- Classification of Body Postures and Movements Data Set

Содержание
- 2. Purpose of Project With the rise of life expectancy and aging of population, the development of
- 3. Dataset Wearable Computing: Classification of Body Postures and Movements (PUC-Rio) Data Set. (UCI Machine Learning Repository)
- 4. (gender, age, tall, weight, body massive, x1, y1, z1, x2, y2, z2, x3, y3, z3, x4,
- 5. Models of Project SVM with Linear Kernel SVM with Polynomial Kernel SVM with RBF Kernel Decision
- 6. SVM with Linear Kernel
- 7. SVM with Polynomial Kernel
- 8. SVM with RBF Kernel
- 9. Decision Tree
- 10. Random Forest
- 11. Gradient boosting is a way of boosting, just like Ada boosting. However, its idea is that
- 12. GBDT Review what we learned in Ada boosting. In Ada boosting, we change the weight of
- 13. GBDT There are some important parameters when we use GBDT. n_estimators: The number of boosting stages
- 14. GBDT We trained the model on different max depths, and we found the best max depth
- 15. GBDT To reduce the time complexity, we also trained the model on different size of train
- 16. Neural Network Input Layer: 17 features as 17 inputs; Output Layer: 5 outputs. (Then take the
- 17. Neural Network Our NN model has little improvement after 24 epoch in training. Some representative hidden
- 18. Ensemble of Models
- 20. Скачать презентацию

Purpose of Project
With the rise of life expectancy and aging of
Purpose of Project
With the rise of life expectancy and aging of

Dataset
Wearable Computing: Classification of Body Postures and Movements (PUC-Rio) Data Set.
Dataset
Wearable Computing: Classification of Body Postures and Movements (PUC-Rio) Data Set.

(gender, age, tall, weight, body massive, x1, y1, z1, x2, y2,
(gender, age, tall, weight, body massive, x1, y1, z1, x2, y2,

Models of Project
SVM with Linear Kernel
SVM with Polynomial Kernel
SVM with RBF
Models of Project
SVM with Linear Kernel
SVM with Polynomial Kernel
SVM with RBF
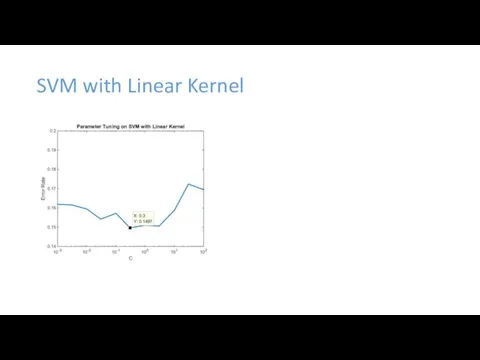
SVM with Linear Kernel
SVM with Linear Kernel
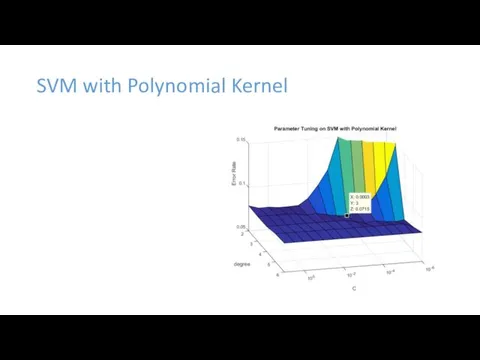
SVM with Polynomial Kernel
SVM with Polynomial Kernel
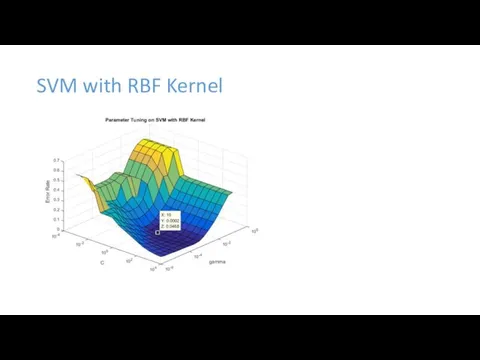
SVM with RBF Kernel
SVM with RBF Kernel
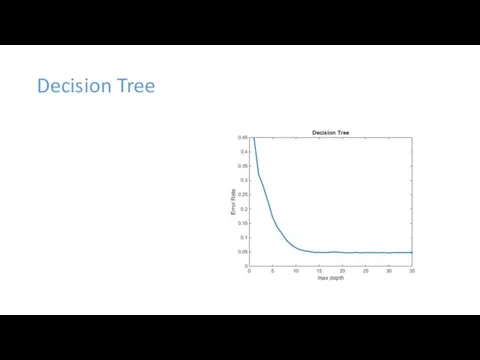
Decision Tree
Decision Tree
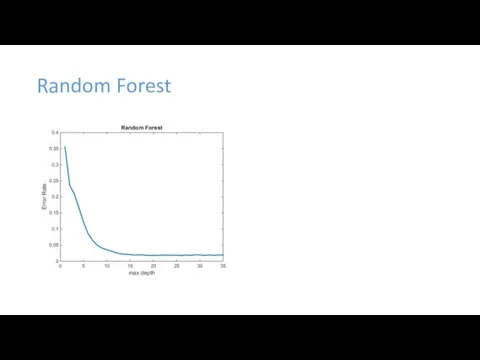
Random Forest
Random Forest
Gradient boosting is a way of boosting, just like Ada boosting.
However,
Gradient boosting is a way of boosting, just like Ada boosting.
However,
GBDT
Review what we learned in Ada boosting. In Ada boosting, we
GBDT
Review what we learned in Ada boosting. In Ada boosting, we

GBDT
There are some important parameters when we use GBDT.
n_estimators: The number of
GBDT
There are some important parameters when we use GBDT.
n_estimators: The number of
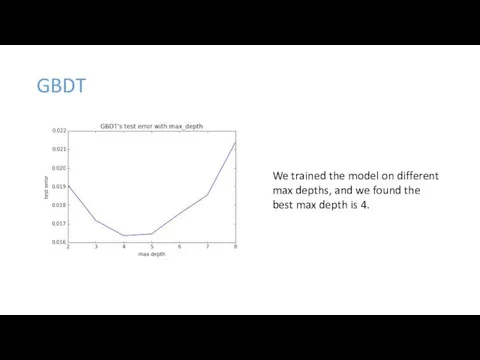
GBDT
We trained the model on different max depths, and we found
GBDT
We trained the model on different max depths, and we found
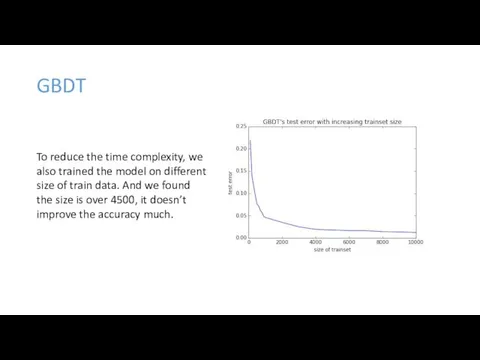
GBDT
To reduce the time complexity, we also trained the model on
GBDT
To reduce the time complexity, we also trained the model on

Neural Network
Input Layer: 17 features as 17 inputs;
Output Layer: 5 outputs.
Neural Network
Input Layer: 17 features as 17 inputs;
Output Layer: 5 outputs.
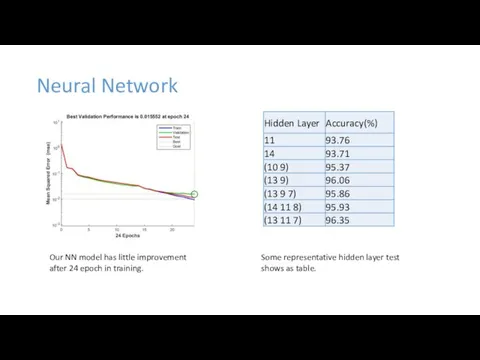
Neural Network
Our NN model has little improvement after 24 epoch in
Neural Network
Our NN model has little improvement after 24 epoch in
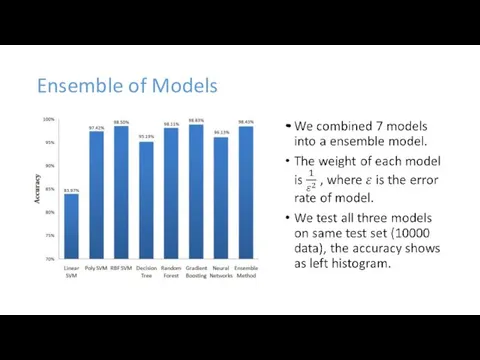
Ensemble of Models
Ensemble of Models
 Формы взаимодействия ДОУ с семьёй в условиях реализации ФГОС
Формы взаимодействия ДОУ с семьёй в условиях реализации ФГОС Глобальная структура дискурса
Глобальная структура дискурса Невроз навязчивых состояний
Невроз навязчивых состояний проект Знакомство с профессией парикмахера
проект Знакомство с профессией парикмахера Презентация праздников совместно с родителями Праздничный калейдоскоп
Презентация праздников совместно с родителями Праздничный калейдоскоп Хронические гепатиты. Определение, классификация, клиника
Хронические гепатиты. Определение, классификация, клиника Физминутка Прогулка по городу
Физминутка Прогулка по городу Шумилов Верх-Теча
Шумилов Верх-Теча Младший дошкольник в ДОУ
Младший дошкольник в ДОУ Конкурсные работы по методике В.Ф.Шаталова
Конкурсные работы по методике В.Ф.Шаталова Принципы и методы управления
Принципы и методы управления Водитель по доставке баллонов. Транспортируемая продукция. PG-WIM Corporate Training IN-TQ-TRN-001 Rev 0
Водитель по доставке баллонов. Транспортируемая продукция. PG-WIM Corporate Training IN-TQ-TRN-001 Rev 0 Фото девушек
Фото девушек Угадай - ка .
Угадай - ка . Francesco Petrarca IL CANZONIERE
Francesco Petrarca IL CANZONIERE Портфолио Натальи Рудяковой. Маркетолог
Портфолио Натальи Рудяковой. Маркетолог Графічні дисплеї
Графічні дисплеї NK-клетки
NK-клетки Необходимое оборудование. Профессия фотограф
Необходимое оборудование. Профессия фотограф Совершенствование перевозок пассажиров на линии метрополитена
Совершенствование перевозок пассажиров на линии метрополитена Шефская работа. Игры народов России.
Шефская работа. Игры народов России. პირველადი სტატისტიკური ანალიზი
პირველადი სტატისტიკური ანალიზი Презентация к открытому воспитательскому мероприятию: На планете Толерантность
Презентация к открытому воспитательскому мероприятию: На планете Толерантность Кризис трёх лет
Кризис трёх лет Устройство бетонной водосливной плотины гравитационного типа на скальном основании (Лекция 5)
Устройство бетонной водосливной плотины гравитационного типа на скальном основании (Лекция 5) Волшебство нового года. Предложение по зимнему декору
Волшебство нового года. Предложение по зимнему декору Портфолио учителя
Портфолио учителя Прочитанная книга о войне - мой подарок ко Дню Победы
Прочитанная книга о войне - мой подарок ко Дню Победы