- Цифровая схемотехника и архитектура компьютера. Микроархитектура. (Глава 7)

Содержание
- 2. Цифровая схемотехника и архитектура компьютера Эти слайды предназначены для преподавателей, которые читают лекции на основе учебника
- 3. Благодарности Перевод данных слайдов на русский язык был выполнен командой сотрудников университетов и компаний из России,
- 4. Глава 7 :: Темы Введение Анализ производительности Однотактный процессор Многотактный процессор Конвейерный процессор Исключения Улучшение микроархитектуры
- 5. Микроархитектура: аппаратная реализация архитектуры в виде схемы Процессор: Тракт данных: функциональные блоки обработки и передачи данных
- 6. Несколько аппаратных реализаций одной и той же архитектуры: Однотактная реализация: каждая инструкция выполняется за один такт
- 7. Время выполнения программы Execution Time = (#instructions)(cycles/instruction)(seconds/cycle) Время выполнения = (#инструкции)(такты/инструкция)(секунды/такт) Определения: CPI: Количество тактов на
- 8. Будем рассматривать подмножество инструкций MIPS: Инструкции R-типа: and, or, add, sub, slt Инструкции работы с памятью:
- 9. Определяется: Содержимым счетчика команд (PC) Содержимым 32-х регистров общего назначения Содержимым памяти Архитектурное состояние
- 10. Элементы, хранящие состояние MIPS
- 11. Тракт данных Устройство управления Однотактный MIPS процессор
- 12. Шаг 1: Выборка (считывание) инструкции lw из памяти Однотактный тракт данных: выборка lw
- 13. Шаг 2: считывание операндов-источников из регистрового файла Однотактный тракт данных: чтение регистров lw rt, imm(rs)
- 14. Шаг 3: расширение 16-битной константы до 32-х разрядов битом знака Однотактный тракт данных: расширение константы
- 15. Шаг 4: Вычисление адреса ячейки в памяти Однотактный тракт данных: вычисление адреса
- 16. Шаг 5: считываем данные из памяти и записываем их в регистр, номер которого хранится в коде
- 17. Шаг 6: Вычисляем адрес следующей инструкции Однотактный тракт данных: увеличение PC
- 18. Запись содержимого регистра rt в память Однотактный тракт данных: sw sw rt, imm(rs)
- 19. Считываем операнды из регистров rs и rt Записываем ALUResult в регистр с номером из поля rd
- 20. Проверяем на равенство регистры rs и rt Рассчитываем адрес для условного перехода: BTA = (sign-extended immediate
- 21. Однотактный процессор
- 22. Управление однотактным процессором
- 23. Вспомним принцип работы АЛУ
- 24. Вспомним принцип работы АЛУ
- 25. Управляющее устройство: Дешифратор АЛУ
- 26. Управляющее устройство: основной дешифратор
- 27. Управляющее устройство: основной дешифратор
- 28. Однотактный тракт данных: or
- 29. Необходимо сформировать управляющие сигналы, а тракт данных менять не нужно Добавим инструкцию addi
- 30. Управляющее устройство: addi
- 31. Управляющее устройство: addi
- 32. Добавим функционала: j
- 33. Управляющее устройство: j
- 34. Управляющее устройство: j
- 35. Время выполнения программы = (#инструкции)(такты/инструкция)(секунды/такт) = # инструкции x CPI x TC Вернемся к вопросу производительности
- 36. TC определяется цепью с наибольшей задержкой (lw) Производительность однотактного процессора CPI = 1
- 37. Задержка самой длинной цепи комбинационной логики: Tc = tpcq_PC + tmem + max(tRFread, tsext + tmux)
- 38. Tc = ? Посчитаем производительность однотактного процессора
- 39. Tc = tpcq_PC + 2tmem + tRFread + tmux + tALU + tRFsetup = [30 +
- 40. Предположим, в программе 100 миллиардов инструкций: Время выполнения = # инструкции x CPI x TC =
- 41. Однотактный: + Простой Период тактовой частоты ограничен инструкцией с самой длинной цепью комбинационной логики (lw) Несколько
- 42. Вместо отдельной памяти для инструкций и данных будем использовать одну общую память Элементы хранящие состояние многотактного
- 43. Шаг 1: Выборка инструкции Многотактный тракт данных: Выборка инструкции
- 44. Многотактный тракт данных: чтение регистров Шаг 2a: считывание операндов-источников из регистрового файла (на примере инструкции lw)
- 45. Многотактный тракт данных: расширение константы Шаг 2b: расширение 16-битной константы до 32-х разрядов битом знака
- 46. Многотактный тракт данных: вычисление адреса Шаг 3: Вычисление адреса ячейки в памяти
- 47. Многотактный тракт данных: считывание из памяти Шаг 4: считываем данные из памяти
- 48. Многотактный тракт данных: запись в регистр Шаг 5: записываем считанное из памяти 32-битное число в регистр
- 49. Многотактный тракт данных: увеличиваем PC Шаг 6: вычисляем адрес следующей инструкции и записываем в PC
- 50. Многотактный тракт данных: sw Запись содержимого регистра rt в память sw rt, imm(rs)
- 51. Многотактный тракт данных: R-Тип Считываем операнды из регистров rs и rt Записываем ALUResult в регистр с
- 52. rs == rt? BTA = (sign-extended immediate Многотактный тракт данных: beq
- 53. Многотактный процессор
- 54. Многотактное устройство управления
- 55. Основной управляющий автомат: Выборка
- 56. Основной управляющий автомат: Выборка Сигналы разрешения записи будем показывать только если они не равны нулю Одновременно
- 57. Основной управляющий автомат: Декодирование Будем указывать только те управляющие сигналы, которые имеют смысл на конкретном этапе
- 58. Основной управляющий автомат: Адрес
- 59. Основной управляющий автомат: Адрес
- 60. Основной управляющий автомат: lw
- 61. Основной управляющий автомат: sw
- 62. Основной управляющий автомат: R-Тип
- 63. Основной управляющий автомат : beq
- 64. Основной управляющий автомат
- 65. Добавим функционала: addi
- 66. Основной управляющий автомат: addi
- 67. Добавим функционала: j
- 68. Основной управляющий автомат : j
- 69. Основной управляющий автомат : j
- 70. Инструкции выполняются за разное количество тактов: 3 такта: beq, j 4 такта: R-тип, sw, addi 5
- 71. Задержка самой длинной цепи комбинационной логики многотактного процессора: Tc = tpcq + tmux + max(tALU +
- 72. Tc = ? Посчитаем производительность многотактного процессора
- 73. Tc = tpcq_PC + tmux + max(tALU + tmux, tmem) + tsetup = tpcq_PC + tmux
- 74. Предположим, в программе 100 миллиардов инструкций: CPI = 4.12 Tc = 325 пс Время выполнения =
- 75. Повторение: однотактный процессор
- 76. Повторение: многотактный процессор
- 77. Временной параллелизм Разделим однотактный процессор на 5 стадий: Выборка Декодирование Выполнение Доступ к памяти Запись результатов
- 78. Однотактный / Конвейерный
- 79. Абстрактное представление конвейера
- 80. Однотактный и конвейерный тракт данных
- 81. Теперь WriteRegW и ResultW подаются на входы регистрового файла в стадии Writeback одновременно. Исправленный конвейерный тракт
- 82. То же устройство управления, что и в однотактном процессоре Сигналы управления доходят до соответствующей стадии с
- 83. В конвейере выполняется несколько инструкций одновременно Конфликты случаются когда одна инструкция зависит от результата другой, еще
- 84. Конфликты данных
- 85. Можно вставлять пустые инструкции (nop) в код программы перед компиляцией или во время компиляции Во время
- 86. Вставить в код достаточно пустых инструкций (nop), которые будут заполнять стадии конвейера, пока необходимый результат не
- 87. Передача данных между стадиями (Forwarding, Bypass)
- 88. Передача данных между стадиями (Forwarding, Bypass)
- 89. Можно передавать необходимые данные на этап Выполнения с этапов: Доступа к памяти или Записи результатов в
- 90. Останов конвейера
- 91. Останов конвейера
- 92. Останов конвейера
- 93. lwstall = ((rsD==rtE) OR (rtD==rtE)) AND MemtoRegE StallF = StallD = FlushE = lwstall Логика управления
- 94. beq: Будет выполнен условный переход или нет становится известно только на 4-й стадии конвейера Пока это
- 95. Конвейер до разрешения конфликтов управления
- 96. Конфликты управления
- 97. Приводит к новому конфликту данных на стадии Декодирования Ранняя проверка условия перехода
- 98. Ранняя проверка условия перехода Инструкцию загруженную в конвейер после beq не обязательно удалять в случае выполнения
- 99. Устранение конфликтов управления и данных
- 100. Логика управления передачей данных между стадиями конвейера (Forwarding logic): ForwardAD = (rsD !=0) AND (rsD ==
- 101. Мы можем попробовать оценить на сколько вероятно выполнение условного перехода и использовать наиболее вероятный результат Например,
- 102. Тестовый набор SPECINT2000 содержит : 25% инструкций lw 10% инструкций sw 11% условных переходов 2% безусловных
- 103. Тестовый набор SPECINT2000 содержит : 25% инструкций lw 10% инструкций sw 11% условных переходов 2% безусловных
- 104. Задержка самой длинной цепи комбинационной логики конвейерного процессора: Tc = max { tpcq + tmem +
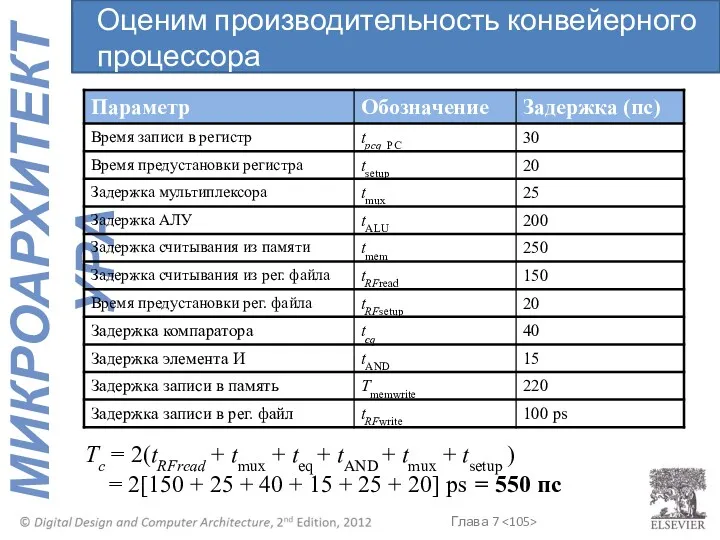
- 105. Tc = 2(tRFread + tmux + teq + tAND + tmux + tsetup ) = 2[150
- 106. Предположим, в программе 100 миллиардов инструкций Время выполнения = (# инструкции) × CPI × Tc =
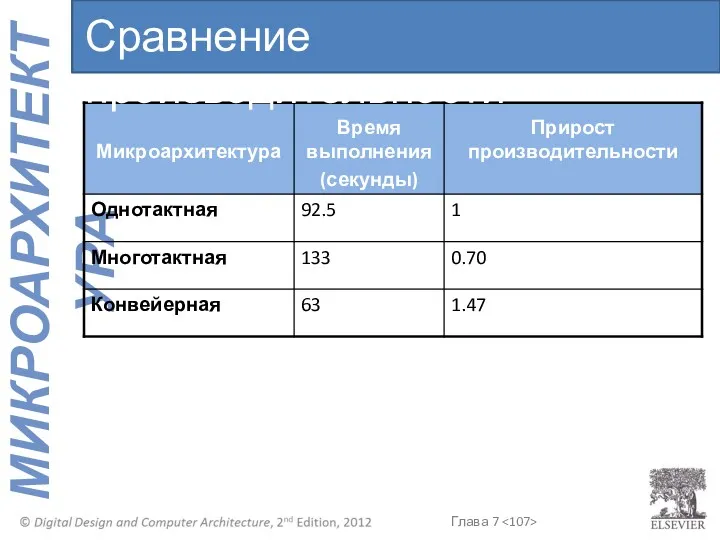
- 107. Сравнение производительности
- 108. Повторение: Исключения Исключение (англ.: exception) – незапланированный вызов функции-обработчика исключения (exception handler) Исключения бывают: Аппаратные (например,
- 109. Пример исключения
- 110. Отдельные регистры. Не входят в регистровый файл Cause Содержит код причины исключения Регистр 13 Сопроцессора 0
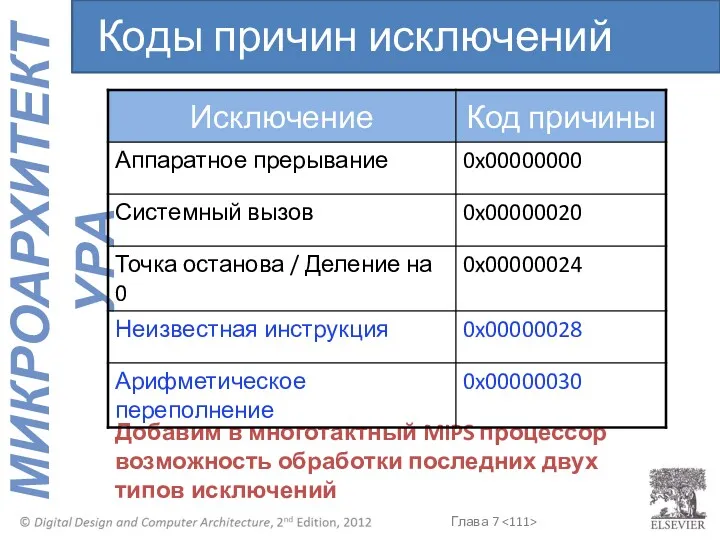
- 111. Добавим в многотактный MIPS процессор возможность обработки последних двух типов исключений Коды причин исключений
- 112. Аппаратура исключений: EPC & Cause
- 113. Исключения в управляющем автомате
- 114. Аппаратура исключений: mfc0
- 115. Длинные конвейеры Динамическое предсказание переходов Суперскалярные процессоры Процессоры с внеочередным выполнением инструкций Переименование регистров SIMD Многопоточность
- 116. Содержат 10-20 стадий Количество стадий ограничивается: Конфликтами конвейера Энергопотреблением Стоимостью Увеличением задержки тактового сигнала Длинные конвейеры
- 117. У идеального конвейерного процессора: CPI = 1 Неверное предсказание переходов увеличивает CPI Статическое предсказание переходов: Проверяем
- 118. add $s1, $0, $0 # sum = 0 add $s0, $0, $0 # i = 0
- 119. Запоминает, был ли переход выполнен в прошлый раз, и предсказывает, что в следующий раз произойдет то
- 120. Дает неверное предсказание только для последнего условного перехода цикла (на последней итерации) Двухбитный динамический предсказатель переходов
- 121. Позволяет одновременно считывать и выполнять несколько инструкций за счет дублирования функциональных блоков Как будто в процессоре
- 122. lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 Идеальный IPC: 2 and $t2,
- 123. lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 Идеальный IPC: 2 and $t2,
- 124. Процессор заранее просматривает наперед большое количество инструкций, находит независимые друг от друга инструкции и запускает их
- 125. Параллелизм на уровне инструкций (Instruction level parallelism, ILP): число инструкций, которые могут выполнятся одновременно (обычно Таблица
- 126. lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 Идеальный IPC: 2 and $t2,
- 127. lw $t0, 40($s0) add $t1, $t0, $s1 sub $t0, $s2, $s3 Идеальный IPC: 2 and $t2,
- 128. Одиночный поток команд, множественный поток данных (Single Instruction Multiple Data, SIMD) Одна инструкция обрабатывает множество блоков
- 129. Многопоточность Например, в текстовом редакторе один поток может отвечать за обработку вводимых с клавиатуры символов и
- 130. Процесс: программа, которая выполняется на компьютере Несколько процессов могут выполняться одновременно, например: веб серфинг, прослушивание музыки,
- 131. В каждый момент времени выполняется один поток Когда выполнение потока блокируется (например, поток ожидает данные из
- 132. У многопоточного процессора есть несколько копий архитектурного состояния Несколько потоков могут быть активны одновременно: Когда выполнение
- 133. Многопроцессорная система (multiprocessor system), или просто мультипроцессор, состоит из нескольких процессоров и аппаратуры для соединения их
- 135. Скачать презентацию

Цифровая схемотехника и архитектура компьютера
Эти слайды предназначены для преподавателей, которые читают
Цифровая схемотехника и архитектура компьютера
Эти слайды предназначены для преподавателей, которые читают

Благодарности
Перевод данных слайдов на русский язык был выполнен командой сотрудников университетов
Благодарности
Перевод данных слайдов на русский язык был выполнен командой сотрудников университетов

Глава 7 :: Темы
Введение
Анализ производительности
Однотактный процессор
Многотактный процессор
Конвейерный процессор
Исключения
Улучшение микроархитектуры
Глава 7 :: Темы
Введение
Анализ производительности
Однотактный процессор
Многотактный процессор
Конвейерный процессор
Исключения
Улучшение микроархитектуры

Микроархитектура: аппаратная реализация архитектуры в виде схемы
Процессор:
Тракт данных: функциональные блоки обработки
Микроархитектура: аппаратная реализация архитектуры в виде схемы
Процессор:
Тракт данных: функциональные блоки обработки

Несколько аппаратных реализаций одной и той же архитектуры:
Однотактная реализация: каждая инструкция
Несколько аппаратных реализаций одной и той же архитектуры:
Однотактная реализация: каждая инструкция

Время выполнения программы
Execution Time = (#instructions)(cycles/instruction)(seconds/cycle)
Время выполнения = (#инструкции)(такты/инструкция)(секунды/такт)
Определения:
CPI:
Время выполнения программы
Execution Time = (#instructions)(cycles/instruction)(seconds/cycle)
Время выполнения = (#инструкции)(такты/инструкция)(секунды/такт)
Определения:
CPI:

Будем рассматривать подмножество инструкций MIPS:
Инструкции R-типа: and, or, add, sub, slt
Инструкции
Будем рассматривать подмножество инструкций MIPS:
Инструкции R-типа: and, or, add, sub, slt
Инструкции

Определяется:
Содержимым счетчика команд (PC)
Содержимым 32-х регистров общего назначения
Содержимым памяти
Архитектурное состояние
Определяется:
Содержимым счетчика команд (PC)
Содержимым 32-х регистров общего назначения
Содержимым памяти
Архитектурное состояние
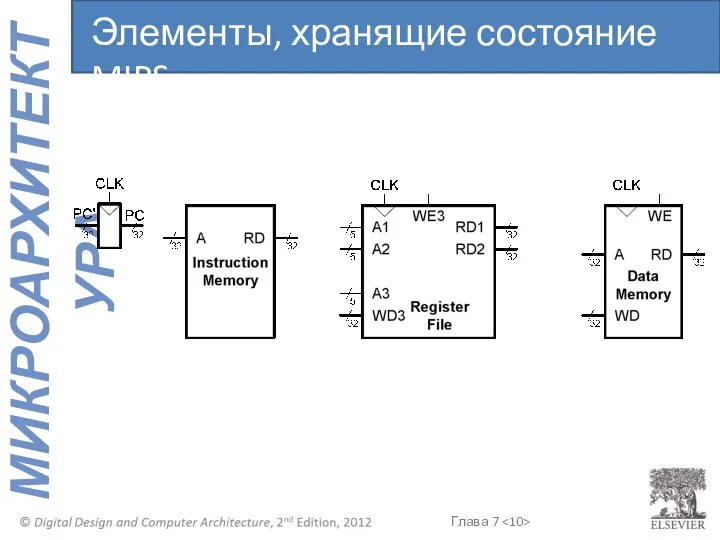
Элементы, хранящие состояние MIPS
Элементы, хранящие состояние MIPS

Тракт данных
Устройство управления
Однотактный MIPS процессор
Тракт данных
Устройство управления
Однотактный MIPS процессор
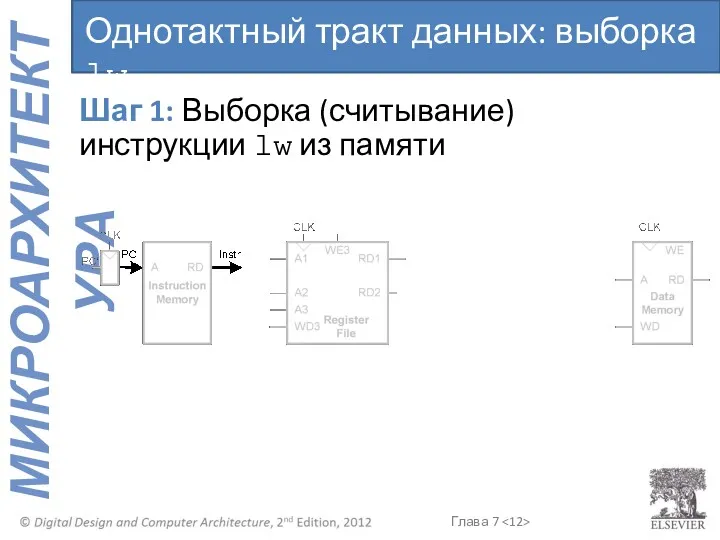
Шаг 1: Выборка (считывание) инструкции lw из памяти
Однотактный тракт данных: выборка
Шаг 1: Выборка (считывание) инструкции lw из памяти
Однотактный тракт данных: выборка

Шаг 2: считывание операндов-источников из регистрового файла
Однотактный тракт данных: чтение регистров
lw
Шаг 2: считывание операндов-источников из регистрового файла
Однотактный тракт данных: чтение регистров
lw
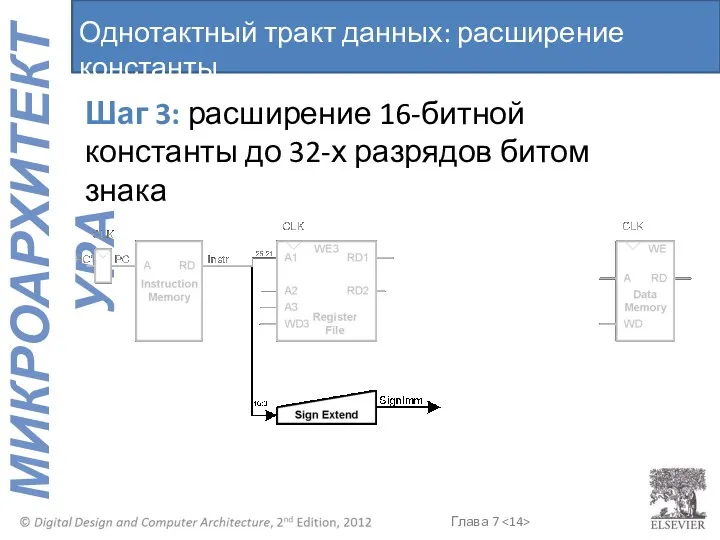
Шаг 3: расширение 16-битной константы до 32-х разрядов битом знака
Однотактный тракт
Шаг 3: расширение 16-битной константы до 32-х разрядов битом знака
Однотактный тракт
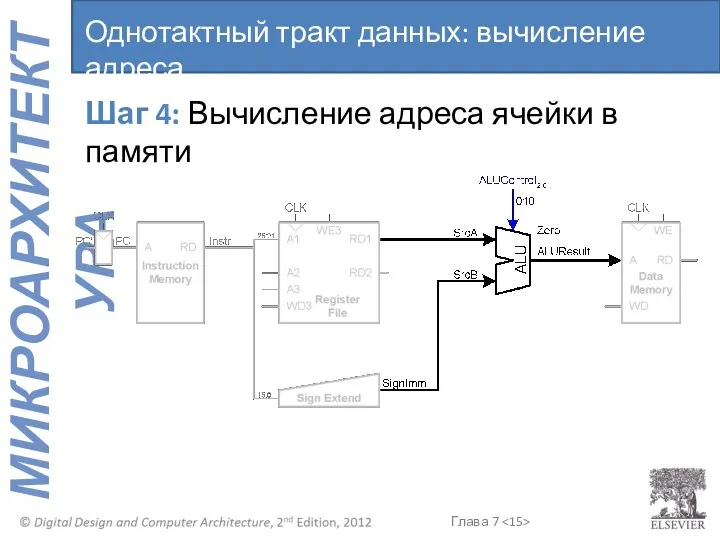
Шаг 4: Вычисление адреса ячейки в памяти
Однотактный тракт данных: вычисление адреса
Шаг 4: Вычисление адреса ячейки в памяти
Однотактный тракт данных: вычисление адреса
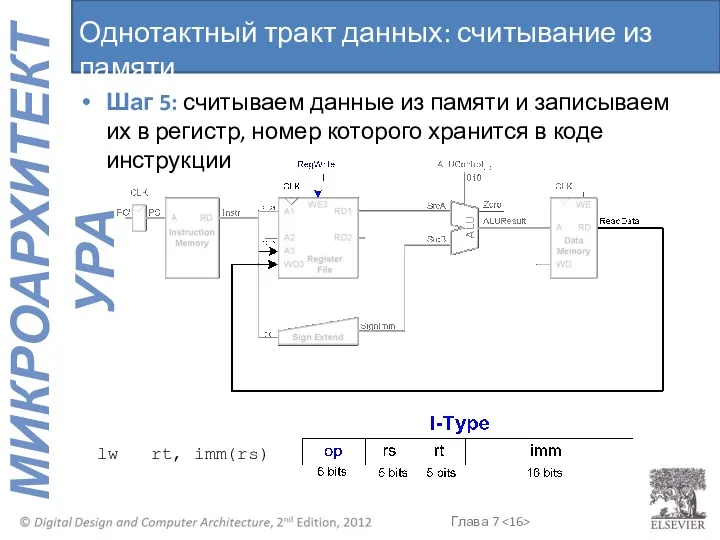
Шаг 5: считываем данные из памяти и записываем их в регистр,
Шаг 5: считываем данные из памяти и записываем их в регистр,
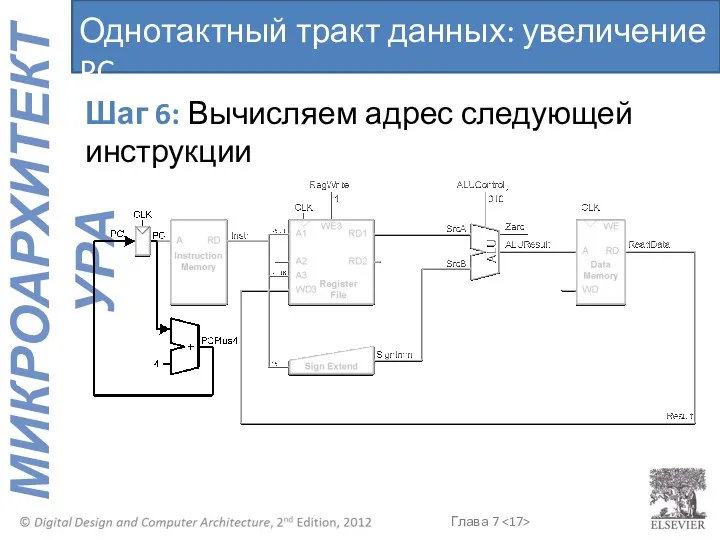
Шаг 6: Вычисляем адрес следующей инструкции
Однотактный тракт данных: увеличение PC
Шаг 6: Вычисляем адрес следующей инструкции
Однотактный тракт данных: увеличение PC
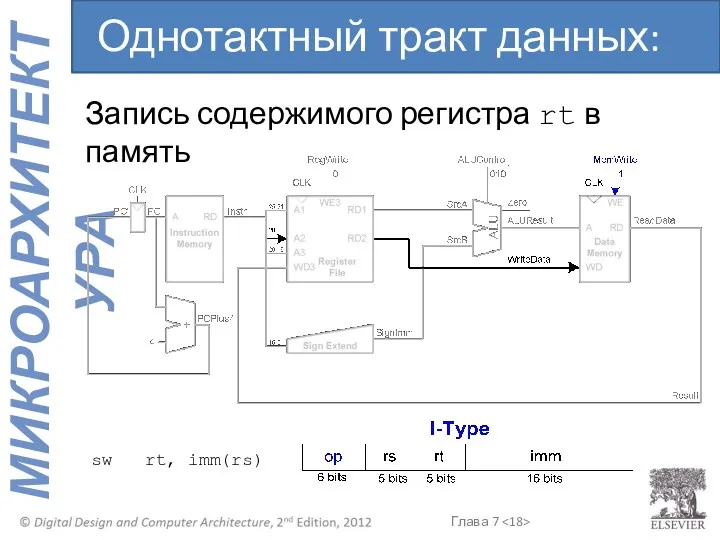
Запись содержимого регистра rt в память
Однотактный тракт данных: sw
sw rt, imm(rs)
Запись содержимого регистра rt в память
Однотактный тракт данных: sw
sw rt, imm(rs)
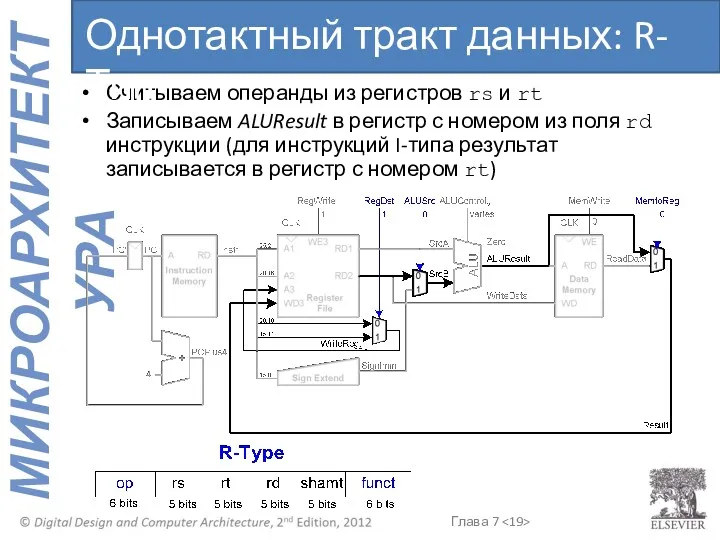
Считываем операнды из регистров rs и rt
Записываем ALUResult в регистр с
Считываем операнды из регистров rs и rt
Записываем ALUResult в регистр с
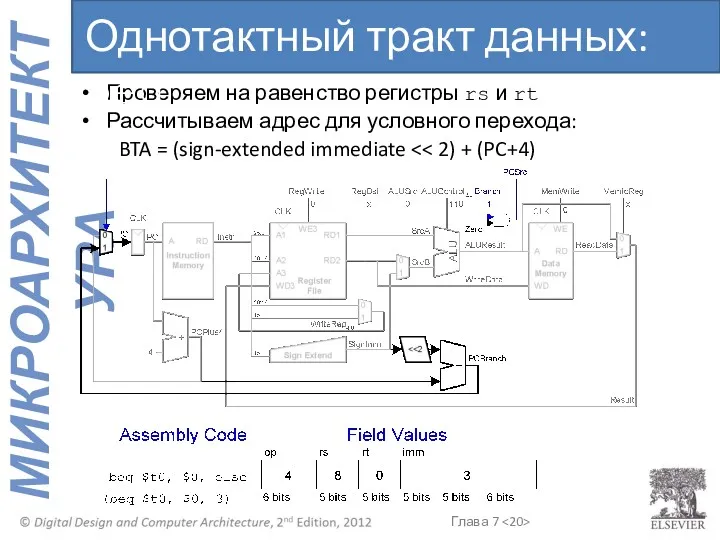
Проверяем на равенство регистры rs и rt
Рассчитываем адрес для условного перехода:
Проверяем на равенство регистры rs и rt
Рассчитываем адрес для условного перехода:
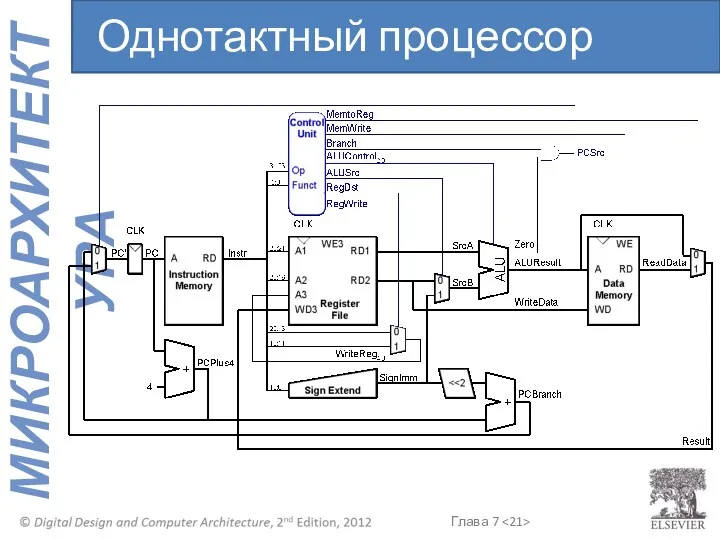
Однотактный процессор
Однотактный процессор
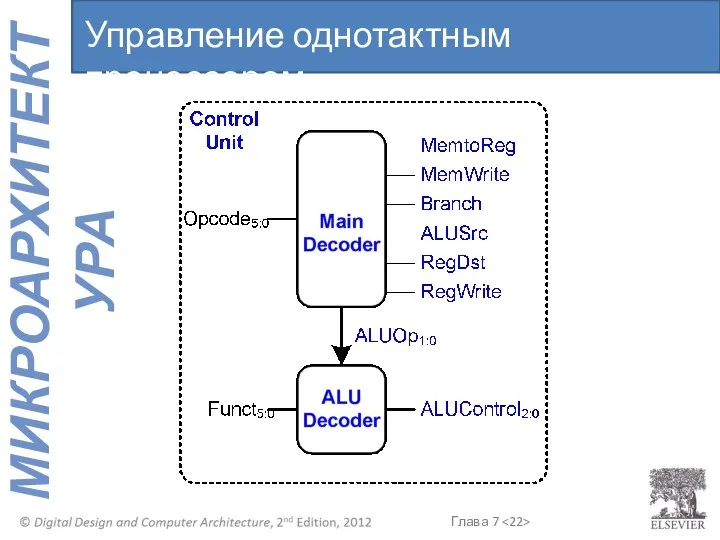
Управление однотактным процессором
Управление однотактным процессором
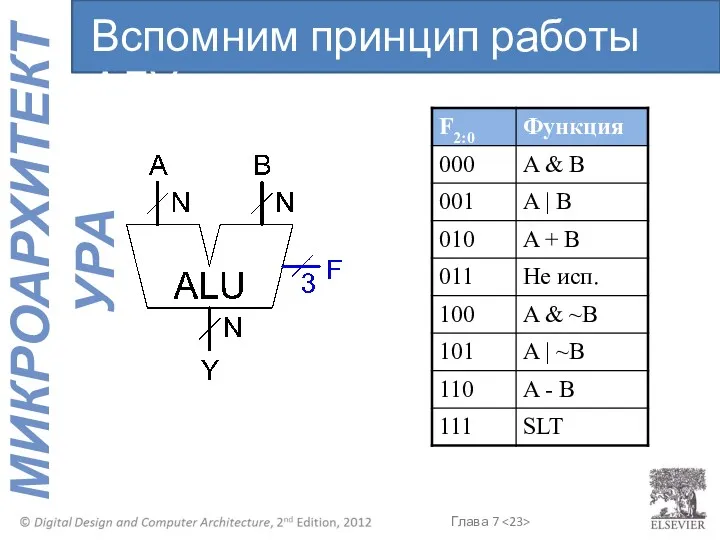
Вспомним принцип работы АЛУ
Вспомним принцип работы АЛУ
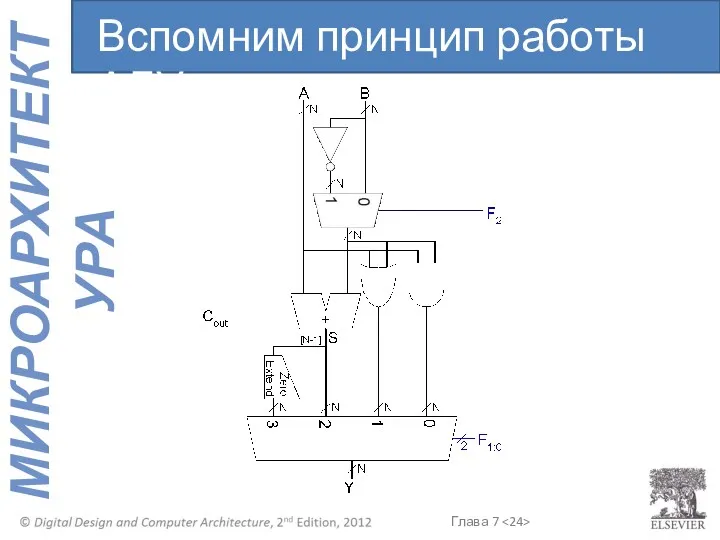
Вспомним принцип работы АЛУ
Вспомним принцип работы АЛУ
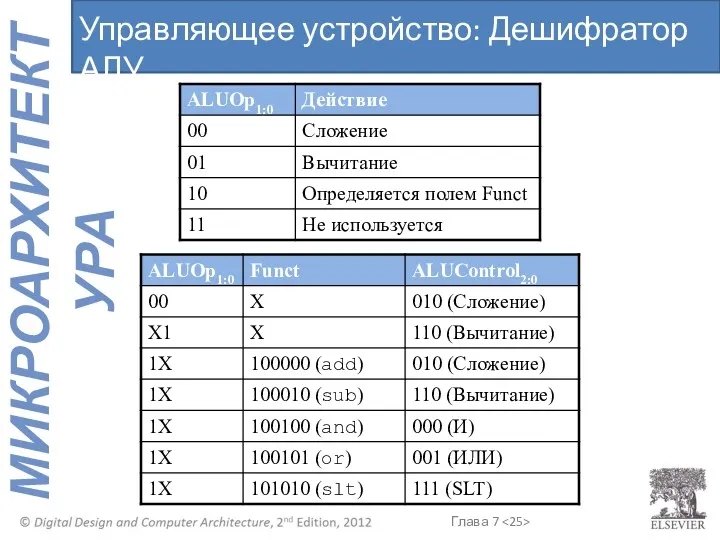
Управляющее устройство: Дешифратор АЛУ
Управляющее устройство: Дешифратор АЛУ
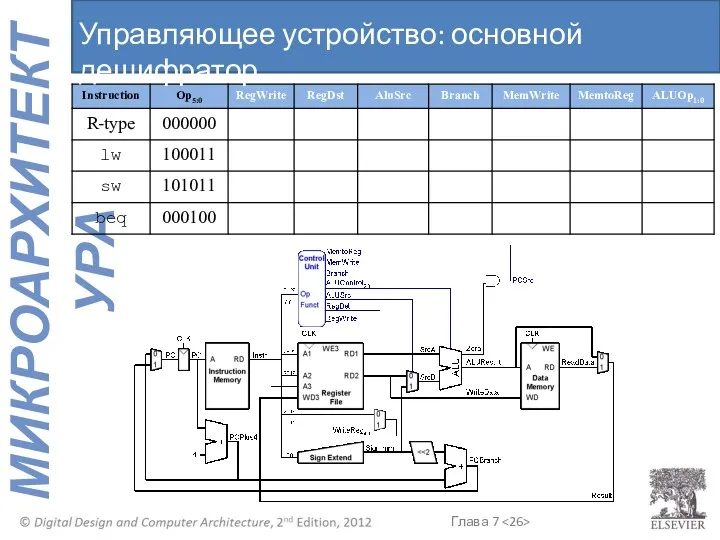
Управляющее устройство: основной дешифратор
Управляющее устройство: основной дешифратор
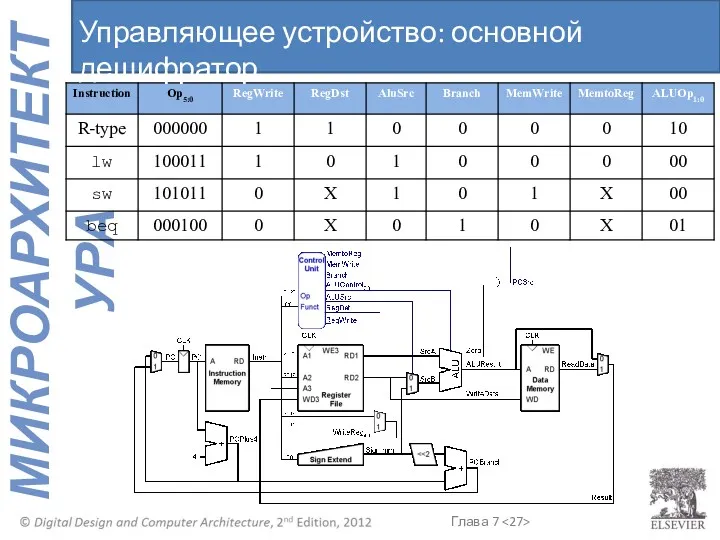
Управляющее устройство: основной дешифратор
Управляющее устройство: основной дешифратор
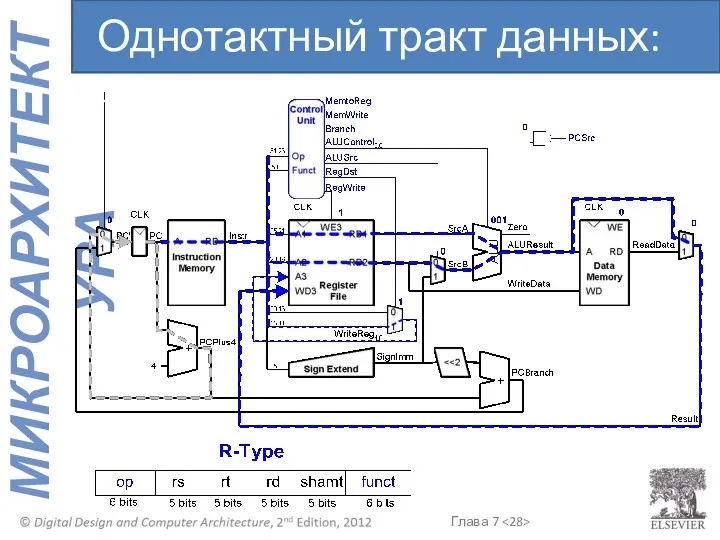
Однотактный тракт данных: or
Однотактный тракт данных: or
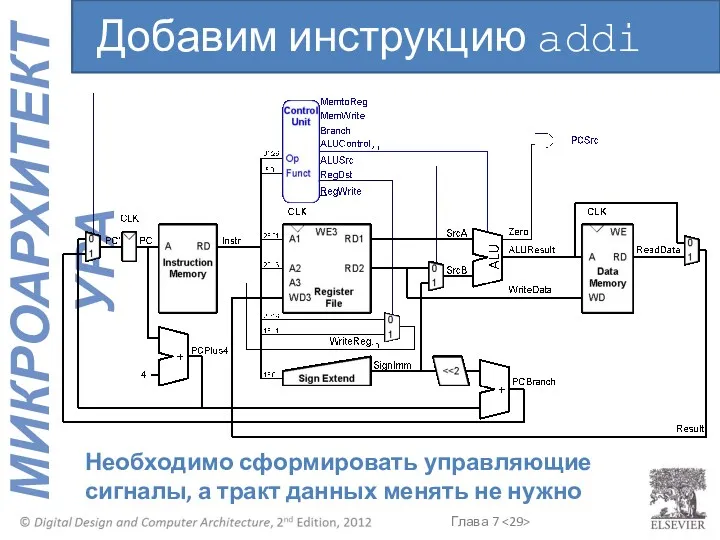
Необходимо сформировать управляющие сигналы, а тракт данных менять не нужно
Добавим инструкцию
Необходимо сформировать управляющие сигналы, а тракт данных менять не нужно
Добавим инструкцию
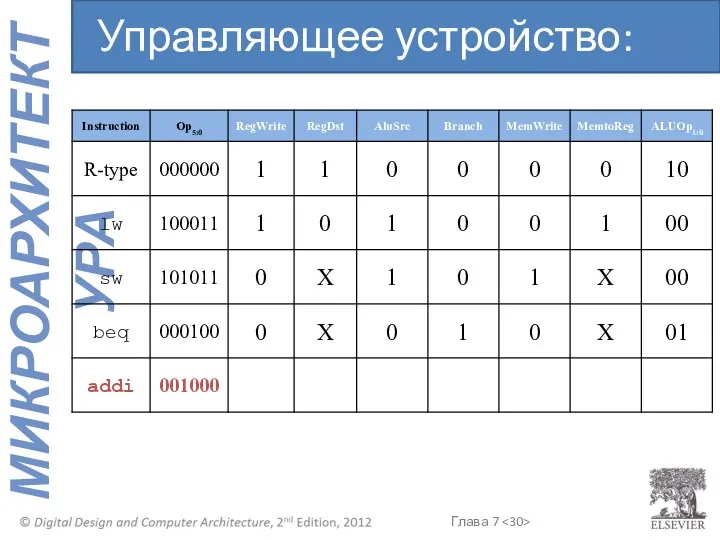
Управляющее устройство: addi
Управляющее устройство: addi
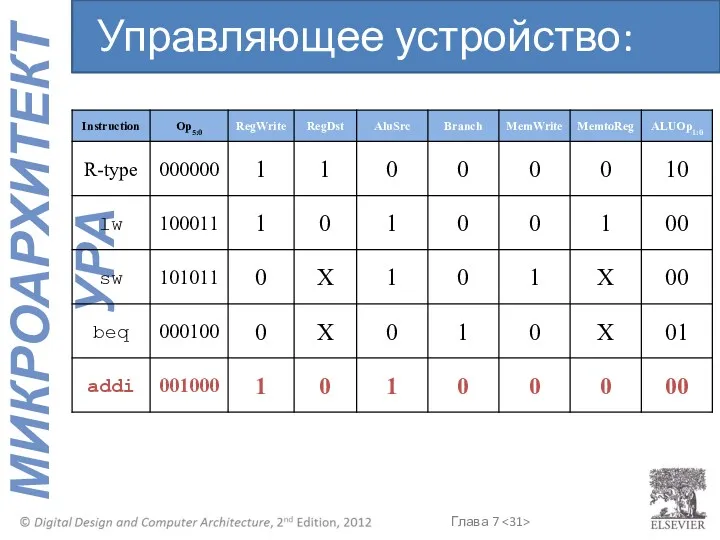
Управляющее устройство: addi
Управляющее устройство: addi
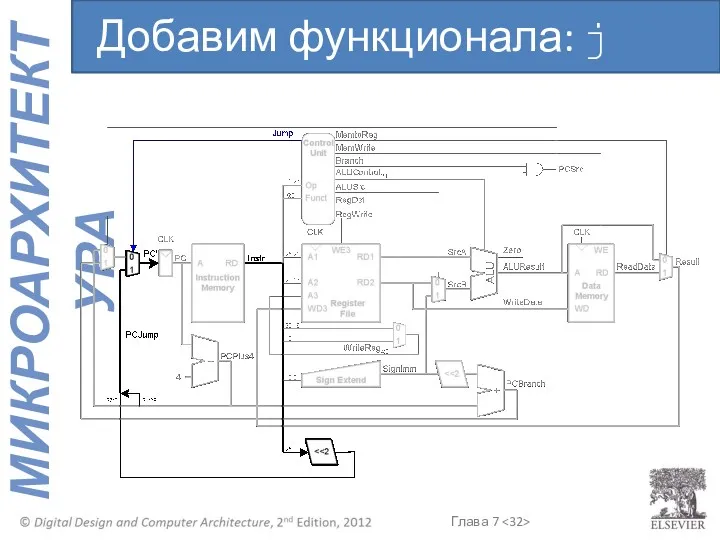
Добавим функционала: j
Добавим функционала: j
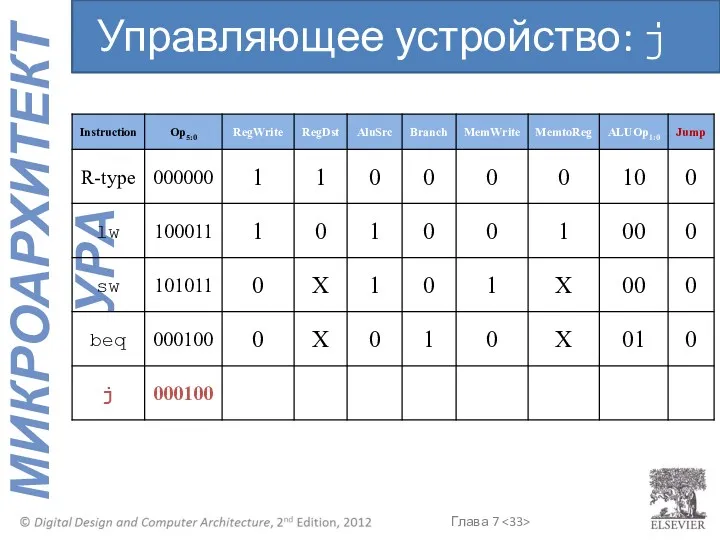
Управляющее устройство: j
Управляющее устройство: j
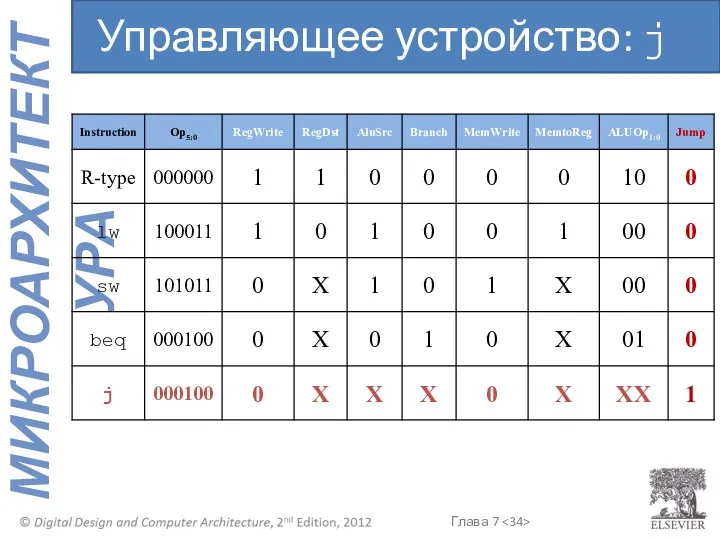
Управляющее устройство: j
Управляющее устройство: j

Время выполнения программы
= (#инструкции)(такты/инструкция)(секунды/такт)
= # инструкции x CPI x
= (#инструкции)(такты/инструкция)(секунды/такт)
= # инструкции x CPI x
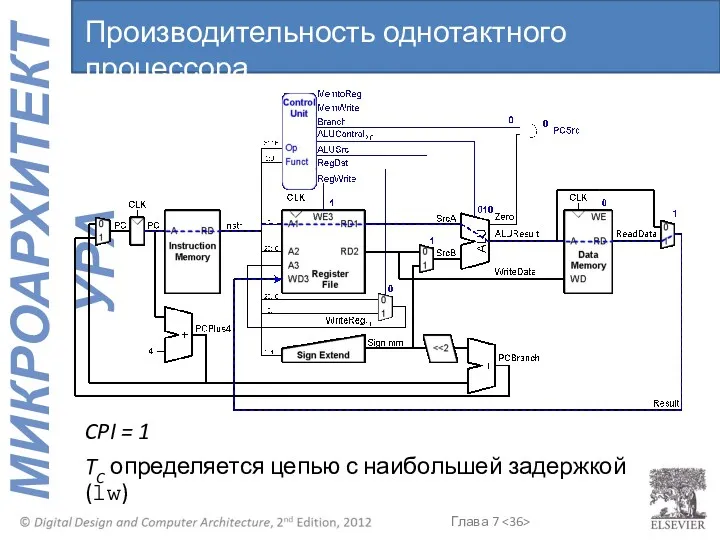
TC определяется цепью с наибольшей задержкой (lw)
Производительность однотактного процессора
CPI = 1
TC определяется цепью с наибольшей задержкой (lw)
Производительность однотактного процессора
CPI = 1

Задержка самой длинной цепи комбинационной логики:
Tc = tpcq_PC + tmem
Задержка самой длинной цепи комбинационной логики:
Tc = tpcq_PC + tmem

Tc = ?
Посчитаем производительность однотактного процессора
Tc = ?
Посчитаем производительность однотактного процессора

Tc = tpcq_PC + 2tmem + tRFread + tmux + tALU
Tc = tpcq_PC + 2tmem + tRFread + tmux + tALU

Предположим, в программе 100 миллиардов инструкций:
Время выполнения = # инструкции x
Предположим, в программе 100 миллиардов инструкций:
Время выполнения = # инструкции x

Однотактный:
+ Простой
Период тактовой частоты ограничен инструкцией с самой длинной цепью комбинационной
Однотактный:
+ Простой
Период тактовой частоты ограничен инструкцией с самой длинной цепью комбинационной
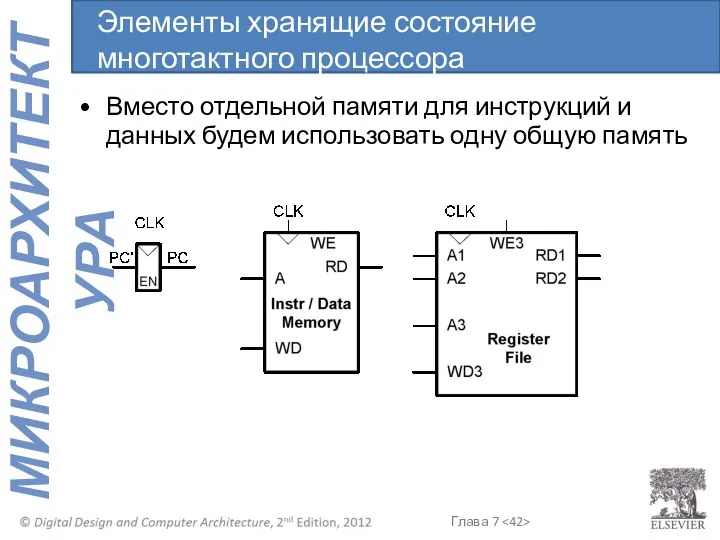
Вместо отдельной памяти для инструкций и данных будем использовать одну общую
Вместо отдельной памяти для инструкций и данных будем использовать одну общую
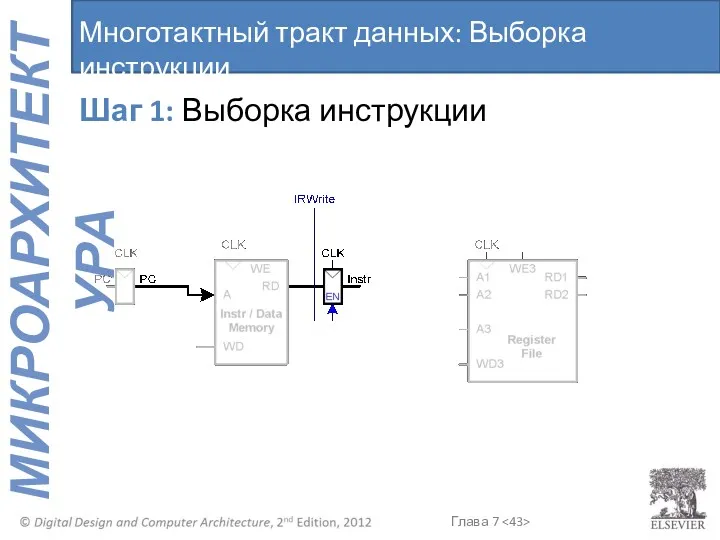
Шаг 1: Выборка инструкции
Многотактный тракт данных: Выборка инструкции
Шаг 1: Выборка инструкции
Многотактный тракт данных: Выборка инструкции
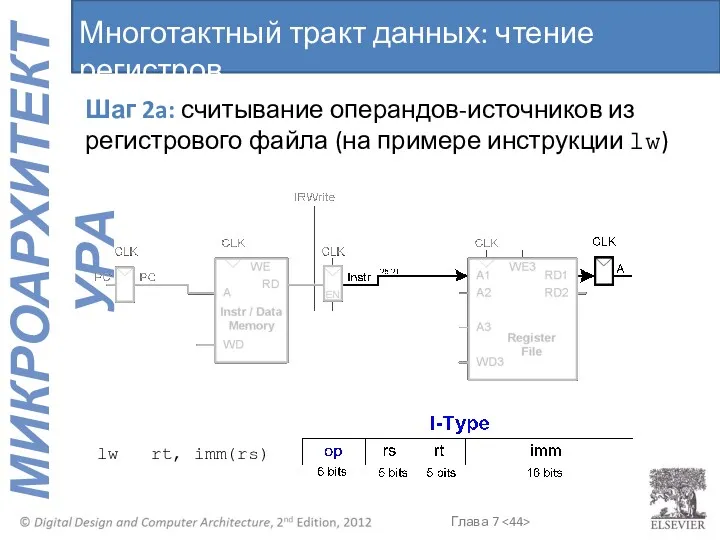
Многотактный тракт данных: чтение регистров
Шаг 2a: считывание операндов-источников из регистрового файла
Многотактный тракт данных: чтение регистров
Шаг 2a: считывание операндов-источников из регистрового файла
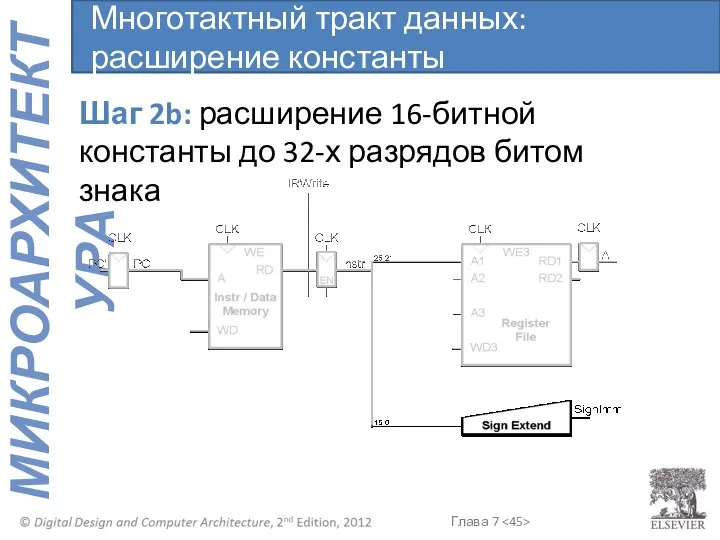
Многотактный тракт данных: расширение константы
Шаг 2b: расширение 16-битной константы до 32-х
Многотактный тракт данных: расширение константы
Шаг 2b: расширение 16-битной константы до 32-х
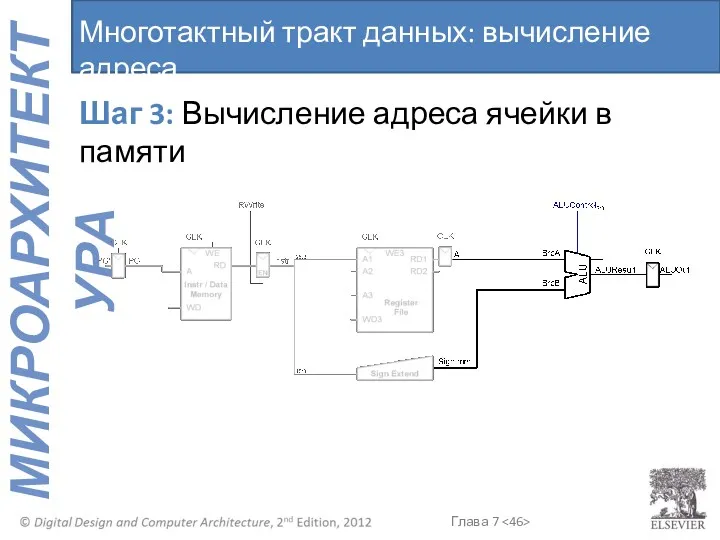
Многотактный тракт данных: вычисление адреса
Шаг 3: Вычисление адреса ячейки в памяти
Многотактный тракт данных: вычисление адреса
Шаг 3: Вычисление адреса ячейки в памяти
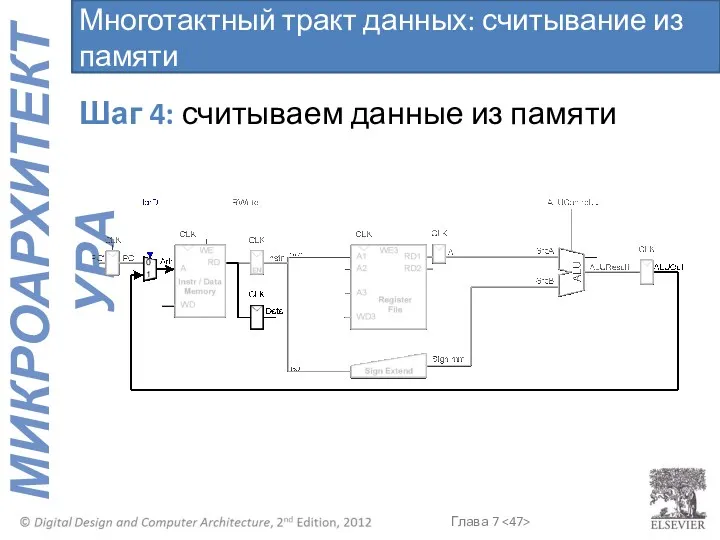
Многотактный тракт данных: считывание из памяти
Шаг 4: считываем данные из памяти
Многотактный тракт данных: считывание из памяти
Шаг 4: считываем данные из памяти
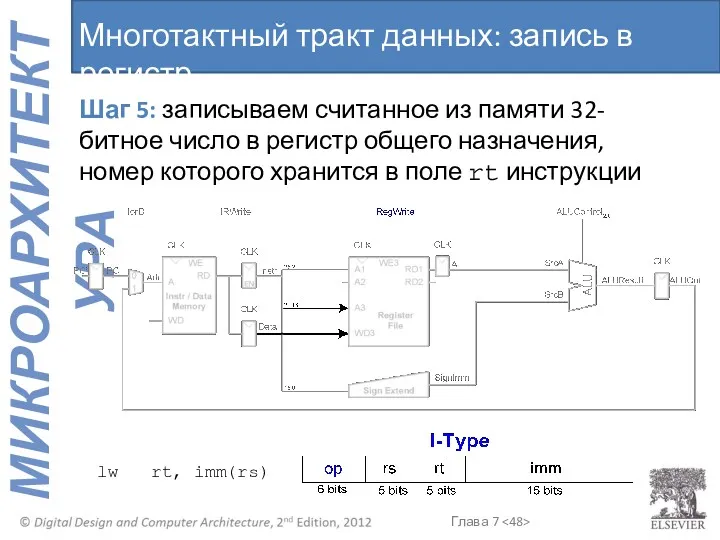
Многотактный тракт данных: запись в регистр
Шаг 5: записываем считанное из памяти
Многотактный тракт данных: запись в регистр
Шаг 5: записываем считанное из памяти
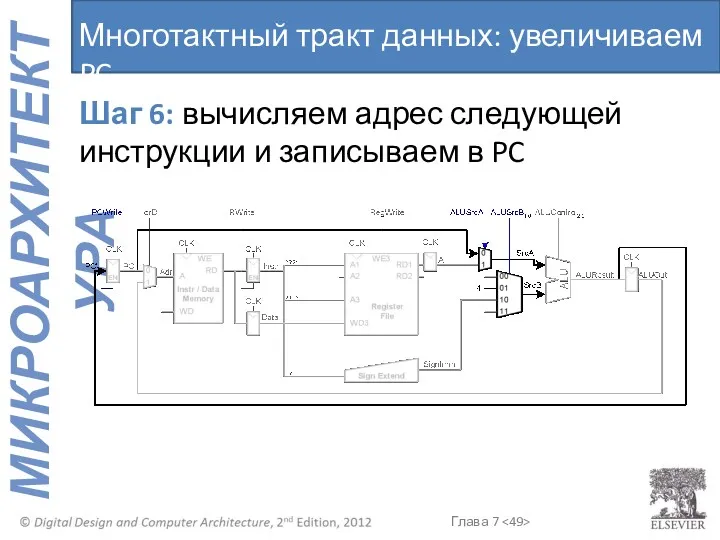
Многотактный тракт данных: увеличиваем PC
Шаг 6: вычисляем адрес следующей инструкции и
Многотактный тракт данных: увеличиваем PC
Шаг 6: вычисляем адрес следующей инструкции и
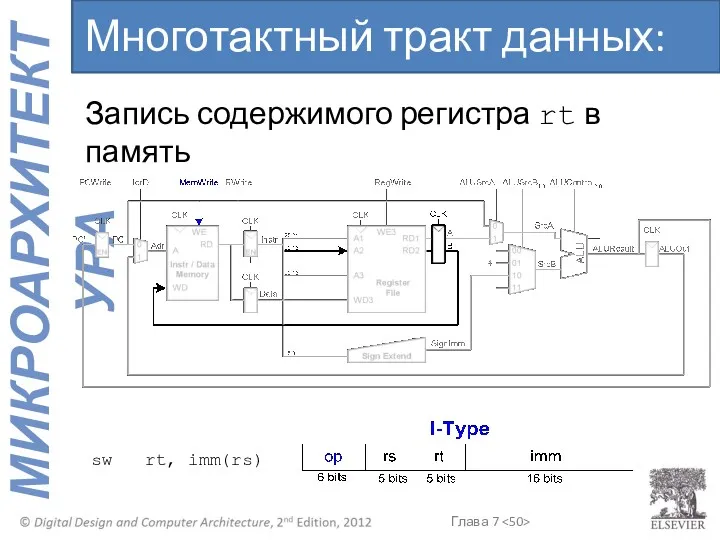
Многотактный тракт данных: sw
Запись содержимого регистра rt в память
sw rt, imm(rs)
Многотактный тракт данных: sw
Запись содержимого регистра rt в память
sw rt, imm(rs)

Многотактный тракт данных: R-Тип
Считываем операнды из регистров rs и rt
Записываем ALUResult
Многотактный тракт данных: R-Тип
Считываем операнды из регистров rs и rt
Записываем ALUResult
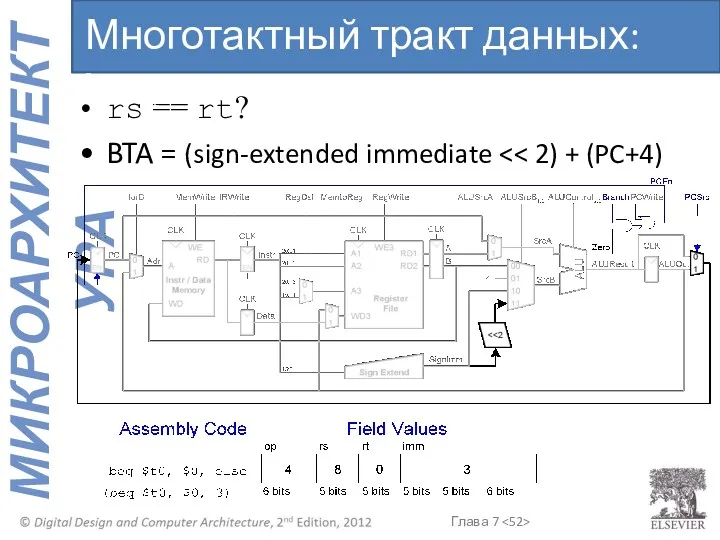
rs == rt?
BTA = (sign-extended immediate << 2) + (PC+4)
Многотактный тракт
rs == rt?
BTA = (sign-extended immediate << 2) + (PC+4)
Многотактный тракт
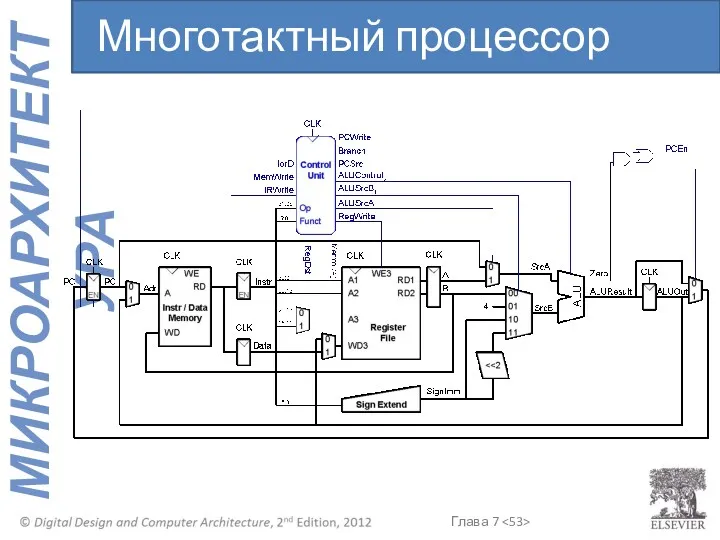
Многотактный процессор
Многотактный процессор
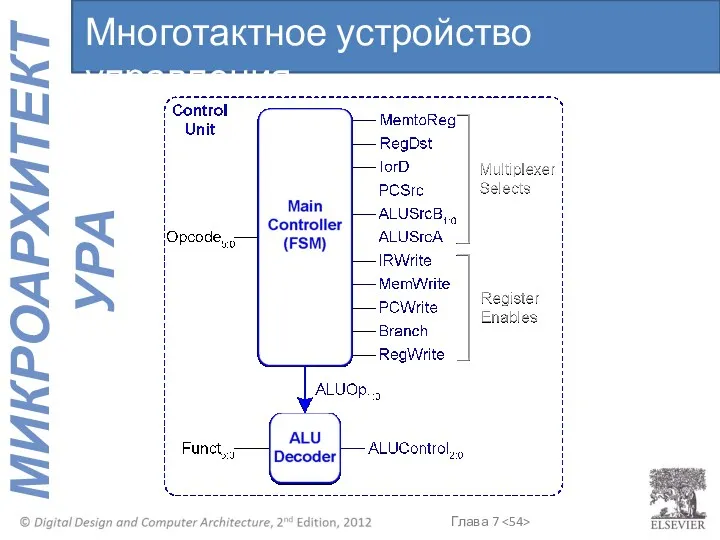
Многотактное устройство управления
Многотактное устройство управления
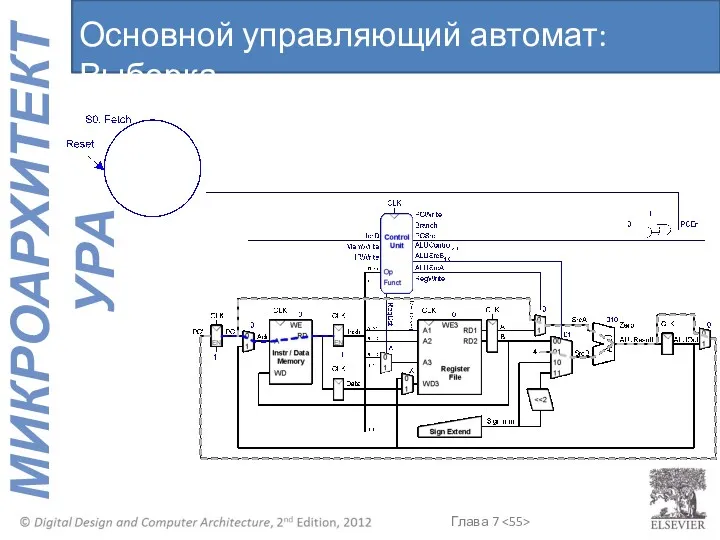
Основной управляющий автомат: Выборка
Основной управляющий автомат: Выборка
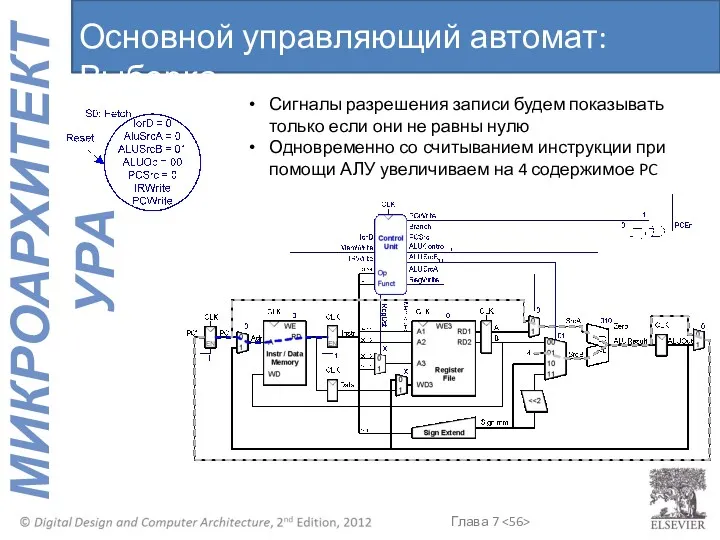
Основной управляющий автомат: Выборка
Сигналы разрешения записи будем показывать только если они
Основной управляющий автомат: Выборка
Сигналы разрешения записи будем показывать только если они
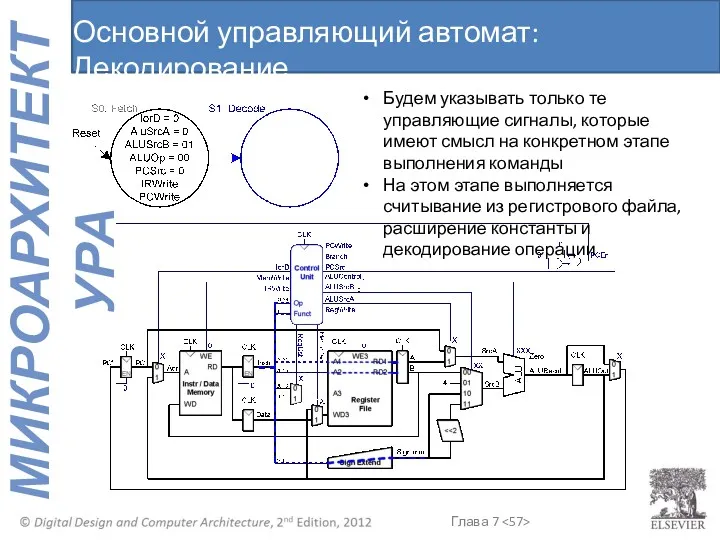
Основной управляющий автомат: Декодирование
Будем указывать только те управляющие сигналы, которые имеют
Основной управляющий автомат: Декодирование
Будем указывать только те управляющие сигналы, которые имеют
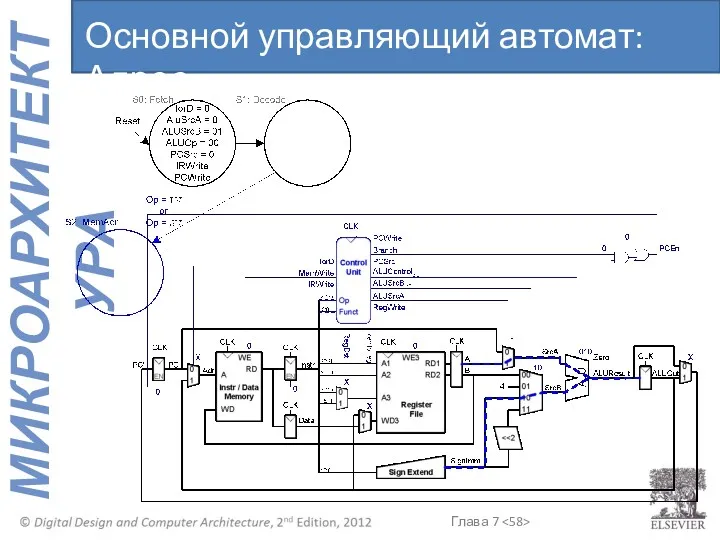
Основной управляющий автомат: Адрес
Основной управляющий автомат: Адрес
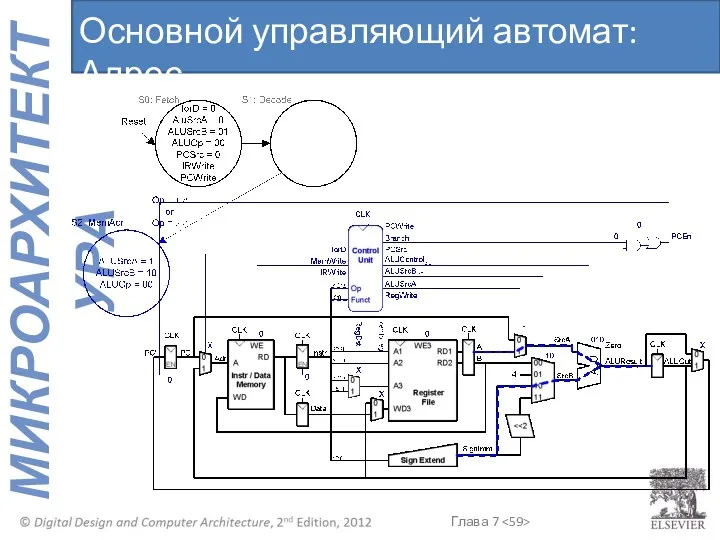
Основной управляющий автомат: Адрес
Основной управляющий автомат: Адрес
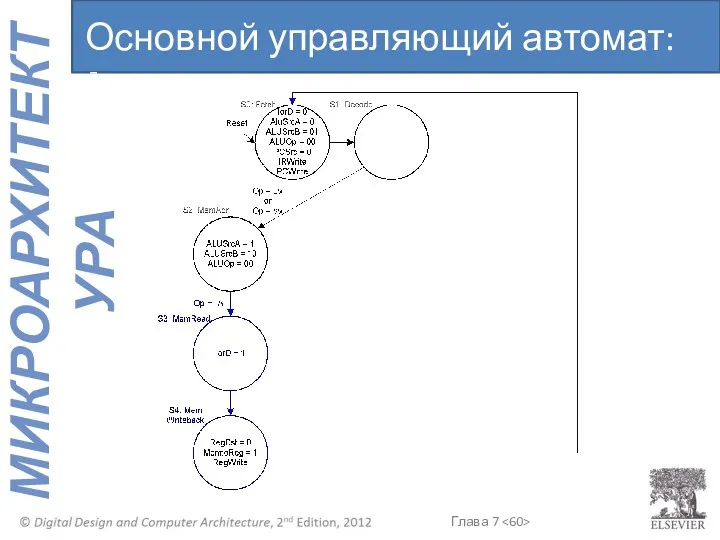
Основной управляющий автомат: lw
Основной управляющий автомат: lw
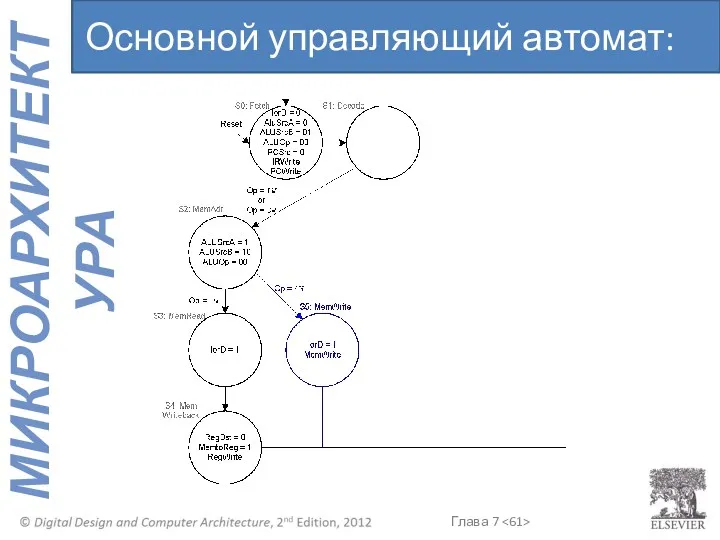
Основной управляющий автомат: sw
Основной управляющий автомат: sw
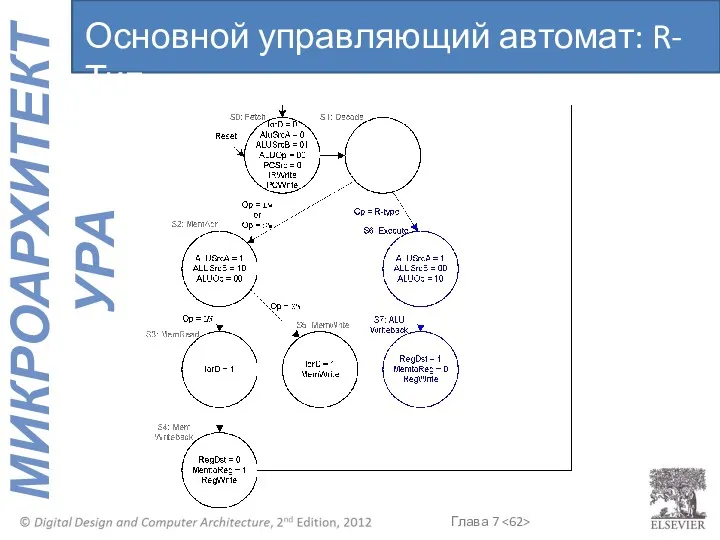
Основной управляющий автомат: R-Тип
Основной управляющий автомат: R-Тип
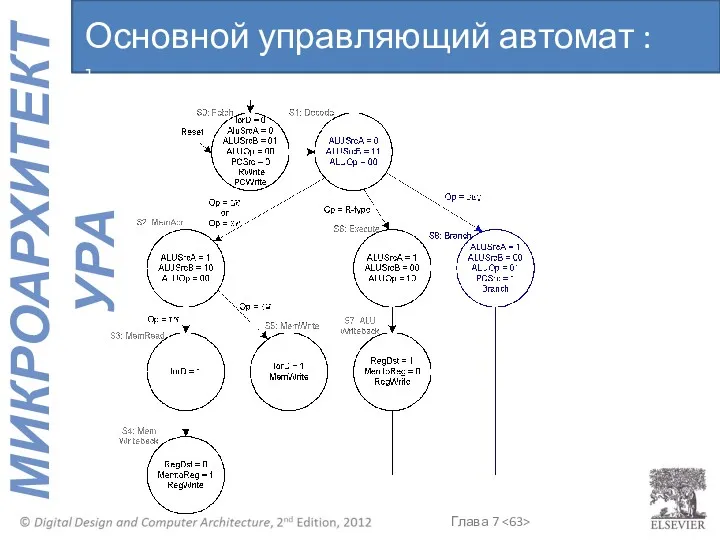
Основной управляющий автомат : beq
Основной управляющий автомат : beq
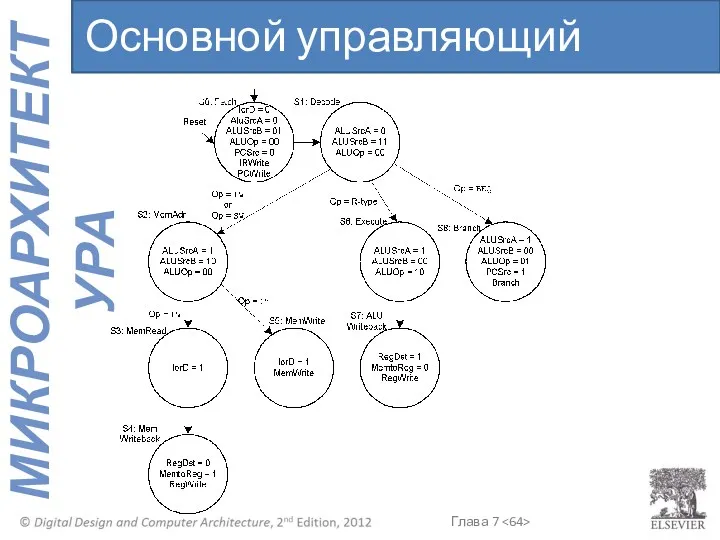
Основной управляющий автомат
Основной управляющий автомат
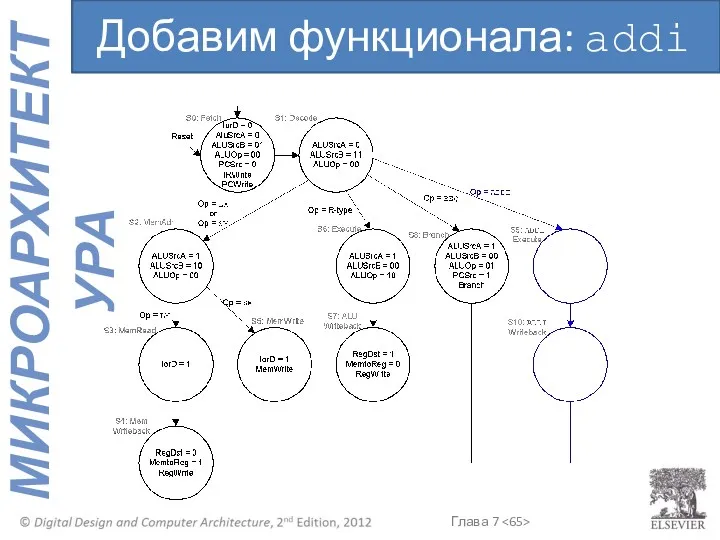
Добавим функционала: addi
Добавим функционала: addi
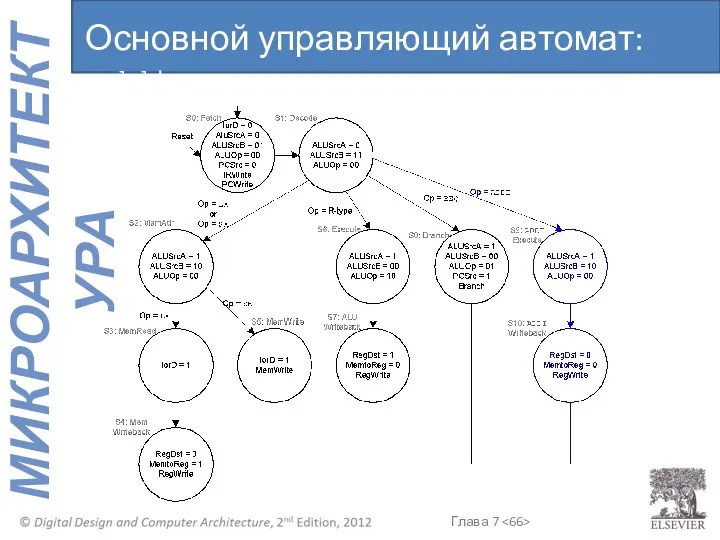
Основной управляющий автомат: addi
Основной управляющий автомат: addi
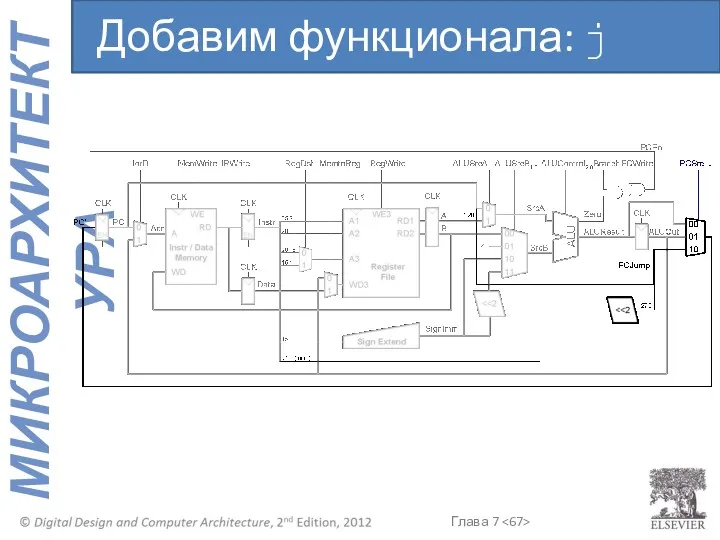
Добавим функционала: j
Добавим функционала: j
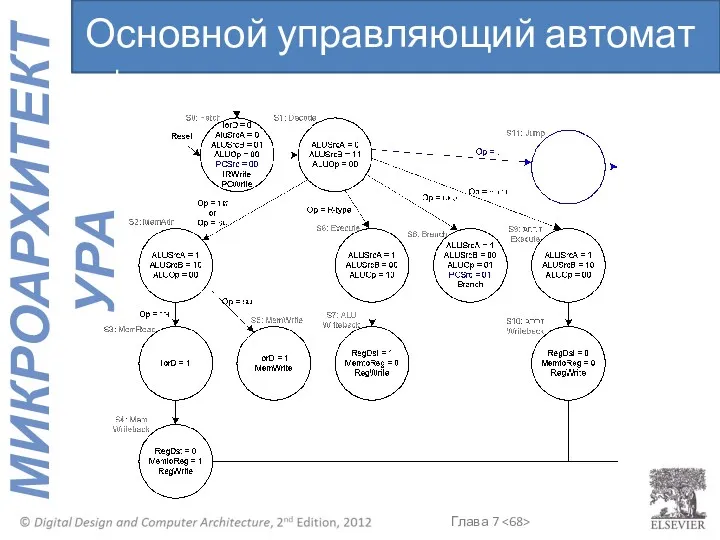
Основной управляющий автомат : j
Основной управляющий автомат : j
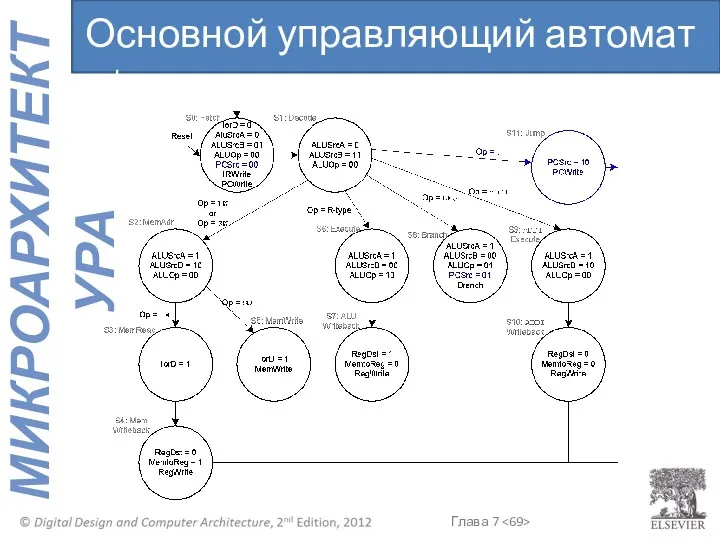
Основной управляющий автомат : j
Основной управляющий автомат : j

Инструкции выполняются за разное количество тактов:
3 такта: beq, j
4 такта: R-тип,
Инструкции выполняются за разное количество тактов:
3 такта: beq, j
4 такта: R-тип,
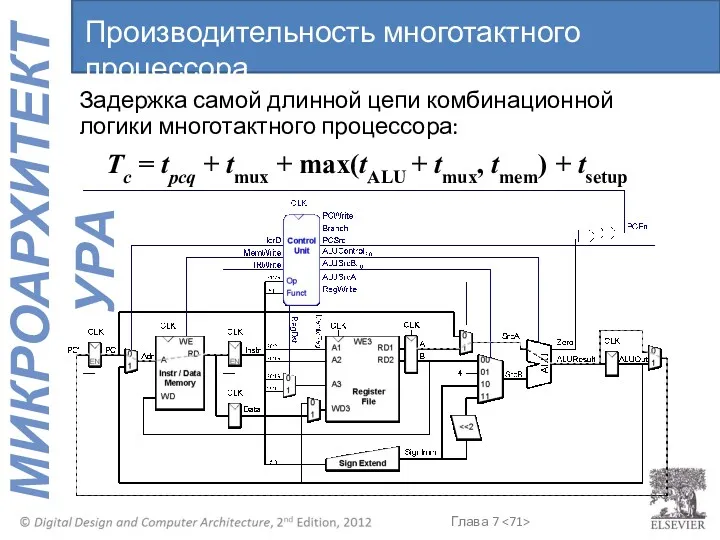
Задержка самой длинной цепи комбинационной логики многотактного процессора:
Tc = tpcq
Задержка самой длинной цепи комбинационной логики многотактного процессора:
Tc = tpcq

Tc = ?
Посчитаем производительность многотактного процессора
Tc = ?
Посчитаем производительность многотактного процессора

Tc = tpcq_PC + tmux + max(tALU + tmux, tmem) +
Tc = tpcq_PC + tmux + max(tALU + tmux, tmem) +

Предположим, в программе 100 миллиардов инструкций:
CPI = 4.12
Tc = 325 пс
Время
Предположим, в программе 100 миллиардов инструкций:
CPI = 4.12
Tc = 325 пс
Время
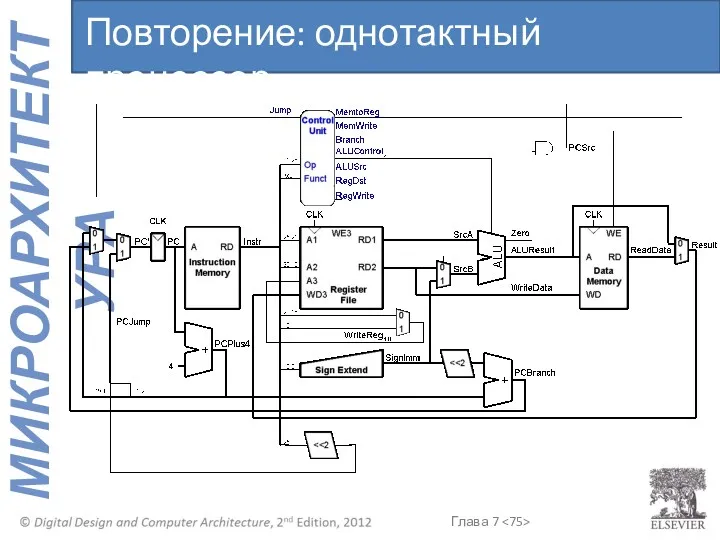
Повторение: однотактный процессор
Повторение: однотактный процессор
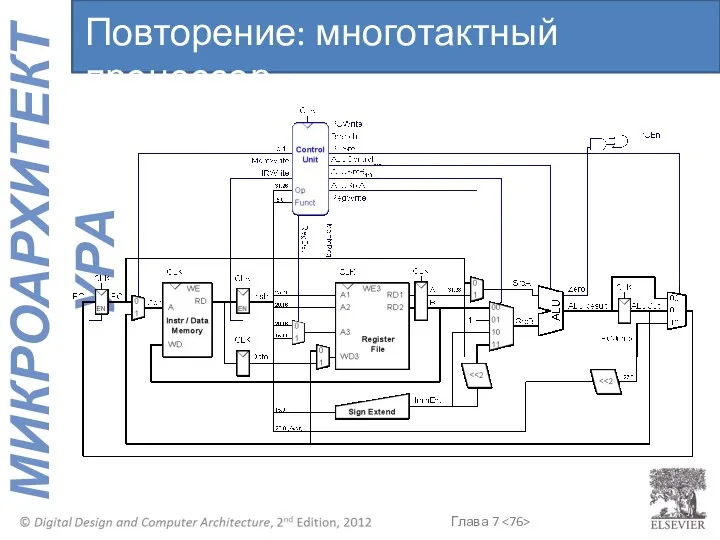
Повторение: многотактный процессор
Повторение: многотактный процессор

Временной параллелизм
Разделим однотактный процессор на 5 стадий:
Выборка
Декодирование
Выполнение
Доступ к памяти
Запись результатов
Добавим регистры
Временной параллелизм
Разделим однотактный процессор на 5 стадий:
Выборка
Декодирование
Выполнение
Доступ к памяти
Запись результатов
Добавим регистры
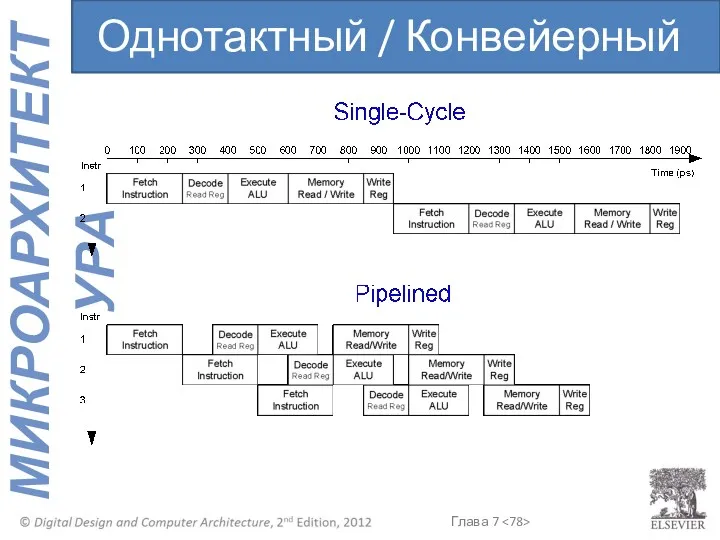
Однотактный / Конвейерный
Однотактный / Конвейерный

Абстрактное представление конвейера
Абстрактное представление конвейера
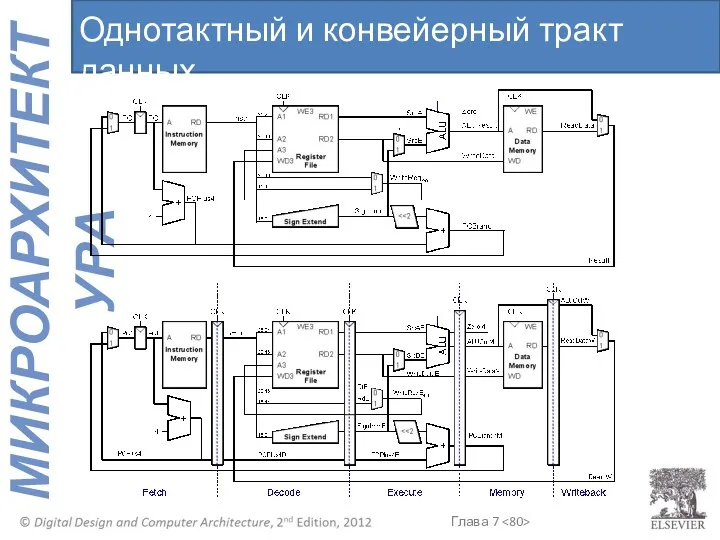
Однотактный и конвейерный тракт данных
Однотактный и конвейерный тракт данных
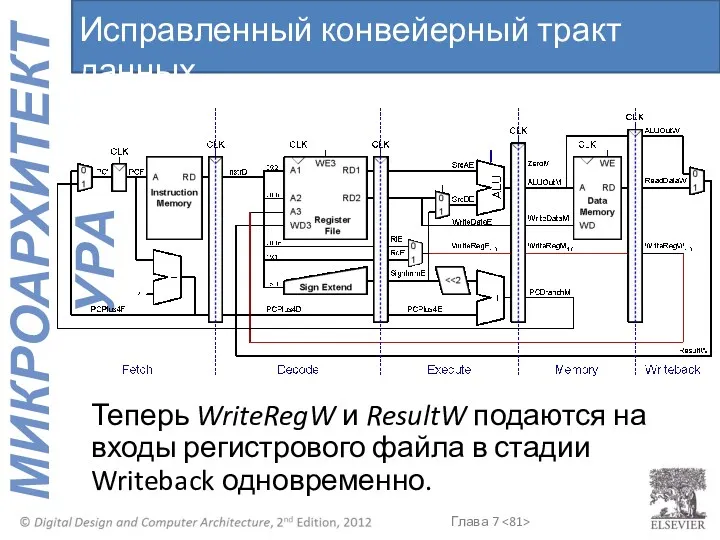
Теперь WriteRegW и ResultW подаются на входы регистрового файла в стадии
Теперь WriteRegW и ResultW подаются на входы регистрового файла в стадии
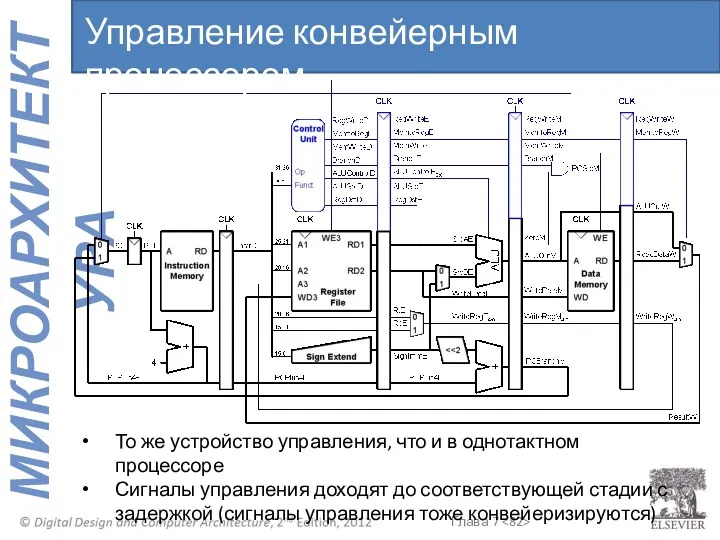
То же устройство управления, что и в однотактном процессоре
Сигналы управления доходят
То же устройство управления, что и в однотактном процессоре
Сигналы управления доходят

В конвейере выполняется несколько инструкций одновременно
Конфликты случаются когда одна инструкция зависит
В конвейере выполняется несколько инструкций одновременно
Конфликты случаются когда одна инструкция зависит

Конфликты данных
Конфликты данных

Можно вставлять пустые инструкции (nop) в код программы перед компиляцией или
Можно вставлять пустые инструкции (nop) в код программы перед компиляцией или

Вставить в код достаточно пустых инструкций (nop), которые будут заполнять стадии
Вставить в код достаточно пустых инструкций (nop), которые будут заполнять стадии

Передача данных между стадиями (Forwarding, Bypass)
Передача данных между стадиями (Forwarding, Bypass)
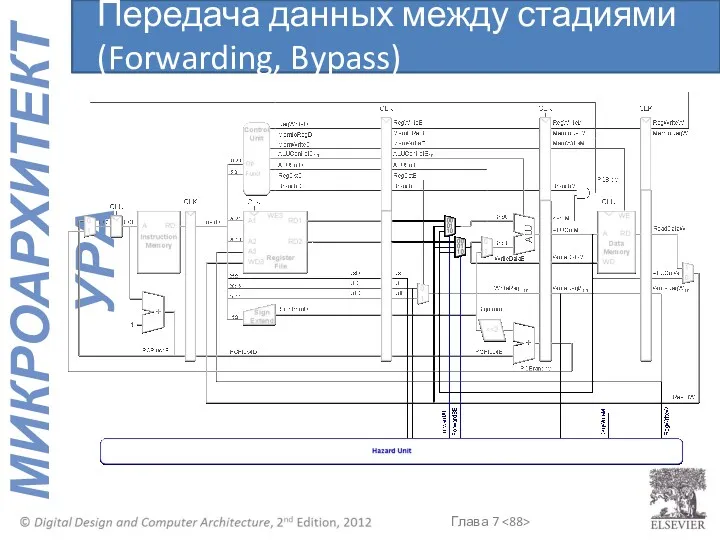
Передача данных между стадиями (Forwarding, Bypass)
Передача данных между стадиями (Forwarding, Bypass)

Можно передавать необходимые данные на этап Выполнения с этапов:
Доступа к памяти
Можно передавать необходимые данные на этап Выполнения с этапов:
Доступа к памяти
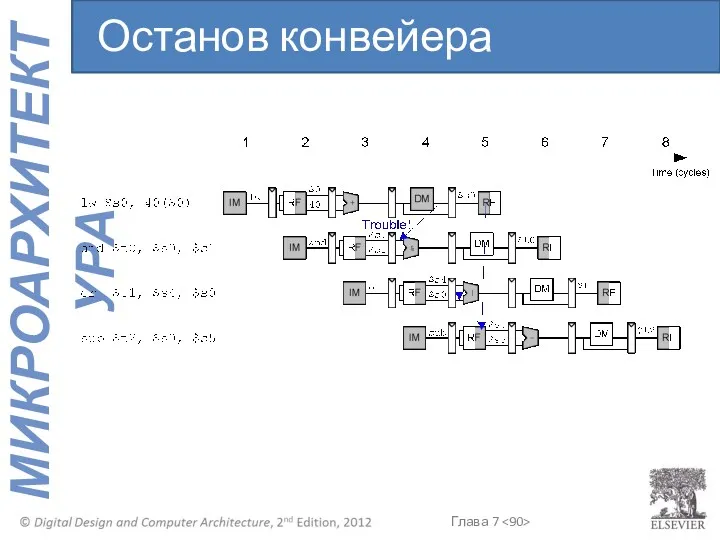
Останов конвейера
Останов конвейера

Останов конвейера
Останов конвейера
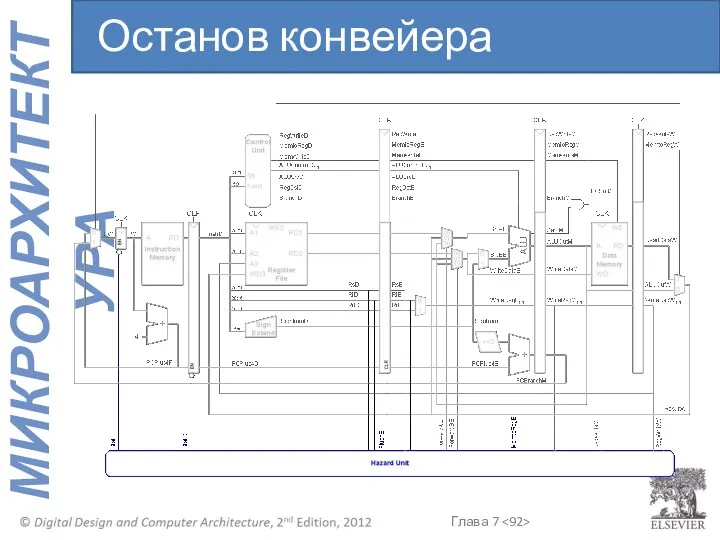
Останов конвейера
Останов конвейера

lwstall =
((rsD==rtE) OR (rtD==rtE)) AND MemtoRegE
StallF = StallD = FlushE
lwstall =
((rsD==rtE) OR (rtD==rtE)) AND MemtoRegE
StallF = StallD = FlushE

beq:
Будет выполнен условный переход или нет становится известно только на
beq:
Будет выполнен условный переход или нет становится известно только на
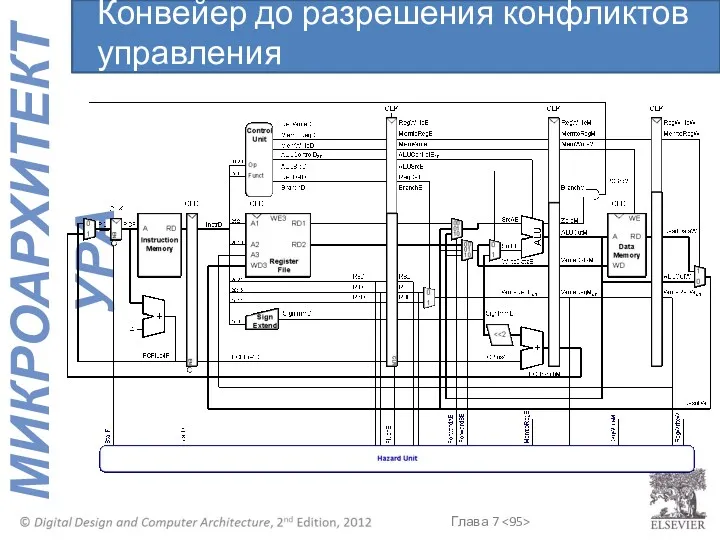
Конвейер до разрешения конфликтов управления
Конвейер до разрешения конфликтов управления

Конфликты управления
Конфликты управления
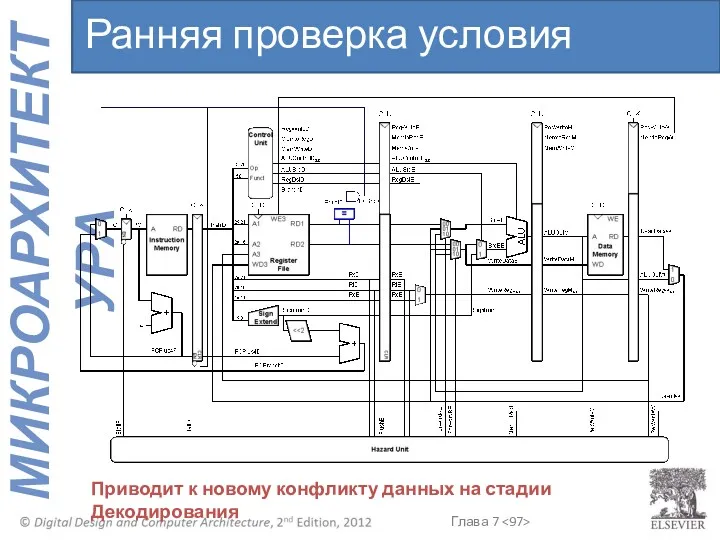
Приводит к новому конфликту данных на стадии Декодирования
Ранняя проверка условия перехода
Приводит к новому конфликту данных на стадии Декодирования
Ранняя проверка условия перехода

Ранняя проверка условия перехода
Инструкцию загруженную в конвейер после beq не обязательно
Ранняя проверка условия перехода
Инструкцию загруженную в конвейер после beq не обязательно
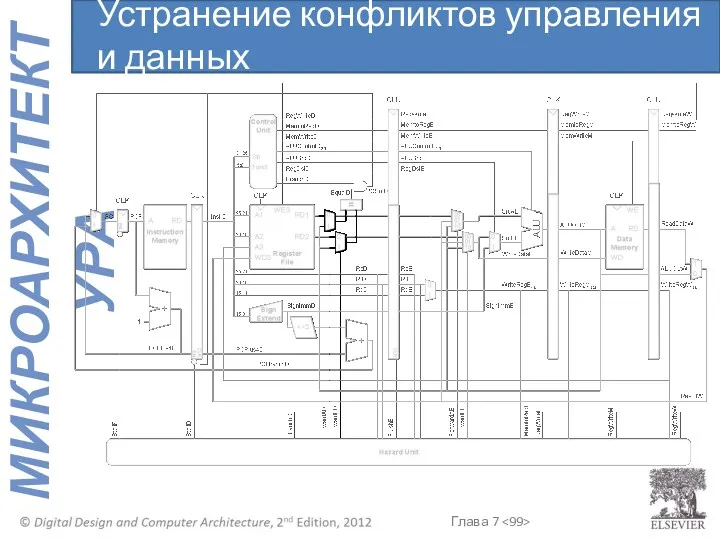
Устранение конфликтов управления и данных
Устранение конфликтов управления и данных

Логика управления передачей данных между стадиями конвейера (Forwarding logic):
ForwardAD = (rsD
Логика управления передачей данных между стадиями конвейера (Forwarding logic):
ForwardAD = (rsD

Мы можем попробовать оценить на сколько вероятно выполнение условного перехода и
Мы можем попробовать оценить на сколько вероятно выполнение условного перехода и

Тестовый набор SPECINT2000 содержит :
25% инструкций lw
10% инструкций sw
11% условных
Тестовый набор SPECINT2000 содержит :
25% инструкций lw
10% инструкций sw
11% условных

Тестовый набор SPECINT2000 содержит :
25% инструкций lw
10% инструкций sw
11% условных
Тестовый набор SPECINT2000 содержит :
25% инструкций lw
10% инструкций sw
11% условных

Задержка самой длинной цепи комбинационной логики конвейерного процессора:
Tc = max
Задержка самой длинной цепи комбинационной логики конвейерного процессора:
Tc = max
Tc = 2(tRFread + tmux + teq + tAND + tmux
Tc = 2(tRFread + tmux + teq + tAND + tmux

Предположим, в программе 100 миллиардов инструкций
Время выполнения = (# инструкции)
Предположим, в программе 100 миллиардов инструкций
Время выполнения = (# инструкции)
Сравнение производительности
Сравнение производительности

Повторение: Исключения
Исключение (англ.: exception) – незапланированный вызов функции-обработчика исключения (exception handler)
Исключения
Повторение: Исключения
Исключение (англ.: exception) – незапланированный вызов функции-обработчика исключения (exception handler)
Исключения
Пример исключения
Пример исключения

Отдельные регистры. Не входят в регистровый файл
Cause
Содержит код причины исключения
Регистр 13
Отдельные регистры. Не входят в регистровый файл
Cause
Содержит код причины исключения
Регистр 13
Добавим в многотактный MIPS процессор возможность обработки последних двух типов исключений
Коды
Добавим в многотактный MIPS процессор возможность обработки последних двух типов исключений
Коды
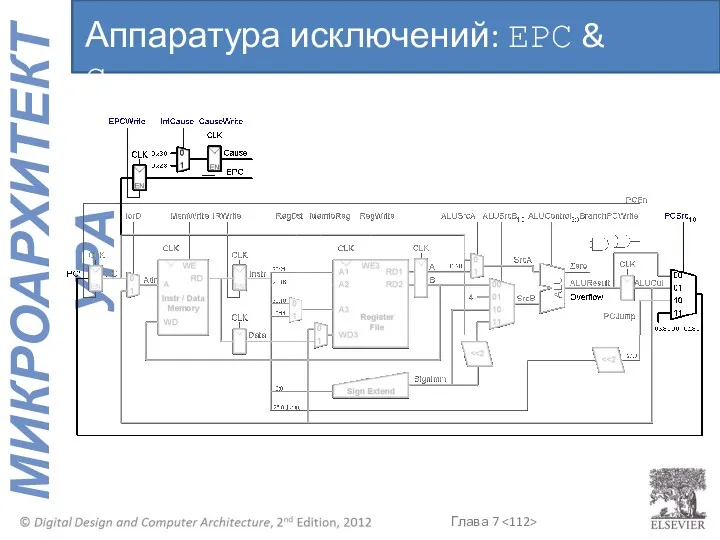
Аппаратура исключений: EPC & Cause
Аппаратура исключений: EPC & Cause
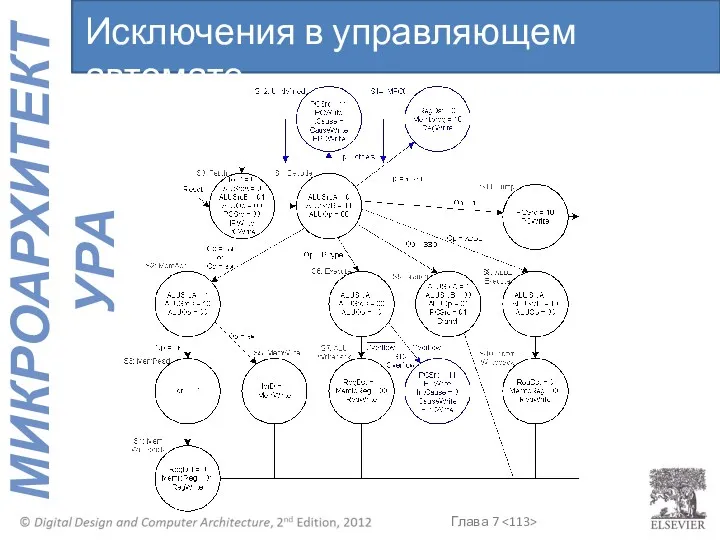
Исключения в управляющем автомате
Исключения в управляющем автомате
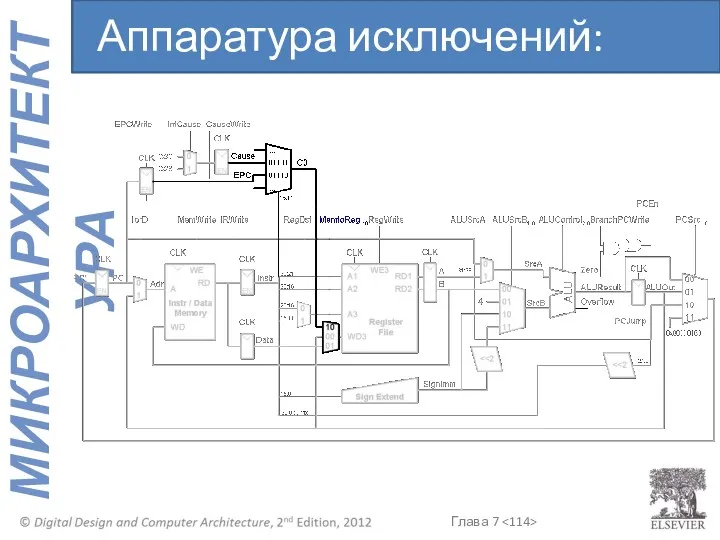
Аппаратура исключений: mfc0
Аппаратура исключений: mfc0

Длинные конвейеры
Динамическое предсказание переходов
Суперскалярные процессоры
Процессоры с внеочередным выполнением инструкций
Переименование регистров
SIMD
Многопоточность
Многопроцессорность
Улучшения микроархитектуры
Длинные конвейеры
Динамическое предсказание переходов
Суперскалярные процессоры
Процессоры с внеочередным выполнением инструкций
Переименование регистров
SIMD
Многопоточность
Многопроцессорность
Улучшения микроархитектуры

Содержат 10-20 стадий
Количество стадий ограничивается:
Конфликтами конвейера
Энергопотреблением
Стоимостью
Увеличением задержки тактового сигнала
Длинные конвейеры
Содержат 10-20 стадий
Количество стадий ограничивается:
Конфликтами конвейера
Энергопотреблением
Стоимостью
Увеличением задержки тактового сигнала
Длинные конвейеры

У идеального конвейерного процессора: CPI = 1
Неверное предсказание переходов увеличивает CPI
Статическое
У идеального конвейерного процессора: CPI = 1
Неверное предсказание переходов увеличивает CPI
Статическое

add $s1, $0, $0 # sum = 0
add $s0,
add $s1, $0, $0 # sum = 0
add $s0,

Запоминает, был ли переход выполнен в прошлый раз, и предсказывает, что
Запоминает, был ли переход выполнен в прошлый раз, и предсказывает, что
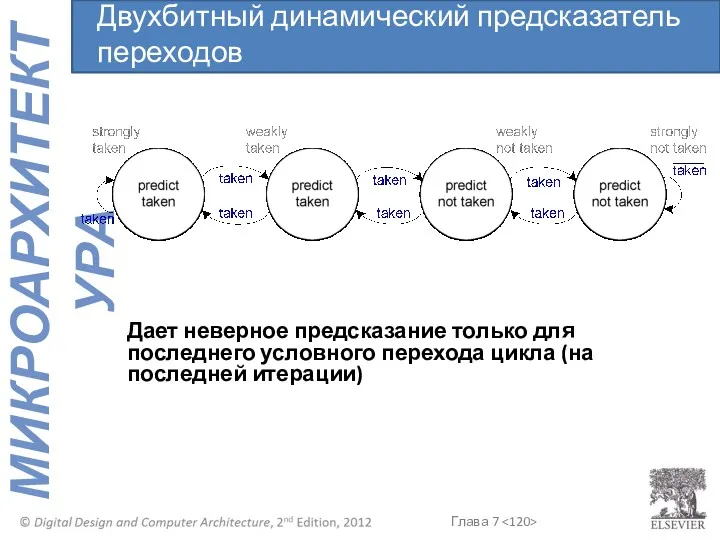
Дает неверное предсказание только для последнего условного перехода цикла (на последней
Дает неверное предсказание только для последнего условного перехода цикла (на последней
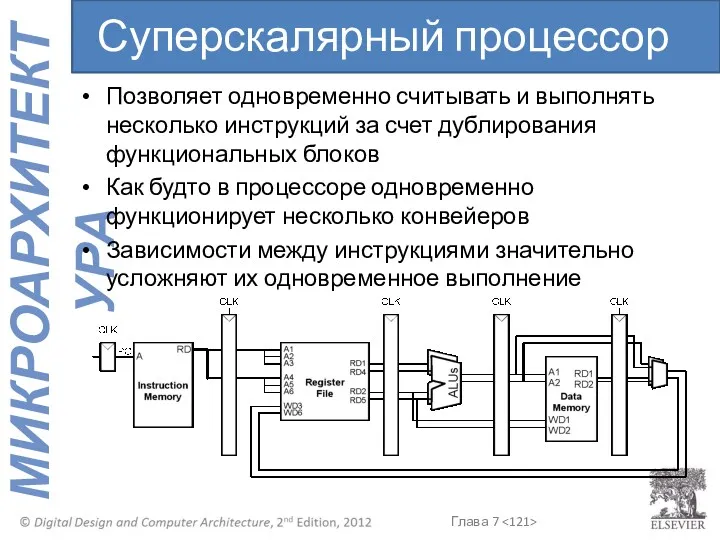
Позволяет одновременно считывать и выполнять несколько инструкций за счет дублирования функциональных
Позволяет одновременно считывать и выполнять несколько инструкций за счет дублирования функциональных

lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:

lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:

Процессор заранее просматривает наперед большое количество инструкций, находит независимые друг от
Процессор заранее просматривает наперед большое количество инструкций, находит независимые друг от

Параллелизм на уровне инструкций (Instruction level parallelism, ILP): число инструкций, которые
Параллелизм на уровне инструкций (Instruction level parallelism, ILP): число инструкций, которые
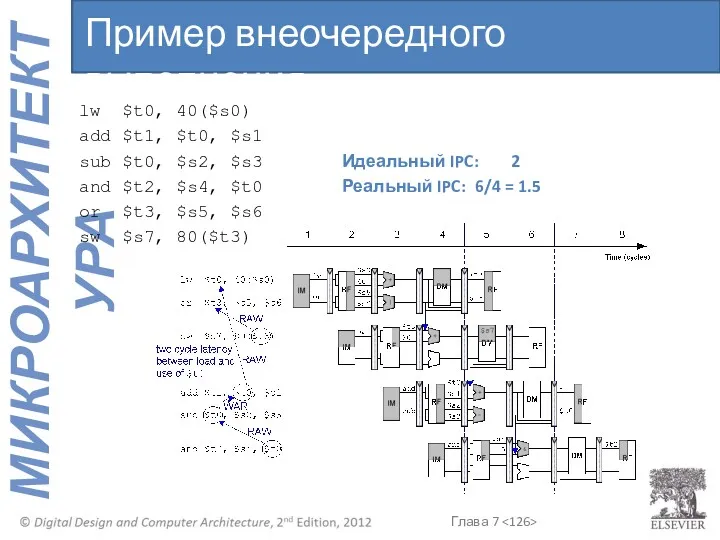
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:

lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3 Идеальный IPC:

Одиночный поток команд, множественный поток данных (Single Instruction Multiple Data, SIMD)
Одна
Одиночный поток команд, множественный поток данных (Single Instruction Multiple Data, SIMD)
Одна

Многопоточность
Например, в текстовом редакторе один поток может отвечать за обработку вводимых
Многопоточность
Например, в текстовом редакторе один поток может отвечать за обработку вводимых

Процесс: программа, которая выполняется на компьютере
Несколько процессов могут выполняться одновременно, например:
Процесс: программа, которая выполняется на компьютере
Несколько процессов могут выполняться одновременно, например:

В каждый момент времени выполняется один поток
Когда выполнение потока блокируется (например,
В каждый момент времени выполняется один поток
Когда выполнение потока блокируется (например,

У многопоточного процессора есть несколько копий архитектурного состояния
Несколько потоков могут быть
У многопоточного процессора есть несколько копий архитектурного состояния
Несколько потоков могут быть

Многопроцессорная система (multiprocessor system), или просто мультипроцессор, состоит из нескольких процессоров
Многопроцессорная система (multiprocessor system), или просто мультипроцессор, состоит из нескольких процессоров
 Использование информационных технологий
Использование информационных технологий Получение квалифицированной электронной подписи (КЭП)
Получение квалифицированной электронной подписи (КЭП) Фотомонтаж и коллаж. Возможности графической программы Adobe Photoshop
Фотомонтаж и коллаж. Возможности графической программы Adobe Photoshop Признаки, определяющие поколение ЭВМ
Признаки, определяющие поколение ЭВМ Разработка интернет-магазина по продаже спортивного питания ИП Беляев
Разработка интернет-магазина по продаже спортивного питания ИП Беляев Представление информации. Языки. Кодирование
Представление информации. Языки. Кодирование Оптимізація топології гетерогенної комп’ютерної мережі навчального закладу
Оптимізація топології гетерогенної комп’ютерної мережі навчального закладу Хранимые процедуры
Хранимые процедуры Презентация Диагонали в двумерных массивах, 9,10 класс
Презентация Диагонали в двумерных массивах, 9,10 класс Защиты информации от несанкционированного доступа
Защиты информации от несанкционированного доступа Устройства памяти ЭВМ
Устройства памяти ЭВМ Веселая Информатика. Игра
Веселая Информатика. Игра Автоматизация офиса
Автоматизация офиса Итоги проведения профессионального конкурса рефератов
Итоги проведения профессионального конкурса рефератов Игровые персонажи Dota 2
Игровые персонажи Dota 2 Курсы международной школы программирования Алгоритмика 2019–2020
Курсы международной школы программирования Алгоритмика 2019–2020 Файлы. Потоки
Файлы. Потоки 1С - ИТС ПРОФ. Сервисы включенные в договор сопровождения
1С - ИТС ПРОФ. Сервисы включенные в договор сопровождения Работа с таблицами
Работа с таблицами Қашықтықтан оқыту
Қашықтықтан оқыту 3D-Blender
3D-Blender Медиаландшафт Франции
Медиаландшафт Франции Написання програм
Написання програм Сервисная компания по предоставлению ИТ и Телеком услуг АО НВБС
Сервисная компания по предоставлению ИТ и Телеком услуг АО НВБС Синхронизация потоков
Синхронизация потоков Система электронного документооборота. ёЛогика. Особенности для делопроизводителя
Система электронного документооборота. ёЛогика. Особенности для делопроизводителя Основные понятия объектно-ориентированного программирования
Основные понятия объектно-ориентированного программирования Решение задач ЕГЭ типа В12
Решение задач ЕГЭ типа В12