- Анализ данных в иммунологии

Содержание
- 2. ЗАДАЧИ ИММУНОЛОГИЧЕСКИХ ИССЛЕДОВАНИЙ Определение связи между несколькими иммунологическими и/или иными показателями без предположения о том, что
- 3. Этапы анализа данных
- 4. ОСНОВНЫЕ ПОНЯТИЯ СТАТИСТИКИ Совокупность – это всякое множество отдельных объектов, отличающихся друг от друга и в
- 5. Генеральная совокупность Выборочная совокупность
- 6. Репрезентативность - свойство выборочной совокупности отражать основные, важные для исследования, характеристики генеральной совокупности. Репрезентативность определяет, насколько
- 7. Типы данных Количественные Качественные Дискретные Непрерывные Номинальные Порядковые Дихотомические
- 8. Типы данных Количественные Различия равновелики Непрерывные (напр., кровяное давление, масса тела, рост, возраст, биохимические показатели крови)
- 9. Типы данных Качественные Порядковые (отражают условную степень выраженности признака) Можно ранжировать, но различия между категориями не
- 10. Качественные Номинальные (отражают условные коды неизмеряемых категорий) Коды диагнозов Коды пола: мужской, женский Раса: белая, черная,
- 11. Для различных переменных и шкал применяются разные методы статистического анализа !!!
- 12. Виды статистических пакетов Универсальные пакеты - отсутствие прямой ориентации на специфическую предметную область, предлагают широкий диапазон
- 13. STATISTICA - это универсальная интегрированная система, предназначенная для статистического анализа и визуализации данных, управления базами данных
- 14. Система обладает следующими общепризнанными достоинствами: содержит полный набор классических методов анализа данных; отвечает всем стандартам Windows;
- 15. Основные формы представления выборки из генеральной совокупности 1. Представление выборки в несгрупированном виде, путём обычного перечисления
- 16. Представление выборки в сгруппированном виде, когда вместе с вариантами указываются числа (называемые частотами), равными числу повторений
- 17. Способы графического изображения данных Гистограмма Полигон распределения
- 18. Первым этапом анализа количественных данных является анализ вида их распределения
- 19. Кривая нормального распределения 68% всех наблюдений лежат в диапазоне ±1 стандартное отклонение от среднего, а диапазон
- 20. Проверка соответствия распределения нормальному закону выборочные среднее, медиана и мода должны быть близки по значению и
- 21. Статистические критерии для проверки нормальности распределения Критерий согласия χ2 Пирсона (Pearson). Критерий Колмогорова-Смирнова (Kolmogorov-Smirnov). Применяется, если
- 22. Как часто встречается нормальное распределение??? Можно сказать, что из всех распределений в природе чаще всего встречается
- 23. Статистические методы Описание данных Оценка статистической значимости результатов исследования (проверка гипотез)
- 24. Способы описания данных Точечные характеристики • Мода • Медиана • Средняя Характеристики вариации • Размах колебаний
- 25. Точечные характеристики (меры центральной тенденции) Среднее арифметическое (среднее) Медиана (Ме) - это средняя (центральная) варианта, делящая
- 26. Характеристики вариации (меры рассеяния) Стандартное отклонение (σ) – величина, отражающая вариабельность данных относительно средней арифметической Межквартильный
- 27. Описание данных Описание данных зависит от их типа (качественные или количественные) и способа их распределения !
- 28. Описание данных в зависимости от их типа Количественные Для описания используется среднее или медиана Качественные (номинальные)
- 29. Какую среднюю величину использовать? Нормальное или ненормальное распределение ?
- 30. Методы описания данных Параметрический метод: для нормально распределенных количественных данных Для описания используется среднее арифметическое и
- 32. Скачать презентацию

ЗАДАЧИ ИММУНОЛОГИЧЕСКИХ ИССЛЕДОВАНИЙ
Определение связи между несколькими иммунологическими и/или иными показателями
ЗАДАЧИ ИММУНОЛОГИЧЕСКИХ ИССЛЕДОВАНИЙ
Определение связи между несколькими иммунологическими и/или иными показателями

Этапы анализа данных
Этапы анализа данных

ОСНОВНЫЕ ПОНЯТИЯ СТАТИСТИКИ
Совокупность – это всякое множество отдельных объектов, отличающихся друг
ОСНОВНЫЕ ПОНЯТИЯ СТАТИСТИКИ
Совокупность – это всякое множество отдельных объектов, отличающихся друг

Генеральная совокупность
Выборочная совокупность
Генеральная совокупность
Выборочная совокупность

Репрезентативность - свойство выборочной совокупности отражать основные, важные для исследования, характеристики
Репрезентативность - свойство выборочной совокупности отражать основные, важные для исследования, характеристики
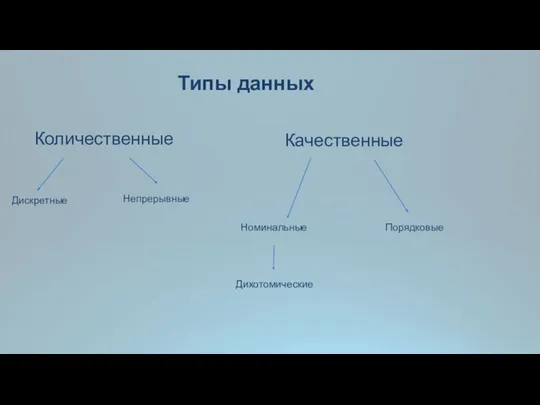
Типы данных
Количественные
Качественные
Дискретные
Непрерывные
Номинальные
Порядковые
Дихотомические
Типы данных
Количественные
Качественные
Дискретные
Непрерывные
Номинальные
Порядковые
Дихотомические

Типы данных
Количественные
Различия равновелики
Непрерывные (напр., кровяное давление, масса тела, рост, возраст,
Типы данных
Количественные
Различия равновелики
Непрерывные (напр., кровяное давление, масса тела, рост, возраст,

Типы данных
Качественные
Порядковые (отражают условную степень выраженности признака)
Можно ранжировать, но различия между
Типы данных
Качественные
Порядковые (отражают условную степень выраженности признака)
Можно ранжировать, но различия между

Качественные
Номинальные (отражают условные коды неизмеряемых категорий)
Коды диагнозов
Коды пола: мужской, женский
Раса:
Качественные
Номинальные (отражают условные коды неизмеряемых категорий)
Коды диагнозов
Коды пола: мужской, женский
Раса:

Для различных переменных и шкал применяются
разные методы статистического анализа !!!
Для различных переменных и шкал применяются
разные методы статистического анализа !!!

Виды статистических пакетов
Универсальные пакеты
- отсутствие прямой ориентации на специфическую
Виды статистических пакетов Универсальные пакеты - отсутствие прямой ориентации на специфическую

STATISTICA - это универсальная интегрированная система, предназначенная для статистического анализа и
STATISTICA - это универсальная интегрированная система, предназначенная для статистического анализа и

Система обладает следующими общепризнанными достоинствами:
содержит полный набор классических методов анализа
Система обладает следующими общепризнанными достоинствами:
содержит полный набор классических методов анализа

Основные формы представления выборки
из генеральной совокупности
1. Представление выборки в несгрупированном виде,
Основные формы представления выборки
из генеральной совокупности
1. Представление выборки в несгрупированном виде,

Представление выборки в сгруппированном виде, когда вместе с вариантами указываются числа
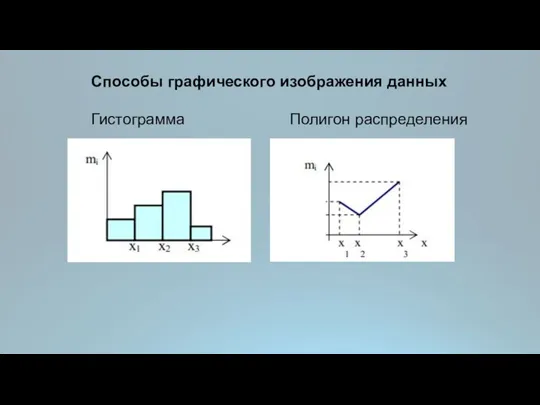
Способы графического изображения данных
Гистограмма Полигон распределения
Гистограмма Полигон распределения

Первым этапом анализа количественных данных является анализ вида их распределения
Первым этапом анализа количественных данных является анализ вида их распределения
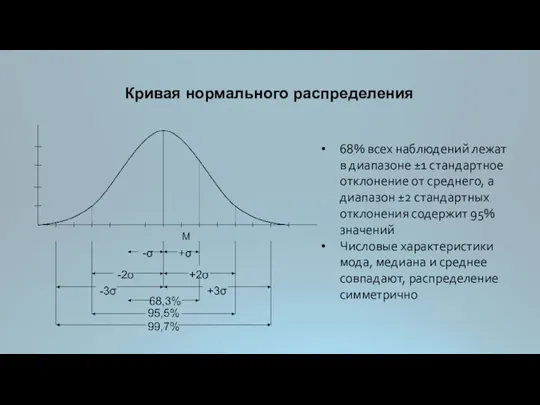
Кривая нормального распределения
68% всех наблюдений лежат в диапазоне ±1 стандартное отклонение
Кривая нормального распределения
68% всех наблюдений лежат в диапазоне ±1 стандартное отклонение

Проверка соответствия распределения нормальному закону
выборочные среднее, медиана и мода должны быть
Проверка соответствия распределения нормальному закону
выборочные среднее, медиана и мода должны быть

Статистические критерии для проверки нормальности распределения
Критерий согласия χ2 Пирсона (Pearson).
Критерий Колмогорова-Смирнова
Статистические критерии для проверки нормальности распределения
Критерий согласия χ2 Пирсона (Pearson).
Критерий Колмогорова-Смирнова

Как часто встречается нормальное распределение???
Можно сказать, что из всех распределений в
Как часто встречается нормальное распределение???
Можно сказать, что из всех распределений в

Статистические методы
Описание данных
Оценка статистической значимости результатов исследования (проверка гипотез)
Статистические методы
Описание данных
Оценка статистической значимости результатов исследования (проверка гипотез)

Способы описания данных
Точечные характеристики
• Мода
• Медиана
• Средняя
Характеристики
Способы описания данных
Точечные характеристики
• Мода
• Медиана
• Средняя
Характеристики

Точечные характеристики
(меры центральной тенденции)
Среднее арифметическое (среднее)
Медиана (Ме) - это средняя (центральная)
Точечные характеристики
(меры центральной тенденции)
Среднее арифметическое (среднее)
Медиана (Ме) - это средняя (центральная)

Характеристики вариации (меры рассеяния)
Стандартное отклонение (σ) – величина, отражающая вариабельность данных
Характеристики вариации (меры рассеяния)
Стандартное отклонение (σ) – величина, отражающая вариабельность данных

Описание данных
Описание данных зависит от их типа (качественные или количественные) и
Описание данных
Описание данных зависит от их типа (качественные или количественные) и

Описание данных в зависимости от их типа
Количественные
Для описания используется среднее или
Описание данных в зависимости от их типа
Количественные
Для описания используется среднее или

Какую среднюю величину использовать?
Нормальное
или
ненормальное распределение ?
Какую среднюю величину использовать?
Нормальное
или
ненормальное распределение ?

Методы описания данных
Параметрический метод: для нормально распределенных количественных данных
Для описания используется
Методы описания данных
Параметрический метод: для нормально распределенных количественных данных
Для описания используется
 Простые и сложные проценты
Простые и сложные проценты Triangle. Inequalities
Triangle. Inequalities Презентация по математике Устный счет
Презентация по математике Устный счет Действия с дробями
Действия с дробями Урок по теме Доли
Урок по теме Доли Презентация к уроку математики Сложение и вычитание в пределах 20
Презентация к уроку математики Сложение и вычитание в пределах 20 Тема 4. Сети Петри
Тема 4. Сети Петри Математический диктант
Математический диктант Логарифмическая функция
Логарифмическая функция Числовые промежутки. Геометрическая и аналитическая модели числового промежутка
Числовые промежутки. Геометрическая и аналитическая модели числового промежутка Функция её свойства и график. Урок 2
Функция её свойства и график. Урок 2 Урок - практикум по решению задач части Геометрия ОГЭ по математике
Урок - практикум по решению задач части Геометрия ОГЭ по математике Умники и умницы. К внеурочному по математике
Умники и умницы. К внеурочному по математике Внеклассное мероприятие по математике Своя игра
Внеклассное мероприятие по математике Своя игра 02.2022 матем
02.2022 матем The Chain Rule
The Chain Rule Введение в биостатистику. Лекция 2
Введение в биостатистику. Лекция 2 Законы арифметических действий
Законы арифметических действий Свойства и график функции y=sinх
Свойства и график функции y=sinх Решение задач на отыскание части от целого и целого по его части
Решение задач на отыскание части от целого и целого по его части Вычисления вида 7+ 8, 15 - 8
Вычисления вида 7+ 8, 15 - 8 Урок математики для 1 класса Число и цифра 4
Урок математики для 1 класса Число и цифра 4 Умножение рациональных чисел
Умножение рациональных чисел Задачи на смекалку
Задачи на смекалку Үш таңбалы сандарды ауызша қосу және азайту. Матем (1-т)
Үш таңбалы сандарды ауызша қосу және азайту. Матем (1-т) Методы искусственного базиса при решении ЗЛП. Лекция 3
Методы искусственного базиса при решении ЗЛП. Лекция 3 Алгебра як навчальний предмет, цілі вивчення і зміст, вимоги до мтематичної підготовки учнів
Алгебра як навчальний предмет, цілі вивчення і зміст, вимоги до мтематичної підготовки учнів Презентация урока математики на тему Компоненты сложения
Презентация урока математики на тему Компоненты сложения