- Технологии аналитики и визуализации больших данных (лекция № 7)

Содержание
- 2. Лекция №7 Технологии аналитики и визуализации больших данных
- 3. Технологии анализа данных: понятие аналитики данных, интеллектуальный анализ данных, математические методы анализа данных. Аналитические базы данных.
- 4. Часть 1. Аналитические базы данных. Организация хранилищ данных
- 5. Классический конвейер обработки больших данных Классически поток обработки больших данных состоит из следующих стадий: Сбор и
- 6. Источники данных Данные в поток обработки попадают из различных источников. Настроенный источник данных также называют подключением
- 7. Стадия сбора/извлечения данных Для переноса данных из подключения используют инструменты миграции данных. Они позволяют осуществлять перенос
- 8. Стадия сбора/извлечения данных На стадии извлечения и сбора данных ставится задача загрузки данных из нескольких внешних
- 9. Стадия предобработки данных Стадия предобработки данных решает задачу преобразования полученных данных в необходимую форму. Среди направлений
- 10. Очистка данных Очистка данных — этап удаления нерелевантных значений показателей или записей данных с нетипичными значениями.
- 11. Стадия загрузки данных в хранилище Процесс загрузки заключается в переносе данных из промежуточных таблиц в структуры
- 12. Проблемы при загрузке данных в хранилище Одной из основных проблем данного шага является то, что далеко
- 13. Понятие хранилища данных Хранилище данных — это цифровая система хранения, которая выполняет объединение и согласование больших
- 14. Свойства хранилища данных Хранилище данных должно обладать следующими свойствами: Предметная ориентированность — создается с ориентацией на
- 15. Основные задачи консолидации данных Задача консолидации данных и заключается в соблюдении ранее упомянутых свойств. В процессе
- 16. Задачи хранилища данных Хранилище данных решает ряд важных задач: предоставление оперативного доступа и хранение информации (структурированной
- 17. ETL (Extract-Transform-Load) Процесс ETL представляет собой комплекс операций, реализующих процесс переноса первичных данных из различных источников
- 18. ETL (Extract-Transform-Load) Любая ETL-система должна обеспечивать выполнение трех основных этапов процесса переноса данных: Извлечение данных —
- 19. ELT (Extract-Load-Transform) ELT — это процесс переноса данных из разнородных источников в хранилище данных с целью
- 20. Основные различия ETL и ELT Помимо порядка проведения операций, между процессами ETL и ELT встречаются следующие
- 21. Оптимизация данных Оптимизация данных — этап преобразования данных в формат, удобный для анализа. В оптимизации данных
- 22. Витрины данных Витрина данных — это часть хранилища данных, секционированная для отделов или направлений бизнеса (например,
- 23. Типы витрин данных Существует три основных типа витрин данных. Разница между ними определяется их отношением к
- 24. Стадия формирования витрин данных После загрузки данных в хранилище формируем витрины данных по следующему алгоритму: Создаем
- 25. Стадия формирования витрин данных Представления данных (VIEW) — специальные конструкции в реляционных СУБД, позволяющие хранить предметно-ориентированные
- 26. Стадия формирования аналитических отчетностей Цель ведения аналитической отчетности — обнаружить проблему или возможность и объяснить, как
- 27. Часть 2. Технологии анализа данных. Аналитика данных
- 28. Понятие аналитики данных Аналитика данных — область занимающаяся преобразованием «сырых» данных в практические выводы. Использует определенный
- 29. Интеллектуальный анализ данных
- 30. Применение
- 32. Задачи бизнес-аналитики Изучение и формализация предметной области клиента Оптимизация бизнес-процессов Разработка характеристик IT продукта Внедрение новых
- 33. Задачи машинного обучения Задачи машинного обучения заключаются в получении прогноза или вывода, восстанавливая закономерность исходных данных.
- 35. Обучение с учителем Алгоритмы машинного обучения, настраивающие свои параметры по методу минимизации ошибок между предсказаниями на
- 36. Обучение без учителя Обучение без учителя – процесс при котором система учится находить закономерности в данных
- 37. Задачи глубокого обучения Подкласс задач машинного обучения с учителем при решении которых используются нейронные сети. Примеры
- 38. Задачи глубокого обучения
- 39. Часть 3. OLAP системы
- 40. OLAP системы OLAP (Online Analytical Processing) – это система аналитической обработки данных. Она предназначена для подготовки
- 41. Скорость доступа к данным в OLAP системах Аналитические базы данных — специализированные колоночные РСУБД, оптимизированные для
- 42. Колоночные СУБД Колоночные СУБД — системы управления базами данных в которых данные хранятся и индексируются столбцами.
- 43. MPP-системы MPP – архитектура параллельных вычислений, при которой память физически разделена. Система строится из отдельных узлов,
- 44. Аппаратная масштабируемость
- 45. Принципы работы с MPP Используются, если: объемы данных слишком большие для классической СУБД когда есть готовое
- 46. OLAP против OLTP OLTP — системы хранения оперативных данных с высокой скоростью записи данных и фиксации
- 47. Часть 4. Способы визуализации данных
- 48. Разведочный анализ данных (EDA) Разведочный анализ данных — анализ основных свойств данных, нахождение в них общих
- 49. График разброса График разброса — это средство для показа взаимоотношений между двумя переменными. Строит визуализацию точек-строк
- 50. График линий График линий отображает динамику развития процесса во времени или измерении. Основная цель — отследить
- 51. Столбчатая диаграмма
- 52. Карты Карты помогают отследить распределение спроса на реальных географических данных. Визуализация позволяет сконцентрироваться на популярных точках
- 53. OLAP куб OLAP куб — предназначен для визуализации многомерных массивов данных.
- 54. Построение динамических отчетов Упрощение Сравнение Сопровождение Взгляд иначе Вопрос “почему?” Скептицизм Отклик
- 55. Отчеты в аналитике Отчеты используются для работы с определенными наборами данных, например, создания ежедневных отчетов о
- 56. Дашборды Дашборд — это интерактивная аналитическая панель, графический интерфейс. Смысл в том, что на одном экране
- 58. Скачать презентацию

Лекция №7
Технологии аналитики и визуализации больших данных
Лекция №7
Технологии аналитики и визуализации больших данных

Технологии анализа данных: понятие аналитики данных, интеллектуальный анализ данных, математические методы
Технологии анализа данных: понятие аналитики данных, интеллектуальный анализ данных, математические методы

Часть 1. Аналитические базы данных. Организация хранилищ данных
Часть 1. Аналитические базы данных. Организация хранилищ данных
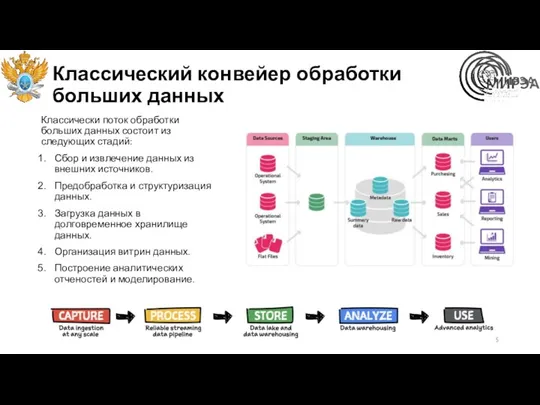
Классический конвейер обработки больших данных
Классически поток обработки больших данных состоит из
Классический конвейер обработки больших данных
Классически поток обработки больших данных состоит из

Источники данных
Данные в поток обработки попадают из различных источников. Настроенный источник
Источники данных
Данные в поток обработки попадают из различных источников. Настроенный источник
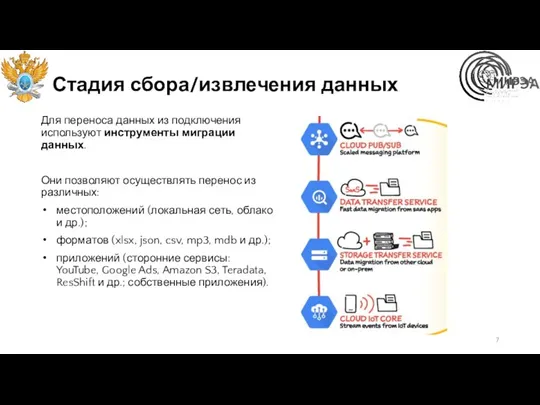
Стадия сбора/извлечения данных
Для переноса данных из подключения используют инструменты миграции данных.
Они
Стадия сбора/извлечения данных
Для переноса данных из подключения используют инструменты миграции данных.
Они
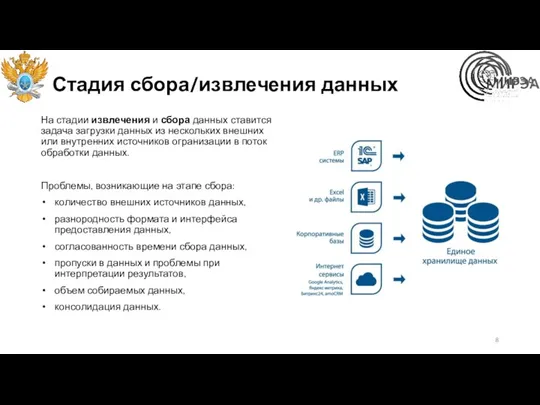
Стадия сбора/извлечения данных
На стадии извлечения и сбора данных ставится задача загрузки
Стадия сбора/извлечения данных
На стадии извлечения и сбора данных ставится задача загрузки
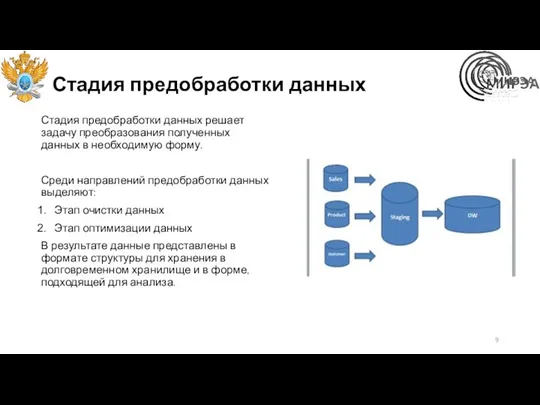
Стадия предобработки данных
Стадия предобработки данных решает задачу преобразования полученных данных в
Стадия предобработки данных
Стадия предобработки данных решает задачу преобразования полученных данных в

Очистка данных
Очистка данных — этап удаления нерелевантных значений показателей или записей
Очистка данных
Очистка данных — этап удаления нерелевантных значений показателей или записей
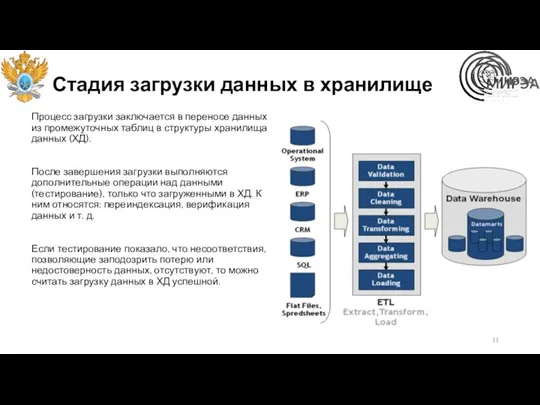
Стадия загрузки данных в хранилище
Процесс загрузки заключается в переносе данных из
Стадия загрузки данных в хранилище
Процесс загрузки заключается в переносе данных из

Проблемы при загрузке данных в хранилище
Одной из основных проблем данного шага
Проблемы при загрузке данных в хранилище
Одной из основных проблем данного шага
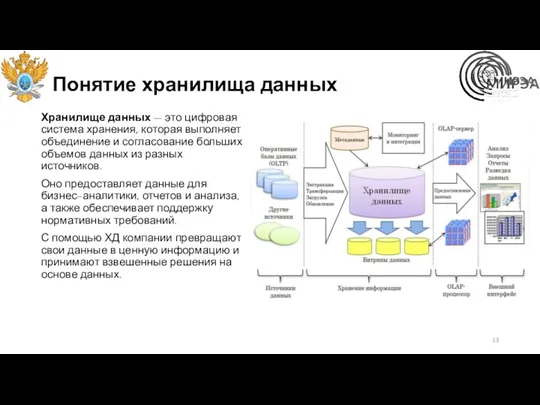
Понятие хранилища данных
Хранилище данных — это цифровая система хранения, которая выполняет
Понятие хранилища данных
Хранилище данных — это цифровая система хранения, которая выполняет

Свойства хранилища данных
Хранилище данных должно обладать следующими свойствами:
Предметная ориентированность — создается
Свойства хранилища данных
Хранилище данных должно обладать следующими свойствами:
Предметная ориентированность — создается

Основные задачи консолидации данных
Задача консолидации данных и заключается в соблюдении ранее
Основные задачи консолидации данных
Задача консолидации данных и заключается в соблюдении ранее

Задачи хранилища данных
Хранилище данных решает ряд важных задач:
предоставление оперативного доступа и
Задачи хранилища данных
Хранилище данных решает ряд важных задач:
предоставление оперативного доступа и
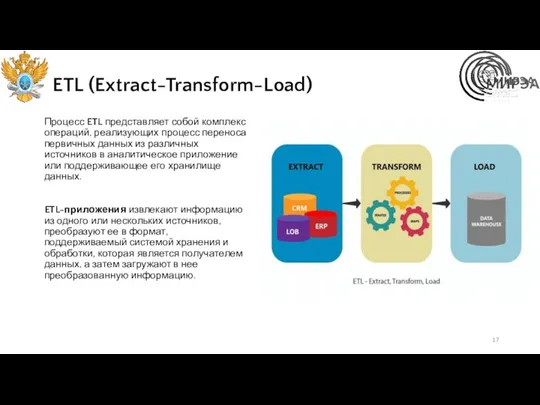
ETL (Extract-Transform-Load)
Процесс ETL представляет собой комплекс операций, реализующих процесс переноса первичных
ETL (Extract-Transform-Load)
Процесс ETL представляет собой комплекс операций, реализующих процесс переноса первичных

ETL (Extract-Transform-Load)
Любая ETL-система должна обеспечивать выполнение трех основных этапов процесса переноса
ETL (Extract-Transform-Load)
Любая ETL-система должна обеспечивать выполнение трех основных этапов процесса переноса

ELT (Extract-Load-Transform)
ELT — это процесс переноса данных из разнородных источников
ELT (Extract-Load-Transform)
ELT — это процесс переноса данных из разнородных источников
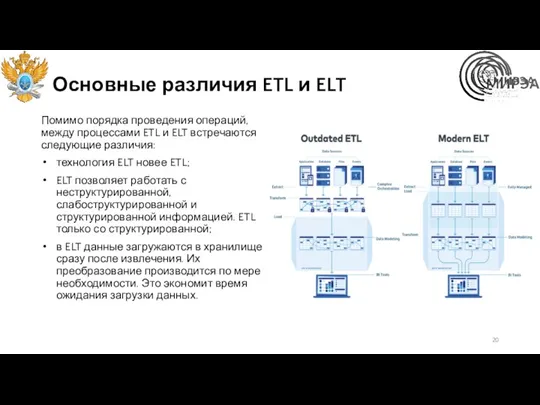
Основные различия ETL и ELT
Помимо порядка проведения операций, между процессами ETL
Основные различия ETL и ELT
Помимо порядка проведения операций, между процессами ETL

Оптимизация данных
Оптимизация данных — этап преобразования данных в формат, удобный для
Оптимизация данных
Оптимизация данных — этап преобразования данных в формат, удобный для

Витрины данных
Витрина данных — это часть хранилища данных, секционированная для отделов
Витрины данных
Витрина данных — это часть хранилища данных, секционированная для отделов

Типы витрин данных
Существует три основных типа витрин данных. Разница между ними
Типы витрин данных
Существует три основных типа витрин данных. Разница между ними

Стадия формирования витрин данных
После загрузки данных в хранилище формируем витрины данных
Стадия формирования витрин данных
После загрузки данных в хранилище формируем витрины данных
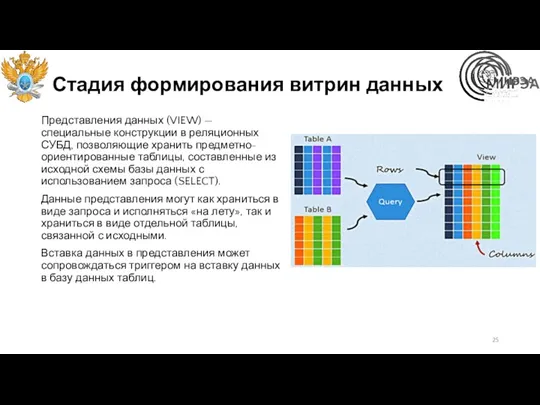
Стадия формирования витрин данных
Представления данных (VIEW) — специальные конструкции в реляционных
Стадия формирования витрин данных
Представления данных (VIEW) — специальные конструкции в реляционных
Стадия формирования аналитических отчетностей
Цель ведения аналитической отчетности — обнаружить проблему или
Стадия формирования аналитических отчетностей
Цель ведения аналитической отчетности — обнаружить проблему или

Часть 2. Технологии анализа данных. Аналитика данных
Часть 2. Технологии анализа данных. Аналитика данных
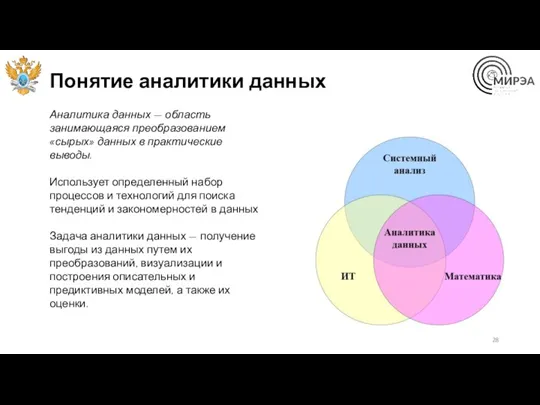
Понятие аналитики данных
Аналитика данных — область занимающаяся преобразованием «сырых» данных в
Понятие аналитики данных
Аналитика данных — область занимающаяся преобразованием «сырых» данных в
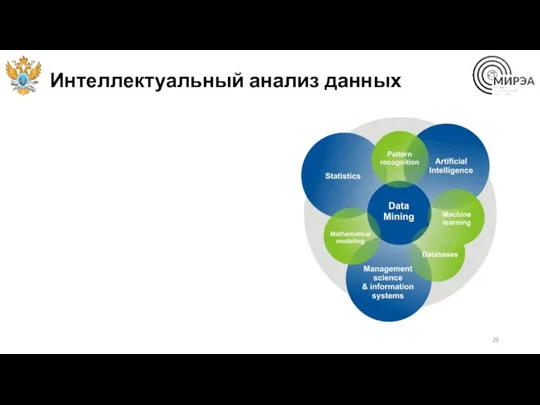
Интеллектуальный анализ данных
Интеллектуальный анализ данных
Применение
Применение
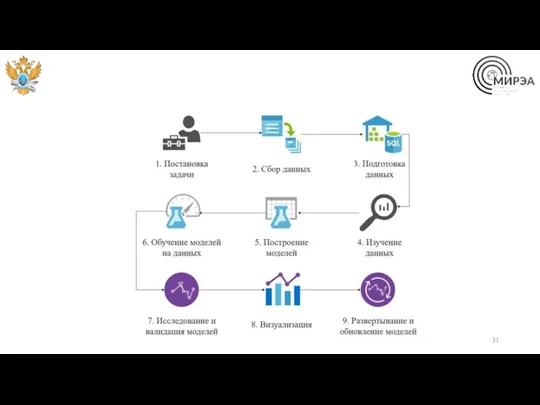
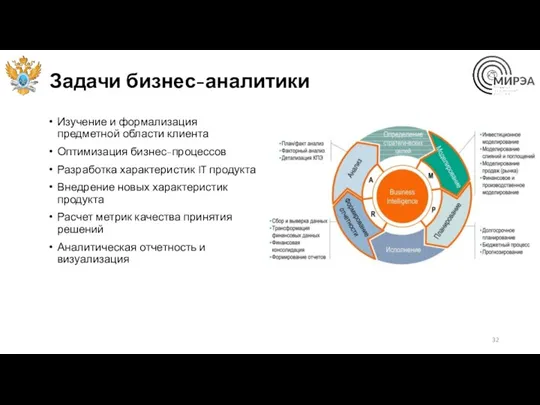
Задачи бизнес-аналитики
Изучение и формализация предметной области клиента
Оптимизация бизнес-процессов
Разработка характеристик IT продукта
Внедрение
Задачи бизнес-аналитики
Изучение и формализация предметной области клиента
Оптимизация бизнес-процессов
Разработка характеристик IT продукта
Внедрение

Задачи машинного обучения
Задачи машинного обучения заключаются в получении прогноза или вывода,
Задачи машинного обучения
Задачи машинного обучения заключаются в получении прогноза или вывода,
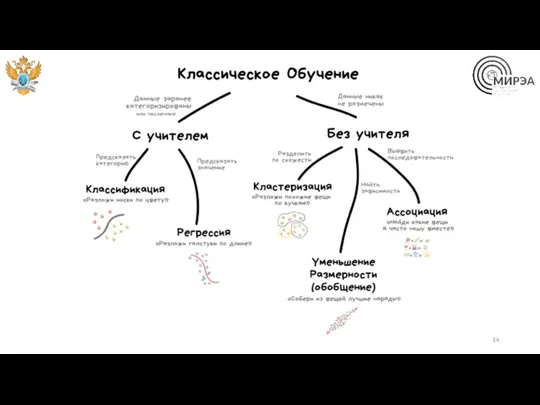
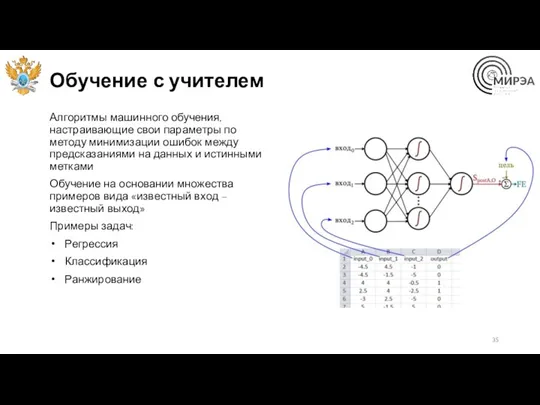
Обучение с учителем
Алгоритмы машинного обучения, настраивающие свои параметры по методу минимизации
Обучение с учителем
Алгоритмы машинного обучения, настраивающие свои параметры по методу минимизации
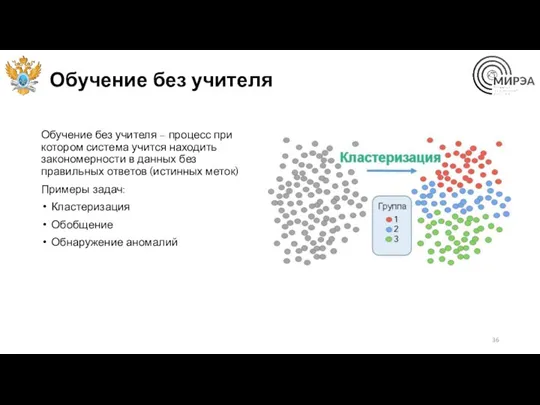
Обучение без учителя
Обучение без учителя – процесс при котором система учится
Обучение без учителя
Обучение без учителя – процесс при котором система учится
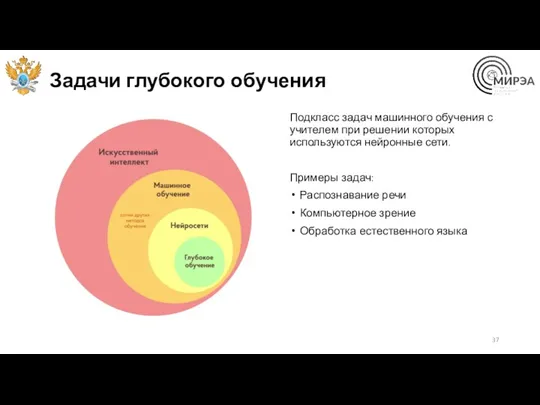
Задачи глубокого обучения
Подкласс задач машинного обучения с учителем при решении которых
Задачи глубокого обучения
Подкласс задач машинного обучения с учителем при решении которых

Задачи глубокого обучения
Задачи глубокого обучения

Часть 3. OLAP системы
Часть 3. OLAP системы
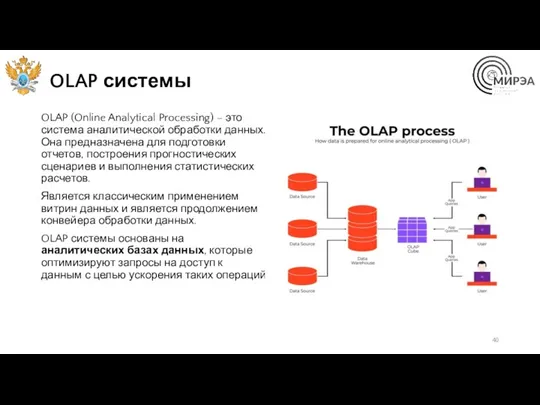
OLAP системы
OLAP (Online Analytical Processing) – это система аналитической обработки данных.
OLAP системы
OLAP (Online Analytical Processing) – это система аналитической обработки данных.

Скорость доступа к данным в OLAP системах
Аналитические базы данных — специализированные
Скорость доступа к данным в OLAP системах
Аналитические базы данных — специализированные
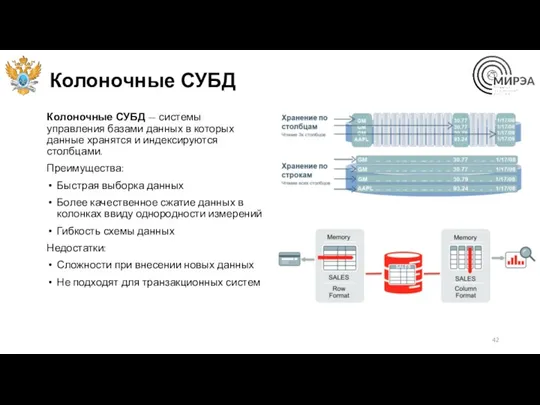
Колоночные СУБД
Колоночные СУБД — системы управления базами данных в которых данные
Колоночные СУБД
Колоночные СУБД — системы управления базами данных в которых данные

MPP-системы
MPP – архитектура параллельных вычислений, при которой память физически разделена.
Система строится
MPP-системы
MPP – архитектура параллельных вычислений, при которой память физически разделена.
Система строится
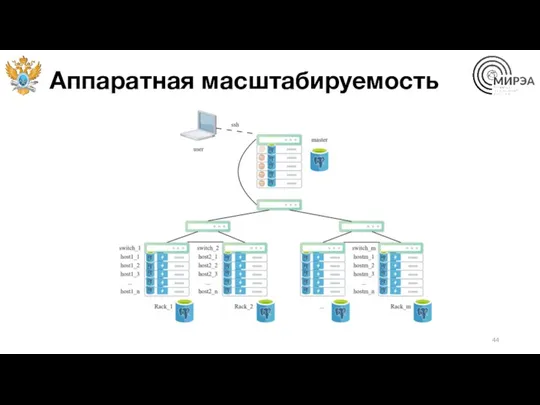
Аппаратная масштабируемость
Аппаратная масштабируемость

Принципы работы с MPP
Используются, если:
объемы данных слишком большие для классической СУБД
когда
Принципы работы с MPP
Используются, если:
объемы данных слишком большие для классической СУБД
когда

OLAP против OLTP
OLTP — системы хранения оперативных данных с высокой скоростью
OLAP против OLTP
OLTP — системы хранения оперативных данных с высокой скоростью

Часть 4. Способы визуализации данных
Часть 4. Способы визуализации данных
Разведочный анализ данных (EDA)
Разведочный анализ данных — анализ основных свойств данных,
Разведочный анализ данных (EDA)
Разведочный анализ данных — анализ основных свойств данных,

График разброса
График разброса — это средство для показа взаимоотношений между двумя
График разброса
График разброса — это средство для показа взаимоотношений между двумя
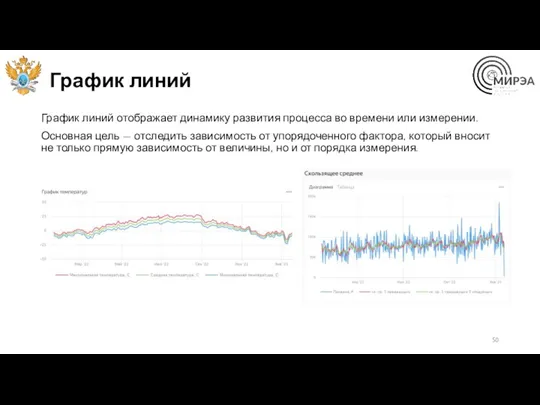
График линий
График линий отображает динамику развития процесса во времени или измерении.
График линий
График линий отображает динамику развития процесса во времени или измерении.
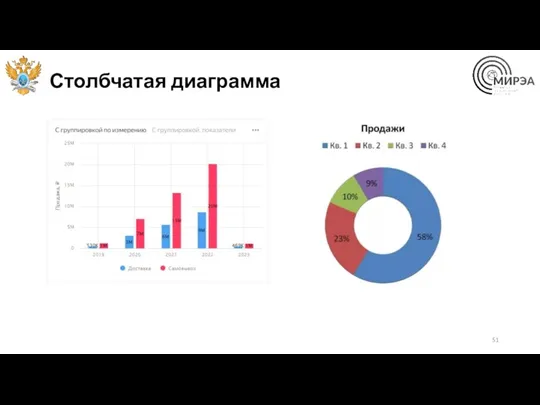
Столбчатая диаграмма
Столбчатая диаграмма

Карты
Карты помогают отследить распределение спроса на реальных географических данных.
Визуализация позволяет сконцентрироваться
Карты
Карты помогают отследить распределение спроса на реальных географических данных.
Визуализация позволяет сконцентрироваться
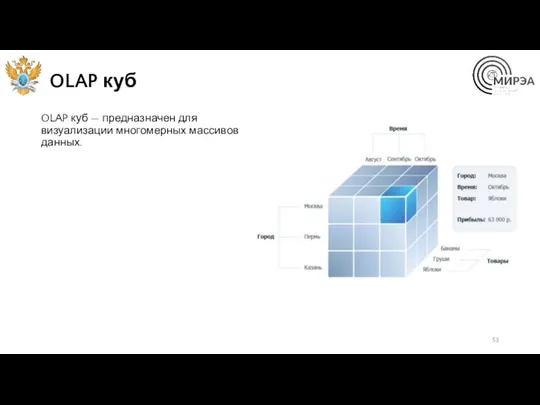
OLAP куб
OLAP куб — предназначен для визуализации многомерных массивов данных.
OLAP куб
OLAP куб — предназначен для визуализации многомерных массивов данных.
Построение динамических отчетов
Упрощение
Сравнение
Сопровождение
Взгляд иначе
Вопрос “почему?”
Скептицизм
Отклик
Построение динамических отчетов
Упрощение
Сравнение
Сопровождение
Взгляд иначе
Вопрос “почему?”
Скептицизм
Отклик

Отчеты в аналитике
Отчеты используются для работы с определенными наборами данных, например,
Отчеты в аналитике
Отчеты используются для работы с определенными наборами данных, например,

Дашборды
Дашборд — это интерактивная аналитическая панель, графический интерфейс. Смысл в том,
Дашборды
Дашборд — это интерактивная аналитическая панель, графический интерфейс. Смысл в том,
 Иcтория и направления развития компании Yahoo!
Иcтория и направления развития компании Yahoo! Игровые методы в преподавании информатики
Игровые методы в преподавании информатики Прокси-сервера
Прокси-сервера Мобильді құрылғыларға арналған операциялық жүйелер
Мобильді құрылғыларға арналған операциялық жүйелер Глобальное информационное общество
Глобальное информационное общество Билл Гейтс
Билл Гейтс Регистр
Регистр Анализ алгоритма, содержащего цикл и ветвление
Анализ алгоритма, содержащего цикл и ветвление Компьютерные игры The elder scrolls
Компьютерные игры The elder scrolls Деректер базасының түрлері
Деректер базасының түрлері Урок по теме Устройства компьютера
Урок по теме Устройства компьютера Сокет - бағдарламалық интерфейсі
Сокет - бағдарламалық интерфейсі Методы оптимизации в электронных таблицах
Методы оптимизации в электронных таблицах Дифференцированный подход в изучении физики и информатики
Дифференцированный подход в изучении физики и информатики Электронные таблицы. Работа с формулами
Электронные таблицы. Работа с формулами Автоматическая обработка информации. Машина Поста
Автоматическая обработка информации. Машина Поста Внеклассное мероприятие Король ринга
Внеклассное мероприятие Король ринга Уроки безопасного интернета. Викторина
Уроки безопасного интернета. Викторина Методы кодирования. Циклический код. Использование образующих матриц
Методы кодирования. Циклический код. Использование образующих матриц Комп'ютерні мережі та їх призначення. Поняття про мережну взаємодію. Типи комп'ютерних мереж
Комп'ютерні мережі та їх призначення. Поняття про мережну взаємодію. Типи комп'ютерних мереж Введение в операционную систему и виртуализацию
Введение в операционную систему и виртуализацию Общие сведения о VBA
Общие сведения о VBA ПО и ОС Windows
ПО и ОС Windows История компьютера
История компьютера Нормативно-правовые документы и стандарты в области защиты информации и информационной безопасности
Нормативно-правовые документы и стандарты в области защиты информации и информационной безопасности База данных
База данных Програмний комплекс автоматизації центрів надання адміністративних послуг (Інформаційна система Вулик)
Програмний комплекс автоматизації центрів надання адміністративних послуг (Інформаційна система Вулик) От идеи – до результата. О реализации проектов по информационной работе в МГО Профсоюза
От идеи – до результата. О реализации проектов по информационной работе в МГО Профсоюза