Эконометрика. Обратная и пропорциональная модель парной линейной регрессии. Фиктивная линейная зависимость презентация
- Эконометрика. Обратная и пропорциональная модель парной линейной регрессии. Фиктивная линейная зависимость

Содержание
- 2. Задача состоит в оценивании модели прямолинейной связи между некоторыми переменными x и y на основе наблюдений
- 3. По первой модели наблюдений мы получаем наилучшую прямую а по второй – прямую Первую прямую мы
- 4. При получаем В то же время, При совпадают и отрезки на осях, т. е. наилучшая прямая
- 5. Пусть получены наблюдения , такие, что гипотетическая линейная связь между переменными и имеет вид (пропорциональная связь
- 6. Оценка единственного параметра пропорциональной модели будет: И, следовательно, а точка не лежит на полученной прямой .
- 7. выражение не имеет смысла. И можно воспользоваться формулой . Однако, такой подход к определению коэффициента детерминации
- 8. сумма квадратов, не центрированных значений переменной y (отклонений значений переменной y от «нулевого уровня»). При таком
- 9. Доказать заявленное равенство не сложно. Действительно, Но, что и приводит к искомому результату.
- 10. На практике часто встречаются ситуации, при которых существует заметный тренд (убывание или возрастание) в динамике изменений
- 11. и , значение будет тем ближе к 1, чем большим будет значение Последнее же обеспечивается совпадением
- 12. значение будет тем ближе к -1, чем меньшим будет значение Последнее же обеспечивается несовпадением знаков разностей
- 13. Свойства МНК-оценок параметров регрессии. Показатели качества регрессии
- 14. Способ оценивания дает состоятельные оценки, если при бесконечно большом объеме выборки значение статистической оценки стремится к
- 15. Докажем, что является несмещенной оценкой β. Если выполнены предпосылки нормальной линейной модели регрессии, то х –
- 16. Дисперсии МНК–оценок параметров регрессии будут где – дисперсия случайной составляющей, – дисперсия фактора х. А так
- 17. связывают с адекватностью модели по наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным
- 18. где – объясненная уравнением регрессии дисперсия результирующего признака, а – необъясненная уравнением регрессии дисперсия результирующего признака.
- 19. Теоретический коэффициент детерминации (индекс для нелинейных форм связей) . Этот коэффициент характеризует долю вариации (дисперсии) результирующего
- 20. Коэффициент (индекс) множественной корреляции рассчитывается как корень квадратный из коэффициента детерминации . Он тоже изменяется на
- 21. Средняя ошибка аппроксимации Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка
- 22. ПРОВЕРКА ГИПОТЕЗ О ЗНАЧИМОСТИ ПАРАМЕТРОВ РЕГРЕССИИ, КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ И УРАВНЕНИЯ РЕГРЕССИИ В ЦЕЛОМ
- 23. С помощью метода наименьших квадратов можно получить лишь оценки параметров модели, чтобы проверить, значимы ли они
- 24. Для проверки гипотез используют t–статистику распределения Стьюдента, критическое значение которой определяется по таблице (или с помощью
- 25. Для проверки гипотезы: β=0 статистика критерия будет где – оценка параметра β, полученная по наблюдаемым данным,
- 26. Для проверки гипотезы: α=0 статистика критерия будет В случае парной линейной регрессии:
- 27. Для проверки гипотез о незначительном отклонении от нуля «истинного» коэффициента линейной парной корреляции используют статистику при
- 28. Существует взаимосвязь Рассмотренная формула статистики критерия проверки гипотез применима, если: Оценки делаются по большому числу наблюдений
- 29. Если же величина выборочного коэффициента корреляции близка к 1, то распределение его оценок отличается от распределения
- 30. Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно ли уравнение для практического применения. Основная
- 31. ПРОГНОЗ ОЖИДАЕМОГО ЗНАЧЕНИЯ РЕЗУЛЬТИРУЮЩЕГО ПРИЗНАКА.
- 32. Предположим, необходимо определить для заданного значения фактора xp с доверительной вероятностью (1–α) прогнозируемое значение результирующего признака.
- 33. Вокруг линии регрессии образуется доверительный интервал («коридор», в который попадет прогнозируемое значение результирующего признака):
- 34. НЕЛИНЕЙНАЯ РЕГРЕССИЯ
- 35. Большинство экономических ситуаций характеризуются нелинейной зависимостью между результирующим и факторными признаками.
- 36. Полиномы различных степеней – yi=a0+ a1⋅xi+…+ am⋅xim+εi. Равностороння гипербола –
- 37. Степенная функция – ; Показательная функция – ; Экспоненциальная функция – .
- 39. Скачать презентацию

Задача состоит в оценивании модели прямолинейной связи между некоторыми переменными x
Задача состоит в оценивании модели прямолинейной связи между некоторыми переменными x

По первой модели наблюдений мы получаем наилучшую прямую
а по
По первой модели наблюдений мы получаем наилучшую прямую
а по

При получаем В то же время,
При совпадают и отрезки на
При получаем В то же время,
При совпадают и отрезки на

Пусть получены наблюдения , такие, что гипотетическая линейная связь между переменными
Пусть получены наблюдения , такие, что гипотетическая линейная связь между переменными

Оценка единственного параметра пропорциональной модели будет:
И, следовательно, а точка не лежит
И, следовательно, а точка не лежит

выражение не имеет смысла. И можно
воспользоваться формулой . Однако, такой
воспользоваться формулой . Однако, такой

сумма квадратов, не центрированных значений переменной y (отклонений значений переменной y
сумма квадратов, не центрированных значений переменной y (отклонений значений переменной y

Доказать заявленное равенство не сложно. Действительно,
Но,
что и приводит к искомому результату.
Доказать заявленное равенство не сложно. Действительно,
Но,
что и приводит к искомому результату.

На практике часто встречаются ситуации, при которых существует заметный тренд (убывание
На практике часто встречаются ситуации, при которых существует заметный тренд (убывание

и , значение будет тем ближе к 1, чем большим
и , значение будет тем ближе к 1, чем большим

значение будет тем ближе к -1, чем меньшим будет значение Последнее
значение будет тем ближе к -1, чем меньшим будет значение Последнее

Свойства МНК-оценок параметров регрессии. Показатели качества регрессии
Свойства МНК-оценок параметров регрессии. Показатели качества регрессии

Способ оценивания дает состоятельные оценки, если при бесконечно большом объеме выборки
Способ оценивания дает состоятельные оценки, если при бесконечно большом объеме выборки

Докажем, что является несмещенной оценкой β. Если выполнены предпосылки нормальной линейной
Докажем, что является несмещенной оценкой β. Если выполнены предпосылки нормальной линейной

Дисперсии МНК–оценок параметров регрессии будут
где – дисперсия случайной составляющей, – дисперсия
Дисперсии МНК–оценок параметров регрессии будут
где – дисперсия случайной составляющей, – дисперсия

связывают с адекватностью модели по наблюдаемым (эмпирическим) данным. Проверка адекватности (или
связывают с адекватностью модели по наблюдаемым (эмпирическим) данным. Проверка адекватности (или

где – объясненная уравнением регрессии
дисперсия результирующего признака, а
– необъясненная уравнением
дисперсия результирующего признака, а
– необъясненная уравнением

Теоретический коэффициент детерминации (индекс для нелинейных форм связей)
. Этот
Теоретический коэффициент детерминации (индекс для нелинейных форм связей)
. Этот

Коэффициент (индекс) множественной корреляции рассчитывается как корень квадратный из коэффициента
детерминации
Коэффициент (индекс) множественной корреляции рассчитывается как корень квадратный из коэффициента
детерминации

Средняя ошибка аппроксимации
Чем меньше рассеяние эмпирических точек вокруг теоретической линии
Чем меньше рассеяние эмпирических точек вокруг теоретической линии

ПРОВЕРКА ГИПОТЕЗ О ЗНАЧИМОСТИ ПАРАМЕТРОВ РЕГРЕССИИ, КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ И УРАВНЕНИЯ РЕГРЕССИИ
ПРОВЕРКА ГИПОТЕЗ О ЗНАЧИМОСТИ ПАРАМЕТРОВ РЕГРЕССИИ, КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ И УРАВНЕНИЯ РЕГРЕССИИ

С помощью метода наименьших квадратов можно получить лишь оценки параметров модели,
С помощью метода наименьших квадратов можно получить лишь оценки параметров модели,

Для проверки гипотез используют t–статистику распределения Стьюдента, критическое значение которой определяется
Для проверки гипотез используют t–статистику распределения Стьюдента, критическое значение которой определяется

Для проверки гипотезы: β=0 статистика критерия будет
где – оценка параметра β,
Для проверки гипотезы: β=0 статистика критерия будет
где – оценка параметра β,

Для проверки гипотезы: α=0 статистика критерия будет
В случае парной линейной
Для проверки гипотезы: α=0 статистика критерия будет
В случае парной линейной

Для проверки гипотез о незначительном отклонении от нуля «истинного» коэффициента линейной

Существует взаимосвязь
Рассмотренная формула статистики критерия проверки гипотез применима, если:
Оценки делаются
Рассмотренная формула статистики критерия проверки гипотез применима, если:
Оценки делаются

Если же величина выборочного коэффициента корреляции близка к 1, то распределение
Если же величина выборочного коэффициента корреляции близка к 1, то распределение

Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно ли
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно ли

ПРОГНОЗ ОЖИДАЕМОГО ЗНАЧЕНИЯ РЕЗУЛЬТИРУЮЩЕГО ПРИЗНАКА.
ПРОГНОЗ ОЖИДАЕМОГО ЗНАЧЕНИЯ РЕЗУЛЬТИРУЮЩЕГО ПРИЗНАКА.

Предположим, необходимо определить для заданного значения фактора xp с доверительной вероятностью
Предположим, необходимо определить для заданного значения фактора xp с доверительной вероятностью
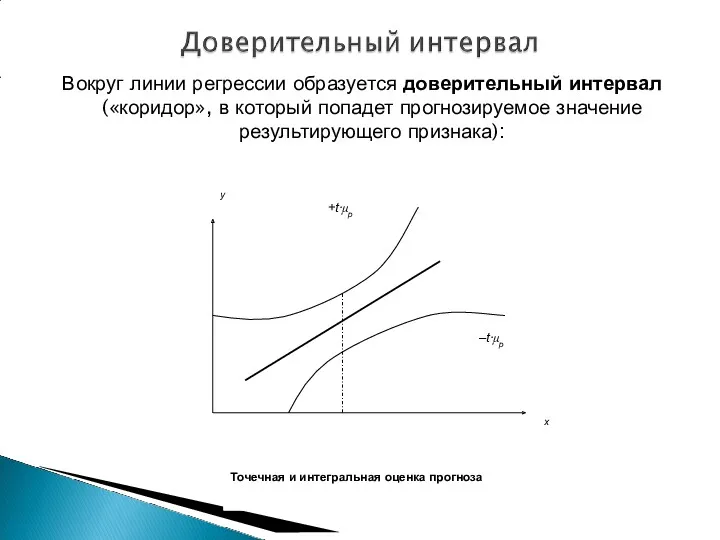
Вокруг линии регрессии образуется доверительный интервал («коридор», в который попадет прогнозируемое
Вокруг линии регрессии образуется доверительный интервал («коридор», в который попадет прогнозируемое

НЕЛИНЕЙНАЯ РЕГРЕССИЯ
НЕЛИНЕЙНАЯ РЕГРЕССИЯ
Большинство экономических ситуаций характеризуются нелинейной зависимостью между результирующим и факторными признаками.
Большинство экономических ситуаций характеризуются нелинейной зависимостью между результирующим и факторными признаками.

Полиномы различных степеней –
yi=a0+ a1⋅xi+…+ am⋅xim+εi.
Равностороння гипербола –
Полиномы различных степеней –
yi=a0+ a1⋅xi+…+ am⋅xim+εi.
Равностороння гипербола –

Степенная функция –
;
Показательная функция –
;
Экспоненциальная функция –
.
Степенная функция –
;
Показательная функция –
;
Экспоненциальная функция –
.
 Решение задач по теме Площади фигур
Решение задач по теме Площади фигур Презентация по математике.
Презентация по математике. Дифференциальное исчисление
Дифференциальное исчисление Углы. Измерение углов. Построение углов. 5 класс
Углы. Измерение углов. Построение углов. 5 класс Математика.Тема урока: Числа от 1 до 10.
Математика.Тема урока: Числа от 1 до 10. Замена произведения чисел их суммой
Замена произведения чисел их суммой Неопределенный интеграл
Неопределенный интеграл Задачи на переливание жидкости
Задачи на переливание жидкости Теория графов: основные понятия и определения
Теория графов: основные понятия и определения Угол. Прямой угол (с применением ИКТ)
Угол. Прямой угол (с применением ИКТ) презентации по математике
презентации по математике Теорема о биссектрисе треугольника
Теорема о биссектрисе треугольника Среднее арифметическое, размах и мода ряда чисел
Среднее арифметическое, размах и мода ряда чисел Вивчаємо арифметичні дії множення і ділення; табличне множення та ділення
Вивчаємо арифметичні дії множення і ділення; табличне множення та ділення Конспект урока математики во 2 классе. Умножение
Конспект урока математики во 2 классе. Умножение Функции и ее графики
Функции и ее графики Путешествие по математическим станциям
Путешествие по математическим станциям КУС по математике для 4 класса
КУС по математике для 4 класса Ученые математики
Ученые математики Понятие бесконечной интегральной суммы. Интеграл (11 класс)
Понятие бесконечной интегральной суммы. Интеграл (11 класс) Перпендикулярність прямої і площини
Перпендикулярність прямої і площини Основные формулы комбинаторики. Классическое определение вероятности. Теоремы сложения и умножения вероятностей
Основные формулы комбинаторики. Классическое определение вероятности. Теоремы сложения и умножения вероятностей Понятие площади многоугольника
Понятие площади многоугольника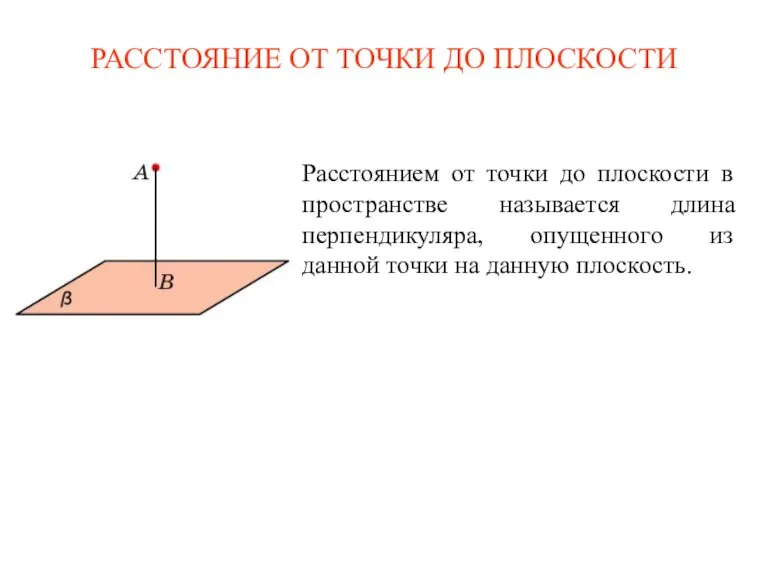 Расстояние от точки до плоскости в пространстве
Расстояние от точки до плоскости в пространстве Топқа бөлу
Топқа бөлу Педагогический опыт Развитие логического мышления и математических представлений у детей дошкольного возраста через развивающие игры
Педагогический опыт Развитие логического мышления и математических представлений у детей дошкольного возраста через развивающие игры Задачи на сравнение
Задачи на сравнение Упрощение выражений, 5 класс
Упрощение выражений, 5 класс