- Основы теории проверки статистических гипотез

Содержание
- 2. Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой гипотез. Задачи статистической проверки гипотез: Относительно
- 3. Гипотеза – предположение о свойстве популяции (каком-либо параметре, форме распределения…). Тестирование гипотезы (hypothesis testing) – –
- 4. Предполагается, что мы формулируем гипотезу ДО сбора данных.
- 5. Тестирование гипотез в статистике Гипотеза формулируется о свойствах ПОПУЛЯЦИИ = генеральной совокупности, (предположения о самой выборке
- 7. Уровнем значимости критерия (α) называется вероятность допустить ошибку 1-го рода. Уровень значимости — процент появления ошибок
- 8. Тестирование гипотез в статистике Хорошая практика при изложении результатов в публикации – Приводить точную оценку вероятности
- 9. Тестирование гипотез в статистике Односторонняя альтернатива (one-tailed hypothesis) H0: μ ≤ 90 г; H1 : μ
- 10. Сравнение групп
- 11. Виды критериев Параметрические т.е. основанные на расчете параметрв генеральной совокупности (X, σ2). Достоинства: более мощные и
- 12. t-критерий Стьюдента - общее название для класса методов статистической проверки гипотез (статистических критериев), основанных на распределении
- 13. Применение t-критерия Критерий позволяет найти вероятность того, что оба средних значения в выборке относятся к одной
- 14. Критерий Стьюдента применяется, если нужно сравнить только две группы количественных признаков с нормальным распределением (частный случай
- 18. Виды критериев Непараметрические т.е. не включающие в формулу расчета параметров распределения, основанные на оперировании частотами или
- 20. Критерий Вилкоксона - вычисляются разности между индивидуальными значениями показателя после проведения эксперимента и до него. Алгоритм
- 44. КОРРЕЛЯЦИОННЫЙ и РЕГРЕССИОННЫЙ АНАЛИЗ
- 45. Если из множества значений аргумента Х одному значению соответствуют множество значений Y на конечном интервале значений,
- 46. Различают корреляции нескольких направлений: Прямая положительная корреляция, при которой увеличение причинного фактора вызывает увеличение следственного фактора;
- 47. Прямая отрицательная корреляция, при которой уменьшение причинного фактора вызывает уменьшение следственного фактора; например, уменьшение длины дистанции
- 48. Обратная положительная корреляция, при которой уменьшение причинного фактора вызывает увеличение следственного фактора; например, уменьшение длины дистанции
- 49. Обратная отрицательная корреляция, при которой увеличение причинного фактора вызывает уменьшение следственного; например, увеличение силы мышц может
- 50. Коэффициент корреляции Коэффициент корреляции (r)– показатель тесноты взаимосвязи между парой показателей, получивший широкое применение в практике.
- 51. Количественную меру коэффициента корреляции принято различать по нескольким уровням: Слабая связь – при /r/ Средняя связь
- 52. Качественный анализ коэффициента корреляции принято различать по характеру взаимосвязи: Отрицательная связь – при r Положительная связь
- 53. Результат вычисления коэффициента корреляции позволяет отвечать на три вопроса: Имеется ли взаимосвязь между двумя величинами? Какова
- 54. Цель корреляционного анализа – установить, можно ли значения одного показателя предсказывать по значениям другого. Задачи корреляционного
- 55. Если величина коэффициента корреляции по модулю больше или ровна 0,7 , то говорят, что корреляция, имеет
- 56. Корреляция Корелляция Пирсона (параметрический) Ранговая корреляция Спирмена(непараметрический)
- 57. ТЕОРИЯ КОРРЕЛЯЦИИ ЗАДАЧИ Установить ФОРМУ корреляционной связи Установить ТЕСНОТУ корреляционной связи решает регрессионный анализ решает корреляционный
- 58. Регрессионный анализ Задачей регрессионного анализа является нахождение функциональной зависимости между зависимой у и независимой х переменными
- 59. В ходе регрессионного анализа определяется аналитическое выражение связи зависимой случайной величины Y (результативный признак) с независимыми
- 60. 1.В зависимости от числа явлений – простой (регрессия между двумя переменными); – множественной (регрессия между зависимой
- 61. – линейной (отображается линейной функцией, а между изучаемыми явлениями существуют линейные отношения); – нелинейной (отображается нелинейной
- 62. 3. По характеру связи между включенными в рассмотрение переменными – положительной (увеличение значения независимой переменной приводит
- 63. Основные задачи 1. Определение формы зависимости. 2. Отыскание подходящих значений неизвестных параметров. 3. Оценка неизвестных значений
- 64. 1. Определение формы зависимости
- 65. 1. Определение формы зависимости
- 66. Линейную регрессию можно отразить уравнением прямой линии: Y = а · X + в, где: Y
- 67. Нелинейная регрессия Полиномиальная Гиперболическая Степенная Показательная Экспоненциальная
- 68. Определение коэффициента детерминации Для анализа общего качества уравнения линейной многофакторной регрессии используют множественный коэффициент детерминации ,
- 69. Коэффициент детерминации Свойства: а) 0≤RI≤1; б) Чем ближе коэффициент детерминации к 1, тем лучше регрессия «объясняет»
- 70. Порядок действий при использовании методов корреляционно-регрессионного анализа 1. Исследование природы рассматриваемых переменных для установления типа зависимости
- 71. Порядок действий 2.1. Случайность выборки: несвязанность i-го наблюдения с предыдущими и отсутствие влияния на последующие. 2.2.
- 72. Порядок действий 4. Измерение тесноты связи, вычисление выборочного коэффициента корреляции. 3. Построение диаграммы разброса. 5. Установление
- 74. Скачать презентацию

Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой
Процедура сопоставления высказанного предположения (гипотезы) с выборочными данными называется проверкой

Гипотеза – предположение о свойстве популяции (каком-либо параметре, форме распределения…).
Тестирование гипотезы
Гипотеза – предположение о свойстве популяции (каком-либо параметре, форме распределения…).
Тестирование гипотезы

Предполагается, что мы формулируем гипотезу ДО сбора данных.
Предполагается, что мы формулируем гипотезу ДО сбора данных.

Тестирование гипотез в статистике
Гипотеза формулируется о свойствах ПОПУЛЯЦИИ = генеральной совокупности,
Тестирование гипотез в статистике
Гипотеза формулируется о свойствах ПОПУЛЯЦИИ = генеральной совокупности,


Уровнем значимости критерия (α) называется вероятность допустить ошибку 1-го
Уровнем значимости критерия (α) называется вероятность допустить ошибку 1-го

Тестирование гипотез в статистике
Хорошая практика при изложении результатов в публикации –
Тестирование гипотез в статистике
Хорошая практика при изложении результатов в публикации –

Тестирование гипотез в статистике
Односторонняя альтернатива
(one-tailed hypothesis)
H0: μ ≤ 90 г;
H1
Тестирование гипотез в статистике
Односторонняя альтернатива
(one-tailed hypothesis)
H0: μ ≤ 90 г;
H1

Сравнение групп
Сравнение групп

Виды критериев
Параметрические т.е. основанные на расчете параметрв генеральной совокупности (X,
Виды критериев
Параметрические т.е. основанные на расчете параметрв генеральной совокупности (X,

t-критерий Стьюдента - общее название для класса методов статистической проверки гипотез (статистических критериев), основанных
t-критерий Стьюдента - общее название для класса методов статистической проверки гипотез (статистических критериев), основанных

Применение t-критерия
Критерий позволяет найти вероятность того, что оба средних значения
Применение t-критерия
Критерий позволяет найти вероятность того, что оба средних значения

Критерий Стьюдента применяется, если нужно сравнить только две группы количественных признаков
Критерий Стьюдента применяется, если нужно сравнить только две группы количественных признаков




Виды критериев
Непараметрические т.е. не включающие в формулу расчета параметров распределения,
Виды критериев
Непараметрические т.е. не включающие в формулу расчета параметров распределения,


Критерий Вилкоксона - вычисляются разности между индивидуальными значениями показателя после проведения
Критерий Вилкоксона - вычисляются разности между индивидуальными значениями показателя после проведения























КОРРЕЛЯЦИОННЫЙ и РЕГРЕССИОННЫЙ АНАЛИЗ
КОРРЕЛЯЦИОННЫЙ и РЕГРЕССИОННЫЙ АНАЛИЗ

Если из множества значений аргумента Х одному значению соответствуют множество значений
Если из множества значений аргумента Х одному значению соответствуют множество значений

Различают корреляции нескольких направлений:
Прямая положительная корреляция, при которой увеличение причинного
Различают корреляции нескольких направлений:
Прямая положительная корреляция, при которой увеличение причинного

Прямая отрицательная корреляция, при которой уменьшение причинного фактора вызывает уменьшение следственного
Прямая отрицательная корреляция, при которой уменьшение причинного фактора вызывает уменьшение следственного

Обратная положительная корреляция, при которой уменьшение причинного фактора вызывает увеличение следственного
Обратная положительная корреляция, при которой уменьшение причинного фактора вызывает увеличение следственного

Обратная отрицательная корреляция, при которой увеличение причинного фактора вызывает уменьшение следственного;
Обратная отрицательная корреляция, при которой увеличение причинного фактора вызывает уменьшение следственного;

Коэффициент корреляции
Коэффициент корреляции (r)– показатель тесноты взаимосвязи между парой
Коэффициент корреляции
Коэффициент корреляции (r)– показатель тесноты взаимосвязи между парой

Количественную меру коэффициента корреляции принято различать по нескольким уровням:
Слабая связь
Количественную меру коэффициента корреляции принято различать по нескольким уровням:
Слабая связь

Качественный анализ коэффициента корреляции принято различать по характеру взаимосвязи:
Отрицательная связь
Качественный анализ коэффициента корреляции принято различать по характеру взаимосвязи:
Отрицательная связь

Результат вычисления коэффициента корреляции позволяет отвечать на три вопроса:
Имеется ли
Результат вычисления коэффициента корреляции позволяет отвечать на три вопроса:
Имеется ли

Цель корреляционного анализа – установить, можно ли значения одного показателя предсказывать
Цель корреляционного анализа – установить, можно ли значения одного показателя предсказывать

Если величина коэффициента корреляции по модулю больше или ровна 0,7 ,
Если величина коэффициента корреляции по модулю больше или ровна 0,7 ,

Корреляция
Корелляция Пирсона (параметрический)
Ранговая корреляция Спирмена(непараметрический)
Корреляция
Корелляция Пирсона (параметрический)
Ранговая корреляция Спирмена(непараметрический)
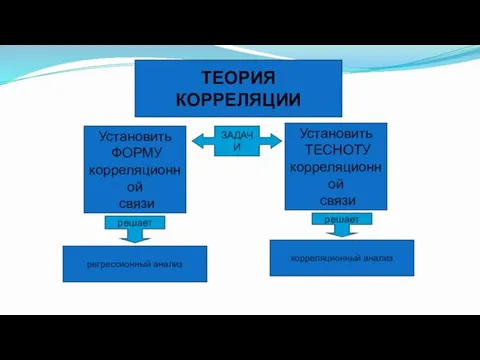
ТЕОРИЯ
КОРРЕЛЯЦИИ
ЗАДАЧИ
Установить
ФОРМУ
корреляционной
связи
Установить
ТЕСНОТУ
корреляционной
связи
решает
регрессионный анализ
решает
корреляционный анализ
КОРРЕЛЯЦИИ
ЗАДАЧИ
Установить
ФОРМУ
корреляционной
связи
Установить
ТЕСНОТУ
корреляционной
связи
решает
регрессионный анализ
решает
корреляционный анализ

Регрессионный анализ
Задачей регрессионного анализа является нахождение функциональной зависимости между зависимой у
Регрессионный анализ
Задачей регрессионного анализа является нахождение функциональной зависимости между зависимой у

В ходе регрессионного анализа определяется аналитическое выражение связи зависимой случайной величины
В ходе регрессионного анализа определяется аналитическое выражение связи зависимой случайной величины

1.В зависимости от числа явлений
– простой (регрессия между двумя переменными);
– множественной (регрессия между
1.В зависимости от числа явлений
– простой (регрессия между двумя переменными);
– множественной (регрессия между

– линейной (отображается линейной функцией, а между изучаемыми явлениями существуют линейные отношения);
– нелинейной
– линейной (отображается линейной функцией, а между изучаемыми явлениями существуют линейные отношения);
– нелинейной

3. По характеру связи между включенными
в рассмотрение переменными
– положительной (увеличение значения
3. По характеру связи между включенными
в рассмотрение переменными
– положительной (увеличение значения

Основные задачи
1. Определение формы зависимости.
2. Отыскание подходящих значений неизвестных параметров.
3. Оценка неизвестных значений зависимой
Основные задачи
1. Определение формы зависимости.
2. Отыскание подходящих значений неизвестных параметров.
3. Оценка неизвестных значений зависимой

1. Определение формы зависимости
1. Определение формы зависимости

1. Определение формы зависимости
1. Определение формы зависимости

Линейную регрессию можно отразить уравнением прямой линии:
Y = а · X
Линейную регрессию можно отразить уравнением прямой линии:
Y = а · X

Нелинейная регрессия
Полиномиальная
Гиперболическая
Степенная
Показательная
Экспоненциальная
Нелинейная регрессия
Полиномиальная
Гиперболическая
Степенная
Показательная
Экспоненциальная

Определение коэффициента детерминации
Для анализа общего качества уравнения линейной многофакторной регрессии используют
Определение коэффициента детерминации
Для анализа общего качества уравнения линейной многофакторной регрессии используют

Коэффициент детерминации
Свойства:
а) 0≤RI≤1;
б) Чем ближе коэффициент детерминации к 1, тем лучше
Коэффициент детерминации
Свойства:
а) 0≤RI≤1;
б) Чем ближе коэффициент детерминации к 1, тем лучше

Порядок действий
при использовании методов
корреляционно-регрессионного анализа
1. Исследование природы рассматриваемых переменных для
Порядок действий
при использовании методов
корреляционно-регрессионного анализа
1. Исследование природы рассматриваемых переменных для

Порядок действий
2.1. Случайность выборки: несвязанность i-го наблюдения с предыдущими и отсутствие влияния
Порядок действий
2.1. Случайность выборки: несвязанность i-го наблюдения с предыдущими и отсутствие влияния

Порядок действий
4. Измерение тесноты связи, вычисление
выборочного коэффициента корреляции.
3. Построение
Порядок действий
4. Измерение тесноты связи, вычисление
выборочного коэффициента корреляции.
3. Построение
 презентация по ОРКСЭ 4 класс
презентация по ОРКСЭ 4 класс Викторина Своя игра
Викторина Своя игра Информационно-практическое занятие для педагогов ДОУ. Презентация. Взаимодействие педагогов дошкольного учреждения с семьей
Информационно-практическое занятие для педагогов ДОУ. Презентация. Взаимодействие педагогов дошкольного учреждения с семьей Животноводство России
Животноводство России Проект урока. Тема Машиностроение мира
Проект урока. Тема Машиностроение мира Порядок слов в английском предложении
Порядок слов в английском предложении Колокол милосердия
Колокол милосердия ЕГЭ на 100 баллов или 100% студент
ЕГЭ на 100 баллов или 100% студент Дитерс Рамс. 10 принципов хорошего дизайна
Дитерс Рамс. 10 принципов хорошего дизайна ИТ поддержки принятия решений (СППР)
ИТ поддержки принятия решений (СППР) Требования к личности воспитателя
Требования к личности воспитателя Налоговые последствия оформления первичных учетных документов
Налоговые последствия оформления первичных учетных документов druzhba_etochudo
druzhba_etochudo Презентация к уроку Краски Тихого Дона2 класс
Презентация к уроку Краски Тихого Дона2 класс Гербы городов Сахалинской области. Презентация.
Гербы городов Сахалинской области. Презентация. Неотложная помощь
Неотложная помощь Решение задач по готовым чертежам. Теорема Пифагора
Решение задач по готовым чертежам. Теорема Пифагора Нестандартный подход к формированию географического мышления с применением карт-анаморфоз
Нестандартный подход к формированию географического мышления с применением карт-анаморфоз презентация работа с родителями по фгос
презентация работа с родителями по фгос Танцы народов Кавказа
Танцы народов Кавказа Развитие стран Восточной Европы во второй половине XX – начале XXI в.в
Развитие стран Восточной Европы во второй половине XX – начале XXI в.в Решение неравенств с одной переменной
Решение неравенств с одной переменной Социал-дарвинизм. Формирование социал-дарвинизма
Социал-дарвинизм. Формирование социал-дарвинизма Мир информатики. Ответы, решения, разъяснения к заданиям. (Часть 1)
Мир информатики. Ответы, решения, разъяснения к заданиям. (Часть 1) Проблемы развития малого и среднего предпринимательства в Чувашской Республике
Проблемы развития малого и среднего предпринимательства в Чувашской Республике Подготовительные работы при строительстве земляного полотна
Подготовительные работы при строительстве земляного полотна Презентация к 70 летию со Дня Победы
Презентация к 70 летию со Дня Победы The Empire State Building
The Empire State Building