- Операционные системы. Стратегии и критерии диспетчеризации процессов

Содержание
- 2. Основные понятия диспетчеризации процессора Цель – максимальная загрузка процессора. Достигается п помощью мультипрограммирования Цикл CPU /
- 3. Последовательность активных фаз (bursts) процессора и ввода-вывода
- 4. Гистограмма периодов активности процессора
- 5. Планировщик процессора (scheduler) Выбирает один из нескольких процессов, загруженных в память и готовых к выполнению, и
- 6. диспетчер Модуль диспетчера предоставляет процессор тому процессу, который был выбран планировщиком, то есть: Переключает контекст Переключает
- 7. Критерии диспетчеризации Использование процессора – поддержание его в режиме занятости, насколько это возможно Пропускная способность (throughput)
- 8. Стратегия диспетчеризации «обслуживание в порядке поступления» First-Come-First-Served (FCFS) Процесс Период активности P1 24 P2 3 P3
- 9. Стратегия FCFS (продолжение) Пусть порядок процессов таков: P2 , P3 , P1 . Диаграмма Ганта для
- 10. Стратегия Shortest-Job-First (SJF) обслуживание самого короткого задания первым С каждым процессом связывается длина его очередного периода
- 11. Пример: Процесс Время появления Время активности P1 0.0 7 P2 2.0 4 P3 4.0 1 P4
- 12. Определение длины следующего периода активности Является лишь оценкой длины. Может быть выполнено с использованием длин предыдущих
- 13. Предсказание длины следующего периода активности
- 14. Примеры экспоненциального усреднения α =0 τn+1 = τn Недавняя история не учитывается. α =1 τn+1 =
- 15. Диспетчеризация по приоритетам С каждым процессом связывается его приоритет (целое число) Процессор выделяется процессу с наивысшим
- 16. Стратегия Round Robin (RR)–круговая система Каждый процесс получает небольшой квант процессорного времени, обычно – 10-100 миллисекунд.
- 17. Пример RR (квант времени = 20) Пример RR с квантом времени = 20 Процес Время активности
- 18. Квант времени ЦП и время переключения контекста
- 19. Изменение времени оборота, в зависимости от кванта времени
- 20. Многоуровневая очередь Очередь готовых к выполнению процессов делится на две очереди: основная (интерактивные процессы) фоновая (пакет)
- 21. Диспетчеризация по принципу многоуровневой очереди
- 22. Многоуровневая аналитическая очередь (multi-level feedback queue) Процесс может перемещаться из одной очереди в другую; увеличение его
- 23. Пример многоуровневой аналитической очереди Три очереди: Q0 – квант времени - 8 миллисекунд Q1 – квант
- 24. Многоуровневые аналитические очереди
- 25. Планирование загрузки многопроцессорных систем Планирование загрузки процессора более сложно, когда доступны несколько процессоров Однородные процессоры в
- 26. Планирование загрузки процессоров в реальном времени Системы реального времени класса 1 (hard real-time systems) – требуют
- 27. Латентность диспетчера (dispatch latency)
- 28. Планирование в Solaris 2
- 29. Приоритеты в Windows
- 30. Операционные системы Методы синхронизации процессов.
- 31. История Совместный доступ к общим данным может привести к нарушению их целостности (inconsistency). Поддержание целостности общих
- 32. Ограниченный буфер Общие данные #define BUFFER_SIZE 10 typedef struct { . . . } item; item
- 33. Ограниченный буфер Операторы counter++;counter--; должны быть выполнены атомарно (atomically). Атомарная операция – такая, которая должна быть
- 34. Ограниченный буфер Если и производитель, и потребитель пытаются обратиться к буферу совместно (одновременно), то указанные ассемблерные
- 35. Конкуренция за общие данные (race condition) Race condition: Ситуация, когда взаимодействующие процессы могут обращаться к общим
- 36. Проблема критической секции n процессов – каждый может обратиться к общим данным Каждый процесс имеет участок
- 37. Решение проблемы критической секции 1. Взаимное исключение. Если процесс Pi исполняет свою критическую секцию, то никакой
- 38. Первоначальные попытки решения проблемы Есть только два процесса, P0 и P1 Общая структура процесса Pi: do
- 39. Алгоритм 1 Общие переменные: int turn; первоначально turn = 0 turn == i ⇒ процесс Pi
- 40. Алгоритм 2 Общие переменные boolean flag[2]; первоначально flag [0] = flag [1] = false. flag [i]
- 41. Алгоритм 3 Объединяет общие переменные алгоритмов 1 и 2. Процесс Pi : do { flag [i]:=
- 42. Алгоритм булочной (bakery algorithm) Обозначения: (a,b) max (a0,…, an-1)- число k, такое, что k ≥ ai
- 43. Алгоритм булочной do { choosing[i] = true; number[i] = max(number[0], number[1], …, number [n – 1])+1;
- 44. Аппаратная поддержка синхронизации Атомарная операция проверки и модификации значения переменной . boolean TestAndSet(boolean &target) { boolean
- 45. Взаимное исключение с помощью TestAndSet Общие данные: boolean lock = false; Процесс Pi do { while
- 46. Аппаратное решение для синхронизации Атомарная перестановка значений двух переменных. void Swap (boolean * a, boolean *
- 47. Взаимное исключение с помощью Swap Общие данные (инициализируемые false): boolean lock; boolean waiting[n]; Процесс Pi do
- 48. Общие семафоры – counting semaphores (по Э. Дейкстре) Семафоры-средство синхронизации, не требующее активного ожидания. (Общий) семафор
- 49. Критическая секция для N процессов Общие данные: semaphore mutex; //initially mutex = 1 Процесс Pi: do
- 50. Реализация семафора Определяем семафор как структуру: typedef struct { int value; struct process *L; } semaphore;
- 51. Реализация Определим семафорные операции следующим образом: wait(S): S.value--; if (S.value добавить текущий процесс к S.L; block;
- 52. Семафоры как общее средство синхронизации Исполнить действие B в процессе Pj только после того, как действие
- 53. Два типа семафоров Общий семафор (Counting semaphore) – целое значение, теоретически неограниченное Двоичный семафор (Binary semaphore)
- 54. Вариант операции wait(S) для системных процессов (“Эльбрус”) Для системного процесса лишние прерывания нежелательны и может оказаться
- 55. Реализация общего семафора S с помощью двоичных семафоров Структуры данных: binary-semaphore S1, S2; int C: Инициализация:
- 56. Реализация операций над семафором S Операция wait: wait(S1); C--; if (C signal(S1); wait(S2); } signal(S1); Операция
- 57. Классические задачи синхронизации Задача “ограниченный буфер” (Bounded-Buffer Problem) Задача “читатели-писатели” (Readers and Writers Problem) Задача “обедающие
- 58. Задача “ограниченный буфер” Общие данные: semaphore full, empty, mutex; Начальные значения: full = 0, empty =
- 59. Процесс-производитель ограниченного буфера do { … сгенерировать элемент в nextp … wait(empty); wait(mutex); … добавить nextp
- 60. Процесс-потребитель ограниченного буфера do { wait(full) wait(mutex); … взять (и удалить) элемент из буфера в nextc
- 61. Задача “читатели-писатели” Общие данные: semaphore mutex, wrt; Начальные значения: mutex = 1, wrt = 1, readcount
- 62. Задача “обедающие философы” Общие данные semaphore chopstick[5]; Первоначально все значения равны 1 Суть задачи обедающие философы
- 63. Задача “обедающие философы” Философ i: do { wait(chopstick[i]); wait(chopstick[(i+1) % 5]); … dine … signal(chopstick[i]); signal(chopstick[(i+1)
- 64. Критические области (critical regions) Высокоуровневая конструкция для синхронизации Общая переменная v типа T, определяемая следующим образом:
- 65. Пример: ограниченный буфер Общие данные: struct buffer { int pool[n]; int count, in, out; }
- 66. Реализация оператора region x when B do S Свяжем с общей переменной x следующие переменные: semaphore
- 67. Реализация Число процессов, ждущих на first-delay и second-delay, хранится, соответственно, в first-count и second-count. Алгоритм предполагает
- 68. Мониторы (C. A. R. Hoare) Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать доступ к абстрактному типу
- 69. Мониторы: условные переменные Для реализации ожидания процесса внутри монитора, вводятся условные переменные: condition x, y; Условные
- 70. Схематическое представление монитора
- 71. Монитор с условными переменными
- 72. Пример: обедающие философы monitor dp { enum {thinking, hungry, eating} state[5]; condition self[5]; void pickup(int i)
- 73. Обедающие философы: реализация операций pickup и putdown void pickup(int i) { state[i] = hungry; test[i]; if
- 74. Обедающие философы: реализация операции test void test(int i) { if ( (state[(i + 4) % 5]
- 75. Реализация мониторов с помощью семафоров Переменные semaphore mutex; // (initially = 1) semaphore next; // (initially
- 76. Реализация мониторов Для каждой условной переменной x: semaphore x-sem; // (initially = 0) int x-count =
- 77. Реализация мониторов Реализация операции x.signal: if (x-count > 0) { next-count++; signal(x-sem); wait(next); next-count--; }
- 78. Реализация мониторов Конструкция conditional-wait: x.wait(c); c – целое выражение, вычисляемое при исполнении операции wait. значение c
- 79. Синхронизация в Solaris 2 Реализованы разнообразные виды блокировок для поддержки многозадачности, многопоточности (включая потоки реального времени)
- 81. Скачать презентацию

Основные понятия диспетчеризации процессора
Цель – максимальная загрузка процессора. Достигается п помощью
Основные понятия диспетчеризации процессора
Цель – максимальная загрузка процессора. Достигается п помощью
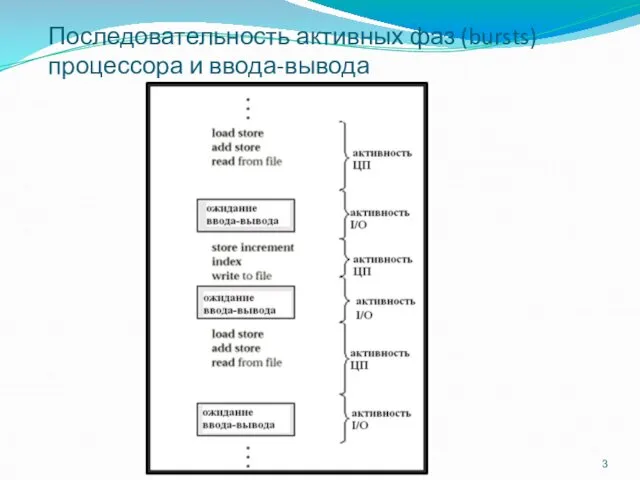
Последовательность активных фаз (bursts) процессора и ввода-вывода
Последовательность активных фаз (bursts) процессора и ввода-вывода
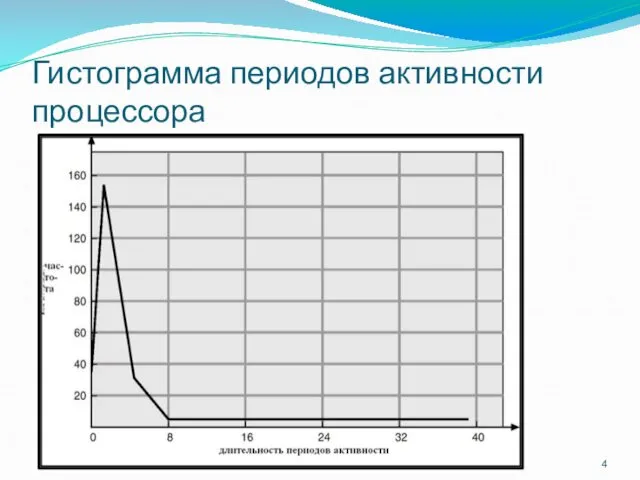
Гистограмма периодов активности процессора
Гистограмма периодов активности процессора

Планировщик процессора (scheduler)
Выбирает один из нескольких процессов, загруженных в память и
Планировщик процессора (scheduler)
Выбирает один из нескольких процессов, загруженных в память и

диспетчер
Модуль диспетчера предоставляет процессор тому процессу, который был выбран планировщиком, то
диспетчер
Модуль диспетчера предоставляет процессор тому процессу, который был выбран планировщиком, то

Критерии диспетчеризации
Использование процессора – поддержание его в режиме занятости, насколько это
Критерии диспетчеризации
Использование процессора – поддержание его в режиме занятости, насколько это

Стратегия диспетчеризации «обслуживание в порядке поступления» First-Come-First-Served (FCFS)
Процесс Период активности
P1 24
P2
Стратегия диспетчеризации «обслуживание в порядке поступления» First-Come-First-Served (FCFS)
Процесс Период активности
P1 24
P2

Стратегия FCFS (продолжение)
Пусть порядок процессов таков:
P2 , P3 , P1
Стратегия FCFS (продолжение)
Пусть порядок процессов таков:
P2 , P3 , P1

Стратегия Shortest-Job-First (SJF) обслуживание самого короткого задания первым
С каждым процессом связывается
Стратегия Shortest-Job-First (SJF) обслуживание самого короткого задания первым
С каждым процессом связывается

Пример:
Процесс Время появления Время активности
P1 0.0 7
P2 2.0 4
P3 4.0 1
P4 5.0 4
SJF (без опережения) Среднее
Пример:
Процесс Время появления Время активности
P1 0.0 7
P2 2.0 4
P3 4.0 1
P4 5.0 4
SJF (без опережения) Среднее

Определение длины следующего периода активности
Является лишь оценкой длины.
Может быть выполнено с
Определение длины следующего периода активности
Является лишь оценкой длины.
Может быть выполнено с
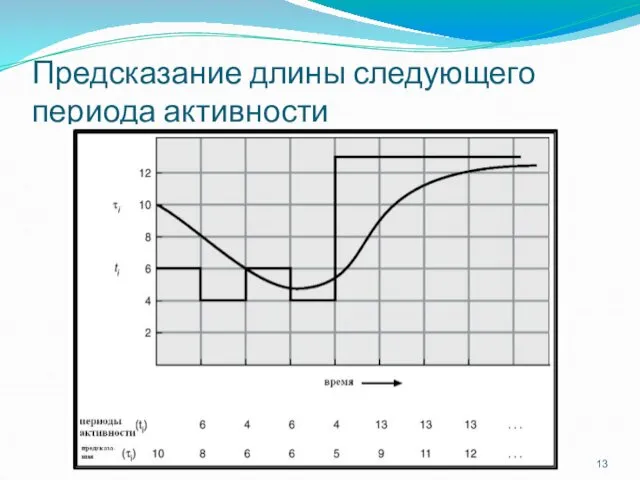
Предсказание длины следующего периода активности
Предсказание длины следующего периода активности

Примеры экспоненциального усреднения
α =0
τn+1 = τn
Недавняя история не учитывается.
α =1
τn+1
Примеры экспоненциального усреднения
α =0
τn+1 = τn
Недавняя история не учитывается.
α =1
τn+1

Диспетчеризация по приоритетам
С каждым процессом связывается его приоритет (целое число)
Процессор выделяется
Диспетчеризация по приоритетам
С каждым процессом связывается его приоритет (целое число)
Процессор выделяется

Стратегия Round Robin (RR)–круговая система
Каждый процесс получает небольшой квант процессорного времени,
Стратегия Round Robin (RR)–круговая система
Каждый процесс получает небольшой квант процессорного времени,

Пример RR (квант времени = 20)
Пример RR с квантом времени =
Пример RR (квант времени = 20)
Пример RR с квантом времени =
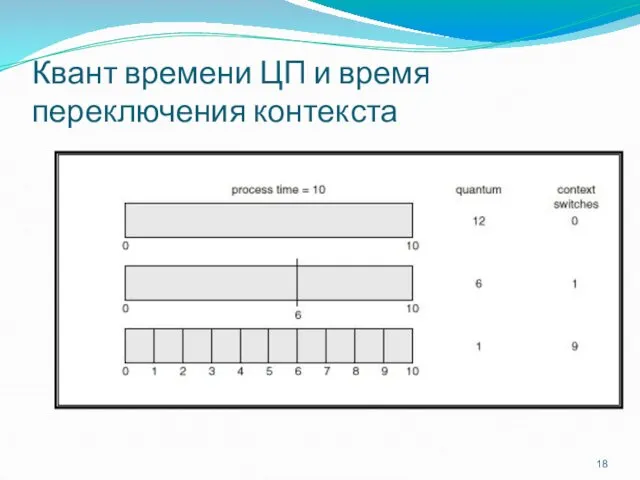
Квант времени ЦП и время переключения контекста
Квант времени ЦП и время переключения контекста
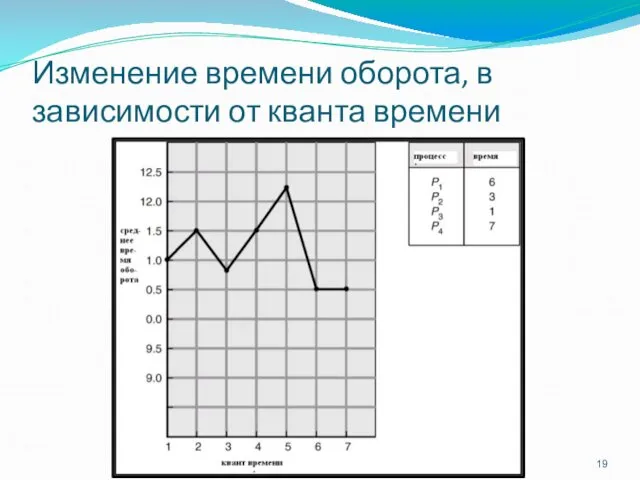
Изменение времени оборота, в зависимости от кванта времени
Изменение времени оборота, в зависимости от кванта времени

Многоуровневая очередь
Очередь готовых к выполнению процессов делится на две очереди:
основная
Многоуровневая очередь
Очередь готовых к выполнению процессов делится на две очереди:
основная
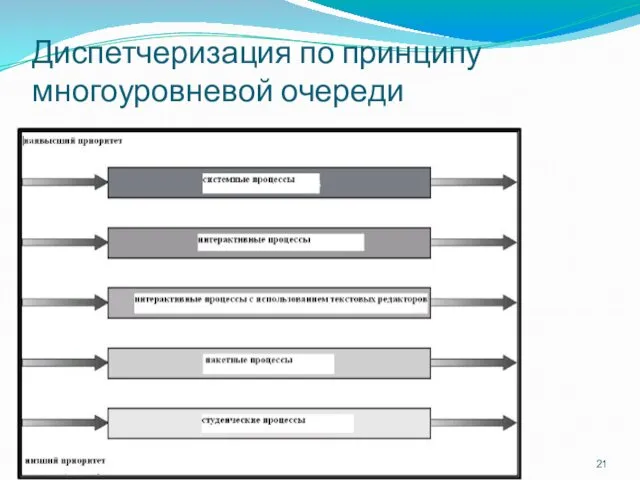
Диспетчеризация по принципу многоуровневой очереди
Диспетчеризация по принципу многоуровневой очереди

Многоуровневая аналитическая очередь (multi-level feedback queue)
Процесс может перемещаться из одной очереди
Многоуровневая аналитическая очередь (multi-level feedback queue)
Процесс может перемещаться из одной очереди

Пример многоуровневой аналитической очереди
Три очереди:
Q0 – квант времени - 8
Пример многоуровневой аналитической очереди
Три очереди:
Q0 – квант времени - 8
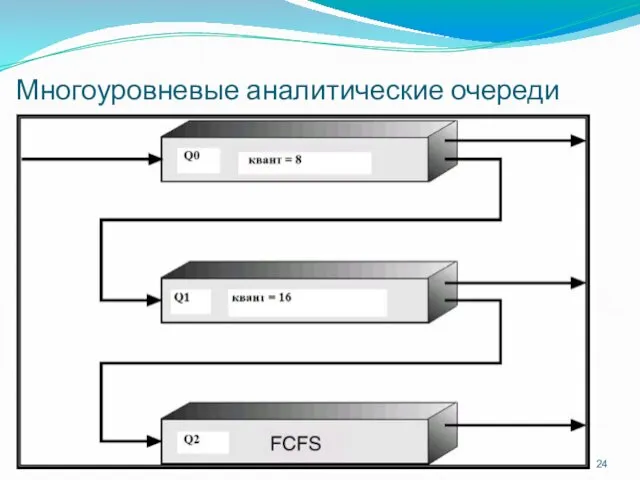
Многоуровневые аналитические очереди
Многоуровневые аналитические очереди

Планирование загрузки многопроцессорных систем
Планирование загрузки процессора более сложно, когда доступны несколько
Планирование загрузки многопроцессорных систем
Планирование загрузки процессора более сложно, когда доступны несколько

Планирование загрузки процессоров в реальном времени
Системы реального времени класса 1 (hard
Планирование загрузки процессоров в реальном времени
Системы реального времени класса 1 (hard
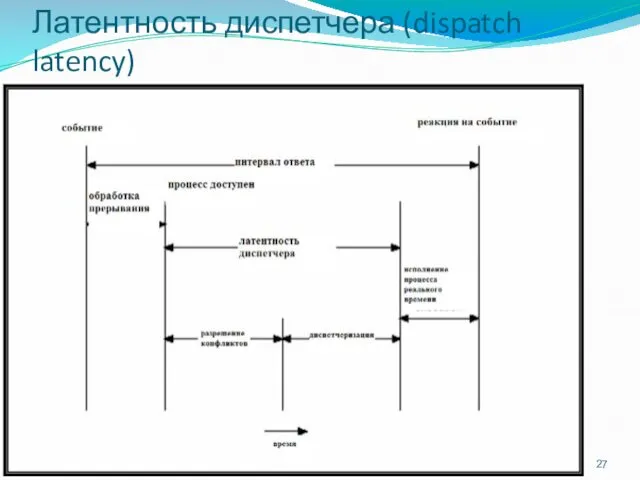
Латентность диспетчера (dispatch latency)
Латентность диспетчера (dispatch latency)
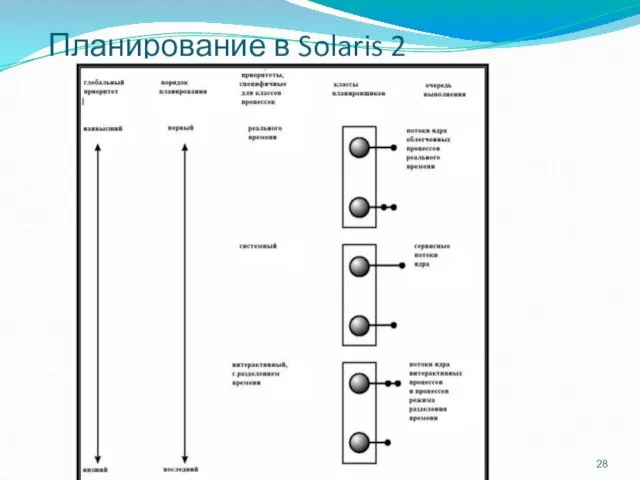
Планирование в Solaris 2
Планирование в Solaris 2
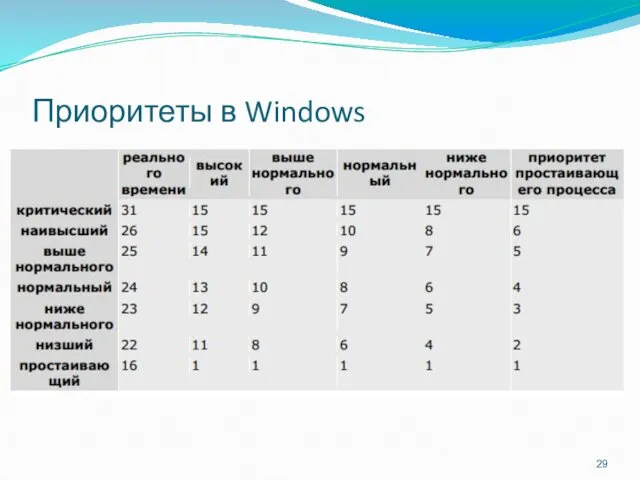
Приоритеты в Windows
Приоритеты в Windows

Операционные системы
Методы синхронизации процессов.
Операционные системы
Методы синхронизации процессов.

История
Совместный доступ к общим данным может привести к нарушению их
История
Совместный доступ к общим данным может привести к нарушению их

Ограниченный буфер
Общие данные
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item
Ограниченный буфер
Общие данные
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item

Ограниченный буфер
Операторы counter++;counter--;
должны быть выполнены атомарно (atomically).
Атомарная операция – такая, которая
Ограниченный буфер
Операторы counter++;counter--;
должны быть выполнены атомарно (atomically).
Атомарная операция – такая, которая

Ограниченный буфер
Если и производитель, и потребитель пытаются обратиться к буферу совместно
Ограниченный буфер
Если и производитель, и потребитель пытаются обратиться к буферу совместно

Конкуренция за общие данные
(race condition)
Race condition: Ситуация, когда взаимодействующие процессы
Конкуренция за общие данные
(race condition)
Race condition: Ситуация, когда взаимодействующие процессы

Проблема критической секции
n процессов – каждый может обратиться к общим данным
Каждый
Проблема критической секции
n процессов – каждый может обратиться к общим данным
Каждый

Решение проблемы критической секции
1. Взаимное исключение. Если процесс Pi исполняет свою
Решение проблемы критической секции
1. Взаимное исключение. Если процесс Pi исполняет свою

Первоначальные попытки решения проблемы
Есть только два процесса, P0 и P1
Общая структура
Первоначальные попытки решения проблемы
Есть только два процесса, P0 и P1
Общая структура

Алгоритм 1
Общие переменные:
int turn;
первоначально turn = 0
turn == i ⇒
Алгоритм 1
Общие переменные:
int turn;
первоначально turn = 0
turn == i ⇒
![Алгоритм 2 Общие переменные boolean flag[2]; первоначально flag [0] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/36912/slide-39.jpg)
Алгоритм 2
Общие переменные
boolean flag[2];
первоначально flag [0] = flag [1] = false.
flag
Алгоритм 2
Общие переменные
boolean flag[2];
первоначально flag [0] = flag [1] = false.
flag

Алгоритм 3
Объединяет общие переменные алгоритмов 1 и 2.
Процесс Pi :
do {
flag
Алгоритм 3
Объединяет общие переменные алгоритмов 1 и 2.
Процесс Pi :
do {
flag

Алгоритм булочной (bakery algorithm)
Обозначения: < ≡ лексикографический порядок
(a,b) < (c,d)
Алгоритм булочной (bakery algorithm)
Обозначения: < ≡ лексикографический порядок
(a,b) < (c,d)
![Алгоритм булочной do { choosing[i] = true; number[i] = max(number[0],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/36912/slide-42.jpg)
Алгоритм булочной
do {
choosing[i] = true;
number[i] = max(number[0], number[1], …, number
Алгоритм булочной
do {
choosing[i] = true;
number[i] = max(number[0], number[1], …, number

Аппаратная поддержка синхронизации
Атомарная операция проверки и модификации значения переменной
.
boolean TestAndSet(boolean &target)
Аппаратная поддержка синхронизации
Атомарная операция проверки и модификации значения переменной
.
boolean TestAndSet(boolean &target)

Взаимное исключение с помощью TestAndSet
Общие данные:
boolean lock = false;
Процесс Pi
do
Взаимное исключение с помощью TestAndSet
Общие данные:
boolean lock = false;
Процесс Pi
do

Аппаратное решение для синхронизации
Атомарная перестановка значений двух переменных.
void Swap (boolean *
Аппаратное решение для синхронизации
Атомарная перестановка значений двух переменных.
void Swap (boolean *

Взаимное исключение с помощью Swap
Общие данные (инициализируемые false):
boolean lock;
boolean waiting[n];
Процесс
Взаимное исключение с помощью Swap
Общие данные (инициализируемые false):
boolean lock;
boolean waiting[n];
Процесс

Общие семафоры – counting semaphores (по Э. Дейкстре)
Семафоры-средство синхронизации, не требующее
Общие семафоры – counting semaphores (по Э. Дейкстре)
Семафоры-средство синхронизации, не требующее

Критическая секция для N процессов
Общие данные:
semaphore mutex; //initially mutex =
Критическая секция для N процессов
Общие данные:
semaphore mutex; //initially mutex =

Реализация семафора
Определяем семафор как структуру:
typedef struct {
int value;
struct process
Реализация семафора
Определяем семафор как структуру:
typedef struct {
int value;
struct process

Реализация
Определим семафорные операции следующим образом:
wait(S):
S.value--;
if (S.value < 0) {
добавить
Реализация
Определим семафорные операции следующим образом:
wait(S):
S.value--;
if (S.value < 0) {
добавить

Семафоры как общее средство синхронизации
Исполнить действие B в процессе Pj только
Семафоры как общее средство синхронизации
Исполнить действие B в процессе Pj только

Два типа семафоров
Общий семафор (Counting semaphore) – целое значение, теоретически неограниченное
Два типа семафоров
Общий семафор (Counting semaphore) – целое значение, теоретически неограниченное

Вариант операции wait(S) для системных процессов (“Эльбрус”)
Для системного процесса лишние прерывания
Вариант операции wait(S) для системных процессов (“Эльбрус”)
Для системного процесса лишние прерывания

Реализация общего семафора S с помощью двоичных семафоров
Структуры данных:
binary-semaphore S1, S2;
int
Реализация общего семафора S с помощью двоичных семафоров
Структуры данных:
binary-semaphore S1, S2;
int

Реализация операций над семафором S
Операция wait:
wait(S1);
C--;
if (C < 0) {
signal(S1);
wait(S2);
}
signal(S1);
Операция
Реализация операций над семафором S
Операция wait:
wait(S1);
C--;
if (C < 0) {
signal(S1);
wait(S2);
}
signal(S1);
Операция

Классические задачи синхронизации
Задача “ограниченный буфер” (Bounded-Buffer Problem)
Задача “читатели-писатели” (Readers and Writers
Классические задачи синхронизации
Задача “ограниченный буфер” (Bounded-Buffer Problem)
Задача “читатели-писатели” (Readers and Writers

Задача “ограниченный буфер”
Общие данные:
semaphore full, empty, mutex;
Начальные значения:
full = 0, empty
Задача “ограниченный буфер”
Общие данные: semaphore full, empty, mutex; Начальные значения: full = 0, empty

Процесс-производитель ограниченного буфера
do {
…
сгенерировать элемент в nextp
…
wait(empty);
wait(mutex);
…
добавить nextp
Процесс-производитель ограниченного буфера
do {
…
сгенерировать элемент в nextp
…
wait(empty);
wait(mutex);
…
добавить nextp

Процесс-потребитель ограниченного буфера
do {
wait(full)
wait(mutex);
…
взять (и удалить) элемент из буфера
Процесс-потребитель ограниченного буфера
do {
wait(full)
wait(mutex);
…
взять (и удалить) элемент из буфера

Задача “читатели-писатели”
Общие данные:
semaphore mutex, wrt;
Начальные значения:
mutex = 1, wrt = 1,
Задача “читатели-писатели”
Общие данные: semaphore mutex, wrt; Начальные значения: mutex = 1, wrt = 1,
![Задача “обедающие философы” Общие данные semaphore chopstick[5]; Первоначально все значения](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/36912/slide-61.jpg)
Задача “обедающие философы”
Общие данные
semaphore chopstick[5];
Первоначально все значения равны 1
Суть задачи
Задача “обедающие философы”
Общие данные
semaphore chopstick[5];
Первоначально все значения равны 1
Суть задачи
![Задача “обедающие философы” Философ i: do { wait(chopstick[i]); wait(chopstick[(i+1) %](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/36912/slide-62.jpg)
Задача “обедающие философы”
Философ i:
do {
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
…
dine
…
signal(chopstick[i]);
signal(chopstick[(i+1) % 5]);
Задача “обедающие философы”
Философ i:
do {
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
…
dine
…
signal(chopstick[i]);
signal(chopstick[(i+1) % 5]);

Критические области
(critical regions)
Высокоуровневая конструкция для синхронизации
Общая переменная v типа T,
Критические области
(critical regions)
Высокоуровневая конструкция для синхронизации
Общая переменная v типа T,
![Пример: ограниченный буфер Общие данные: struct buffer { int pool[n]; int count, in, out; }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/36912/slide-64.jpg)
Пример: ограниченный буфер
Общие данные:
struct buffer {
int pool[n];
int count, in, out;
}
Пример: ограниченный буфер
Общие данные:
struct buffer {
int pool[n];
int count, in, out;
}

Реализация оператора region x when B do S
Свяжем с общей переменной
Реализация оператора region x when B do S
Свяжем с общей переменной

Реализация
Число процессов, ждущих на first-delay и second-delay, хранится, соответственно, в first-count
Реализация
Число процессов, ждущих на first-delay и second-delay, хранится, соответственно, в first-count

Мониторы (C. A. R. Hoare)
Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать
Мониторы (C. A. R. Hoare)
Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать

Мониторы: условные переменные
Для реализации ожидания процесса внутри монитора, вводятся условные переменные:
condition
Мониторы: условные переменные
Для реализации ожидания процесса внутри монитора, вводятся условные переменные:
condition
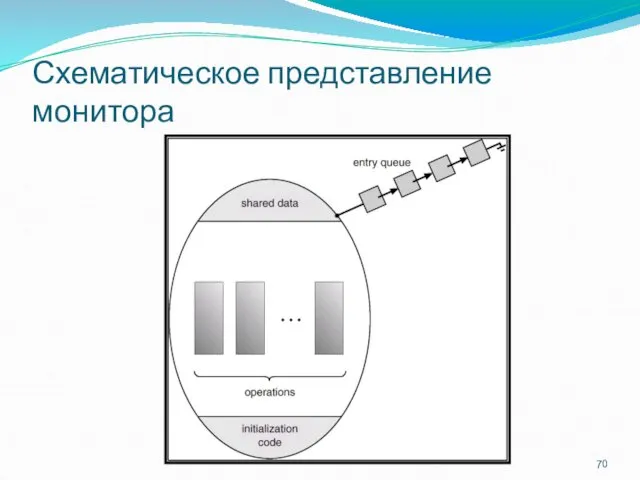
Схематическое представление монитора
Схематическое представление монитора
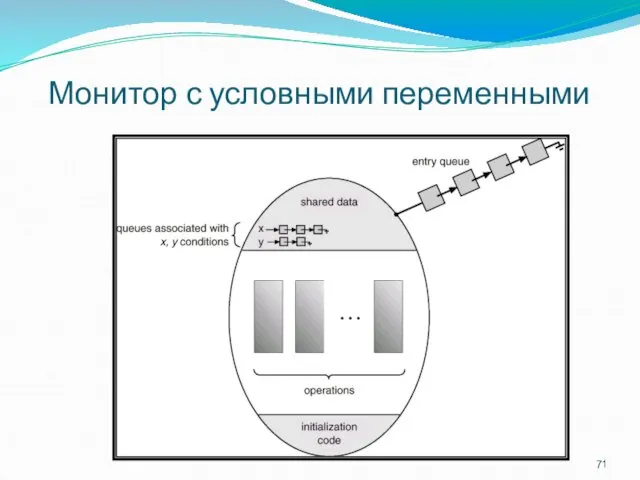
Монитор с условными переменными
Монитор с условными переменными

Пример: обедающие философы
monitor dp
{
enum {thinking, hungry, eating} state[5];
condition self[5];
void pickup(int
Пример: обедающие философы
monitor dp
{
enum {thinking, hungry, eating} state[5];
condition self[5];
void pickup(int

Обедающие философы: реализация операций pickup и putdown
void pickup(int i) {
state[i] =
Обедающие философы: реализация операций pickup и putdown
void pickup(int i) {
state[i] =

Обедающие философы: реализация операции test
void test(int i) {
if ( (state[(i +
Обедающие философы: реализация операции test
void test(int i) {
if ( (state[(i +

Реализация мониторов с помощью семафоров
Переменные
semaphore mutex; // (initially = 1)
semaphore
Реализация мониторов с помощью семафоров
Переменные
semaphore mutex; // (initially = 1)
semaphore

Реализация мониторов
Для каждой условной переменной x:
semaphore x-sem; // (initially = 0)
int
Реализация мониторов
Для каждой условной переменной x:
semaphore x-sem; // (initially = 0)
int

Реализация мониторов
Реализация операции x.signal:
if (x-count > 0) {
next-count++;
signal(x-sem);
wait(next);
next-count--;
}
Реализация мониторов
Реализация операции x.signal:
if (x-count > 0) {
next-count++;
signal(x-sem);
wait(next);
next-count--;
}

Реализация мониторов
Конструкция conditional-wait: x.wait(c);
c – целое выражение, вычисляемое при исполнении операции
Реализация мониторов
Конструкция conditional-wait: x.wait(c);
c – целое выражение, вычисляемое при исполнении операции

Синхронизация в Solaris 2
Реализованы разнообразные виды блокировок для поддержки многозадачности, многопоточности
Синхронизация в Solaris 2
Реализованы разнообразные виды блокировок для поддержки многозадачности, многопоточности
 Поражение суставов при иммунодефицитных состоянии
Поражение суставов при иммунодефицитных состоянии Реконструкция существующих одномодовых ВОЛС первичной сети
Реконструкция существующих одномодовых ВОЛС первичной сети МЕТАЛЛЫ
МЕТАЛЛЫ Пристрої цифрової обробки радіолокаційних сигналів (заняття № 2.5)
Пристрої цифрової обробки радіолокаційних сигналів (заняття № 2.5) Общее равновесие в международной торговле. Стандартная модель международной торговли (СММТ)
Общее равновесие в международной торговле. Стандартная модель международной торговли (СММТ) Искусственные материалы. Тонколистовой металл и проволока
Искусственные материалы. Тонколистовой металл и проволока Культурно-исторические особенности народов России
Культурно-исторические особенности народов России Виды термической обработки стали
Виды термической обработки стали Травмы. Переломы и вывихи
Травмы. Переломы и вывихи ДНК и РНК. Устройство генома
ДНК и РНК. Устройство генома Научающе-бихевиоральное направление Б.Ф. Скиннер
Научающе-бихевиоральное направление Б.Ф. Скиннер Туган төбәгебезнең экологик торышы.
Туган төбәгебезнең экологик торышы. Ангельское личико. Фабула или пересказ содержания. Жак Лурселль. Авторская энциклопедия фильмов
Ангельское личико. Фабула или пересказ содержания. Жак Лурселль. Авторская энциклопедия фильмов Презентация проекта Деревянная ложка
Презентация проекта Деревянная ложка Структурированная кабельная система (СКС)
Структурированная кабельная система (СКС) методическая разработка классного час по теме Толерантность
методическая разработка классного час по теме Толерантность Наволочка с клапаном. Обработка поперечных срезов наволочки
Наволочка с клапаном. Обработка поперечных срезов наволочки Викторина Африка
Викторина Африка Презентация к уроку Австралия (7 класс)
Презентация к уроку Австралия (7 класс) конспект урока по окружающему миру Воздух 1 класс
конспект урока по окружающему миру Воздух 1 класс Совершенствование перевозок пассажиров на линии метрополитена
Совершенствование перевозок пассажиров на линии метрополитена Тепловая карта ОМП 01.2024
Тепловая карта ОМП 01.2024 Виды трубопроводов
Виды трубопроводов Объекты - продолжение. Ценные бумаги и нематериальные блага
Объекты - продолжение. Ценные бумаги и нематериальные блага Звук и буква Ц
Звук и буква Ц В гостях у сказки
В гостях у сказки ВКР: Организация медницко-радиаторного участка на предприятии АТЦ АО Соликамский завод Урал
ВКР: Организация медницко-радиаторного участка на предприятии АТЦ АО Соликамский завод Урал Организация методической помощи студентам по написанию ВКР. Требования к ВКР
Организация методической помощи студентам по написанию ВКР. Требования к ВКР