- Типы данных АСДП

Содержание
- 2. Понятие типа данных и переменной Тип данных (англ. Data type) - характеристика, определяющая: множество допустимых значений,
- 3. Все типы в Python являются объектами (в отличие, например, от C++). Объект в Python - это
- 4. Классификация типов данных В Python встроенные типы данных подразделяются на 2 группы: 1. Скалярные (неделимые). Числа
- 5. Кроме того, все объекты в Python относятся к одной из 2-х категорий: 1. Мутирующие (англ. Mutable):
- 6. Оператор присваивания Для связывания (и при необходимости предварительного создания) объекта и переменной используется оператор присваивания =.
- 9. Инициализация переменной перед использованием Переменная должна быть проинициализирована (ссылаться на данные) перед использованием в выражении. Например,
- 10. Управление памятью и сборщик мусора Создание объекта любого типа подразумевает выделение памяти для размещения данных об
- 11. Время между созданием и уничтожением объекта - его жизненный цикл. Объекты, которые имеют на протяжении своего
- 12. Скалярные типы В Python существует 2 категории чисел: целые и вещественные. Целые числа в Python представлены
- 13. Для чисел с плавающей точкой существует ряд нюансов: в машинном представлении такие хранятся как двоичные числа.
- 14. Операции над числами Для арифметических операций тип результата операции определяется типом аргументов. Если тип результата явно
- 15. Скалярные типы Логический тип представлен типом bool и позволяет хранить 2 значения: True (Истина / Да
- 16. Коллекции Используя скалярные типы, можно столкнуться с проблемой - что делать, если необходимо хранить и обрабатывать
- 17. Среди коллекций выделяют 3 группы: последовательности: строка, список, кортеж, числовой диапазон; множества; отображения: словарь.
- 18. Последовательности Последовательность - это упорядоченная коллекция, поддерживающая индексированный доступ к элементам. Некоторые последовательности в Python в
- 19. Последовательности. Общие операции Некоторые операции справедливы для всех последовательностей (за исключением случаев, где они не возможны
- 20. Последовательности. Общие операции Длина len(s) Функция len() возвращает длину (количество элементов в последовательности) s. Конкатенация («склеивание»)
- 21. Последовательности. Общие операции Индексация и срезы Получить доступ к отдельному элементу или группе элементов последовательности возможно
- 22. Последовательности. Общие операции Минимальное и максимальное значения min(s) max(s) Возвращает минимальный и максимальный элементы последовательности s
- 23. Последовательности. Общие операции Количество повторений s.count(x) Возвращает количество вхождений элементов x в последовательность s. Сортировка sorted(s,
- 24. Последовательности. Строки Строка (str) - это упорядоченная неизменяемая последовательность символов Юникода. Литералы строк создаются с использованием
- 25. Последовательности. Строки. Операции над строковым типом
- 26. Последовательности. Строки. Операции над строковым типом
- 27. Последовательности. Строки. Индексация и срезы
- 28. Последовательности. Строки. Характерные операции Строки поддерживают все общие операции для последовательностей и имеют ряд дополнительных методов.
- 29. Последовательности. Строки. Характерные операции Пусть s - строка, на которой вызывается метод. upper() Возвращает копию строки
- 30. Последовательности. Строки. Характерные операции count(t[, start[, end]]) Возвращает число вхождений строки t в строку s (или
- 31. Использование строковых методов
- 32. Последовательности. Список Список (list) - это упорядоченная изменяемая последовательность элементов. Особенности: может содержать элементы разного типа;
- 33. Последовательности. Список. Характерные операции Списки поддерживают все общие операции для последовательностей, и имеют ряд дополнительных методов.
- 34. Последовательности. Список. Характерные операции remove(x) Удаляет из списка lst первый элемент со значением x. pop([i]) Возвращает
- 36. Последовательности. Кортеж Кортеж (tuple) - это упорядоченная неизменяемая последовательность элементов. Особенности: умеет все, что умеет список,
- 37. Последовательности. Кортеж Кортежи поддерживают все операции, общие для последовательностей.
- 38. Последовательности. Числовой диапазон Числовой диапазон (range) - это упорядоченная неизменяемая последовательность элементов - целых чисел. range(stop)
- 39. Создание числового диапазона Числовые диапазоны поддерживают те же операции, что и кортежи.
- 40. Множества Множество - это неупорядоченная коллекция уникальных элементов. В Python существует 2 класса для работы с
- 41. Множества Оба типа обладают различиями, схожими с различиями между списком и кортежем.
- 42. Множества. Общие операции Пусть st - множество, на котором вызывается метод. add(elem) Добавляем элемент elem в
- 43. Множества. Математические операции Множества поддерживают математические операции, характерные для множеств (пересечение, объединение и др.). Пусть st
- 44. Множества. Математические операции st Аналогично st issuperset(other) st >= other Возвращает True если все элементы other
- 45. Пример работы с множеством
- 46. Отображения Отображение - это неупорядоченная коллекция пар элементов «ключ-значение». В разных языках синонимом отображений являются термины
- 48. Словарь. Операции Пусть d - словарь, на котором вызывается метод. d[key] Возвращает значение словаря для ключа
- 49. Словарь. Операции items() Возвращает набор пар «ключ-значение» для словаря d. keys() Возвращает набор ключей для словаря
- 50. Словарь. Операции
- 51. Общие функции Все объекты независимо от типа поддерживают ряд общих функций. help([object]) Отображает справку для object.
- 52. Проверка типов Для того, чтобы проверить, какой тип имеет тот или иной объект можно воспользоваться функциями
- 53. Взаимное преобразование Все типы поддерживают взаимное преобразование (где оно имеет смысл, например, преобразование списка в кортеж,
- 55. Приоритет операций Операции над объектами выполняются в определенном порядке: Изменение порядка можно производить за счет использования
- 56. Поверхностное и глубокое копирование Оператор присваивания копирует ссылку на объект, создавая т.н. поверхностную копию. В ряде
- 58. Константы В Python не существует привычного для, например, Си или Паскаля понятия константы. Вместо этого, значение,
- 60. Скачать презентацию

Понятие типа данных и переменной
Тип данных (англ. Data type) - характеристика,
Понятие типа данных и переменной
Тип данных (англ. Data type) - характеристика,

Все типы в Python являются объектами (в отличие, например, от C++).
Все типы в Python являются объектами (в отличие, например, от C++).

Классификация типов данных
В Python встроенные типы данных подразделяются на 2 группы:
1.
Классификация типов данных
В Python встроенные типы данных подразделяются на 2 группы:
1.

Кроме того, все объекты в Python относятся к одной из 2-х
Кроме того, все объекты в Python относятся к одной из 2-х

Оператор присваивания
Для связывания (и при необходимости предварительного создания) объекта и переменной
Оператор присваивания
Для связывания (и при необходимости предварительного создания) объекта и переменной



Инициализация переменной перед использованием
Переменная должна быть проинициализирована (ссылаться на данные) перед
Инициализация переменной перед использованием
Переменная должна быть проинициализирована (ссылаться на данные) перед

Управление памятью и сборщик мусора
Создание объекта любого типа подразумевает выделение памяти
Управление памятью и сборщик мусора
Создание объекта любого типа подразумевает выделение памяти

Время между созданием и уничтожением объекта - его жизненный цикл.
Объекты, которые
Время между созданием и уничтожением объекта - его жизненный цикл.
Объекты, которые

Скалярные типы
В Python существует 2 категории чисел: целые и вещественные.
Целые числа
Скалярные типы
В Python существует 2 категории чисел: целые и вещественные.
Целые числа

Для чисел с плавающей точкой существует ряд нюансов:
в машинном представлении такие
Для чисел с плавающей точкой существует ряд нюансов:
в машинном представлении такие

Операции над числами
Для арифметических операций тип результата операции определяется типом аргументов.
Операции над числами
Для арифметических операций тип результата операции определяется типом аргументов.

Скалярные типы
Логический тип представлен типом bool и позволяет хранить 2 значения:
True
Скалярные типы
Логический тип представлен типом bool и позволяет хранить 2 значения:
True

Коллекции
Используя скалярные типы, можно столкнуться с проблемой - что делать, если
Коллекции
Используя скалярные типы, можно столкнуться с проблемой - что делать, если

Среди коллекций выделяют 3 группы:
последовательности: строка, список, кортеж, числовой диапазон;
множества;
отображения: словарь.
Среди коллекций выделяют 3 группы:
последовательности: строка, список, кортеж, числовой диапазон;
множества;
отображения: словарь.

Последовательности
Последовательность - это упорядоченная коллекция, поддерживающая индексированный доступ к элементам.
Некоторые последовательности
Последовательности
Последовательность - это упорядоченная коллекция, поддерживающая индексированный доступ к элементам.
Некоторые последовательности

Последовательности. Общие операции
Некоторые операции справедливы для всех последовательностей (за исключением случаев,
Последовательности. Общие операции
Некоторые операции справедливы для всех последовательностей (за исключением случаев,

Последовательности. Общие операции
Длина
len(s)
Функция len() возвращает длину (количество элементов в последовательности) s.
Конкатенация
Последовательности. Общие операции
Длина
len(s)
Функция len() возвращает длину (количество элементов в последовательности) s.
Конкатенация

Последовательности. Общие операции
Индексация и срезы
Получить доступ к отдельному элементу или группе
Последовательности. Общие операции
Индексация и срезы
Получить доступ к отдельному элементу или группе

Последовательности. Общие операции
Минимальное и максимальное значения
min(s)
max(s)
Возвращает минимальный и максимальный элементы последовательности
Последовательности. Общие операции
Минимальное и максимальное значения
min(s)
max(s)
Возвращает минимальный и максимальный элементы последовательности

Последовательности. Общие операции
Количество повторений
s.count(x)
Возвращает количество вхождений элементов x в последовательность s.
Сортировка
sorted(s,
Последовательности. Общие операции
Количество повторений
s.count(x)
Возвращает количество вхождений элементов x в последовательность s.
Сортировка
sorted(s,
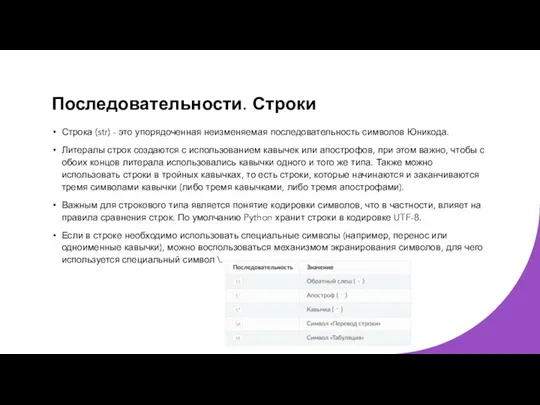
Последовательности. Строки
Строка (str) - это упорядоченная неизменяемая последовательность символов Юникода.
Литералы строк
Последовательности. Строки
Строка (str) - это упорядоченная неизменяемая последовательность символов Юникода.
Литералы строк

Последовательности. Строки. Операции над строковым типом
Последовательности. Строки. Операции над строковым типом

Последовательности. Строки. Операции над строковым типом
Последовательности. Строки. Операции над строковым типом
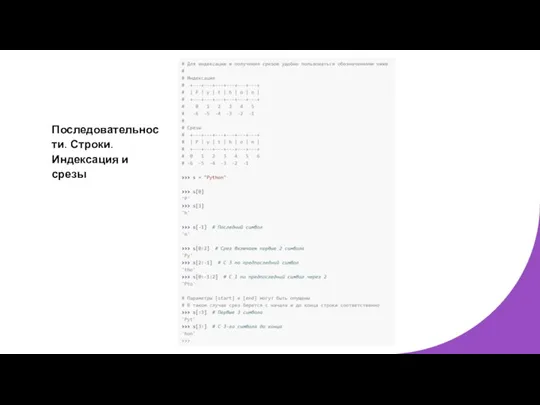
Последовательности. Строки. Индексация и срезы
Последовательности. Строки. Индексация и срезы

Последовательности. Строки. Характерные операции
Строки поддерживают все общие операции для последовательностей и
Последовательности. Строки. Характерные операции
Строки поддерживают все общие операции для последовательностей и

Последовательности. Строки. Характерные операции
Пусть s - строка, на которой вызывается метод.
upper()
Возвращает
Последовательности. Строки. Характерные операции
Пусть s - строка, на которой вызывается метод.
upper()
Возвращает
![Последовательности. Строки. Характерные операции count(t[, start[, end]]) Возвращает число вхождений](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/608509/slide-29.jpg)
Последовательности. Строки. Характерные операции
count(t[, start[, end]])
Возвращает число вхождений строки t в
Последовательности. Строки. Характерные операции
count(t[, start[, end]])
Возвращает число вхождений строки t в

Использование строковых методов
Использование строковых методов

Последовательности. Список
Список (list) - это упорядоченная изменяемая последовательность элементов.
Особенности:
может содержать элементы
Последовательности. Список
Список (list) - это упорядоченная изменяемая последовательность элементов.
Особенности:
может содержать элементы

Последовательности. Список. Характерные операции
Списки поддерживают все общие операции для последовательностей, и
Последовательности. Список. Характерные операции
Списки поддерживают все общие операции для последовательностей, и

Последовательности. Список. Характерные операции
remove(x)
Удаляет из списка lst первый элемент со значением
Последовательности. Список. Характерные операции
remove(x)
Удаляет из списка lst первый элемент со значением


Последовательности. Кортеж
Кортеж (tuple) - это упорядоченная неизменяемая последовательность элементов.
Особенности: умеет
Последовательности. Кортеж
Кортеж (tuple) - это упорядоченная неизменяемая последовательность элементов.
Особенности: умеет

Последовательности. Кортеж
Кортежи поддерживают все операции, общие для последовательностей.
Последовательности. Кортеж
Кортежи поддерживают все операции, общие для последовательностей.

Последовательности. Числовой диапазон
Числовой диапазон (range) - это упорядоченная неизменяемая последовательность элементов
Последовательности. Числовой диапазон
Числовой диапазон (range) - это упорядоченная неизменяемая последовательность элементов
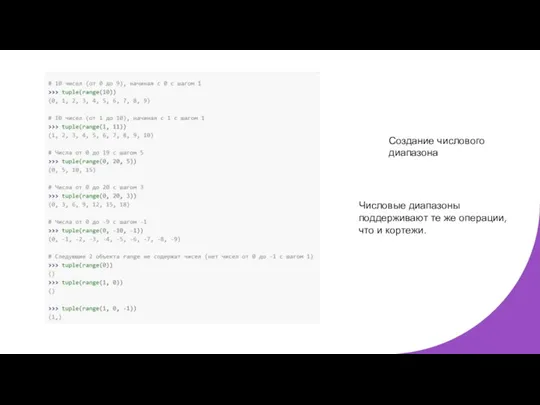
Создание числового диапазона
Числовые диапазоны поддерживают те же операции, что и кортежи.
Создание числового диапазона
Числовые диапазоны поддерживают те же операции, что и кортежи.

Множества
Множество - это неупорядоченная коллекция уникальных элементов.
В Python существует 2 класса
Множества
Множество - это неупорядоченная коллекция уникальных элементов.
В Python существует 2 класса

Множества
Оба типа обладают различиями, схожими с различиями между списком и кортежем.
Множества
Оба типа обладают различиями, схожими с различиями между списком и кортежем.

Множества. Общие операции
Пусть st - множество, на котором вызывается метод.
add(elem)
Добавляем элемент
Множества. Общие операции
Пусть st - множество, на котором вызывается метод.
add(elem)
Добавляем элемент

Множества. Математические операции
Множества поддерживают математические операции, характерные для множеств (пересечение, объединение
Множества. Математические операции
Множества поддерживают математические операции, характерные для множеств (пересечение, объединение

Множества. Математические операции
st < other
Аналогично st <= other, но множества не
Множества. Математические операции
st < other
Аналогично st <= other, но множества не

Пример работы с множеством
Пример работы с множеством

Отображения
Отображение - это неупорядоченная коллекция пар элементов «ключ-значение». В разных
Отображения
Отображение - это неупорядоченная коллекция пар элементов «ключ-значение». В разных


Словарь. Операции
Пусть d - словарь, на котором вызывается метод.
d[key]
Возвращает значение словаря
Словарь. Операции
Пусть d - словарь, на котором вызывается метод.
d[key]
Возвращает значение словаря

Словарь. Операции
items()
Возвращает набор пар «ключ-значение» для словаря d.
keys()
Возвращает набор ключей для
Словарь. Операции
items()
Возвращает набор пар «ключ-значение» для словаря d.
keys()
Возвращает набор ключей для

Словарь. Операции
Словарь. Операции

Общие функции
Все объекты независимо от типа поддерживают ряд общих функций.
help([object])
Отображает справку
Общие функции
Все объекты независимо от типа поддерживают ряд общих функций.
help([object])
Отображает справку

Проверка типов
Для того, чтобы проверить, какой тип имеет тот или иной
Проверка типов
Для того, чтобы проверить, какой тип имеет тот или иной

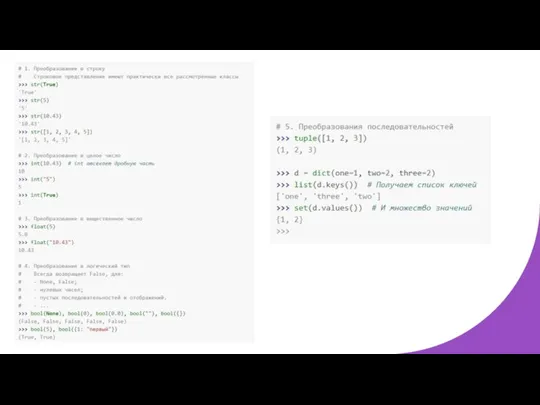
Взаимное преобразование
Все типы поддерживают взаимное преобразование (где оно имеет смысл, например,
Взаимное преобразование
Все типы поддерживают взаимное преобразование (где оно имеет смысл, например,

Приоритет операций
Операции над объектами выполняются в определенном порядке:
Изменение порядка можно производить
Приоритет операций
Операции над объектами выполняются в определенном порядке:
Изменение порядка можно производить

Поверхностное и глубокое копирование
Оператор присваивания копирует ссылку на объект, создавая т.н.
Поверхностное и глубокое копирование
Оператор присваивания копирует ссылку на объект, создавая т.н.
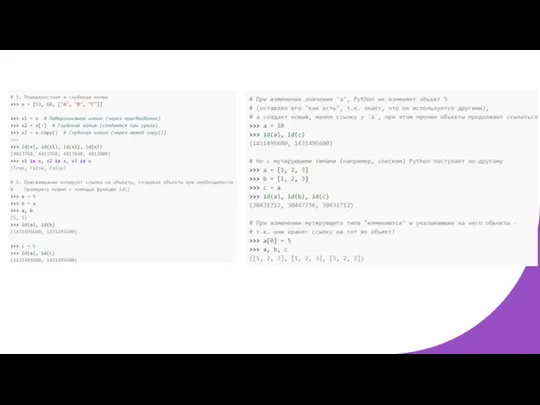

Константы
В Python не существует привычного для, например, Си или Паскаля понятия
Константы
В Python не существует привычного для, например, Си или Паскаля понятия
 Графические планшеты как инструмент развития детского творчества
Графические планшеты как инструмент развития детского творчества Алгоритмизация и программирование. Лекция 1
Алгоритмизация и программирование. Лекция 1 Парадигмы и методологии программирования
Парадигмы и методологии программирования Представление информации в форме таблиц. Структура таблицы
Представление информации в форме таблиц. Структура таблицы Защита компьютера от вредоносных программ
Защита компьютера от вредоносных программ Создание презентаций в Microsoft Power Point
Создание презентаций в Microsoft Power Point Information and communications technology
Information and communications technology Этапы разработки программного обеспечения
Этапы разработки программного обеспечения Организация документооборота. Информационно-поисковые справочники
Организация документооборота. Информационно-поисковые справочники Класифікація та загальна характеристика програмного забезпечення
Класифікація та загальна характеристика програмного забезпечення Региональный сегмент единой государственной информационной системы в сфере здравоохранении
Региональный сегмент единой государственной информационной системы в сфере здравоохранении Системы искусственного интеллекта
Системы искусственного интеллекта Microsoft Excel. Использование встроенных функций. Формулы, их копирование, расчеты
Microsoft Excel. Использование встроенных функций. Формулы, их копирование, расчеты Основы информационных систем. Основные понятия
Основы информационных систем. Основные понятия Юридическое программирование / Искусственный интеллект
Юридическое программирование / Искусственный интеллект Язык программирования Паскаль. Начала программирования
Язык программирования Паскаль. Начала программирования Внедрение новых технологий Digital Art. Государственная программа Цифровой Казахстан
Внедрение новых технологий Digital Art. Государственная программа Цифровой Казахстан Объектно-ориентированное программирование на С++
Объектно-ориентированное программирование на С++ Виды носителей информации
Виды носителей информации Introduction to computer systems. Architecture of computer systems. Lecture2
Introduction to computer systems. Architecture of computer systems. Lecture2 Информационные ресурсы архивов Прикамья
Информационные ресурсы архивов Прикамья Програмування пристрою для контролю температури на базі мікроконтролера RISC-архітектури
Програмування пристрою для контролю температури на базі мікроконтролера RISC-архітектури Информационные системы, как средство реализации информационных технологий. Стандарты. Понятие архитектуры. (Лекция 7)
Информационные системы, как средство реализации информационных технологий. Стандарты. Понятие архитектуры. (Лекция 7) Команда FevDay. Создание приложения на мобильное устройство
Команда FevDay. Создание приложения на мобильное устройство Авторское право, преподаватель и Интернет
Авторское право, преподаватель и Интернет Табличный процессор MS EXCEL
Табличный процессор MS EXCEL Зачем люди кодируют информацию?
Зачем люди кодируют информацию? Обновлённый личный кабинет родителя для Школ_removed (1) (1)
Обновлённый личный кабинет родителя для Школ_removed (1) (1)