- A FPGA Accelerated AI for Connect-5

Содержание
- 2. Goal Build an AI for connect-5 (Gomoku) in FPGA hardware and leverage Vivado’s High Level Synthesis
- 3. Literature Review Began by looking at papers from ICFPT design competition 2013: Blokus 2012: Connect-6 Variant
- 4. Board Evaluation Board Evaluation Function sweeps a 5-square mask across board. Adds a number based on
- 5. Board Evaluation (Cont.) If the board is represented with a bit-board, the BEF is just bit-manipulation,
- 6. Search Tree Minimax Search Tree + Alpha-Beta Pruning
- 7. Search Tree (Cont.) To avoid dynamic memory allocation, we will specify how many moves per level
- 8. Hardware Acceleration Instead of checking the squares in a mask sequentially, a hardware module can do
- 9. Block Diagram
- 11. Скачать презентацию

Goal
Build an AI for connect-5 (Gomoku) in FPGA hardware and leverage
Goal
Build an AI for connect-5 (Gomoku) in FPGA hardware and leverage

Literature Review
Began by looking at papers from ICFPT design competition
2013: Blokus
2012:
Literature Review
Began by looking at papers from ICFPT design competition
2013: Blokus
2012:
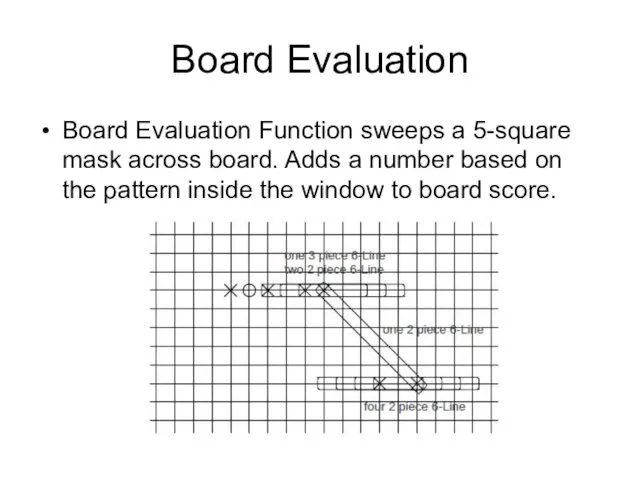
Board Evaluation
Board Evaluation Function sweeps a 5-square mask across board. Adds
Board Evaluation
Board Evaluation Function sweeps a 5-square mask across board. Adds

Board Evaluation (Cont.)
If the board is represented with a bit-board, the
Board Evaluation (Cont.)
If the board is represented with a bit-board, the
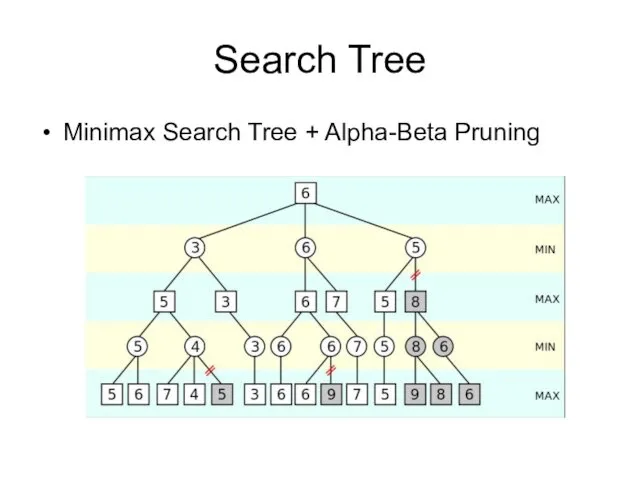
Search Tree
Minimax Search Tree + Alpha-Beta Pruning
Search Tree
Minimax Search Tree + Alpha-Beta Pruning

Search Tree (Cont.)
To avoid dynamic memory allocation, we will specify how
Search Tree (Cont.)
To avoid dynamic memory allocation, we will specify how

Hardware Acceleration
Instead of checking the squares in a mask sequentially, a
Hardware Acceleration
Instead of checking the squares in a mask sequentially, a
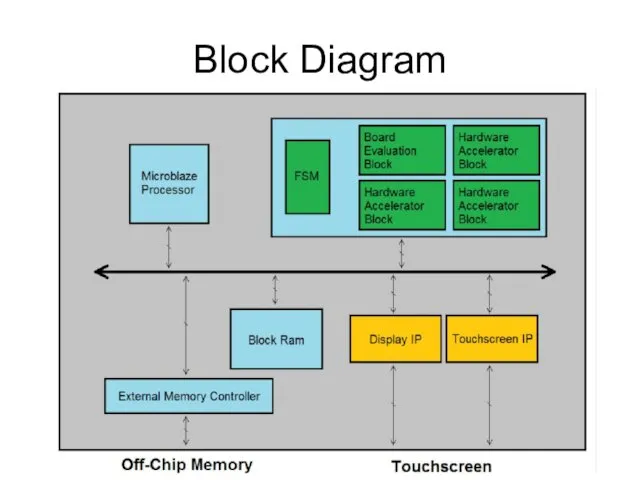
Block Diagram
Block Diagram
 Классный час к празднику 23 февраля Путешествие в разные страны за днём мужчин
Классный час к празднику 23 февраля Путешествие в разные страны за днём мужчин Органическая химия.Белки.Жиры.Углеводы.
Органическая химия.Белки.Жиры.Углеводы. Комплексно-тематическое планирование Книжкина неделя
Комплексно-тематическое планирование Книжкина неделя Оформление древнерусских книг
Оформление древнерусских книг Видільна система. 8 клас
Видільна система. 8 клас Основы обороны государства. Лекция 5
Основы обороны государства. Лекция 5 Презентация Стихи Агнии Барто
Презентация Стихи Агнии Барто Ленин Владимир Ильич - человек, “перевернувший Россию”
Ленин Владимир Ильич - человек, “перевернувший Россию” Выдающаяся личность Джаред Падалеки
Выдающаяся личность Джаред Падалеки презентация Лекарственные растения
презентация Лекарственные растения Половое воспитание
Половое воспитание Энергосбережение в строительстве. Япония
Энергосбережение в строительстве. Япония Расчет одиночных трубчатых колодцев (скважин)
Расчет одиночных трубчатых колодцев (скважин) Тұздар химиялық қосылыстар класы
Тұздар химиялық қосылыстар класы Смертная казнь. Отношение общества к данной мере наказания
Смертная казнь. Отношение общества к данной мере наказания Игра Подари картинки Боре
Игра Подари картинки Боре Программа ИГРАЛОЧКА. Игра как средство развития логического мышления
Программа ИГРАЛОЧКА. Игра как средство развития логического мышления Лес - наше богатство. Викторина
Лес - наше богатство. Викторина Геморрагический васкулит у детей
Геморрагический васкулит у детей Экосистемы. Понятие экосистемы
Экосистемы. Понятие экосистемы Виброакустический метод диагностирования технического состояния колесно-моторного блока
Виброакустический метод диагностирования технического состояния колесно-моторного блока Социальная политика ТРАНСАЭРО
Социальная политика ТРАНСАЭРО Зороастризм
Зороастризм Проект Театр своими руками
Проект Театр своими руками Алгоритмы решения задач по химии (I часть)
Алгоритмы решения задач по химии (I часть) Всероссийская акция Привет солдату
Всероссийская акция Привет солдату Триггеры и их классификация
Триггеры и их классификация Портфолио профессиональной деятельности воспитателя Николенко Татьяны Николаевны
Портфолио профессиональной деятельности воспитателя Николенко Татьяны Николаевны