- Математичні методи в біології

Содержание
- 2. Гланц С. Медико-биологическая статистика. Пер. С англ..– М., Практика, 1998.– 459с. Атраментова Л.А., Утевская О.М. Статистические
- 3. Біля витоків біометрії стояв Френсіс Гальтон (1822-1911). Спочатку Гальтон готувався стати лікарем. Однак, навчаючись в Кембриджському
- 4. Однак перетворив її в наукову дисципліну математик Карл Пірсон (1857-1936). В 1884 Пірсон отримав кафедру прикладної
- 5. Наступний етап розвитку біометрії пов'язаний з ім'ям великого англійського статистика Рональда Фішера (1890-1962). Під час навчання
- 6. Описова статистика. Оцінювання гіпотез, порівняльний аналіз. Кореляційний , регресійний і дисперсійний аналіз залежностей. Методи аналізу структури
- 7. Біологічним об’єктам властива велика різноманітність морфологічних, фізіологічних та інших ознак. Їх можна розділити на кількісні і
- 8. В біометрії масовий матеріал називають генеральною сукупністю, що становить мету дослідження. Теоретично це безмежно велика або
- 9. Середнє арифметичне (вибіркове) Як математична величина, вибіркове середнє арифметичне має наступні властивості: Сума відхилень від середнього
- 11. Розглянемо числовий приклад 1. Визначали вміст вітаміну С у крові хворих людей (в мг%). Виконано 13
- 12. Середнє гармонічне Мh застосовується тоді, коли результати спостережень виявляють обернену залежність, задані оберненими значеннями варіант. Обчислення
- 13. Обчислення середнього геометричного необхідне для визначення темпу зміни ознаки, якщо вона вимірюється в часі чи в
- 14. Середнє квадратичне Мq. Для більш точної числової характеристики мір площі застосовують середнє квадратичне. Його обчисляють за
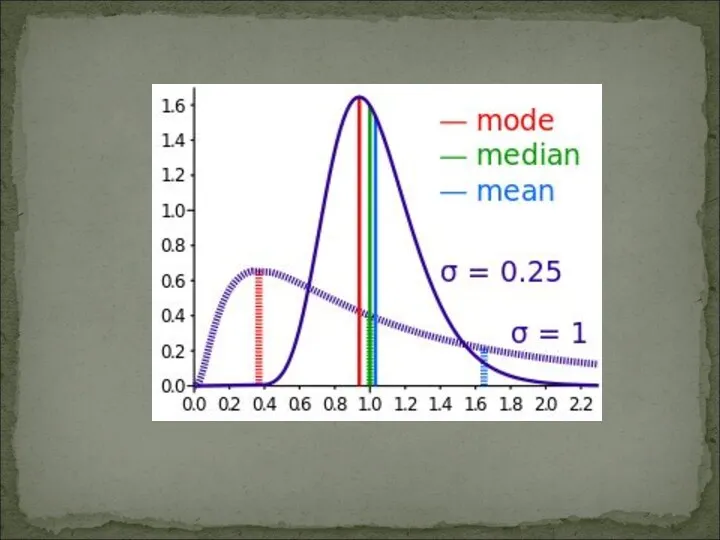
- 15. У випадку великої сукупності експериментальних даних для визначення моди дані формують у варіаційний ряд. Спочатку їх
- 17. Медіана – це значення, яке ділить варіаційний експериментальний ряд на дві рівні за об’ємом групи. У
- 19. середнє квадратичне відхилення (σ), дисперсія, коефіцієнт варіації (Cv), нормоване відхилення (t), розкид даних (xmax - xmin).
- 20. Основними критерієм мінливості є середнє квадратичне відхилення, який показує на скільки в середньому відхиляється за досліджуваною
- 21. Ще один показник, який служить для оцінки мінливості (варіації) сукупності даних – це емпірична дисперсія, яка
- 22. Величина σ завжди іменована (кг, см, % і т.п.). Якщо потрібно порівняти ступінь мінливості ознак, що
- 23. Бажано, щоб статистичні похибки були якнайменші, тоді вибіркові параметри більш правильно характеризують генеральну сукупність. Величина статистичної
- 24. Статистично правильний запис результатів експерименту буде тоді, коли ми вкажемо інтервал змінювання середнього значення M±m (n)
- 25. Довірчий інтервал для середнього визначається за формулою [M – tn,pm , M + tn,pm], де М
- 27. Скачать презентацию

Гланц С. Медико-биологическая статистика. Пер. С англ..– М., Практика, 1998.– 459с.
Атраментова
Гланц С. Медико-биологическая статистика. Пер. С англ..– М., Практика, 1998.– 459с.
Атраментова

Біля витоків біометрії стояв Френсіс Гальтон (1822-1911). Спочатку Гальтон готувався стати
Біля витоків біометрії стояв Френсіс Гальтон (1822-1911). Спочатку Гальтон готувався стати

Однак перетворив її в наукову дисципліну математик Карл Пірсон (1857-1936). В
Однак перетворив її в наукову дисципліну математик Карл Пірсон (1857-1936). В

Наступний етап розвитку біометрії пов'язаний з ім'ям великого англійського статистика Рональда
Наступний етап розвитку біометрії пов'язаний з ім'ям великого англійського статистика Рональда

Описова статистика.
Оцінювання гіпотез, порівняльний аналіз.
Кореляційний , регресійний і дисперсійний аналіз залежностей.
Методи
Описова статистика.
Оцінювання гіпотез, порівняльний аналіз.
Кореляційний , регресійний і дисперсійний аналіз залежностей.
Методи

Біологічним об’єктам властива велика різноманітність морфологічних, фізіологічних та інших ознак. Їх
Біологічним об’єктам властива велика різноманітність морфологічних, фізіологічних та інших ознак. Їх

В біометрії масовий матеріал називають генеральною сукупністю, що становить мету дослідження.
В біометрії масовий матеріал називають генеральною сукупністю, що становить мету дослідження.

Середнє арифметичне (вибіркове)
Як математична величина, вибіркове середнє арифметичне має наступні властивості:
Сума
Середнє арифметичне (вибіркове)
Як математична величина, вибіркове середнє арифметичне має наступні властивості:
Сума

Розглянемо числовий приклад 1. Визначали вміст вітаміну С у крові хворих
Розглянемо числовий приклад 1. Визначали вміст вітаміну С у крові хворих

Середнє гармонічне Мh застосовується тоді, коли результати спостережень виявляють обернену залежність,
Середнє гармонічне Мh застосовується тоді, коли результати спостережень виявляють обернену залежність,

Обчислення середнього геометричного
необхідне для визначення темпу зміни ознаки, якщо вона
Обчислення середнього геометричного
необхідне для визначення темпу зміни ознаки, якщо вона

Середнє квадратичне Мq. Для більш точної числової характеристики мір площі застосовують
Середнє квадратичне Мq. Для більш точної числової характеристики мір площі застосовують

У випадку великої сукупності експериментальних даних для визначення моди дані формують
У випадку великої сукупності експериментальних даних для визначення моди дані формують


Медіана – це значення, яке ділить варіаційний експериментальний ряд на дві
Медіана – це значення, яке ділить варіаційний експериментальний ряд на дві


середнє квадратичне відхилення (σ),
дисперсія,
коефіцієнт варіації (Cv),
нормоване відхилення (t),
розкид
середнє квадратичне відхилення (σ),
дисперсія,
коефіцієнт варіації (Cv),
нормоване відхилення (t),
розкид

Основними критерієм мінливості є середнє квадратичне відхилення, який показує на скільки
Основними критерієм мінливості є середнє квадратичне відхилення, який показує на скільки

Ще один показник, який служить для оцінки мінливості (варіації) сукупності даних
Ще один показник, який служить для оцінки мінливості (варіації) сукупності даних

Величина σ завжди іменована (кг, см, % і т.п.). Якщо потрібно
Величина σ завжди іменована (кг, см, % і т.п.). Якщо потрібно

Бажано, щоб статистичні похибки були якнайменші, тоді вибіркові параметри більш правильно
Бажано, щоб статистичні похибки були якнайменші, тоді вибіркові параметри більш правильно

Статистично правильний запис результатів експерименту буде тоді, коли ми вкажемо інтервал
Статистично правильний запис результатів експерименту буде тоді, коли ми вкажемо інтервал

Довірчий інтервал для середнього визначається за формулою [M – tn,pm ,
Довірчий інтервал для середнього визначається за формулою [M – tn,pm ,
 Нумерація чисел першої сотні. Нумераційна таблиця. Знаходження невідомого доданка. Урок №106
Нумерація чисел першої сотні. Нумераційна таблиця. Знаходження невідомого доданка. Урок №106 Задачи на построение. Окружность. Урок 2
Задачи на построение. Окружность. Урок 2 Інформаційна система учасника стохастичних ігор
Інформаційна система учасника стохастичних ігор Шар. Сечения шара плоскостью
Шар. Сечения шара плоскостью Презентация Волшебный мир геометрических фигур
Презентация Волшебный мир геометрических фигур Алгебраические выражения
Алгебраические выражения Отношение. Задачи
Отношение. Задачи Виды треугольников. 3 класс
Виды треугольников. 3 класс Следствия из аксиом
Следствия из аксиом Системы линейных алгебраических уравнений. Метод Гаусса
Системы линейных алгебраических уравнений. Метод Гаусса Логарифмическая функция
Логарифмическая функция Конспект занятия с презентацией по ФЭМП в средней группе по теме Учимся с Лунтиком!
Конспект занятия с презентацией по ФЭМП в средней группе по теме Учимся с Лунтиком! Тригонометрические неравенства
Тригонометрические неравенства Поняття про об’єм тіла. Основні властивості об’ємів. Об’єм прямокутного паралелепіпеда
Поняття про об’єм тіла. Основні властивості об’ємів. Об’єм прямокутного паралелепіпеда Механический и геометрический смысл производной
Механический и геометрический смысл производной Найрозумніший математик. Викторина
Найрозумніший математик. Викторина Число и цифра 4
Число и цифра 4 Сумма углов треугольника
Сумма углов треугольника Повторение курса геометрии, 7 класс
Повторение курса геометрии, 7 класс Выражения и их преобразования
Выражения и их преобразования Статистика и теория вероятностей. Испытание. Успех и неудача. Серия испытаний до первого успеха. 9 класс
Статистика и теория вероятностей. Испытание. Успех и неудача. Серия испытаний до первого успеха. 9 класс Приведение подобных слагаемых
Приведение подобных слагаемых Наглядное представление статистической информации - диаграмма
Наглядное представление статистической информации - диаграмма Дециметр урок математики в 1 классе
Дециметр урок математики в 1 классе Квадратные уравнения
Квадратные уравнения Тренажёр Три медведя (Математика, 1 класс)
Тренажёр Три медведя (Математика, 1 класс) Комбинации тел с шаром
Комбинации тел с шаром Уравнения высших степеней
Уравнения высших степеней