- Параллельное программирование. Модель данных в OpenMP

Содержание
- 2. Модель данных Модель данных в OpenMP предполагает наличие как общей для всех нитей области памяти, так
- 3. Пример 12 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 4. Результаты выполнения примера 12 n в последовательной области (начало): 1 Значение n на нити (на входе):
- 5. Пример 13 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 6. Статические и динамические переменные В языке Си статические (static) переменные, определённые в параллельной области программы, являются
- 7. Пример 14 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 8. Результат выполнения примера 14 Значение n в начале: 1 Значение n на нити (на входе): 1
- 9. Директива threadprivate Директива threadprivate указывает, что переменные из списка должны быть размножены с тем, чтобы каждая
- 10. Пример 15 #include "stdafx.h #include #include "windows.h" #include using namespace std; int n; #pragma omp threadprivate(n)
- 11. Результаты выполнения примера 15 Значение n на нити 0 (на входе): 1 Значение n на нити
- 12. Если необходимо переменную, объявленную как threadprivate, инициализировать значением размножаемой переменной из нити-мастера, то на входе в
- 13. Пример 16 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int n; #pragma omp threadprivate(n)
- 14. Результаты выполненимя примера 16 Значение n: 1 (нить 1) Значение n: 1 (нить 4) Значение n:
- 15. Распределение работы Низкоуровневое распараллеливание Параллельные циклы Параллельные секции Директива workshare Задачи (tasks)
- 16. Распределение работы OpenMP предлагает несколько вариантов распределения работы между запущенными нитями. Конструкции распределения работ в OpenMP
- 17. Пример 17 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 18. Использование omp_get_thread_num() и omp_get_num_threads() Использование функций omp_get_thread_num() и omp_get_num_threads() позволяет назначать каждой нити свой кусок кода
- 19. Параллельные циклы Если в параллельной области встретился оператор цикла, то, согласно общему правилу, он будет выполнен
- 20. Опции директивы for : private(список) – задаёт список переменных, для которых порождается локальная копия в каждой
- 21. Опции директивы for (продолжение): schedule(type[, chunk]) – опция задаёт, каким образом итерации цикла распределяются между нитями;
- 22. На вид параллельных циклов накладываются достаточно жёсткие ограничения. В частности, предполагается, что корректная программа не должна
- 23. #include "stdafx.h" #include #include "windows.h" #include using namespace std; #define N 15 int main(int argc, char
- 24. Результаты выполнения примера 18 Нить 0 сложила элементы с номером 0 Нить 0 сложила элементы с
- 25. Опция schedule В опции schedule параметр type задаёт следующий тип распределения итераций: • static – блочно-циклическое
- 26. Опция schedule (продолжение) guided – динамическое распределение итераций, при котором размер порции уменьшается с некоторого начального
- 27. Пример 19 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 28. Результаты выполнения примера 19 #pragma omp for schedule (static) Нить 0 выполнила итерацию 0 Нить 2
- 29. Результаты выполнения примера 19 #pragma omp for schedule (static, 1) Нить 0 выполнила итерацию 0 Нить
- 30. Результаты выполнения примера 19 #pragma omp for schedule (dynamic) Нить 0 выполнила итерацию 0 Нить 2
- 31. Результаты выполнения примера 19 #pragma omp for schedule (guided) Нить 0 выполнила итерацию 0 Нить 1
- 32. Результаты выполнения примера 19
- 33. Пример 20 #include "stdafx.h" #include #include #include using namespace std; int main(int argc, char *argv[]){ SetConsoleCP(1251);
- 34. Результаты выполнения примера 20
- 35. Переменная OMP_SCHEDULE Значение по умолчанию переменной OMP_SCHEDULE зависит от реализации. Если переменная задана неправильно, то поведение
- 36. Параллельные секции Директива sections используется для задания конечного (неитеративного) параллелизма: #pragma omp sections [опция [[,] опция]...]
- 37. Возможные опции: private(список) – задаёт список переменных, для которых порождается локальная копия в каждой нити; начальное
- 38. Пример 21 int main(int argc, char *argv[]){ SetConsoleCP(1251); SetConsoleOutputCP(1251); int n; #pragma omp parallel private(n) {
- 39. Результаты выполнения примера 21 Вторая секция, процесс 3 Первая секция, процесс 0 Третья секция, процесс 1
- 40. Пример 22 int main(int argc, char *argv[]){ SetConsoleCP(1251); SetConsoleOutputCP(1251); int n=0; #pragma omp parallel { #pragma
- 41. Результаты выполнения примера 22 Первая секция, нить 0: 1 Вторая секция, нить 1: 2 Третья секция,
- 42. Задачи (tasks) Директива task применяется для выделения отдельной независимой задачи: #pragma omp task [опция [[,] опция]...]
- 44. Скачать презентацию

Модель данных
Модель данных в OpenMP предполагает наличие как общей для всех
Модель данных
Модель данных в OpenMP предполагает наличие как общей для всех

Пример 12
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
int
Пример 12
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
int

Результаты выполнения примера 12
n в последовательной области (начало): 1
Значение n на
Результаты выполнения примера 12
n в последовательной области (начало): 1
Значение n на

Пример 13
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 13
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;

Статические и динамические переменные
В языке Си статические (static) переменные, определённые в
Статические и динамические переменные
В языке Си статические (static) переменные, определённые в

Пример 14
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace
Пример 14
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace

Результат выполнения примера 14
Значение n в начале: 1
Значение n на нити
Результат выполнения примера 14
Значение n в начале: 1
Значение n на нити

Директива threadprivate
Директива threadprivate указывает, что переменные из списка должны быть
Директива threadprivate
Директива threadprivate указывает, что переменные из списка должны быть

Пример 15
#include "stdafx.h
#include
#include "windows.h"
#include
using namespace std;
Пример 15
#include "stdafx.h
#include
#include "windows.h"
#include
using namespace std;

Результаты выполнения примера 15
Значение n на нити 0 (на входе): 1
Значение
Результаты выполнения примера 15
Значение n на нити 0 (на входе): 1
Значение

Если необходимо переменную, объявленную как threadprivate, инициализировать значением размножаемой переменной из
Если необходимо переменную, объявленную как threadprivate, инициализировать значением размножаемой переменной из

Пример 16
#include "stdafx.h"
#include
#include "windows.h"
#include
using
Пример 16
#include "stdafx.h"
#include
#include "windows.h"
#include
using

Результаты выполненимя примера 16
Значение n: 1 (нить 1)
Значение n: 1 (нить
Результаты выполненимя примера 16
Значение n: 1 (нить 1)
Значение n: 1 (нить

Распределение работы
Низкоуровневое распараллеливание
Параллельные циклы
Параллельные секции
Директива workshare
Задачи (tasks)
Распределение работы
Низкоуровневое распараллеливание
Параллельные циклы
Параллельные секции
Директива workshare
Задачи (tasks)

Распределение работы
OpenMP предлагает несколько вариантов распределения работы между запущенными нитями. Конструкции
Распределение работы
OpenMP предлагает несколько вариантов распределения работы между запущенными нитями. Конструкции

Пример 17
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 17
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;

Использование omp_get_thread_num() и omp_get_num_threads()
Использование функций omp_get_thread_num() и omp_get_num_threads() позволяет назначать каждой
Использование omp_get_thread_num() и omp_get_num_threads()
Использование функций omp_get_thread_num() и omp_get_num_threads() позволяет назначать каждой

Параллельные циклы
Если в параллельной области встретился оператор цикла, то, согласно общему
Параллельные циклы
Если в параллельной области встретился оператор цикла, то, согласно общему

Опции директивы for :
private(список) – задаёт список переменных, для которых порождается
Опции директивы for :
private(список) – задаёт список переменных, для которых порождается
![Опции директивы for (продолжение): schedule(type[, chunk]) – опция задаёт, каким](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/65965/slide-20.jpg)
Опции директивы for (продолжение):
schedule(type[, chunk]) – опция задаёт, каким образом итерации
Опции директивы for (продолжение):
schedule(type[, chunk]) – опция задаёт, каким образом итерации

На вид параллельных циклов накладываются достаточно жёсткие ограничения. В частности, предполагается,
На вид параллельных циклов накладываются достаточно жёсткие ограничения. В частности, предполагается,

#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
#define N 15
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
#define N 15
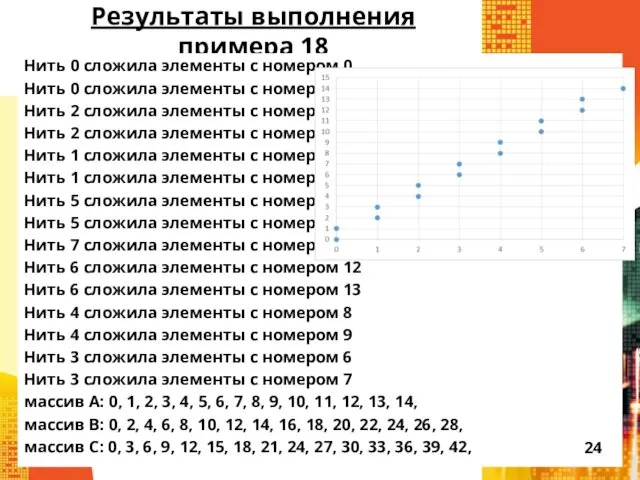
Результаты выполнения примера 18
Нить 0 сложила элементы с номером 0
Нить 0
Результаты выполнения примера 18
Нить 0 сложила элементы с номером 0
Нить 0

Опция schedule
В опции schedule параметр type задаёт следующий тип распределения
Опция schedule
В опции schedule параметр type задаёт следующий тип распределения

Опция schedule (продолжение)
guided – динамическое распределение итераций, при котором размер
Опция schedule (продолжение)
guided – динамическое распределение итераций, при котором размер

Пример 19
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
int
Пример 19
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
int

Результаты выполнения примера 19
#pragma omp for schedule (static)
Нить 0 выполнила итерацию
Результаты выполнения примера 19
#pragma omp for schedule (static)
Нить 0 выполнила итерацию

Результаты выполнения примера 19
#pragma omp for schedule (static, 1)
Нить 0
Результаты выполнения примера 19
#pragma omp for schedule (static, 1)
Нить 0

Результаты выполнения примера 19
#pragma omp for schedule (dynamic)
Нить 0 выполнила
Результаты выполнения примера 19
#pragma omp for schedule (dynamic)
Нить 0 выполнила

Результаты выполнения примера 19
#pragma omp for schedule (guided)
Нить 0 выполнила
Результаты выполнения примера 19
#pragma omp for schedule (guided)
Нить 0 выполнила
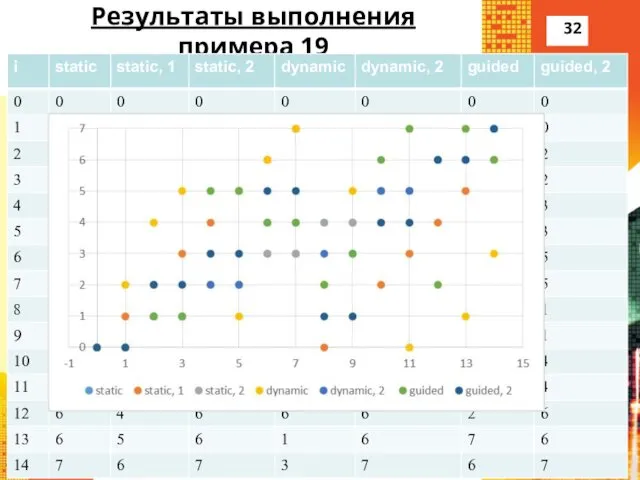
Результаты выполнения примера 19
Результаты выполнения примера 19

Пример 20
#include "stdafx.h"
#include
#include #include
using namespace std;
int
Пример 20
#include "stdafx.h"
#include
#include
using namespace std;
int

Результаты выполнения примера 20
Результаты выполнения примера 20

Переменная OMP_SCHEDULE
Значение по умолчанию переменной OMP_SCHEDULE зависит от реализации. Если переменная
Переменная OMP_SCHEDULE
Значение по умолчанию переменной OMP_SCHEDULE зависит от реализации. Если переменная

Параллельные секции
Директива sections используется для задания конечного (неитеративного) параллелизма:
#pragma omp
Параллельные секции
Директива sections используется для задания конечного (неитеративного) параллелизма:
#pragma omp

Возможные опции:
private(список) – задаёт список переменных, для которых порождается локальная
Возможные опции:
private(список) – задаёт список переменных, для которых порождается локальная
![Пример 21 int main(int argc, char *argv[]){ SetConsoleCP(1251); SetConsoleOutputCP(1251); int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/65965/slide-37.jpg)
Пример 21
int main(int argc, char *argv[]){
SetConsoleCP(1251); SetConsoleOutputCP(1251);
int n;
#pragma omp
Пример 21
int main(int argc, char *argv[]){
SetConsoleCP(1251); SetConsoleOutputCP(1251);
int n;
#pragma omp

Результаты выполнения примера 21
Вторая секция, процесс 3
Первая секция, процесс 0
Третья секция,
Результаты выполнения примера 21
Вторая секция, процесс 3
Первая секция, процесс 0
Третья секция,
![Пример 22 int main(int argc, char *argv[]){ SetConsoleCP(1251); SetConsoleOutputCP(1251); int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/65965/slide-39.jpg)
Пример 22
int main(int argc, char *argv[]){
SetConsoleCP(1251);
SetConsoleOutputCP(1251);
int n=0;
#pragma omp
Пример 22
int main(int argc, char *argv[]){
SetConsoleCP(1251);
SetConsoleOutputCP(1251);
int n=0;
#pragma omp

Результаты выполнения примера 22
Первая секция, нить 0: 1
Вторая секция, нить 1:
Результаты выполнения примера 22
Первая секция, нить 0: 1
Вторая секция, нить 1:

Задачи (tasks)
Директива task применяется для выделения отдельной независимой задачи:
#pragma
Задачи (tasks)
Директива task применяется для выделения отдельной независимой задачи:
#pragma
 Праздники народов России. 4 класс
Праздники народов России. 4 класс Александр Александрович Фадеев 1901 - 1956
Александр Александрович Фадеев 1901 - 1956 Школьный этикет. Правила поведения на уроке.
Школьный этикет. Правила поведения на уроке. Рождественская звезда . Рождение Иисуса
Рождественская звезда . Рождение Иисуса TCU (traffic control unit)
TCU (traffic control unit) Именные химические реакции в органической химии
Именные химические реакции в органической химии Применение материалов в кабельных изделиях
Применение материалов в кабельных изделиях Ярослав Гашек Камень жизни
Ярослав Гашек Камень жизни Научные принципы, параметры технологии и технологическое оборудование для прямой переработки кусковой сидеритовой руды в сталь
Научные принципы, параметры технологии и технологическое оборудование для прямой переработки кусковой сидеритовой руды в сталь Лексикалық қосымшалар тәсілі. Екінші тілдің тепе-тең бірліктерін іріктеп алу дағдысы
Лексикалық қосымшалар тәсілі. Екінші тілдің тепе-тең бірліктерін іріктеп алу дағдысы Экономика и экология
Экономика и экология Презентация Игровые технологии в детском саду Игровые технологии в ДОУ
Презентация Игровые технологии в детском саду Игровые технологии в ДОУ Кадры предприятия. (Тема 9)
Кадры предприятия. (Тема 9) Моральное стимулирование труда персонала
Моральное стимулирование труда персонала 20190306_larina_n.p
20190306_larina_n.p Характеристика элементов III A группы. Бор и алюминий
Характеристика элементов III A группы. Бор и алюминий Использование информационно-коммуникационной технологии Игры для Тигры для коррекции общего недоразвития речи в дошкольном возрасте.
Использование информационно-коммуникационной технологии Игры для Тигры для коррекции общего недоразвития речи в дошкольном возрасте. Данные в экономике, их визуализация и предварительная обработка. Визуализация качественных признаков в Microsoft Excel
Данные в экономике, их визуализация и предварительная обработка. Визуализация качественных признаков в Microsoft Excel Бихевиоризм
Бихевиоризм Презентация по ПДД
Презентация по ПДД Пробный ЕГЭ. Вариант 1
Пробный ЕГЭ. Вариант 1 Нуклеиновые кислоты
Нуклеиновые кислоты Презентация по химии Спирты 10 класс
Презентация по химии Спирты 10 класс Секреты ораторского искусства
Секреты ораторского искусства Оперативное управление коммутационными аппаратами
Оперативное управление коммутационными аппаратами Готов ли Ваш ребенок к школе?
Готов ли Ваш ребенок к школе? Внеурочная деятельность в младшей школе как важное условие реализации деятельности ФГОС нового поколения
Внеурочная деятельность в младшей школе как важное условие реализации деятельности ФГОС нового поколения  Расставание с прошлым, дорога в светлое будущее
Расставание с прошлым, дорога в светлое будущее