- Технологии искусственного интеллекта: основные понятия, направления развития. Лекция 6

Содержание
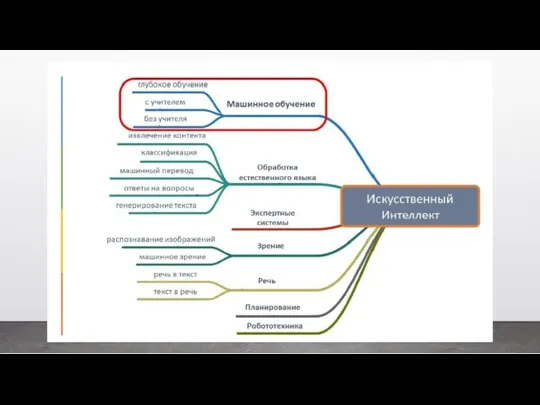
- 2. Искусственный интеллект является одной из сквозных технологий, которые заложены в национальную программу «Цифровая экономика». Сквозные технологии
- 5. Машинное обучение Класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение
- 6. Одно из самых частых применений машинного обучения — распознавание объектов: изображений, речи и т. д. Например,
- 7. Глубинное обучение Иногда называют «глубокое обучение» (от англ. Deep Learning). Подобласть машинного обучения, где в качестве
- 8. Data Science Это концепция объединения статистики, анализа данных, машинного обучения и связанных с ними методов для
- 9. Data Mining Широкое понятие, означающее извлечение знаний из данных. Очень часто под Data Mining подразумевают методологию
- 10. Большие данные Большие данные предполагают не просто большой объем данных, они имеют определенные характеристики. В 2001
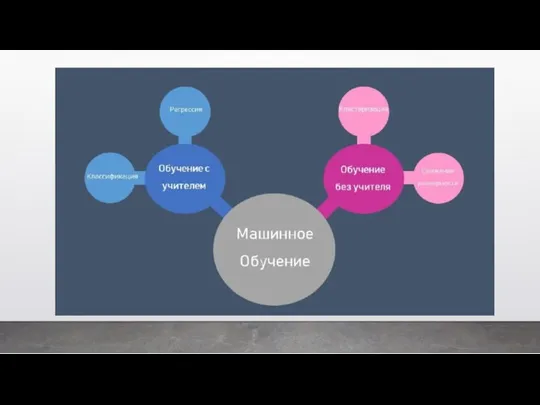
- 14. В первом случае у машины есть некий учитель, который говорит ей как правильно. Рассказывает, что на
- 18. Это будет пример цветков ириса Фишера. Этот набор данных стал уже классическим, и часто используется для
- 23. На основании этого набора данных требуется построить правило классификации, определяющее вид растения в зависимости от размеров.
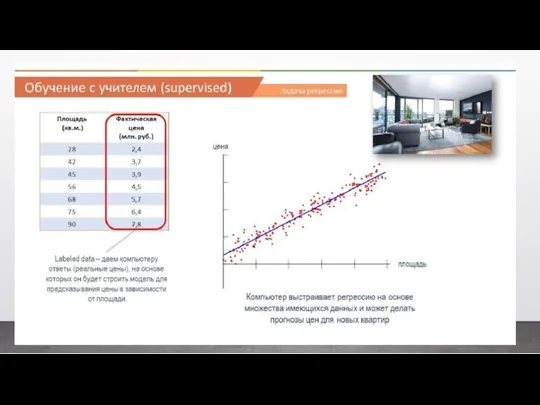
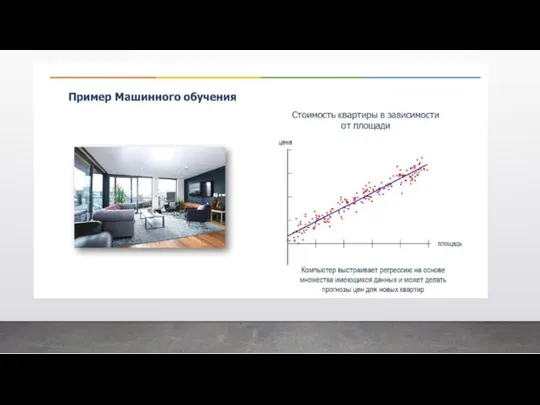
- 29. Классический пример регрессии – это когда мы предсказываем цену квартиры в зависимости от ее площади. Опять
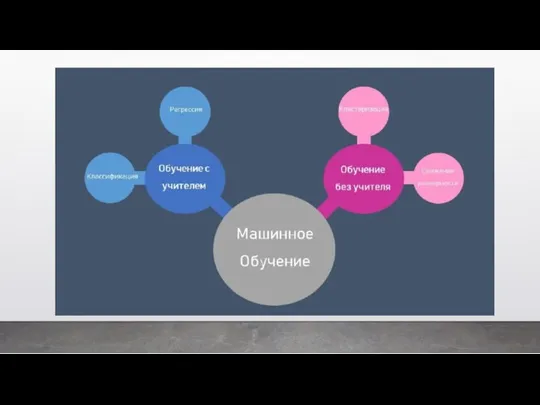
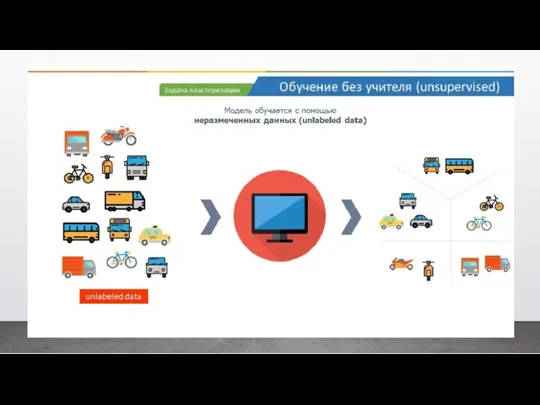
- 36. Второй вид машинного обучения – это обучение без учителя. Это когда мы позволяем нашей модели обучаться
- 37. Задачи классификации можно решить с помощью разных методов. Наиболее часто используемыми являются следующие: – Дерево решений
- 39. В задачах кластеризации у нас имеется набор объектов и нам надо выявить его внутреннюю структуру. То
- 41. Такие задачи бывают очень полезны для крупных ритейлеров, если они, например, хотят понять из кого состоят
- 42. Ба́йесовская фильтра́ция спа́ма — метод для фильтрации спама, основанный на применении наивного байесовского классификатора, опирающегося на
- 43. Первой известной программой, фильтрующей почту с использованием байесовского классификатора, была программа iFile Джейсона Ренни, выпущенная в
- 44. Первой известной программой, фильтрующей почту с использованием байесовского классификатора, была программа iFile Джейсона Ренни, выпущенная в
- 46. Предположим, ваш компьютер оценивает, насколько хорошо написано эссе. Если вы используете ГО, то компьютер вам просто
- 48. Если вкратце, то каким образом работает ГО. Предположим, наша задача вычислить сколько единиц транспорта и какой
- 49. Поэтому другой вариант решения этой задачи, это загрузить большое количество изоб- ражений с разными видами транспорта
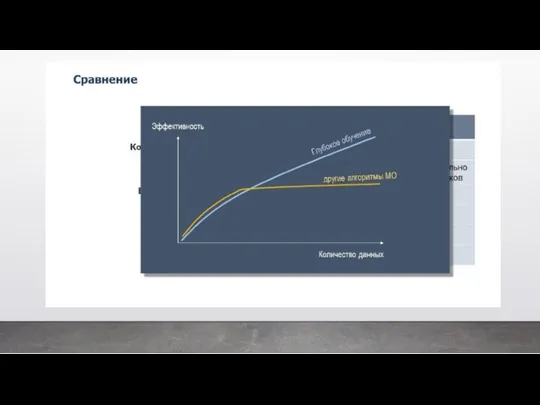
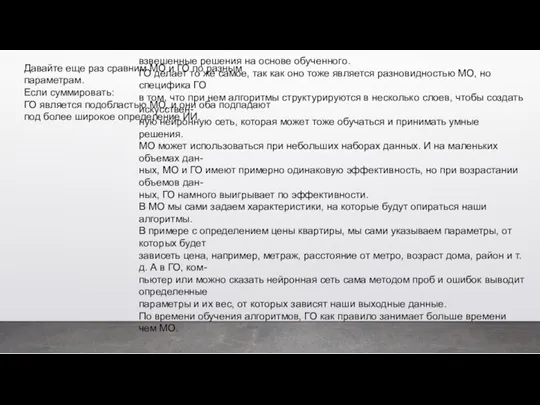
- 50. Давайте еще раз сравним МО и ГО по разным параметрам. Если суммировать: ГО является подобластью МО,
- 51. Расшифровка или интерпретация алгоритмов МО легче, потому что мы видим какой параметр играет важную роль для
- 53. Таким образом, если суммировать всю данную главу, то везде, где применяется распо- знавание речи или изображений,
- 54. Примеры использования ИИ, МО и ГО Все лунные модули, которые бороздят поверхность Луны, используют алгоритмы ИИ.
- 55. Машинное обучение Улучшение выдачи результатов поиска в Google. Когда ты вбиваешь какой-то запрос в поисковой строке,
- 56. Глубокое обучение Очень часто ГО используется для распознавания объектов на изображениях. Кроме того, с помощью ГО
- 58. Еще одним популярным применением ГО являются так называемые рекомендательные системы: когда при покупке одного товара нам
- 60. И в конце, на что еще хотелось бы обратить внимание. Как уже было сказано, и ГО
- 62. В 40-х годах ХХ в. с появлением ЭВМ искусственный интеллект обрел второе рождение. Произошло выделение искусственного
- 63. Несмотря на наличие множества подходов как к пониманию задач ИИ, так и созданию интеллектуальных информационных систем
- 64. Пионером искусственного интеллекта по праву можно считать коллежского советника С.Н. Корсакова, ставившего задачу усиления возможностей разума
- 65. Цель машинного обучения — это предсказать результат по входным данным. Чем разнообразнее входные данные, тем проще
- 66. Данные
- 67. Признаки (фичи от английского слова «feature») Машина должна знать, на что ей конкретно смотреть.
- 68. Алгоритм Одну задачу можно решить разными методами. От выбора метода зависит точность, скорость работы и размер
- 71. используется для задач, когда есть простые данные и понятные признаки Первые алгоритмы - из чистой статистики
- 72. Классификация Пример метода Дерево решений Вы берёте кредит в банке. Как банку удостовериться, вернёте вы его
- 73. Классификация Пример метода Метод опорных векторов Им классифицировали уже всё — виды растений, лица на фотографиях,
- 74. У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то признак объекта не вписывается в
- 75. Регрессия — та же классификация, только вместо категории мы предсказываем число. Например, стоимость автомобиля по его
- 76. Классификация Пример метода Кластеризация, или кластерный анализ Это классификация, но без заранее известных классов. Машина сама
- 77. Классификация Пример метода Кластеризация, или кластерный анализ Сжатие изображений — ещё одна популярная проблема. Сохраняя картинку
- 78. Классификация Пример метода Кластеризация, или кластерный анализ метод К-средних Проблема только, как быть с цветами типа
- 79. Классификация Пример метода Кластеризация, или кластерный анализ метод DBSCAN Метод DBSCAN. Он сам находит скопления точек
- 80. Обучение с подкреплением — это когда мы бросаем робота в лабиринт, и он сам там ищет
- 81. Умные модели роботов-пылесосов и беспилотные автомобили обучаются именно так: часто на основе карт настоящих городов для
- 82. Марковский процесс принятия решений — это способ последовательного решения задачи для полностью наблюдаемой среды, в которой
- 83. Пример метода Стекинг Мы обучаем несколько разных алгоритмов и передаём их результаты на вход последнему, который
- 84. Пример метода Бэггинг Бэггинг — это когда мы обучаем один алгоритм много раз на случайных выборках
- 85. Пример метода Бустинг При бустинге мы обучаем алгоритмы последовательно, и каждый следующий уделяет особое внимание тем
- 86. Сегодня нейронные сети используют для определения объектов на фото и видео, распознавания и синтеза речи, обработки
- 88. Скачать презентацию

Искусственный интеллект является одной из сквозных технологий, которые заложены в национальную



Машинное обучение
Класс методов искусственного интеллекта, характерной чертой которых является не
Машинное обучение
Класс методов искусственного интеллекта, характерной чертой которых является не

Одно из самых частых применений машинного обучения — распознавание объектов: изображений,

Глубинное обучение
Иногда называют «глубокое обучение» (от англ. Deep Learning). Подобласть
Глубинное обучение
Иногда называют «глубокое обучение» (от англ. Deep Learning). Подобласть

Data Science
Это концепция объединения статистики, анализа данных, машинного обучения и
Data Science
Это концепция объединения статистики, анализа данных, машинного обучения и

Data Mining
Широкое понятие, означающее извлечение знаний из данных.
Очень часто
Data Mining
Широкое понятие, означающее извлечение знаний из данных.
Очень часто

Большие данные
Большие данные предполагают не просто большой объем данных, они
Большие данные
Большие данные предполагают не просто большой объем данных, они
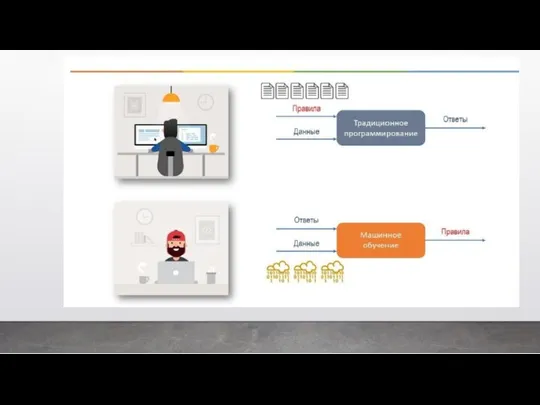


В первом случае у машины есть некий учитель, который говорит ей
В первом случае у машины есть некий учитель, который говорит ей


Это будет пример цветков ириса Фишера. Этот набор данных стал уже
Это будет пример цветков ириса Фишера. Этот набор данных стал уже

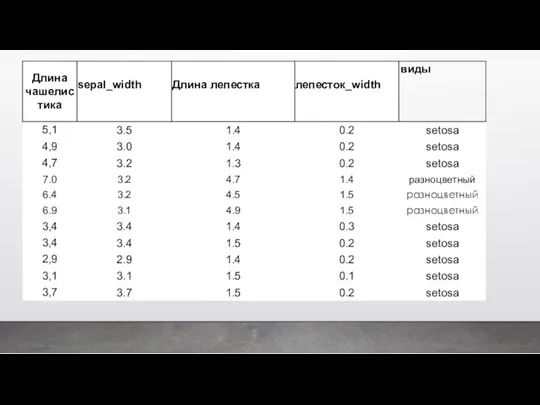

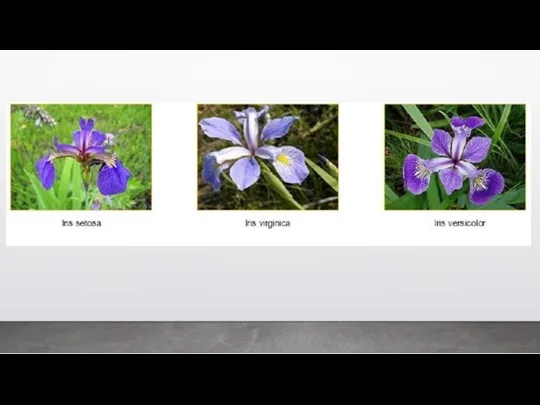

На основании этого набора данных требуется построить правило классификации, определяющее вид
На основании этого набора данных требуется построить правило классификации, определяющее вид

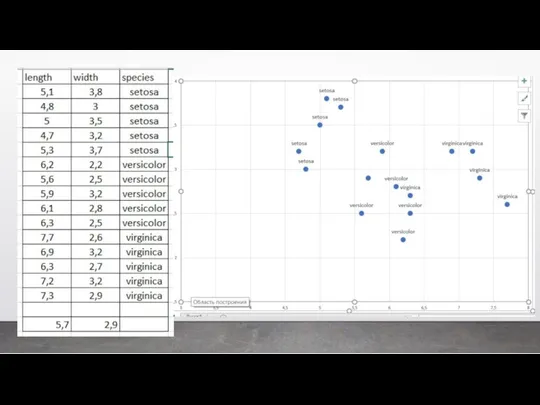
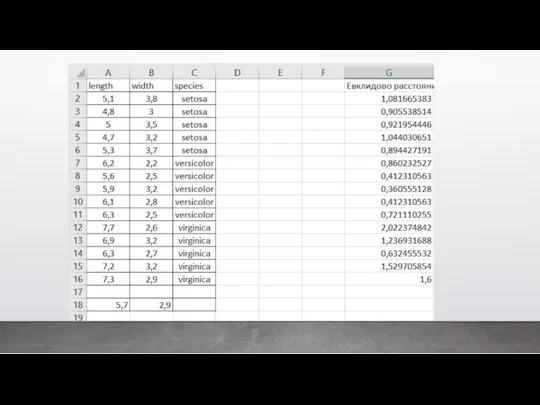
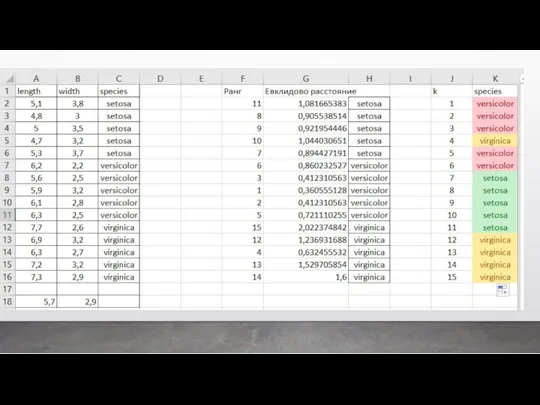
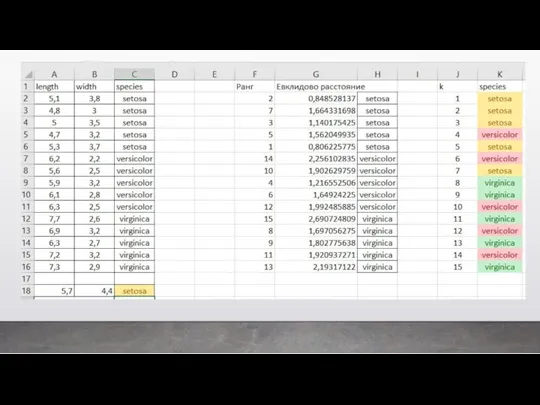

Классический пример регрессии – это когда мы предсказываем цену квартиры в
Классический пример регрессии – это когда мы предсказываем цену квартиры в
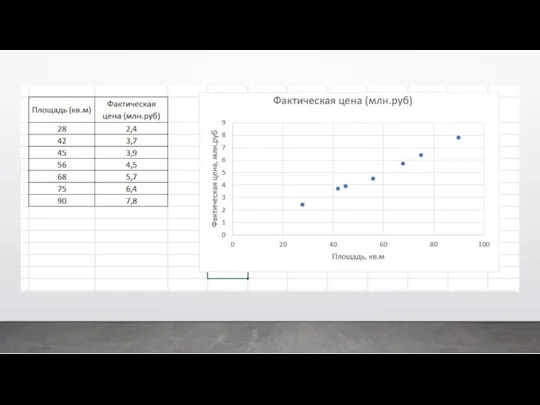
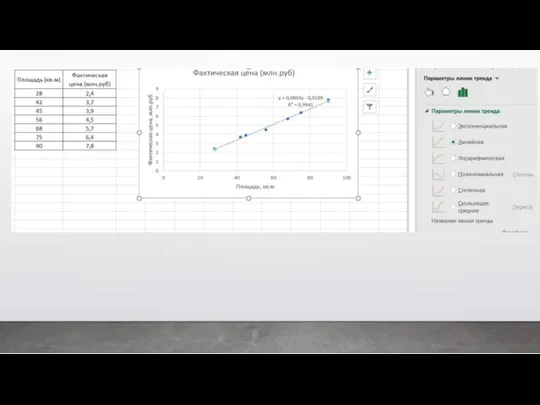
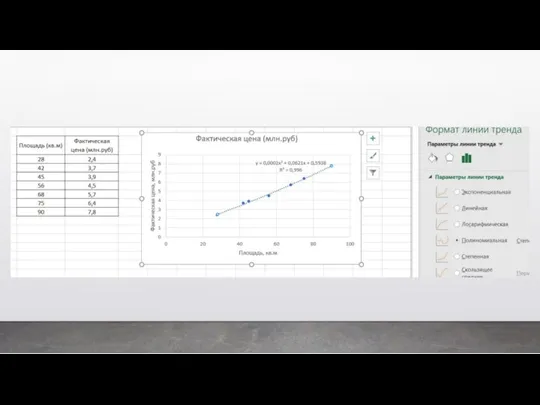
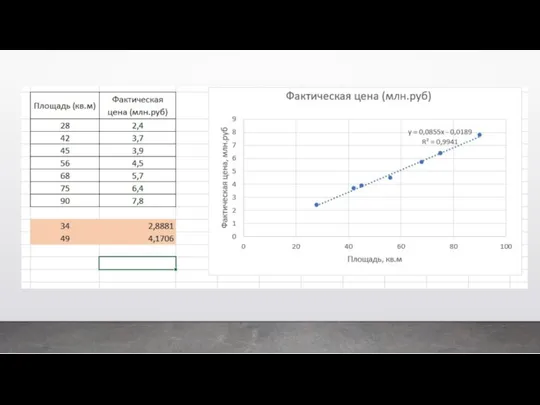

Второй вид машинного обучения – это обучение без учителя. Это когда
мы
Второй вид машинного обучения – это обучение без учителя. Это когда
мы

Задачи классификации можно решить с помощью разных методов. Наиболее часто используемыми
Задачи классификации можно решить с помощью разных методов. Наиболее часто используемыми

В задачах кластеризации у нас имеется набор объектов и нам надо
В задачах кластеризации у нас имеется набор объектов и нам надо

Такие задачи бывают очень полезны для крупных ритейлеров, если они, например,
Такие задачи бывают очень полезны для крупных ритейлеров, если они, например,

Ба́йесовская фильтра́ция спа́ма — метод для фильтрации спама, основанный на применении наивного байесовского классификатора,
Ба́йесовская фильтра́ция спа́ма — метод для фильтрации спама, основанный на применении наивного байесовского классификатора,

Первой известной программой, фильтрующей почту с использованием байесовского классификатора, была программа iFile Джейсона
Первой известной программой, фильтрующей почту с использованием байесовского классификатора, была программа iFile Джейсона

Первой известной программой, фильтрующей почту с использованием байесовского классификатора, была программа iFile Джейсона
Первой известной программой, фильтрующей почту с использованием байесовского классификатора, была программа iFile Джейсона


Предположим, ваш компьютер оценивает, насколько хорошо написано эссе. Если вы
используете ГО,
Предположим, ваш компьютер оценивает, насколько хорошо написано эссе. Если вы
используете ГО,

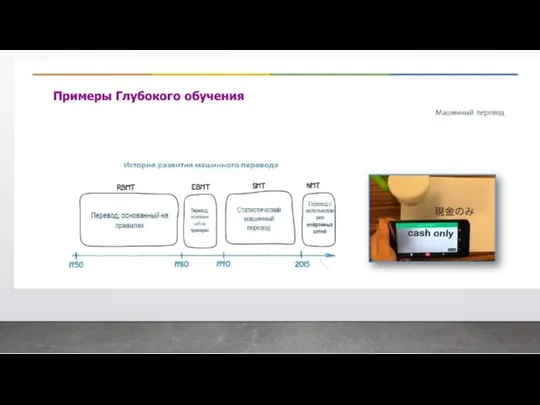
Если вкратце, то каким образом работает ГО. Предположим, наша задача вычислить
сколько
Если вкратце, то каким образом работает ГО. Предположим, наша задача вычислить
сколько

Поэтому другой вариант решения этой задачи, это загрузить большое количество изоб-
ражений
Поэтому другой вариант решения этой задачи, это загрузить большое количество изоб-
ражений
Давайте еще раз сравним МО и ГО по разным параметрам.
Если суммировать:
ГО
Давайте еще раз сравним МО и ГО по разным параметрам.
Если суммировать:
ГО

Расшифровка или интерпретация алгоритмов МО легче, потому что мы видим какой
параметр
Расшифровка или интерпретация алгоритмов МО легче, потому что мы видим какой
параметр


Таким образом, если суммировать всю данную главу, то везде, где применяется
Таким образом, если суммировать всю данную главу, то везде, где применяется

Примеры использования ИИ, МО и ГО
Все лунные модули, которые бороздят поверхность
Примеры использования ИИ, МО и ГО
Все лунные модули, которые бороздят поверхность

Машинное обучение
Улучшение выдачи результатов поиска в Google. Когда ты вбиваешь какой-то
Машинное обучение
Улучшение выдачи результатов поиска в Google. Когда ты вбиваешь какой-то

Глубокое обучение
Очень часто ГО используется для распознавания объектов на изображениях. Кроме
Глубокое обучение
Очень часто ГО используется для распознавания объектов на изображениях. Кроме

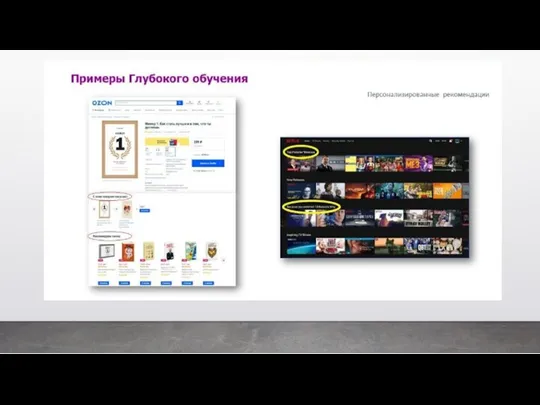
Еще одним популярным применением ГО являются так называемые рекомендательные
системы: когда при
Еще одним популярным применением ГО являются так называемые рекомендательные
системы: когда при

И в конце, на что еще хотелось бы обратить внимание. Как
И в конце, на что еще хотелось бы обратить внимание. Как


В 40-х годах ХХ в. с появлением ЭВМ искусственный интеллект обрел
В 40-х годах ХХ в. с появлением ЭВМ искусственный интеллект обрел

Несмотря на наличие множества подходов как к пониманию задач ИИ, так
Несмотря на наличие множества подходов как к пониманию задач ИИ, так

Пионером искусственного интеллекта по праву можно считать коллежского советника С.Н. Корсакова,
Пионером искусственного интеллекта по праву можно считать коллежского советника С.Н. Корсакова,
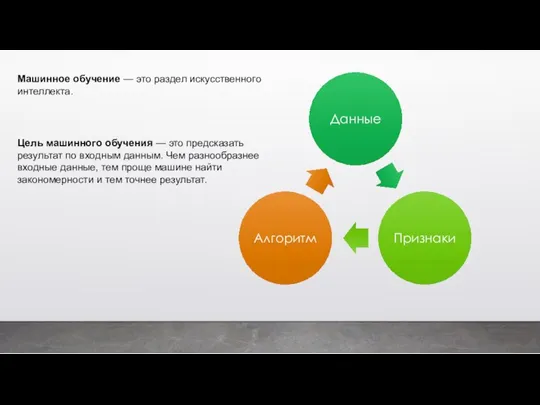
Цель машинного обучения — это предсказать результат по входным данным. Чем
Цель машинного обучения — это предсказать результат по входным данным. Чем

Данные
Данные
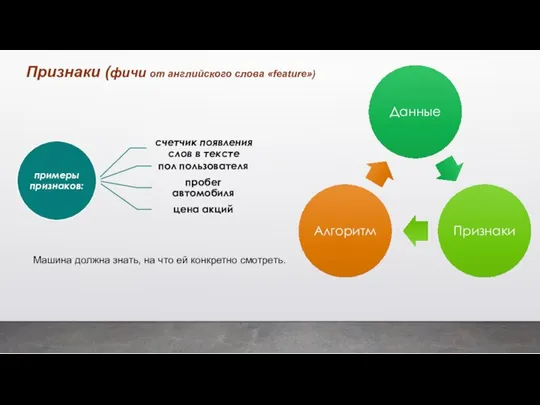
Признаки (фичи от английского слова «feature»)
Машина должна знать, на что ей
Признаки (фичи от английского слова «feature»)
Машина должна знать, на что ей

Алгоритм
Одну задачу можно решить разными методами.
От выбора метода зависит точность,
Алгоритм
Одну задачу можно решить разными методами.
От выбора метода зависит точность,


используется для задач,
когда есть простые данные и понятные признаки
Первые алгоритмы -
используется для задач,
когда есть простые данные и понятные признаки
Первые алгоритмы -

Классификация
Пример метода
Дерево решений
Вы берёте кредит в банке. Как банку удостовериться, вернёте
Классификация
Пример метода
Дерево решений
Вы берёте кредит в банке. Как банку удостовериться, вернёте

Классификация
Пример метода
Метод опорных векторов
Им классифицировали уже всё — виды растений, лица
Классификация
Пример метода
Метод опорных векторов
Им классифицировали уже всё — виды растений, лица

У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то
У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то

Регрессия — та же классификация, только вместо категории мы предсказываем число.
Регрессия — та же классификация, только вместо категории мы предсказываем число.

Классификация
Пример метода
Кластеризация, или кластерный анализ
Это классификация, но без заранее известных классов.
Машина
Классификация
Пример метода
Кластеризация, или кластерный анализ
Это классификация, но без заранее известных классов.
Машина

Классификация
Пример метода
Кластеризация, или кластерный анализ
Сжатие изображений — ещё одна популярная проблема.
Классификация
Пример метода
Кластеризация, или кластерный анализ
Сжатие изображений — ещё одна популярная проблема.

Классификация
Пример метода
Кластеризация, или кластерный анализ
метод К-средних
Проблема только, как быть с цветами
Классификация
Пример метода
Кластеризация, или кластерный анализ
метод К-средних
Проблема только, как быть с цветами

Классификация
Пример метода
Кластеризация, или кластерный анализ
метод DBSCAN
Метод DBSCAN. Он сам находит скопления
Классификация
Пример метода
Кластеризация, или кластерный анализ
метод DBSCAN
Метод DBSCAN. Он сам находит скопления

Обучение с подкреплением — это когда мы бросаем робота в лабиринт,
Обучение с подкреплением — это когда мы бросаем робота в лабиринт,

Умные модели роботов-пылесосов и беспилотные автомобили обучаются именно так: часто на
Умные модели роботов-пылесосов и беспилотные автомобили обучаются именно так: часто на

Марковский процесс принятия решений — это способ последовательного решения задачи для
Марковский процесс принятия решений — это способ последовательного решения задачи для

Пример метода
Стекинг
Мы обучаем несколько разных алгоритмов и передаём их результаты на
Пример метода
Стекинг
Мы обучаем несколько разных алгоритмов и передаём их результаты на

Пример метода
Бэггинг
Бэггинг — это когда мы обучаем один алгоритм много раз
Пример метода
Бэггинг
Бэггинг — это когда мы обучаем один алгоритм много раз

Пример метода
Бустинг
При бустинге мы обучаем алгоритмы последовательно, и каждый следующий уделяет
Пример метода
Бустинг
При бустинге мы обучаем алгоритмы последовательно, и каждый следующий уделяет

Сегодня нейронные сети используют для определения объектов на фото и видео,
Сегодня нейронные сети используют для определения объектов на фото и видео,
 Оператор цикла с предусловием
Оператор цикла с предусловием Другие нейросети. Урок 4.3
Другие нейросети. Урок 4.3 Методы сортировок массивов
Методы сортировок массивов Динамикалық SQL
Динамикалық SQL Программирование на Паскале - первый уровень. Простые (линейные) программы
Программирование на Паскале - первый уровень. Простые (линейные) программы Основы алгебры логики. Логические основы компьютера
Основы алгебры логики. Логические основы компьютера Числовые данные 2 класс
Числовые данные 2 класс Структура и функции MS DOS
Структура и функции MS DOS Организация труда в конвергентной редакции мультимедийного СМИ
Организация труда в конвергентной редакции мультимедийного СМИ Массивы
Массивы Quicksort
Quicksort Основные понятия и принципы математического моделирования
Основные понятия и принципы математического моделирования География сферы услуг (инфографика)
География сферы услуг (инфографика) Разработка клиентских веб-приложений
Разработка клиентских веб-приложений Кодирование графической информации
Кодирование графической информации Этапы проектирования базы данных
Этапы проектирования базы данных Информационное общество
Информационное общество MobileTrans. Поддержка 3000 + телефонов и различных сетей
MobileTrans. Поддержка 3000 + телефонов и различных сетей Общие сведения о языке программирования Паскаль
Общие сведения о языке программирования Паскаль Умовні і циклічні конструкції JavaScript
Умовні і циклічні конструкції JavaScript Зачем нужна информатика
Зачем нужна информатика Параллельные и последовательные интерфейсы. ААС 05
Параллельные и последовательные интерфейсы. ААС 05 MS Excel в курсовой работе
MS Excel в курсовой работе Электронное пособие для оказания профориентационной поддержки школьникам
Электронное пособие для оказания профориентационной поддержки школьникам Основы логики.
Основы логики. Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Website redesign
Website redesign ВКР: Совершенствование системы управления персоналом сервисного предприятия
ВКР: Совершенствование системы управления персоналом сервисного предприятия