- Технологии решения задач в ЭС. Поиск решений на основе нейросетевых моделей

Содержание
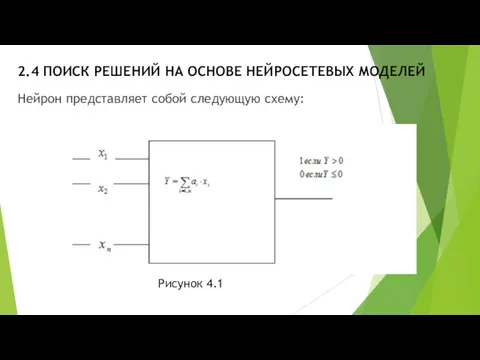
- 2. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Нейрон представляет собой следующую схему: Рисунок 4.1
- 3. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ На вход нейрона поступают сигналы xi . В наших
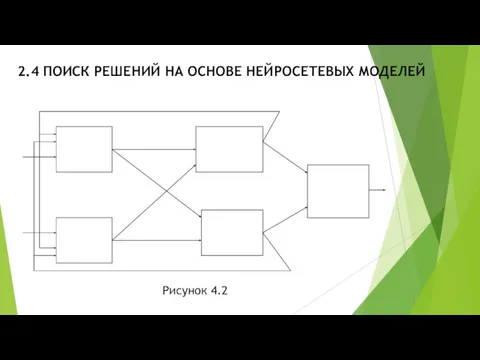
- 4. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Рисунок 4.2
- 5. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Такая сеть является многослойной. В нашем примере – трехслойной.
- 6. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Здесь вычисляется рекуррентная формула Для простоты примем, что .
- 7. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Кроме того, пусть . Решая данное рекуррентное уравнение с
- 8. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Обратимся снова к нейрону на рисунке 4.1. Входы xi
- 9. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Раскроем скобки и получим: или В скалярной форме это
- 10. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Последнее выражение дает нам линейную распознающую функцию нейрона, если
- 11. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ В первом случае коэффициенты нейрона пересчитываются по формуле: Во
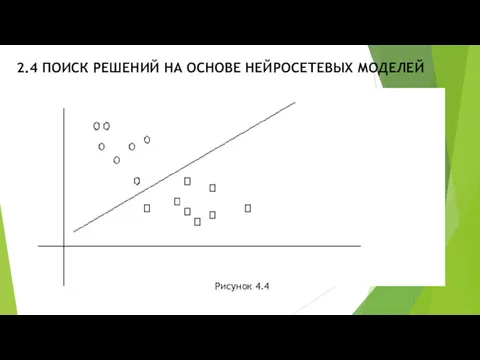
- 12. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Рисунок 4.4
- 13. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ На рис.4.4 овалы соответствуют, например, входным образцам, относящимся к
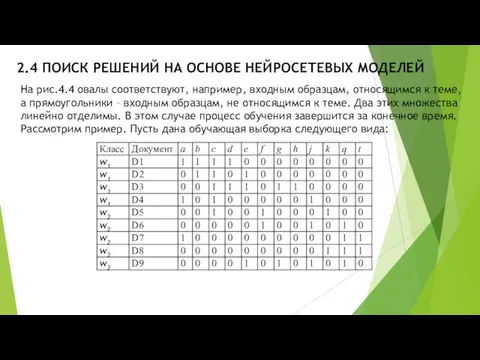
- 14. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Здесь двоичные перемененные обозначены литерами: a-h,j,k,q,t (играют роль ключевых
- 15. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Легко убедиться, что теперь все образцы обучающей таблицы распознаются
- 16. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Рисунок 4.4
- 17. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Полином второй степени от двух переменных есть в общем
- 18. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
- 19. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Допустим, что линейную функцию построить для этой таблицы нельзя.
- 20. 2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ Теперь можно строить линейную функцию вида где Если и
- 21. 2.5 Алгоритм обратного распространения ошибки Рассмотрим сеть на рис.5.1. Пусть на входной слой подана некая комбинация,
- 22. 2.5 Алгоритм обратного распространения ошибки Отклонение сигнала от желаемого трактуется как ошибка. Для каждого выхода вычисляется
- 23. 2.5 Алгоритм обратного распространения ошибки Отыскивать коэффициенты распознающей функции нейрона можно также с помощью алгоритма решения
- 24. 2.5 Алгоритм обратного распространения ошибки По данной таблице запишем следующую систему неравенств: Неравенства (5.2) составлены согласно
- 25. 2.5 Алгоритм обратного распространения ошибки можно заменить на Заметим, что такая замена может сделать систему неравенств
- 26. 2.5 Алгоритм обратного распространения ошибки Для решения системы линейных алгебраических неравенств используем алгоритм устранения невязок. Определение.
- 27. 2.5 Алгоритм обратного распространения ошибки Здесь z1 – новая неотрицательная переменная. Подставим вместо a1 выражение (5.4)
- 28. 2.5 Алгоритм обратного распространения ошибки Выражаем a2: В (5.6) z2 есть новая неотрицательная переменная. Подставляем (5.6)
- 29. 2.5 Алгоритм обратного распространения ошибки Осталась одна единственная невязка: Подстановка (5.8) приводит к системе без невязок.
- 30. 2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ В основе генетических (эволюционных) алгоритмов лежит простая идея: берут пару
- 31. 2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ Сформируем начальную популяцию случайным образом
- 32. 2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ Выберем элиту из 4 наилучших образцов, где функция достигает наибольших
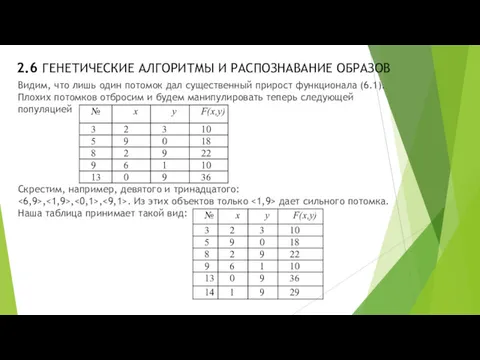
- 33. 2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ Видим, что лишь один потомок дал существенный прирост функционала (6.1).
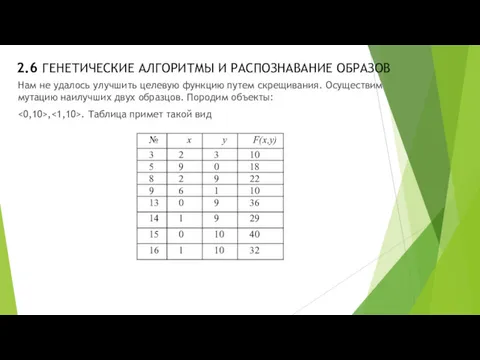
- 34. 2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ Нам не удалось улучшить целевую функцию путем скрещивания. Осуществим мутацию
- 35. 2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ Таким образом, удалось улучшить функционал. Снова возобновляем скрещивания и т.д.,
- 37. Скачать презентацию
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Нейрон представляет собой следующую схему:
Рисунок
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Нейрон представляет собой следующую схему:
Рисунок

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
На вход нейрона поступают сигналы
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
На вход нейрона поступают сигналы
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Рисунок 4.2
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Рисунок 4.2

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Такая сеть является многослойной. В
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Такая сеть является многослойной. В

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Здесь вычисляется рекуррентная формула
Для простоты
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Здесь вычисляется рекуррентная формула
Для простоты

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Кроме того, пусть . Решая
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Кроме того, пусть . Решая

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Обратимся снова к нейрону на
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Обратимся снова к нейрону на

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Раскроем скобки и получим:
или
В скалярной
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Раскроем скобки и получим:
или
В скалярной

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Последнее выражение дает нам линейную
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Последнее выражение дает нам линейную

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
В первом случае коэффициенты нейрона
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
В первом случае коэффициенты нейрона
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Рисунок 4.4
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Рисунок 4.4
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
На рис.4.4 овалы соответствуют, например,
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
На рис.4.4 овалы соответствуют, например,

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Здесь двоичные перемененные обозначены литерами:
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Здесь двоичные перемененные обозначены литерами:

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Легко убедиться, что теперь все
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Легко убедиться, что теперь все
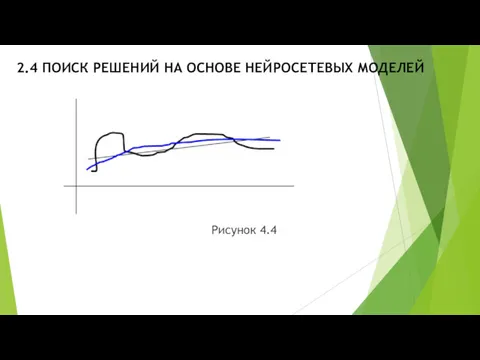
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Рисунок 4.4
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Рисунок 4.4

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Полином второй степени от двух
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Полином второй степени от двух
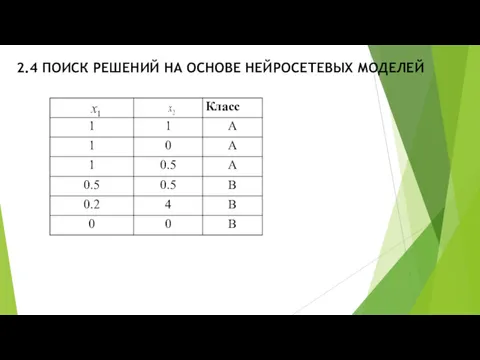
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
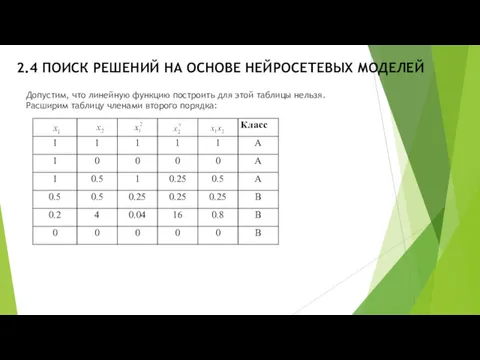
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Допустим, что линейную функцию построить
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Допустим, что линейную функцию построить

2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Теперь можно строить линейную функцию
2.4 ПОИСК РЕШЕНИЙ НА ОСНОВЕ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
Теперь можно строить линейную функцию
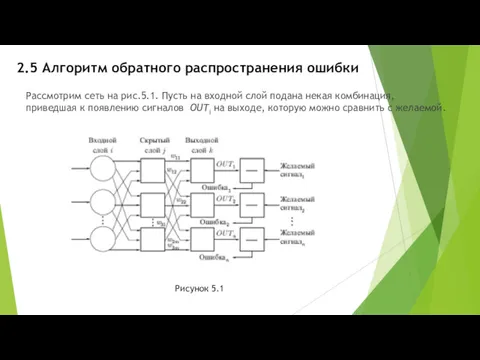
2.5 Алгоритм обратного распространения ошибки
Рассмотрим сеть на рис.5.1. Пусть на входной
2.5 Алгоритм обратного распространения ошибки
Рассмотрим сеть на рис.5.1. Пусть на входной

2.5 Алгоритм обратного распространения ошибки
Отклонение сигнала от желаемого трактуется как ошибка.
2.5 Алгоритм обратного распространения ошибки
Отклонение сигнала от желаемого трактуется как ошибка.

2.5 Алгоритм обратного распространения ошибки
Отыскивать коэффициенты распознающей функции нейрона можно также
2.5 Алгоритм обратного распространения ошибки
Отыскивать коэффициенты распознающей функции нейрона можно также

2.5 Алгоритм обратного распространения ошибки
По данной таблице запишем следующую систему неравенств:
Неравенства
2.5 Алгоритм обратного распространения ошибки
По данной таблице запишем следующую систему неравенств:
Неравенства

2.5 Алгоритм обратного распространения ошибки
можно заменить на
Заметим, что такая замена может
2.5 Алгоритм обратного распространения ошибки
можно заменить на
Заметим, что такая замена может

2.5 Алгоритм обратного распространения ошибки
Для решения системы линейных алгебраических неравенств используем
2.5 Алгоритм обратного распространения ошибки
Для решения системы линейных алгебраических неравенств используем

2.5 Алгоритм обратного распространения ошибки
Здесь z1 – новая неотрицательная переменная. Подставим
2.5 Алгоритм обратного распространения ошибки
Здесь z1 – новая неотрицательная переменная. Подставим

2.5 Алгоритм обратного распространения ошибки
Выражаем a2:
В (5.6) z2 есть новая неотрицательная
2.5 Алгоритм обратного распространения ошибки
Выражаем a2:
В (5.6) z2 есть новая неотрицательная

2.5 Алгоритм обратного распространения ошибки
Осталась одна единственная невязка:
Подстановка (5.8) приводит к
2.5 Алгоритм обратного распространения ошибки
Осталась одна единственная невязка:
Подстановка (5.8) приводит к

2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
В основе генетических (эволюционных) алгоритмов лежит
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
В основе генетических (эволюционных) алгоритмов лежит

2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Сформируем начальную популяцию случайным образом
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Сформируем начальную популяцию случайным образом

2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Выберем элиту из 4 наилучших образцов,
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Выберем элиту из 4 наилучших образцов,
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Видим, что лишь один потомок дал
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Видим, что лишь один потомок дал
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Нам не удалось улучшить целевую функцию
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Нам не удалось улучшить целевую функцию

2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Таким образом, удалось улучшить функционал. Снова
2.6 ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ И РАСПОЗНАВАНИЕ ОБРАЗОВ
Таким образом, удалось улучшить функционал. Снова
 Интерактивная презентация
Интерактивная презентация SKP. Инструкция для АСЦ
SKP. Инструкция для АСЦ Розробка Web-сайту кафедри біомедичної інженерії
Розробка Web-сайту кафедри біомедичної інженерії Рекурсивті тәртіптерді анықтау және GNU. Prolog қолдану
Рекурсивті тәртіптерді анықтау және GNU. Prolog қолдану Обработка исключений
Обработка исключений Тема урока: Алфавитный подход к определению количества информации. Единицы измерения информации. 8 класс
Тема урока: Алфавитный подход к определению количества информации. Единицы измерения информации. 8 класс Дети и компьютер
Дети и компьютер Основные процессы жизненного цикла АИС
Основные процессы жизненного цикла АИС Оптические устройства в системах передачи информации
Оптические устройства в системах передачи информации Приложения MS Office 2023
Приложения MS Office 2023 Облікові регістри та їх класифікації
Облікові регістри та їх класифікації Лекция 6. Структура программы. Основные понятия языка. Система базовых типов. Операторы объявлений
Лекция 6. Структура программы. Основные понятия языка. Система базовых типов. Операторы объявлений Инструкция по регистрации на информационном портале ОЦКС и прохождение видеокурса Безопасность на стройках атомной отрасли
Инструкция по регистрации на информационном портале ОЦКС и прохождение видеокурса Безопасность на стройках атомной отрасли Графические возможности Паскаля. Цикл с параметром
Графические возможности Паскаля. Цикл с параметром Операционные системы и среды
Операционные системы и среды Информационное моделирование. Модели объектов и их назначение. Разнообразие информационных моделей. (6 класс)
Информационное моделирование. Модели объектов и их назначение. Разнообразие информационных моделей. (6 класс) Модели решения функциональных и вычислительных задач
Модели решения функциональных и вычислительных задач Операционная система Linux
Операционная система Linux Методы передачи дискретных данных, общие для локальных и глобальных сетей по длинным линиям связи ( >10 м)
Методы передачи дискретных данных, общие для локальных и глобальных сетей по длинным линиям связи ( >10 м) Корпоративный сайт Веб-студия Green Bay
Корпоративный сайт Веб-студия Green Bay Історія виникнення ПК
Історія виникнення ПК Внеклассное мероприятие Путешествие с Инфознайкой
Внеклассное мероприятие Путешествие с Инфознайкой Информационные модели на графах. Разработка урока с презентациями.
Информационные модели на графах. Разработка урока с презентациями. Большие данные
Большие данные Подача заявления на организацию временного трудоустройства несовершеннолетних граждан
Подача заявления на организацию временного трудоустройства несовершеннолетних граждан Операторы цикла. Цикл с предусловием
Операторы цикла. Цикл с предусловием Классификация информационных систем
Классификация информационных систем Информационное общество
Информационное общество