- SQL. (Лекция 6)

Содержание
- 2. SQL подразделяется на DDL (язык определения данных) и DML (язык обработки данных). В языке SQL имеются
- 3. numeric exact numeric integer bigint Целые от –2^63 до 2^63-1 int Целые от –2^31 до 2^31-1
- 4. approximate numeric float Числа с плавающей точкой от –1.79Е+308 до 1.79Е+308 real Числа с плавающей точкой
- 5. Неопределенные или пропущенные данные (NULL). Для обозначения неопределенных, пропущенных, или неизвестных значений SQL использует слово NULL.
- 6. Все операторы возвращают состояние NULL, если один из операндов NULL. Для проверки на наличие NULL используются
- 7. Используемые термины и обозначения. Ключевые слова – зарезервированные в SQL слова. Команды или предложения- это инструкции,
- 8. База данных «Колледж»
- 12. Простейшие SELECT- запросы. Оператор SELECT ( выбрать) языка SQL является самым важным и самым часто используемым
- 13. ПРИМЕРЫ: 1) SELECT * from USP WHERE SNUM = 3412; 2)SELECT SNUM,SFAM,SNAME FROM STUDENTS WHERE STIP>0;
- 14. Построение запросов с условием отбора. Наибольший интерес представляют такие запросы, в которых выполняется выборка данных в
- 15. Пример 1 Показать номера студенческих билетов, фамилии и имена тех лиц, чьи имена начинаются с буквы
- 16. Пример 2 Показать предметы, которые изучаются на 1 курсе и на них отводится более 30 часов.
- 17. В записи логических условий могут быть использованы операторы IN, BETWEEN, LIKE, IS NULL. Операторы IN (равен
- 18. Пример 3 Получить сведения о студентах, получивших оценки только 4 и 5. SELECT USP.SNUM, USP.UDATE, USP.MARK,
- 19. Пример 4 Получить сведения о студентах, не получивших оценок 4 и 5. SELECT USP.SNUM, STUDENTS.SFAM, USP.UDATE,
- 20. Оператор BETWEEN используется для проверки условия вхождения значения поля в заданный интервал, т.е. задаются вместо списка
- 21. Оператор LIKE применим только символьным полям типа CHAR или VARCHAR. Этот оператор просматривает строковые значения полей
- 22. Пример 7 Показать списки студентов с отчеством на «Ни*». SELECT STUDENTS.SNUM, STUDENTS.SFAM, STUDENTS.SNAME, STUDENTS.SFATH FROM STUDENTS
- 23. Если внутри образца содержатся знаки _ | % | *|, то применяют escape – символы. Например,
- 24. Пример 8 Составить список изучаемых предметов. SELECT PREDMET.PNUM as код, PREDMET.PNAME as название, PREDMET.HOURS as количество_часов
- 25. Пример. Создать таблицу STUDENTS. CREATE TABLE STUDENTS (SNUM INTEGER, SFAM CHAR (20), SNAME CHAR (15), SFATH
- 26. Для удаления таблицы необходимо: 1) быть ее создателем или иметь на это право; 2) перед удалением
- 27. Основы SQL Использование выражений : унарный оператор « - » (знак минус) меняет знак выражения на
- 28. Пример 9 Увеличить размер стипендии «учащимся без троек»(оператор *) SELECT DISTINCT STUDENTS.SNUM, STUDENTS.SFAM, STUDENTS.STIP*1.25 AS STIP
- 29. Функции преобразования символов в строке: LOWER – перевод в строчные символы(нижний регистр) UPPER – перевод в
- 30. LTRIM ( ]) удаление левых граничных символов RTRIM ( [, ]) удаление правых граничных символов SUBSTR
- 31. ЧИСЛОВЫЕ ФУНКЦИИ: ABS – абсолютное значение FLOOR –урезанное целое CELL-самое малое целое >=заданного ROUND - округленное
- 32. Агрегирование и групповые функции Агрегирующие функции позволяют получать из таблицы сводную (агрегированную) информацию, выполняя операции над
- 33. Для подсчета общего количества строк в таблице следует использовать функцию COUNT . COUNT ( { [
- 34. DDL – язык определения данных. В SQL существует ряд операторов, позволяющих изменять структуру данных . Операторы
- 35. Это операции: 1)создание новой БД; 2)определение новой структуры и создание таблицы; 3) удаление таблицы; 4)изменение структуры
- 36. Основу DDL составляют три команды: 1) CREATE - создать; 2) DROP – удалить; 3) ALTER –
- 37. Создание базы данных. В системе MS SQL эти действия выполняются оператором: CREATE DATABASE ON , ,
- 38. CREATE DATABASE database_name [ ON [ [ ,...n ] ] [ , [ ,...n ] ]
- 39. Создание БД со спецификациями данных и журнала.
- 42. После создания пустой базы можно создавать таблицы. Эти действия относятся к структуре, а не к данным.
- 43. | [ [ FOREIGN KEY ] REFERENCES ref_table [ ( ref_column ) ] [ ON DELETE
- 44. 1)Для разделения элементов команды используются пробелы, пробел не может быть частью имени ( MY_Table). 2)Значение аргумента
- 45. Пример. Создать таблицу STUDENTS. CREATE TABLE STUDENTS (SNUM INTEGER, SFAM CHAR (20), SNAME CHAR (15), SFATH
- 46. Добавление новых полей выполняется командой: ALTER TABLE ADD [( )], … [( )]); Добавляемые поля автоматически
- 47. Пример. Предположим мы решили добавить номер курса и специальность. ALTER TABLE STUDENTS ADD COURS INTEGER, SPEC
- 48. Для удаления таблицы необходимо: 1) быть ее создателем или иметь на это право; 2) перед удалением
- 49. INSERT [ INTO] { table_name WITH ( [ ...n ] ) | view_name | rowset_function_limited }
- 50. Пример Создать для пользователя копию таблицы PREDMET, добавить в нее поля: лабораторные работы, их количество. CREATE
- 51. INSERT INTO PREDMET_NEW SELECT * FROM PREDMET; Новые поля заполнятся значениями по умолчанию или значениями NULL.
- 52. Индексы, ограничения, синонимы. Индексом принято называть упорядоченный список полей таблицы или групп полей в таблице. В
- 53. Когда создаётся индекс, в поле БД запоминается порядок всех значений этого поля в области памяти. При
- 54. Индексы могут состоять из нескольких полей, при этом первое поле считается главным, второе поле упорядоченным внутри
- 55. Пример В таблице STUDENT наиболее часто употребимо поле SFAM, создать индекс по этому полю. CREATE INDEX
- 56. Для удаления используется команда: DROP INDEX ; Например: DROP INDEX SFAMIDX; Удаление индексов не влияет на
- 57. Ограничения данных. Ограничения данных – это часть определений таблицы, описывающих условия ввода данных. В качестве ограничений
- 58. Существуют ограничения двух типов: 1) ограничения поля – применимые только к указанному полю; 2) ограничения таблицы
- 59. CREATE TABLE ( [( )] , [( ] , … , [( )], , );
- 60. Часто описание ограничений используют для ограждения от так называемых NULL значений, для этих целей используют предложения
- 61. Ограничения по уникальности. Уникальные индексы – один из самых простых и наиболее эффективных методов. Однако имеется
- 62. Пример 11.3 Устраним повторяющиеся значения в поле SNUM. CREATE TABLE STUDENTS (SNUM INTEGER NOT NULL UNIQUE,
- 63. Подобное ограничение в поле SFAM запретило бы иметь однофамильцев в таблице STUDENTS! Объявление уникальности возможно и
- 64. Транзакции Транзакция это последовательность операций, объединенных в единый логический рабочий модуль. Механизм транзакций позволяет контролировать выполнение
- 65. Atomicity (атомарность)Логика приложения должна предполагать, что должны быть проделаны либо все изменения данных, входящие в транзакцию
- 66. Запуск транзакции SQL сервер позволяет запустить явную, автоматически совершаемую или неявную транзакцию Explicit (явная) транзакция предваряется
- 67. Завершение транзакции. Для завершения транзакции используется конструкция COMMIT Если все прошло успешно, конструкция COMMIT гарантирует, что
- 68. Синтаксис SAVE TRAN [ SACTION ] { savepoint_name | @savepoint_variable } – объявить savepoint BEGIN TRAN
- 69. Триггеры Триггер - особая разновидность хранимой процедуры, которая выполняется в тех случаях, когда пользователь пытается добавить,
- 70. Синтаксис CREATE TRIGGER trigger_name ON { table | view } [ WITH ENCRYPTION ] { {
- 71. FOR (или AFTER) и INSTEAD OF устанавливают тип триггера. FOR(AFTER) – все операции в триггере выполняются
- 72. insert into… начинается транзакция instead of? yes заполняются таблицы inserted и deleted instead of trigger выполняется
- 73. CREATE TABLE my_table (a int NULL, b int NULL) GO ALTER TRIGGER my_trig ON my_table FOR
- 74. Хранимые процедуры "трехзвенная архитектура" - имеется хранилище данных (1-е звено), имеется сервер приложений (2-е звено), который
- 75. Репликации , дублирование, восстановление
- 76. Репликация - это процесс, посредством которого данные копируются между базами данных, находящимися на том же самом
- 77. Publisher - сервер или база данных, которая посылает данные на другой сервер или в другую базу
- 78. Publisher содержит публикацию/публикации. Публикация - это совокупность одной или более статей, которые посылаются серверу подписчику (subscriber)
- 79. Существуют виды подписки: push и pull subscriptions Push subscription - это подписка, при которой сервер издатель
- 80. Distribution database - это системная база данных, которая хранится на дистрибуторе (distributor) и не содержит никаких
- 81. Топология репликации Microsoft SQL Server поддерживает следующие топологии репликации - Центральный publisher - Центральный subscriber -
- 82. Центральный publisher Это одна из наиболее используемых топологий репликации. В этом сценарии, один сервер исполняет роли
- 83. Центральный subscriber Это обычная топология складирования данных. Несколько серверов или баз данных копируют свои данные на
- 84. Центральный publisher с отдаленным distributor В этой топологии база Distribution постоянно находится на сервере, отличном от
- 85. Центральный distributor В этой топологии, несколько издателей используют только один distributor, который постоянно находится на отличном
- 86. Издающий subscriber Это топология двойственной роли. В ней, два сервера издают те же самые данные. Сервер
- 87. Типы репликации Microsoft SQL Server 7.0/2000 поддерживает следующие виды репликации: - Snapshot - Transactional - Merge
- 88. Snapshot репликация (снимок) Является самой простой. При этом, все копируемые данные (точная копия) будут копироваться из
- 89. Transactional репликация SQL Server фиксирует (делает моментальные снимки) все изменения, которые были сделаны в статье, и
- 90. Transactional репликации лучше использовать, когда копируемые данные часто изменяются или когда размер копируемых данных достаточно велик
- 91. Merge репликация Является наиболее трудным типом репликации. Она предоставляет возможность автономных изменений реплицируемых данных и на
- 92. Merge репликацию лучше использовать, когда Вы хотите обеспечить поддержку автономных изменений реплицируемых данных относительно publisher и
- 93. Агенты Репликации Microsoft SQL Server 7.0/2000 поддерживает следующих агентов репликации: - Snapshot Agent - Log Reader
- 94. Snapshot Agent Агент репликации, который создаёт файлы снимков, хранит снимки на distributor и производит запись информации
- 95. Log Reader Agent Агент репликации, который перемещает транзакции, отмеченные для репликации из transaction log, находящегося на
- 96. Distribution Agent Агент репликации, который перемещает обрабатывающие снимки задания из Distribution database к подписчикам и перемещает
- 97. Merge Agent Агент репликации, который применяет первоначальные, обрабатывающие снимки задания по таблицам базы данных publication на
- 99. Скачать презентацию

SQL подразделяется на DDL (язык определения данных) и DML (язык обработки
SQL подразделяется на DDL (язык определения данных) и DML (язык обработки

numeric
exact numeric
integer
bigint Целые от –2^63 до 2^63-1
int Целые от
numeric
exact numeric
integer
bigint Целые от –2^63 до 2^63-1
int Целые от

approximate numeric
float Числа с плавающей точкой от –1.79Е+308 до 1.79Е+308
real
approximate numeric
float Числа с плавающей точкой от –1.79Е+308 до 1.79Е+308
real

Неопределенные или пропущенные данные (NULL).
Для обозначения неопределенных, пропущенных, или неизвестных значений
Неопределенные или пропущенные данные (NULL).
Для обозначения неопределенных, пропущенных, или неизвестных значений

Все операторы возвращают состояние NULL, если один из операндов NULL.
Для проверки
Все операторы возвращают состояние NULL, если один из операндов NULL.
Для проверки

Используемые термины и обозначения.
Ключевые слова – зарезервированные в SQL слова.
Команды или
Используемые термины и обозначения.
Ключевые слова – зарезервированные в SQL слова.
Команды или
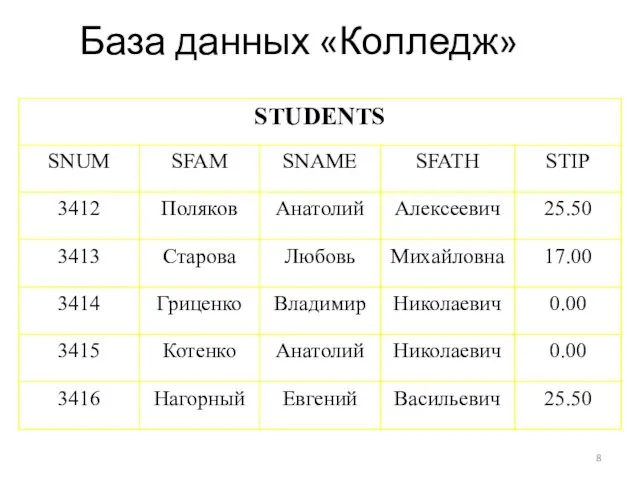
База данных «Колледж»
База данных «Колледж»
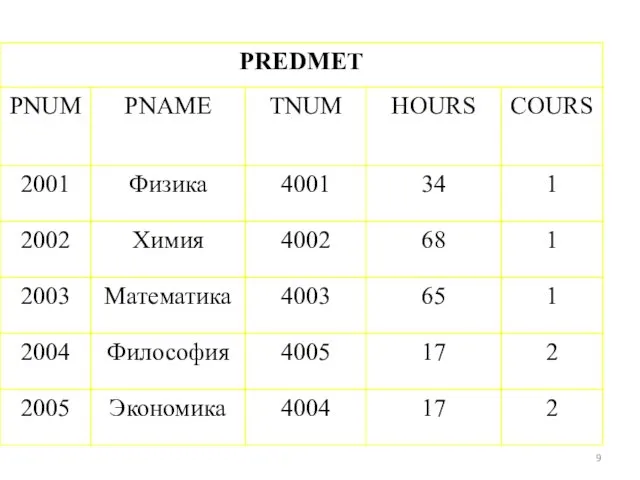
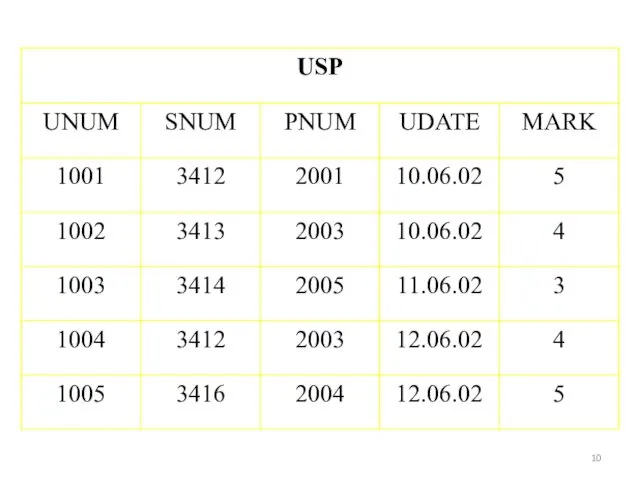
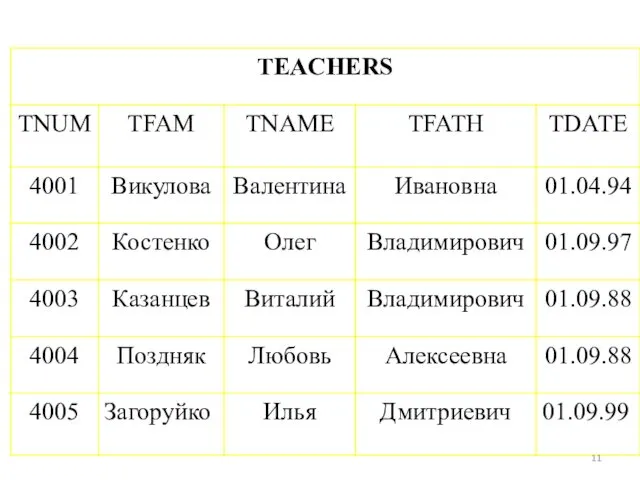

Простейшие SELECT- запросы.
Оператор SELECT ( выбрать) языка SQL является самым важным
Простейшие SELECT- запросы.
Оператор SELECT ( выбрать) языка SQL является самым важным

ПРИМЕРЫ:
1) SELECT * from USP
WHERE SNUM = 3412;
2)SELECT SNUM,SFAM,SNAME
FROM STUDENTS
WHERE STIP>0;
ПРИМЕРЫ:
1) SELECT * from USP
WHERE SNUM = 3412;
2)SELECT SNUM,SFAM,SNAME
FROM STUDENTS
WHERE STIP>0;

Построение запросов с условием отбора.
Наибольший интерес представляют такие запросы, в которых
Построение запросов с условием отбора.
Наибольший интерес представляют такие запросы, в которых

Пример 1
Показать номера студенческих билетов, фамилии и имена тех лиц, чьи
Пример 1
Показать номера студенческих билетов, фамилии и имена тех лиц, чьи

Пример 2
Показать предметы, которые изучаются на 1 курсе и на них
Пример 2
Показать предметы, которые изучаются на 1 курсе и на них

В записи логических условий могут быть использованы операторы IN, BETWEEN, LIKE,
В записи логических условий могут быть использованы операторы IN, BETWEEN, LIKE,
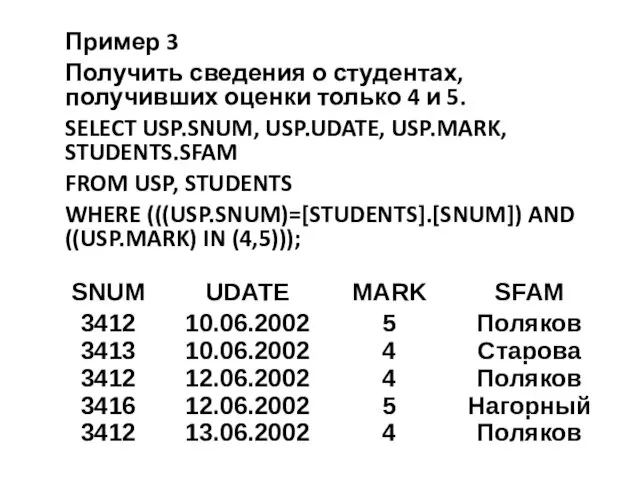
Пример 3
Получить сведения о студентах, получивших оценки только 4 и 5.
SELECT
Пример 3
Получить сведения о студентах, получивших оценки только 4 и 5.
SELECT

Пример 4
Получить сведения о студентах, не получивших оценок 4 и 5.
SELECT
Пример 4
Получить сведения о студентах, не получивших оценок 4 и 5.
SELECT

Оператор BETWEEN используется для проверки условия вхождения значения поля в заданный
Оператор BETWEEN используется для проверки условия вхождения значения поля в заданный

Оператор LIKE применим только символьным полям типа CHAR или VARCHAR. Этот
Оператор LIKE применим только символьным полям типа CHAR или VARCHAR. Этот

Пример 7
Показать списки студентов с отчеством на «Ни*».
SELECT STUDENTS.SNUM, STUDENTS.SFAM, STUDENTS.SNAME,
Пример 7
Показать списки студентов с отчеством на «Ни*».
SELECT STUDENTS.SNUM, STUDENTS.SFAM, STUDENTS.SNAME,

Если внутри образца содержатся знаки _ | % | *|, то
Если внутри образца содержатся знаки _ | % | *|, то

Пример 8
Составить список изучаемых предметов.
SELECT PREDMET.PNUM as код, PREDMET.PNAME as название,
Пример 8
Составить список изучаемых предметов.
SELECT PREDMET.PNUM as код, PREDMET.PNAME as название,

Пример. Создать таблицу STUDENTS.
CREATE TABLE STUDENTS (SNUM INTEGER, SFAM CHAR (20),
Пример. Создать таблицу STUDENTS.
CREATE TABLE STUDENTS (SNUM INTEGER, SFAM CHAR (20),

Для удаления таблицы необходимо:
1) быть ее создателем или иметь на это
Для удаления таблицы необходимо: 1) быть ее создателем или иметь на это

Основы SQL
Использование выражений :
унарный оператор « - » (знак минус)
Основы SQL
Использование выражений :
унарный оператор « - » (знак минус)

Пример 9
Увеличить размер стипендии «учащимся без троек»(оператор *)
SELECT DISTINCT STUDENTS.SNUM, STUDENTS.SFAM,
Пример 9
Увеличить размер стипендии «учащимся без троек»(оператор *)
SELECT DISTINCT STUDENTS.SNUM, STUDENTS.SFAM,

Функции преобразования символов в строке:
LOWER <строка> – перевод в строчные символы(нижний
Функции преобразования символов в строке:
LOWER <строка> – перевод в строчные символы(нижний
![LTRIM ( ]) удаление левых граничных символов RTRIM ( [,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-29.jpg)
LTRIM ( <строка [,<подстрока>]) удаление левых граничных символов
RTRIM ( <строка> [,<подстрока>])
LTRIM ( <строка [,<подстрока>]) удаление левых граничных символов
RTRIM ( <строка> [,<подстрока>])

ЧИСЛОВЫЕ ФУНКЦИИ:
ABS – абсолютное значение
FLOOR –урезанное целое
CELL-самое малое целое >=заданного
ROUND -
ЧИСЛОВЫЕ ФУНКЦИИ:
ABS – абсолютное значение
FLOOR –урезанное целое
CELL-самое малое целое >=заданного
ROUND -

Агрегирование и групповые функции
Агрегирующие функции позволяют получать из таблицы
Агрегирование и групповые функции
Агрегирующие функции позволяют получать из таблицы

Для подсчета общего количества строк в таблице следует использовать функцию COUNT
Для подсчета общего количества строк в таблице следует использовать функцию COUNT

DDL – язык определения данных.
В SQL существует ряд операторов, позволяющих изменять
DDL – язык определения данных.
В SQL существует ряд операторов, позволяющих изменять

Это операции:
1)создание новой БД;
2)определение новой структуры и создание таблицы;
3) удаление таблицы;
4)изменение структуры
Это операции:
1)создание новой БД;
2)определение новой структуры и создание таблицы;
3) удаление таблицы;
4)изменение структуры

Основу DDL составляют три команды:
1) CREATE - создать;
2) DROP – удалить;
3)
Основу DDL составляют три команды:
1) CREATE - создать;
2) DROP – удалить;
3)

Создание базы данных.
В системе MS SQL эти действия выполняются оператором:
CREATE
Создание базы данных.
В системе MS SQL эти действия выполняются оператором:
CREATE
![CREATE DATABASE database_name [ ON [ [ ,...n ] ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-37.jpg)
CREATE DATABASE database_name
[ ON
[ < filespec > [ ,...n
CREATE DATABASE database_name [ ON [ < filespec > [ ,...n

Создание БД со спецификациями данных и журнала.
Создание БД со спецификациями данных и журнала.



После создания пустой базы можно создавать таблицы.
Эти действия относятся к
После создания пустой базы можно создавать таблицы. Эти действия относятся к
![| [ [ FOREIGN KEY ] REFERENCES ref_table [ (](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-42.jpg)
| [ [ FOREIGN KEY ]
REFERENCES ref_table [ ( ref_column
| [ [ FOREIGN KEY ] REFERENCES ref_table [ ( ref_column

1)Для разделения элементов команды используются пробелы, пробел не может быть частью
1)Для разделения элементов команды используются пробелы, пробел не может быть частью

Пример. Создать таблицу STUDENTS.
CREATE TABLE STUDENTS (SNUM INTEGER, SFAM CHAR (20),
Пример. Создать таблицу STUDENTS.
CREATE TABLE STUDENTS (SNUM INTEGER, SFAM CHAR (20),
![Добавление новых полей выполняется командой: ALTER TABLE ADD [( )],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-45.jpg)
Добавление новых полей выполняется командой:
ALTER TABLE ADD
Добавление новых полей выполняется командой:
ALTER TABLE

Пример. Предположим мы решили добавить номер курса и специальность.
ALTER TABLE STUDENTS
Пример. Предположим мы решили добавить номер курса и специальность.
ALTER TABLE STUDENTS

Для удаления таблицы необходимо:
1) быть ее создателем или иметь на это
Для удаления таблицы необходимо: 1) быть ее создателем или иметь на это
![INSERT [ INTO] { table_name WITH ( [ ...n ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-48.jpg)
INSERT [ INTO]
{ table_name WITH ( < table_hint_limited > [
INSERT [ INTO] { table_name WITH ( < table_hint_limited > [

Пример
Создать для пользователя копию таблицы PREDMET,
добавить в нее поля:
Пример Создать для пользователя копию таблицы PREDMET, добавить в нее поля:
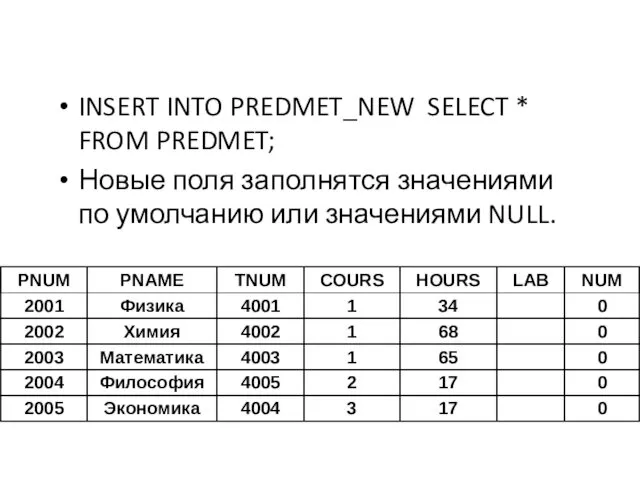
INSERT INTO PREDMET_NEW SELECT * FROM PREDMET;
Новые поля заполнятся значениями
INSERT INTO PREDMET_NEW SELECT * FROM PREDMET;
Новые поля заполнятся значениями

Индексы, ограничения, синонимы.
Индексом принято называть упорядоченный список полей таблицы или групп
Индексы, ограничения, синонимы.
Индексом принято называть упорядоченный список полей таблицы или групп

Когда создаётся индекс, в поле БД запоминается порядок всех значений этого
Когда создаётся индекс, в поле БД запоминается порядок всех значений этого

Индексы могут состоять из нескольких полей, при этом первое поле считается
Индексы могут состоять из нескольких полей, при этом первое поле считается

Пример В таблице STUDENT наиболее часто употребимо поле SFAM, создать индекс
Пример В таблице STUDENT наиболее часто употребимо поле SFAM, создать индекс

Для удаления используется команда:
DROP INDEX ;
Например:
DROP INDEX SFAMIDX;
Удаление
Для удаления используется команда:
DROP INDEX
Например:
DROP INDEX SFAMIDX;
Удаление

Ограничения данных.
Ограничения данных – это часть определений таблицы, описывающих условия ввода
Ограничения данных.
Ограничения данных – это часть определений таблицы, описывающих условия ввода

Существуют ограничения двух типов:
1) ограничения поля – применимые только к указанному
Существуют ограничения двух типов:
1) ограничения поля – применимые только к указанному
![CREATE TABLE ( [( )] , [( ] , … , [( )], , );](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-58.jpg)
CREATE TABLE
(
CREATE TABLE
(

Часто описание ограничений используют для ограждения от так называемых NULL значений,
Часто описание ограничений используют для ограждения от так называемых NULL значений,

Ограничения по уникальности.
Уникальные индексы – один из самых простых и наиболее
Ограничения по уникальности.
Уникальные индексы – один из самых простых и наиболее

Пример 11.3
Устраним повторяющиеся значения в поле SNUM.
CREATE TABLE STUDENTS
(SNUM INTEGER NOT
Пример 11.3
Устраним повторяющиеся значения в поле SNUM.
CREATE TABLE STUDENTS
(SNUM INTEGER NOT

Подобное ограничение в поле SFAM запретило бы иметь однофамильцев в таблице
Подобное ограничение в поле SFAM запретило бы иметь однофамильцев в таблице

Транзакции
Транзакция это последовательность операций, объединенных в единый логический рабочий модуль.
Транзакции
Транзакция это последовательность операций, объединенных в единый логический рабочий модуль.

Atomicity (атомарность)Логика приложения должна предполагать, что должны быть проделаны либо все
Atomicity (атомарность)Логика приложения должна предполагать, что должны быть проделаны либо все

Запуск транзакции
SQL сервер позволяет запустить явную, автоматически совершаемую или неявную
Запуск транзакции
SQL сервер позволяет запустить явную, автоматически совершаемую или неявную

Завершение транзакции.
Для завершения транзакции используется конструкция COMMIT
Если все прошло успешно,
Завершение транзакции.
Для завершения транзакции используется конструкция COMMIT
Если все прошло успешно,
![Синтаксис SAVE TRAN [ SACTION ] { savepoint_name | @savepoint_variable](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1971/slide-67.jpg)
Синтаксис
SAVE TRAN [ SACTION ] { savepoint_name | @savepoint_variable } –
Синтаксис
SAVE TRAN [ SACTION ] { savepoint_name | @savepoint_variable } –

Триггеры
Триггер - особая разновидность хранимой процедуры, которая выполняется в тех
Триггеры
Триггер - особая разновидность хранимой процедуры, которая выполняется в тех

Синтаксис
CREATE TRIGGER trigger_name
ON { table | view }
[ WITH
Синтаксис
CREATE TRIGGER trigger_name ON { table | view } [ WITH

FOR (или AFTER) и INSTEAD OF устанавливают тип триггера. FOR(AFTER) –
FOR (или AFTER) и INSTEAD OF устанавливают тип триггера. FOR(AFTER) –
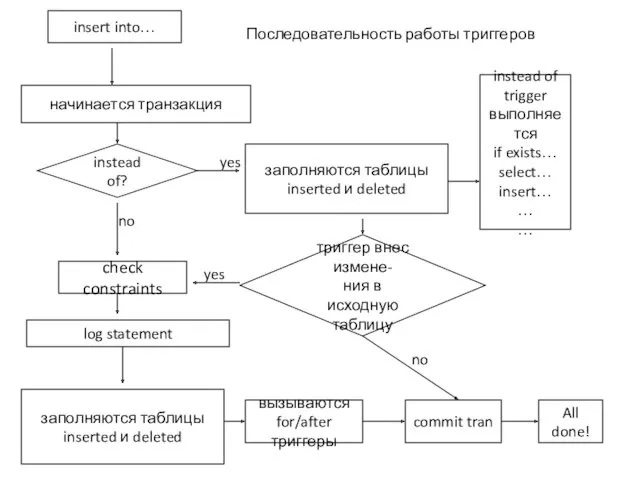
insert into…
начинается транзакция
instead of?
yes
заполняются таблицы
inserted и deleted
instead of
trigger
выполняется
if exists…
select…
insert…
…
…
no
триггер внес измене-
ния
insert into…
начинается транзакция
instead of?
yes
заполняются таблицы
inserted и deleted
instead of
trigger
выполняется
if exists…
select…
insert…
…
…
no
триггер внес измене-
ния

CREATE TABLE my_table (a int NULL, b int NULL)
GO
ALTER
CREATE TABLE my_table (a int NULL, b int NULL)
GO
ALTER

Хранимые процедуры
"трехзвенная архитектура" - имеется хранилище данных (1-е звено), имеется сервер
Хранимые процедуры
"трехзвенная архитектура" - имеется хранилище данных (1-е звено), имеется сервер

Репликации , дублирование, восстановление
Репликации , дублирование, восстановление

Репликация - это процесс, посредством которого данные копируются между базами данных,
Репликация - это процесс, посредством которого данные копируются между базами данных,

Publisher - сервер или база данных, которая посылает данные на другой
Publisher - сервер или база данных, которая посылает данные на другой

Publisher содержит публикацию/публикации. Публикация - это совокупность одной или более статей,
Publisher содержит публикацию/публикации. Публикация - это совокупность одной или более статей,

Существуют виды подписки:
push и pull subscriptions
Push subscription - это
Существуют виды подписки:
push и pull subscriptions
Push subscription - это

Distribution database - это системная база данных, которая хранится на дистрибуторе
Distribution database - это системная база данных, которая хранится на дистрибуторе

Топология репликации
Microsoft SQL Server поддерживает следующие топологии репликации
- Центральный publisher
-
Топология репликации
Microsoft SQL Server поддерживает следующие топологии репликации
- Центральный publisher
-

Центральный publisher
Это одна из наиболее используемых топологий репликации. В этом
Центральный publisher
Это одна из наиболее используемых топологий репликации. В этом

Центральный subscriber
Это обычная топология складирования данных. Несколько серверов или баз
Центральный subscriber
Это обычная топология складирования данных. Несколько серверов или баз

Центральный publisher с отдаленным distributor
В этой топологии база Distribution постоянно
Центральный publisher с отдаленным distributor
В этой топологии база Distribution постоянно

Центральный distributor
В этой топологии, несколько издателей используют только один distributor,
Центральный distributor
В этой топологии, несколько издателей используют только один distributor,

Издающий subscriber
Это топология двойственной роли. В ней, два сервера издают
Издающий subscriber
Это топология двойственной роли. В ней, два сервера издают

Типы репликации
Microsoft SQL Server 7.0/2000 поддерживает следующие виды репликации:
- Snapshot
- Transactional
-
Типы репликации
Microsoft SQL Server 7.0/2000 поддерживает следующие виды репликации:
- Snapshot
- Transactional
-

Snapshot репликация
(снимок)
Является самой простой. При этом, все копируемые данные (точная
Snapshot репликация
(снимок)
Является самой простой. При этом, все копируемые данные (точная

Transactional репликация
SQL Server фиксирует (делает моментальные снимки) все изменения, которые были
Transactional репликация
SQL Server фиксирует (делает моментальные снимки) все изменения, которые были

Transactional репликации лучше использовать, когда копируемые данные часто изменяются или когда
Transactional репликации лучше использовать, когда копируемые данные часто изменяются или когда

Merge репликация
Является наиболее трудным типом репликации. Она предоставляет возможность автономных
Merge репликация
Является наиболее трудным типом репликации. Она предоставляет возможность автономных

Merge репликацию лучше использовать, когда Вы хотите обеспечить поддержку автономных изменений
Merge репликацию лучше использовать, когда Вы хотите обеспечить поддержку автономных изменений

Агенты Репликации
Microsoft SQL Server 7.0/2000 поддерживает следующих агентов репликации:
- Snapshot
Агенты Репликации
Microsoft SQL Server 7.0/2000 поддерживает следующих агентов репликации:
- Snapshot

Snapshot Agent
Агент репликации, который создаёт файлы снимков, хранит снимки на
Snapshot Agent
Агент репликации, который создаёт файлы снимков, хранит снимки на

Log Reader Agent
Агент репликации, который перемещает транзакции, отмеченные для репликации
Log Reader Agent
Агент репликации, который перемещает транзакции, отмеченные для репликации

Distribution Agent
Агент репликации, который перемещает обрабатывающие снимки задания из Distribution
Distribution Agent
Агент репликации, который перемещает обрабатывающие снимки задания из Distribution

Merge Agent
Агент репликации, который применяет первоначальные, обрабатывающие снимки задания по
Merge Agent
Агент репликации, который применяет первоначальные, обрабатывающие снимки задания по
 Алгоритм ветвления. Условный оператор в языке Турбо Паскаль
Алгоритм ветвления. Условный оператор в языке Турбо Паскаль Комп’ютерні технології в музичній сфері
Комп’ютерні технології в музичній сфері Использование блоков Дьенеша в работе с детьми.
Использование блоков Дьенеша в работе с детьми. Структурирование знаний
Структурирование знаний Русско-болгарские словари. Болгарский словарь сообщества LingvoKit
Русско-болгарские словари. Болгарский словарь сообщества LingvoKit Презентация к уроку по теме Чертежник
Презентация к уроку по теме Чертежник Введение в SMM. Урок №1
Введение в SMM. Урок №1 Файловая система
Файловая система Защита ПК от вирусов. Антивирусные средства
Защита ПК от вирусов. Антивирусные средства Вставляння графічних об’єктів у текстовий документ. Вставляння схем/діаграм
Вставляння графічних об’єктів у текстовий документ. Вставляння схем/діаграм Информатика и ИКТ. 9 класс
Информатика и ИКТ. 9 класс Измерение объема информации
Измерение объема информации Заседание комиссии при Правительстве Оренбургской области: использование информационных технологий в деятельности органов власти
Заседание комиссии при Правительстве Оренбургской области: использование информационных технологий в деятельности органов власти Модели жизненного цикла программного продукта. (Лекция 1.2)
Модели жизненного цикла программного продукта. (Лекция 1.2) Защита персональных данных и информационная безопасность в Бельгии
Защита персональных данных и информационная безопасность в Бельгии Подготовка к ОГЭ (информатика)
Подготовка к ОГЭ (информатика) Базы данных, СУБД MS Access
Базы данных, СУБД MS Access DHCP. Доставка почты
DHCP. Доставка почты Информатика. Что такое информатика
Информатика. Что такое информатика Программирование на языке С. Модуль 1. Введение в язык С
Программирование на языке С. Модуль 1. Введение в язык С Язык С. Операции в языке С
Язык С. Операции в языке С Операційні системи. Керування введенням-виведенням
Операційні системи. Керування введенням-виведенням Компьютерные сети. История создания сети интернет
Компьютерные сети. История создания сети интернет Логические основы
Логические основы Кабельные каналы связи
Кабельные каналы связи Моделирование в Excel. Старинная задача о лошади
Моделирование в Excel. Старинная задача о лошади Научно-техническая информация
Научно-техническая информация Язык SQL для работы с базами данных
Язык SQL для работы с базами данных