- Задачи и стандарты анализа данных

Содержание
- 2. Предпосылки к использованию интеллектуального анализа данных Парадокс: Чем больше данных, тем меньше знаний Данные имеют неограниченный
- 3. Пирамида знаний
- 4. Применение интеллектуального анализа данных Реклама и продвижение товара Какова эффективность рекламы? Перекрестные продажи Какие продукты покупатель
- 5. Развитие методологий анализа данных
- 6. Методология KDD Несмотря на разнообразие бизнес-задач почти все они могут решаться по единой методике. Эта методика,
- 7. Этапы процесса анализа данных по методологии KDD Интерпретация Очистка Трансформация Выборка данных Data mining
- 8. Методология KDD. Выборка данных. Первым шагом в анализе является получение исходной выборки. На основе отобранных данных
- 9. Методология KDD. Очистка данных. Реальные данные для анализа редко бывают хорошего качества. Необходимость в предварительной обработке
- 10. Методология KDD. Трансформация данных. Этот шаг необходим для тех методов, при использовании которых исходные данные должны
- 11. Методология KDD. Data Mining. Термин Data Mining дословно переводится как «добыча данных» или «раскопка данных» и
- 12. Методология KDD. Интерпертация данных. В случае, когда извлеченные зависимости и шаблоны непрозрачны для пользователя, должны существовать
- 13. Стандарт CRISP-DM Хотя корни сбора данных могут быть прослежены до конца 1980-х, в течение большинства 1990-х,
- 14. Этапы процесса анализа данных по стандарту CRISP-DM
- 15. Процессы понимания бизнеса
- 16. Процессы понимания данных
- 17. Процессы подготовки данных
- 18. Процессы моделирования
- 19. Процессы оценки
- 20. Процессы развёртывания
- 21. Методология SEMMA Методология SEMMA (аббревиатура, образованная от слов Sample, Explore, Modify, Model, Assess) заключается в поэтапном
- 22. Этапы процесса анализа данных по методологии SEMMA
- 23. Использование различных методологий в анализе данных http://www.kdnuggets.com/2014/10/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html
- 24. Типы задач анализа данных
- 25. Подготовка данных по CRISP-DM
- 26. Основные понятия Переменная - свойство или характеристика, общая для всех изучаемых объектов, проявление которой может изменяться
- 27. Шкалы измерений
- 28. Примеры шкал измерений Дихотомическая переменная Пол (‘Мужчины’, ‘Женщины’) Номинальная переменная Город (‘Москва’, ‘Санкт-Петербург’, ‘Казань’) Порядковая переменная
- 29. Типовой вид исходных данных ПАРАМЕТРЫ (АТТРИБУТЫ, СВОЙСТВА, ХАРАКТЕРИСТИКИ…) ОБЪЕКТЫ
- 30. Представление изображений в формате RGB
- 31. Понятие очистки данных Очистка данных – процедура корректировки данных, которые в каком-либо смысле не удовлетворяют определённым
- 32. Качество данных
- 33. Понятие обогащения данных Обогащение данных – процесс насыщения данных новой информацией, которая позволяет сделать их более
- 34. Восстановление пропущенных значений
- 35. Метод исключения некомплектных объектов При отсутствии у ряда объектов значений каких-либо переменных некомплектные объекты удаляются из
- 36. Методы с заполнением
- 37. Понятие трансформации данных Трансформация данных – комплекс методов и алгоритмов, направленных на оптимизацию представления и форматов
- 38. Методы трансформации данных
- 39. Квантование Квантование – процедура преобразования данных, состоящая из 2-х шагов. На первом шаге диапазон значений переменной
- 40. Квантование
- 41. Равномерное квантование Равномерное (однородное) квантование – преобразование, при котором диапазон значений переменной разбивается на интервалы одинаковой
- 42. Неравномерное квантование Неравномерное (однородное) квантование – преобразование, при котором диапазон значений переменной разбивается на интервалы различной
- 43. Слияние
- 44. Внутреннее соединение Исходная таблица Связываемая таблица
- 45. Внешнее соединение Исходная таблица Связываемая таблица Связываемая таблица Исходная таблица
- 46. Объединение Исходная таблица Связываемая таблица
- 47. Полное внешнее соединение Исходная таблица Связываемая таблица
- 49. Скачать презентацию
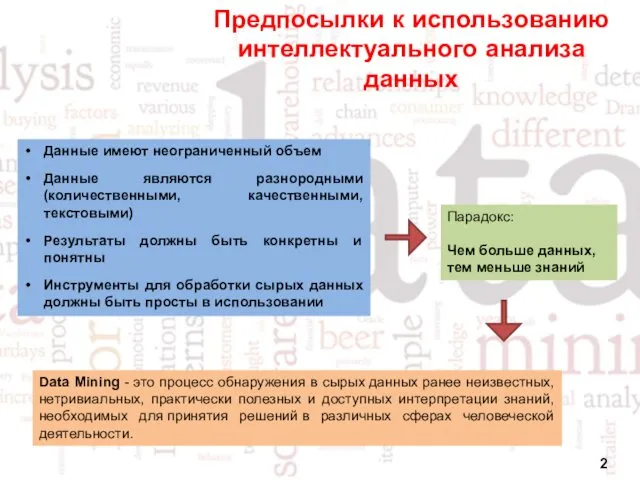
Предпосылки к использованию интеллектуального анализа данных
Парадокс:
Чем больше данных, тем меньше
Предпосылки к использованию интеллектуального анализа данных
Парадокс:
Чем больше данных, тем меньше
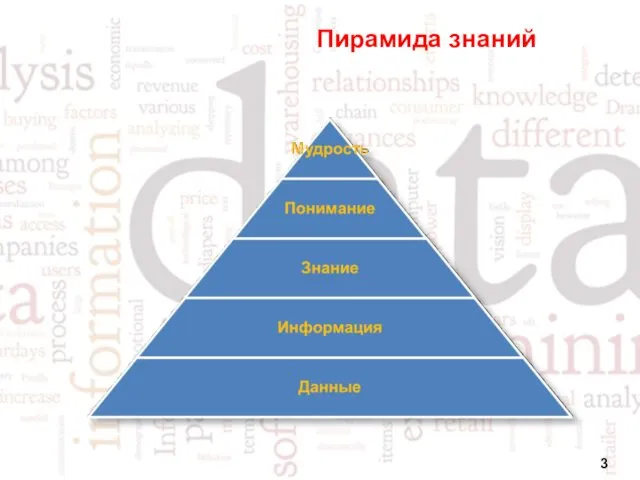
Пирамида знаний
Пирамида знаний

Применение интеллектуального анализа данных
Реклама и продвижение товара
Какова эффективность рекламы?
Перекрестные продажи
Какие продукты
Применение интеллектуального анализа данных
Реклама и продвижение товара
Какова эффективность рекламы?
Перекрестные продажи
Какие продукты
Развитие методологий анализа данных
Развитие методологий анализа данных

Методология KDD
Несмотря на разнообразие бизнес-задач почти все они могут решаться
Методология KDD
Несмотря на разнообразие бизнес-задач почти все они могут решаться
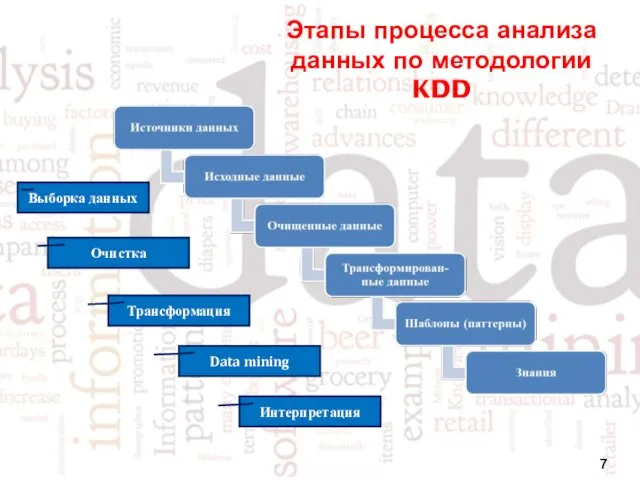
Этапы процесса анализа данных по методологии KDD
Интерпретация
Очистка
Трансформация
Выборка данных
Data mining
Этапы процесса анализа данных по методологии KDD
Интерпретация
Очистка
Трансформация
Выборка данных
Data mining

Методология KDD. Выборка данных.
Первым шагом в анализе является получение исходной
Методология KDD. Выборка данных.
Первым шагом в анализе является получение исходной

Методология KDD. Очистка данных.
Реальные данные для анализа редко бывают хорошего
Методология KDD. Очистка данных.
Реальные данные для анализа редко бывают хорошего

Методология KDD. Трансформация данных.
Этот шаг необходим для тех методов, при
Методология KDD. Трансформация данных.
Этот шаг необходим для тех методов, при

Методология KDD. Data Mining.
Термин Data Mining дословно переводится как «добыча
Методология KDD. Data Mining.
Термин Data Mining дословно переводится как «добыча

Методология KDD. Интерпертация данных.
В случае, когда извлеченные зависимости и шаблоны
Методология KDD. Интерпертация данных.
В случае, когда извлеченные зависимости и шаблоны

Стандарт CRISP-DM
Хотя корни сбора данных могут быть прослежены до конца 1980-х,
Стандарт CRISP-DM
Хотя корни сбора данных могут быть прослежены до конца 1980-х,
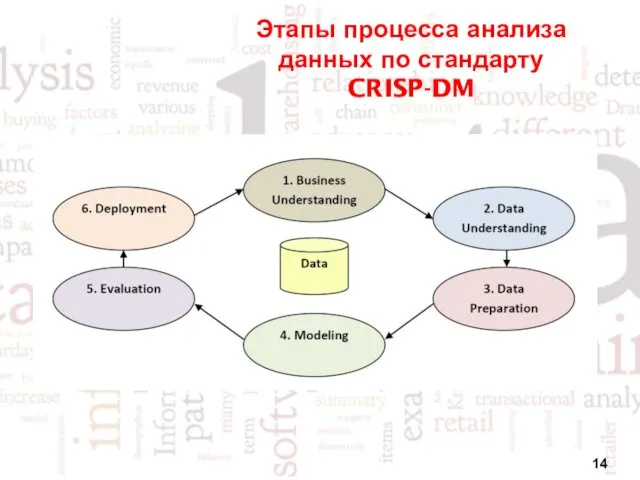
Этапы процесса анализа данных по стандарту CRISP-DM
Этапы процесса анализа данных по стандарту CRISP-DM

Процессы понимания бизнеса
Процессы понимания бизнеса

Процессы понимания данных
Процессы понимания данных

Процессы подготовки данных
Процессы подготовки данных

Процессы моделирования
Процессы моделирования

Процессы оценки
Процессы оценки

Процессы развёртывания
Процессы развёртывания

Методология SEMMA
Методология SEMMA (аббревиатура, образованная от слов Sample, Explore, Modify, Model,
Методология SEMMA
Методология SEMMA (аббревиатура, образованная от слов Sample, Explore, Modify, Model,
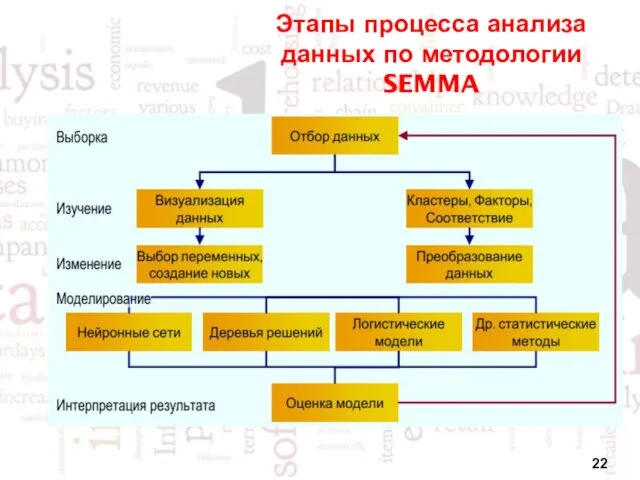
Этапы процесса анализа данных по методологии SEMMA
Этапы процесса анализа данных по методологии SEMMA
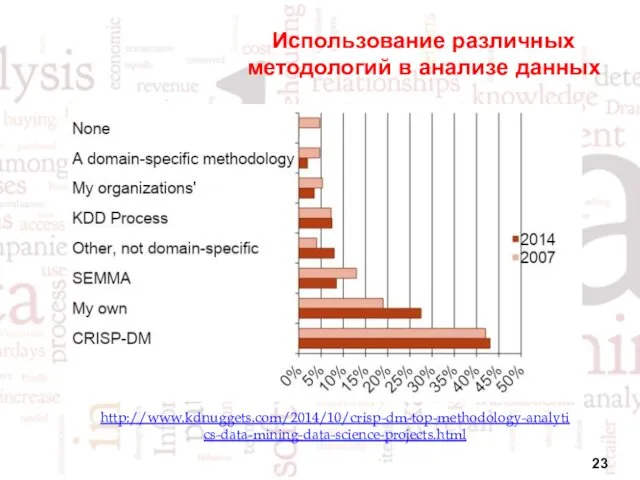
Использование различных методологий в анализе данных
http://www.kdnuggets.com/2014/10/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html
Использование различных методологий в анализе данных
http://www.kdnuggets.com/2014/10/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html
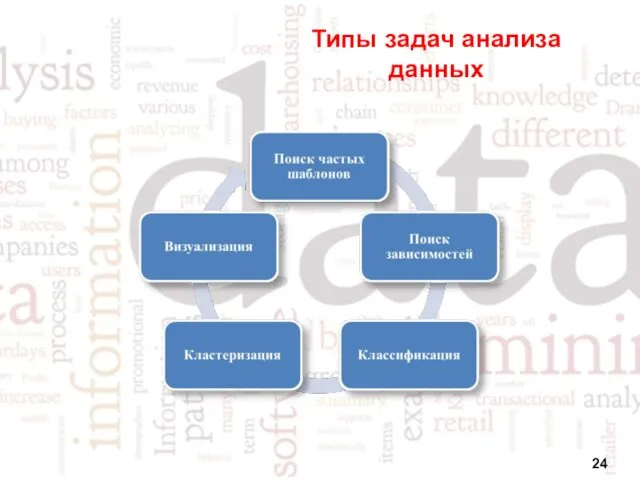
Типы задач анализа данных
Типы задач анализа данных
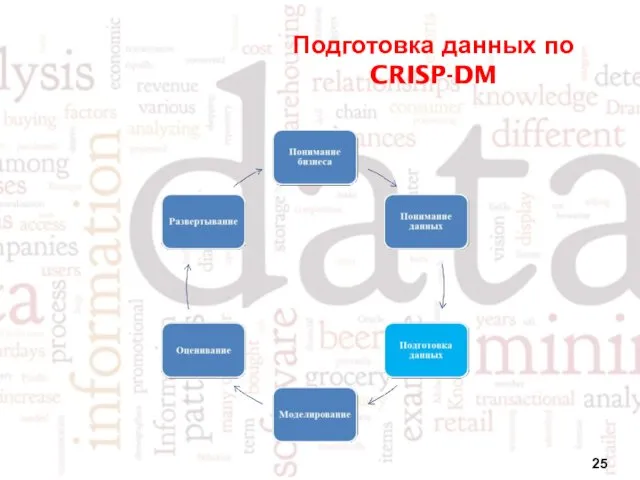
Подготовка данных по CRISP-DM
Подготовка данных по CRISP-DM

Основные понятия
Переменная - свойство или характеристика, общая для всех изучаемых объектов,
Основные понятия
Переменная - свойство или характеристика, общая для всех изучаемых объектов,
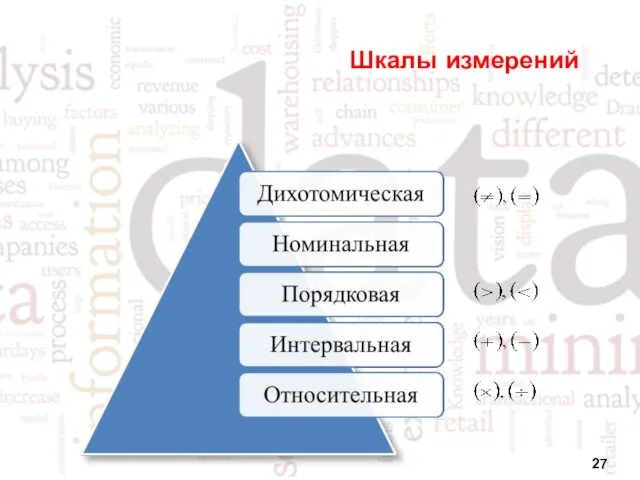
Шкалы измерений
Шкалы измерений

Примеры шкал измерений
Дихотомическая переменная
Пол (‘Мужчины’, ‘Женщины’)
Номинальная переменная
Город (‘Москва’, ‘Санкт-Петербург’, ‘Казань’)
Порядковая переменная
Доход
Примеры шкал измерений
Дихотомическая переменная
Пол (‘Мужчины’, ‘Женщины’)
Номинальная переменная
Город (‘Москва’, ‘Санкт-Петербург’, ‘Казань’)
Порядковая переменная
Доход
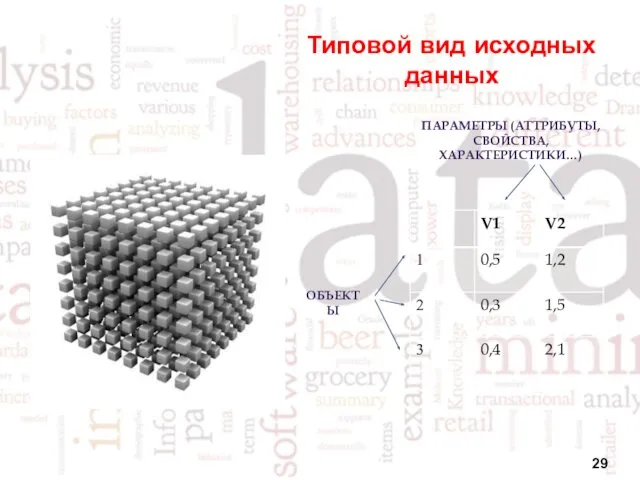
Типовой вид исходных данных
ПАРАМЕТРЫ (АТТРИБУТЫ,
СВОЙСТВА, ХАРАКТЕРИСТИКИ…)
ОБЪЕКТЫ
Типовой вид исходных данных
ПАРАМЕТРЫ (АТТРИБУТЫ,
СВОЙСТВА, ХАРАКТЕРИСТИКИ…)
ОБЪЕКТЫ
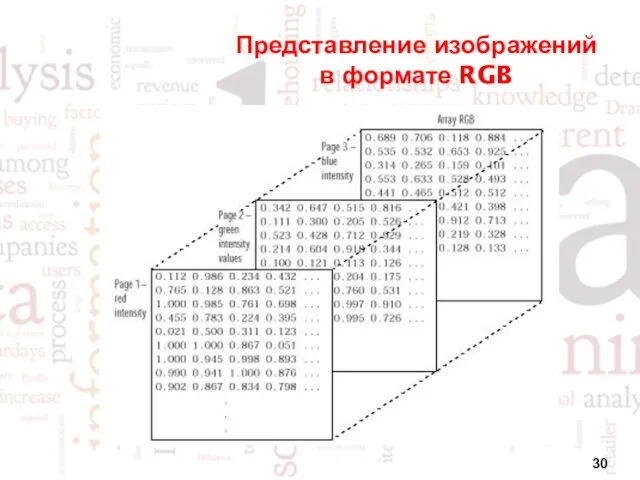
Представление изображений в формате RGB
Представление изображений в формате RGB

Понятие очистки данных
Очистка данных – процедура корректировки данных, которые в каком-либо
Понятие очистки данных
Очистка данных – процедура корректировки данных, которые в каком-либо

Качество данных
Качество данных

Понятие обогащения данных
Обогащение данных – процесс насыщения данных новой информацией, которая
Понятие обогащения данных
Обогащение данных – процесс насыщения данных новой информацией, которая

Восстановление пропущенных значений
Восстановление пропущенных значений

Метод исключения некомплектных объектов
При отсутствии у ряда объектов значений каких-либо переменных
Метод исключения некомплектных объектов
При отсутствии у ряда объектов значений каких-либо переменных

Методы с заполнением
Методы с заполнением

Понятие трансформации данных
Трансформация данных – комплекс методов и алгоритмов, направленных на
Понятие трансформации данных
Трансформация данных – комплекс методов и алгоритмов, направленных на

Методы трансформации данных
Методы трансформации данных

Квантование
Квантование – процедура преобразования данных, состоящая из 2-х шагов. На первом
Квантование
Квантование – процедура преобразования данных, состоящая из 2-х шагов. На первом

Квантование
Квантование

Равномерное квантование
Равномерное (однородное) квантование – преобразование, при котором диапазон значений переменной
Равномерное квантование
Равномерное (однородное) квантование – преобразование, при котором диапазон значений переменной

Неравномерное квантование
Неравномерное (однородное) квантование – преобразование, при котором диапазон значений переменной
Неравномерное квантование
Неравномерное (однородное) квантование – преобразование, при котором диапазон значений переменной

Слияние
Слияние

Внутреннее соединение
Исходная таблица
Связываемая таблица
Внутреннее соединение
Исходная таблица
Связываемая таблица
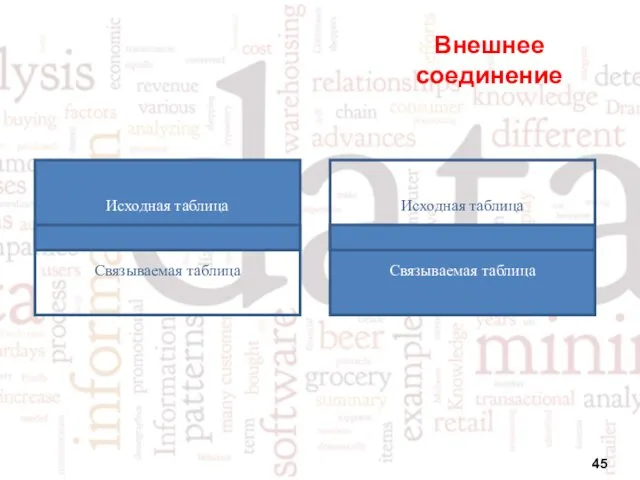
Внешнее соединение
Исходная таблица
Связываемая таблица
Связываемая таблица
Исходная таблица
Внешнее соединение
Исходная таблица
Связываемая таблица
Связываемая таблица
Исходная таблица

Объединение
Исходная таблица
Связываемая таблица
Объединение
Исходная таблица
Связываемая таблица
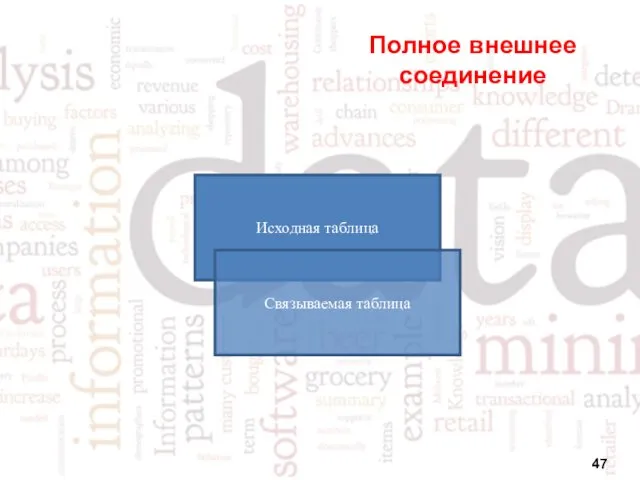
Полное внешнее соединение
Исходная таблица
Связываемая таблица
Полное внешнее соединение
Исходная таблица
Связываемая таблица
 Технологии программирования. Строки
Технологии программирования. Строки Разработка информационной системы инвентаризации компьютеров в сети для предприятия
Разработка информационной системы инвентаризации компьютеров в сети для предприятия Параметры страницы. Форматирование текста
Параметры страницы. Форматирование текста 3D печать. Будущее и перспективы. (Часть 1)
3D печать. Будущее и перспективы. (Часть 1) Вероятностный подход к определению количества информации.
Вероятностный подход к определению количества информации. Пример кейса-референса
Пример кейса-референса Проектирование баз данных
Проектирование баз данных Память и виды памяти
Память и виды памяти Практическая работа Устройства компьютера. Адрес клетки
Практическая работа Устройства компьютера. Адрес клетки Powerpoint бағдарламасымен жұмыс жасау
Powerpoint бағдарламасымен жұмыс жасау Безопасность в сети Интернет
Безопасность в сети Интернет Локальные сети. Параметры сетей и их стандарты
Локальные сети. Параметры сетей и их стандарты Нестандартные периферийные устройства ПК
Нестандартные периферийные устройства ПК Информационная безопасность
Информационная безопасность fbea8-fe014e85
fbea8-fe014e85 Электронные российские учебники
Электронные российские учебники Таблицы в MsWord
Таблицы в MsWord Creating Functions and Debugging Subprograms
Creating Functions and Debugging Subprograms Моделирование. Модели и моделирование
Моделирование. Модели и моделирование Что такое CSS
Что такое CSS Сведения о программе 1С: Предприятие
Сведения о программе 1С: Предприятие Программирование на Python. Урок 11. Взаимодействие объектов
Программирование на Python. Урок 11. Взаимодействие объектов Информатика 10-11 класс тема Логика
Информатика 10-11 класс тема Логика Массивы
Массивы Язык С++. Введение в С++
Язык С++. Введение в С++ Как составить техническое задание?
Как составить техническое задание? Дополнительная литература для лекций курса - Основы тестирования ПО
Дополнительная литература для лекций курса - Основы тестирования ПО Открытый урок
Открытый урок