- Теория формальных языков и грамматик. (Глава 2)

Содержание
- 2. 2.1 ЯЗЫКИ И ЦЕПОЧКИ СИМВОЛОВ. СПОСОБЫ ЗАДАНИЯ ЯЗЫКОВ ГЛАВА 2. Основы теории формальных языков и грамматик
- 3. 2.1.1 Цепочки символов. Операции над ними Цепочкой (строкой) называется последовательность символов записанных один за одним. α
- 4. 2.1.1 Цепочки символов. Операции над ними Если из цепочки единичной длины |α|=1 удаляется этот единственный символ,
- 5. 2.1.1 Цепочки символов. Операции над ними Если α и β - цепочки, то цепочка αβ называется
- 6. 2.1.2 Формальное определение языка. Понятие языка Язык – это заданный набор символов и правил, устанавливающих способы
- 7. 2.1.2 Формальное определение языка. Понятие языка V* множество, содержащее все цепочки в алфавите V, включая пустую
- 8. 2.1.2 Формальное определение языка. Понятие языка Языком L над алфавитом V называют некоторое счетное подмножество цепочек
- 9. 2.1.2 Формальное определение языка. Понятие языка Язык L над алфавитом V включает в себя язык L’
- 10. 2.1.3 Способы задания языка перечисление всех допустимых цепочек языка с помощью указания способа порождения цепочек языка
- 11. 2.1.4 Синтаксис и семантика Лексема – это языковая конструкция, которая состоит из элементов алфавита языка и
- 12. 2.2 ОПРЕДЕЛЕНИЕ ГРАММАТИКИ ГЛАВА 2. Основы теории формальных языков и грамматик
- 13. 2.2.1 Понятие о грамматике языка Грамматика – описание способов построения предложений некоторого языка. Грамматика — один
- 14. 2.2.1 Понятие о грамматике языка Грамматики G1 и G2 называются эквивалентными, если L(G1) = L(G2). G1
- 15. 2.2.2 Формальное определение грамматики По определению Хомского формальная грамматика представляет собой четвёрку: G={VT, VN, P, S}
- 16. 2.2.2 Формальное определение грамматики Грамматика, определяющая целое число без знака: G={VT,VN,P,S} VN = {A,B} VТ =
- 17. 2.3 СПОСОБЫ ЗАПИСИ СИНТАКСИСА ЯЗЫКА ГЛАВА 2. Основы теории формальных языков и грамматик Метаязык - язык,
- 18. 2.3.1 Метаязык Хомского -> символ отделяет левую часть правила от правой (читается как "порождает" и "это
- 19. 2.3.1 Метаязык Хомского Описание идентификатора на метаязыке Хомского
- 20. 2.3.2 Бэкуса-Наура формы (БНФ) символ "::=" отделяет левую часть правила от правой; нетерминалы обозначаются произвольной символьной
- 21. 2.3.2 Бэкуса-Наура формы (БНФ) 1. ::= A | B| C …| Z| а| b| c| …|
- 22. 2.3.2 Бэкуса-Наура формы (БНФ) ::= ::= | ::= БЛАТНОЙ| КОНКРЕТНЫЙ ::= ПАЦАН| БРАТАН| СИЛА ::= |
- 23. 2.3.3 РБНФ (расширенная) [ ] – синтаксическая конструкция может отсутствовать; { } – повторение синтаксической конструкции
- 24. 2.3.3 РБНФ ::= A | B| C …| Z| а| b| c| …| z ::= 0|
- 25. 2.3.4 Диаграмма Вирта терминальный символ, принадлежащий алфавиту языка постоянная группа терминальных символов, определяющая название лексемы, ключевое
- 26. 2.3.4 Диаграмма Вирта Пример описания идентификатора с использованием диаграмм Вирта
- 27. 2.4 КЛАССИФИКАЦИЯ ЯЗЫКОВ И ГРАММАТИК ГЛАВА 2. Основы теории формальных языков и грамматик
- 28. 2.4.1 Классификация грамматик
- 29. 2.4.1 Классификация грамматик
- 30. 2.4.1 Классификация грамматик Эта иерархия грамматик – включающая. Грамматика 2 включает 3, но не наоборот. Любая
- 31. 2.4.2 Классификация языков Языки классифицируются в соответствие с типами грамматик с помощью которых они заданы. Поскольку
- 32. 2.4.2 Классификация языков Грамматика 0 G1 = ({0,1}, {A,S}, P1, S) и P1: S -> 0A1
- 33. 2.4.2 Классификация языков Сложность языка убывает с возрастанием классификационного типа языка. Тип 0. Язык с фразовой
- 34. 2.4.3 Примеры классификации языков и грамматик Язык типа 2: L(G3) = {(ac)n (cb)n | n >
- 35. 2.4.3 Примеры классификации языков и грамматик
- 36. 2.5 ЦЕПОЧКИ ВЫВОДА. СЕНТЕНЦИАЛЬНАЯ ФОРМА ГЛАВА 2. Основы теории формальных языков и грамматик
- 37. 2.5.1 Вывод. Цепочка вывода. Выводом называется процесс порождения предложений языка на основе правил, определяющих язык. Цепочка
- 38. 2.5.1 Вывод. Цепочка вывода. Цепочка β ∈ V* выводима из цепочки α ∈ V+ в грамматике
- 39. 2.5.1 Вывод. Цепочка вывода. Если цепочка вывода от α к β содержит одну и более промежуточных
- 40. 2.5.1 Вывод. Цепочка вывода. G=({A, S) {0, 1}, Р, S) P: S -> 0А1 0A ->
- 41. 2.5.2 Сентенциальная форма грамматики. Основа Вывод называется законченным, если на основе цепочки β, полученной в результате
- 42. 2.5.2 Сентенциальная форма грамматики. Основа Пусть G=(VN, VT, P, S) грамматика и цепочка w = γ1
- 43. 2.5.3 Левосторонний и правосторонний вывод Вывод цепочки β ∈ (VT)* из S ∈ VN в КС-грамматике
- 44. 2.5.3 Левосторонний и правосторонний вывод Например, для цепочки a+b+a в грамматике G = ({a,b,+}, {S,T}, {S
- 46. Скачать презентацию

2.1 ЯЗЫКИ И ЦЕПОЧКИ СИМВОЛОВ. СПОСОБЫ ЗАДАНИЯ ЯЗЫКОВ
ГЛАВА 2. Основы теории
2.1 ЯЗЫКИ И ЦЕПОЧКИ СИМВОЛОВ. СПОСОБЫ ЗАДАНИЯ ЯЗЫКОВ
ГЛАВА 2. Основы теории

2.1.1 Цепочки символов. Операции над ними
Цепочкой (строкой) называется последовательность символов записанных
2.1.1 Цепочки символов. Операции над ними
Цепочкой (строкой) называется последовательность символов записанных

2.1.1 Цепочки символов. Операции над ними
Если из цепочки единичной длины |α|=1
2.1.1 Цепочки символов. Операции над ними
Если из цепочки единичной длины |α|=1

2.1.1 Цепочки символов. Операции над ними
Если α и β - цепочки,
2.1.1 Цепочки символов. Операции над ними
Если α и β - цепочки,

2.1.2 Формальное определение языка. Понятие языка
Язык – это заданный набор символов
2.1.2 Формальное определение языка. Понятие языка
Язык – это заданный набор символов

2.1.2 Формальное определение языка. Понятие языка
V* множество, содержащее все цепочки в
2.1.2 Формальное определение языка. Понятие языка
V* множество, содержащее все цепочки в

2.1.2 Формальное определение языка. Понятие языка
Языком L над алфавитом V называют
2.1.2 Формальное определение языка. Понятие языка
Языком L над алфавитом V называют

2.1.2 Формальное определение языка. Понятие языка
Язык L над алфавитом V включает
2.1.2 Формальное определение языка. Понятие языка
Язык L над алфавитом V включает

2.1.3 Способы задания языка
перечисление всех допустимых цепочек языка
с помощью указания способа
2.1.3 Способы задания языка
перечисление всех допустимых цепочек языка
с помощью указания способа

2.1.4 Синтаксис и семантика
Лексема – это языковая конструкция, которая состоит из
2.1.4 Синтаксис и семантика
Лексема – это языковая конструкция, которая состоит из

2.2 ОПРЕДЕЛЕНИЕ ГРАММАТИКИ
ГЛАВА 2. Основы теории формальных языков и грамматик
2.2 ОПРЕДЕЛЕНИЕ ГРАММАТИКИ
ГЛАВА 2. Основы теории формальных языков и грамматик

2.2.1 Понятие о грамматике языка
Грамматика – описание способов построения предложений некоторого
2.2.1 Понятие о грамматике языка
Грамматика – описание способов построения предложений некоторого

2.2.1 Понятие о грамматике языка
Грамматики G1 и G2 называются эквивалентными, если
2.2.1 Понятие о грамматике языка
Грамматики G1 и G2 называются эквивалентными, если

2.2.2 Формальное определение грамматики
По определению Хомского формальная грамматика представляет собой четвёрку:
G={VT,
2.2.2 Формальное определение грамматики
По определению Хомского формальная грамматика представляет собой четвёрку:
G={VT,

2.2.2 Формальное определение грамматики
Грамматика, определяющая целое число без знака:
G={VT,VN,P,S}
VN
2.2.2 Формальное определение грамматики
Грамматика, определяющая целое число без знака:
G={VT,VN,P,S}
VN

2.3 СПОСОБЫ ЗАПИСИ СИНТАКСИСА ЯЗЫКА
ГЛАВА 2. Основы теории формальных языков и
2.3 СПОСОБЫ ЗАПИСИ СИНТАКСИСА ЯЗЫКА
ГЛАВА 2. Основы теории формальных языков и

2.3.1 Метаязык Хомского
-> символ отделяет левую часть правила от правой (читается
2.3.1 Метаязык Хомского
-> символ отделяет левую часть правила от правой (читается

2.3.1 Метаязык Хомского
Описание идентификатора на метаязыке Хомского
2.3.1 Метаязык Хомского
Описание идентификатора на метаязыке Хомского

2.3.2 Бэкуса-Наура формы (БНФ)
символ "::=" отделяет левую часть правила от правой;
нетерминалы
2.3.2 Бэкуса-Наура формы (БНФ)
символ "::=" отделяет левую часть правила от правой;
нетерминалы

2.3.2 Бэкуса-Наура формы (БНФ)
1. <буква> ::= A | B| C …|
2.3.2 Бэкуса-Наура формы (БНФ)
1. <буква> ::= A | B| C …|
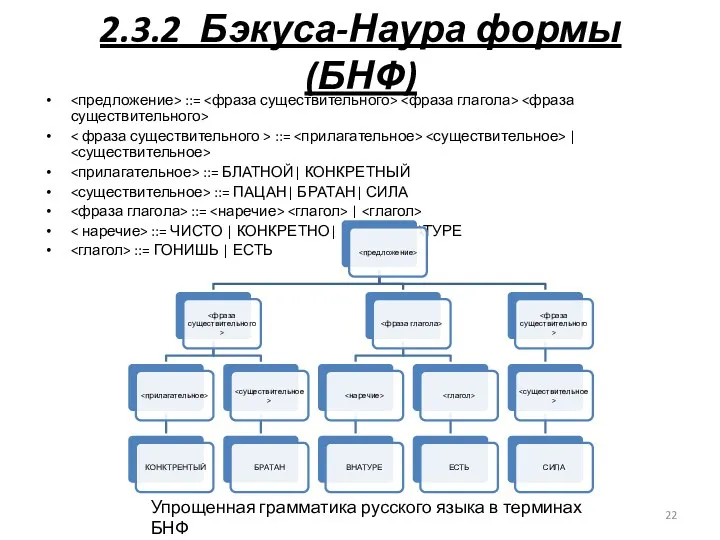
2.3.2 Бэкуса-Наура формы (БНФ)
<предложение> ::= <фраза существительного> <фраза глагола> <фраза существительного>
2.3.2 Бэкуса-Наура формы (БНФ)
<предложение> ::= <фраза существительного> <фраза глагола> <фраза существительного>
![2.3.3 РБНФ (расширенная) [ ] – синтаксическая конструкция может отсутствовать;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/392111/slide-22.jpg)
2.3.3 РБНФ (расширенная)
[ ] – синтаксическая конструкция может отсутствовать;
{ } –
2.3.3 РБНФ (расширенная)
[ ] – синтаксическая конструкция может отсутствовать;
{ } –

2.3.3 РБНФ
<буква> ::= A | B| C …| Z| а| b|
2.3.3 РБНФ
<буква> ::= A | B| C …| Z| а| b|

2.3.4 Диаграмма Вирта
терминальный символ, принадлежащий алфавиту языка
постоянная группа терминальных символов, определяющая
2.3.4 Диаграмма Вирта
терминальный символ, принадлежащий алфавиту языка
постоянная группа терминальных символов, определяющая
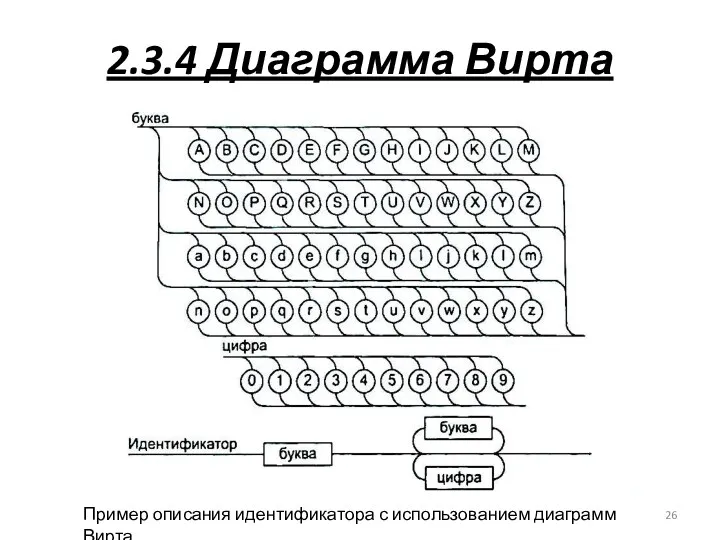
2.3.4 Диаграмма Вирта
Пример описания идентификатора с использованием диаграмм Вирта
2.3.4 Диаграмма Вирта
Пример описания идентификатора с использованием диаграмм Вирта

2.4 КЛАССИФИКАЦИЯ ЯЗЫКОВ И ГРАММАТИК
ГЛАВА 2. Основы теории формальных языков и
2.4 КЛАССИФИКАЦИЯ ЯЗЫКОВ И ГРАММАТИК
ГЛАВА 2. Основы теории формальных языков и

2.4.1 Классификация грамматик
2.4.1 Классификация грамматик

2.4.1 Классификация грамматик
2.4.1 Классификация грамматик

2.4.1 Классификация грамматик
Эта иерархия грамматик – включающая.
Грамматика 2 включает 3, но
2.4.1 Классификация грамматик
Эта иерархия грамматик – включающая.
Грамматика 2 включает 3, но

2.4.2 Классификация языков
Языки классифицируются в соответствие с типами грамматик с помощью
2.4.2 Классификация языков
Языки классифицируются в соответствие с типами грамматик с помощью

2.4.2 Классификация языков
Грамматика 0 G1 = ({0,1}, {A,S}, P1, S) и
P1: S
2.4.2 Классификация языков
Грамматика 0 G1 = ({0,1}, {A,S}, P1, S) и
P1: S

2.4.2 Классификация языков
Сложность языка убывает с возрастанием классификационного типа языка.
Тип 0.
2.4.2 Классификация языков
Сложность языка убывает с возрастанием классификационного типа языка.
Тип 0.

2.4.3 Примеры классификации языков и грамматик
Язык типа 2: L(G3) = {(ac)n
2.4.3 Примеры классификации языков и грамматик
Язык типа 2: L(G3) = {(ac)n

2.4.3 Примеры классификации языков и грамматик
2.4.3 Примеры классификации языков и грамматик

2.5 ЦЕПОЧКИ ВЫВОДА. СЕНТЕНЦИАЛЬНАЯ ФОРМА
ГЛАВА 2. Основы теории формальных языков и
2.5 ЦЕПОЧКИ ВЫВОДА. СЕНТЕНЦИАЛЬНАЯ ФОРМА
ГЛАВА 2. Основы теории формальных языков и

2.5.1 Вывод. Цепочка вывода.
Выводом называется процесс порождения предложений языка на основе
2.5.1 Вывод. Цепочка вывода.
Выводом называется процесс порождения предложений языка на основе

2.5.1 Вывод. Цепочка вывода.
Цепочка β ∈ V* выводима из цепочки α
2.5.1 Вывод. Цепочка вывода.
Цепочка β ∈ V* выводима из цепочки α

2.5.1 Вывод. Цепочка вывода.
Если цепочка вывода от α к β содержит
2.5.1 Вывод. Цепочка вывода.
Если цепочка вывода от α к β содержит

2.5.1 Вывод. Цепочка вывода.
G=({A, S) {0, 1}, Р, S)
P: S ->
2.5.1 Вывод. Цепочка вывода.
G=({A, S) {0, 1}, Р, S)
P: S ->

2.5.2 Сентенциальная форма грамматики. Основа
Вывод называется законченным, если на основе цепочки
2.5.2 Сентенциальная форма грамматики. Основа
Вывод называется законченным, если на основе цепочки

2.5.2 Сентенциальная форма грамматики. Основа
Пусть G=(VN, VT, P, S) грамматика и
2.5.2 Сентенциальная форма грамматики. Основа
Пусть G=(VN, VT, P, S) грамматика и

2.5.3 Левосторонний и правосторонний вывод
Вывод цепочки β ∈ (VT)* из S
2.5.3 Левосторонний и правосторонний вывод
Вывод цепочки β ∈ (VT)* из S

2.5.3 Левосторонний и правосторонний вывод
Например, для цепочки a+b+a в грамматике
G =
2.5.3 Левосторонний и правосторонний вывод
Например, для цепочки a+b+a в грамматике
G =
 Main features of CSS
Main features of CSS Компьютерные сети. Интернет
Компьютерные сети. Интернет Документ РосБизнесКонсалтинг. Использованы шаблоны MICROSOFT Corp. ©
Документ РосБизнесКонсалтинг. Использованы шаблоны MICROSOFT Corp. © Автоматизация в легкой промышленности
Автоматизация в легкой промышленности Задание на 10 марта 6 класс
Задание на 10 марта 6 класс Паттерн Репозиторий
Паттерн Репозиторий Кодирование информации. 5 класс
Кодирование информации. 5 класс Объекты ядра Windows
Объекты ядра Windows Основы построения инфокоммуникационных систем и сетей
Основы построения инфокоммуникационных систем и сетей Информационное моделирование
Информационное моделирование Разработка программного модуля проверки на столкновения в Navisworks Simulate
Разработка программного модуля проверки на столкновения в Navisworks Simulate Табличный процессор MS Excel 2007: формулы и функции
Табличный процессор MS Excel 2007: формулы и функции Бесплатный онлайн квест по автоматизации бизнеса в соцсетях
Бесплатный онлайн квест по автоматизации бизнеса в соцсетях Методы системного анализа. Лекция 2
Методы системного анализа. Лекция 2 Общественное объединение родителей Бумеранг добра
Общественное объединение родителей Бумеранг добра WORD-тын графикалык мумкіндіктері
WORD-тын графикалык мумкіндіктері Язык HTML. Начальные сведения
Язык HTML. Начальные сведения Настройка пользовательского интерфейса Microsoft Word. Лекция 7
Настройка пользовательского интерфейса Microsoft Word. Лекция 7 Технология программирования. Функции и структуры
Технология программирования. Функции и структуры Тезаурус курса Математика и информатика и ОИКТ
Тезаурус курса Математика и информатика и ОИКТ Объектно-ориентированное программирование
Объектно-ориентированное программирование Машинне навчання. Навчання з підкріпленням (частина 2)
Машинне навчання. Навчання з підкріпленням (частина 2) Знакомство с ТРИК Студией
Знакомство с ТРИК Студией Пользовательский интерфейс
Пользовательский интерфейс MAX mobile - users.pdf
MAX mobile - users.pdf SQL Server
SQL Server Информационные технологии в работе ДОУ
Информационные технологии в работе ДОУ Телеграмм-бот по игре Dota
Телеграмм-бот по игре Dota