- Многомерный анализ данных ( лекция 9)

Содержание
- 2. Что такое data mining? Это процесс нетривиального извлечения новой, полезной и экстраполируемой информации из большого массива
- 3. Классификация многомерных методов Визуализация Классификация Визуализация «сырых» данных (данные как они есть) Методы понижения размерности Деревья
- 4. Ещё один пример «парной» визуализации: Белки теплового шока ангидробиотической хирономиды Polypedilum vanderplanki (Африка) Ответ на 48-часовое
- 5. Пиктограммы – весёлый и лёгкий способ находить похожие объекты Лица Чернова Набор из 15 HSP P.
- 6. Методы понижения размерности: анализ главных компонент (PCA) Идея. Каждый объект – точка в n-мерном Евклидовом пространстве,
- 7. Как преобразовать 4х-мерное пространство к 2х-мерному? Исходные данные Данные в новых координатах Визуализация в новых координатах
- 8. График biplot графически увязывает старые и новые координаты Каждый ирис пронумерован числом Чем меньше угол –
- 9. Применение метода главных компонент для анализа дифференциальной экспрессии Проверка самосогласованности реплик (повторностей) Каждый объект – вектор
- 10. Методы понижения размерности: кластеризация Кластеризация – разбиение большого набора объектов на более мелкие наборы (кластеры) Основная
- 11. Классификация методов кластеризации Иерархическая / плоская Комплексная древоподобная система разбиений а) / одно и только одно
- 12. Кластеризация методом k-средних (k-means) Рис.3 итоговая кластеризация Рис.1 Рис.2 (Фактически, каждая точка окрашивается в цвет того
- 13. Замечательная визуализация! https://www.naftaliharris.com/blog/visualizing-k-means-clustering/ Шаг 0. Начальное положение точек Шаг 1. Бросаем начальные центры кластеров Шаг 2.
- 14. Шаг 4. «Перекрашиваем» точки, которые находятся «на чужой территории» Шаг 5. Переставляем центры кластеров в центр
- 15. И так до тех пор, пока есть что «перекрашивать»! Финальная «раскраска» – после очередного перемещения центров
- 16. Как помочь анализу методом k-средних? Это так называемый elbow-plot (график локтя) 3 Оптимальное число кластеров Чем
- 17. Иерархическая кластеризация Два принципиально разных подхода: Снизу-вверх (каждая точка – один кластер, дальше кластеры объединяются в
- 18. Как вычислять расстояния между кластерами? Метод ближайшего соседа (метод одиночной связи) Метод дальнего соседа (метод полной
- 19. Иерархическая кластеризация 30 ирисов (по 10 каждого вида) a – virginica, s – setosa, v -
- 20. Задача классификации Похожа на кластеризацию, но деление на группы происходит с учётом конкретных признаков объектов Например,
- 21. Базовый алгоритм классификации Находим параметр, по которому группа разделяется лучше всего Делим данные на 2 группы
- 22. Дерево принятия решений – наиболее популярный, простой и интуитивно понятный метод решения задач классификации Его результат
- 23. Дерево принятия решений для ирисов да нет да нет
- 25. Скачать презентацию
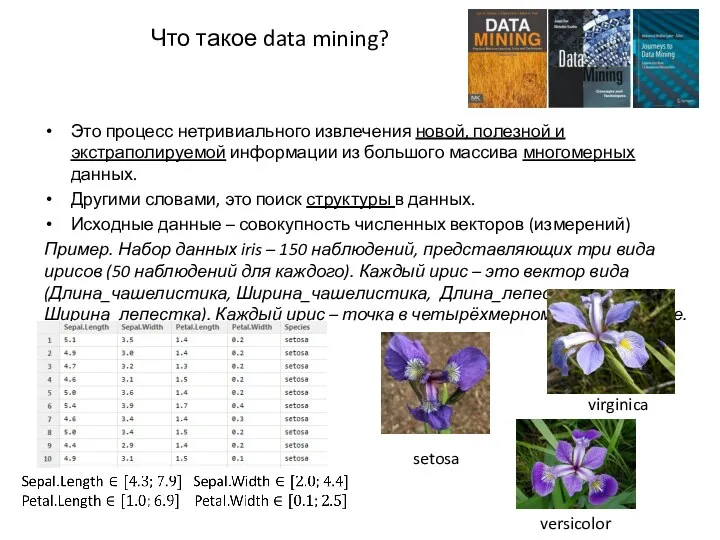
Что такое data mining?
Это процесс нетривиального извлечения новой, полезной и экстраполируемой
Что такое data mining?
Это процесс нетривиального извлечения новой, полезной и экстраполируемой
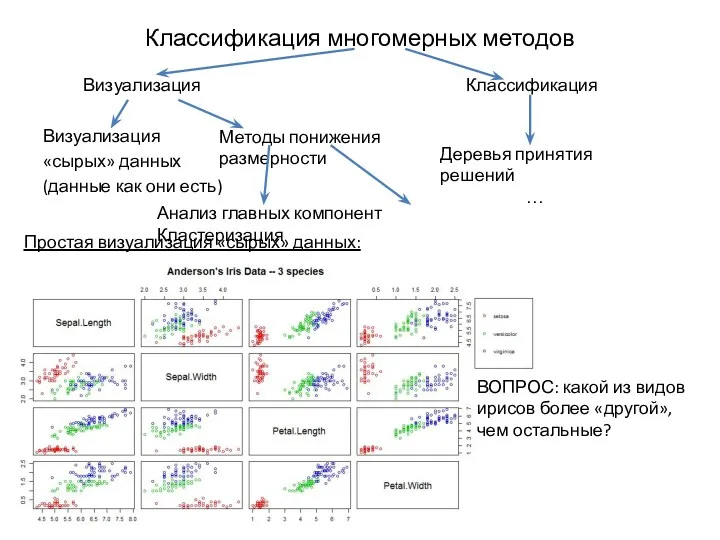
Классификация многомерных методов
Визуализация Классификация
Визуализация
«сырых» данных
(данные как они есть)
Методы понижения размерности
Деревья
Классификация многомерных методов
Визуализация Классификация
Визуализация
«сырых» данных
(данные как они есть)
Методы понижения размерности
Деревья
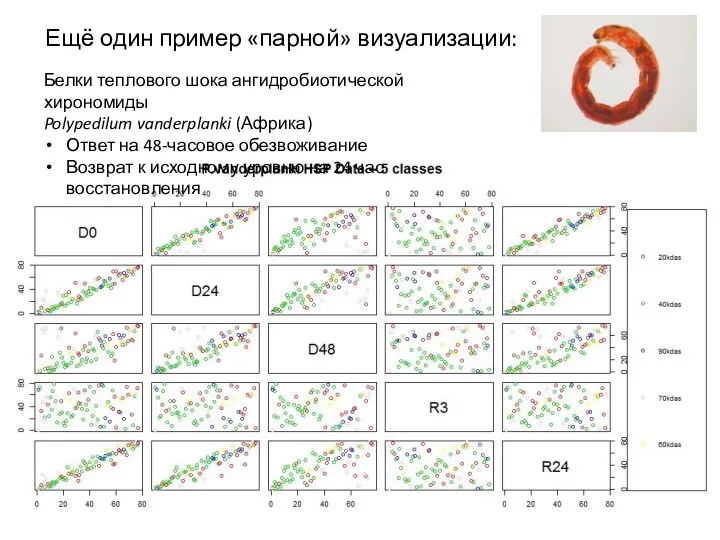
Ещё один пример «парной» визуализации:
Белки теплового шока ангидробиотической хирономиды
Polypedilum vanderplanki
Ещё один пример «парной» визуализации:
Белки теплового шока ангидробиотической хирономиды
Polypedilum vanderplanki
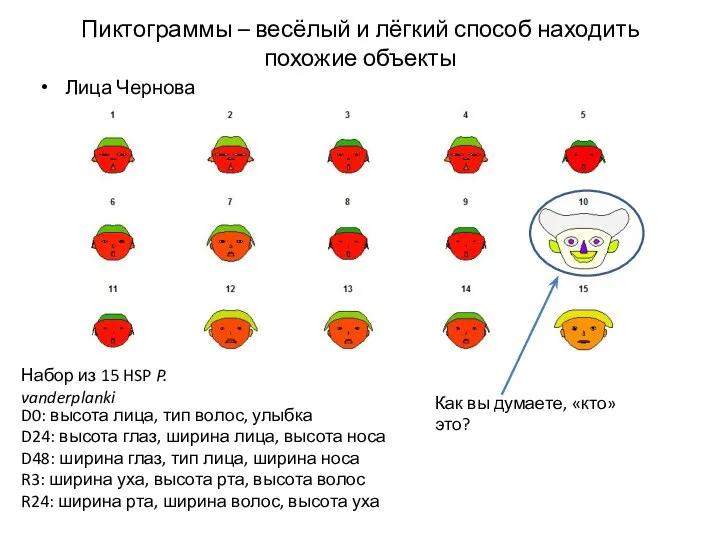
Пиктограммы – весёлый и лёгкий способ находить похожие объекты
Лица Чернова
Набор из
Пиктограммы – весёлый и лёгкий способ находить похожие объекты
Лица Чернова
Набор из
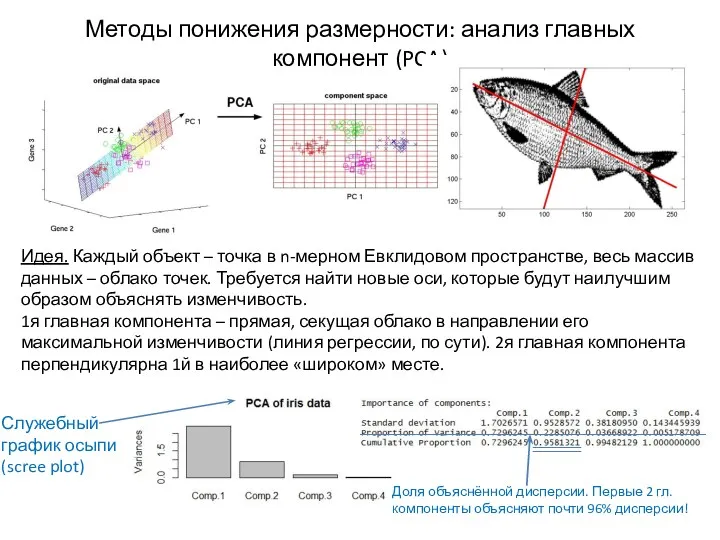
Методы понижения размерности: анализ главных компонент (PCA)
Идея. Каждый объект – точка
Методы понижения размерности: анализ главных компонент (PCA)
Идея. Каждый объект – точка

Как преобразовать 4х-мерное пространство к 2х-мерному?
Исходные данные
Данные в новых координатах
Визуализация в
Как преобразовать 4х-мерное пространство к 2х-мерному?
Исходные данные
Данные в новых координатах
Визуализация в
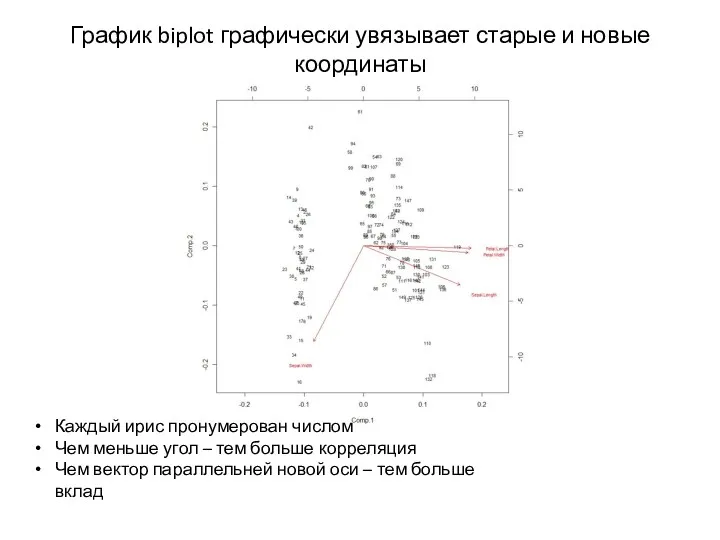
График biplot графически увязывает старые и новые координаты
Каждый ирис пронумерован числом
Чем
График biplot графически увязывает старые и новые координаты
Каждый ирис пронумерован числом
Чем
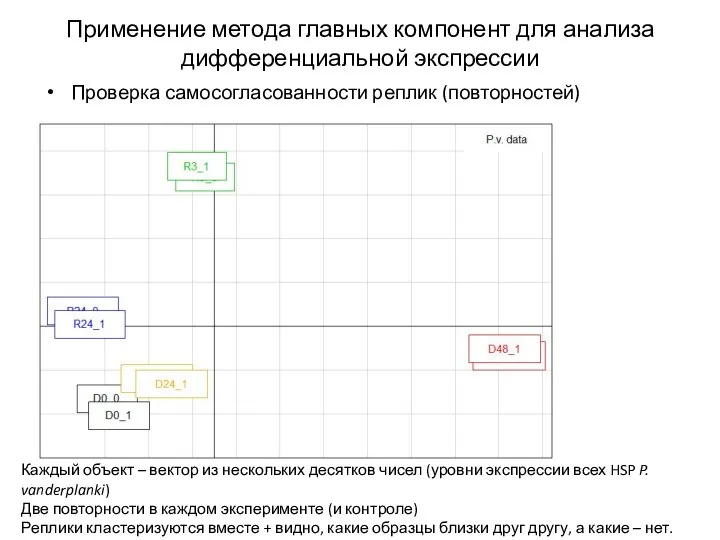
Применение метода главных компонент для анализа дифференциальной экспрессии
Проверка самосогласованности реплик (повторностей)
Каждый
Применение метода главных компонент для анализа дифференциальной экспрессии
Проверка самосогласованности реплик (повторностей)
Каждый

Методы понижения размерности: кластеризация
Кластеризация – разбиение большого набора объектов на более
Методы понижения размерности: кластеризация
Кластеризация – разбиение большого набора объектов на более
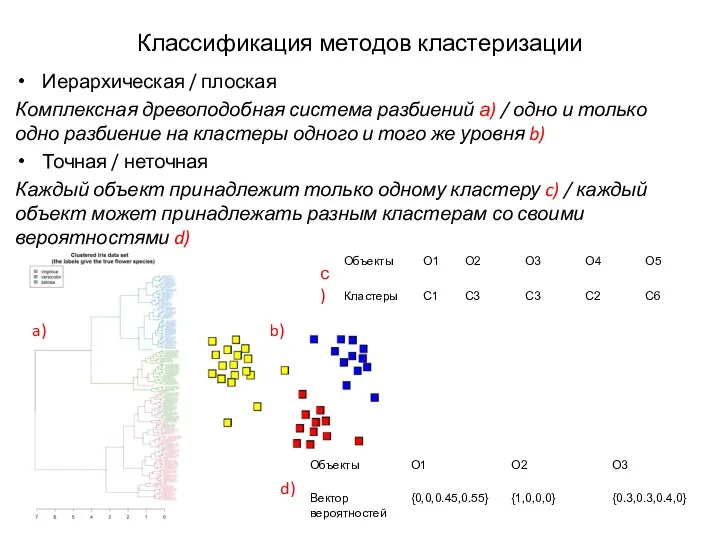
Классификация методов кластеризации
Иерархическая / плоская
Комплексная древоподобная система разбиений а) / одно
Классификация методов кластеризации
Иерархическая / плоская
Комплексная древоподобная система разбиений а) / одно
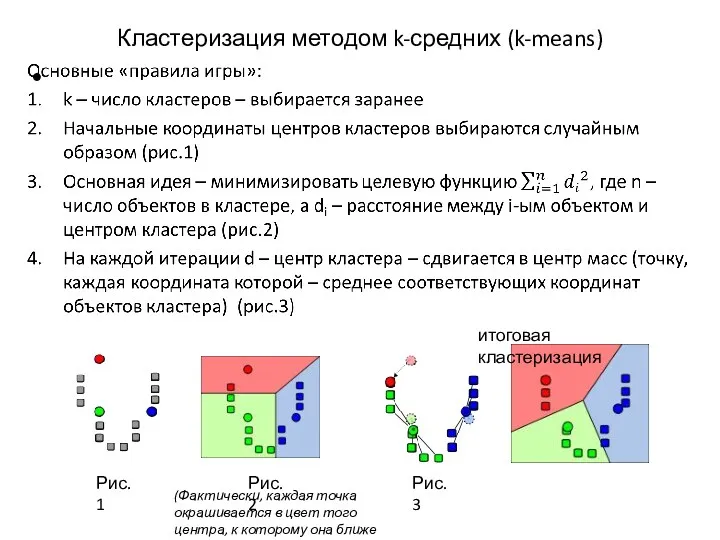
Кластеризация методом k-средних (k-means)
Рис.3
итоговая кластеризация
Рис.1
Рис.2
(Фактически, каждая точка окрашивается в цвет того
Кластеризация методом k-средних (k-means)
Рис.3
итоговая кластеризация
Рис.1
Рис.2
(Фактически, каждая точка окрашивается в цвет того
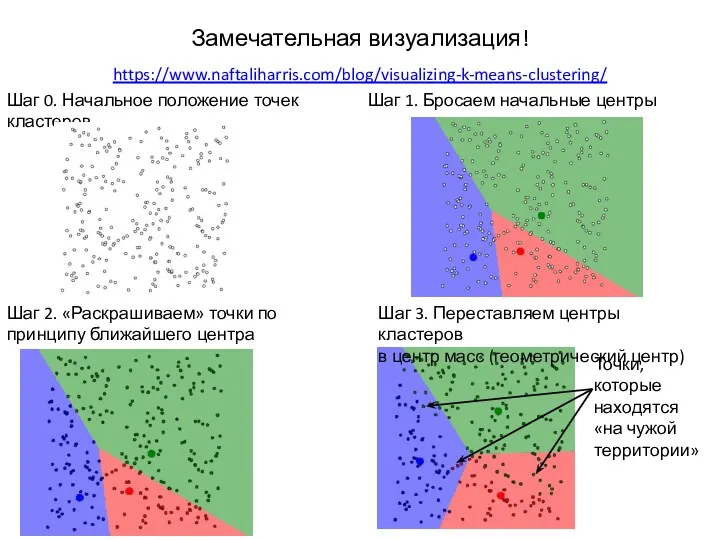
Замечательная визуализация!
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
Шаг 0. Начальное положение точек Шаг 1. Бросаем начальные центры
Замечательная визуализация!
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
Шаг 0. Начальное положение точек Шаг 1. Бросаем начальные центры

Шаг 4. «Перекрашиваем» точки,
которые находятся «на чужой территории»
Шаг 5. Переставляем
Шаг 4. «Перекрашиваем» точки,
которые находятся «на чужой территории»
Шаг 5. Переставляем
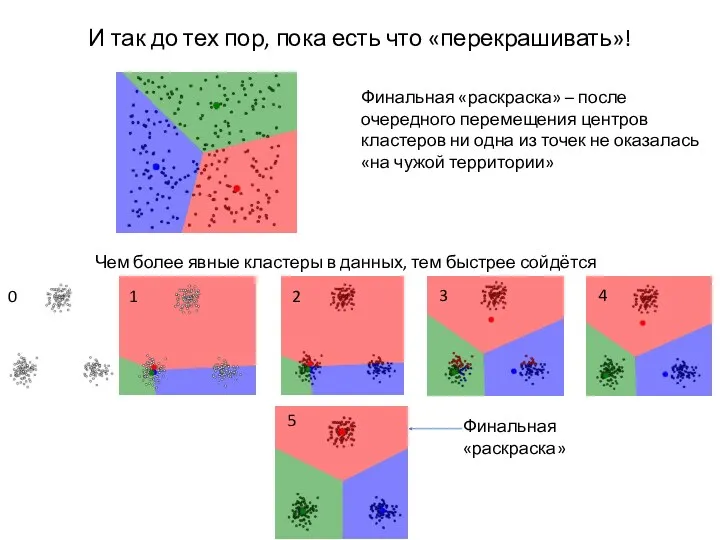
И так до тех пор, пока есть что «перекрашивать»!
Финальная «раскраска» –
И так до тех пор, пока есть что «перекрашивать»!
Финальная «раскраска» –
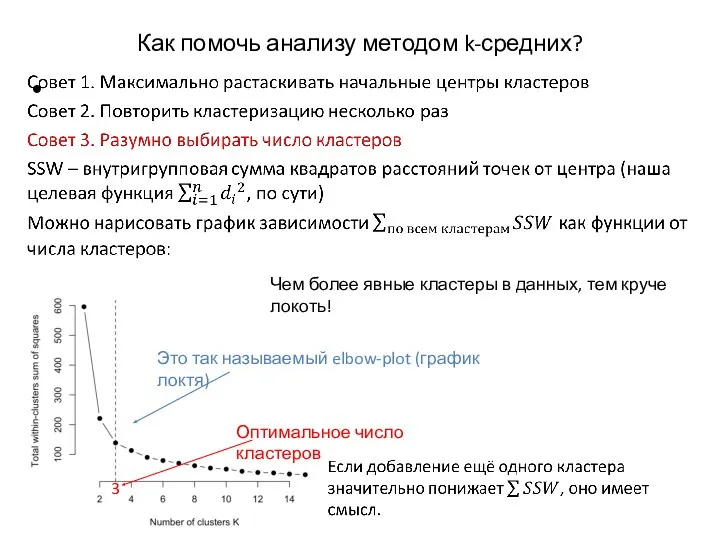
Как помочь анализу методом k-средних?
Это так называемый elbow-plot (график локтя)
3
Оптимальное число
Как помочь анализу методом k-средних?
Это так называемый elbow-plot (график локтя)
3
Оптимальное число
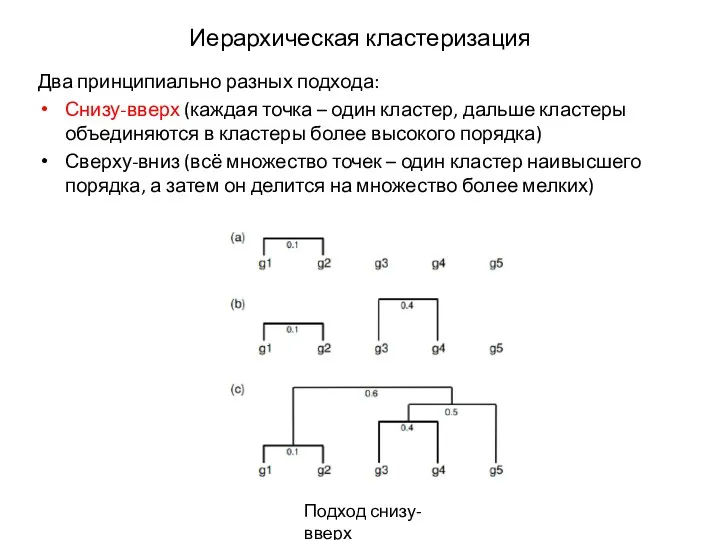
Иерархическая кластеризация
Два принципиально разных подхода:
Снизу-вверх (каждая точка – один кластер, дальше
Иерархическая кластеризация
Два принципиально разных подхода:
Снизу-вверх (каждая точка – один кластер, дальше
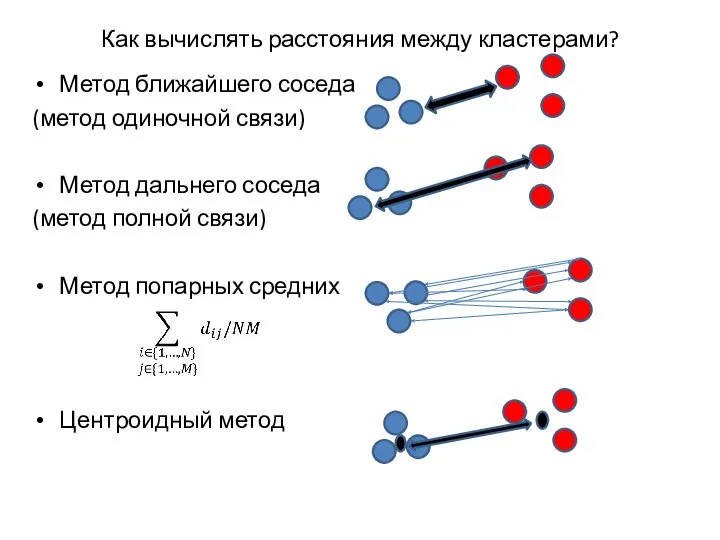
Как вычислять расстояния между кластерами?
Метод ближайшего соседа
(метод одиночной связи)
Метод дальнего соседа
(метод
Как вычислять расстояния между кластерами?
Метод ближайшего соседа
(метод одиночной связи)
Метод дальнего соседа
(метод
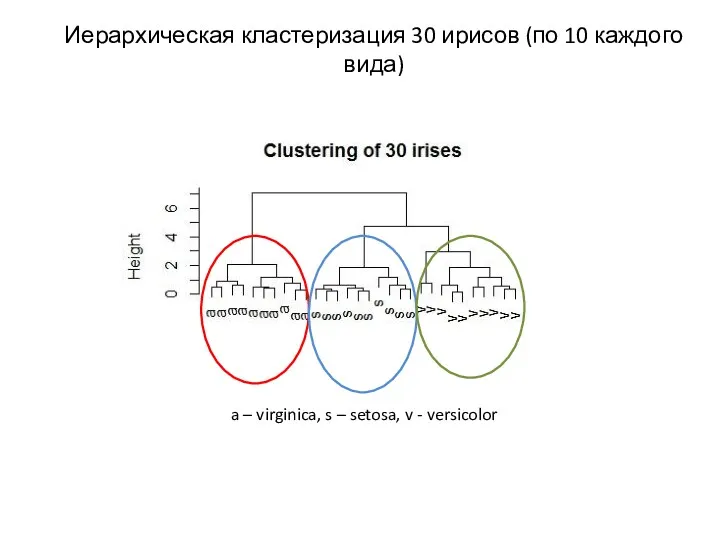
Иерархическая кластеризация 30 ирисов (по 10 каждого вида)
a – virginica, s
Иерархическая кластеризация 30 ирисов (по 10 каждого вида)
a – virginica, s

Задача классификации
Похожа на кластеризацию, но деление на группы происходит с учётом
Задача классификации
Похожа на кластеризацию, но деление на группы происходит с учётом

Базовый алгоритм классификации
Находим параметр, по которому группа разделяется лучше всего
Делим данные
Базовый алгоритм классификации
Находим параметр, по которому группа разделяется лучше всего
Делим данные
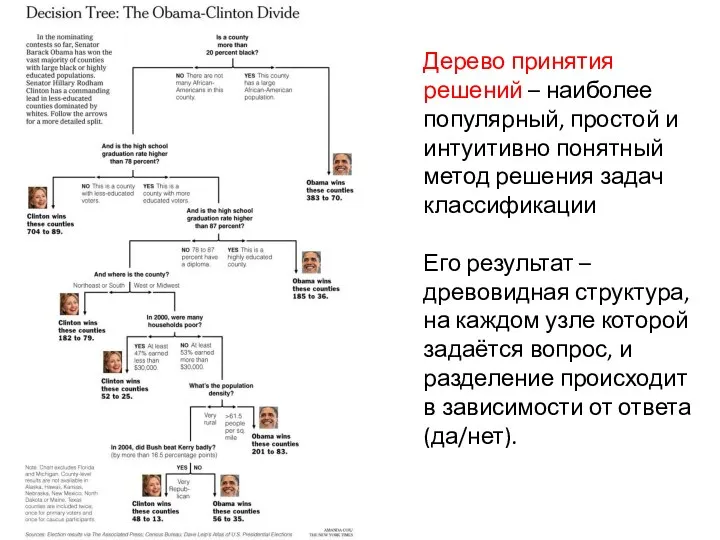
Дерево принятия решений – наиболее популярный, простой и интуитивно понятный метод
Дерево принятия решений – наиболее популярный, простой и интуитивно понятный метод
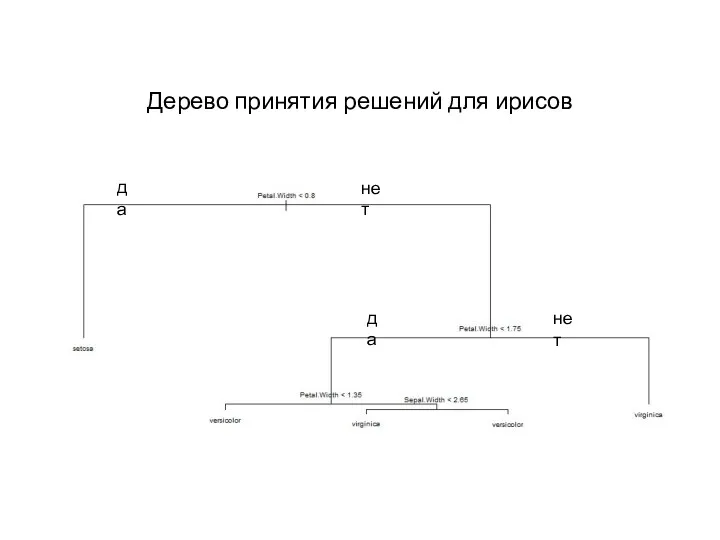
Дерево принятия решений для ирисов
да
нет
да
нет
Дерево принятия решений для ирисов
да
нет
да
нет
 Кто хочет получить 5? Игра. Действия с десятичными дробями
Кто хочет получить 5? Игра. Действия с десятичными дробями Проектная деятельность школьников, как средство усиления прикладной направленности обучения математике
Проектная деятельность школьников, как средство усиления прикладной направленности обучения математике Метод Ньютона: 1- и 2-я интерполяционные формулы Ньютона
Метод Ньютона: 1- и 2-я интерполяционные формулы Ньютона Длина окружности. 6 класс:
Длина окружности. 6 класс: презентация к коспекту занятия Измерение длины по Л.Г. Петерсону Диск Диск Диск
презентация к коспекту занятия Измерение длины по Л.Г. Петерсону Диск Диск Диск Путешествие в Математическую страну
Путешествие в Математическую страну Китайская система счисления
Китайская система счисления Применение производных частных. Касательная плоскость и нормаль к поверхности
Применение производных частных. Касательная плоскость и нормаль к поверхности презентация к уроку математики 6 класс виленкин
презентация к уроку математики 6 класс виленкин Метод Голубева. Решение неравенств
Метод Голубева. Решение неравенств Проверка статистических гипотез
Проверка статистических гипотез Круг. Площадь круга
Круг. Площадь круга Расстояние между точками координатной прямой
Расстояние между точками координатной прямой Умножение многочлена на одночлен
Умножение многочлена на одночлен Внеклассное занятие по математике 2 класс Путешествие в Простоквашино. Поиск клада
Внеклассное занятие по математике 2 класс Путешествие в Простоквашино. Поиск клада Появление дробей. 5 класс
Появление дробей. 5 класс Наибольшее и наименьшее значения функции
Наибольшее и наименьшее значения функции Презентация к урокуВычитание суммы из числа
Презентация к урокуВычитание суммы из числа Презентация к уроку математики Признаки предметов. Построение таблиц или ряда предметов по определенному правилу.
Презентация к уроку математики Признаки предметов. Построение таблиц или ряда предметов по определенному правилу. Задачи на нахождение двух чисел по их сумме и разности. 5 класс
Задачи на нахождение двух чисел по их сумме и разности. 5 класс Геометрические понятия. Плакат.
Геометрические понятия. Плакат. Математические сказки
Математические сказки График линейного уравнения с двумя переменными
График линейного уравнения с двумя переменными Применение определенного интеграла для нахождения площади криволинейной трапеции
Применение определенного интеграла для нахождения площади криволинейной трапеции презентация по математике Табличное умножение и деление 2 класс
презентация по математике Табличное умножение и деление 2 класс Решение задач по теме Призма. Площадь поверхности призмы 10 класс
Решение задач по теме Призма. Площадь поверхности призмы 10 класс Измерение углов. Транспортир. 5 класс
Измерение углов. Транспортир. 5 класс Решение задач на движение. Компетентностно-ориентированные задания
Решение задач на движение. Компетентностно-ориентированные задания