- Транзакции и параллелизм. SQL и многопользовательский режим работы (часть 2)

Содержание
- 2. Транзакция (transection) – это группа операторов SQL, выполняемых, как единое целое. Параллелизм (concurrency) относится к механизмам,
- 3. Фиксация вносимых изменений Среду базы данных легко представить в виде множества пользователей, постоянно вводящих и изменяющих
- 4. Фиксация вносимых изменений Оператор SQL, влияющий на обновления (например на оператор обновления или на DROP TABLE),
- 5. Транзакция – это последовательность операторов SQL, которая принимается или отменяется, как единое целое. Инициируя сеанс работы
- 6. Чтобы сделать постоянными все изменения с момента входа или последнего изменения Commit и Rollback, используется следующий
- 7. Во многих реализациях предусмотрен специальный параметр AUTOCOMMIT или SET AUTOCOMMIT ON Что бы вернутся к обычной
- 8. При аварийном завершении сеанса пользователя – например, когда система дает сбой или пользователь перезагружает компьютер –
- 9. Транзакции, которые включают целую группу несвязанных операторов позволяют только сохранить или отменить всю группу. Как группу,
- 10. Предположим, что нам нужно удалить из базы данных продавца по имени Иванов. Прежде чем удалить ее
- 11. UPDATE Orders SET snum = NULL WHERE snum = 1004; UPDATE Customers SET snum WHERE snum
- 12. Следовательно, приведенную группу операторов можно рассматривать как одну транзакцию. Можно предварить эту группу операторов COMMIT или
- 13. SQL и многопользовательский режим работы Обычно SQL используется в многопользовательской среде, где в одно и то
- 14. Предположим, что вы применяете к таблице продавцы следующий оператор: UPDATE Salespeople SET comm = comm *
- 15. Будут ли отражать средние значения, полученные последним пользователем, те изменения, которые вносились в таблицу ранее? Это
- 16. Допустим, что вы нашли ошибку и выполняете откат изменений после того как последний пользователь получил свои
- 17. Типовые проблемы параллелизма Одновременная обработка транзакций называется параллелизмом (concurrency) и здесь могут возникать следующий проблемы. Обновления
- 18. Изменения в БД могут отменяться уже после их использования, как в приведенном выше примере, когда вы
- 19. Например: Аудитор должен иметь возможность вернуться назад и опередить, что средние значения существовали в некоторый момент
- 20. Пример: Два пользователя одновременно пытаются изменить значения внешнего ключа и значение его родительского ключа.
- 21. Стандартные термины для проблем параллелизма Потерянное обновление (LOST UPDATE) Преждевременное чтение (DIRTY READ) Неповторяющееся чтение (NON-REPETEABLE
- 22. Потерянное обновление
- 23. По завершению этой последовательности операторов значение comm = . 14 Обновление до . 10 не имело
- 24. Преждевременное чтение
- 25. Запрос к транзакции №2 выводит значение, которое уже исчезло из БД. Отмена транзакции №1 эквивалентна тому,
- 26. Неповторяющиеся чтение
- 27. В транзакции №2 были получены два разных ответа на один вопрос, данные действительно изменились, но иногда
- 28. Фантомная вставка
- 29. Поскольку в середине транзакции №2 выполняется оператор ISERT из транзакции №1 результаты одинаковых запросов будут отличатся.
- 30. Решение проблем параллелизма SQL обеспечивает управление параллелизмом CUNCURRENCY CONTROL В первоначальном стандарте SQL говорилось, что одновременное
- 31. В любой момент времени лишь одна транзакция будет иметь возможность изменять данные (хотя их чтение возможно
- 32. Все блокировки делятся на две общие категории: Пессимистические блокировки (pessimistic locks) Прекращают доступ к данным для
- 33. Использование пессимистического блокирования При пессимистическом блокировании некоторые типы одновременного доступа к данным запрещены. Первая операция, которая
- 34. Уровни изоляции Для поддержки блокировок определены уровни изоляции (ISOLATION LEVELS), определяющие какие типы конфликтов допустимы. В
- 36. Уровень SERIALIZABLE (последовательное выполнение), устанавливается по умолчанию и обеспечивает максимальную степень контроля. В последовательном режиме каждая
- 37. Уровень REPEATABLE READ (повторяющееся чтение) допускает из всех возможных видов неповторяющегося чтения только фантомные вставки. Этот
- 38. Уровень READ COMMITED (чтение с фиксацией) допускает неоднократное выполнение одного и того же запроса с разными
- 39. Уровень READ UNCOMMITED (чтение без фиксаций) допускает не однократное выполнение одного и того же запроса с
- 40. Разделяемы и исключительные блокировки Для обеспечения всех уровней изоляции используются блокировки двух логических типов: разделяемые и
- 41. Исключительные блокировки (EXCLUSIVE LOCKS) или Х-блокировки (X-LOCKS), позволяют иметь доступ к данным только владельцу блокировки. Исключительные
- 43. Скачать презентацию

Транзакция (transection) – это группа операторов SQL, выполняемых, как единое целое.
Параллелизм
Транзакция (transection) – это группа операторов SQL, выполняемых, как единое целое.
Параллелизм

Фиксация вносимых изменений
Среду базы данных легко представить в виде множества пользователей,
Фиксация вносимых изменений
Среду базы данных легко представить в виде множества пользователей,

Фиксация вносимых изменений
Оператор SQL, влияющий на обновления (например на оператор обновления
Фиксация вносимых изменений
Оператор SQL, влияющий на обновления (например на оператор обновления

Транзакция – это последовательность операторов SQL, которая принимается или отменяется, как
Транзакция – это последовательность операторов SQL, которая принимается или отменяется, как

Чтобы сделать постоянными все изменения с момента входа или последнего изменения
Чтобы сделать постоянными все изменения с момента входа или последнего изменения

Во многих реализациях предусмотрен специальный параметр AUTOCOMMIT или SET AUTOCOMMIT ON
Что
Во многих реализациях предусмотрен специальный параметр AUTOCOMMIT или SET AUTOCOMMIT ON
Что

При аварийном завершении сеанса пользователя – например, когда система дает сбой
При аварийном завершении сеанса пользователя – например, когда система дает сбой

Транзакции, которые включают целую группу несвязанных операторов позволяют только сохранить или
Транзакции, которые включают целую группу несвязанных операторов позволяют только сохранить или

Предположим, что нам нужно удалить из базы данных продавца по имени
Предположим, что нам нужно удалить из базы данных продавца по имени

UPDATE Orders
SET snum = NULL
WHERE snum = 1004;
UPDATE Customers
UPDATE Orders
SET snum = NULL
WHERE snum = 1004;
UPDATE Customers

Следовательно, приведенную группу операторов можно рассматривать как одну транзакцию.
Можно предварить эту
Следовательно, приведенную группу операторов можно рассматривать как одну транзакцию.
Можно предварить эту

SQL и многопользовательский режим работы
Обычно SQL используется в многопользовательской среде, где
SQL и многопользовательский режим работы
Обычно SQL используется в многопользовательской среде, где

Предположим, что вы применяете к таблице продавцы следующий оператор:
UPDATE Salespeople
Предположим, что вы применяете к таблице продавцы следующий оператор:
UPDATE Salespeople

Будут ли отражать средние значения, полученные последним пользователем, те изменения, которые
Будут ли отражать средние значения, полученные последним пользователем, те изменения, которые

Допустим, что вы нашли ошибку и выполняете откат изменений после того
Допустим, что вы нашли ошибку и выполняете откат изменений после того

Типовые проблемы параллелизма
Одновременная обработка транзакций называется параллелизмом (concurrency) и здесь
Типовые проблемы параллелизма
Одновременная обработка транзакций называется параллелизмом (concurrency) и здесь

Изменения в БД могут отменяться уже после их использования, как в
Изменения в БД могут отменяться уже после их использования, как в

Например:
Аудитор должен иметь возможность вернуться назад и опередить, что средние значения
Например:
Аудитор должен иметь возможность вернуться назад и опередить, что средние значения

Пример:
Два пользователя одновременно пытаются изменить значения внешнего ключа и значение его
Пример:
Два пользователя одновременно пытаются изменить значения внешнего ключа и значение его

Стандартные термины для проблем параллелизма
Потерянное обновление (LOST UPDATE)
Преждевременное чтение (DIRTY
Стандартные термины для проблем параллелизма
Потерянное обновление (LOST UPDATE)
Преждевременное чтение (DIRTY
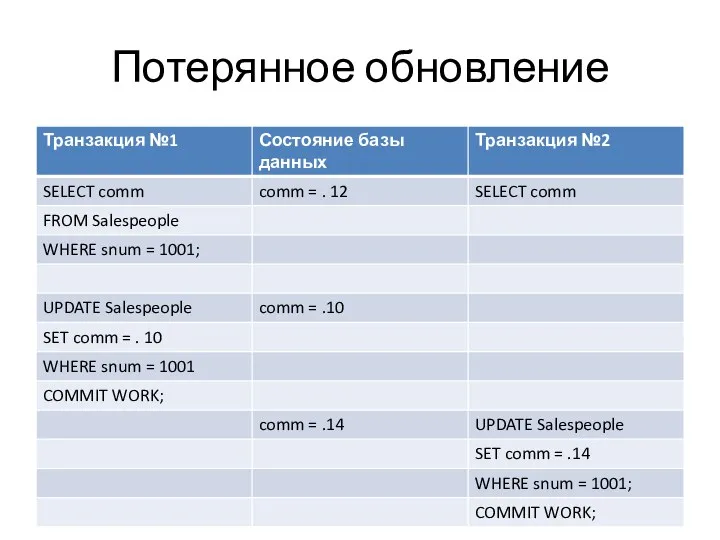
Потерянное обновление
Потерянное обновление

По завершению этой последовательности операторов значение comm = . 14
Обновление до
По завершению этой последовательности операторов значение comm = . 14
Обновление до
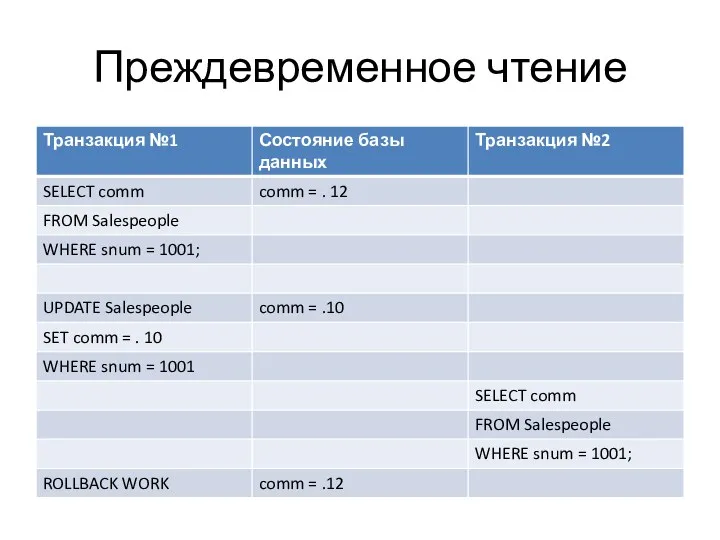
Преждевременное чтение
Преждевременное чтение

Запрос к транзакции №2 выводит значение, которое уже исчезло из БД.
Запрос к транзакции №2 выводит значение, которое уже исчезло из БД.
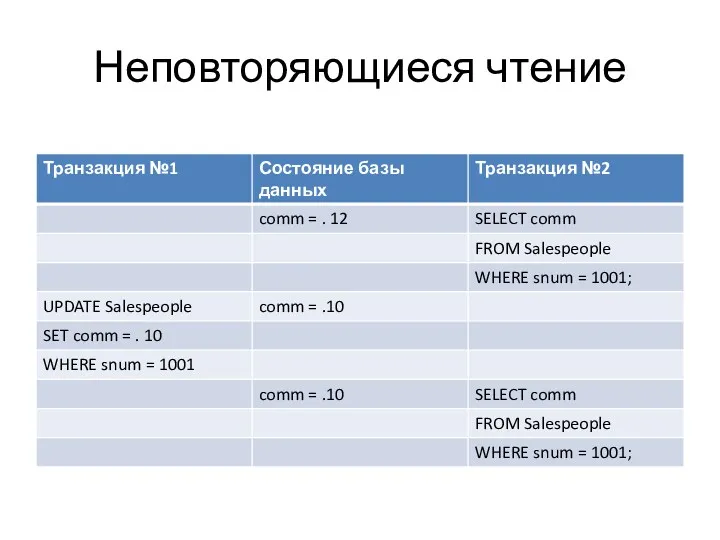
Неповторяющиеся чтение
Неповторяющиеся чтение

В транзакции №2 были получены два разных ответа на один вопрос,
В транзакции №2 были получены два разных ответа на один вопрос,
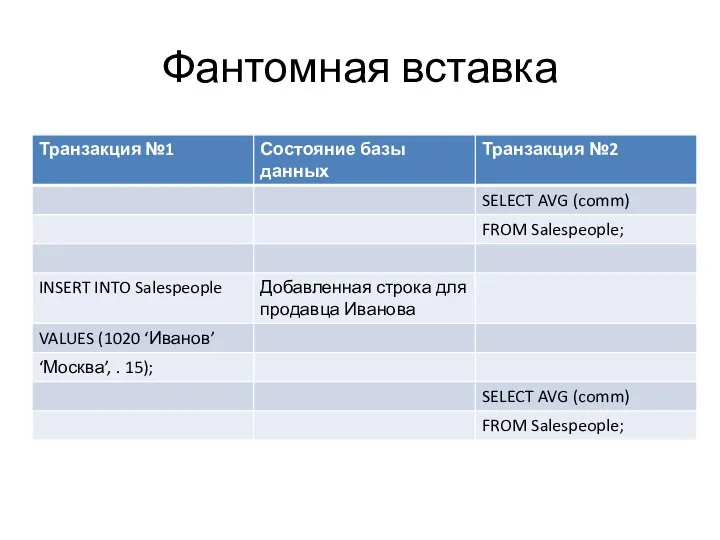
Фантомная вставка
Фантомная вставка

Поскольку в середине транзакции №2 выполняется оператор ISERT из транзакции №1
Поскольку в середине транзакции №2 выполняется оператор ISERT из транзакции №1

Решение проблем параллелизма
SQL обеспечивает управление параллелизмом CUNCURRENCY CONTROL
В первоначальном стандарте SQL
Решение проблем параллелизма
SQL обеспечивает управление параллелизмом CUNCURRENCY CONTROL
В первоначальном стандарте SQL

В любой момент времени лишь одна транзакция будет иметь возможность изменять
В любой момент времени лишь одна транзакция будет иметь возможность изменять

Все блокировки делятся на две общие категории:
Пессимистические блокировки (pessimistic locks)
Прекращают доступ
Все блокировки делятся на две общие категории:
Пессимистические блокировки (pessimistic locks)
Прекращают доступ

Использование пессимистического блокирования
При пессимистическом блокировании некоторые типы одновременного доступа к данным
Использование пессимистического блокирования
При пессимистическом блокировании некоторые типы одновременного доступа к данным

Уровни изоляции
Для поддержки блокировок определены уровни изоляции (ISOLATION LEVELS), определяющие какие
Уровни изоляции
Для поддержки блокировок определены уровни изоляции (ISOLATION LEVELS), определяющие какие
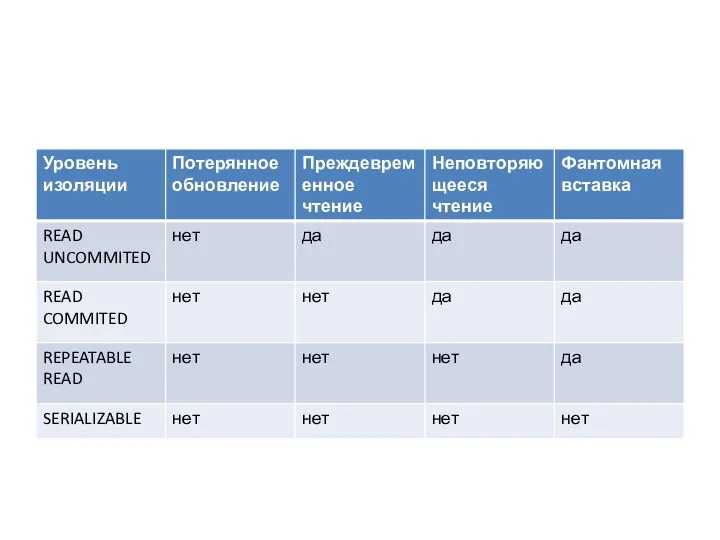

Уровень SERIALIZABLE (последовательное выполнение), устанавливается по умолчанию и обеспечивает максимальную степень
Уровень SERIALIZABLE (последовательное выполнение), устанавливается по умолчанию и обеспечивает максимальную степень

Уровень REPEATABLE READ (повторяющееся чтение) допускает из всех возможных видов неповторяющегося
Уровень REPEATABLE READ (повторяющееся чтение) допускает из всех возможных видов неповторяющегося

Уровень READ COMMITED (чтение с фиксацией) допускает неоднократное выполнение одного и
Уровень READ COMMITED (чтение с фиксацией) допускает неоднократное выполнение одного и

Уровень READ UNCOMMITED (чтение без фиксаций) допускает не однократное выполнение одного
Уровень READ UNCOMMITED (чтение без фиксаций) допускает не однократное выполнение одного

Разделяемы и исключительные блокировки
Для обеспечения всех уровней изоляции используются блокировки двух
Разделяемы и исключительные блокировки
Для обеспечения всех уровней изоляции используются блокировки двух

Исключительные блокировки (EXCLUSIVE LOCKS) или Х-блокировки (X-LOCKS), позволяют иметь доступ к
Исключительные блокировки (EXCLUSIVE LOCKS) или Х-блокировки (X-LOCKS), позволяют иметь доступ к
 Internet principles of operation
Internet principles of operation Первый канал
Первый канал Новая научная литература в читальном зале
Новая научная литература в читальном зале Programming in the Integrated Environments. Programming in the Scilab system
Programming in the Integrated Environments. Programming in the Scilab system Научно-исследовательская работа на тему: Разработка мобильного приложения Anamnesis
Научно-исследовательская работа на тему: Разработка мобильного приложения Anamnesis Оформление научной работы
Оформление научной работы Развитие творческой активности обучающихся 6 класса на уроках математики средствами ИКТ
Развитие творческой активности обучающихся 6 класса на уроках математики средствами ИКТ Работа с графиками функций в Еxcel: проект Ракета Диск
Работа с графиками функций в Еxcel: проект Ракета Диск Основные понятия объектно-ориентированного программирования. Классы, объекты, методы, свойства
Основные понятия объектно-ориентированного программирования. Классы, объекты, методы, свойства Временное трудоустройство несовершеннолетних граждан в возрасте от 14 до 18 лет в свободное от учёбы время
Временное трудоустройство несовершеннолетних граждан в возрасте от 14 до 18 лет в свободное от учёбы время Руководство по размещению тестовых заданий в компьютерной программе
Руководство по размещению тестовых заданий в компьютерной программе Автоматическая обработка информации
Автоматическая обработка информации Графики и диаграммы
Графики и диаграммы Следуя командам
Следуя командам Architecture of computer systems
Architecture of computer systems Вставка формул в документ. Редактор формул Equation 3.0
Вставка формул в документ. Редактор формул Equation 3.0 Adobe Photoshop
Adobe Photoshop Автоматизированное рабочее место (АРМ) специалиста
Автоматизированное рабочее место (АРМ) специалиста Урок информатики, 10 класс Технология создания презентации (гиперссылки и управляющие кнопки)
Урок информатики, 10 класс Технология создания презентации (гиперссылки и управляющие кнопки) Вероятностный подход к изучению информации материалы к уроку
Вероятностный подход к изучению информации материалы к уроку Информационно-поисковая система
Информационно-поисковая система СМИ, которые я предпочитаю
СМИ, которые я предпочитаю Табличный процессор Excel. Электронные таблицы
Табличный процессор Excel. Электронные таблицы Анимация. Создать черепашку
Анимация. Создать черепашку Основы компьютерной графики
Основы компьютерной графики Analysis and Design of Data Systems. Complex SQL Queries (Lecture 13)
Analysis and Design of Data Systems. Complex SQL Queries (Lecture 13) Клавиатура. Монитор
Клавиатура. Монитор