- Моделирование рядов динамики

Содержание
- 2. 5. 1. Постановка задачи и общие сведения о временных рядах
- 3. 1 Под временным рядом (рядом динамики) в экономике понимается совокупность наблюдений некоторого признака (случайной величины Y)
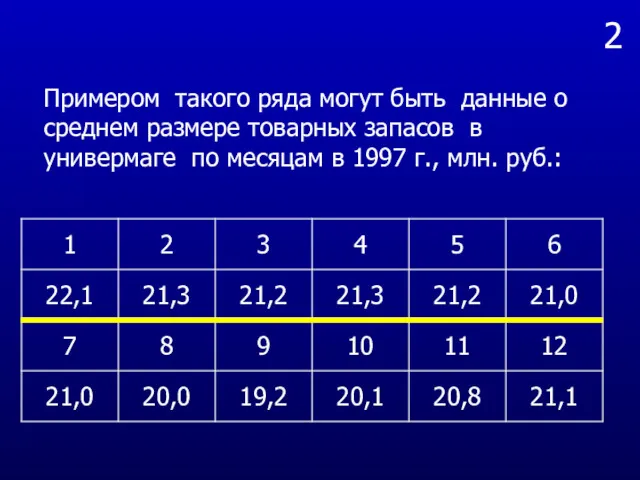
- 4. 2 Примером такого ряда могут быть данные о среднем размере товарных запасов в универмаге по месяцам
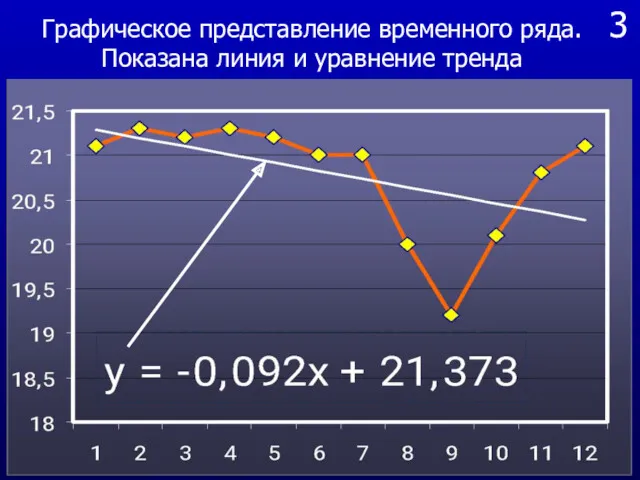
- 5. 3 Графическое представление временного ряда. Показана линия и уравнение тренда
- 6. 4 Каждый уровень (значение) временного ряда формируется под действием большого числа факторов, которые можно разделить на
- 7. 5 Естественно предположить, что все четыре компоненты (трендовая, сезонная, циклическая и случайная) будут формировать наблюдаемое значение
- 8. 6 Важно подчеркнуть. что в отличие от Важнейшей классической задачей при исследовании экономических временных рядов является
- 9. 7 Отметим основные этапы анализа временных рядов: 1. Графическое представление временного ряда; 2. Выделение и удаление
- 10. 8 На первый взгляд кажется. что набор величин можно рассматривать как элементы некоторой случайной выборки. В
- 11. 5.2. Автокорреляция в рядах динамики
- 12. 1 При наличии во временном ряде тенденции или циклических колебаний значения каждого последующего уровня ряда зависит
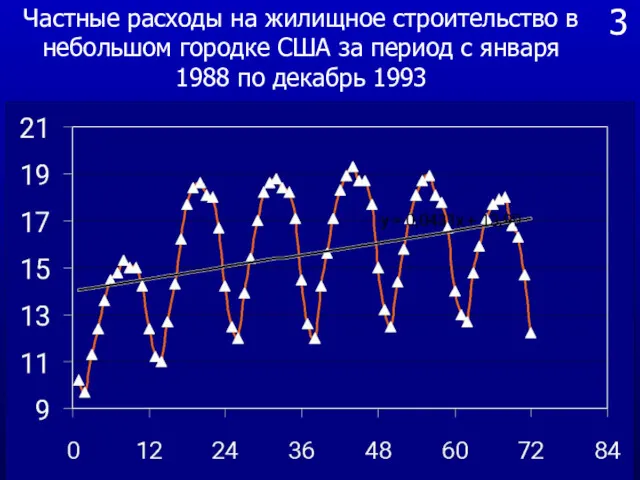
- 13. 2 Ниже представлена таблица с данными о частных расходах на жилищное строительство в небольшом городке США
- 14. 3 Частные расходы на жилищное строительство в небольшом городке США за период с января 1988 по
- 15. 4 Очевидно, что если сдвинуть данные ровно на год, то картина повторяется и поэтому коэффициент корреляции
- 16. 4a Пример 1. Аддитивная модель ряда. Рассмотрим более удобный для анализа пример зависимости поквартального потребления электроэнергии
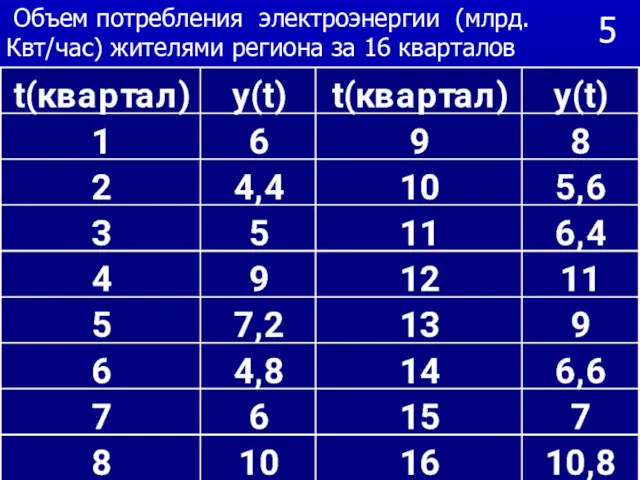
- 17. 5 Объем потребления электроэнергии (млрд. Квт/час) жителями региона за 16 кварталов
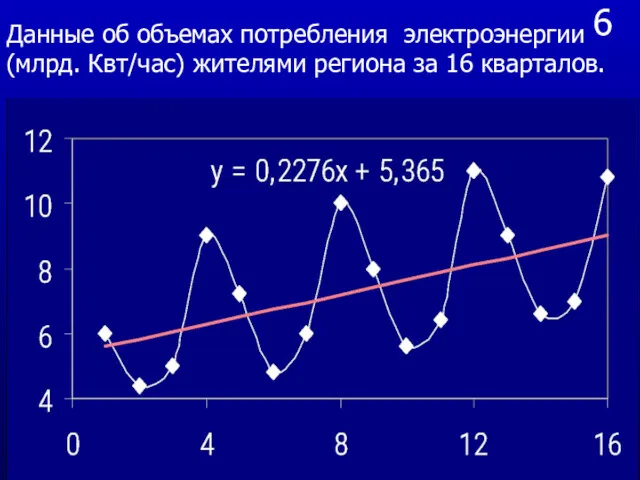
- 18. 6 Данные об объемах потребления электроэнергии (млрд. Квт/час) жителями региона за 16 кварталов.
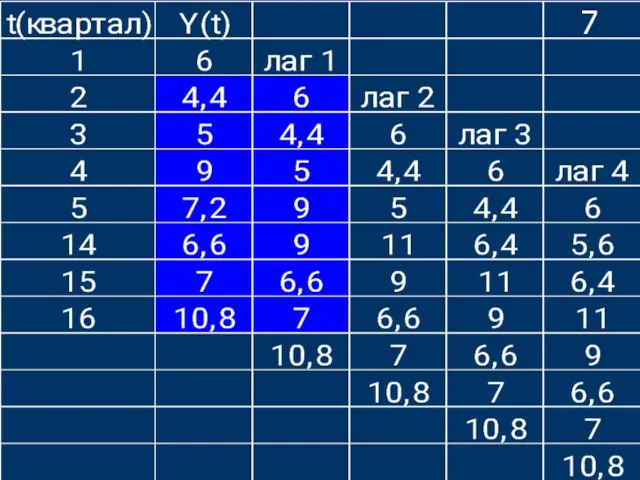
- 19. 6a Вычислим коэффициенты корреляции исходных данных и данных сдвинутых на один кварта, два квартала три квартала
- 20. 7 7
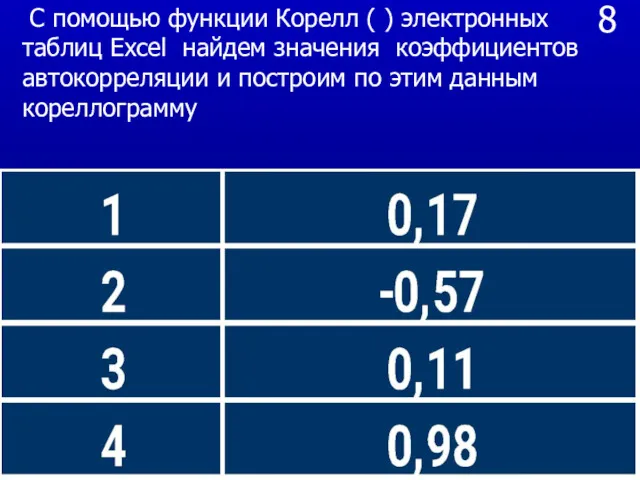
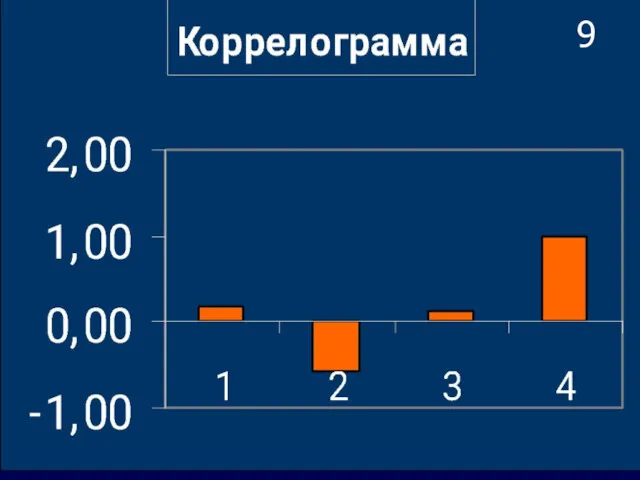
- 21. 8 С помощью функции Корелл ( ) электронных таблиц Excel найдем значения коэффициентов автокорреляции и построим
- 22. 9 9
- 23. 10 Далеко не всегда автокорреляция столь заметна, как в рассмотренных выше примерах. В то же время
- 24. 11 Автокорреляция первого порядка характеризует тесноту связи между соседними значениями временного ряда, автокорреляция второго порядка -
- 25. 12 Авторегрессионные модели разных порядков - первого, второго, в общем случае n-ого - можно описать уравнениями
- 26. 5.3. Выделение тренда и сезонной составляющей для аддитивной и мультипликативной моделей временного ряда.
- 27. 1 Как уже отмечалось, важнейшей задачей исследования временного ряда в экономике является выявление основной тенденции (тренда).
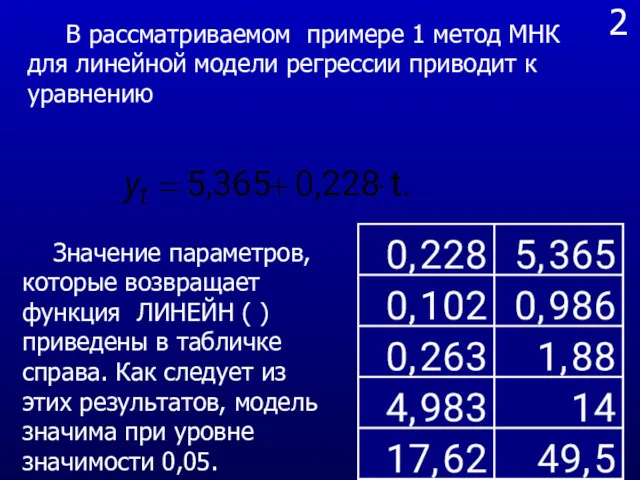
- 28. 2 В рассматриваемом примере 1 метод МНК для линейной модели регрессии приводит к уравнению Значение параметров,
- 29. 3 Причина небольшого по величине фактора детерминации понятна, поскольку есть еще и сезонная составляющая, которую мы
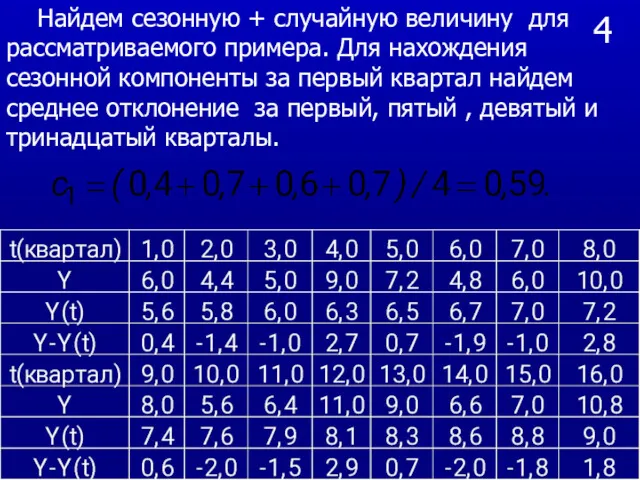
- 30. 4 Найдем сезонную + случайную величину для рассматриваемого примера. Для нахождения сезонной компоненты за первый квартал
- 31. 5 Аналогично найдем сезонную компоненту за второй, третий и четвертый кварталы. Соответствующие величины получились равными: Легко
- 32. 6 Представляет интерес определить насколько хорошо детерминированная составляющая описывает эмпирический набор данных. Проведем это сравнение в
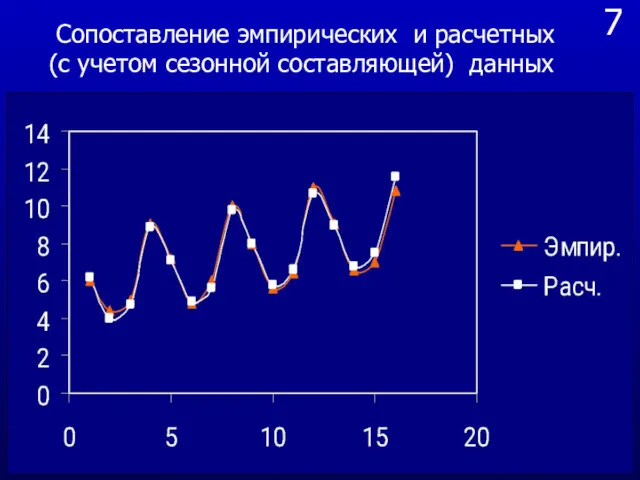
- 33. 7 Сопоставление эмпирических и расчетных (с учетом сезонной составляющей) данных
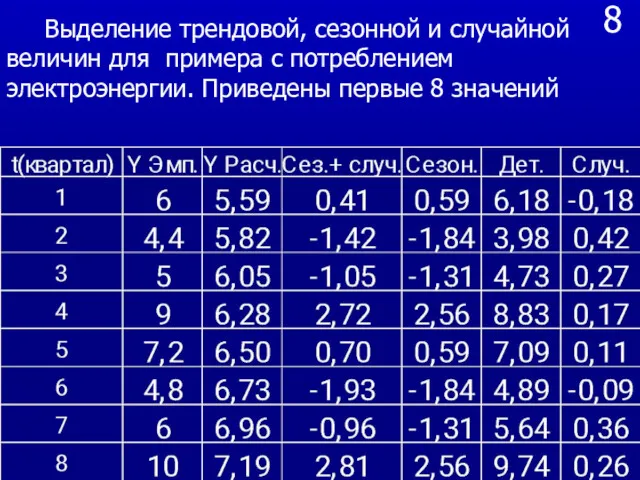
- 34. 8 Выделение трендовой, сезонной и случайной величин для примера с потреблением электроэнергии. Приведены первые 8 значений
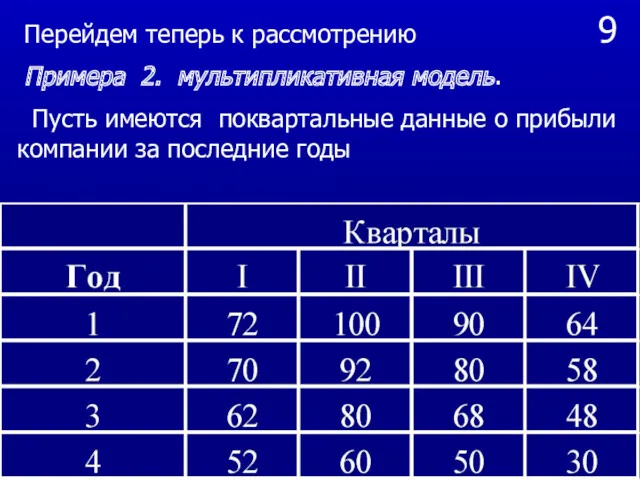
- 35. 9 Перейдем теперь к рассмотрению Примера 2. мультипликативная модель. Пусть имеются поквартальные данные о прибыли компании
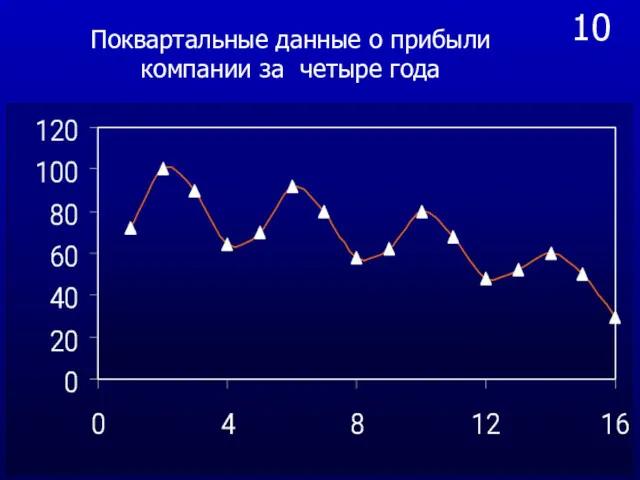
- 36. 10 Поквартальные данные о прибыли компании за четыре года
- 37. 11 Как видно из графика амплитуда осцилляций уменьшается, что и наводит на мысль использовать мультипликативную модель
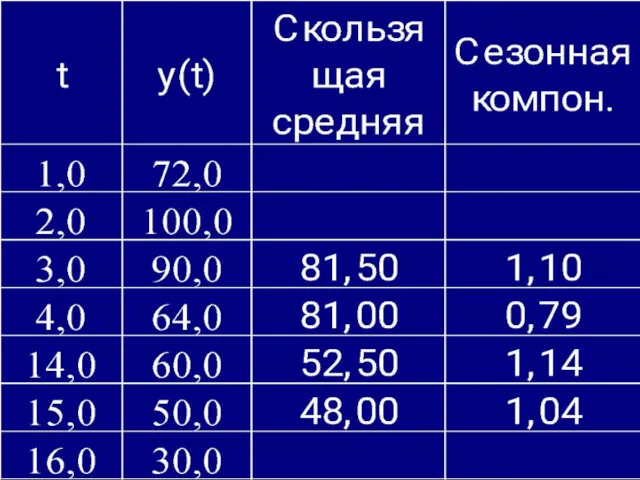
- 38. 12 Суть метода скользящей средней в том, что в данном случае наблюдается явная периодичность в четыре
- 39. 13
- 40. 14 После того, как рассчитана скользящая средняя, используя уравнение мультипликативной модели сезонную компоненту найдем как отношение
- 41. 15 Выравнивание ряда с помощью четырехзвенной скользящей средней
- 42. 16 Итоговые данные для сезонной составляющей
- 43. 17 Существует простой способ проверить правильность проведенных вычислений для сезонной составляющей. Если трендовая составляющая является постоянной
- 44. 18 Рассчитаем теперь трендовую и случайную составляющие. Для этого эмпирические данные разделим на значение средней сезонной
- 45. 19 Как следует из приведенных результатов модель и регрессионные коэффициенты являются значимыми при уровне значимости 0,05.
- 46. 5.4. Прогнозирование по аддитивной и мультипликативной моделям
- 47. 1 Предположим, что по данным рассмотренного Примера 1 необходимо дать прогноз потребления электроэнергии жителями района в
- 48. 2 Прогнозное значение Ft уровня временного ряда в мультипликативной модели есть произведение трендовой и сезонной компонент.
- 49. 5.5. Обнаружение автокорреляции. Авторегрессионые модели первого порядка.
- 50. 1 Рассмотрим прогнозирование для для авторегрессионной модели первого порядка на примере статистического материала об объеме выпуска
- 51. 2 Объем производства фирмы Кодак в период с 1970 по 1992 г. (млрд. долл.)
- 52. 3 Конечно, можно было бы не раздумывая применить линейную или экспоненциальную модель и получить достаточно хорошее
- 53. 4 Большая величина фактора детерминации и статистическая значимость коэффициентов регрессии еще не гарантируют правильность модели. поскольку
- 54. 5 Тест Дарбина – Уотсона основан на простой идее: если корреляция ошибок уравнения регрессии не равна
- 55. 6 Несложные вычисления показывают, что статистика Дарбина – Уотсона просто связана с коэффициентом автокорреляции первого порядка
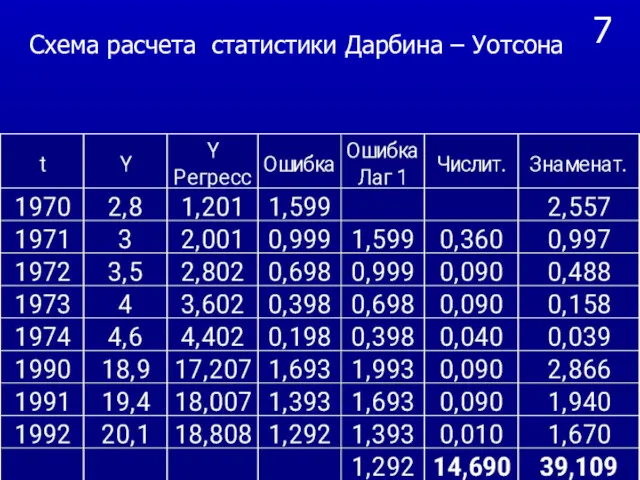
- 56. 7 Схема расчета статистики Дарбина – Уотсона
- 57. 8 Таким образом, Теперь следует разобраться в каких пределах должна изменяться эта величина. Для этого нужно
- 58. 9 Хотя тест Дарбина – Уотсона не является в полном смысле этого слова статистическим тестом, тем
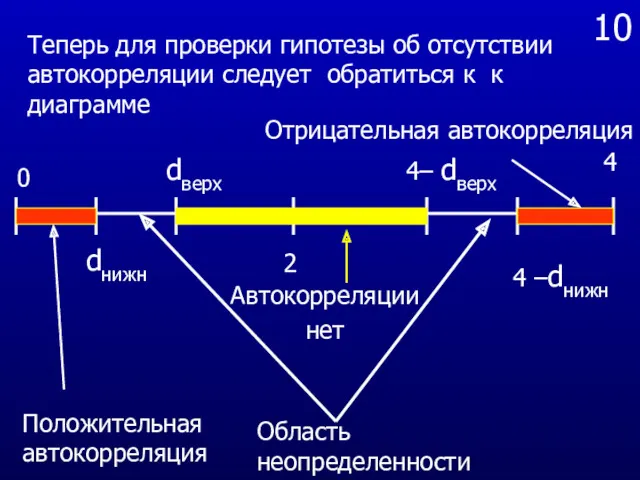
- 59. 10 Теперь для проверки гипотезы об отсутствии автокорреляции следует обратиться к к диаграмме 0 dнижн 2
- 60. 11 В рассматриваемом случае эмпирическое значение d попадает в область сильной положительной корреляции. По этой причине
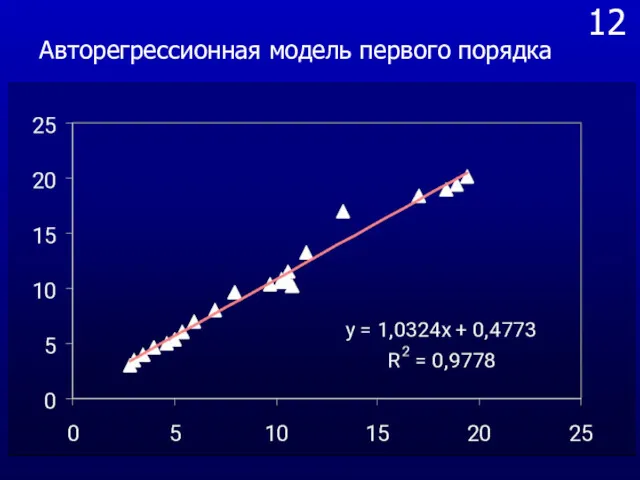
- 61. 12 Авторегрессионная модель первого порядка
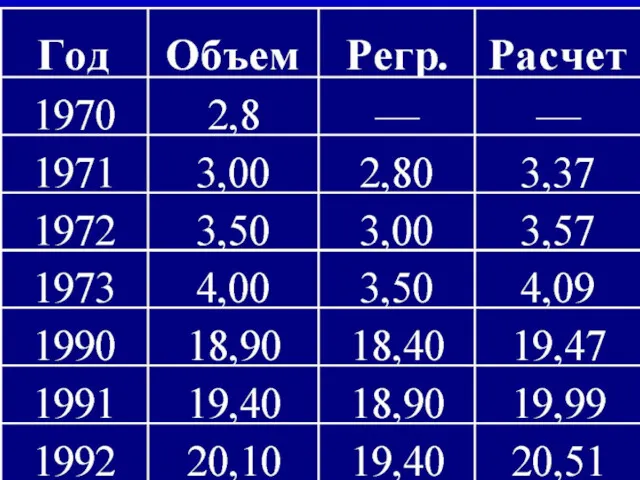
- 62. 12а На следующем слайде изображены часть исходных и расчетных данных. На основании расчетных данных можно строить
- 63. 13
- 64. 15 Эти данные позволяют построить два графика объема производства по годам эмпирический и расчетный. Обратите внимание
- 66. Скачать презентацию

5. 1. Постановка задачи и общие сведения о временных рядах
5. 1. Постановка задачи и общие сведения о временных рядах

1
Под временным рядом (рядом динамики) в экономике понимается совокупность наблюдений
1
Под временным рядом (рядом динамики) в экономике понимается совокупность наблюдений
2
Примером такого ряда могут быть данные о среднем размере товарных запасов
2
Примером такого ряда могут быть данные о среднем размере товарных запасов
3
Графическое представление временного ряда. Показана линия и уравнение тренда
3
Графическое представление временного ряда. Показана линия и уравнение тренда

4
Каждый уровень (значение) временного ряда формируется под действием большого числа факторов,
4
Каждый уровень (значение) временного ряда формируется под действием большого числа факторов,

5
Естественно предположить, что все четыре компоненты (трендовая, сезонная, циклическая и случайная)
5
Естественно предположить, что все четыре компоненты (трендовая, сезонная, циклическая и случайная)

6
Важно подчеркнуть. что в отличие от
Важнейшей классической задачей при
6
Важно подчеркнуть. что в отличие от
Важнейшей классической задачей при

7
Отметим основные этапы анализа временных рядов:
1. Графическое представление временного ряда;
2. Выделение
7
Отметим основные этапы анализа временных рядов:
1. Графическое представление временного ряда;
2. Выделение

8
На первый взгляд кажется. что набор величин
можно рассматривать как
8
На первый взгляд кажется. что набор величин
можно рассматривать как

5.2. Автокорреляция в рядах динамики
5.2. Автокорреляция в рядах динамики

1
При наличии во временном ряде тенденции или циклических колебаний значения
1
При наличии во временном ряде тенденции или циклических колебаний значения

2
Ниже представлена таблица с данными о частных расходах на жилищное
2
Ниже представлена таблица с данными о частных расходах на жилищное
3
Частные расходы на жилищное строительство в небольшом городке США за период
3
Частные расходы на жилищное строительство в небольшом городке США за период

4
Очевидно, что если сдвинуть данные ровно на год, то картина
4
Очевидно, что если сдвинуть данные ровно на год, то картина

4a
Пример 1. Аддитивная модель ряда.
Рассмотрим более удобный для анализа
4a
Пример 1. Аддитивная модель ряда.
Рассмотрим более удобный для анализа
5
Объем потребления электроэнергии (млрд. Квт/час) жителями региона за 16 кварталов
5
Объем потребления электроэнергии (млрд. Квт/час) жителями региона за 16 кварталов
6
Данные об объемах потребления электроэнергии (млрд. Квт/час) жителями региона за 16
6
Данные об объемах потребления электроэнергии (млрд. Квт/час) жителями региона за 16

6a
Вычислим коэффициенты корреляции исходных данных и данных сдвинутых на один
6a
Вычислим коэффициенты корреляции исходных данных и данных сдвинутых на один
7
7
7
7
8
С помощью функции Корелл ( ) электронных таблиц Excel найдем
8
С помощью функции Корелл ( ) электронных таблиц Excel найдем
9
9
9
9

10
Далеко не всегда автокорреляция столь заметна, как в рассмотренных выше
10
Далеко не всегда автокорреляция столь заметна, как в рассмотренных выше

11
Автокорреляция первого порядка характеризует тесноту связи между соседними значениями временного
11
Автокорреляция первого порядка характеризует тесноту связи между соседними значениями временного

12
Авторегрессионные модели разных порядков - первого, второго, в общем случае n-ого
12
Авторегрессионные модели разных порядков - первого, второго, в общем случае n-ого

5.3. Выделение тренда и сезонной составляющей для аддитивной и мультипликативной моделей
5.3. Выделение тренда и сезонной составляющей для аддитивной и мультипликативной моделей

1
Как уже отмечалось, важнейшей задачей исследования временного ряда в экономике
1
Как уже отмечалось, важнейшей задачей исследования временного ряда в экономике
2
В рассматриваемом примере 1 метод МНК для линейной модели регрессии
2
В рассматриваемом примере 1 метод МНК для линейной модели регрессии

3
Причина небольшого по величине фактора детерминации понятна, поскольку есть еще
3
Причина небольшого по величине фактора детерминации понятна, поскольку есть еще
4
Найдем сезонную + случайную величину для рассматриваемого примера. Для нахождения
4
Найдем сезонную + случайную величину для рассматриваемого примера. Для нахождения

5
Аналогично найдем сезонную компоненту за второй, третий и четвертый кварталы.
5
Аналогично найдем сезонную компоненту за второй, третий и четвертый кварталы.

6
Представляет интерес определить насколько хорошо детерминированная составляющая описывает эмпирический набор
6
Представляет интерес определить насколько хорошо детерминированная составляющая описывает эмпирический набор
7
Сопоставление эмпирических и расчетных (с учетом сезонной составляющей) данных
7
Сопоставление эмпирических и расчетных (с учетом сезонной составляющей) данных
8
Выделение трендовой, сезонной и случайной величин для примера с потреблением
8
Выделение трендовой, сезонной и случайной величин для примера с потреблением
9
Перейдем теперь к рассмотрению
Примера 2. мультипликативная модель.
Пусть
9
Перейдем теперь к рассмотрению
Примера 2. мультипликативная модель.
Пусть
10
Поквартальные данные о прибыли компании за четыре года
10
Поквартальные данные о прибыли компании за четыре года

11
Как видно из графика амплитуда осцилляций уменьшается, что и наводит
11
Как видно из графика амплитуда осцилляций уменьшается, что и наводит

12
Суть метода скользящей средней в том, что в данном случае
12
Суть метода скользящей средней в том, что в данном случае
13
13

14
После того, как рассчитана скользящая средняя, используя уравнение мультипликативной модели
14
После того, как рассчитана скользящая средняя, используя уравнение мультипликативной модели
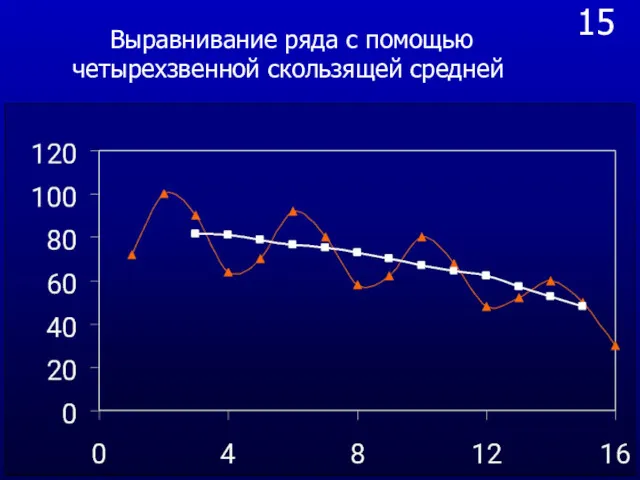
15
Выравнивание ряда с помощью четырехзвенной скользящей средней
15
Выравнивание ряда с помощью четырехзвенной скользящей средней
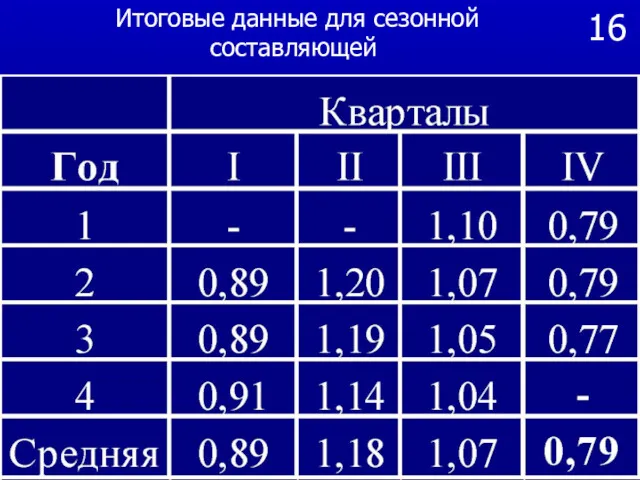
16
Итоговые данные для сезонной составляющей
16
Итоговые данные для сезонной составляющей

17
Существует простой способ проверить правильность проведенных вычислений для сезонной составляющей.
17
Существует простой способ проверить правильность проведенных вычислений для сезонной составляющей.
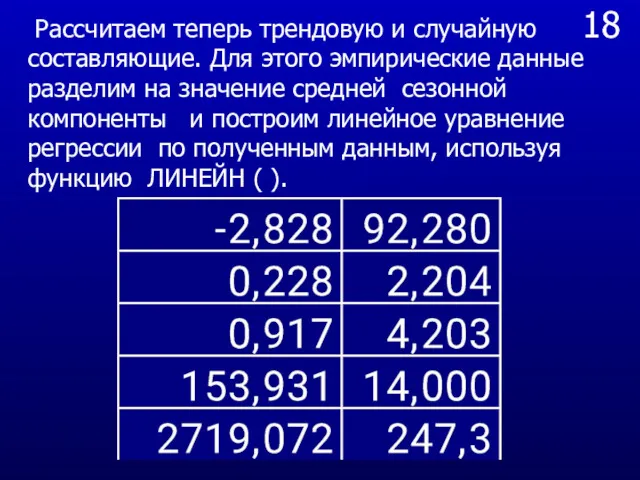
18
Рассчитаем теперь трендовую и случайную составляющие. Для этого эмпирические данные
18
Рассчитаем теперь трендовую и случайную составляющие. Для этого эмпирические данные

19
Как следует из приведенных результатов модель и регрессионные коэффициенты являются
19
Как следует из приведенных результатов модель и регрессионные коэффициенты являются

5.4. Прогнозирование по аддитивной и мультипликативной моделям
5.4. Прогнозирование по аддитивной и мультипликативной моделям

1
Предположим, что по данным рассмотренного Примера 1 необходимо дать прогноз
1
Предположим, что по данным рассмотренного Примера 1 необходимо дать прогноз

2
Прогнозное значение Ft уровня временного ряда в мультипликативной модели есть
2
Прогнозное значение Ft уровня временного ряда в мультипликативной модели есть

5.5. Обнаружение автокорреляции.
Авторегрессионые модели первого порядка.
5.5. Обнаружение автокорреляции.
Авторегрессионые модели первого порядка.

1
Рассмотрим прогнозирование для для авторегрессионной модели
первого порядка на примере статистического
1
Рассмотрим прогнозирование для для авторегрессионной модели
первого порядка на примере статистического
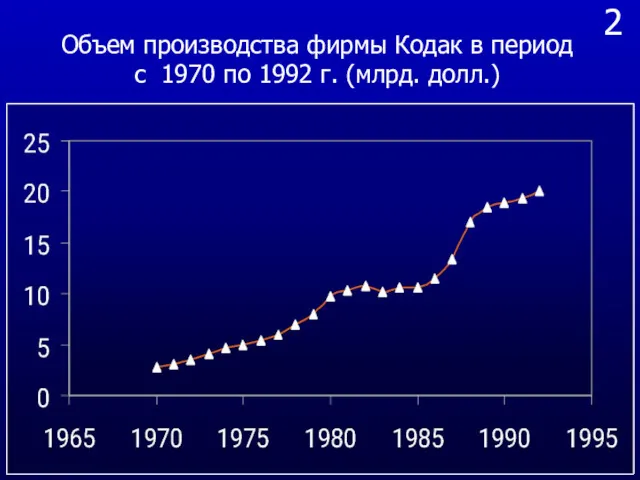
2
Объем производства фирмы Кодак в период с 1970 по 1992 г.
2
Объем производства фирмы Кодак в период с 1970 по 1992 г.
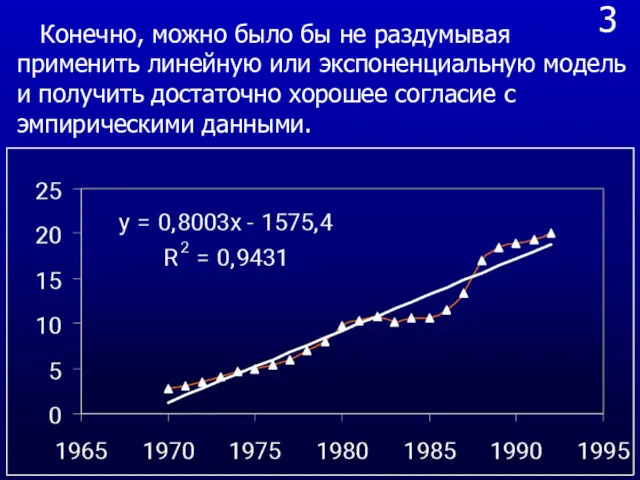
3
Конечно, можно было бы не раздумывая применить линейную или экспоненциальную
3
Конечно, можно было бы не раздумывая применить линейную или экспоненциальную

4
Большая величина фактора детерминации и статистическая значимость коэффициентов регрессии еще
4
Большая величина фактора детерминации и статистическая значимость коэффициентов регрессии еще

5
Тест Дарбина – Уотсона основан на простой идее: если корреляция
5
Тест Дарбина – Уотсона основан на простой идее: если корреляция

6
Несложные вычисления показывают, что статистика Дарбина – Уотсона просто связана с
6
Несложные вычисления показывают, что статистика Дарбина – Уотсона просто связана с
7
Схема расчета статистики Дарбина – Уотсона
7
Схема расчета статистики Дарбина – Уотсона

8
Таким образом,
Теперь следует разобраться в каких пределах должна изменяться эта
8
Таким образом,
Теперь следует разобраться в каких пределах должна изменяться эта

9
Хотя тест Дарбина – Уотсона не является в полном смысле этого
9
Хотя тест Дарбина – Уотсона не является в полном смысле этого
10
Теперь для проверки гипотезы об отсутствии автокорреляции следует обратиться к к
10
Теперь для проверки гипотезы об отсутствии автокорреляции следует обратиться к к

11
В рассматриваемом случае эмпирическое значение d попадает в область сильной положительной
11
В рассматриваемом случае эмпирическое значение d попадает в область сильной положительной
12
Авторегрессионная модель первого порядка
12
Авторегрессионная модель первого порядка

12а
На следующем слайде изображены часть исходных и расчетных данных. На
12а
На следующем слайде изображены часть исходных и расчетных данных. На
13
13

15
Эти данные позволяют построить два графика объема производства по годам
15
Эти данные позволяют построить два графика объема производства по годам
 Симметрия вокруг нас
Симметрия вокруг нас урок Скалярное произведение
урок Скалярное произведение Теория вероятностей
Теория вероятностей Игра Заселяем домики. Состав чисел от 2 до 9
Игра Заселяем домики. Состав чисел от 2 до 9 Минимизация логических функций
Минимизация логических функций Симметрия относительно прямой и мы в мире симметрии
Симметрия относительно прямой и мы в мире симметрии Простейшие преобразования графиков функций
Простейшие преобразования графиков функций Углы в кубе. Расстояния в кубе
Углы в кубе. Расстояния в кубе Занимательная математика
Занимательная математика Применение синквейна на уроках истории и обществознания
Применение синквейна на уроках истории и обществознания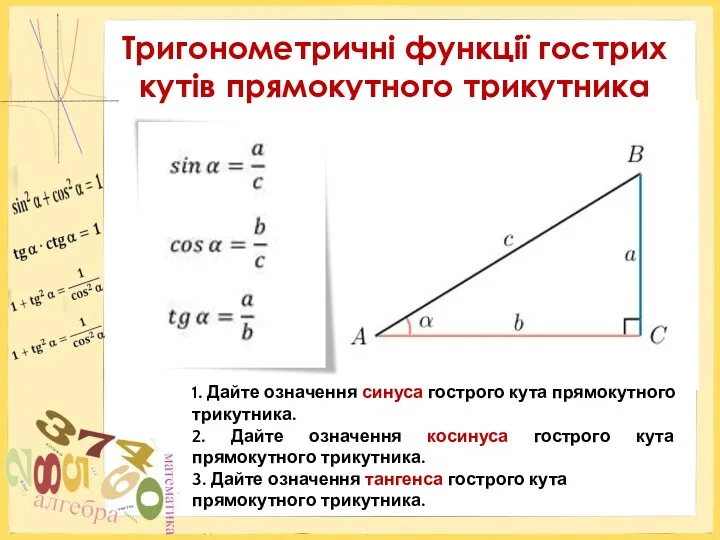 Тригонометричні функції гострих кутів прямокутного трикутника
Тригонометричні функції гострих кутів прямокутного трикутника Дроби. Устный счет
Дроби. Устный счет Элементы комбинаторики. Способы решения комбинаторных задач
Элементы комбинаторики. Способы решения комбинаторных задач Приближенные методы решения определенных интегралов
Приближенные методы решения определенных интегралов Сикһеҙ геометрик прогрессия
Сикһеҙ геометрик прогрессия Конкурсный урок геометрии в 7 классе. Тема урока Треугольники
Конкурсный урок геометрии в 7 классе. Тема урока Треугольники Прием письменного вычитания для случаев вида 7000-456
Прием письменного вычитания для случаев вида 7000-456 Отрицательные числа
Отрицательные числа Прямая на плоскости
Прямая на плоскости Интерактивное пособие по математике 1 класс.Рабочая тетрадь 1 часть (продолжение)
Интерактивное пособие по математике 1 класс.Рабочая тетрадь 1 часть (продолжение) Математический турнир
Математический турнир Презентация Знакомим дошкольника с часами
Презентация Знакомим дошкольника с часами Умножение и деление рациональных чисел
Умножение и деление рациональных чисел Натуральные числа. Урок-сказка
Натуральные числа. Урок-сказка Архангельск в огненные военные...
Архангельск в огненные военные... Определения многогранников. Теорема Эйлера
Определения многогранников. Теорема Эйлера Вписані та описані чотирикутники
Вписані та описані чотирикутники 23. Признак перпендикулярности двух плоскостей
23. Признак перпендикулярности двух плоскостей