- Технологии анализа данных

Содержание
- 2. ❶ ❸ ❷ Выявление (подтверждение, корректиро-вка) закономерности в поведении соци-ального объекта (явления, процесса) Объяснение на основе
- 3. Процесс аналитического исследования больших массивов необработанных данных в целях выявления скрытых закономернос-тей и систематических взаимосвязей между
- 4. Понятие Data Mining Data Mining - мультидисциплинарная область зна-ний, нацеленная на «раскопку» полезных данных в больших
- 5. Методы и алгоритмы Data Mining К методам и алгоритмам Data Mining можно отнести следующие: ⮊ искусственные
- 6. Состоит из трех стадий: Выявление закономерностей (свободный поиск) Использование выявленных закономерностей для предсказания неизвестных
- 7. Стадия свободного поиска Осуществляется извлечение полезной информации из первичных данных и преобразование ее в некото-рые формальные
- 8. Стадия прогностического моделирования Использует результаты предыдущей стадии непос-редственно для прогнозирования новых результа-тов, основанного на анализе прецедентов
- 9. Анализ исключений Предназначен для выявления и формализации ано-малий (отклонений), в найденных на предыдущих стадиях закономерностях Найдено
- 10. Применяется: ⮊ при отсутствии или недостаточности предвари- тельной информации о природе связей; ⮊ при необходимости учета
- 11. С методологической точки зрения: Класс аналитических методов, построенных на при-нципах обучения мыслящих существ и функциони-рования мозга,
- 12. Входной слой Выходной слой Скрытые слои Построение нейронных сетей
- 13. Таким образом, передаточная функция имеет вид: Y = f ( ∑ Wi*Xi ) где, Xi –
- 14. Для разработки и применения нейронных сетей используются: ⮊ программный пакет NeurOn-line ⮊ NeuralWorks Professional II/Plus ⮊
- 15. Представляет собой структурно-параметрическую формализацию социально-экономических и поли-тических процессов Выражается в виде ориентированного графа Вершины графа –
- 16. Для повышения адекватности когнитивных моделей изменяют качество оргграфа: Знаковый граф (когнитивная карта) Взвешенный граф Функциональный граф
- 17. анализа документов текстовых Методы
- 18. Анализ символьных данных представляет собой творческий процесс, зависящий от: ⮊ содержания и сложности построения документа ⮊
- 19. При оценке надежности учитывают следующие факторы: ⮊ является ли документ официальным ⮊ является ли документ личным
- 20. Технологии автоматического извлечения знаний могут быть сведены к следующим направлениям: ❶ классификация ❷ кластерный анализ ❸
- 21. Представляет собой систему рубрицирования тек-стовых документов, базирующуюся на разделении понятий «тема» и «проблема» Тема более простая
- 22. обеспечивает: ❶ интеграцию разнородной информации ❷ профилирование пользователей и проблем ❸ проблемно-тематическую навигацию по информационным фондам
- 23. Применяется при реферировании больших докуме-нтальных массивов и выделении компактных под-групп документов с близкими свойствами Различают два
- 24. Заключается в использовании технологических процедур: ❶ индексирование ключевыми словами анализ смыслового содержания текста для выделения све-дений
- 26. Скачать презентацию

❶
❸
❷
Выявление (подтверждение, корректиро-вка) закономерности в поведении соци-ального объекта (явления, процесса)
Объяснение на
❶
❸
❷
Выявление (подтверждение, корректиро-вка) закономерности в поведении соци-ального объекта (явления, процесса)
Объяснение на

Процесс аналитического исследования больших массивов необработанных данных в целях выявления
Процесс аналитического исследования больших массивов необработанных данных в целях выявления
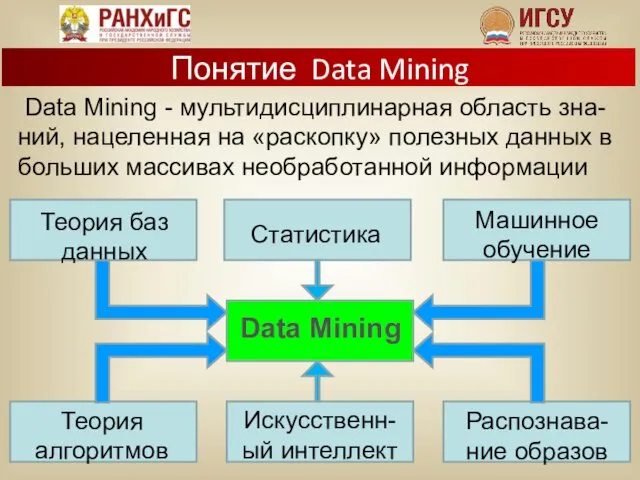
Понятие Data Mining
Data Mining - мультидисциплинарная область зна-ний, нацеленная на
Понятие Data Mining
Data Mining - мультидисциплинарная область зна-ний, нацеленная на

Методы и алгоритмы Data Mining
К методам и алгоритмам Data Mining можно
Методы и алгоритмы Data Mining
К методам и алгоритмам Data Mining можно

Состоит из трех стадий:
Выявление закономерностей (свободный поиск)
Использование выявленных закономерностей
Состоит из трех стадий:
Выявление закономерностей (свободный поиск)
Использование выявленных закономерностей

Стадия свободного поиска
Осуществляется извлечение полезной информации из первичных данных и преобразование
Стадия свободного поиска
Осуществляется извлечение полезной информации из первичных данных и преобразование

Стадия прогностического моделирования
Использует результаты предыдущей стадии непос-редственно для прогнозирования новых результа-тов,
Стадия прогностического моделирования
Использует результаты предыдущей стадии непос-редственно для прогнозирования новых результа-тов,

Анализ исключений
Предназначен для выявления и формализации ано-малий (отклонений), в найденных на
Анализ исключений
Предназначен для выявления и формализации ано-малий (отклонений), в найденных на

Применяется:
⮊ при отсутствии или недостаточности предвари-
тельной информации о природе связей;
⮊
Применяется:
⮊ при отсутствии или недостаточности предвари-
тельной информации о природе связей;
⮊

С методологической точки зрения:
Класс аналитических методов, построенных на при-нципах обучения мыслящих
С методологической точки зрения:
Класс аналитических методов, построенных на при-нципах обучения мыслящих
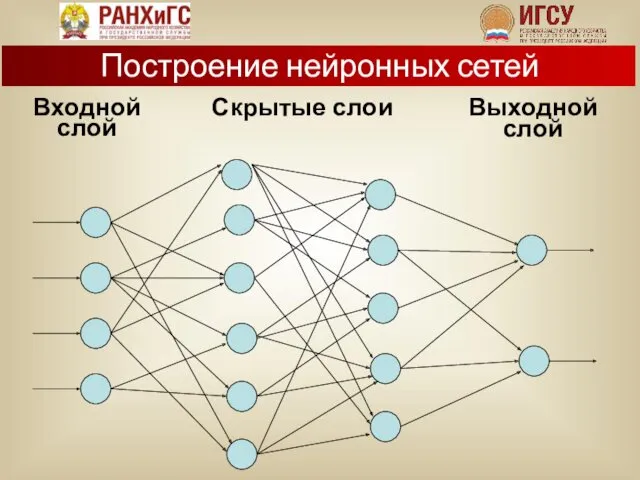
Входной
слой
Выходной
слой
Скрытые слои
Построение нейронных сетей
Входной
слой
Выходной
слой
Скрытые слои
Построение нейронных сетей
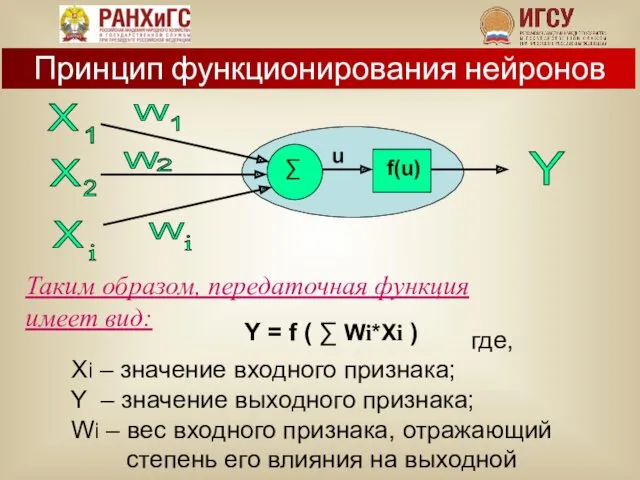
Таким образом, передаточная функция имеет вид:
Y = f ( ∑ Wi*Xi
Таким образом, передаточная функция имеет вид:
Y = f ( ∑ Wi*Xi

Для разработки и применения нейронных сетей используются:
⮊ программный пакет NeurOn-line
⮊ NeuralWorks
Для разработки и применения нейронных сетей используются:
⮊ программный пакет NeurOn-line
⮊ NeuralWorks
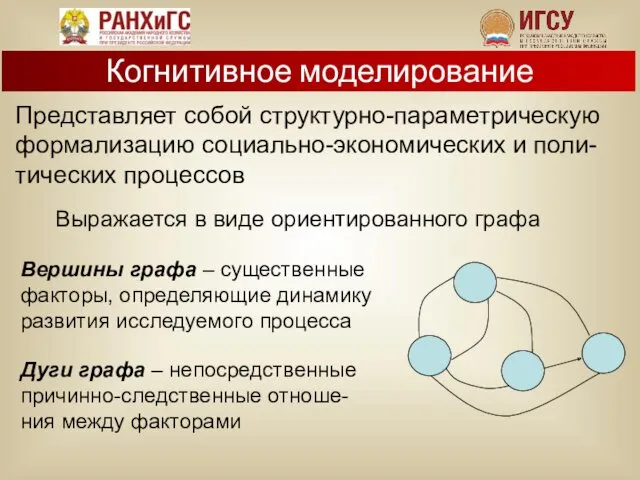
Представляет собой структурно-параметрическую формализацию социально-экономических и поли-тических процессов
Выражается в виде ориентированного
Представляет собой структурно-параметрическую формализацию социально-экономических и поли-тических процессов
Выражается в виде ориентированного
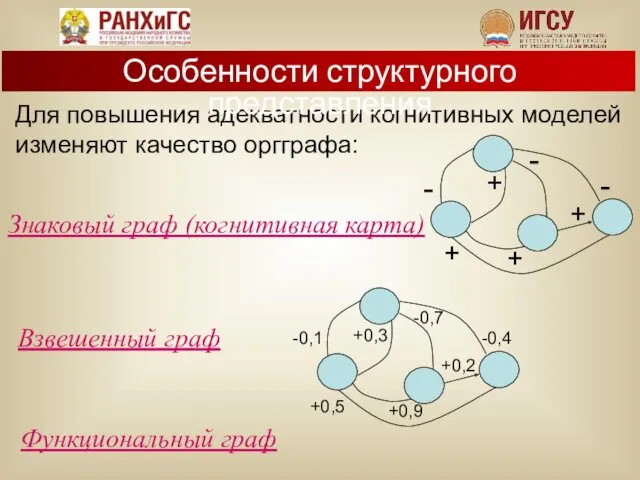
Для повышения адекватности когнитивных моделей изменяют качество оргграфа:
Знаковый граф (когнитивная карта)
Взвешенный
Для повышения адекватности когнитивных моделей изменяют качество оргграфа:
Знаковый граф (когнитивная карта)
Взвешенный

анализа
документов
текстовых
Методы
анализа
документов
текстовых
Методы

Анализ символьных данных представляет собой творческий процесс, зависящий от:
⮊ содержания и
Анализ символьных данных представляет собой творческий процесс, зависящий от:
⮊ содержания и

При оценке надежности учитывают следующие факторы:
⮊ является ли документ официальным
⮊ является
При оценке надежности учитывают следующие факторы:
⮊ является ли документ официальным
⮊ является

Технологии автоматического извлечения знаний могут быть сведены к следующим направлениям:
❶ классификация
❷
Технологии автоматического извлечения знаний могут быть сведены к следующим направлениям:
❶ классификация
❷

Представляет собой систему рубрицирования тек-стовых документов, базирующуюся на разделении понятий «тема»
Представляет собой систему рубрицирования тек-стовых документов, базирующуюся на разделении понятий «тема»

обеспечивает:
❶ интеграцию разнородной информации
❷ профилирование пользователей и проблем
❸ проблемно-тематическую навигацию по
обеспечивает:
❶ интеграцию разнородной информации
❷ профилирование пользователей и проблем
❸ проблемно-тематическую навигацию по

Применяется при реферировании больших докуме-нтальных массивов и выделении компактных под-групп документов
Применяется при реферировании больших докуме-нтальных массивов и выделении компактных под-групп документов

Заключается в использовании технологических процедур:
❶ индексирование ключевыми словами
анализ смыслового содержания текста
Заключается в использовании технологических процедур:
❶ индексирование ключевыми словами
анализ смыслового содержания текста
 Основы автоматизации и автоматизация производственных процессов ( ОА и АПП)
Основы автоматизации и автоматизация производственных процессов ( ОА и АПП) Обработка данных средствами электронных таблиц Microsoft Excel
Обработка данных средствами электронных таблиц Microsoft Excel Знакомство с IDE
Знакомство с IDE Язык программирования Python. Основы языка Python. Линейные программы
Язык программирования Python. Основы языка Python. Линейные программы Использование логических функций в excel
Использование логических функций в excel Инструкция по работе с приложением Adobe Acrobat PRO DC
Инструкция по работе с приложением Adobe Acrobat PRO DC Введение в HTML 5
Введение в HTML 5 Электронное портфолио Exabis E-Portfolio
Электронное портфолио Exabis E-Portfolio Конспект урока информатики на тему Хранение информации
Конспект урока информатики на тему Хранение информации Знакомство с новым учебником по информатике. (8 класс)
Знакомство с новым учебником по информатике. (8 класс) Технологии баз данных и знаний
Технологии баз данных и знаний Направление в Банк выписки СЗИ 6 из ПФ РФ с использованием Портала Госуслуг
Направление в Банк выписки СЗИ 6 из ПФ РФ с использованием Портала Госуслуг Современные способы и средства зашиты информации
Современные способы и средства зашиты информации Формы и отчеты в СУБД Access
Формы и отчеты в СУБД Access Эффективное продвижение в INSTAGRAM 2018
Эффективное продвижение в INSTAGRAM 2018 Дополнительные возможности использования Active Directory в корпоративной сети
Дополнительные возможности использования Active Directory в корпоративной сети Відгуки про ковбасу
Відгуки про ковбасу Основы информатики и компьютерный практикум. ОС Windows. Текстовый процессор Word
Основы информатики и компьютерный практикум. ОС Windows. Текстовый процессор Word Трёхмерная графика и 3D - моделирование
Трёхмерная графика и 3D - моделирование История развития вычислительной техники
История развития вычислительной техники Устройство ЭВМ
Устройство ЭВМ Модель даних “сутність-зв’язок”
Модель даних “сутність-зв’язок” Історія комп'ютерної техніки
Історія комп'ютерної техніки Возможности интерактивности в создании современных аудиовизуальных программ
Возможности интерактивности в создании современных аудиовизуальных программ Урок по теме Системы счисления 9 класс
Урок по теме Системы счисления 9 класс Антивирусные программы
Антивирусные программы Создание модели подарочной коробки при помощи программы Tinkercad
Создание модели подарочной коробки при помощи программы Tinkercad Лекция № 12. Транзакции,тригеры
Лекция № 12. Транзакции,тригеры