- Искусственный интеллект в сетях связи. Машинное обучение

Содержание
- 2. Что такое машинное обучение? Машинное обучение – это обеспечение для какой-либо системы возможности решать задачи, обучаться
- 3. Что такое машинное обучение? Машинное обучение по сути позволяет анализировать некоторый набор данных и находить в
- 4. Классификация Классификация методов машинного обучения: Классификация/кластеризация: Два варианта ответа (да или нет). Больше двух вариантов ответа
- 5. Классификация Классификация методов машинного обучения: Обучение с учителем: Классификация. Регрессия. Обучение без учителя: Кластеризация. Обучение с
- 6. Обучение с учителем Обучение с учителем – это вид МО, при котором для всех обучающих данных
- 7. Обучение с учителем
- 8. Обучение с учителем Обучение с учителем может использоваться для построения как регрессионных (один численный выход), так
- 9. Обучение с учителем Для обучения с учителем нейронных сетей (в отличие от других систем) может использоваться
- 10. Обучение с учителем При использовании метода обратного распространения ошибки разница между ответом нейронной сети и правильным
- 11. Обучение с учителем
- 12. Обучение с учителем Как определяется насколько менять вес каждой связи? В основе – метод градиентного спуска.
- 13. Обучение с учителем
- 14. Обучение с учителем
- 15. Обучение без учителя Обучение без учителя – обучение на основе только входных данных, при котором обучаемая
- 16. Обучение без учителя Обучение без учителя может использоваться как для обучения нейронных сетей, так и для
- 17. Обучение без учителя Для нейронных сетей может использоваться один из «нечетких» методов к-средних, в которых на
- 18. Обучение c частично известными метками В таких ситуациях на помощь может прийти обучение с частично известными
- 19. Обучение c частично известными метками
- 20. Обучение c частично известными метками Обучение на частично размеченной выборке теоретически позволяет более точно классифицировать данные,
- 21. Обучение c частично известными метками Для успешного обучения с частично известными ответами данные должны удовлетворять хотя
- 22. Обучение c подкреплением Обучение с подкреплением – случай МО, когда ответы не известны, но на принятое
- 23. Проблемы МО В некоторых случаях МО не может дать приемлемого результата. Это может быть следствием одной
- 24. Корреляция и причинно-следственная связь При выборе данных для анализа следует выбирать те данные, которые теоретически имеют
- 25. Скрытые переменные Скрытые переменные в МО – это явление, когда обучающаяся система берет в расчет данные,
- 26. Сильно коррелированные входные данные Если во входных данных есть две или более сильно коррелированных между собой
- 27. Сильно коррелированные входные данные В выборе данных для МО чаще всего участвует человек, а значит может
- 28. Переобучение Переобучение (overfitting) – это явление, когда из-за слишком высокой «сложности» обучаемой системы и методов обучения
- 29. Переобучение На переобучение влияет: Число узлов скрытого слоя. Число шагов (эпох) обучения. Размер допустимой ошибки. Слишком
- 30. Переобучение
- 31. Дилемма «отклонение – дисперсия» Переобучение также тесно связано с дилеммой «отклонение – дисперсия» (Bias-Variance Tradeoff). Отклонение
- 32. Дилемма «отклонение – дисперсия»
- 34. Скачать презентацию

Что такое машинное обучение?
Машинное обучение – это обеспечение для какой-либо системы
Что такое машинное обучение?
Машинное обучение – это обеспечение для какой-либо системы

Что такое машинное обучение?
Машинное обучение по сути позволяет анализировать некоторый набор
Что такое машинное обучение?
Машинное обучение по сути позволяет анализировать некоторый набор

Классификация
Классификация методов машинного обучения:
Классификация/кластеризация:
Два варианта ответа (да или нет).
Больше двух вариантов
Классификация
Классификация методов машинного обучения:
Классификация/кластеризация:
Два варианта ответа (да или нет).
Больше двух вариантов

Классификация
Классификация методов машинного обучения:
Обучение с учителем:
Классификация.
Регрессия.
Обучение без учителя:
Кластеризация.
Обучение с частично известными
Классификация
Классификация методов машинного обучения:
Обучение с учителем:
Классификация.
Регрессия.
Обучение без учителя:
Кластеризация.
Обучение с частично известными

Обучение с учителем
Обучение с учителем – это вид МО, при котором
Обучение с учителем
Обучение с учителем – это вид МО, при котором
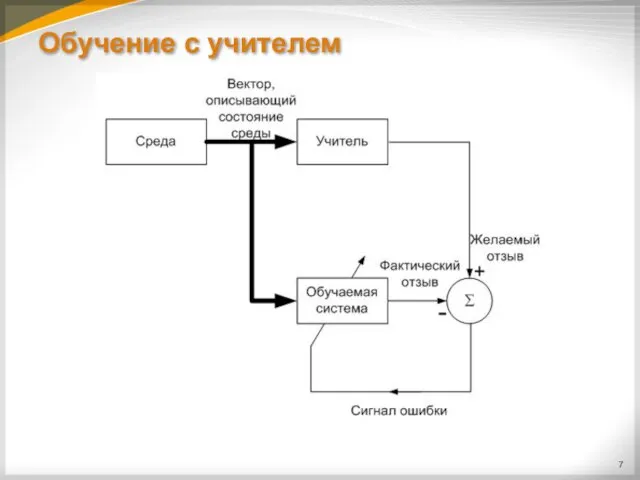
Обучение с учителем
Обучение с учителем

Обучение с учителем
Обучение с учителем может использоваться для построения как регрессионных
Обучение с учителем
Обучение с учителем может использоваться для построения как регрессионных

Обучение с учителем
Для обучения с учителем нейронных сетей (в отличие от
Обучение с учителем
Для обучения с учителем нейронных сетей (в отличие от
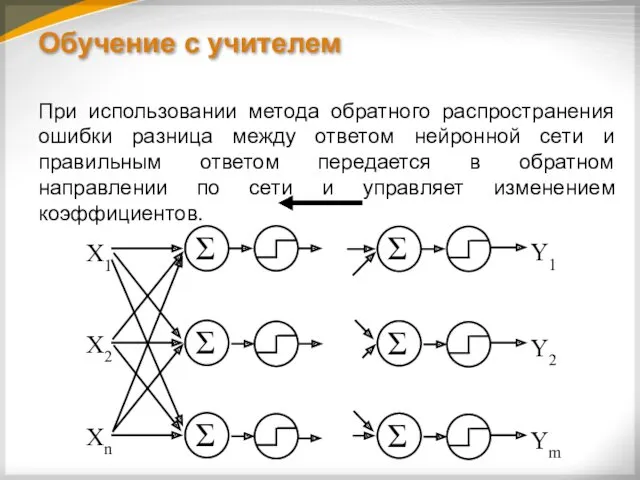
Обучение с учителем
При использовании метода обратного распространения ошибки разница между ответом
Обучение с учителем
При использовании метода обратного распространения ошибки разница между ответом

Обучение с учителем
Обучение с учителем

Обучение с учителем
Как определяется насколько менять вес каждой связи?
В основе –
Обучение с учителем
Как определяется насколько менять вес каждой связи?
В основе –

Обучение с учителем
Обучение с учителем

Обучение с учителем
Обучение с учителем
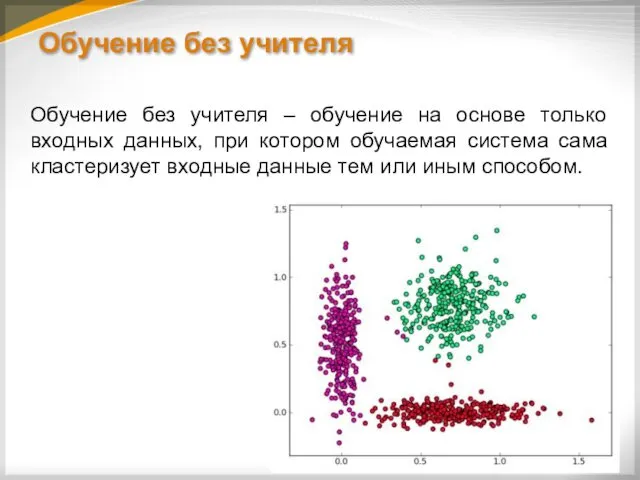
Обучение без учителя
Обучение без учителя – обучение на основе только входных
Обучение без учителя
Обучение без учителя – обучение на основе только входных
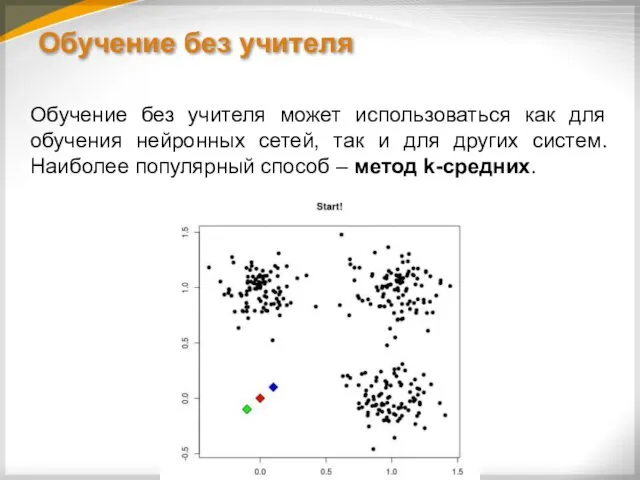
Обучение без учителя
Обучение без учителя может использоваться как для обучения нейронных
Обучение без учителя
Обучение без учителя может использоваться как для обучения нейронных

Обучение без учителя
Для нейронных сетей может использоваться один из «нечетких» методов
Обучение без учителя
Для нейронных сетей может использоваться один из «нечетких» методов
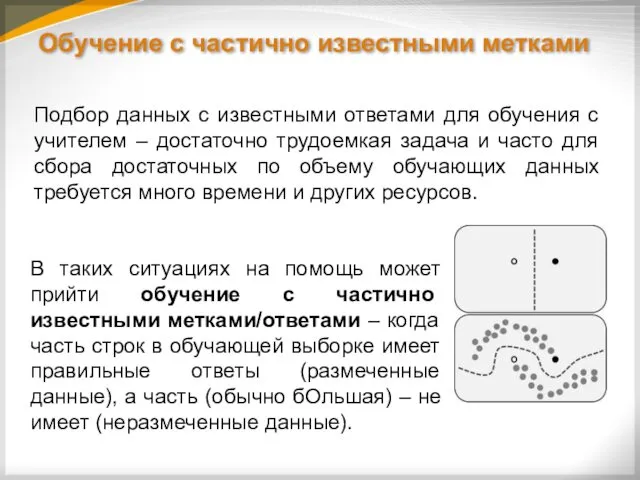
Обучение c частично известными метками
В таких ситуациях на помощь может прийти
Обучение c частично известными метками
В таких ситуациях на помощь может прийти
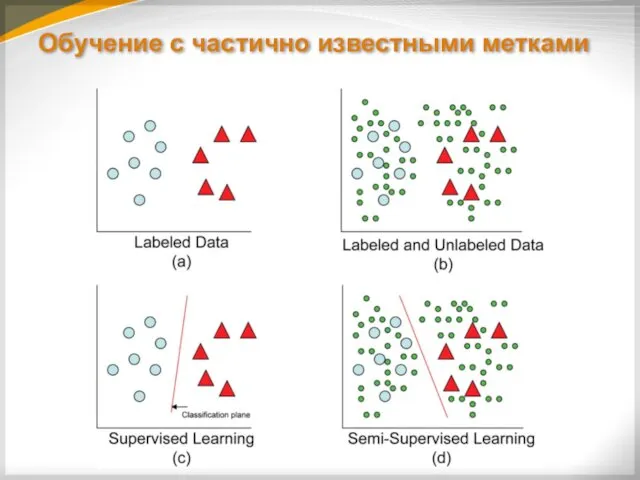
Обучение c частично известными метками
Обучение c частично известными метками

Обучение c частично известными метками
Обучение на частично размеченной выборке теоретически позволяет
Обучение c частично известными метками
Обучение на частично размеченной выборке теоретически позволяет

Обучение c частично известными метками
Для успешного обучения с частично известными ответами
Обучение c частично известными метками
Для успешного обучения с частично известными ответами
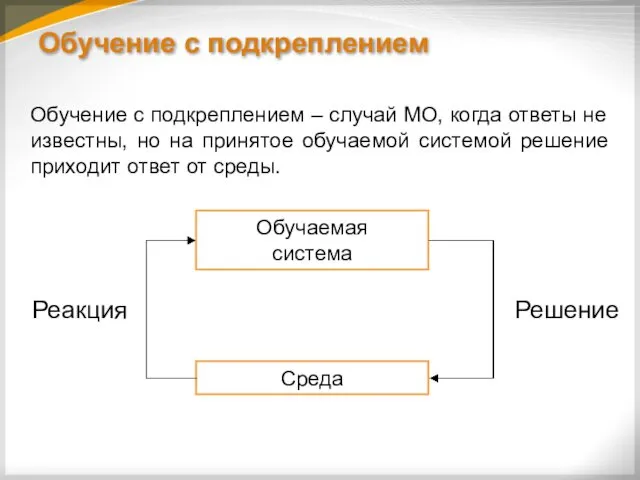
Обучение c подкреплением
Обучение с подкреплением – случай МО, когда ответы не
Обучение c подкреплением
Обучение с подкреплением – случай МО, когда ответы не

Проблемы МО
В некоторых случаях МО не может дать приемлемого результата. Это
Проблемы МО
В некоторых случаях МО не может дать приемлемого результата. Это
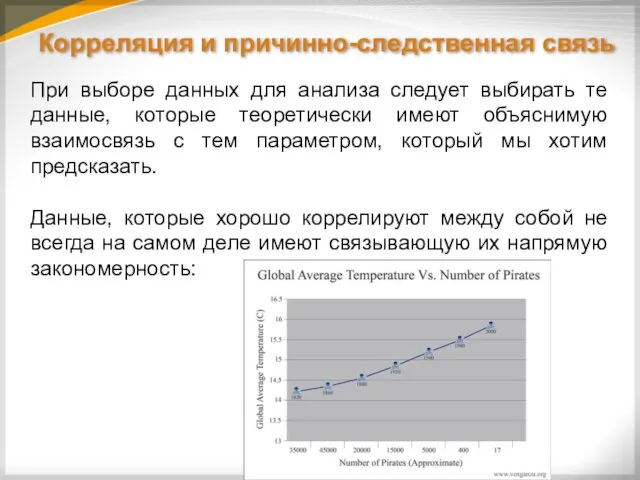
Корреляция и причинно-следственная связь
При выборе данных для анализа следует выбирать те
Корреляция и причинно-следственная связь
При выборе данных для анализа следует выбирать те

Скрытые переменные
Скрытые переменные в МО – это явление, когда обучающаяся система
Скрытые переменные
Скрытые переменные в МО – это явление, когда обучающаяся система

Сильно коррелированные входные данные
Если во входных данных есть две или более
Сильно коррелированные входные данные
Если во входных данных есть две или более

Сильно коррелированные входные данные
В выборе данных для МО чаще всего участвует
Сильно коррелированные входные данные
В выборе данных для МО чаще всего участвует
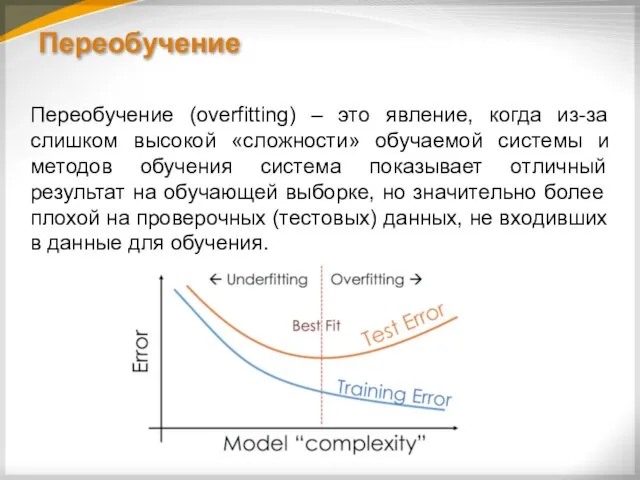
Переобучение
Переобучение (overfitting) – это явление, когда из-за слишком высокой «сложности» обучаемой
Переобучение
Переобучение (overfitting) – это явление, когда из-за слишком высокой «сложности» обучаемой

Переобучение
На переобучение влияет:
Число узлов скрытого слоя.
Число шагов (эпох) обучения.
Размер допустимой ошибки.
Слишком
Переобучение
На переобучение влияет:
Число узлов скрытого слоя.
Число шагов (эпох) обучения.
Размер допустимой ошибки.
Слишком

Переобучение
Переобучение

Дилемма «отклонение – дисперсия»
Переобучение также тесно связано с дилеммой «отклонение –
Дилемма «отклонение – дисперсия»
Переобучение также тесно связано с дилеммой «отклонение –
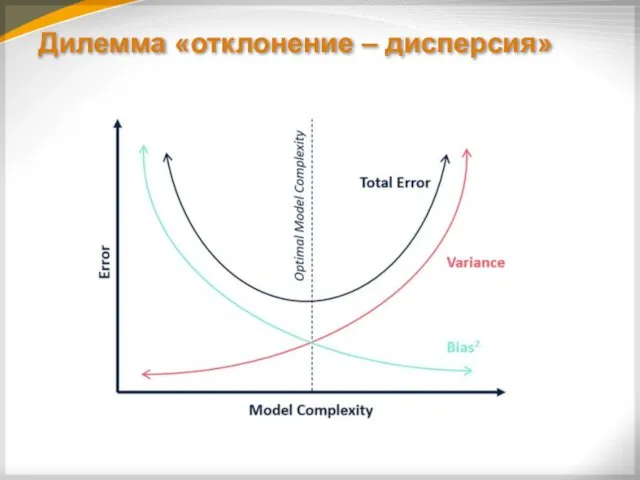
Дилемма «отклонение – дисперсия»
Дилемма «отклонение – дисперсия»
 Былины в славянском фольклоре
Былины в славянском фольклоре Климатообразующие факторы России
Климатообразующие факторы России Программа инвестиции Резидуальный доход
Программа инвестиции Резидуальный доход Вкусная Франшиза. Лапша
Вкусная Франшиза. Лапша Услуга Мобильный VPN
Услуга Мобильный VPN Definitions of motivation
Definitions of motivation Отчет о деятельности ПОС ИСИ за 2018 год
Отчет о деятельности ПОС ИСИ за 2018 год Работа с одарёнными детьми
Работа с одарёнными детьми Проектно-исследовательская работа по теме Мороженое-польза или вред?
Проектно-исследовательская работа по теме Мороженое-польза или вред? Производственная практика в компании ООО Спецмонтаж-Ц1
Производственная практика в компании ООО Спецмонтаж-Ц1 Презентация к лекционному занятию Введение в предмет фармакология
Презентация к лекционному занятию Введение в предмет фармакология фотоотчет Адаптация детей первый раз в детский сад
фотоотчет Адаптация детей первый раз в детский сад Братья наши меньшие. Произведения. Тест для младших школьников
Братья наши меньшие. Произведения. Тест для младших школьников Презентация Птицы нашего края
Презентация Птицы нашего края Циклон, тайфун. Швидкість вітру
Циклон, тайфун. Швидкість вітру Презентация IT чемпион
Презентация IT чемпион Предистория науки. Преднаука
Предистория науки. Преднаука Презентация Олимпиада - 2014г.
Презентация Олимпиада - 2014г. Медитация. Для чего это нужно
Медитация. Для чего это нужно Технология стыковой сварки сопротивлением. (Лекция 11)
Технология стыковой сварки сопротивлением. (Лекция 11) Организация процесса обучения. Содержание
Организация процесса обучения. Содержание Первичная профсоюзная организация Муниципального автономного дошкольного образовательного учреждения
Первичная профсоюзная организация Муниципального автономного дошкольного образовательного учреждения Роль религии в жизни общества
Роль религии в жизни общества Организация летнего отдыха детей в образовательных учреждениях г. Перми
Организация летнего отдыха детей в образовательных учреждениях г. Перми Разработки уроков
Разработки уроков Периметр прямоугольника. Урок математики во 2 классе
Периметр прямоугольника. Урок математики во 2 классе Эпидемии современного мира
Эпидемии современного мира Внешняя политика России при Иване Грозном
Внешняя политика России при Иване Грозном