- Выборка в социологическом исследовании

Содержание
- 2. Основные понятия выборочного метода Генеральная совокупность – совокупность всех единиц наблюдения. Почти всегда «объект» исследования и
- 3. Гипотетическая совокупность
- 4. Производная совокупность выборок объемом n=2 Среднее средних – 9400 долларов
- 5. Параметр (средний доход)= 9400 долларов К=25 Выборка=ВН Статистика (выборочный средний доход)= 7200 долларов К=62 Выборка=DL Статистика
- 6. Распределение по числу выборок
- 7. х Частота Частота 1 0 Распределение количественного признака в генеральной совокупности и 0 Распределение оценок в
- 8. Центральная предельная теорема Для простых случайных выборок объемом n, выделенных из генеральной совокупности с генеральным средним
- 9. Значение х n=2 Распределение выборочных средних для выборок различного объема и различных популяционных распределений
- 10. Доверительные интервалы Доверительный интервал - интервал, который покрывает неизвестный параметр с заданной надёжностью. 68,26% выборочных средних
- 11. Доверительные интервалы (при µ=9200)
- 12. Репрезентативность Репрезентативность – соответствие характеристик выборочной совокупности характеристикам генеральной. Репрезентативность определяет, насколько возможно обобщать результаты исследования
- 13. Свойства репрезентативности Репрезентативность не бывает вообще – репрезентативность существует только по определенным переменным. Репрезентативность не обеспечивает
- 14. Типы выборки
- 15. Простая вероятностная Выборка в которой каждый элемент генеральной совокупности имеет одинаковую, заданную и независимую вероятность попадания
- 16. Систематическая Выборка в которой сначала из генеральной совокупности N случайно выбирается первый элемент выборочной совокупности i1,
- 17. Стратифицированная Двухэтапная выборка, при которой сначала генеральная совокупность делится на страты (слои), каждая из которых содержит
- 18. Гипотетическая совокупность
- 19. Распределение по числу выборок
- 20. Определение средней и среднеквадратичной ошибки
- 21. Кластерная Выборка в которой сначала генеральная совокупность делится на кластеры (гнезда), каждый из которых имеет примерно
- 22. Территориальная выборка Кластерная выборка чаще всего используется в случаях, когда необходимо собрать данные в генеральной совокупности,
- 23. Территориальная выборка 1 этап – генеральная совокупность разделена на непересекающиеся, исчерпывающие генеральную совокупность, сравнимые по объему
- 24. По удобству Выборка в которой выборочная совокупность формируется исходя из возможностей исследователя. Чаще всего, процесс выборки
- 25. Направленный отбор Выборка в которой выборочная совокупность из тех единиц генеральной, которые по мнению исследователя отвечают
- 26. Квотный отбор Выборка в которой вначале выбираются критерии для отбора респондентов – пол, возраст, район проживания,
- 27. Квотный отбор Если выбраны релевантные целям данного исследования и значимые характеристики, то результаты данного отбора будут
- 28. Снежный ком Этап формирования выборочной совокупности, который проводят после отбора респондентов по любой из схем вероятностного
- 29. Реализация репрезентативной выборки в массовом опросе Лекция 7 Звоновский, к.с.н.
- 30. Территориальный дизайн выборки
- 31. Опрос производился по специально спроектированной многоступенчатой выборке, репрезентирующей взрослое (старше 18 лет) население Самарской области. Формирование
- 32. Отбор производился в четыре этапа. На первом этапе отбирались населенные пункты, где должен был проводиться опрос.
- 33. На первом этапе все населенные пункты области были стратифицированы на восемь частей по типу поселения, исходя
- 34. Формирование выборки
- 35. Далее городские страты были стратифицированы с целью максимально точного воспроизведения в выборочной совокупности соотношения населения в
- 36. Исследовательский опыт показывает, что деление Самары по административным районам не всегда оправдано, поскольку различия в настроениях
- 37. Самара делится на 4+2 страты: на 4 делится основная часть города, части примерно равны, границы частей
- 38. Третий и четвертый этапы отбора (отбор домохозяйств) был различным для Самары и Тольятти (крупнейших городов области),
- 39. В Самаре и Тольятти третий и четвертый этапы формирования выборки были реализованы иным способом. В этих
- 40. Адресная и именная схемы выборки
- 41. При адресной схеме отбора каждый интервьюер должен был опросить на выданном ему избирательном участке определенное (также
- 42. Помимо этого каждому интервьюеру выдавалось квотное задание, в котором было указано, сколько респондентов определенного пола и
- 43. Из полной базы респондентов по Самаре и Тольятти с помощью специального программного обеспечения (модуль SPSS Complex
- 44. Перед проведением сентябрьской волны интервьюерам выдавались квотные задания. Реализация квотных ограничений состояла в том, что, когда
- 45. Преимущества и недостатки адресной и именной выборок
- 46. Адресная vs. именная выборка Именная выборка позволяет существенно увеличить долю законченных интервью и уменьшить долю отказов.
- 47. Многократное посещение
- 48. Многократное посещение Увеличение числа посещений увеличивает долю несостоявшихся контактов. При этом доля законченных интервью остается примерно
- 49. Трехкратное посещение и мобильность молодежи Увеличение числа посещений также увеличивает долю молодежи в выборке и приближает
- 50. Шестикратное посещение Однако даже шестикратное посещение не восстанавливает долю молодежи в генеральной совокупности.
- 51. Возрастные группы респондентов, которых сначала не заставали дома, а затем все-таки опросили В результате повторное посещение
- 52. Качество базы жителей города и статистических данных Серьезной проблемой является вопрос о расхождении (причем, значимом при
- 53. Возможное решение проблемы нехватки молодежи Поскольку задача репрезентации молодежи в выборочной совокупности даже после шестикратного посещения
- 54. Суточная динамика результатов опроса
- 55. Суточная динамика результатов опроса Суточная динамика момента первого посещения в сентябре и декабре 2005 г. Суточная
- 56. Суточная динамика результатов опроса Суточная динамика момента опроса за все три посещения в сентябре и декабре
- 57. Увеличивает ли число посещений количество отказов?
- 58. Увеличивает ли число посещений количество отказов? Здравый смысл подсказывает, что повторные посещения могут привести к увеличению
- 59. Возрастные группы респондентов, отказавшихся от интервью после первого посещения Возрастные группы респондентов, которых сначала не заставали,
- 60. Определение объема выборки Лекция 8 Звоновский, к.с.н.
- 61. Расчет объема выборки Выборочное измерение проводят с целью получить значение одного из количественных параметров генеральной совокупности
- 62. Дисперсия оценки выборочного среднего определяет объем выборки σₓ = σ ⁄ √ n Увеличение размера выборки
- 63. Объем выборки для оценки среднего Случай когда выборочная дисперсия известна Пусть выборочная оценка (результат измерения) не
- 64. Объем выборки для оценки среднего Случай когда выборочная дисперсия известна Пример. Необходимо определить объем выборки для
- 65. Объем выборки для оценки среднего Случай когда выборочная дисперсия неизвестна При первом расчете выборки мы оцениваем
- 66. Объем выборки для оценки среднего Случай когда выборочная дисперсия неизвестна Оценка дисперсии: 15 посещений магазина в
- 67. Объем выборки в случае конечной генеральной совокупности В случае, если объем выборочной совокупности составляет значимую долю
- 68. Объем выборки для оценки доли Распределение выборочных долей при небольших объемах выборки (n=30) является биноминальным. Но
- 69. Коррекция объема выборки Коррекция на инцидентность (проникновение). В случае, если в выборочной совокупности доля целевой подгруппы
- 70. Коррекция объема выборки Коррекция на неполное заполнение. В случае, если анкеты заполнены не полностью, необходимо увеличить
- 71. Коррекция объема выборки Объем выборки следует увеличивать в случае измерения параметра в перекрестных группах. Например, доли
- 73. Скачать презентацию

Основные понятия выборочного метода
Генеральная совокупность – совокупность всех единиц наблюдения.
Основные понятия выборочного метода
Генеральная совокупность – совокупность всех единиц наблюдения.
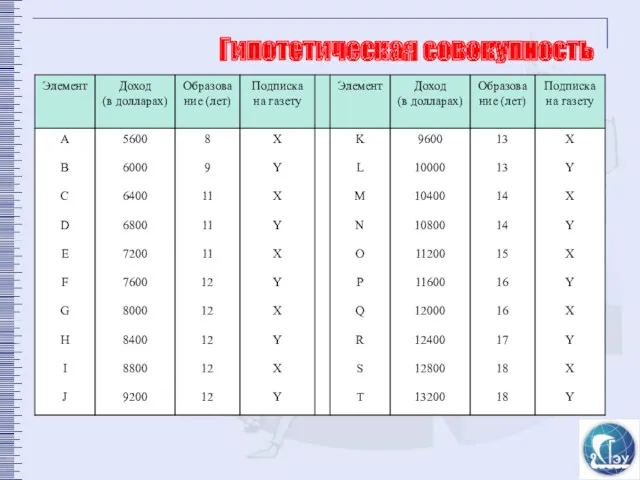
Гипотетическая совокупность
Гипотетическая совокупность
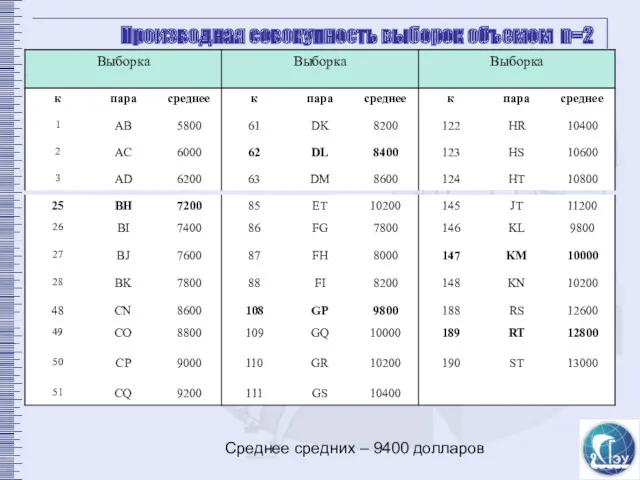
Производная совокупность выборок объемом n=2
Среднее средних – 9400 долларов
Производная совокупность выборок объемом n=2
Среднее средних – 9400 долларов
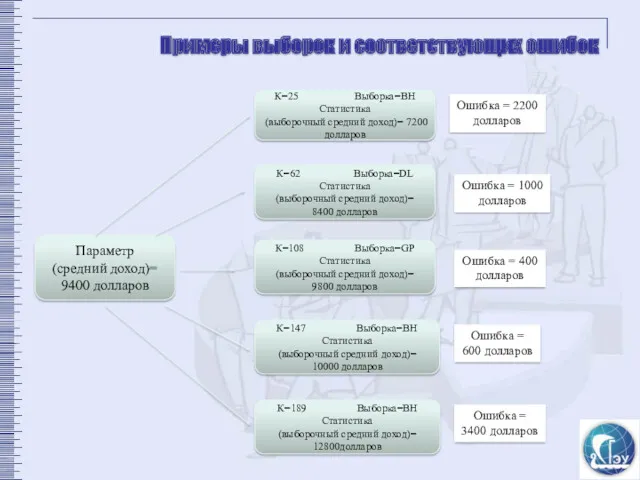
Параметр
(средний доход)=
9400 долларов
К=25 Выборка=ВН
Статистика
(выборочный средний доход)= 7200 долларов
К=62
Параметр
(средний доход)=
9400 долларов
К=25 Выборка=ВН
Статистика
(выборочный средний доход)= 7200 долларов
К=62
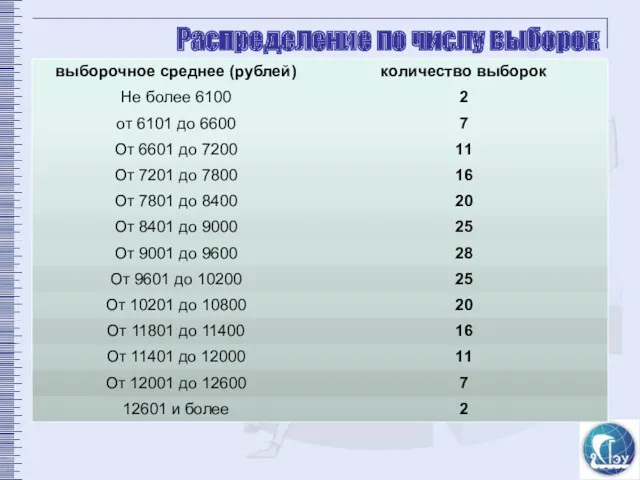
Распределение по числу выборок
Распределение по числу выборок
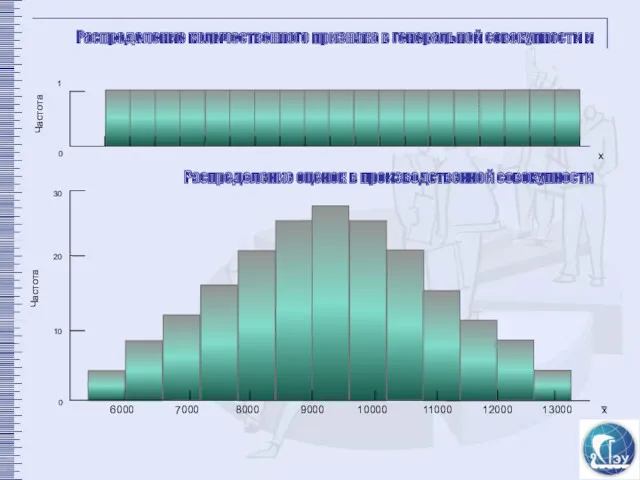
х
Частота
Частота
1
0
Распределение количественного признака в генеральной совокупности и
0
Распределение оценок в производственной совокупности
х
Частота
Частота
1
0
Распределение количественного признака в генеральной совокупности и
0
Распределение оценок в производственной совокупности

Центральная предельная теорема
Для простых случайных выборок объемом n, выделенных из генеральной
Центральная предельная теорема
Для простых случайных выборок объемом n, выделенных из генеральной
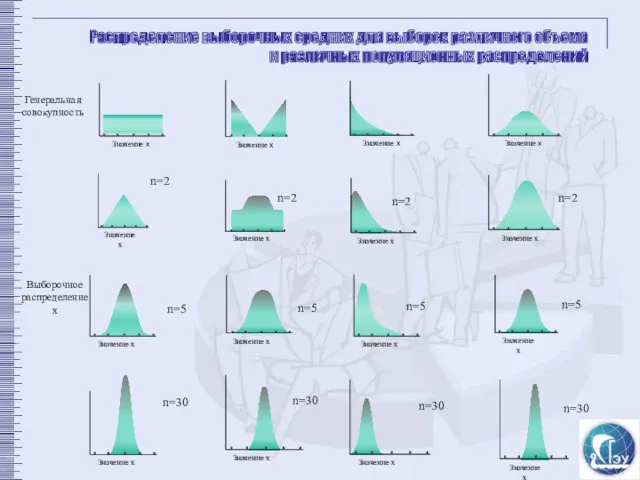
Значение х
n=2
Распределение выборочных средних для выборок различного объема
и различных популяционных
Значение х
n=2
Распределение выборочных средних для выборок различного объема
и различных популяционных

Доверительные интервалы
Доверительный интервал - интервал, который покрывает неизвестный параметр с заданной
Доверительные интервалы
Доверительный интервал - интервал, который покрывает неизвестный параметр с заданной
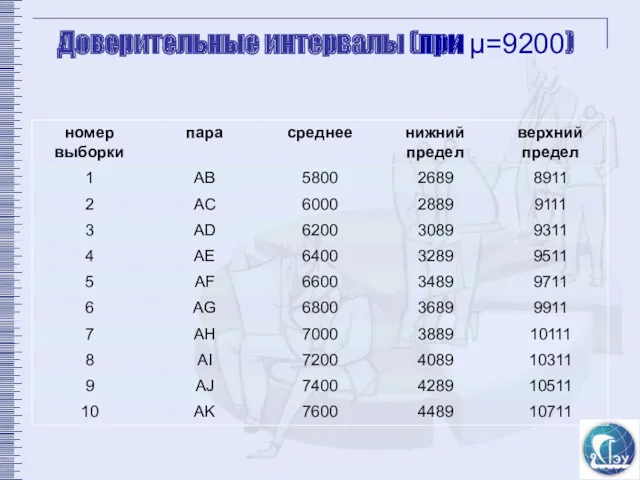
Доверительные интервалы (при µ=9200)
Доверительные интервалы (при µ=9200)

Репрезентативность
Репрезентативность – соответствие характеристик выборочной совокупности характеристикам генеральной. Репрезентативность определяет, насколько
Репрезентативность
Репрезентативность – соответствие характеристик выборочной совокупности характеристикам генеральной. Репрезентативность определяет, насколько

Свойства репрезентативности
Репрезентативность не бывает вообще – репрезентативность существует только по определенным
Свойства репрезентативности
Репрезентативность не бывает вообще – репрезентативность существует только по определенным
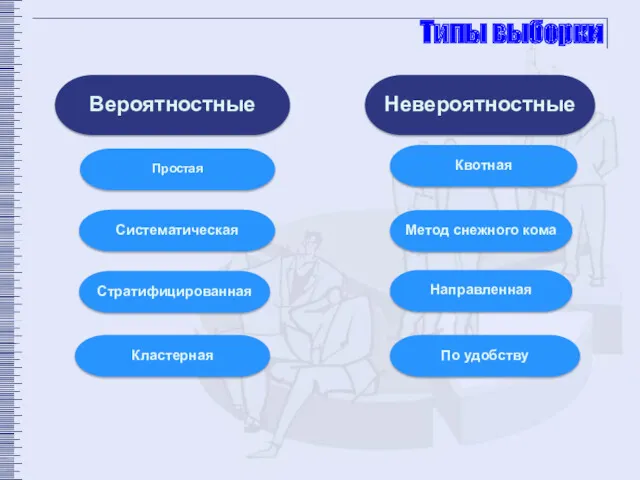
Типы выборки
Типы выборки

Простая вероятностная
Выборка в которой каждый элемент генеральной совокупности имеет одинаковую, заданную
Простая вероятностная
Выборка в которой каждый элемент генеральной совокупности имеет одинаковую, заданную

Систематическая
Выборка в которой сначала из генеральной совокупности N случайно выбирается первый
Систематическая
Выборка в которой сначала из генеральной совокупности N случайно выбирается первый

Стратифицированная
Двухэтапная выборка, при которой сначала генеральная совокупность делится на страты (слои),
Стратифицированная
Двухэтапная выборка, при которой сначала генеральная совокупность делится на страты (слои),
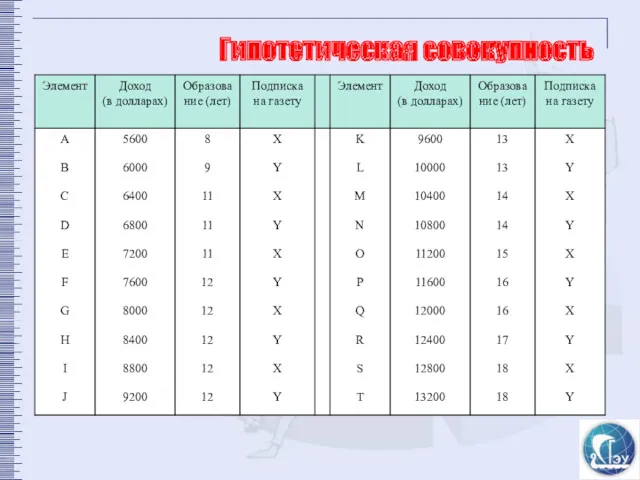
Гипотетическая совокупность
Гипотетическая совокупность
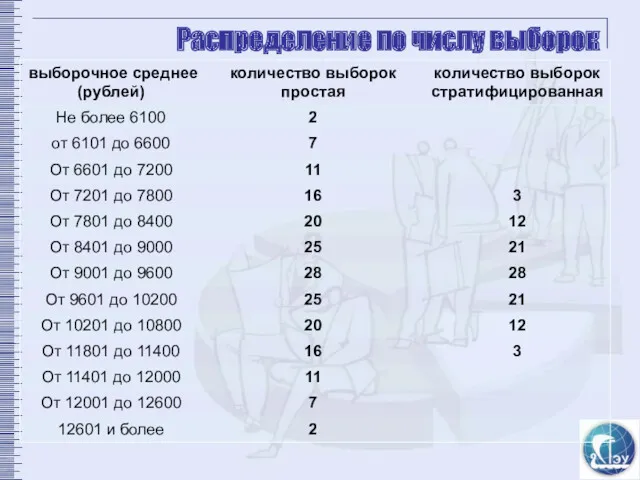
Распределение по числу выборок
Распределение по числу выборок

Определение средней и среднеквадратичной ошибки
Определение средней и среднеквадратичной ошибки

Кластерная
Выборка в которой сначала генеральная совокупность делится на кластеры (гнезда), каждый
Кластерная
Выборка в которой сначала генеральная совокупность делится на кластеры (гнезда), каждый

Территориальная выборка
Кластерная выборка чаще всего используется в случаях, когда необходимо собрать
Территориальная выборка
Кластерная выборка чаще всего используется в случаях, когда необходимо собрать

Территориальная выборка
1 этап – генеральная совокупность разделена на непересекающиеся, исчерпывающие генеральную
Территориальная выборка
1 этап – генеральная совокупность разделена на непересекающиеся, исчерпывающие генеральную

По удобству
Выборка в которой выборочная совокупность формируется исходя из возможностей исследователя.
По удобству
Выборка в которой выборочная совокупность формируется исходя из возможностей исследователя.

Направленный отбор
Выборка в которой выборочная совокупность из тех единиц генеральной, которые
Направленный отбор
Выборка в которой выборочная совокупность из тех единиц генеральной, которые

Квотный отбор
Выборка в которой вначале выбираются критерии для отбора респондентов –
Квотный отбор
Выборка в которой вначале выбираются критерии для отбора респондентов –

Квотный отбор
Если выбраны релевантные целям данного исследования и значимые характеристики, то
Квотный отбор
Если выбраны релевантные целям данного исследования и значимые характеристики, то

Снежный ком
Этап формирования выборочной совокупности, который проводят после отбора респондентов по
Снежный ком
Этап формирования выборочной совокупности, который проводят после отбора респондентов по

Реализация репрезентативной выборки в массовом опросе
Лекция 7
Звоновский, к.с.н.
Реализация репрезентативной выборки в массовом опросе
Лекция 7
Звоновский, к.с.н.

Территориальный дизайн выборки
Территориальный дизайн выборки

Опрос производился по специально спроектированной многоступенчатой выборке, репрезентирующей взрослое (старше 18
Опрос производился по специально спроектированной многоступенчатой выборке, репрезентирующей взрослое (старше 18
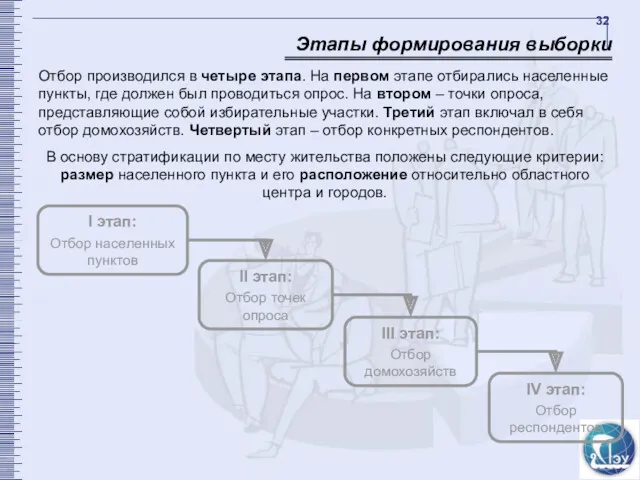
Отбор производился в четыре этапа. На первом этапе отбирались населенные пункты,
Отбор производился в четыре этапа. На первом этапе отбирались населенные пункты,

На первом этапе все населенные пункты области были стратифицированы на восемь
На первом этапе все населенные пункты области были стратифицированы на восемь
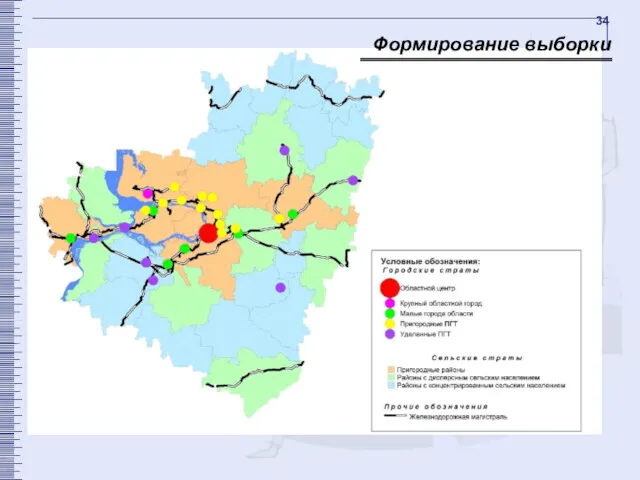
Формирование выборки
Формирование выборки

Далее городские страты были стратифицированы с целью максимально точного воспроизведения в
Далее городские страты были стратифицированы с целью максимально точного воспроизведения в

Исследовательский опыт показывает, что деление Самары по административным районам не всегда
Исследовательский опыт показывает, что деление Самары по административным районам не всегда
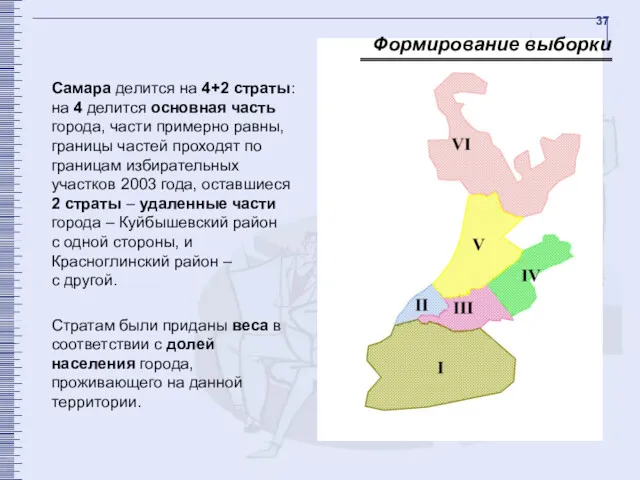
Самара делится на 4+2 страты: на 4 делится основная часть города,
Самара делится на 4+2 страты: на 4 делится основная часть города,

Третий и четвертый этапы отбора (отбор домохозяйств) был различным для Самары
Третий и четвертый этапы отбора (отбор домохозяйств) был различным для Самары

В Самаре и Тольятти третий и четвертый этапы формирования выборки были
В Самаре и Тольятти третий и четвертый этапы формирования выборки были

Адресная и именная схемы выборки
Адресная и именная схемы выборки

При адресной схеме отбора каждый интервьюер должен был опросить на выданном
При адресной схеме отбора каждый интервьюер должен был опросить на выданном

Помимо этого каждому интервьюеру выдавалось квотное задание, в котором было указано,
Помимо этого каждому интервьюеру выдавалось квотное задание, в котором было указано,

Из полной базы респондентов по Самаре и Тольятти с помощью специального
Из полной базы респондентов по Самаре и Тольятти с помощью специального

Перед проведением сентябрьской волны интервьюерам выдавались квотные задания.
Реализация квотных ограничений состояла
Перед проведением сентябрьской волны интервьюерам выдавались квотные задания.
Реализация квотных ограничений состояла
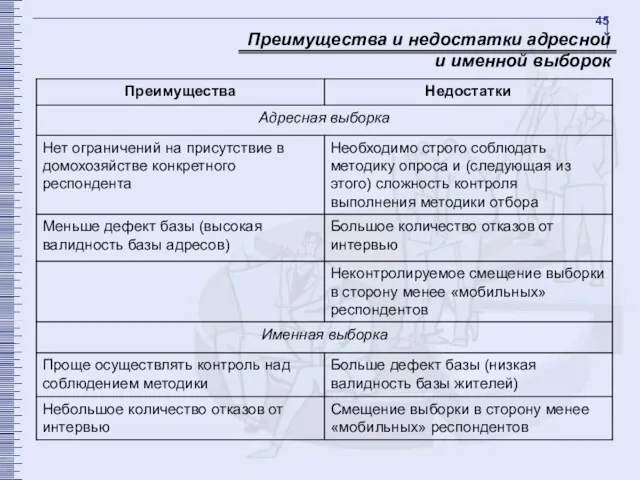
Преимущества и недостатки адресной и именной выборок
Преимущества и недостатки адресной и именной выборок
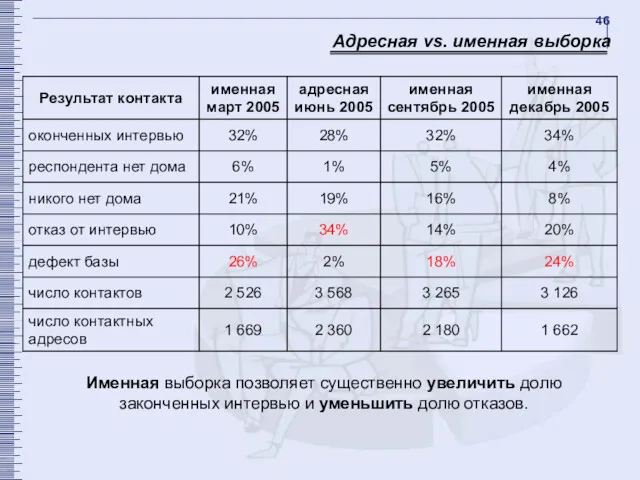
Адресная vs. именная выборка
Именная выборка позволяет существенно увеличить долю законченных интервью
Адресная vs. именная выборка
Именная выборка позволяет существенно увеличить долю законченных интервью

Многократное посещение
Многократное посещение
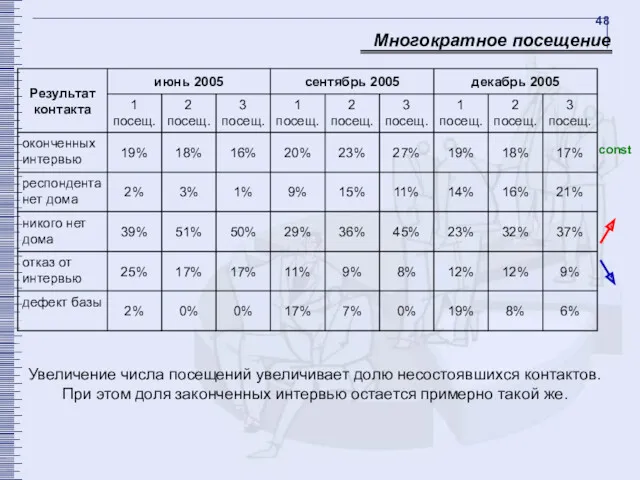
Многократное посещение
Увеличение числа посещений увеличивает долю несостоявшихся контактов. При этом доля
Многократное посещение
Увеличение числа посещений увеличивает долю несостоявшихся контактов. При этом доля

Трехкратное посещение и мобильность молодежи
Увеличение числа посещений также увеличивает долю молодежи
Трехкратное посещение и мобильность молодежи
Увеличение числа посещений также увеличивает долю молодежи
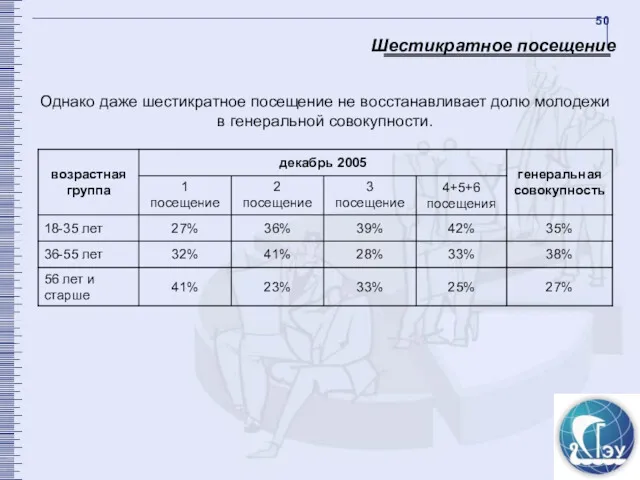
Шестикратное посещение
Однако даже шестикратное посещение не восстанавливает долю молодежи в генеральной
Шестикратное посещение
Однако даже шестикратное посещение не восстанавливает долю молодежи в генеральной
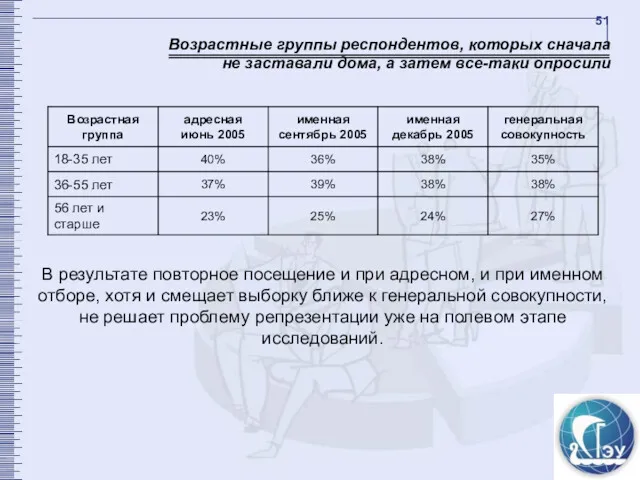
Возрастные группы респондентов, которых сначала не заставали дома, а затем все-таки
Возрастные группы респондентов, которых сначала не заставали дома, а затем все-таки
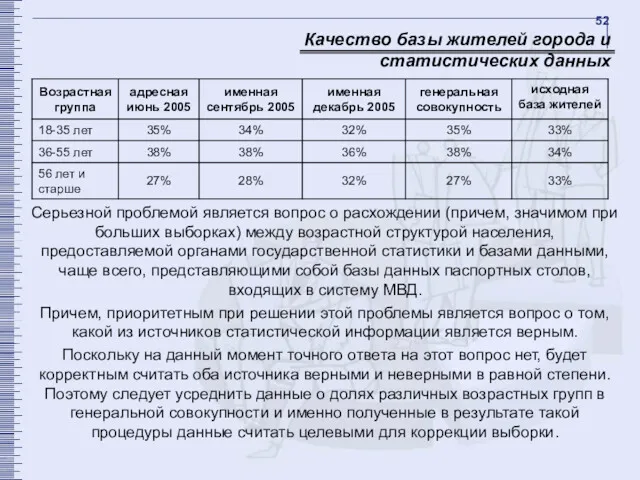
Качество базы жителей города и статистических данных
Серьезной проблемой является вопрос о
Качество базы жителей города и статистических данных
Серьезной проблемой является вопрос о

Возможное решение
проблемы нехватки молодежи
Поскольку задача репрезентации молодежи в выборочной совокупности даже
Возможное решение
проблемы нехватки молодежи
Поскольку задача репрезентации молодежи в выборочной совокупности даже

Суточная динамика результатов опроса
Суточная динамика результатов опроса
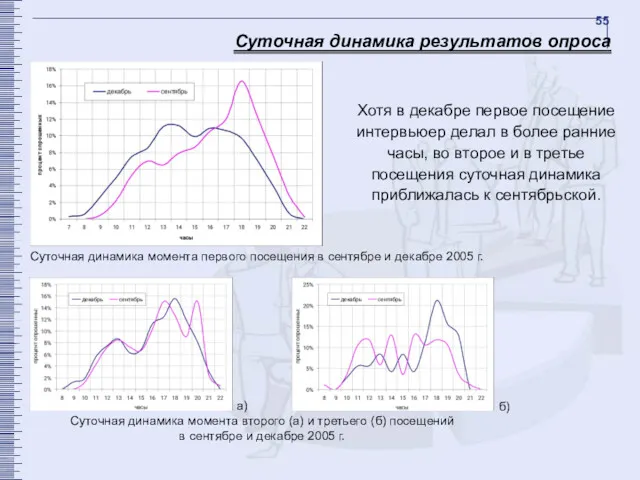
Суточная динамика результатов опроса
Суточная динамика момента первого посещения в сентябре и
Суточная динамика результатов опроса
Суточная динамика момента первого посещения в сентябре и
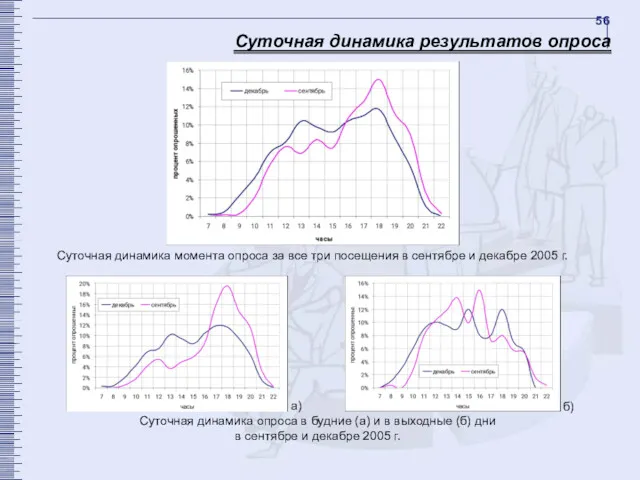
Суточная динамика результатов опроса
Суточная динамика момента опроса за все три посещения
Суточная динамика результатов опроса
Суточная динамика момента опроса за все три посещения

Увеличивает ли число посещений количество отказов?
Увеличивает ли число посещений количество отказов?
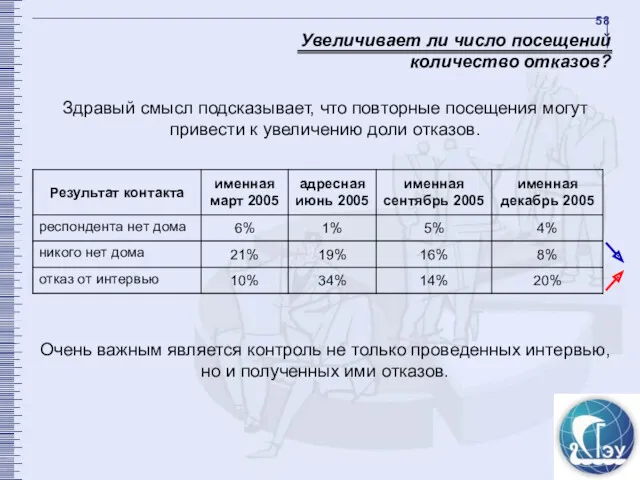
Увеличивает ли число посещений количество отказов?
Здравый смысл подсказывает, что повторные посещения
Увеличивает ли число посещений количество отказов?
Здравый смысл подсказывает, что повторные посещения
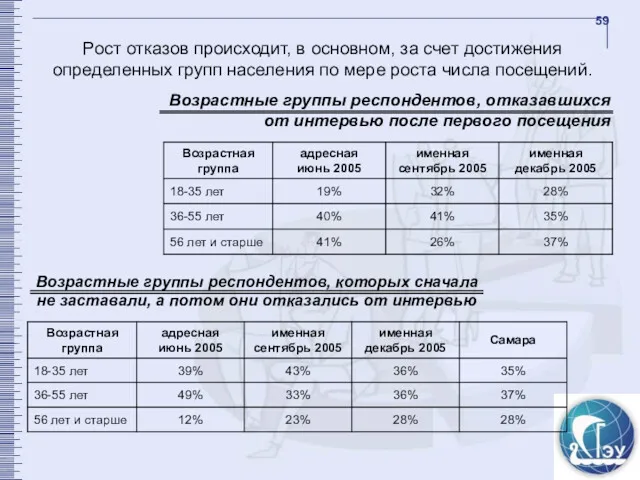
Возрастные группы респондентов, отказавшихся от интервью после первого посещения
Возрастные группы респондентов,
Возрастные группы респондентов, отказавшихся от интервью после первого посещения
Возрастные группы респондентов,

Определение объема выборки
Лекция 8
Звоновский, к.с.н.
Определение объема выборки
Лекция 8
Звоновский, к.с.н.

Расчет объема выборки
Выборочное измерение проводят с целью получить значение одного из
Расчет объема выборки
Выборочное измерение проводят с целью получить значение одного из

Дисперсия оценки выборочного среднего определяет объем выборки
σₓ = σ ⁄ √
Дисперсия оценки выборочного среднего определяет объем выборки
σₓ = σ ⁄ √

Объем выборки для оценки среднего
Случай когда выборочная дисперсия известна
Пусть выборочная
Объем выборки для оценки среднего
Случай когда выборочная дисперсия известна
Пусть выборочная

Объем выборки для оценки среднего
Случай когда выборочная дисперсия известна
Пример. Необходимо
Объем выборки для оценки среднего
Случай когда выборочная дисперсия известна
Пример. Необходимо

Объем выборки для оценки среднего
Случай когда выборочная дисперсия неизвестна
При первом
Объем выборки для оценки среднего
Случай когда выборочная дисперсия неизвестна
При первом

Объем выборки для оценки среднего
Случай когда выборочная дисперсия неизвестна
Оценка дисперсии:
Объем выборки для оценки среднего
Случай когда выборочная дисперсия неизвестна
Оценка дисперсии:

Объем выборки в случае конечной генеральной совокупности
В случае, если объем
Объем выборки в случае конечной генеральной совокупности
В случае, если объем

Объем выборки для оценки доли
Распределение выборочных долей при небольших объемах
Объем выборки для оценки доли
Распределение выборочных долей при небольших объемах

Коррекция объема выборки
Коррекция на инцидентность (проникновение). В случае, если в выборочной
Коррекция объема выборки
Коррекция на инцидентность (проникновение). В случае, если в выборочной

Коррекция объема выборки
Коррекция на неполное заполнение. В случае, если анкеты заполнены
Коррекция объема выборки
Коррекция на неполное заполнение. В случае, если анкеты заполнены

Коррекция объема выборки
Объем выборки следует увеличивать в случае измерения параметра в
Коррекция объема выборки
Объем выборки следует увеличивать в случае измерения параметра в
 Активизация познавательного интереса на уроках обществознания
Активизация познавательного интереса на уроках обществознания Роль и функции семьи в развитии, воспитании, социализации личности
Роль и функции семьи в развитии, воспитании, социализации личности урок по теме: Духовная жизнь
урок по теме: Духовная жизнь презентация к уроку обществознания Правовые основы брака и семьи
презентация к уроку обществознания Правовые основы брака и семьи Образовательный курс для кандидатов в члены экспертного совета Всероссийского конкурса молодежных проектов.Тест
Образовательный курс для кандидатов в члены экспертного совета Всероссийского конкурса молодежных проектов.Тест Волонтерський рух
Волонтерський рух Программа Кандидата на пост Председателя Студенческого совета Финансового университета при Правительстве РФ Каплиной Виктории
Программа Кандидата на пост Председателя Студенческого совета Финансового университета при Правительстве РФ Каплиной Виктории Методология и методика проведения социологических исследований
Методология и методика проведения социологических исследований Волонтерство и участие россиян в деятельности НКО и гражданских инициатив
Волонтерство и участие россиян в деятельности НКО и гражданских инициатив Гражданское общество. Социальные движения второй половине XX - начале XXI века
Гражданское общество. Социальные движения второй половине XX - начале XXI века Влияние среды на развитие - формирование человека
Влияние среды на развитие - формирование человека Рекомендации по подготовке к ЕГЭ по обществознанию
Рекомендации по подготовке к ЕГЭ по обществознанию Волонтеры в помощь особым детям: отчет за период с 10 августа по 10 сентября 2017
Волонтеры в помощь особым детям: отчет за период с 10 августа по 10 сентября 2017 Моральный выбор. Моральные знания и практическое поведение личности
Моральный выбор. Моральные знания и практическое поведение личности Job hunting
Job hunting Студенческий совет Физического факультета СГУ
Студенческий совет Физического факультета СГУ Урок по обществознанию Декларация прав человека
Урок по обществознанию Декларация прав человека Организация предметной развивающей среды по Программе социального развития Л.В. Коломийченко (методические рекомендации)
Организация предметной развивающей среды по Программе социального развития Л.В. Коломийченко (методические рекомендации) Роль социального партнерства в решении социальных проблем региона
Роль социального партнерства в решении социальных проблем региона Социальная работа с детьми-сиротами и детьми, оставшимися без попечения родителей
Социальная работа с детьми-сиротами и детьми, оставшимися без попечения родителей Геймеры как субкультура
Геймеры как субкультура Развитие государственно-частного партнерства в сфере оказания социальных услуг
Развитие государственно-частного партнерства в сфере оказания социальных услуг Международный конкурс социальных проектов с применением цифровых технологий
Международный конкурс социальных проектов с применением цифровых технологий Разбор задания 26 ОГЭ по обществознанию
Разбор задания 26 ОГЭ по обществознанию Ресурсно-методический центр социальной защиты населения
Ресурсно-методический центр социальной защиты населения Развитие и систематизация практик социального добровольчества в Красноярском крае. Данные опроса
Развитие и систематизация практик социального добровольчества в Красноярском крае. Данные опроса Основной закон страны
Основной закон страны Отношения с родителями
Отношения с родителями