- Структуры данных: динамический массив, стек, очередь, дек, бинарная куча

Содержание
- 2. Содержание Структура данных «Динамический массив» Амортизированное время работы Метод предоплаты Метод потенциалов Однонаправленные, двунаправленные списки Поиск,
- 3. Основные понятия Структура данных (англ. data structure) — программная единица, позволяющая хранить и обрабатывать множество однотипных
- 4. Основные понятия Абстрактный тип данных (АТД) — это множество объектов, определяемое списком операций, применимых к этим
- 5. Основные понятия При этом доступ к отдельным элементам массива осуществляется с помощью индексации, то есть через
- 6. Динамический массив Массив — набор однотипных переменных с доступом по индексу. Динамический массив — массив (буффер),
- 7. Динамический массив 1 3 2 4 1 3 2 5 4 6 7 1 3 2
- 8. Динамический массив — Добавления элемента в конец — Доступ к элементу по индексу — Изменение элемента
- 9. Динамический массив … Пример реализации
- 10. Динамический массив O(1) — в лучшем случае O(n) — в худшем случае А сколько в среднем
- 11. Амортизационный анализ Метод подсчета времени, которое необходимо для последовательности операций над структурой данных. Проводится анализ средней
- 12. Амортизационный анализ Например, чтобы показать, что хотя существуют «дорогие» операции, то после усреднения по всем возможным
- 13. Амортизационный анализ S = ∑ti / n t1, t2, …, tn — время выполнения операций 1,
- 14. Амортизационный анализ Использование X времени равносильно использованию X монет (плата за операцию) У каждой операции своя
- 15. Амортизационный анализ Ф — потенциал текущего состояния структура данных Ф0, Ф1, … Фi i-a операция стоит
- 16. Амортизационный анализ — Метод предоплаты — Метод потенциалов Время работы динамического массива
- 17. Связный список Динамическая структура данных, имеющая помимо своих собственных элементов, ссылки на следующий и/или предыдущий элемент
- 18. Связный список Односвязный список 1 2 3 4
- 19. Связный список Двусвязный список 1 2 3 4
- 20. Связный список — Поиск элемента — Вставка элемента — Удаление элемента — Объединение списков — Получение
- 21. Связный список … Пример реализации
- 22. Связный список — Быстрая вставка элемента в любое место, при наличии указателя — Быстрое удаление элемента,
- 23. Стек Абстрактный тип данных (или структура данных), работающий по принципу LIFO — Last In, First Out
- 24. Стек — Вставка (Push) — Извлечение (Pop) Операции
- 25. Динамический массив 1 3 2 4 1 3 2 5 4 6 Push(5), Push(6) Pop() 1
- 26. Стек На (динамическом) массиве 1 3 2 4 1 3 2 5 4 6 Push(5), Push(6)
- 27. Стек На списке Push(3) Pop() 2 1 3 2 1 2 1
- 28. Стек … Пример реализации
- 29. Стек Push — O(1) Pop O(1) — в лучшем случае O(n) — в худшем случае А
- 30. Очередь Абстрактный тип данных (или структура данных), работающий по принципу FIFO — First In, First Out
- 31. Очередь — Вставка (EnQueue) — Извлечение (DeQueue) Операции
- 32. Очередь Очередь EnQueue(3) DeQueue() 1 2 1 2 3 2 3
- 33. Очередь На (динамическом) массиве 1 3 2 4 1 3 2 5 4 6 3 2
- 34. Дэк Абстрактный тип данных (или структура данных), работающий по принципу FIFO и LIFO Можно добавлять и
- 35. Дэк — Вставка в начало (PushFront) — Вставка в конец (PushBack) — Извлечение из начала (PopFront)
- 36. Дэк Дэк 1 2 3 4 1 2 3
- 37. Дэк … Пример реализации
- 38. Двоичная куча Двоичный подвешенный [связный ациклический граф — дерево], для которого выполнены условия: 1 — Значение
- 39. Двоичная куча Двоичная куча 5 8 6 11 10 9 14 14 13 Глубина O(log(n))
- 40. Двоичная куча Удобно хранить в массиве a[0] — корень а дети a[i] - a[2i + 2]
- 41. Двоичная куча После изменение элемента в куче, она может перестать удовлетворять условиям кучи. Для поддержания свойств,
- 42. Двоичная куча Изменили элемент Если его значение стало больше, то используем siftDown Если элемент меньше детей
- 43. Двоичная куча Изменили элемент Если его значение стало меньше, то используем siftUp Если элемент больше родителя
- 44. Двоичная куча Элемент в корне :) ≻ Получаем значение корня Восстанавливаем кучу Берём последний элемент Ставим
- 45. Двоичная куча Вставляем элемент в конец Восстанавливаем кучу siftUp(elementIndex) Время работы O(log n) Добавление элемента
- 46. Двоичная куча Вход — неупорядоченный массив данных Первый элемент кладём в корень Второй и последующие —
- 47. Двоичная куча Вход — неупорядоченный массив данных Представим что наш массив — это дерево Запустим siftDown
- 48. Двоичная куча Доказательство времени работы … Построение кучи [2]
- 49. Очередь с приоритетом Абстрактный тип данных (или структура данных), с операциями: 1 — Добавить элемент с
- 50. Очередь с приоритетом 1 — Добавить элемент с приоритетом O(log n) 2 — Достать элемент с
- 52. Скачать презентацию

Содержание
Структура данных «Динамический массив»
Амортизированное время работы
Метод предоплаты
Метод потенциалов
Однонаправленные, двунаправленные списки
Поиск, добавление
Содержание
Структура данных «Динамический массив»
Амортизированное время работы
Метод предоплаты
Метод потенциалов
Однонаправленные, двунаправленные списки
Поиск, добавление

Основные понятия
Структура данных (англ. data structure) — программная единица, позволяющая хранить
Основные понятия
Структура данных (англ. data structure) — программная единица, позволяющая хранить

Основные понятия
Абстрактный тип данных (АТД) — это множество объектов, определяемое списком
Основные понятия
Абстрактный тип данных (АТД) — это множество объектов, определяемое списком

Основные понятия
При этом доступ к отдельным элементам массива осуществляется с помощью
Основные понятия
При этом доступ к отдельным элементам массива осуществляется с помощью

Динамический массив
Массив — набор однотипных переменных с доступом по индексу.
Динамический массив
Динамический массив
Массив — набор однотипных переменных с доступом по индексу.
Динамический массив

Динамический массив
1
3
2
4
1
3
2
5
4
6
7
1
3
2
5
4
6
+ 5, + 6
+ 7
6
6
12
Динамический массив
1
3
2
4
1
3
2
5
4
6
7
1
3
2
5
4
6
+ 5, + 6
+ 7
6
6
12

Динамический массив
— Добавления элемента в конец
— Доступ к элементу по индексу
—
Динамический массив
— Добавления элемента в конец
— Доступ к элементу по индексу
—

Динамический массив
…
Пример реализации
Динамический массив
…
Пример реализации

Динамический массив
O(1) — в лучшем случае
O(n) — в худшем случае
А сколько в
Динамический массив
O(1) — в лучшем случае
O(n) — в худшем случае
А сколько в

Амортизационный анализ
Метод подсчета времени, которое необходимо для последовательности операций над структурой
Амортизационный анализ
Метод подсчета времени, которое необходимо для последовательности операций над структурой

Амортизационный анализ
Например, чтобы показать, что хотя существуют «дорогие» операции, то после
Амортизационный анализ
Например, чтобы показать, что хотя существуют «дорогие» операции, то после

Амортизационный анализ
S = ∑ti / n
t1, t2, …, tn — время выполнения
Амортизационный анализ
S = ∑ti / n
t1, t2, …, tn — время выполнения

Амортизационный анализ
Использование X времени равносильно использованию X монет
(плата за операцию)
У каждой
Амортизационный анализ
Использование X времени равносильно использованию X монет
(плата за операцию)
У каждой

Амортизационный анализ
Ф — потенциал текущего состояния структура данных
Ф0, Ф1, … Фi
i-a
Амортизационный анализ
Ф — потенциал текущего состояния структура данных
Ф0, Ф1, … Фi
i-a

Амортизационный анализ
— Метод предоплаты
— Метод потенциалов
Время работы динамического массива
Амортизационный анализ
— Метод предоплаты
— Метод потенциалов
Время работы динамического массива

Связный список
Динамическая структура данных, имеющая помимо своих собственных элементов, ссылки на
Связный список
Динамическая структура данных, имеющая помимо своих собственных элементов, ссылки на
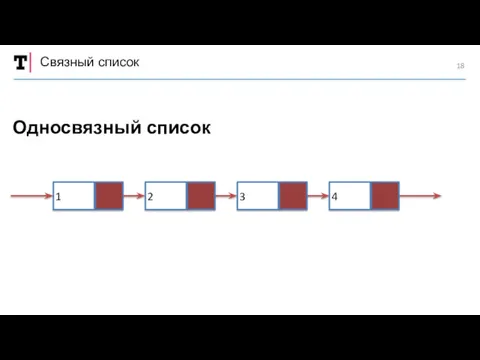
Связный список
Односвязный список
1
2
3
4
Связный список
Односвязный список
1
2
3
4
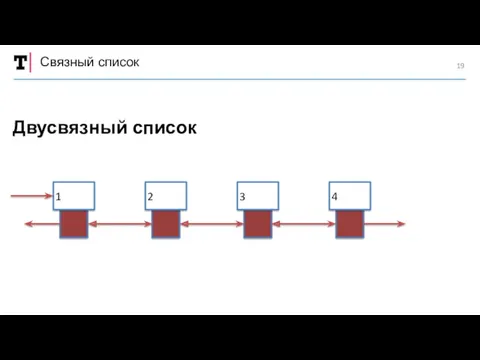
Связный список
Двусвязный список
1
2
3
4
Связный список
Двусвязный список
1
2
3
4

Связный список
— Поиск элемента
— Вставка элемента
— Удаление элемента
— Объединение списков
— Получение размера
Операции
Связный список
— Поиск элемента
— Вставка элемента
— Удаление элемента
— Объединение списков
— Получение размера
Операции
Связный список
…
Пример реализации
Связный список
…
Пример реализации

Связный список
— Быстрая вставка элемента в любое место, при наличии указателя
— Быстрое
Связный список
— Быстрая вставка элемента в любое место, при наличии указателя
— Быстрое

Стек
Абстрактный тип данных (или структура данных), работающий по принципу LIFO —
Стек
Абстрактный тип данных (или структура данных), работающий по принципу LIFO —

Стек
— Вставка (Push)
— Извлечение (Pop)
Операции
Стек
— Вставка (Push)
— Извлечение (Pop)
Операции

Динамический массив
1
3
2
4
1
3
2
5
4
6
Push(5), Push(6)
Pop()
1
3
2
5
4
Динамический массив
1
3
2
4
1
3
2
5
4
6
Push(5), Push(6)
Pop()
1
3
2
5
4

Стек
На (динамическом) массиве
1
3
2
4
1
3
2
5
4
6
Push(5), Push(6)
Pop()
1
3
2
5
4
6
Стек
На (динамическом) массиве
1
3
2
4
1
3
2
5
4
6
Push(5), Push(6)
Pop()
1
3
2
5
4
6
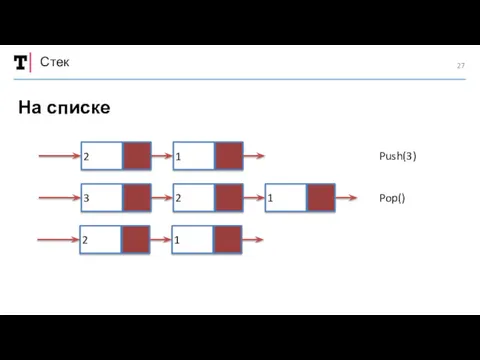
Стек
На списке
Push(3)
Pop()
2
1
3
2
1
2
1
Стек
На списке
Push(3)
Pop()
2
1
3
2
1
2
1

Стек
…
Пример реализации
Стек
…
Пример реализации

Стек
Push — O(1)
Pop
O(1) — в лучшем случае
O(n) — в худшем случае
А
Стек
Push — O(1)
Pop
O(1) — в лучшем случае
O(n) — в худшем случае
А

Очередь
Абстрактный тип данных (или структура данных), работающий по принципу FIFO —
Очередь
Абстрактный тип данных (или структура данных), работающий по принципу FIFO —

Очередь
— Вставка (EnQueue)
— Извлечение (DeQueue)
Операции
Очередь
— Вставка (EnQueue)
— Извлечение (DeQueue)
Операции
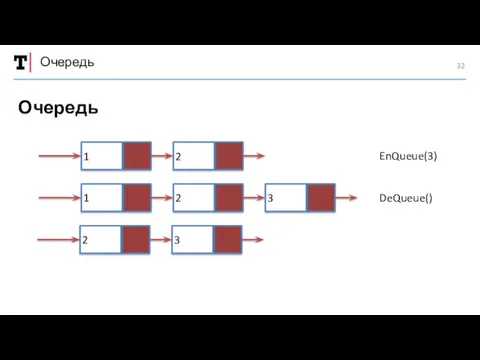
Очередь
Очередь
EnQueue(3)
DeQueue()
1
2
1
2
3
2
3
Очередь
Очередь
EnQueue(3)
DeQueue()
1
2
1
2
3
2
3

Очередь
На (динамическом) массиве
1
3
2
4
1
3
2
5
4
6
3
2
5
4
6
Head
Tail
EnQueue(5)
EnQueue(6)
DeQueue()
Очередь
На (динамическом) массиве
1
3
2
4
1
3
2
5
4
6
3
2
5
4
6
Head
Tail
EnQueue(5)
EnQueue(6)
DeQueue()

Дэк
Абстрактный тип данных (или структура данных), работающий по принципу FIFO и
Дэк
Абстрактный тип данных (или структура данных), работающий по принципу FIFO и

Дэк
— Вставка в начало (PushFront)
— Вставка в конец (PushBack)
— Извлечение из
Дэк
— Вставка в начало (PushFront)
— Вставка в конец (PushBack)
— Извлечение из
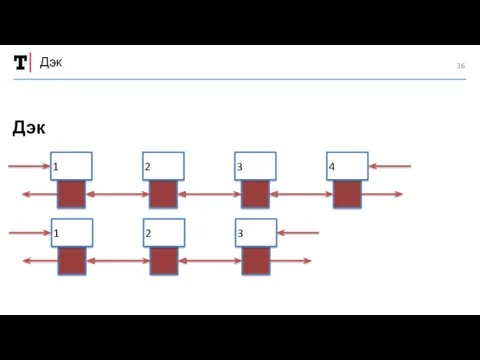
Дэк
Дэк
1
2
3
4
1
2
3
Дэк
Дэк
1
2
3
4
1
2
3

Дэк
…
Пример реализации
Дэк
…
Пример реализации
![Двоичная куча Двоичный подвешенный [связный ациклический граф — дерево], для](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/151959/slide-37.jpg)
Двоичная куча
Двоичный подвешенный [связный ациклический граф — дерево],
для которого выполнены условия:
1
Двоичная куча
Двоичный подвешенный [связный ациклический граф — дерево],
для которого выполнены условия:
1
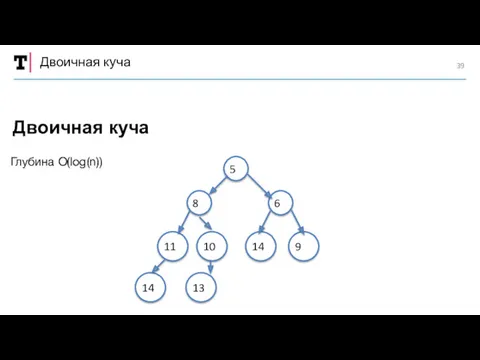
Двоичная куча
Двоичная куча
5
8
6
11
10
9
14
14
13
Глубина O(log(n))
Двоичная куча
Двоичная куча
5
8
6
11
10
9
14
14
13
Глубина O(log(n))
![Двоичная куча Удобно хранить в массиве a[0] — корень а](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/151959/slide-39.jpg)
Двоичная куча
Удобно хранить в массиве
a[0] — корень
а дети a[i] - a[2i
Двоичная куча
Удобно хранить в массиве
a[0] — корень
а дети a[i] - a[2i

Двоичная куча
После изменение элемента в куче, она может перестать удовлетворять условиям
Двоичная куча
После изменение элемента в куче, она может перестать удовлетворять условиям

Двоичная куча
Изменили элемент
Если его значение стало больше, то используем siftDown
Если элемент
Двоичная куча
Изменили элемент
Если его значение стало больше, то используем siftDown
Если элемент

Двоичная куча
Изменили элемент
Если его значение стало меньше, то используем siftUp
Если элемент
Двоичная куча
Изменили элемент
Если его значение стало меньше, то используем siftUp
Если элемент

Двоичная куча
Элемент в корне :)
≻ Получаем значение корня
Восстанавливаем кучу
Берём последний элемент
Ставим
Двоичная куча
Элемент в корне :)
≻ Получаем значение корня
Восстанавливаем кучу
Берём последний элемент
Ставим

Двоичная куча
Вставляем элемент в конец
Восстанавливаем кучу
siftUp(elementIndex)
Время работы O(log n)
Добавление элемента
Двоичная куча
Вставляем элемент в конец
Восстанавливаем кучу
siftUp(elementIndex)
Время работы O(log n)
Добавление элемента

Двоичная куча
Вход — неупорядоченный массив данных
Первый элемент кладём в корень
Второй и
Двоичная куча
Вход — неупорядоченный массив данных
Первый элемент кладём в корень
Второй и

Двоичная куча
Вход — неупорядоченный массив данных
Представим что наш массив — это
Двоичная куча
Вход — неупорядоченный массив данных
Представим что наш массив — это
![Двоичная куча Доказательство времени работы … Построение кучи [2]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/151959/slide-47.jpg)
Двоичная куча
Доказательство времени работы
…
Построение кучи [2]
Двоичная куча
Доказательство времени работы
…
Построение кучи [2]

Очередь с приоритетом
Абстрактный тип данных (или структура данных),
с операциями:
1 — Добавить элемент
Очередь с приоритетом
Абстрактный тип данных (или структура данных),
с операциями:
1 — Добавить элемент

Очередь с приоритетом
1 — Добавить элемент с приоритетом
O(log n)
2 — Достать элемент с
Очередь с приоритетом
1 — Добавить элемент с приоритетом
O(log n)
2 — Достать элемент с
 Робототехника
Робототехника Анализ данных в реляционных БД на примере СУБД MS Access. Создание запросов, изменяющих таблицы. Создание отчетов
Анализ данных в реляционных БД на примере СУБД MS Access. Создание запросов, изменяющих таблицы. Создание отчетов Новые информационные технологии. (Лекция 1а)
Новые информационные технологии. (Лекция 1а) Системы счисления. Представление информации в компьютере
Системы счисления. Представление информации в компьютере Ethernet желілік технологиясы
Ethernet желілік технологиясы Биологические модели
Биологические модели Компьютерные сети
Компьютерные сети Чат-бот Даша
Чат-бот Даша Сетевые информационные технологии
Сетевые информационные технологии Определение количества информации
Определение количества информации История развития вычислительной техники
История развития вычислительной техники 3D моделирование
3D моделирование Текстові редактори
Текстові редактори Social nets are rolling back to connect people along with developing new marketing tools for brands
Social nets are rolling back to connect people along with developing new marketing tools for brands Продвинутый javascript. Лучшие практики и шаблоны проектирования
Продвинутый javascript. Лучшие практики и шаблоны проектирования Связывание таблиц базы данных
Связывание таблиц базы данных Как пройти анкетирование в рамках НОКУООД ОО (пошаговая инструкция)
Как пройти анкетирование в рамках НОКУООД ОО (пошаговая инструкция) Принцип построения логической пирамиды при создании деловых документов. (Тема 9)
Принцип построения логической пирамиды при создании деловых документов. (Тема 9) Intranet технологии. Электронный бизнес и коммерция
Intranet технологии. Электронный бизнес и коммерция Алгоритмы. Свойства алгоритмов. Исполнители
Алгоритмы. Свойства алгоритмов. Исполнители Телекоммуникац технологии основная
Телекоммуникац технологии основная Игра Какуро, 1 класс
Игра Какуро, 1 класс Основные понятия компьютерной графики
Основные понятия компьютерной графики Презентация по информатике В мире кодов 5 класс
Презентация по информатике В мире кодов 5 класс Особливості механізму перевизначення операторів (тема 13)
Особливості механізму перевизначення операторів (тема 13) Использование интерактивных методов обучения на уроках математики
Использование интерактивных методов обучения на уроках математики Тема 15. Инерциальные навигационные системы. Занятие 3. Инерциальная курсовертикаль ИКВ-1
Тема 15. Инерциальные навигационные системы. Занятие 3. Инерциальная курсовертикаль ИКВ-1 Розробка автоматизованої комп’ютерної системи обліку ресурсів і випуску продукції
Розробка автоматизованої комп’ютерної системи обліку ресурсів і випуску продукції