- Оптимизация технологических и процессов общественного питания

Содержание
- 2. Оптимизация – поиск оптимума Оптимумом, или оптимальным вариантом называется вариант, который является наилучшим среди допустимых при
- 3. Литература Разработка новых видов пищевых продуктов [Электронный ресурс] : метод. указания к выполнению практ. работы "Изучение
- 4. Классификация видов оптимизации По количеству критериев (однокритериальная и многокритериальная) По наличию дополнительных условий (безусловная и условная)
- 5. Этапы оптимизации технологического процесса 1. Постановка задачи 1.1. Определение параметров, подлежащих оптимизации и установление ограничений 1.2.
- 6. Критерий оптимальности Правильный выбор критерия оптимальности – это залог успеха всего процесса оптимизации. Высокая субъективность выбора:
- 7. Требования к параметрам оптимизации Простота определения Высокая воспроизводимость Очевидное направление оптимизации Взаимосвязь с общей оценкой привлекательности
- 8. Примеры параметров оптимизации Общая рентабельность предприятия; окупаемость капитальных вложений Себестоимость на единицу продукции или её часть
- 9. Примеры дополнительных условий оптимизации Показатели безопасности (не выше допустимых норм с учётом запаса) Минимальная рентабельность предприятия/максимум
- 10. Подходы к решению многопараметрических задач Оптимизация с несколькими целевыми функциями (многокритериальная оптимизация) Замена некоторых параметров оптимизации
- 11. Обобщённые параметры оптимизации Уровень качества по органолептической оценке: Комплексный безразмерный показатель качества: Аналогично при степенном подходе
- 12. Нормирование параметров Из в Из в Обратное преобразование: в Из в Из в
- 13. Распространённые ошибки при выборе обобщённого параметра оптимизации Отдельные параметры оптимизации не прошли нормирование и могут меняться
- 14. Факторы Варьируемые Фиксируемые Неуправляемые 3.1. Управляемые пассивно 3.2. Совершенно неуправляемые Не учитываемые Не влияющие (маловлияющие)
- 15. Интервал варьирования факторов Естественные границы варьирования Нормирование уровней варьирования (-1; 0; +1) Возможный выход за пределы
- 16. Методы получения целевой функции Анализ математических моделей Использование теории подобия Планирование эксперимента Интерполяционные модели Регрессионный и
- 17. Моделирование технологических процессов Натурное (эксперименты на реальном объекте) Физическое (на основе теории подобия) Аналоговое (аналогичное) моделирование
- 18. Основы теории подобия Подобие – это полная математическая аналогия при наличии пропорциональности между сходственными переменными, сохраняющаяся
- 19. Теоремы подобия Первая теорема (необходимое условие подобия) - для подобных явлений существуют равные критерии подобия Вторая
- 20. Основы теории планирования эксперимента Основная задача планирования эксперимента – минимизация количества опытов для получения максимальной информации
- 21. Полный факторный эксперимент 2n
- 22. Дробный факторный эксперимент Рост числа влияющих факторов приводит к экспоненциальному росту числа опытов ПФЭ позволяет получить
- 23. Полуреплика 23-1 Фактически, здесь X3 выбирается как эффект взаимодействия для ПФЭ 22: Х1Х2.
- 24. Планы Плакетта-Бермана Для очень большого количества факторов кардинально уменьшить число опытов позволяют планы Плакетта-Бермана. Они включают
- 25. Композиционные планы Дробные и полные планы эксперимента с двумя уровнями варьирования позволяют работать с линейными зависимостями,
- 26. Геометрическая интерпретация ЦКП для ПФЭ 22 ПФЭ ЦОКП ЦРКП
- 27. Центральный рототабельный план 22
- 28. Центральный рототабельный план 23
- 29. Особенности практического использования теории планирования эксперимента Необходимость учёта ошибки опытов – повторные эксперименты (особенно в центре
- 30. Рандомизация Рандомизация – это случайное упорядочение объектов совокупности. Опыты первоначально разработанного плана (строки таблицы) случайным образом
- 31. Предварительная обработка экспериментальных данных Обработка результатов повторяющихся опытов Обработка «временных рядов» и последовательных экспериментов 2.1. Сглаживание
- 32. Сглаживание экспериментальных данных Графический интуитивный метод Регрессионные методы (МНК) Упрощённые методы сглаживания (кроме первой и последней
- 33. Интерполяция и интерполяционные модели Интерполяция – способ получения промежуточных данных по имеющимся точкам В большинстве случаев
- 34. Дисперсионный анализ Позволяет оценить, влияет ли фактор на параметр оптимизации Использует F-распределение (критерий Фишера) Многофакторный дисперсионный
- 35. Последовательность однофакторного дисперсионного анализа Выбирается несколько выборок данных (не менее 2), различающихся значением фактора В каждой
- 36. Многофакторный дисперсионный анализ
- 37. Факторный анализ Позволяет сократить количество факторов (или параметров оптимизации) за счёт удаления взаимосвязанных Методы факторного анализа
- 38. Корреляционный анализ Корреляция – статистическая зависимость двух или более случайных (или условно случайных) величин. При наличии
- 39. Особенности коэффициента корреляции (на графиках) r ?1 r ?-1 r ≈0 r ≈0 r r ≈0
- 40. Ограничения коэффициента корреляции Все величины должны быть распределены нормально Для значимого результата необходимо большое число измерений
- 41. Множественная корреляция Оценивается теснота связи одной величины y и нескольких влияющих на неё x1, x2, x3
- 42. Анализ математических моделей Решение дифференциального уравнения для частной задачи - аналитическими методами - численными методами: обыкновенные
- 43. Регрессионный анализ Регрессионный анализ – это статистический метод исследования влияния одной или нескольких независимых переменных на
- 44. Определение коэффициентов регрессии Наиболее распространённый метод – метод наименьших квадратов (МНК) Задача: Для линейных и близких
- 45. Подходы к сведению моделей к линейным Математический аппарат для парной и множественной линейной регрессии хорошо отработан,
- 46. Оценка адекватности модели Подбор наилучших значений коэффициентов регрессии не гарантирует наилучший выбор модели – он лишь
- 47. Значимость коэффициентов регрессии Адекватность уравнения регрессии характеризует его целиком, но отдельные факторы или эффекты могут влиять
- 48. Методы безусловной оптимизации Классификация : По требованиям к гладкости функции Нулевого порядка; прямые методы (требуют только
- 49. Методы с использованием производных (однофакторная задача) Необходимым условием экстремума является равенство нулю, разрыв или неопределённость первой
- 50. Методы с использованием производных (многофакторная задача) При наличии 2 и более факторов необходимым условием экстремума является
- 51. Поскольку при наличии нескольких факторов наибольшее/наименшее значение может быть как внутри границ, так и в любой
- 52. Поисковый метод оптимизации. Методы нулевого порядка Задача поискового метода – определить оптимум без аналитического выражения или
- 53. Симплекс-метод Основан на оптимизации только в точках симплекса – правильного многоугольника/многогранника/гипермногогранника в факторном пространстве с n+1
- 54. Градиентные методы (первого порядка) Движение происходит по градиенту (для максимума) или против (для минимума). Градиент находят
- 55. Метод второго порядка – метод Ньютона Метод Ньютона (метод касательных) – позволяет решить уравнение с использованием
- 56. Условная оптимизация Представляет собой сочетание целевой функции и ряда условий: Линейное программирование – функции f, g,
- 57. Системы нечёткой логики Нечёткая логика – это обобщение задач аристотелевой логики для характеристик, имеющих приблизительную качественную
- 58. Основные операции классической (аристотелевой) логики Конъюнкция (логическое И). a/\b=истина, если а=истина и b=истина; во всех остальных
- 59. Нечёткая логика В нечёткой логике значение логических переменных и результат логических операций лежит в пределах 0…1.
- 60. Работа с неполной, неточной информацией Анализ словесных и качественных описаний Работа с нечёткими множествами Области систем
- 61. Основы теории множеств Множество - это набор некоторого количества (нулевого, конечного, бесконечного) определённых элементов. Элементы множества
- 62. Нечёткие множества Нечётким называют множества, функция принадлежности к которому принимает значения от 0 до 1 (нецелые).
- 63. Лингвистические (нечёткие) переменные Переменные, выражаемые словесно и используемые для суждений, могут быть описаны методами нечёткой логики.
- 65. Применение нечёткой логики и нечётких множеств в оптимизации Задачи нечёткой логики, в первую очередь, важны на
- 66. Альтернативные подходы к формированию целевых функций. 1. Функция потерь Таруги x0 – эталонное значение параметра; х
- 67. Функция желательности Харрингтона Основана на переводе параметра оптимизации к виду шкалы от 0 до 1 и
- 68. Метод множителей Лагранжа
- 69. Решение задач классификации с целью оптимизации Задачи классификации получили широкое распространение в научных исследованиях, в том
- 70. Классификация Классификация – это разделение объектов на группы (классы) в соответствии с некоторыми признаками. Классификация может
- 71. Кластерный анализ Кластерный анализ (кластеризация) – это совокупность методов, позволяющих разбить серию данных, представляющую совокупность признаков
- 72. Методы кластеризации Большинство методов кластерного анализа предполагает, что число классов задаётся изначально. Наиболее распространены следующие методы:
- 73. Метод k-средних Ключевым положением является измерение дистанции между элементами и между кластерами. Первоначально весь набор данных
- 74. Графовый подход, объединительные методы Объединительные методы предполагают объединение отдельных кластеров между собой. Графовый подход предполагает то
- 75. Метод формальных элементов (FOREL) Метод основан на поиске локальных сгущений. В данном методе вокруг случайного элемента
- 76. Оптимизация рецептур в общественном питании (общая методика) Проводится серия поисковых работ для определения направления исследования. Определяются
- 78. Скачать презентацию

Оптимизация – поиск оптимума
Оптимумом, или оптимальным вариантом называется вариант, который является
Оптимизация – поиск оптимума
Оптимумом, или оптимальным вариантом называется вариант, который является
![Литература Разработка новых видов пищевых продуктов [Электронный ресурс] : метод.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/57594/slide-2.jpg)
Литература
Разработка новых видов пищевых продуктов [Электронный ресурс] : метод. указания к
Литература
Разработка новых видов пищевых продуктов [Электронный ресурс] : метод. указания к

Классификация видов оптимизации
По количеству критериев (однокритериальная и многокритериальная)
По наличию дополнительных условий
Классификация видов оптимизации
По количеству критериев (однокритериальная и многокритериальная)
По наличию дополнительных условий

Этапы оптимизации технологического процесса
1. Постановка задачи
1.1. Определение параметров, подлежащих оптимизации и
Этапы оптимизации технологического процесса
1. Постановка задачи
1.1. Определение параметров, подлежащих оптимизации и

Критерий оптимальности
Правильный выбор критерия оптимальности – это залог успеха всего процесса
Критерий оптимальности
Правильный выбор критерия оптимальности – это залог успеха всего процесса

Требования к параметрам оптимизации
Простота определения
Высокая воспроизводимость
Очевидное направление оптимизации
Взаимосвязь с общей оценкой
Требования к параметрам оптимизации
Простота определения
Высокая воспроизводимость
Очевидное направление оптимизации
Взаимосвязь с общей оценкой

Примеры параметров оптимизации
Общая рентабельность предприятия; окупаемость капитальных вложений
Себестоимость на единицу продукции
Примеры параметров оптимизации
Общая рентабельность предприятия; окупаемость капитальных вложений
Себестоимость на единицу продукции

Примеры дополнительных условий оптимизации
Показатели безопасности (не выше допустимых норм с учётом
Примеры дополнительных условий оптимизации
Показатели безопасности (не выше допустимых норм с учётом

Подходы к решению многопараметрических задач
Оптимизация с несколькими целевыми функциями (многокритериальная оптимизация)
Подходы к решению многопараметрических задач
Оптимизация с несколькими целевыми функциями (многокритериальная оптимизация)

Обобщённые параметры оптимизации
Уровень качества по органолептической оценке:
Комплексный безразмерный показатель качества:
Аналогично при
Обобщённые параметры оптимизации
Уровень качества по органолептической оценке:
Комплексный безразмерный показатель качества:
Аналогично при

Нормирование параметров
Из в
Из в
Обратное преобразование: в
Из в
Из
Нормирование параметров
Из в
Из в
Обратное преобразование: в
Из в
Из

Распространённые ошибки при выборе обобщённого параметра оптимизации
Отдельные параметры оптимизации не прошли
Распространённые ошибки при выборе обобщённого параметра оптимизации
Отдельные параметры оптимизации не прошли

Факторы
Варьируемые
Фиксируемые
Неуправляемые
3.1. Управляемые пассивно
3.2. Совершенно неуправляемые
Не учитываемые
Не влияющие (маловлияющие)
Факторы
Варьируемые
Фиксируемые
Неуправляемые
3.1. Управляемые пассивно
3.2. Совершенно неуправляемые
Не учитываемые
Не влияющие (маловлияющие)

Интервал варьирования факторов
Естественные границы варьирования
Нормирование уровней варьирования (-1; 0; +1)
Возможный выход
Интервал варьирования факторов
Естественные границы варьирования
Нормирование уровней варьирования (-1; 0; +1)
Возможный выход

Методы получения целевой функции
Анализ математических моделей
Использование теории подобия
Планирование эксперимента
Интерполяционные модели
Регрессионный и
Методы получения целевой функции
Анализ математических моделей
Использование теории подобия
Планирование эксперимента
Интерполяционные модели
Регрессионный и

Моделирование технологических процессов
Натурное (эксперименты на реальном объекте)
Физическое (на основе теории подобия)
Аналоговое
Моделирование технологических процессов
Натурное (эксперименты на реальном объекте)
Физическое (на основе теории подобия)
Аналоговое

Основы теории подобия
Подобие – это полная математическая аналогия при наличии пропорциональности
Основы теории подобия
Подобие – это полная математическая аналогия при наличии пропорциональности

Теоремы подобия
Первая теорема (необходимое условие подобия) - для подобных явлений существуют
Теоремы подобия
Первая теорема (необходимое условие подобия) - для подобных явлений существуют

Основы теории планирования эксперимента
Основная задача планирования эксперимента – минимизация количества опытов
Основы теории планирования эксперимента
Основная задача планирования эксперимента – минимизация количества опытов
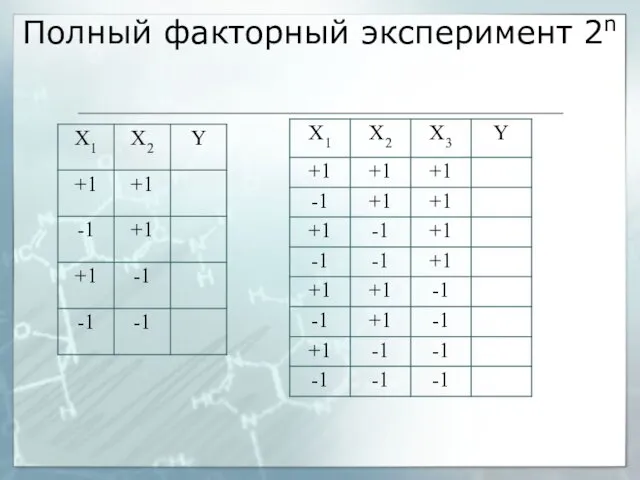
Полный факторный эксперимент 2n
Полный факторный эксперимент 2n

Дробный факторный эксперимент
Рост числа влияющих факторов приводит к экспоненциальному росту числа
Дробный факторный эксперимент
Рост числа влияющих факторов приводит к экспоненциальному росту числа

Полуреплика 23-1
Фактически, здесь X3 выбирается как эффект взаимодействия для ПФЭ 22:
Полуреплика 23-1
Фактически, здесь X3 выбирается как эффект взаимодействия для ПФЭ 22:
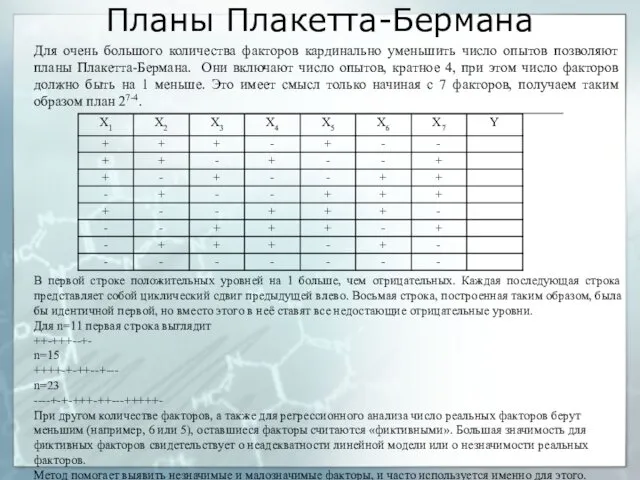
Планы Плакетта-Бермана
Для очень большого количества факторов кардинально уменьшить число опытов позволяют
Планы Плакетта-Бермана
Для очень большого количества факторов кардинально уменьшить число опытов позволяют

Композиционные планы
Дробные и полные планы эксперимента с двумя уровнями варьирования позволяют
Композиционные планы
Дробные и полные планы эксперимента с двумя уровнями варьирования позволяют
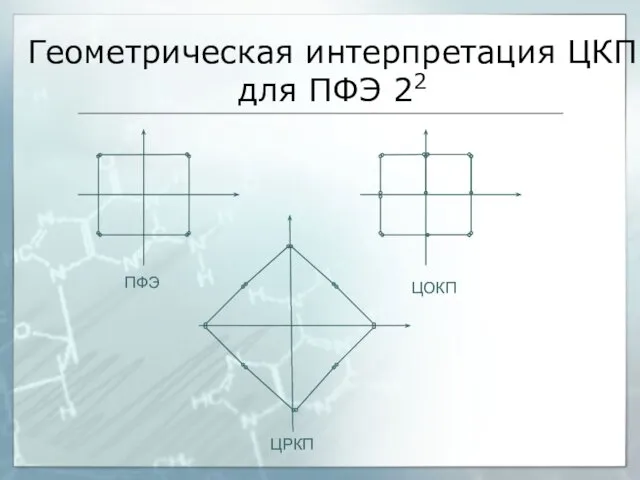
Геометрическая интерпретация ЦКП для ПФЭ 22
ПФЭ
ЦОКП
ЦРКП
Геометрическая интерпретация ЦКП для ПФЭ 22
ПФЭ
ЦОКП
ЦРКП

Центральный рототабельный план 22
Центральный рототабельный план 22

Центральный рототабельный план 23
Центральный рототабельный план 23

Особенности практического
использования теории
планирования эксперимента
Необходимость учёта ошибки опытов – повторные эксперименты (особенно
Особенности практического
использования теории
планирования эксперимента
Необходимость учёта ошибки опытов – повторные эксперименты (особенно
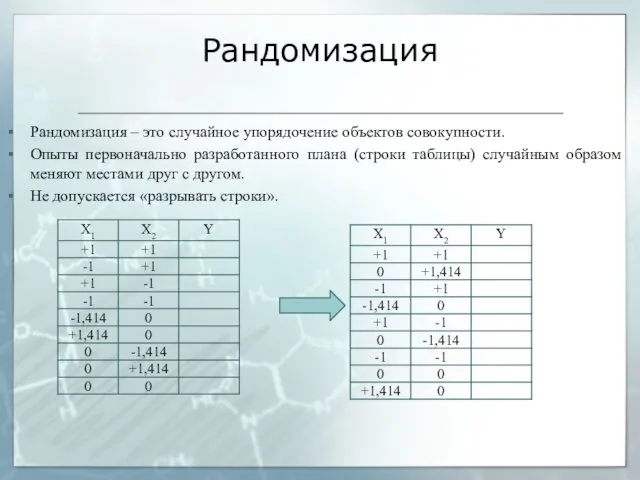
Рандомизация
Рандомизация – это случайное упорядочение объектов совокупности.
Опыты первоначально разработанного плана (строки
Рандомизация
Рандомизация – это случайное упорядочение объектов совокупности.
Опыты первоначально разработанного плана (строки

Предварительная обработка экспериментальных данных
Обработка результатов повторяющихся опытов
Обработка «временных рядов» и
Предварительная обработка экспериментальных данных
Обработка результатов повторяющихся опытов
Обработка «временных рядов» и

Сглаживание экспериментальных данных
Графический интуитивный метод
Регрессионные методы (МНК)
Упрощённые методы сглаживания
(кроме
Сглаживание экспериментальных данных
Графический интуитивный метод
Регрессионные методы (МНК)
Упрощённые методы сглаживания
(кроме

Интерполяция и интерполяционные модели
Интерполяция – способ получения промежуточных данных по имеющимся
Интерполяция и интерполяционные модели
Интерполяция – способ получения промежуточных данных по имеющимся

Дисперсионный анализ
Позволяет оценить, влияет ли фактор на параметр оптимизации
Использует F-распределение (критерий
Дисперсионный анализ
Позволяет оценить, влияет ли фактор на параметр оптимизации
Использует F-распределение (критерий

Последовательность однофакторного дисперсионного анализа
Выбирается несколько выборок данных (не менее 2), различающихся
Последовательность однофакторного дисперсионного анализа
Выбирается несколько выборок данных (не менее 2), различающихся

Многофакторный дисперсионный анализ
Многофакторный дисперсионный анализ

Факторный анализ
Позволяет сократить количество факторов (или параметров оптимизации) за счёт удаления
Факторный анализ
Позволяет сократить количество факторов (или параметров оптимизации) за счёт удаления

Корреляционный анализ
Корреляция – статистическая зависимость двух или более случайных (или условно
Корреляционный анализ
Корреляция – статистическая зависимость двух или более случайных (или условно

Особенности коэффициента корреляции (на графиках)
r ?1
r ?-1
r ≈0
r ≈0
r <1
r ≈0
Особенности коэффициента корреляции (на графиках)
r ?1
r ?-1
r ≈0
r ≈0
r <1
r ≈0

Ограничения коэффициента корреляции
Все величины должны быть распределены нормально
Для значимого результата необходимо
Ограничения коэффициента корреляции
Все величины должны быть распределены нормально
Для значимого результата необходимо

Множественная корреляция
Оценивается теснота связи одной величины y и нескольких влияющих на
Множественная корреляция
Оценивается теснота связи одной величины y и нескольких влияющих на

Анализ математических моделей
Решение дифференциального уравнения для частной задачи
- аналитическими методами
- численными
Анализ математических моделей
Решение дифференциального уравнения для частной задачи
- аналитическими методами
- численными

Регрессионный анализ
Регрессионный анализ – это статистический метод исследования влияния одной или
Регрессионный анализ
Регрессионный анализ – это статистический метод исследования влияния одной или

Определение коэффициентов регрессии
Наиболее распространённый метод – метод наименьших квадратов (МНК)
Задача:
Для линейных
Определение коэффициентов регрессии
Наиболее распространённый метод – метод наименьших квадратов (МНК)
Задача:
Для линейных

Подходы к сведению моделей к линейным
Математический аппарат для парной и множественной
Подходы к сведению моделей к линейным
Математический аппарат для парной и множественной

Оценка адекватности модели
Подбор наилучших значений коэффициентов регрессии не гарантирует наилучший выбор
Оценка адекватности модели
Подбор наилучших значений коэффициентов регрессии не гарантирует наилучший выбор

Значимость коэффициентов регрессии
Адекватность уравнения регрессии характеризует его целиком, но отдельные факторы
Значимость коэффициентов регрессии
Адекватность уравнения регрессии характеризует его целиком, но отдельные факторы

Методы безусловной оптимизации
Классификация :
По требованиям к гладкости функции
Нулевого порядка; прямые методы
Методы безусловной оптимизации
Классификация :
По требованиям к гладкости функции
Нулевого порядка; прямые методы

Методы с использованием производных
(однофакторная задача)
Необходимым условием экстремума является равенство нулю,
Методы с использованием производных
(однофакторная задача)
Необходимым условием экстремума является равенство нулю,

Методы с использованием производных
(многофакторная задача)
При наличии 2 и более факторов
Методы с использованием производных
(многофакторная задача)
При наличии 2 и более факторов

Поскольку при наличии нескольких факторов наибольшее/наименшее значение может быть как внутри
Поскольку при наличии нескольких факторов наибольшее/наименшее значение может быть как внутри

Поисковый метод оптимизации. Методы нулевого порядка
Задача поискового метода – определить оптимум
Поисковый метод оптимизации. Методы нулевого порядка
Задача поискового метода – определить оптимум

Симплекс-метод
Основан на оптимизации только в точках симплекса – правильного многоугольника/многогранника/гипермногогранника в
Симплекс-метод
Основан на оптимизации только в точках симплекса – правильного многоугольника/многогранника/гипермногогранника в

Градиентные методы (первого порядка)
Движение происходит по градиенту (для максимума) или против
Градиентные методы (первого порядка)
Движение происходит по градиенту (для максимума) или против

Метод второго порядка – метод Ньютона
Метод Ньютона (метод касательных) – позволяет
Метод второго порядка – метод Ньютона
Метод Ньютона (метод касательных) – позволяет

Условная оптимизация
Представляет собой сочетание целевой функции и ряда условий:
Линейное программирование –
Условная оптимизация
Представляет собой сочетание целевой функции и ряда условий:
Линейное программирование –

Системы нечёткой логики
Нечёткая логика – это обобщение задач аристотелевой логики для
Системы нечёткой логики
Нечёткая логика – это обобщение задач аристотелевой логики для

Основные операции классической (аристотелевой) логики
Конъюнкция (логическое И). a/\b=истина, если а=истина и
Основные операции классической (аристотелевой) логики
Конъюнкция (логическое И). a/\b=истина, если а=истина и

Нечёткая логика
В нечёткой логике значение логических переменных и результат логических операций
Нечёткая логика
В нечёткой логике значение логических переменных и результат логических операций

Работа с неполной, неточной информацией
Анализ словесных и качественных описаний
Работа с нечёткими
Работа с неполной, неточной информацией
Анализ словесных и качественных описаний
Работа с нечёткими

Основы теории множеств
Множество - это набор некоторого количества (нулевого, конечного, бесконечного)
Основы теории множеств
Множество - это набор некоторого количества (нулевого, конечного, бесконечного)

Нечёткие множества
Нечётким называют множества, функция принадлежности к которому принимает значения от
Нечёткие множества
Нечётким называют множества, функция принадлежности к которому принимает значения от

Лингвистические (нечёткие) переменные
Переменные, выражаемые словесно и используемые для суждений, могут быть
Лингвистические (нечёткие) переменные
Переменные, выражаемые словесно и используемые для суждений, могут быть


Применение нечёткой логики и нечётких множеств в оптимизации
Задачи нечёткой логики, в
Применение нечёткой логики и нечётких множеств в оптимизации
Задачи нечёткой логики, в

Альтернативные подходы к формированию целевых функций.
1. Функция потерь Таруги
x0 –
Альтернативные подходы к формированию целевых функций.
1. Функция потерь Таруги
x0 –

Функция желательности Харрингтона
Основана на переводе параметра оптимизации к виду шкалы от
Функция желательности Харрингтона
Основана на переводе параметра оптимизации к виду шкалы от

Метод множителей Лагранжа
Метод множителей Лагранжа

Решение задач классификации с целью оптимизации
Задачи классификации получили широкое распространение
Решение задач классификации с целью оптимизации
Задачи классификации получили широкое распространение

Классификация
Классификация – это разделение объектов на группы (классы) в соответствии с
Классификация
Классификация – это разделение объектов на группы (классы) в соответствии с

Кластерный анализ
Кластерный анализ (кластеризация) – это совокупность методов, позволяющих разбить серию
Кластерный анализ
Кластерный анализ (кластеризация) – это совокупность методов, позволяющих разбить серию

Методы кластеризации
Большинство методов кластерного анализа предполагает, что число классов задаётся изначально.
Наиболее
Методы кластеризации
Большинство методов кластерного анализа предполагает, что число классов задаётся изначально.
Наиболее

Метод k-средних
Ключевым положением является измерение дистанции между элементами и между кластерами.
Первоначально
Метод k-средних
Ключевым положением является измерение дистанции между элементами и между кластерами.
Первоначально

Графовый подход,
объединительные методы
Объединительные методы предполагают объединение отдельных кластеров между собой.
Графовый подход,
объединительные методы
Объединительные методы предполагают объединение отдельных кластеров между собой.

Метод формальных элементов
(FOREL)
Метод основан на поиске локальных сгущений.
В данном методе вокруг
Метод формальных элементов
(FOREL)
Метод основан на поиске локальных сгущений.
В данном методе вокруг

Оптимизация рецептур в общественном питании (общая методика)
Проводится серия поисковых работ для
Оптимизация рецептур в общественном питании (общая методика)
Проводится серия поисковых работ для
 Актуальные вопросы преподавания предмета Основы религиозных культур и светской этики
Актуальные вопросы преподавания предмета Основы религиозных культур и светской этики Менингококковая инфекция. Менингеальный синдром в клинике инфекционных болезней
Менингококковая инфекция. Менингеальный синдром в клинике инфекционных болезней Преступления против основ конституционного строя и безопасности государства
Преступления против основ конституционного строя и безопасности государства Программы для занятий
Программы для занятий Операциялық жүйе
Операциялық жүйе Общие сведения о программе 1С: Предприятие - ЗУП. Начальное заполнение информационной базы в 1С:
Общие сведения о программе 1С: Предприятие - ЗУП. Начальное заполнение информационной базы в 1С: Кто говорит, что на войне не страшно, тот ничего не знает о войне. 9 мая - День Победы
Кто говорит, что на войне не страшно, тот ничего не знает о войне. 9 мая - День Победы Рисунок птицы в простой графическом редакторе
Рисунок птицы в простой графическом редакторе Методическая разработка образовательной программы по образовательной области ПОЗНАВАТЕЛЬНОЕ РАЗВИТИЕ. Тема Проектная деятельность с детьми старшего дошкольного возраста
Методическая разработка образовательной программы по образовательной области ПОЗНАВАТЕЛЬНОЕ РАЗВИТИЕ. Тема Проектная деятельность с детьми старшего дошкольного возраста Дизартрии у детей. Взгляд невролога
Дизартрии у детей. Взгляд невролога Измерение углов. Транспортир.
Измерение углов. Транспортир. Цветотерапия - как средство снятия стресса
Цветотерапия - как средство снятия стресса Промышленный дизайн
Промышленный дизайн Крайние точки России
Крайние точки России Мастер-класс Розы из кленовых листьев
Мастер-класс Розы из кленовых листьев Политическая система общества
Политическая система общества АҚ Өскемен құс фабрикасы
АҚ Өскемен құс фабрикасы Utilajul frigorific din sala de comerț
Utilajul frigorific din sala de comerț Формикарий – муравьиная ферма
Формикарий – муравьиная ферма Серия мин ТМ-62
Серия мин ТМ-62 Русский алфавит или азбука
Русский алфавит или азбука МАТЕМАТИКА Угол
МАТЕМАТИКА Угол Развитие и воспитание учащихся в процессе обучения биологии
Развитие и воспитание учащихся в процессе обучения биологии Способы доказательств теоремы Пифагора
Способы доказательств теоремы Пифагора Образование как общественное явление
Образование как общественное явление Товароведные характеристики и особенности реализации ювелирных изделий
Товароведные характеристики и особенности реализации ювелирных изделий Презентация Детская организация РОСТ
Презентация Детская организация РОСТ Размещение объявлений на ДомКлик для клиентов и партнеров
Размещение объявлений на ДомКлик для клиентов и партнеров