- Статистика в НМД 2

Содержание
- 2. Логика проверки статистических гипотез Статистические критерии Статистический критерий (statistical test) – статистический метод принятия решения о
- 3. Процедура проверки статистической гипотезы
- 4. Классификация статистических методов (критериев)
- 8. Статистические методы сравнения 2-х выборок
- 9. Сравнение 2-х выборок по 1-му признаку Параметрические критерии – количественные нормально распределённые данные Критерий Стьюдента (t-критерий
- 10. Оценка статистической значимость различий между среднегрупповыми значениями с помощью t-критерия Стьюдента в MS Exel В MS
- 11. Алгоритм вычисления Из пакета «Анализ данных» выбрать необходимый тест, например парный двухвыборочный тест для средних (paired
- 12. Результаты анализа различий с помощью парного двухвыборочного t-теста Стьюдента Примечание. Значение 9.063E-05 для одностороннего Р. E-05
- 13. Непараметрический аналог t-критерия стьюдента для зависимых выборок - критерий знаковых рангов Вилкоксона (Wilcoxon Signed-Rank Test) Алгоритм
- 16. Применяется для сравнения двух зависимых групп по одному признаку. При размере выборки n>20 статистика критерия имеет
- 19. В поля «Лечение 1» («Treatment 1») и «Лечение 2» («Treatment 2») ввести данные из дыух выборок.
- 20. Статистические методы исследования зависимостей: корреляционный, дисперсионный и регрессионный анализ
- 21. Функциональная и статистическая зависимость Функциональная зависимость (взаимосвязь) - каждому значению одной переменной соответствует строго определенное значение
- 22. Для определения статистической зависимости применяют: корреляционный и дисперсный анализ - для установления факта наличия/отсутствия зависимости между
- 23. Корреляционный анализ. Виды корреляции Корреляционный анализ – применение статистических методов для исследования взаимосвязи между переменными, т.е.
- 24. Корреляционное поле (диаграмма рассеивания) Графическое представление данных в прямоугольной система координат, при котором каждой паре переменных
- 25. Коэффициент корреляции Коэффициент корреляции - количественная мера взаимосвязи (совместной изменчивости) двух переменных. Признаки (характеристики) коэффициентов линейной
- 26. Оценка коэффициента корреляции по шкале Чертока: 0,9- 1 очень сильная статистическая связь; 0,9-0,7 сильная; 0,7-0,5 средняя;
- 27. Коэффициент детерминации Является квадратом коэффициента корреляции зависимой и независимой переменных. Показывает, в какой степени изменчивость переменной
- 28. Коэффициент корреляции Пирсона (Pearson Correlation Coefficient) Назначение: используется для оценки силы и направления линейной связи между
- 29. Коэффициент ранговой корреляции Спирмена (Spearman's Rho) Назначение – непараметрический тест, используемый для оценки силы линейной ассоциации
- 30. Регрессионный анализ Линейная регрессия сходна, но не идентична линейной корреляции. Регрессионный анализ проводится, если корреляционный анализ
- 31. Простая линейная регрессия С помощью регрессионного анализа определяются параметры прямой, которая наилучшим способом предсказывает значение одной
- 32. у = а + bх, у - зависимая или предикторная переменная; х – независимая, объясняющая; а
- 33. ANOVA в отличие от множественного регрессионного анализа (работает с непрерывными предикторными переменными) использует категориальные предикторные переменные.
- 34. Методы статистической обработки данных в зависимости от их типа и от задач
- 35. Статистическая ошибка второго рода А. характеризует мощность теста. Б. является более критичной, чем ошибка первого рода.
- 37. Скачать презентацию

Логика проверки статистических гипотез
Статистические критерии
Статистический критерий (statistical test) – статистический метод
Логика проверки статистических гипотез
Статистические критерии
Статистический критерий (statistical test) – статистический метод
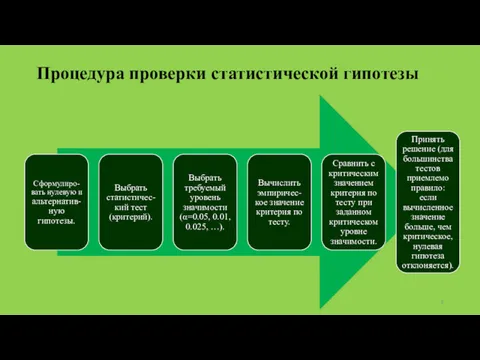
Процедура проверки статистической гипотезы
Процедура проверки статистической гипотезы

Классификация статистических методов (критериев)
Классификация статистических методов (критериев)



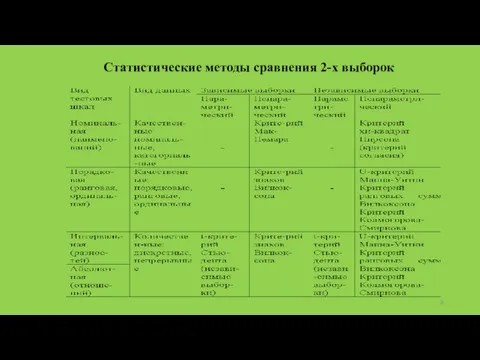
Статистические методы сравнения 2-х выборок

Сравнение 2-х выборок по 1-му признаку
Параметрические критерии – количественные нормально распределённые
Сравнение 2-х выборок по 1-му признаку
Параметрические критерии – количественные нормально распределённые

Оценка статистической значимость различий между среднегрупповыми значениями с помощью t-критерия Стьюдента
Оценка статистической значимость различий между среднегрупповыми значениями с помощью t-критерия Стьюдента
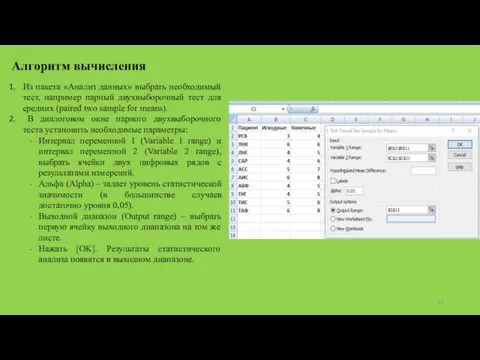
Алгоритм вычисления
Из пакета «Анализ данных» выбрать необходимый тест, например парный двухвыборочный
Алгоритм вычисления
Из пакета «Анализ данных» выбрать необходимый тест, например парный двухвыборочный
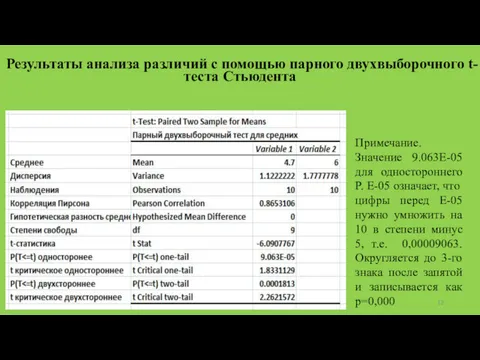
Результаты анализа различий с помощью парного двухвыборочного t-теста Стьюдента
Примечание. Значение 9.063E-05
Примечание. Значение 9.063E-05

Непараметрический аналог t-критерия стьюдента для зависимых выборок - критерий знаковых рангов
Непараметрический аналог t-критерия стьюдента для зависимых выборок - критерий знаковых рангов

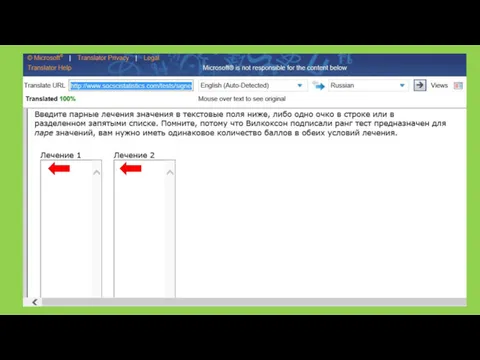

Применяется для сравнения двух зависимых групп по одному признаку.
При размере выборки
Применяется для сравнения двух зависимых групп по одному признаку.
При размере выборки
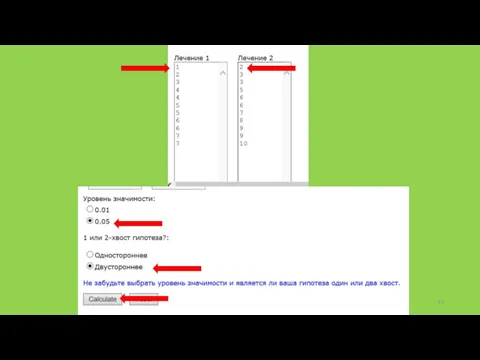


В поля «Лечение 1» («Treatment 1») и «Лечение 2» («Treatment 2»)
В поля «Лечение 1» («Treatment 1») и «Лечение 2» («Treatment 2»)

Статистические методы исследования зависимостей: корреляционный, дисперсионный и регрессионный анализ
Статистические методы исследования зависимостей: корреляционный, дисперсионный и регрессионный анализ

Функциональная и статистическая зависимость
Функциональная зависимость (взаимосвязь) - каждому значению одной переменной
Функциональная и статистическая зависимость
Функциональная зависимость (взаимосвязь) - каждому значению одной переменной

Для определения статистической зависимости применяют:
корреляционный и дисперсный анализ - для
Для определения статистической зависимости применяют:
корреляционный и дисперсный анализ - для

Корреляционный анализ. Виды корреляции
Корреляционный анализ – применение статистических методов для исследования
Корреляционный анализ. Виды корреляции
Корреляционный анализ – применение статистических методов для исследования
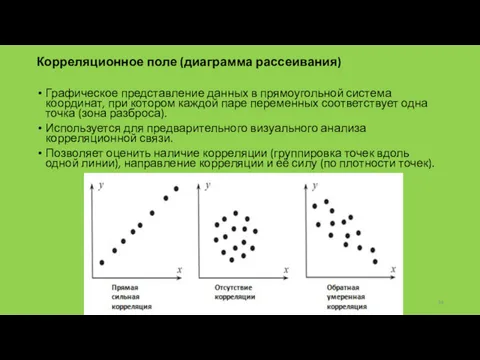
Корреляционное поле (диаграмма рассеивания)
Графическое представление данных в прямоугольной система координат,
Корреляционное поле (диаграмма рассеивания)
Графическое представление данных в прямоугольной система координат,

Коэффициент корреляции
Коэффициент корреляции - количественная мера взаимосвязи (совместной изменчивости) двух переменных.
Признаки
Коэффициент корреляции
Коэффициент корреляции - количественная мера взаимосвязи (совместной изменчивости) двух переменных.
Признаки

Оценка коэффициента корреляции по шкале Чертока:
0,9- 1 очень сильная статистическая связь;
0,9-0,7
Оценка коэффициента корреляции по шкале Чертока:
0,9- 1 очень сильная статистическая связь;
0,9-0,7

Коэффициент детерминации
Является квадратом коэффициента корреляции зависимой и независимой переменных.
Показывает, в какой
Коэффициент детерминации
Является квадратом коэффициента корреляции зависимой и независимой переменных.
Показывает, в какой

Коэффициент корреляции Пирсона (Pearson Correlation Coefficient)
Назначение: используется для оценки силы и
Коэффициент корреляции Пирсона (Pearson Correlation Coefficient)
Назначение: используется для оценки силы и

Коэффициент ранговой корреляции Спирмена (Spearman's Rho)
Назначение – непараметрический тест, используемый
Коэффициент ранговой корреляции Спирмена (Spearman's Rho)
Назначение – непараметрический тест, используемый

Регрессионный анализ
Линейная регрессия сходна, но не идентична линейной корреляции. Регрессионный анализ
Регрессионный анализ
Линейная регрессия сходна, но не идентична линейной корреляции. Регрессионный анализ

Простая линейная регрессия
С помощью регрессионного анализа определяются параметры прямой, которая наилучшим
Простая линейная регрессия
С помощью регрессионного анализа определяются параметры прямой, которая наилучшим
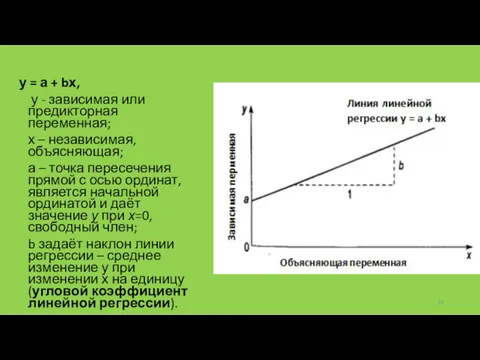
у = а + bх,
у - зависимая или предикторная переменная;
у = а + bх,
у - зависимая или предикторная переменная;

ANOVA в отличие от множественного регрессионного анализа (работает с непрерывными предикторными
ANOVA в отличие от множественного регрессионного анализа (работает с непрерывными предикторными

Методы статистической обработки данных в зависимости от их типа и от
Методы статистической обработки данных в зависимости от их типа и от

Статистическая ошибка второго рода
А. характеризует мощность теста.
Б. является более критичной,
Статистическая ошибка второго рода
А. характеризует мощность теста.
Б. является более критичной,
 Вписанная и описанная окружности
Вписанная и описанная окружности Нахождение дроби от числа
Нахождение дроби от числа Задачи на построение. Геометрия. 7 класс
Задачи на построение. Геометрия. 7 класс Знакомство с задачами
Знакомство с задачами Решение уравнений. 2 класс. УМК Гармония
Решение уравнений. 2 класс. УМК Гармония Неопределённый интеграл, его свойства . Непосредственное интегрирование. Метод замены переменной в неопределенном интеграле
Неопределённый интеграл, его свойства . Непосредственное интегрирование. Метод замены переменной в неопределенном интеграле Знакомим дошкольников с часами
Знакомим дошкольников с часами Развёртка прямоугольного параллелепипеда. Урок 143
Развёртка прямоугольного параллелепипеда. Урок 143 Кубизм в архитектуре. Оригами
Кубизм в архитектуре. Оригами Фалес Милетский. Нахождение расстояния до недоступного предмета
Фалес Милетский. Нахождение расстояния до недоступного предмета Сложение чисел с разными знаками» (проверочная работа)
Сложение чисел с разными знаками» (проверочная работа) Площадь криволинейной трапеции и интеграл
Площадь криволинейной трапеции и интеграл Решение систем, содержащих уравнения второй степени
Решение систем, содержащих уравнения второй степени Осевая и центральная симметрия 8 класс
Осевая и центральная симметрия 8 класс Умножение и деление обыкновенных дробей
Умножение и деление обыкновенных дробей Своя игра. 5 класс
Своя игра. 5 класс Луч и угол
Луч и угол Презентация Занимательная геометрия
Презентация Занимательная геометрия Презентация Веселая математика с Винни-Пухом
Презентация Веселая математика с Винни-Пухом Прямоугольный параллелепипед
Прямоугольный параллелепипед Измерение углов. Транспортир. 5 класс
Измерение углов. Транспортир. 5 класс Математика вокруг нас: форма, размер, цвет
Математика вокруг нас: форма, размер, цвет Конспект урока по математике Составные задачи 1 класс. (Программа Петерсон Л.Г.)
Конспект урока по математике Составные задачи 1 класс. (Программа Петерсон Л.Г.) Презентация по математике на тему Какие бывают алгоритмы
Презентация по математике на тему Какие бывают алгоритмы Дидактическая игра Круги и квадраты (презентация)
Дидактическая игра Круги и квадраты (презентация) Подготовка к ВПР. Математика 3 задание. Арифметический метод
Подготовка к ВПР. Математика 3 задание. Арифметический метод Заниматика №3
Заниматика №3 Способы решения логических задач
Способы решения логических задач