическое задание № 2 (продолжение) 7. Напишите запрос, выводящий фамилии сотрудников, которых приняли на работу 1го,
- 57. Часть 5. Выборка данных из нескольких таблиц SQL. Базовый курс
- 58. Выборка данных из нескольких таблиц SELECT имя_таблицы_1.имя_столбца, имя_таблицы_2. имя_столбца FROM имя_таблицы_1, имя_таблицы_2; SELECT purchase.product_name, person.first_name, person.last_name
- 59. Выборка данных из нескольких таблиц с условием SELECT имя_таблицы_1.имя_столбца, имя_таблчцы_2. имя_столбца FROM имя_таблицы_1, имя_таблицы_2 WHERE имя_главной_таблицы.первичный_ключ
- 60. Типы соединения Существуют также иные способы соединения таблиц по ключам: [ ] JOIN ON представляет собой
- 61. Варианты соединения таблиц INNER JOIN SELECT * FROM address INNER JOIN phone ON address.ClientID=phone.ClientID address phone
- 62. Варианты соединения таблиц SELECT * FROM address, phone WHERE address.clientID=phone.ClientID address phone
- 63. Варианты соединения таблиц LEFT JOIN SELECT * FROM address LEFT JOIN phone ON address.ClientID=phone.ClientID address phone
- 64. Варианты соединения таблиц RIGHT JOIN SELECT * FROM address RIGHT JOIN phone ON address.ClientID=phone.ClientID address phone
- 65. Варианты соединения таблиц FULL JOIN SELECT * FROM address FULL JOIN phone ON address.ClientID=phone.ClientID address phone
- 66. Операторы соединения UNION возвращает все строки из обоих операторов SELECT; повторяющиеся значения удаляются. UNION ALL возвращает
- 67. Операторы соединения SELECT product_name FROM purchase ORDER BY product_name SELECT product_name FROM purchase_archive ORDER BY product_name
- 68. Операторы соединения SELECT product_name FROM purchase UNION ALL SELECT product_name FROM purchase_archive ORDER BY 1 SELECT
- 69. Псевдоним в области FROM При использовании больших баз со схемами принято использование псевдонимов: SELECT purc.product_name, prod.laststockdate,
- 70. Практическое задание № 3 1. Напишите запрос, выводящий декартово произведение таблиц product и purchase. 2. Напишите
- 71. Практическое задание № 3 (продолжение) 5. Напишите запрос, который выводит все неповторяющиеся в purchase коды продавцов
- 72. Часть 6. Агрегатные функции. Группирование данных. SQL. Базовый курс
- 73. Математические операторы Математический оператор – символы, обозначающие операции (+, -,*, /) Вычисления с использованием данных из
- 74. Математические операторы Функции агрегирования (функции над множествами, статистические или базовые) предназначены для вычисления некоторых значений для
- 75. Математические операторы 3. MIN – возвращает минимальное значение из указанного столбца. SELECT MIN(product_price) FROM product; 4.
- 76. Математические операторы 5. COUNT – подсчитывает записи. SELECT COUNT(*) FROM purchase; --число строк с учетом NULL
- 77. GROUP BY Этот раздел предназначен для объединения результатов запроса в группы и расчета для каждой из
- 78. HAVING HAVING – является подразделом предназначенным для ограничения числа строк в сгруппированной таблице и является частью
- 79. HAVING Т.е., подведя итог выше описанного, можно сузить назначение подраздела до: С помощью конструкции HAVING можно
- 80. Практическое задание № 4 1. Напишите запрос, показывающий, какой будет цена продукта product_price после увеличения на
- 81. Часть 7. Подзапросы SQL. Базовый курс
- 82. Подзапросы Подзапрос — это обычный запрос SELECT, вложенный в оператор SELECT, UPDATE или DELETE. Он используется
- 83. Подзапросы Есть некие ограничения использования подзапросов: Подзапрос должен выбирать только один столбец (за исключением подзапроса с
- 84. Однострочные подзапросы Однострочный подзапрос – это подзапрос, который возвращает лишь 1 значение. Используются символы сравнения с
- 85. Многострочные подзапросы Многострочный подзапрос – это подзапрос, который возвращает лишь >=1 значение. Для таких подзапросов нельзя
- 86. EXISTS EXISTS использует подзапрос в качестве аргумента и оценивает его как истинный, если в подзапросе есть
- 87. EXISTS SELECT * FROM product WHERE EXISTS (SELECT * FROM purchase WHERE product.product_name = purchase.product_name);
- 88. Групповые условия (операторы сравнения). ALL - сравнение будет производиться со всеми записями, которые возвращает подзапрос (или
- 89. Групповые условия (операторы сравнения). ANY — сравнение вернет true, если условию будет удовлетворять хотя бы одна
- 90. Практическое задание № 5 1. Напишите запрос, который возвращает всех сотрудников, которых взяли на работу в
- 91. Часть 8. Функции для работы со строками, датами и числами SQL. Базовый курс
- 92. Функции для работы с числами ROUND - округляет числа с любой заданной точностью. ROUND(входное_значение, число_знаков_после_десятичной_точки) SELECT
- 93. Функции для работы с числами TRUNC - усекает число, понижая его точность. Функция TRUNC Возвращаемое значение
- 94. Вспомогательные таблицы Вспомогательные (dummy) таблицы Для выполнения функций, без привязки к конкретным таблицам в ряде СУБД
- 95. Функции для работы с датами GETDATE – возвращает текущую дату. select getdate(); DATEADD – Возвращает дату,
- 96. Функции для работы с датами EOMONTH – возвращает последний день любого месяца, указанного в переданной ей
- 97. Функции для работы с датами DATEDIFF – возвращает количество единиц, разделяющих две даты. DATEDIFF(величина, начальная дата,
- 98. Функции для работы с текстом UPPER – ставит все символы строки в верхний регистр. LOWER -
- 99. Функции для работы с текстом LEN – определяет длину строки. SELECT product_name, LEN(product_name) LENGTH FROM product
- 100. Функции для работы с текстом SUBSTRING – обрезает значение в параметре. SUBSTRING(исходный_текст, позиция начального символа, количество
- 101. Функции для работы с текстом SELECT SUBSTRING(item_id, 1, 3) LOCATION, SUBSTRING(item_id, 5, 3) ITEM_NUMBER FROM old_item;
- 102. Функции для работы с текстом CHARINDEX- находит позицию символа (или символов), разделяющего элементы cтрок. CHARINDEX(строка 1,
- 103. Функции для работы с текстом CHARINDEX(искомый_символ, текст _для_поиска, позиция _начального_символа) SELECT item_desc, CHARINDEX(',', item_desc, 1 )
- 104. Вложение функций SELECT item_desc, SUBSTRING(item_desc, 1, CHARINDEX(',', item_desc, 1)) CATEGORY FROM old_item;
- 105. Вложение функций SELECT item_desc, SUBSTRING(item_desc, 1, CHARINDEX(',', item_desc, 1)-1) CATEGORY, SUBSTRING(item_desc, CHARINDEX(',', item_desc, 1)+2, 99) ITEM_SIZE
- 106. Практическое задание № 6 1. Использую функции для работы с датами и числами, посчитайте, сколько вам
- 107. Полезные ресурсы http://sqlfiddle.com/ - инструмент, эмулирующий пустую БД: позволяет выполнять значительную часть DML, DDR и DR
- 109. Скачать презентацию

Содержание
● Часть 1. Введение в SQL
● Часть 2. Data Defenition Language
●
Содержание
● Часть 1. Введение в SQL
● Часть 2. Data Defenition Language
●

Часть 1. Введение в SQL
SQL. Базовый курс
Часть 1. Введение в SQL
SQL. Базовый курс

Введение в SQL
SQL (англ. Structured Query Language – «язык структурированных запросов») –
Введение в SQL
SQL (англ. Structured Query Language – «язык структурированных запросов») –

Введение в SQL
База данных – список или множество связанных списков с
Введение в SQL
База данных – список или множество связанных списков с

Реляционные и нереляционные БД
Реляционная БД – база данных, основанная на реляционной
Реляционные и нереляционные БД
Реляционная БД – база данных, основанная на реляционной

Чем БД отличаются от электронных таблиц
1. Хранение большого количества строк
В электронных
Чем БД отличаются от электронных таблиц
1. Хранение большого количества строк
В электронных
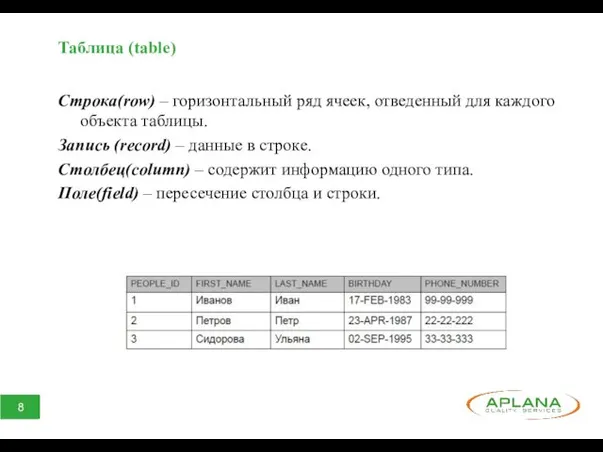
Таблица (table)
Строка(row) – горизонтальный ряд ячеек, отведенный для каждого объекта таблицы.
Запись
Таблица (table)
Строка(row) – горизонтальный ряд ячеек, отведенный для каждого объекта таблицы.
Запись
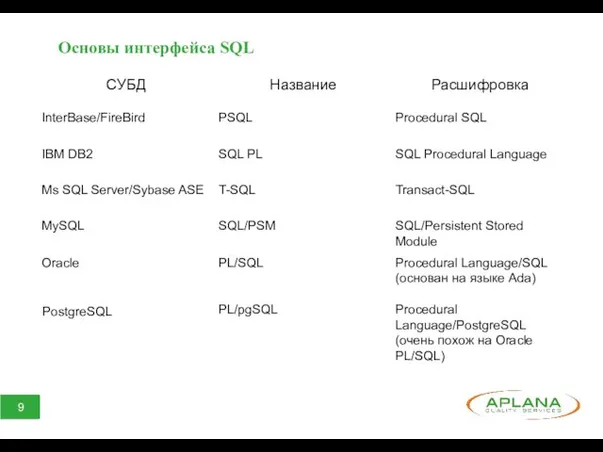
Основы интерфейса SQL
Основы интерфейса SQL

Различия синтаксиса функций СУБД
Различия синтаксиса функций СУБД

Синтаксис SQL
Функции и названия объектов нечуствительны к регистру: SELECT = sELeCt.
Однако
Синтаксис SQL
Функции и названия объектов нечуствительны к регистру: SELECT = sELeCt.
Однако

Типы данных
CHAR(n) – строки постоянной длины (до 256 байтов в MS
Типы данных
CHAR(n) – строки постоянной длины (до 256 байтов в MS

Тип DATE
По умолчанию можно представлять в базе данных дату в формате
Тип DATE
По умолчанию можно представлять в базе данных дату в формате

Преобразование типов данных в MSSQL
CONVERT(тип данных, строка, стиль) – преобразование одного
Преобразование типов данных в MSSQL
CONVERT(тип данных, строка, стиль) – преобразование одного

Преобразование типов данных в Oracle
TO_CHAR(входное значение, формат) – преобразование даты,
числа, времени
Преобразование типов данных в Oracle
TO_CHAR(входное значение, формат) – преобразование даты,
числа, времени

Другие объекты базы данных
Представление (view) – это объекты БД, которые не
Другие объекты базы данных
Представление (view) – это объекты БД, которые не

Другие объекты базы данных
Хранимая процедура (stored procedure) – объект базы данных,
Другие объекты базы данных
Хранимая процедура (stored procedure) – объект базы данных,

Разделы языка SQL
DDL - Data Defenition Language (язык определения объектов БД).
Разделы языка SQL
DDL - Data Defenition Language (язык определения объектов БД).

Часть 2. Data Defenition Language
SQL. Базовый курс
Часть 2. Data Defenition Language
SQL. Базовый курс

Data Defenition Language
CREATE TABLE (создание таблиц)
Общий синтаксис:
CREATE TABLE имя_таблицы (
поле1 Тип
Data Defenition Language
CREATE TABLE (создание таблиц)
Общий синтаксис:
CREATE TABLE имя_таблицы (
поле1 Тип

Data Defenition Language
2. ALTER TABLE (изменение таблиц)
ALTER TABLE имя_таблицы {ADD <имя
Data Defenition Language
2. ALTER TABLE (изменение таблиц)
ALTER TABLE имя_таблицы {ADD <имя

Часть 3. Data Manipulation Language
SQL. Базовый курс
Часть 3. Data Manipulation Language
SQL. Базовый курс

Data Manipulation Language
1. INSERT - Вставка отдельной записи.
INSERT INTO имя_таблицы VALUES
Data Manipulation Language
1. INSERT - Вставка отдельной записи.
INSERT INTO имя_таблицы VALUES

Data Manipulation Language
Вставка группы записей
INSERT INTO имя_таблицы
SELECT…;
CREATE TABLE t2
Data Manipulation Language
Вставка группы записей
INSERT INTO имя_таблицы
SELECT…;
CREATE TABLE t2

Data Manipulation Language
INSERT INTO person_info VALUES (2, 'Sara', 'Doe', 'F', '9-OCT-1986',
Data Manipulation Language
INSERT INTO person_info VALUES (2, 'Sara', 'Doe', 'F', '9-OCT-1986',

Data Manipulation Language
Целостность данных
Целостность сущностей - определяет строку таблицы как уникальный
Data Manipulation Language
Целостность данных
Целостность сущностей - определяет строку таблицы как уникальный
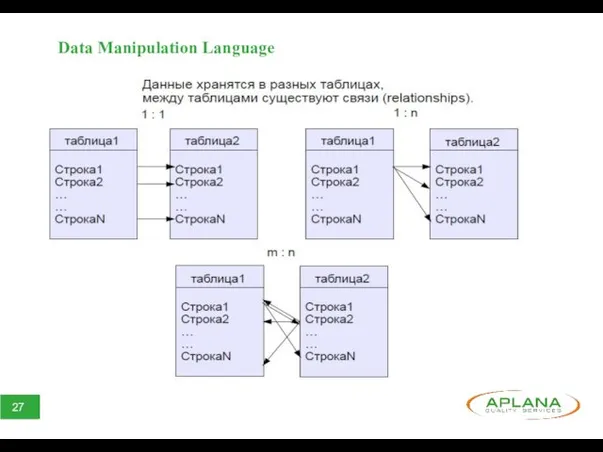
Data Manipulation Language
Data Manipulation Language

Data Manipulation Language
Первичный ключ
ALTER TABLE имя_таблицы
ADD PRIMARY KEY (имя_столбца);
ALTER TABLE
Data Manipulation Language
Первичный ключ
ALTER TABLE имя_таблицы
ADD PRIMARY KEY (имя_столбца);
ALTER TABLE

Внешний ключ
ALTER TABLE имя_подчиненной_таблицы
ADD CONSTRAINT имя_ограничения FOREIGN KEY (имя_столбца подчиненной
таблицы) REFERENCES
Внешний ключ
ALTER TABLE имя_подчиненной_таблицы
ADD CONSTRAINT имя_ограничения FOREIGN KEY (имя_столбца подчиненной
таблицы) REFERENCES

Data Manipulation Language
INSERT INTO person_address VALUES (1, 'Moscow, Arbat street, 67-14');
INSERT
Data Manipulation Language
INSERT INTO person_address VALUES (1, 'Moscow, Arbat street, 67-14');
INSERT

Связывание таблиц при создании
Как мы уже рассмотрели ранее, широко используется создание
Связывание таблиц при создании
Как мы уже рассмотрели ранее, широко используется создание

Data Manipulation Language
2. UPDATE - Изменение значений столбцов таблицы
A)Изменение всех значений
Data Manipulation Language
2. UPDATE - Изменение значений столбцов таблицы
A)Изменение всех значений

Data Manipulation Language
3. DELETE - Удаление строк из таблицы
А) Удаление всех значений
Data Manipulation Language
3. DELETE - Удаление строк из таблицы
А) Удаление всех значений

Практическое задание № 1
1. Создать БД, изображенную на рис.1 (создать таблицы
Практическое задание № 1
1. Создать БД, изображенную на рис.1 (создать таблицы

Практическое задание № 1 (продолжение)
5. Увеличьте на 15% зарплату сотруднику Smith.
6.
Практическое задание № 1 (продолжение)
5. Увеличьте на 15% зарплату сотруднику Smith.
6.

Часть 4. DRL. Простые запросы
SQL. Базовый курс
Часть 4. DRL. Простые запросы
SQL. Базовый курс
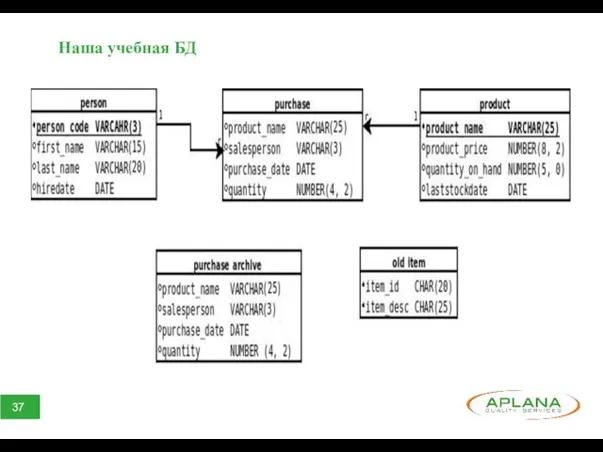
Наша учебная БД
Наша учебная БД

Data Retrieval Language
SELECT – выборка данных. Этот раздел является обязательным
Data Retrieval Language
SELECT – выборка данных. Этот раздел является обязательным

Data Retrieval Language
Определение списка выходных столбцов
Список выходных столбцов может быть
Data Retrieval Language
Определение списка выходных столбцов
Список выходных столбцов может быть

Конкатенация
Соединение двух и более частей текста.
SELECT product_name + ' was sold
Конкатенация
Соединение двух и более частей текста.
SELECT product_name + ' was sold

Data Retrieval Language
Включение вычисляемых столбцов
В качестве вычисляемых столбцов запроса могут
Data Retrieval Language
Включение вычисляемых столбцов
В качестве вычисляемых столбцов запроса могут

Data Retrieval Language
3. Включение констант
В качестве столбцов могут выступать константы числового
Data Retrieval Language
3. Включение констант
В качестве столбцов могут выступать константы числового

Data Retrieval Language
4. Переименование выходных столбцов
Вычисляемым, а также любым другим столбцам,
Data Retrieval Language
4. Переименование выходных столбцов
Вычисляемым, а также любым другим столбцам,

Data Retrieval Language
5. Указывание принципа обработки дублей
DISTINCT – запрещает появление строк-дублей
Data Retrieval Language
5. Указывание принципа обработки дублей
DISTINCT – запрещает появление строк-дублей

Data Retrieval Language
6. Включение агрегатных функций
Функции агрегирования (функции над множествами, статистические
Data Retrieval Language
6. Включение агрегатных функций
Функции агрегирования (функции над множествами, статистические

Data Retrieval Language
WHERE – выборка данных, которые удовлетворяют определенным условиям.
SELECT
Data Retrieval Language
WHERE – выборка данных, которые удовлетворяют определенным условиям.
SELECT

Data Retrieval Language
Примеры:
SELECT * FROM product WHERE laststockdate IS NULL;
SELECT
Data Retrieval Language
Примеры:
SELECT * FROM product WHERE laststockdate IS NULL;
SELECT

Data Retrieval Language
Есть и более сложные условия:
Попадания во множество
<конструктор значений
Data Retrieval Language
Есть и более сложные условия:
Попадания во множество
<конструктор значений
![Data Retrieval Language Принадлежности диапазону [NOT] BETWEEN AND Предикат BETWEEN](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1581/slide-48.jpg)
Data Retrieval Language
Принадлежности диапазону
<конструктор значений строки> [NOT] BETWEEN <конструктор значений
Data Retrieval Language
Принадлежности диапазону
<конструктор значений строки> [NOT] BETWEEN <конструктор значений

Data Retrieval Language
Булевы операторы
<предикат> {AND|OR|NOT} <предикат>
Примечания: булевы оператора связывают один
Data Retrieval Language
Булевы операторы
<предикат> {AND|OR|NOT} <предикат>
Примечания: булевы оператора связывают один

Data Retrieval Language
Оператор примерного поиска LIKE
SELECT список полей FROM список
Data Retrieval Language
Оператор примерного поиска LIKE
SELECT список полей FROM список

Data Retrieval Language
Оператор примерного поиска LIKE
… where отчество like
Data Retrieval Language
Оператор примерного поиска LIKE
… where отчество like

Data Retrieval Language
Оператор примерного поиска LIKE
select product_name from purchase
Data Retrieval Language
Оператор примерного поиска LIKE
select product_name from purchase

Data Retrieval Language
Сортировка
SELECT список столбцов FROM список таблиц WHERE условие
ORDER
Data Retrieval Language
Сортировка
SELECT список столбцов FROM список таблиц WHERE условие
ORDER

Практическое задание № 2
1. Напишите запрос, полностью показывающий таблицу purchase.
2. Напишите
Практическое задание № 2
1. Напишите запрос, полностью показывающий таблицу purchase.
2. Напишите

Практическое задание № 2 (продолжение)
7. Напишите запрос, выводящий фамилии сотрудников, которых
приняли
Практическое задание № 2 (продолжение)
7. Напишите запрос, выводящий фамилии сотрудников, которых
приняли

Часть 5. Выборка данных из нескольких таблиц
SQL. Базовый курс
Часть 5. Выборка данных из нескольких таблиц
SQL. Базовый курс

Выборка данных из нескольких таблиц
SELECT имя_таблицы_1.имя_столбца, имя_таблицы_2. имя_столбца
FROM имя_таблицы_1, имя_таблицы_2;
SELECT purchase.product_name,
Выборка данных из нескольких таблиц
SELECT имя_таблицы_1.имя_столбца, имя_таблицы_2. имя_столбца
FROM имя_таблицы_1, имя_таблицы_2;
SELECT purchase.product_name,

Выборка данных из нескольких таблиц с условием
SELECT имя_таблицы_1.имя_столбца, имя_таблчцы_2. имя_столбца
FROM имя_таблицы_1,
Выборка данных из нескольких таблиц с условием
SELECT имя_таблицы_1.имя_столбца, имя_таблчцы_2. имя_столбца
FROM имя_таблицы_1,

Типы соединения
Существуют также иные способы соединения таблиц по ключам:
<таблица А> [<тип
Типы соединения
Существуют также иные способы соединения таблиц по ключам:
<таблица А> [<тип
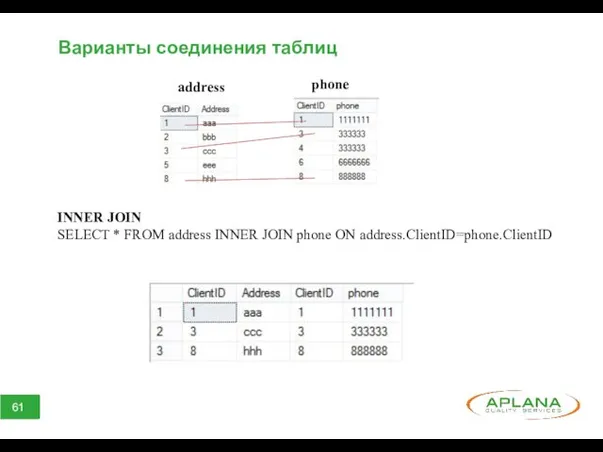
Варианты соединения таблиц
INNER JOIN
SELECT * FROM address INNER JOIN phone ON
Варианты соединения таблиц
INNER JOIN
SELECT * FROM address INNER JOIN phone ON

Варианты соединения таблиц
SELECT * FROM address, phone WHERE address.clientID=phone.ClientID
address
phone
Варианты соединения таблиц
SELECT * FROM address, phone WHERE address.clientID=phone.ClientID
address
phone

Варианты соединения таблиц
LEFT JOIN
SELECT * FROM address LEFT JOIN phone ON
Варианты соединения таблиц
LEFT JOIN
SELECT * FROM address LEFT JOIN phone ON
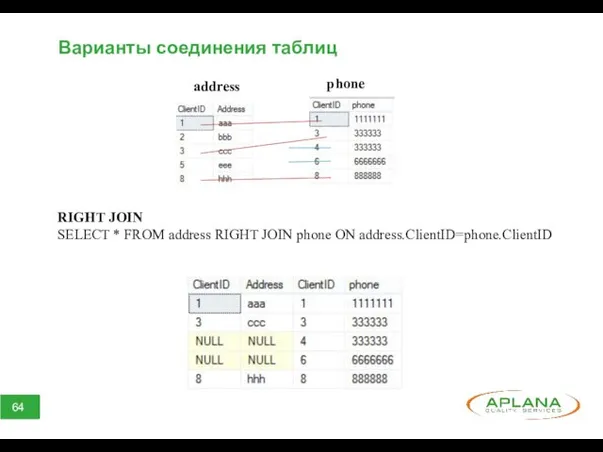
Варианты соединения таблиц
RIGHT JOIN
SELECT * FROM address RIGHT JOIN phone ON
Варианты соединения таблиц
RIGHT JOIN
SELECT * FROM address RIGHT JOIN phone ON

Варианты соединения таблиц
FULL JOIN
SELECT * FROM address FULL JOIN phone ON
Варианты соединения таблиц
FULL JOIN
SELECT * FROM address FULL JOIN phone ON

Операторы соединения
UNION возвращает все строки из обоих операторов SELECT; повторяющиеся значения
Операторы соединения
UNION возвращает все строки из обоих операторов SELECT; повторяющиеся значения

Операторы соединения
SELECT product_name
FROM purchase
ORDER BY product_name
SELECT product_name
FROM purchase_archive
ORDER BY product_name
SELECT product_name
FROM
Операторы соединения
SELECT product_name
FROM purchase
ORDER BY product_name
SELECT product_name
FROM purchase_archive
ORDER BY product_name
SELECT product_name
FROM

Операторы соединения
SELECT product_name
FROM purchase
UNION ALL
SELECT product_name
FROM purchase_archive
ORDER BY 1
SELECT product_name
FROM purchase
EXCEPT
SELECT
Операторы соединения
SELECT product_name
FROM purchase
UNION ALL
SELECT product_name
FROM purchase_archive
ORDER BY 1
SELECT product_name
FROM purchase
EXCEPT
SELECT

Псевдоним в области FROM
При использовании больших баз со схемами принято использование
Псевдоним в области FROM
При использовании больших баз со схемами принято использование

Практическое задание № 3
1. Напишите запрос, выводящий декартово произведение таблиц product
и
Практическое задание № 3
1. Напишите запрос, выводящий декартово произведение таблиц product
и

Практическое задание № 3 (продолжение)
5. Напишите запрос, который выводит все неповторяющиеся
Практическое задание № 3 (продолжение)
5. Напишите запрос, который выводит все неповторяющиеся

Часть 6. Агрегатные функции. Группирование
данных.
SQL. Базовый курс
Часть 6. Агрегатные функции. Группирование
данных.
SQL. Базовый курс

Математические операторы
Математический оператор – символы, обозначающие операции (+, -,*, /)
Вычисления с
Математические операторы
Математический оператор – символы, обозначающие операции (+, -,*, /)
Вычисления с

Математические операторы
Функции агрегирования (функции над множествами, статистические или базовые) предназначены для
Математические операторы
Функции агрегирования (функции над множествами, статистические или базовые) предназначены для

Математические операторы
3. MIN – возвращает минимальное значение из указанного столбца.
SELECT MIN(product_price)
FROM
Математические операторы
3. MIN – возвращает минимальное значение из указанного столбца.
SELECT MIN(product_price)
FROM

Математические операторы
5. COUNT – подсчитывает записи.
SELECT COUNT(*)
FROM purchase; --число строк с
Математические операторы
5. COUNT – подсчитывает записи.
SELECT COUNT(*)
FROM purchase; --число строк с

GROUP BY
Этот раздел предназначен для объединения результатов запроса в группы и
GROUP BY
Этот раздел предназначен для объединения результатов запроса в группы и

HAVING
HAVING – является подразделом предназначенным для ограничения числа строк в сгруппированной
HAVING
HAVING – является подразделом предназначенным для ограничения числа строк в сгруппированной

HAVING
Т.е., подведя итог выше описанного, можно сузить
назначение подраздела до:
С помощью конструкции
HAVING
Т.е., подведя итог выше описанного, можно сузить
назначение подраздела до:
С помощью конструкции

Практическое задание № 4
1. Напишите запрос, показывающий, какой будет цена продукта
Практическое задание № 4
1. Напишите запрос, показывающий, какой будет цена продукта

Часть 7. Подзапросы
SQL. Базовый курс
Часть 7. Подзапросы
SQL. Базовый курс

Подзапросы
Подзапрос — это обычный запрос SELECT, вложенный в оператор SELECT, UPDATE
Подзапросы
Подзапрос — это обычный запрос SELECT, вложенный в оператор SELECT, UPDATE

Подзапросы
Есть некие ограничения использования подзапросов:
Подзапрос должен выбирать только один столбец (за
Подзапросы
Есть некие ограничения использования подзапросов:
Подзапрос должен выбирать только один столбец (за

Однострочные подзапросы
Однострочный подзапрос – это подзапрос, который возвращает лишь 1 значение.
Используются
Однострочные подзапросы
Однострочный подзапрос – это подзапрос, который возвращает лишь 1 значение.
Используются

Многострочные подзапросы
Многострочный подзапрос – это подзапрос, который возвращает лишь >=1 значение.
Для
Многострочные подзапросы
Многострочный подзапрос – это подзапрос, который возвращает лишь >=1 значение.
Для

EXISTS
EXISTS использует подзапрос в качестве аргумента и
оценивает его как истинный,
EXISTS
EXISTS использует подзапрос в качестве аргумента и
оценивает его как истинный,

EXISTS
SELECT * FROM product
WHERE EXISTS
(SELECT * FROM purchase
WHERE product.product_name =
EXISTS
SELECT * FROM product
WHERE EXISTS
(SELECT * FROM purchase
WHERE product.product_name =

Групповые условия (операторы сравнения).
ALL - сравнение будет производиться со всеми записями,
Групповые условия (операторы сравнения).
ALL - сравнение будет производиться со всеми записями,

Групповые условия (операторы сравнения).
ANY — сравнение вернет true, если условию будет
Групповые условия (операторы сравнения).
ANY — сравнение вернет true, если условию будет

Практическое задание № 5
1. Напишите запрос, который возвращает всех сотрудников, которых
Практическое задание № 5
1. Напишите запрос, который возвращает всех сотрудников, которых

Часть 8. Функции для работы со строками, датами и числами
SQL. Базовый
Часть 8. Функции для работы со строками, датами и числами
SQL. Базовый

Функции для работы с числами
ROUND - округляет числа с любой заданной
Функции для работы с числами
ROUND - округляет числа с любой заданной

Функции для работы с числами
TRUNC - усекает число, понижая его точность.
Функция
Функции для работы с числами
TRUNC - усекает число, понижая его точность.
Функция

Вспомогательные таблицы
Вспомогательные (dummy) таблицы
Для выполнения функций, без привязки к конкретным таблицам
Вспомогательные таблицы
Вспомогательные (dummy) таблицы
Для выполнения функций, без привязки к конкретным таблицам

Функции для работы с датами
GETDATE – возвращает текущую дату.
select getdate();
DATEADD –
Функции для работы с датами
GETDATE – возвращает текущую дату.
select getdate();
DATEADD –

Функции для работы с датами
EOMONTH – возвращает последний день любого месяца,
Функции для работы с датами
EOMONTH – возвращает последний день любого месяца,

Функции для работы с датами
DATEDIFF – возвращает количество единиц, разделяющих две
Функции для работы с датами
DATEDIFF – возвращает количество единиц, разделяющих две

Функции для работы с текстом
UPPER – ставит все символы строки в
Функции для работы с текстом
UPPER – ставит все символы строки в

Функции для работы с текстом
LEN – определяет длину строки.
SELECT product_name, LEN(product_name)
Функции для работы с текстом
LEN – определяет длину строки.
SELECT product_name, LEN(product_name)

Функции для работы с текстом
SUBSTRING – обрезает значение в параметре.
SUBSTRING(исходный_текст, позиция
Функции для работы с текстом
SUBSTRING – обрезает значение в параметре.
SUBSTRING(исходный_текст, позиция
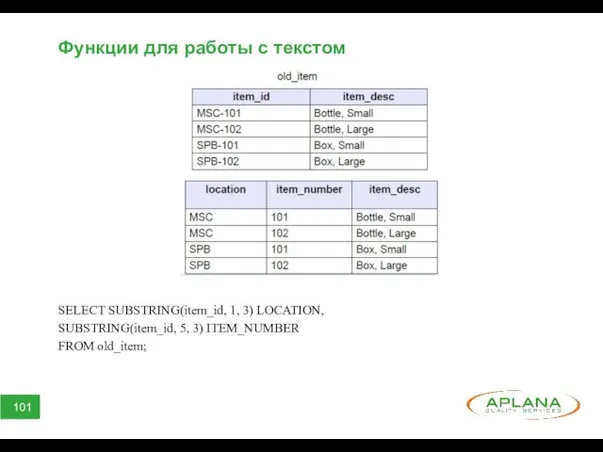
Функции для работы с текстом
SELECT SUBSTRING(item_id, 1, 3) LOCATION,
SUBSTRING(item_id, 5, 3)
Функции для работы с текстом
SELECT SUBSTRING(item_id, 1, 3) LOCATION,
SUBSTRING(item_id, 5, 3)

Функции для работы с текстом
CHARINDEX- находит позицию символа (или символов), разделяющего
Функции для работы с текстом
CHARINDEX- находит позицию символа (или символов), разделяющего
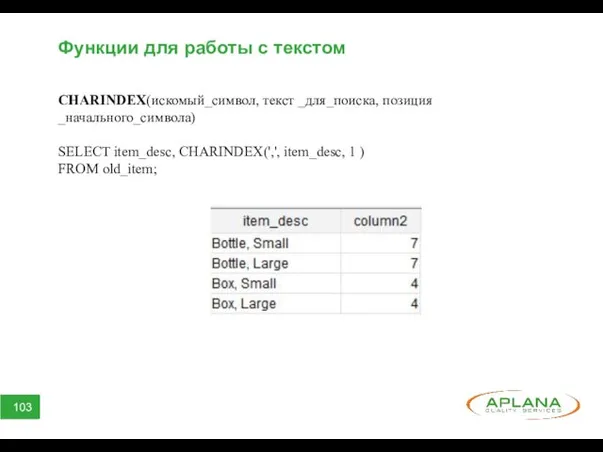
Функции для работы с текстом
CHARINDEX(искомый_символ, текст _для_поиска, позиция
_начального_символа)
SELECT item_desc, CHARINDEX(',', item_desc,
Функции для работы с текстом
CHARINDEX(искомый_символ, текст _для_поиска, позиция
_начального_символа)
SELECT item_desc, CHARINDEX(',', item_desc,

Вложение функций
SELECT item_desc, SUBSTRING(item_desc, 1, CHARINDEX(',', item_desc, 1))
CATEGORY
FROM old_item;
Вложение функций
SELECT item_desc, SUBSTRING(item_desc, 1, CHARINDEX(',', item_desc, 1))
CATEGORY
FROM old_item;

Вложение функций
SELECT item_desc,
SUBSTRING(item_desc, 1, CHARINDEX(',', item_desc, 1)-1) CATEGORY,
SUBSTRING(item_desc, CHARINDEX(',', item_desc, 1)+2,
Вложение функций
SELECT item_desc,
SUBSTRING(item_desc, 1, CHARINDEX(',', item_desc, 1)-1) CATEGORY,
SUBSTRING(item_desc, CHARINDEX(',', item_desc, 1)+2,

Практическое задание № 6
1. Использую функции для работы с датами и
Практическое задание № 6
1. Использую функции для работы с датами и

Полезные ресурсы
http://sqlfiddle.com/ - инструмент, эмулирующий пустую БД: позволяет выполнять значительную часть
Полезные ресурсы
http://sqlfiddle.com/ - инструмент, эмулирующий пустую БД: позволяет выполнять значительную часть
 Суффиксные автоматы 2018
Суффиксные автоматы 2018 Интернет, как информационная система
Интернет, как информационная система Комп’ютерні презентації та публікації
Комп’ютерні презентації та публікації Параллельное программирование. С++. Thread Support Library. Atomic Operations Library
Параллельное программирование. С++. Thread Support Library. Atomic Operations Library Тест з ЗНО
Тест з ЗНО Решение задач общего машиностроения в программном комплексе
Решение задач общего машиностроения в программном комплексе СММП: вбудовані системи
СММП: вбудовані системи Архитектурные особенности проектирования и разработки Веб - приложений (лекция 4)
Архитектурные особенности проектирования и разработки Веб - приложений (лекция 4) Информационные жанры журналистики. Лекция №3. Заметка как жанр журналистики
Информационные жанры журналистики. Лекция №3. Заметка как жанр журналистики Использование ИКТ в образовательном процессе
Использование ИКТ в образовательном процессе Основы поисковой оптимизации (теория и практика)
Основы поисковой оптимизации (теория и практика) Смешанные системы счисления
Смешанные системы счисления Жизненный цикл программы. Программный продукт и его характеристики. Основные этапы решения задач на компьютере
Жизненный цикл программы. Программный продукт и его характеристики. Основные этапы решения задач на компьютере Кибербезопасность
Кибербезопасность Основы программирования: ТЕМА 02. СТРУКТУРА ПРОГРАММЫ В ПАСКАЛЕ. ВВОД И ВЫВОД ДАННЫХ.
Основы программирования: ТЕМА 02. СТРУКТУРА ПРОГРАММЫ В ПАСКАЛЕ. ВВОД И ВЫВОД ДАННЫХ. Базові поняття програмування. Указники і відсилки. Лекція 5
Базові поняття програмування. Указники і відсилки. Лекція 5 Разработка информационно-программного обеспечения управления взаимодействием с клиентами с использованием мобильных устройств
Разработка информационно-программного обеспечения управления взаимодействием с клиентами с использованием мобильных устройств Информационный подход
Информационный подход Архітектура комп’ютера
Архітектура комп’ютера Искусственный интеллект
Искусственный интеллект Journalism
Journalism Компьютерные технологии в обучении: определение, разновидности, этапы
Компьютерные технологии в обучении: определение, разновидности, этапы Основные понятия и объекты PowerPoint
Основные понятия и объекты PowerPoint IT Project. Projects Life Cycles. (Unit 17)
IT Project. Projects Life Cycles. (Unit 17) Сетевой этикет
Сетевой этикет Алгоритмы и способы их описания
Алгоритмы и способы их описания Системы счисления
Системы счисления Правила работы за компьютером
Правила работы за компьютером