- Управление наборами данных. Чтение и запись данных

Содержание
- 2. 1. Работа с наборами данных Доступ к элементам структур данных В R используются несколько операторов для
- 3. > x > x[1] [1] "a" > x[2] [1] "b" > x[1:4] [1] "a" "b" "c"
- 4. Доступ к элементам матриц Доступ к элементам матриц осуществляется с использованием индексов в квадратных скобках –
- 5. По умолчанию возвращается вектор единичной длины того же класса что и исходный объект. Для получения объекта
- 6. Доступ к элементам списка Для доступа к элементам списка можно использовать – “[”, “[[”, “$”. >
- 7. > x > x[c(1, 3)] $foo [1] 1 2 3 4 $baz [1] "hello"
- 8. Оператор “[[” используется с индексами и именами, а “$” - только с именами объектов. “$” упрощает
- 9. Оператор “[[” может принимать последовательность целых чисел и рекурсивно извлекать элементы из вложенного списка. > x
- 10. Частичное совпадение (Partial matching) Partial matching – определение элемента по его первым буквам имени. Используется для
- 11. Часто в ходе обработки данных необходимо найти и удалить из элементов объекта пропущенные значения типа NA
- 12. Если необходимо сравнить два объекта и выделить пары соответственных элементов с непропущенными значениями, то используется функция
- 13. > airquality[1:6, ] Ozone Solar.R Wind Temp Month Day 1 41 190 7.4 67 5 1
- 14. Векторные операции (Vectorized operations) В R можно осуществлять операции над векторами. Это позволяет значительно упростить программный
- 15. Аналогично векторные операции осуществляются над матрицами. > x > x * y ## element-wise multiplication [,1]
- 16. 2. Чтение и запись данных Чтение данных Для чтения данных в R используются несколько базовых функций:
- 17. Запись данных Для записи данных используются функции: write.table – запись табулированных данных writeLines – запись текстовых
- 18. Read.table read.table(file, header, …) одна из основных функций чтения небольших табулированных данных. Рассмотрим основные управляющие аргументы
- 19. nrows – определяет число строк, которое должно быть считано из файла. comment.char – указывает, что является
- 20. Read.table Для небольших наборов данных рекомендуется использовать read.table с параметрами по умолчанию. data В результате выполнения
- 21. Для интерактивного выбора загружаемого файла, который хранится вне рабочей папки, можно использовать вспомогательную функцию file.choose. Выполнение
- 22. dput, dget Для работы с текстовыми данными (не табулированными) используются функции dput, dget. Преимущество хранения данных
- 23. Dump, source Функция dump позволяет записывать сразу несколько объектов. Для восстановления объектов из текстовых файлов используется
- 24. Функции установления соединений с внешними источниками данных Существует несколько альтернативных способов для установления соединения (connection) с
- 25. file > str(file) function (description = "", open = "", blocking = TRUE, encoding = getOption("encoding"))
- 26. connection позволяет упростить работу с большими файлами, когда нет необходимости загружать весь исходный файл данных. То
- 27. readLines В режиме connection можно использовать функцию readLines для чтения заданного количества строк из файлов. >
- 28. readLines Возможно чтение строк из web-страниц. ## This might take time con x > head(x) [1]
- 29. Полезные функции Подлежащий импортированию файл рекомендуется разместить в рабочей папке. Для отображения рабочей папки используется функция
- 30. Полезные функции ls – выводит на экран список объектов в текущем рабочем пространстве. > ls( )
- 32. Скачать презентацию

1. Работа с наборами данных
Доступ к элементам структур данных
В R используются
1. Работа с наборами данных
Доступ к элементам структур данных
В R используются
![> x > x[1] [1] "a" > x[2] [1] "b"](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/357470/slide-2.jpg)
> x <- c("a", "b", "c", "c", "d", "a")
> x[1]
[1] "a"
>
> x <- c("a", "b", "c", "c", "d", "a")
> x[1]
[1] "a"
>

Доступ к элементам матриц
Доступ к элементам матриц осуществляется с использованием индексов
Доступ к элементам матриц
Доступ к элементам матриц осуществляется с использованием индексов

По умолчанию возвращается вектор единичной длины того же класса что и
По умолчанию возвращается вектор единичной длины того же класса что и

Доступ к элементам списка
Для доступа к элементам списка можно использовать –
Доступ к элементам списка
Для доступа к элементам списка можно использовать –
![> x > x[c(1, 3)] $foo [1] 1 2 3 4 $baz [1] "hello"](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/357470/slide-6.jpg)
> x <- list(foo = 1:4, bar = 0.6, baz =
> x <- list(foo = 1:4, bar = 0.6, baz =

Оператор “[[” используется с индексами и именами, а “$” - только
Оператор “[[” используется с индексами и именами, а “$” - только

Оператор “[[” может принимать последовательность целых чисел и рекурсивно извлекать элементы
Оператор “[[” может принимать последовательность целых чисел и рекурсивно извлекать элементы

Частичное совпадение (Partial matching)
Partial matching – определение элемента по его первым
Частичное совпадение (Partial matching)
Partial matching – определение элемента по его первым

Часто в ходе обработки данных необходимо найти и удалить из элементов
Часто в ходе обработки данных необходимо найти и удалить из элементов

Если необходимо сравнить два объекта и выделить пары соответственных элементов с
Если необходимо сравнить два объекта и выделить пары соответственных элементов с
![> airquality[1:6, ] Ozone Solar.R Wind Temp Month Day 1](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/357470/slide-12.jpg)
> airquality[1:6, ]
Ozone Solar.R Wind Temp Month Day
1 41 190
> airquality[1:6, ]
Ozone Solar.R Wind Temp Month Day
1 41 190

Векторные операции (Vectorized operations)
В R можно осуществлять операции над векторами. Это
Векторные операции (Vectorized operations)
В R можно осуществлять операции над векторами. Это

Аналогично векторные операции осуществляются над матрицами.
> x <- matrix(1:4, 2,
Аналогично векторные операции осуществляются над матрицами.
> x <- matrix(1:4, 2,

2. Чтение и запись данных
Чтение данных
Для чтения данных в R используются
2. Чтение и запись данных
Чтение данных
Для чтения данных в R используются

Запись данных
Для записи данных используются функции:
write.table – запись табулированных данных
writeLines –
Запись данных
Для записи данных используются функции:
write.table – запись табулированных данных
writeLines –

Read.table
read.table(file, header, …) одна из основных функций чтения небольших табулированных данных.
Read.table
read.table(file, header, …) одна из основных функций чтения небольших табулированных данных.

nrows – определяет число строк, которое должно быть считано из файла.
comment.char
nrows – определяет число строк, которое должно быть считано из файла.
comment.char

Read.table
Для небольших наборов данных рекомендуется использовать read.table с параметрами по умолчанию.
Read.table
Для небольших наборов данных рекомендуется использовать read.table с параметрами по умолчанию.
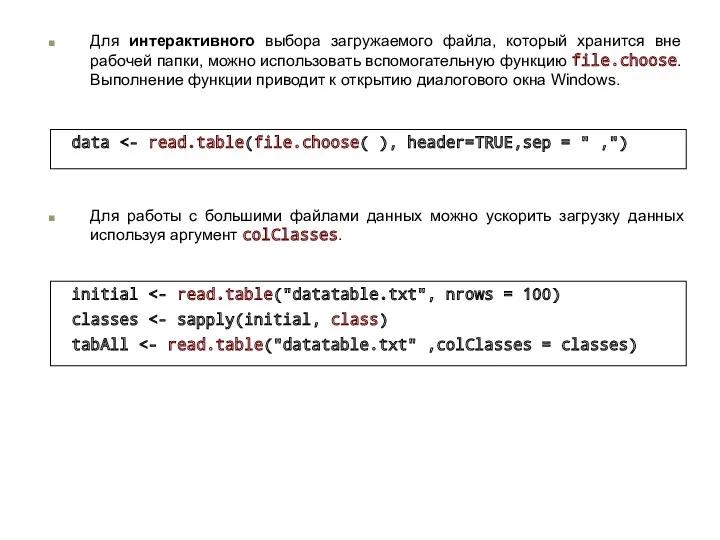
Для интерактивного выбора загружаемого файла, который хранится вне рабочей папки, можно
Для интерактивного выбора загружаемого файла, который хранится вне рабочей папки, можно

dput, dget
Для работы с текстовыми данными (не табулированными) используются функции dput,
dput, dget
Для работы с текстовыми данными (не табулированными) используются функции dput,

Dump, source
Функция dump позволяет записывать сразу несколько объектов. Для восстановления объектов
Dump, source
Функция dump позволяет записывать сразу несколько объектов. Для восстановления объектов

Функции установления соединений с внешними источниками данных
Существует несколько альтернативных способов для
Функции установления соединений с внешними источниками данных
Существует несколько альтернативных способов для

file
> str(file)
function (description = "", open = "", blocking = TRUE,
encoding
file
> str(file)
function (description = "", open = "", blocking = TRUE,
encoding
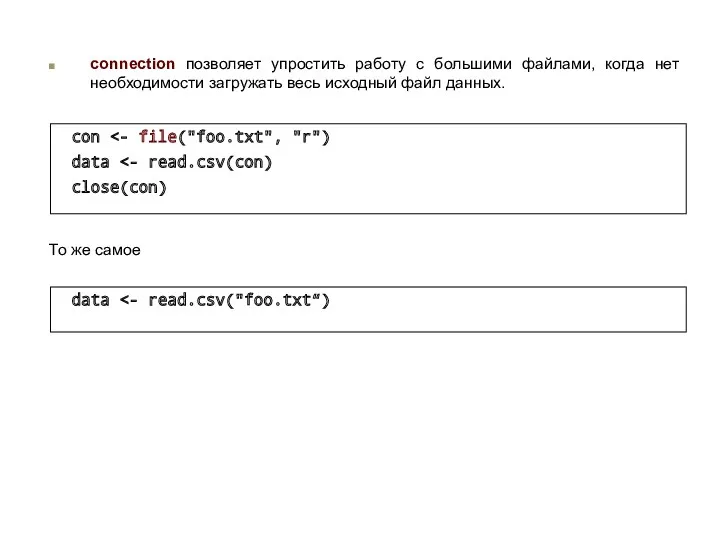
connection позволяет упростить работу с большими файлами, когда нет необходимости загружать
connection позволяет упростить работу с большими файлами, когда нет необходимости загружать

readLines
В режиме connection можно использовать функцию readLines для чтения заданного
readLines
В режиме connection можно использовать функцию readLines для чтения заданного

readLines
Возможно чтение строк из web-страниц.
## This might take time
con <- url("http://www.jhsph.edu",
readLines
Возможно чтение строк из web-страниц.
## This might take time
con <- url("http://www.jhsph.edu",

Полезные функции
Подлежащий импортированию файл рекомендуется разместить в рабочей папке. Для отображения
Полезные функции
Подлежащий импортированию файл рекомендуется разместить в рабочей папке. Для отображения

Полезные функции
ls – выводит на экран список объектов в текущем рабочем
Полезные функции
ls – выводит на экран список объектов в текущем рабочем
 Компьютерные сети их классификация. Работа в локальной сети. Топологии локальных сетей. Обмен данными
Компьютерные сети их классификация. Работа в локальной сети. Топологии локальных сетей. Обмен данными Компьютерная презентация практических достижений
Компьютерная презентация практических достижений Ввод и вывод (язык C, лекция 2)
Ввод и вывод (язык C, лекция 2) Электронная система здравохранения РК
Электронная система здравохранения РК Інформаційно-комунікаційні технології професійної діяльності педагога
Інформаційно-комунікаційні технології професійної діяльності педагога Технологии разработки программного обеспечения (ПО). Традиционные технологии разработки ПО
Технологии разработки программного обеспечения (ПО). Традиционные технологии разработки ПО Информационные ресурсы современного общества
Информационные ресурсы современного общества Проблемы анализа данных в медико-биологических исследованиях. StatSoft Russia
Проблемы анализа данных в медико-биологических исследованиях. StatSoft Russia Интернет-ресурсы успешного педагога
Интернет-ресурсы успешного педагога МК Python
МК Python Родительское собрание Безопасность детей в сети Интернет и интернет-угрозы для ребенка
Родительское собрание Безопасность детей в сети Интернет и интернет-угрозы для ребенка Технологии блокчейн
Технологии блокчейн Создание публикации в программе Microsoft Publisher
Создание публикации в программе Microsoft Publisher Базы данных MS Access
Базы данных MS Access Compass-3d
Compass-3d Технологии доступа к данным. ADO .NET
Технологии доступа к данным. ADO .NET Линия представления информации
Линия представления информации Применение ИКТ на уроках математики
Применение ИКТ на уроках математики Электронные таблицы. (7 класс)
Электронные таблицы. (7 класс) Беспроводной интернет, особенности и функционирования
Беспроводной интернет, особенности и функционирования Способи комунікації в мережі. Модуль 2. Урок 2
Способи комунікації в мережі. Модуль 2. Урок 2 Методы тестирования
Методы тестирования Методы сортировки массивов. Сортировка методом Пузырька
Методы сортировки массивов. Сортировка методом Пузырька История робототехники
История робототехники Летняя практика. Часть 4. Массивы
Летняя практика. Часть 4. Массивы Применение ИКТ на уроках музыки
Применение ИКТ на уроках музыки Бұлтты есептеу технологиясы
Бұлтты есептеу технологиясы Устройства ПК
Устройства ПК