- Параллельная обработка больших графов

Содержание
- 2. Откуда возникают большие графы? Интернет (WWW) На сентябрь 2016 – 47 миллиардов страниц По оценке Google
- 3. Биоинформатика: сходство организмов (HPC) Число долей 105 Длина последовательности 109 Вершин в доле 109 (берутся короткие
- 4. Электросети (HPC) Связанность Надежность Различные пути, betweenness centrality
- 5. Анализ социальных сетей (HPC) Анализ сообществ Понимание намерений Динамика популяции Распространение эпидемий Кластеризация
- 6. Бизнес-аналитика и кибербезопасность (Big Data&HPC) Задачи понимания данных из огромных массивов Выявление аномалий в данных Анализ
- 7. Признаки в графах для машинного обучения Вершины (степень, полустепени, betweenness centrality, PageRank) Пары вершин (количество общих
- 8. Классификация задач анализа графов По типу графов статические графы (static graph analysis) динамические графы (dynamic graph
- 9. Программные модели и средства Реляционная модель Cassandra, SAP HANA, … MapReduce Generic MR: Hadoop, Yarn, Dryad,
- 10. Big Data vs HPC Машинное обучение
- 11. Big Data vs HPC
- 12. План Виды графов Основные проблемы, возникающие при решении задач обработки графов Подходы к решению задач в
- 13. Виды графов
- 14. Виды графов. Случайные графы Random, Random Uniform, Erdos Renyi N вершин, M ребер, k – средняя
- 15. Виды графов. Степенной закон WWW, Социальные сети, Биоинформатика Графы small-world L ~ log N scale-free –
- 16. Виды графов. RMAT-граф a+b+c+d = 1 Сообщества: a и d – сообщества b и c –
- 17. Виды графов. LFR*-граф Параметры: mu ∈ [0;1], показывает количество связей вне сообщества com_tau – показатель степени
- 18. Виды графов. SSCA2-граф Равномерное распределение случайных параметров случайная перестановка вершин
- 19. Основные проблемы, возникающие при решении задач обработки графов
- 20. Проблемы анализа больших графов Data-driven computations. Зависимость вычислений от данных (топологии графа). Невозможность применения методов статического
- 21. Проблемы анализа больших графов (1) Data-driven computations. Зависимость вычислений от данных (топологии графа). Невозможность применения методов
- 22. Проблемы анализа больших графов (2) Unstructured problems. Работа с нерегулярными, неструктурированными данными, трудность распараллеливания.
- 23. Проблемы анализа больших графов (3) Poor locality. Низкая пространственно-временная локализация обращений к памяти.
- 24. Проблемы анализа больших графов (4) High data access to computation ratio. Преобладание команд доступа к памяти
- 25. Проблема низкой реальной производительности
- 26. Проблемы и подходы к решению задач обработки графов в рамках одного вычислительного узла
- 27. Представление графа
- 28. Форматы представления разреженных матриц Доля ненулевых элементов мала Можно хранить только позиции и значения ненулевых элементов
- 29. Внутреннее представление Compressed Row Storage (CRS) for (int u = 0; u n; u++) { for
- 30. Coordinate list (COO) Sparse matrix
- 31. Поиск вширь в графе
- 32. Поиск вширь в графе (BFS) Подход Queue-based, алгоритм simple Qcounter = 1 Q[0] = root Visited[root]
- 33. Производительность алгоритма simple в зависимости от числа используемых тредов на сопроцессоре Phi-5110P Число вершин в графе:
- 34. Производительность алгоритмов simple и block в зависимости от числа используемых тредов на сопроцессоре Phi-5110P Число вершин
- 35. Недостатки подхода Queue-based #pragma omp parallel for for all vertex ∈ Q do for all w:
- 36. Память SDRAM Чтение памяти, необходимо подзаряжать конденсаторы Необходимость перезарядки конденсаторов (токи утечки) На все операции требуется
- 37. На определение состояния и перезарядку требуется время Память SDRAM
- 38. Чтение памяти, необходимо подзаряжать конденсаторы Необходимость перезарядки конденсаторов (токи утечки) tRP - время предварительной зарядки Каждая
- 39. Архитектура процессора, контроллер DRAM
- 40. Подход Read-based, алгоритм read #pragma omp parallel for reduction (…) for all vertex ∈ V do
- 41. Производительность алгоритмов simple, block и read в зависимости от числа используемых тредов на сопроцессоре Phi-5110P Число
- 42. Алгоритм bottom-up-hybrid #pragma omp parallel for reduction (…) for all vertex ∈ V do if levels[vertex]
- 43. Производительность алгоритмов simple, block, read и bottom-up-hybrid в зависимости от числа используемых тредов на сопроцессоре Phi-5110P
- 44. Недостатки алгоритмов read и bottom-up-hybrid #pragma omp parallel for reduction (…) for all vertex ∈ V
- 45. Решение: ручная развертка цикла + использование prefetch #pragma omp parallel for reduction (…) for all vertex
- 46. Производительность алгоритмов simple, block, read и bottom-up-hybrid с префетчем в зависимости от числа используемых тредов на
- 47. Улучшение локализации: перестановка вершин Матрица смежности приводится к ленточному виду с уменьшением ширины ленты (алгоритм Reverse
- 48. Производительность различных алгоритмов, с префетчем и перестановками в зависимости от числа используемых тредов на сопроцессоре Phi-5110P
- 49. Распараллеливание: дисбаланс вычислительной нагрузки Проблема: неравномерность итераций циклов # pragma omp parallel for for (int u
- 50. Проблема: постоянная смена данных в кэше, низкие характеристики при случайном доступе Решения на этапе предобработки: Хранение
- 51. Резюме: проблемы и подходы к решению задач в рамках одного узла Выбор оптимального представления графа По
- 52. Проблемы и подходы к решению графовых задач на распределенной памяти
- 53. Представление графа
- 54. Распределение данных 1D, блоками 1D, с чередованием 2D
- 55. Поиск вширь в графе, распределенная версия function ProcessQueue(Q, E) for all vertex ∈ Q do for
- 56. Поиск вширь в графе, агрегация сообщений function ProcessQueue(Q, E) for all vertex ∈ Q do for
- 57. Поиск вширь в графе, параллельная отправка и прием function ProcessQueue(Q, E) for all vertex ∈ Q
- 58. Организация параллелизма потоков
- 59. Хаотично расположенные вершины и ребра графа Шаблон обменов all-to-all
- 60. Коммуникационная сеть. Бисекционная пропускная способность Бисекционная плоскость – минимальный разрез, который разделяет сеть на две равные
- 61. nPE Уменьшение количества пересылаемых данных Использование простаивающего процессора Сокращение пересылок Отказ от лишней пересылаемой информации Удаление
- 62. Графы реального мира. Степенной закон WWW, Социальные сети, Биоинформатика Графы small-world L ~ log N, scale-free
- 63. Балансировка нагрузки При использовании большого числа вычислительных узлов особенно важна равномерная загрузка Решение1: На этапе предобработки
- 64. Задача поиска минимального остовного дерева (MST) Алгоритм Gallagher, Humblet, Spira. Сеть Ангара Граф RMAT-23, средняя связность
- 65. Проблемы и подходы к решению задач на распределенной памяти Выбор распределения данных Агрегация сообщений Организация внутриузлового
- 67. Скачать презентацию

Откуда возникают большие графы?
Интернет (WWW)
На сентябрь 2016 – 47 миллиардов
Откуда возникают большие графы?
Интернет (WWW)
На сентябрь 2016 – 47 миллиардов
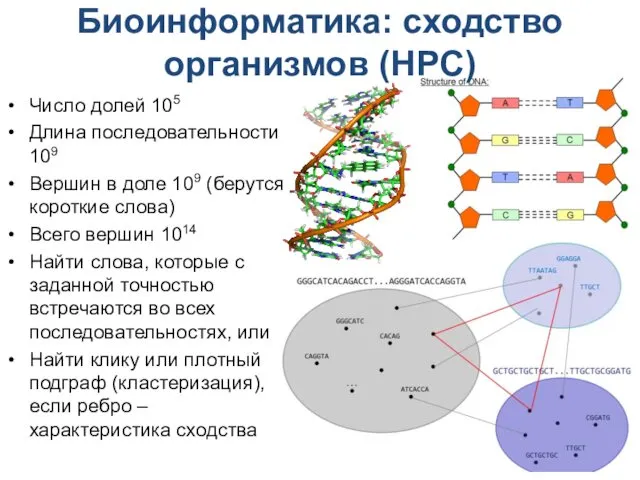
Биоинформатика: сходство организмов (HPC)
Число долей 105
Длина последовательности 109
Вершин в доле
Биоинформатика: сходство организмов (HPC)
Число долей 105
Длина последовательности 109
Вершин в доле
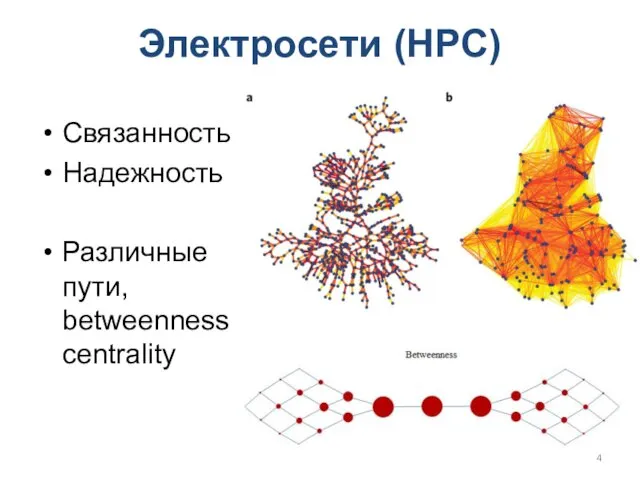
Электросети (HPC)
Связанность
Надежность
Различные пути, betweenness centrality
Электросети (HPC)
Связанность
Надежность
Различные пути, betweenness centrality
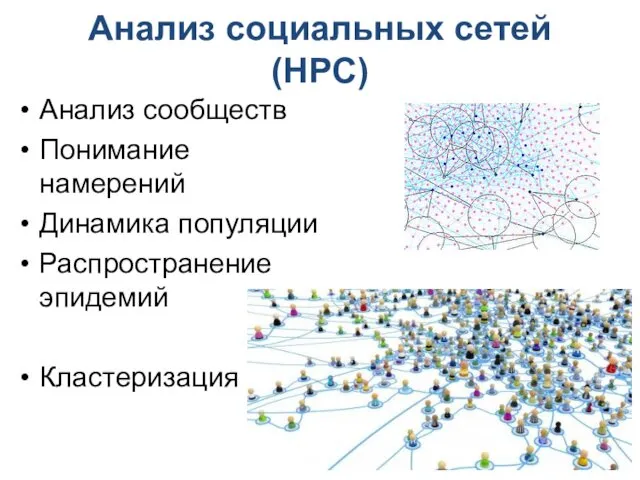
Анализ социальных сетей (HPC)
Анализ сообществ
Понимание намерений
Динамика популяции
Распространение эпидемий
Кластеризация
Анализ социальных сетей (HPC)
Анализ сообществ
Понимание намерений
Динамика популяции
Распространение эпидемий
Кластеризация
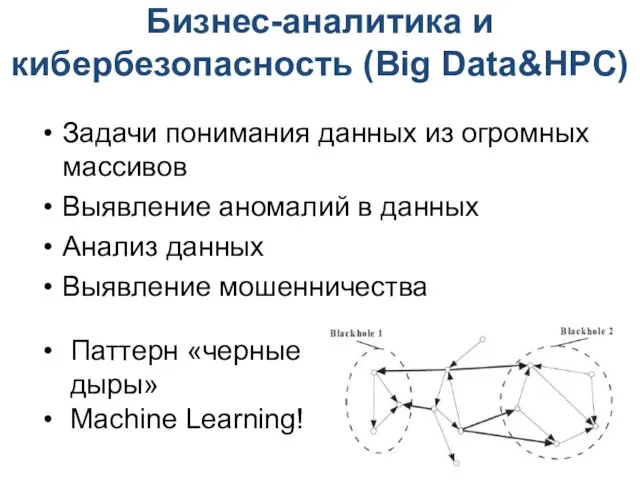
Бизнес-аналитика и кибербезопасность (Big Data&HPC)
Задачи понимания данных из огромных массивов
Выявление аномалий
Бизнес-аналитика и кибербезопасность (Big Data&HPC)
Задачи понимания данных из огромных массивов
Выявление аномалий

Признаки в графах для машинного обучения
Вершины (степень, полустепени, betweenness centrality, PageRank)
Пары
Признаки в графах для машинного обучения
Вершины (степень, полустепени, betweenness centrality, PageRank)
Пары

Классификация задач анализа графов
По типу графов
статические графы (static graph analysis)
динамические графы
Классификация задач анализа графов
По типу графов
статические графы (static graph analysis)
динамические графы

Программные модели и средства
Реляционная модель
Cassandra, SAP HANA, …
MapReduce
Generic MR:
Hadoop, Yarn,
Программные модели и средства
Реляционная модель
Cassandra, SAP HANA, …
MapReduce
Generic MR:
Hadoop, Yarn,
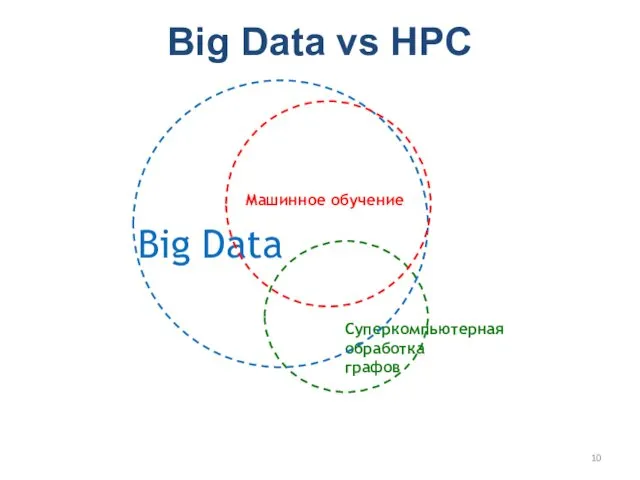
Big Data vs HPC
Машинное обучение
Big Data vs HPC
Машинное обучение
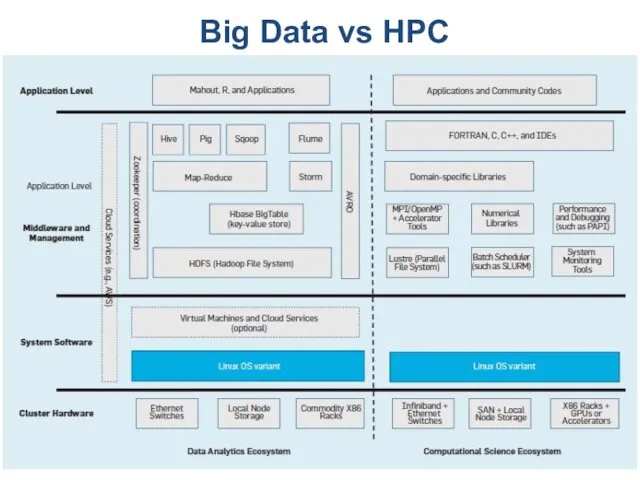
Big Data vs HPC
Big Data vs HPC

План
Виды графов
Основные проблемы, возникающие при решении задач обработки графов
Подходы к решению
План
Виды графов
Основные проблемы, возникающие при решении задач обработки графов
Подходы к решению

Виды графов
Виды графов
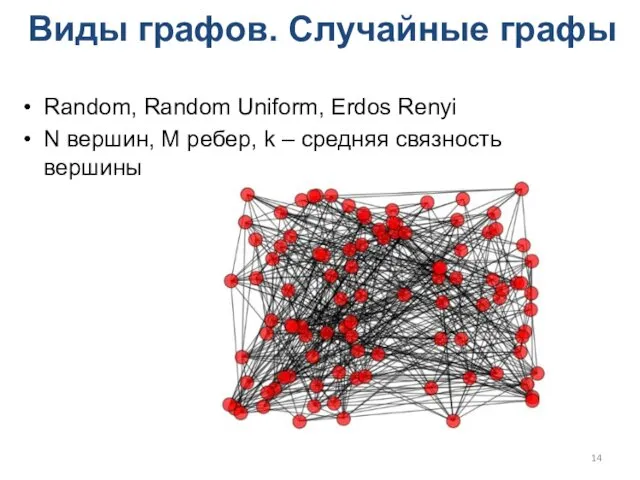
Виды графов. Случайные графы
Random, Random Uniform, Erdos Renyi
N вершин, M ребер,
Виды графов. Случайные графы
Random, Random Uniform, Erdos Renyi
N вершин, M ребер,
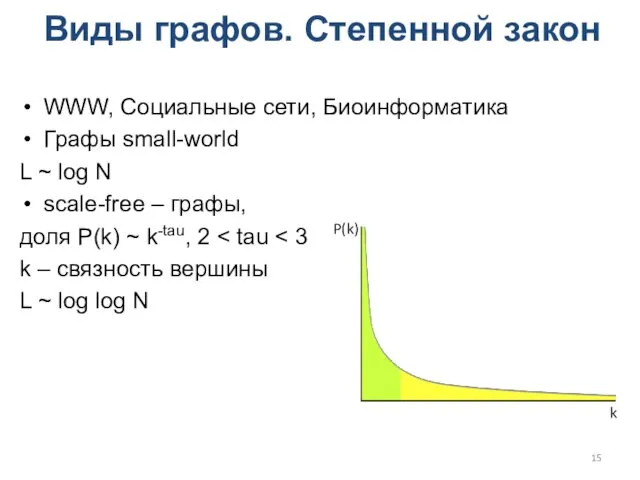
Виды графов. Степенной закон
WWW, Социальные сети, Биоинформатика
Графы small-world
L ~ log N
scale-free
Виды графов. Степенной закон
WWW, Социальные сети, Биоинформатика
Графы small-world
L ~ log N
scale-free
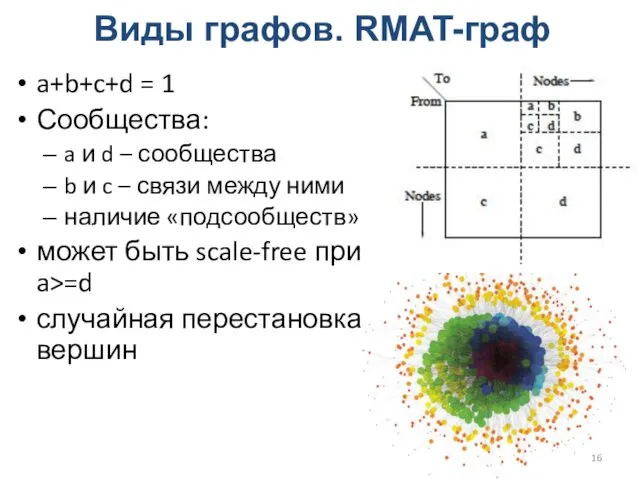
Виды графов. RMAT-граф
a+b+c+d = 1
Сообщества:
a и d – сообщества
b и c
Виды графов. RMAT-граф
a+b+c+d = 1
Сообщества:
a и d – сообщества
b и c
![Виды графов. LFR*-граф Параметры: mu ∈ [0;1], показывает количество связей](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/33778/slide-16.jpg)
Виды графов. LFR*-граф
Параметры:
mu ∈ [0;1], показывает количество связей вне сообщества
Виды графов. LFR*-граф
Параметры:
mu ∈ [0;1], показывает количество связей вне сообщества
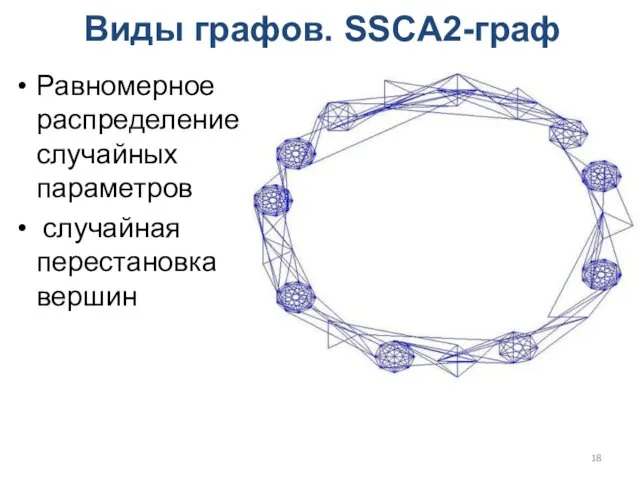
Виды графов. SSCA2-граф
Равномерное распределение случайных параметров
случайная перестановка вершин
Виды графов. SSCA2-граф
Равномерное распределение случайных параметров
случайная перестановка вершин

Основные проблемы, возникающие при решении задач обработки графов
Основные проблемы, возникающие при решении задач обработки графов

Проблемы анализа больших графов
Data-driven computations. Зависимость вычислений от данных (топологии графа).
Проблемы анализа больших графов
Data-driven computations. Зависимость вычислений от данных (топологии графа).
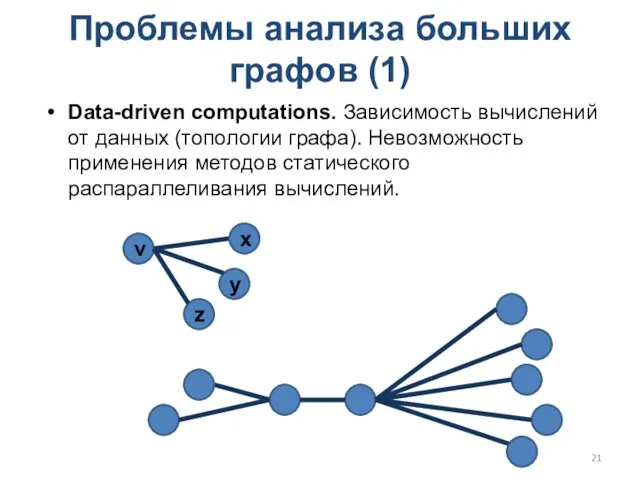
Проблемы анализа больших графов (1)
Data-driven computations. Зависимость вычислений от данных (топологии
Проблемы анализа больших графов (1)
Data-driven computations. Зависимость вычислений от данных (топологии
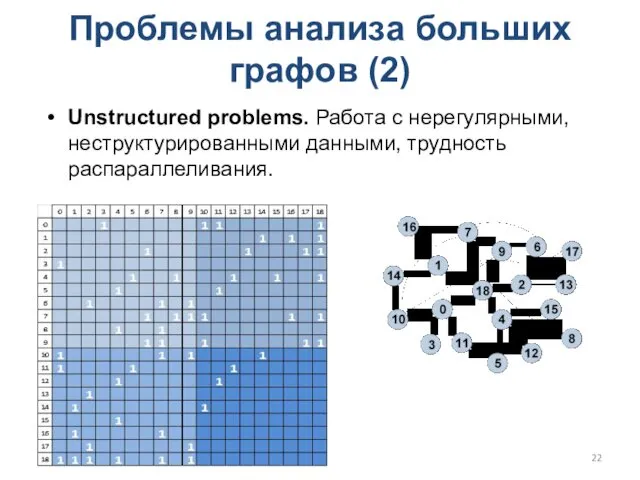
Проблемы анализа больших графов (2)
Unstructured problems. Работа с нерегулярными, неструктурированными данными,
Проблемы анализа больших графов (2)
Unstructured problems. Работа с нерегулярными, неструктурированными данными,
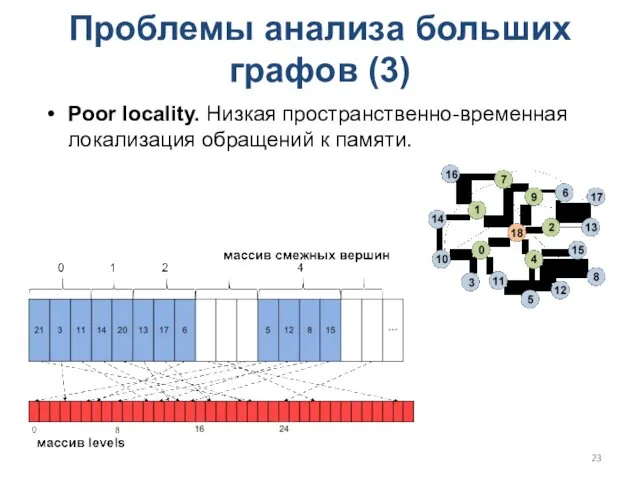
Проблемы анализа больших графов (3)
Poor locality. Низкая пространственно-временная локализация обращений к
Проблемы анализа больших графов (3)
Poor locality. Низкая пространственно-временная локализация обращений к
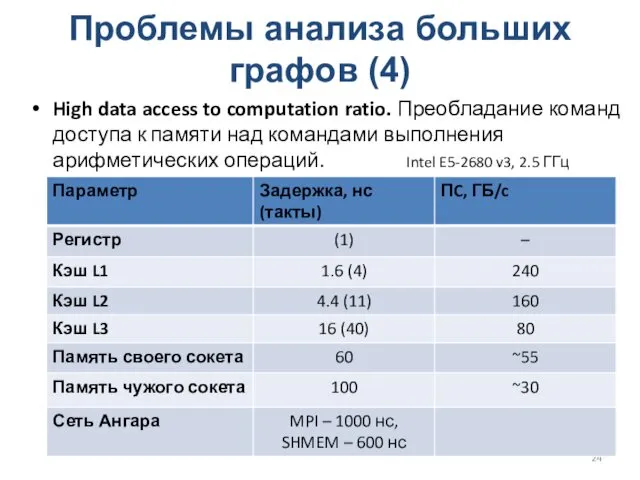
Проблемы анализа больших графов (4)
High data access to computation ratio. Преобладание
Проблемы анализа больших графов (4)
High data access to computation ratio. Преобладание
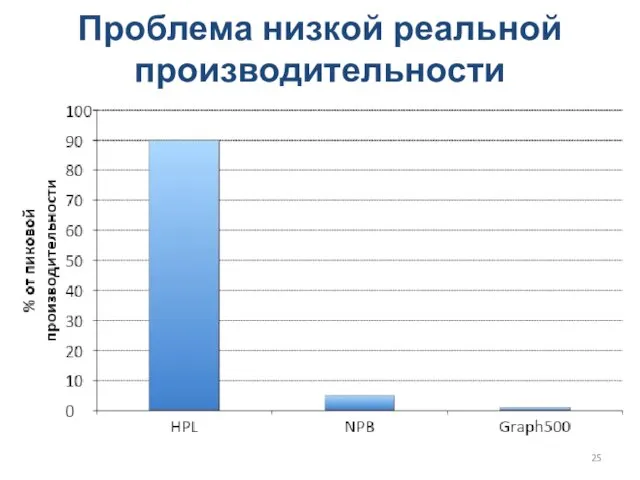
Проблема низкой реальной производительности
Проблема низкой реальной производительности

Проблемы и подходы к решению задач обработки графов в рамках одного
Проблемы и подходы к решению задач обработки графов в рамках одного
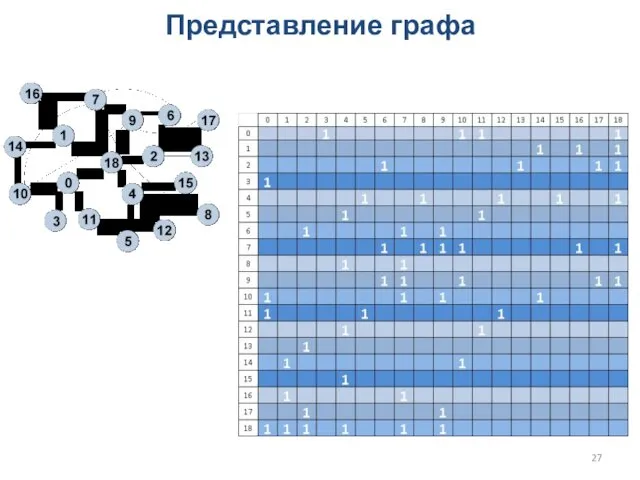
Представление графа
Представление графа

Форматы представления разреженных матриц
Доля ненулевых элементов мала
Можно хранить только позиции
Форматы представления разреженных матриц
Доля ненулевых элементов мала
Можно хранить только позиции
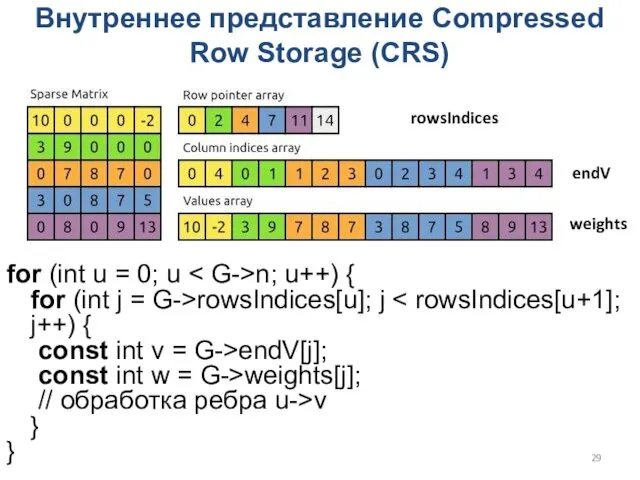
Внутреннее представление Compressed Row Storage (CRS)
for (int u = 0; u
Внутреннее представление Compressed Row Storage (CRS)
for (int u = 0; u
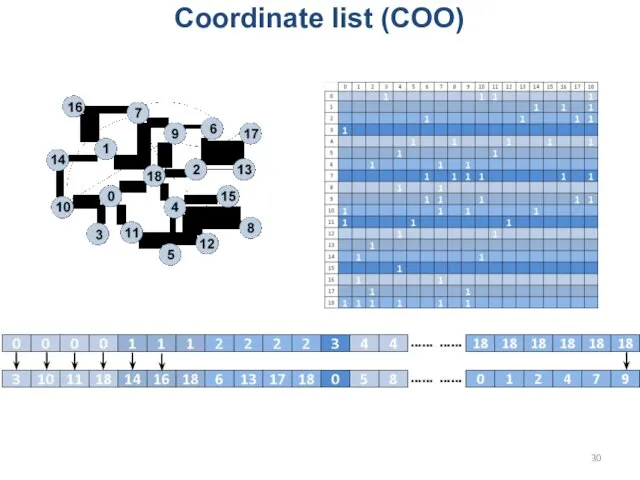
Coordinate list (COO)
Sparse matrix
Coordinate list (COO)
Sparse matrix
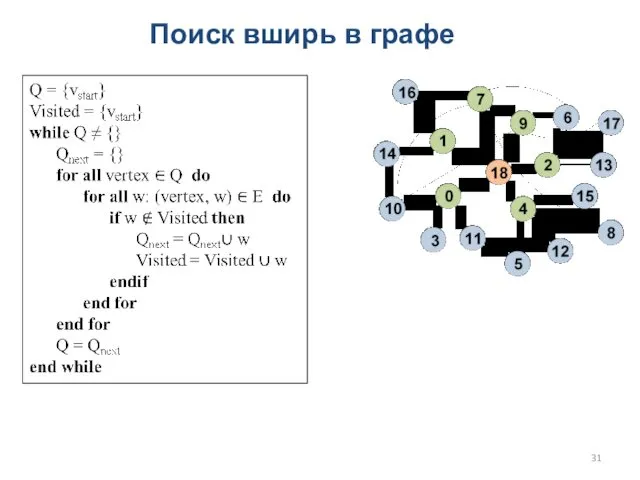
Поиск вширь в графе
Поиск вширь в графе
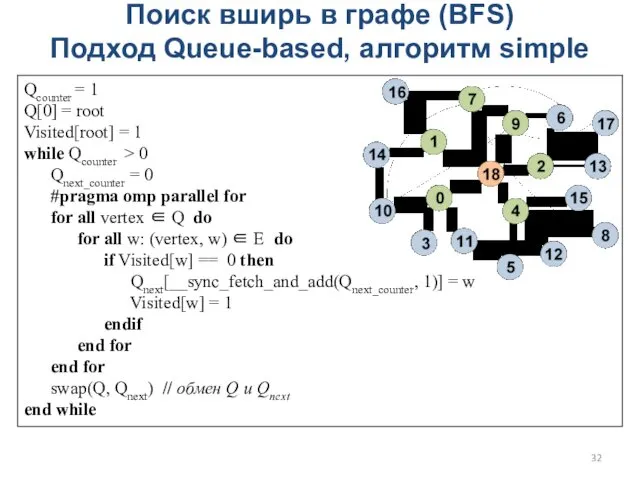
Поиск вширь в графе (BFS)
Подход Queue-based, алгоритм simple
Qcounter = 1
Q[0]
Поиск вширь в графе (BFS)
Подход Queue-based, алгоритм simple
Qcounter = 1
Q[0]
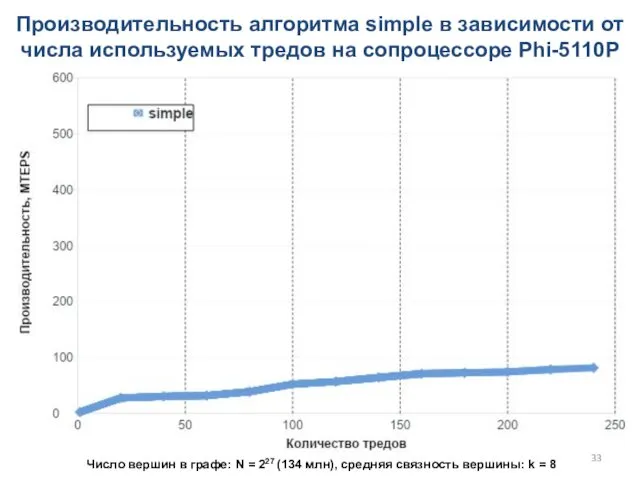
Производительность алгоритма simple в зависимости от числа используемых тредов на сопроцессоре
Производительность алгоритма simple в зависимости от числа используемых тредов на сопроцессоре
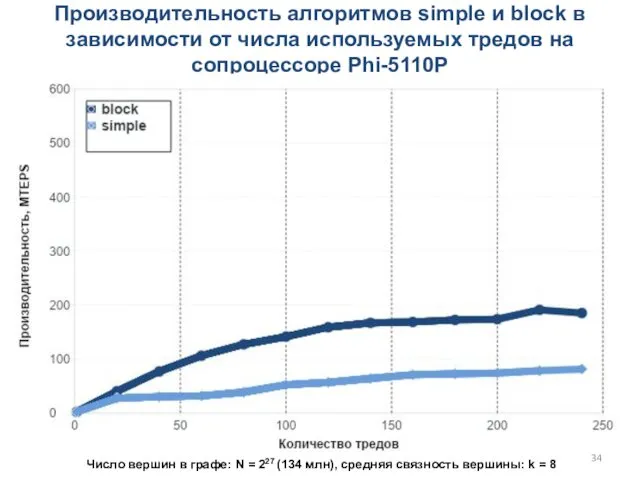
Производительность алгоритмов simple и block в зависимости от числа используемых тредов
Производительность алгоритмов simple и block в зависимости от числа используемых тредов

Недостатки подхода Queue-based
#pragma omp parallel for
for all vertex ∈ Q do
Недостатки подхода Queue-based
#pragma omp parallel for
for all vertex ∈ Q do
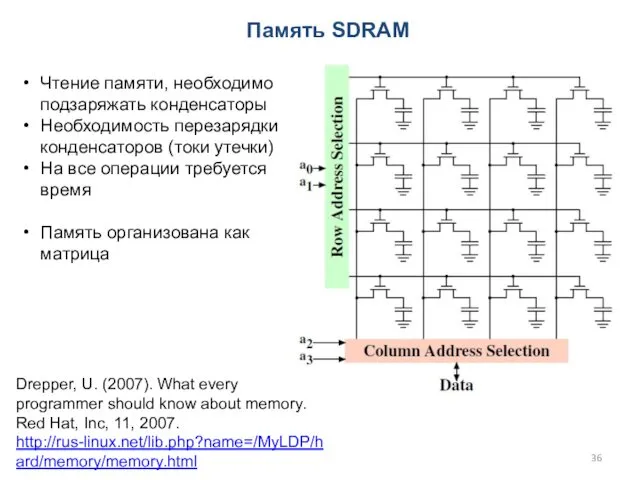
Память SDRAM
Чтение памяти, необходимо подзаряжать конденсаторы
Необходимость перезарядки конденсаторов (токи утечки)
На все
Память SDRAM
Чтение памяти, необходимо подзаряжать конденсаторы
Необходимость перезарядки конденсаторов (токи утечки)
На все
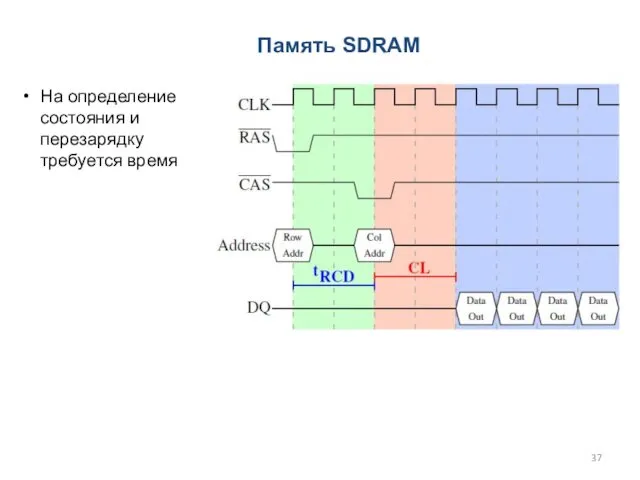
На определение состояния и перезарядку требуется время
Память SDRAM
На определение состояния и перезарядку требуется время
Память SDRAM
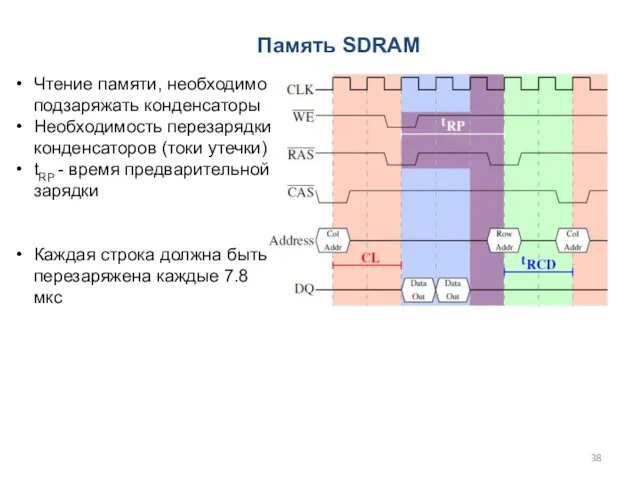
Чтение памяти, необходимо подзаряжать конденсаторы
Необходимость перезарядки конденсаторов (токи утечки)
tRP - время
Чтение памяти, необходимо подзаряжать конденсаторы
Необходимость перезарядки конденсаторов (токи утечки)
tRP - время
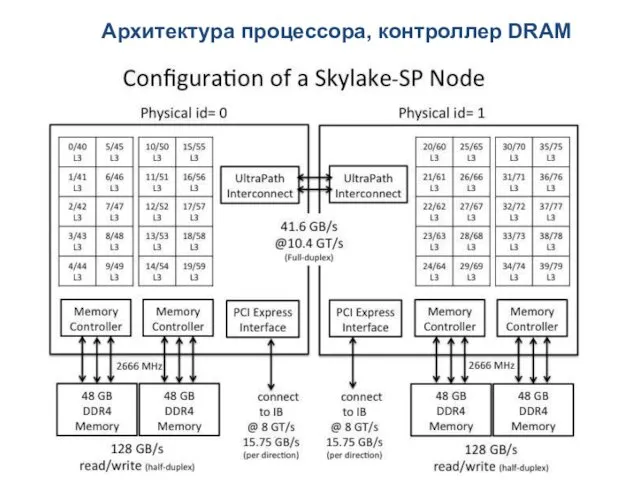
Архитектура процессора, контроллер DRAM
Архитектура процессора, контроллер DRAM
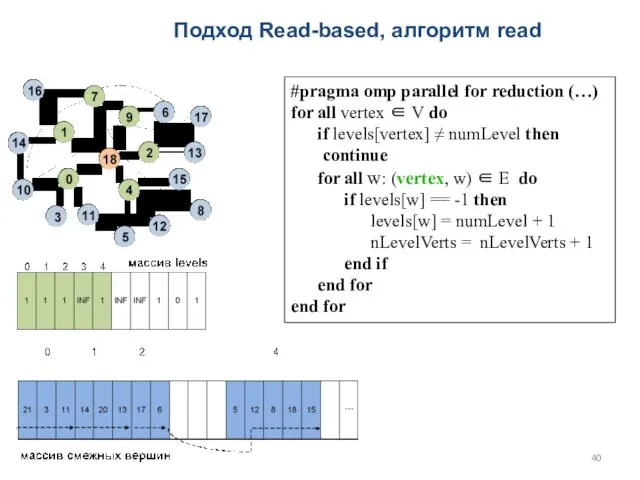
Подход Read-based, алгоритм read
#pragma omp parallel for reduction (…)
for all vertex
Подход Read-based, алгоритм read
#pragma omp parallel for reduction (…)
for all vertex
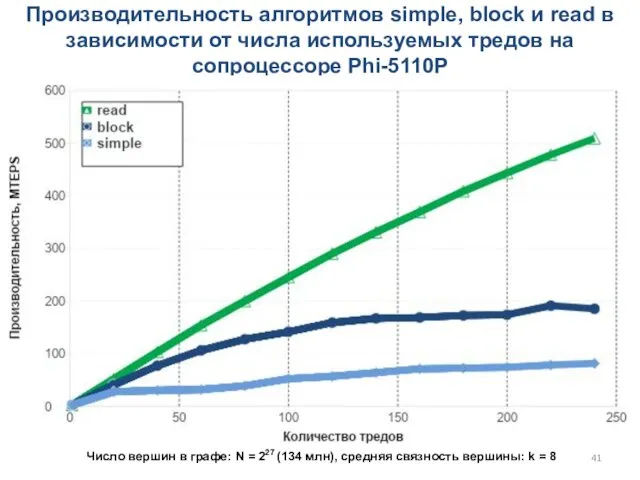
Производительность алгоритмов simple, block и read в зависимости от числа используемых
Производительность алгоритмов simple, block и read в зависимости от числа используемых
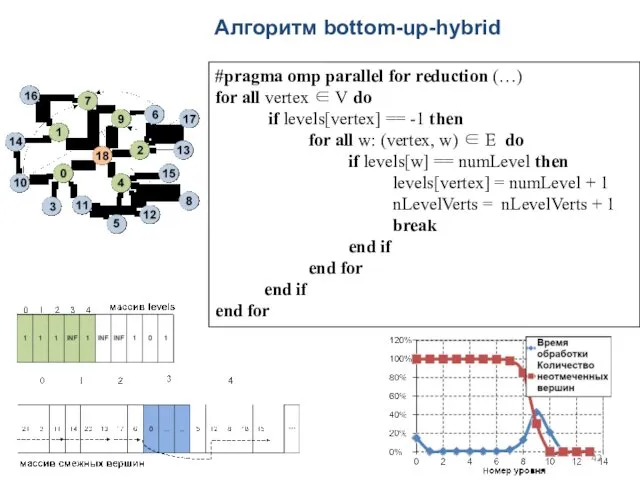
Алгоритм bottom-up-hybrid
#pragma omp parallel for reduction (…)
for all vertex ∈ V
Алгоритм bottom-up-hybrid
#pragma omp parallel for reduction (…)
for all vertex ∈ V
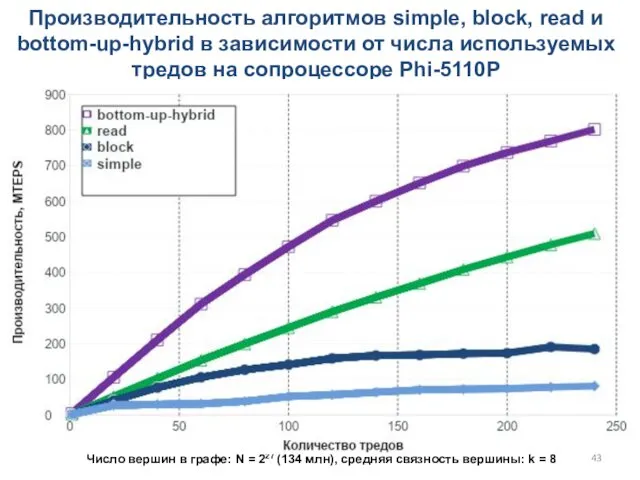
Производительность алгоритмов simple, block, read и bottom-up-hybrid в зависимости от числа
Производительность алгоритмов simple, block, read и bottom-up-hybrid в зависимости от числа
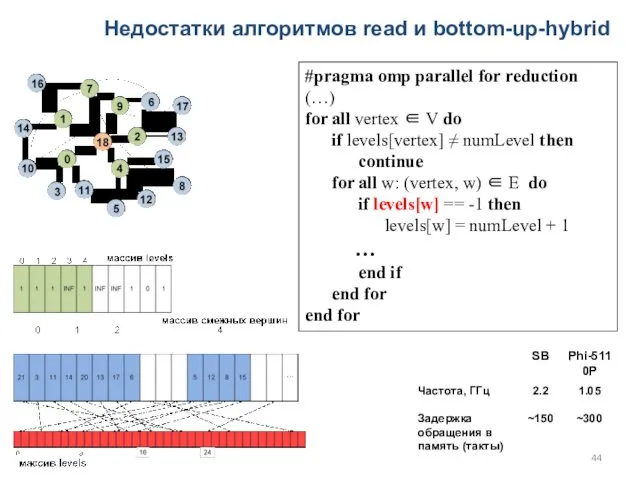
Недостатки алгоритмов read и bottom-up-hybrid
#pragma omp parallel for reduction (…)
for
Недостатки алгоритмов read и bottom-up-hybrid
#pragma omp parallel for reduction (…)
for
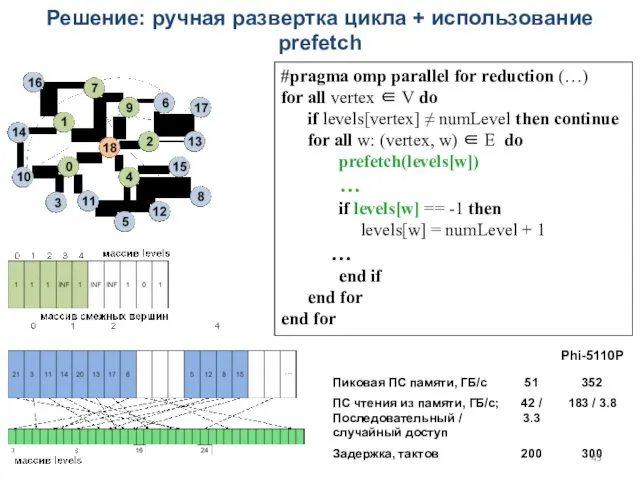
Решение: ручная развертка цикла + использование prefetch
#pragma omp parallel for reduction
Решение: ручная развертка цикла + использование prefetch
#pragma omp parallel for reduction
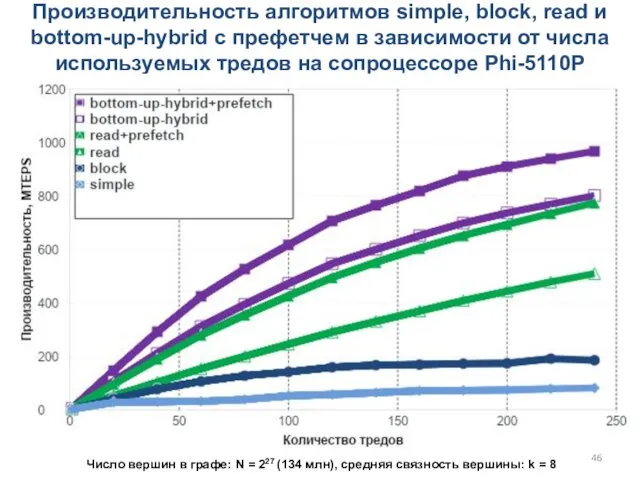
Производительность алгоритмов simple, block, read и bottom-up-hybrid с префетчем в зависимости
Производительность алгоритмов simple, block, read и bottom-up-hybrid с префетчем в зависимости
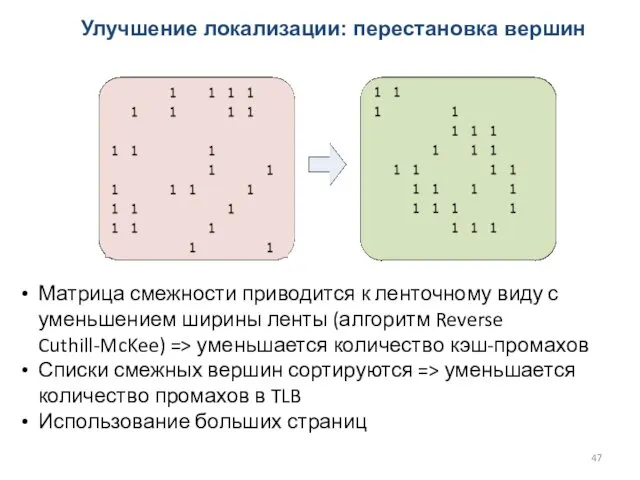
Улучшение локализации: перестановка вершин
Матрица смежности приводится к ленточному виду с уменьшением
Улучшение локализации: перестановка вершин
Матрица смежности приводится к ленточному виду с уменьшением
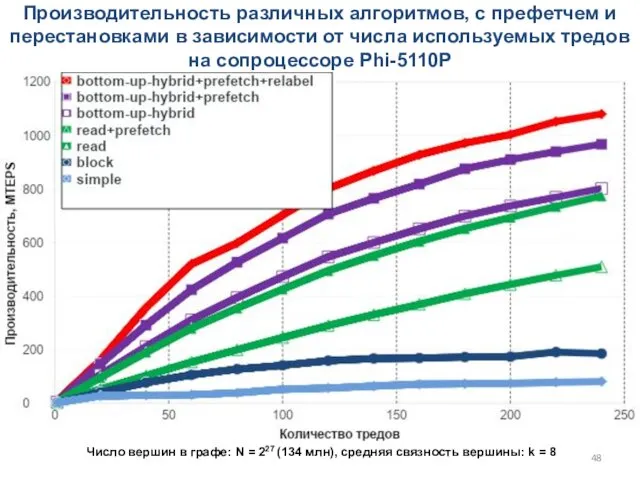
Производительность различных алгоритмов, с префетчем и перестановками в зависимости от числа
Производительность различных алгоритмов, с префетчем и перестановками в зависимости от числа
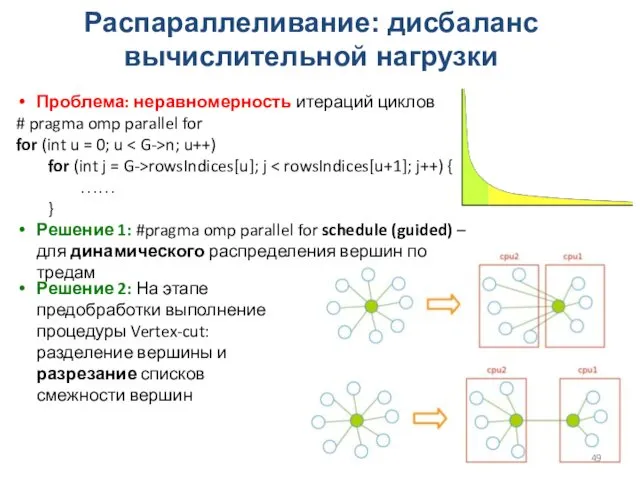
Распараллеливание: дисбаланс вычислительной нагрузки
Проблема: неравномерность итераций циклов
# pragma omp parallel for
for
Распараллеливание: дисбаланс вычислительной нагрузки
Проблема: неравномерность итераций циклов
# pragma omp parallel for
for

Проблема: постоянная смена данных в кэше, низкие характеристики при случайном доступе
Решения
Проблема: постоянная смена данных в кэше, низкие характеристики при случайном доступе
Решения

Резюме: проблемы и подходы к решению задач в рамках одного узла
Выбор
Резюме: проблемы и подходы к решению задач в рамках одного узла
Выбор

Проблемы и подходы к решению графовых задач на распределенной памяти
Проблемы и подходы к решению графовых задач на распределенной памяти
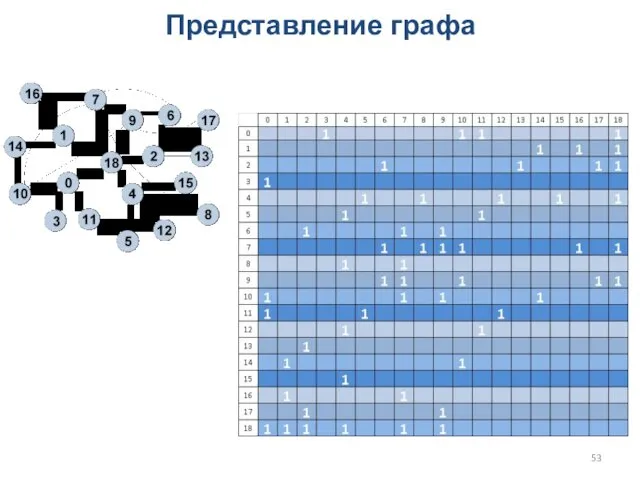
Представление графа
Представление графа
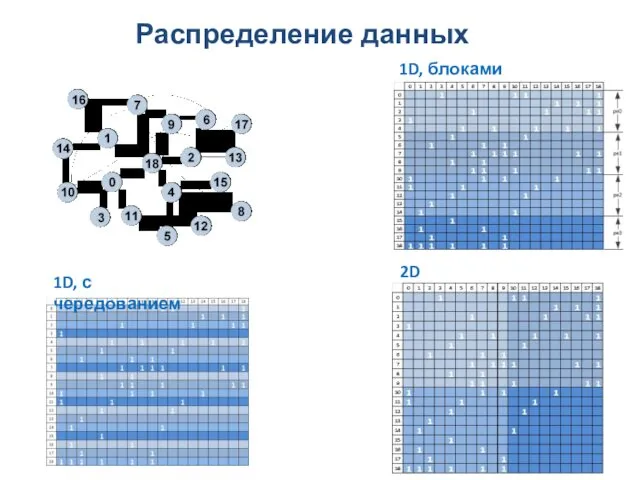
Распределение данных
1D, блоками
1D, с чередованием
2D
Распределение данных
1D, блоками
1D, с чередованием
2D
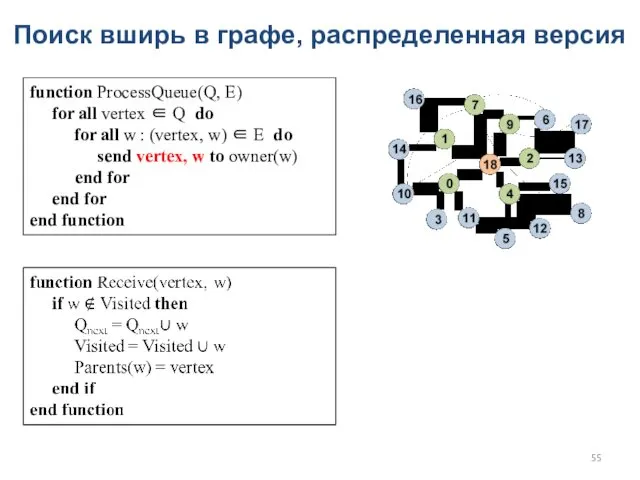
Поиск вширь в графе, распределенная версия
function ProcessQueue(Q, E)
for all vertex
Поиск вширь в графе, распределенная версия
function ProcessQueue(Q, E)
for all vertex
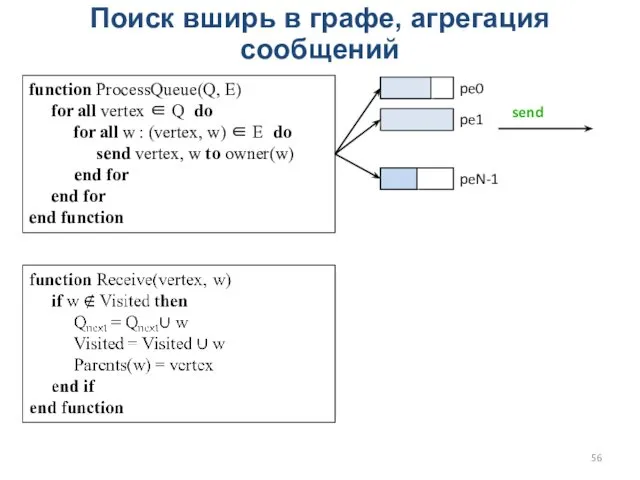
Поиск вширь в графе, агрегация сообщений
function ProcessQueue(Q, E)
for all vertex
Поиск вширь в графе, агрегация сообщений
function ProcessQueue(Q, E)
for all vertex
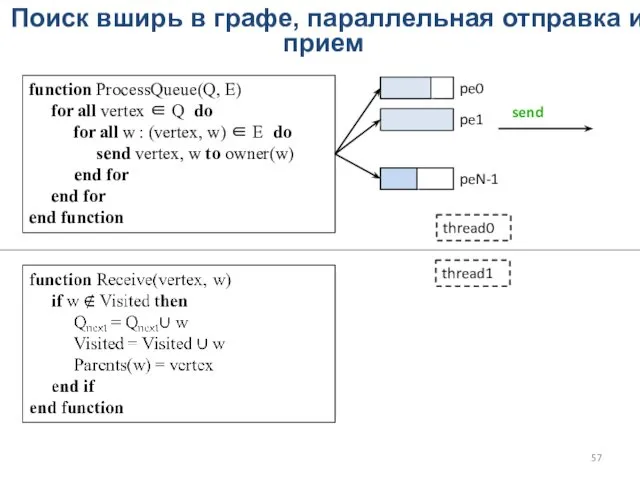
Поиск вширь в графе, параллельная отправка и прием
function ProcessQueue(Q, E)
for
Поиск вширь в графе, параллельная отправка и прием
function ProcessQueue(Q, E)
for
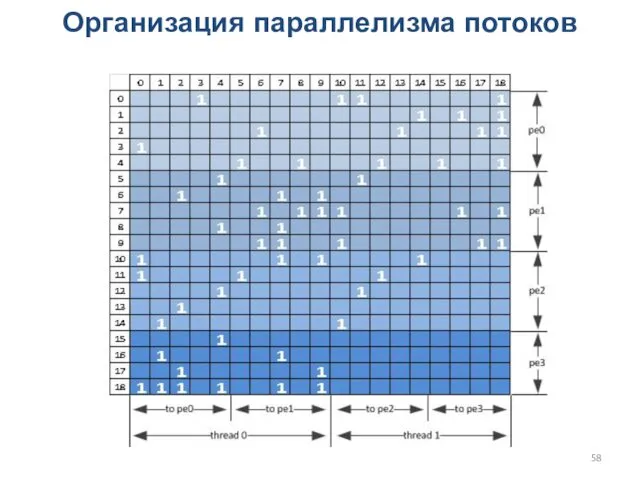
Организация параллелизма потоков
Организация параллелизма потоков
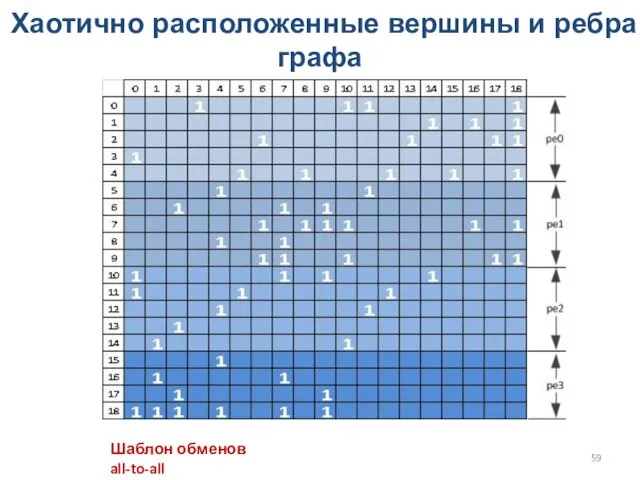
Хаотично расположенные вершины и ребра графа
Шаблон обменов all-to-all
Хаотично расположенные вершины и ребра графа
Шаблон обменов all-to-all
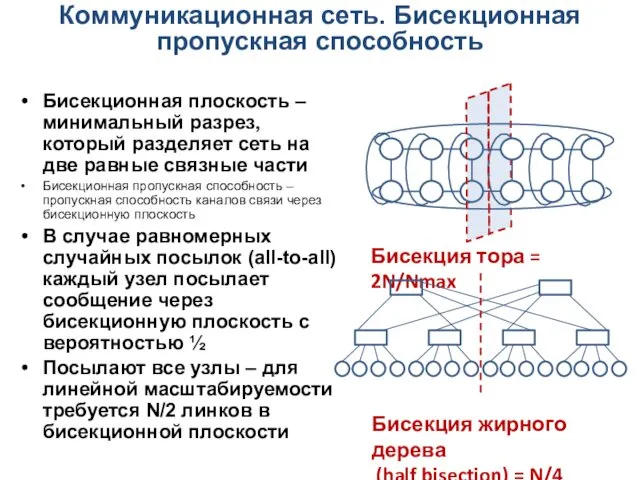
Коммуникационная сеть. Бисекционная пропускная способность
Бисекционная плоскость – минимальный разрез, который разделяет
Коммуникационная сеть. Бисекционная пропускная способность
Бисекционная плоскость – минимальный разрез, который разделяет
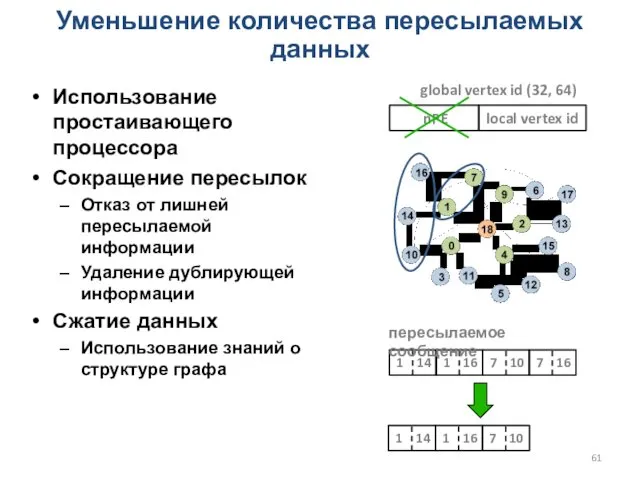
nPE
Уменьшение количества пересылаемых данных
Использование простаивающего процессора
Сокращение пересылок
Отказ от лишней пересылаемой
nPE
Уменьшение количества пересылаемых данных
Использование простаивающего процессора
Сокращение пересылок
Отказ от лишней пересылаемой
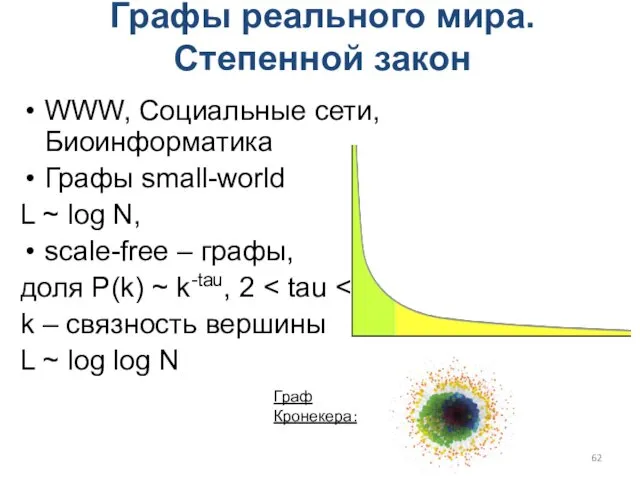
Графы реального мира. Степенной закон
WWW, Социальные сети, Биоинформатика
Графы small-world
L ~ log
Графы реального мира. Степенной закон
WWW, Социальные сети, Биоинформатика
Графы small-world
L ~ log
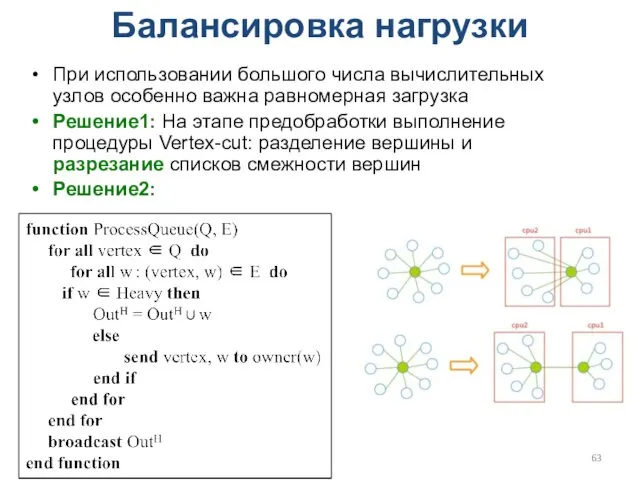
Балансировка нагрузки
При использовании большого числа вычислительных узлов особенно важна равномерная загрузка
Решение1:
Балансировка нагрузки
При использовании большого числа вычислительных узлов особенно важна равномерная загрузка
Решение1:
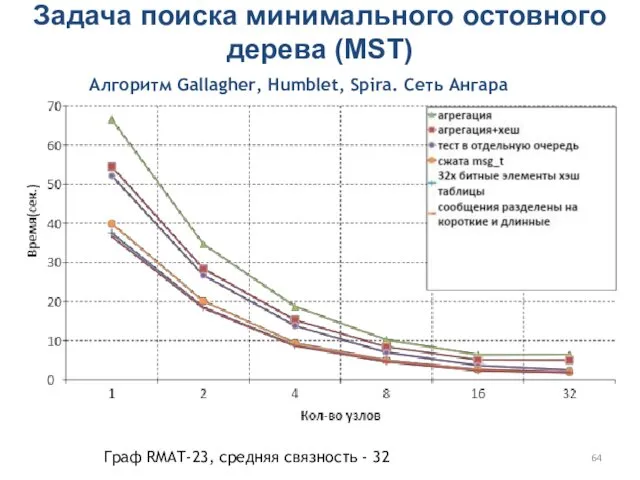
Задача поиска минимального остовного дерева (MST)
Алгоритм Gallagher, Humblet, Spira. Сеть Ангара
Граф
Задача поиска минимального остовного дерева (MST)
Алгоритм Gallagher, Humblet, Spira. Сеть Ангара
Граф

Проблемы и подходы к решению задач на
распределенной памяти
Выбор распределения данных
Агрегация сообщений
Организация
Проблемы и подходы к решению задач на
распределенной памяти
Выбор распределения данных
Агрегация сообщений
Организация
 День смеха
День смеха C_003_hello_world
C_003_hello_world Порядок проведения и организация работ зоны ТР на базе ремонтного предприятия
Порядок проведения и организация работ зоны ТР на базе ремонтного предприятия Тест № 1 Предложение. Русский язык 3 класс
Тест № 1 Предложение. Русский язык 3 класс Врангель Пётр Николаевич
Врангель Пётр Николаевич Пластиковая ферма
Пластиковая ферма Компьютерные игровые комплексы
Компьютерные игровые комплексы Автоматты басқару жүйелері туралы негізгі түсініктер және оларды құру принциптері
Автоматты басқару жүйелері туралы негізгі түсініктер және оларды құру принциптері Россия при первых Романовых. Укрепление самодержавия
Россия при первых Романовых. Укрепление самодержавия Проект к 105-летию со дня рождения русского писателя Н.НосоваНезнайка и его друзья.
Проект к 105-летию со дня рождения русского писателя Н.НосоваНезнайка и его друзья. Члены предложения как структурно-семантические компоненты предложения
Члены предложения как структурно-семантические компоненты предложения Презентация к классному часу, посвященному 70-летию Блокады Ленинграда Классный час: Блокада Ленинграда в Великой Отечественной войне
Презентация к классному часу, посвященному 70-летию Блокады Ленинграда Классный час: Блокада Ленинграда в Великой Отечественной войне Хлебобулочные изделия повышенной пищевой ценности
Хлебобулочные изделия повышенной пищевой ценности Психология младшего школьного возраста
Психология младшего школьного возраста Психологические механизмы профессиональных кризисов
Психологические механизмы профессиональных кризисов Первичный туберкулез
Первичный туберкулез Материалы для подготовки к ЕГЭ по биологии, схемы и таблицы
Материалы для подготовки к ЕГЭ по биологии, схемы и таблицы Общешкольное родительское собрание Права детей - ответственность родителей
Общешкольное родительское собрание Права детей - ответственность родителей Презентация Китайская роза
Презентация Китайская роза Логопедическое занятие (учитель-логопед Е.М. Попова) Дифференциация г-гь, к-кь
Логопедическое занятие (учитель-логопед Е.М. Попова) Дифференциация г-гь, к-кь Теплопотери через ограждающие конструкции
Теплопотери через ограждающие конструкции Горьковское отделение Российских железных дорог
Горьковское отделение Российских железных дорог презентация Домашние животные
презентация Домашние животные Автоматизированные Информационные Системы для государственных, муниципальных заказчиков и бизнеса
Автоматизированные Информационные Системы для государственных, муниципальных заказчиков и бизнеса Электроэнергетика
Электроэнергетика Выбор профессии, связанной с физикой
Выбор профессии, связанной с физикой ПРЕЗЕНТАЦИЯ ЗДРАВСТВУЙ, ПТИЧЬЯ СТРАНА!
ПРЕЗЕНТАЦИЯ ЗДРАВСТВУЙ, ПТИЧЬЯ СТРАНА! Обґрунтування проекту реконструкції водопровідних мереж села Абрикосівка Великокопанівської сільської ради
Обґрунтування проекту реконструкції водопровідних мереж села Абрикосівка Великокопанівської сільської ради