- Параллельные вычислительные системы

Содержание
- 2. Чарльз Бэббидж: первое упоминание о параллелизме " В случае выполнения серии идентичных вычислений, подобных операции умножения
- 3. Чарльз Бэббидж: вычислительная машина
- 4. Определение параллелизма А.С. Головкин Параллельная вычислительная система -вычислительная система, у которой имеется по меньшей мере более
- 5. Определение параллелизма П.М. Коуги Параллелизм - воспроизведение в нескольких копиях некоторой аппаратной структуры, что позволяет достигнуть
- 6. Определение параллелизма Хокни, Джессхоуп Параллелизм - способность к частичному совмещению или одновременному выполнению операций.
- 7. Развитие элементной базы и рост производительности параллельных вычислительных систем
- 8. Области применения параллельных вычислительных систем предсказания погоды, климата и глобальных изменений в атмосфере; науки о материалах;
- 9. Области применения параллельных вычислительных систем квантовая хромодинамика; астрономия; транспортные задачи; гидро- и газодинамика; управляемый термоядерный синтез;
- 10. Области применения параллельных вычислительных систем разведка недр; наука о мировом океане; распознавание и синтез речи; распознавание
- 11. Оценка производительности параллельных вычислительных систем Пиковая производительность - величина, равная произведению пиковой производительности одного процессора на
- 12. Параллельные вычислительные системы Классификация
- 13. Классификация Флинна Основана на том, как в машине увязываются команды с обрабатываемыми данными. Поток - последовательность
- 14. Классификация Флинна ОКОД (SISD) один поток команд, много потоков данных МКОД (MISD) много потоков команд, один
- 15. МКОД – Конвейерные ПВС ВМ1 D’ I 1 D D” I 2 R I n
- 16. ОКМД – Процессорные матрицы ВМ1 D2 D1 Dn I . . .
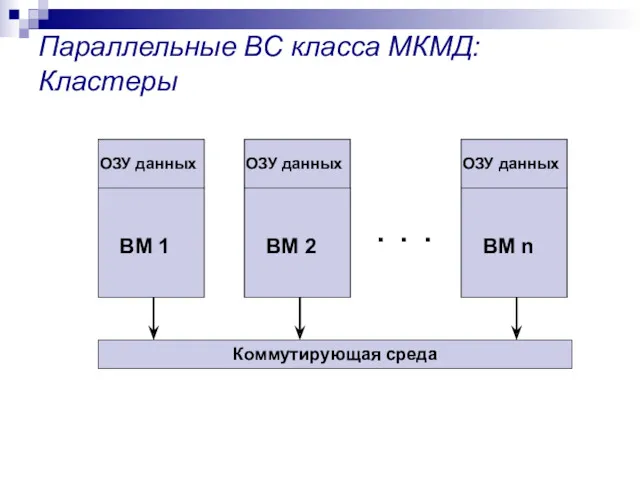
- 17. Классификация Флинна - МКМД SMP – симметричные мультипроцессорные системы Кластерные вычислительные системы Специализированные кластеры Кластеры общего
- 18. Симметричные мультипроцессоры (SMP) - состоят из совокупности процессоров, обладающих одинаковыми возможностями доступа к памяти и внешним
- 19. SMP - симметричные мультипроцессорные системы Коммутирующая среда ОЗУ данных . . . . . .
- 20. Кластеры Кластерная система – параллельная вычислительная система, создаваемая из модулей высокой степени готовности, объединенных стандартной системой
- 21. Массивно-параллельная система МРР Массивно-параллельная система – высокопроизводительная параллельная вычислительная система, создаваемая с использованием специализированных вычислительных модулей
- 22. Кластеры и массивно-параллельные системы (MPP)
- 23. Параллельные вычислительные системы Конвейерные ВС
- 24. Конвейерные ВС Конвейеризация - метод проектирования, в результате применения которого в вычислительной системе обеспечивается совмещение различных
- 25. Конвейерные ВС – Условия конвейеризации вычисление базовой функции эквивалентно вычислению некоторой последовательности подфункций; величины, являющиеся входными
- 26. Конвейерные ВС – Условия конвейеризации каждая подфункция может быть выполнена аппаратными блоками; времена, необходимые для реализации
- 27. Конвейерные ВС - Архитектура ВМ1 D’ I 1 D D” I 2 R I n
- 28. Конвейерные ВС - Классификация Конвейер Однофункциональный Многофункциональный Статический Динамический Синхронный Асинхронный
- 29. Конвейерные ВС – Таблица занятости
- 30. Конвейерные ВС – Задача управления обеспечение входного потока данных (заполнение конвейера) задача диспетчеризации - определение моментов
- 31. Конвейерные ВС – Проблемы управления разный период времени обработки данных на разных ступенях; обратная связь от
- 32. Конвейерные ВС – Стратегия управления Стратегия управления - процедура, которая выбирает последовательность латентностей. Жадная стратегия -
- 33. Конвейерные ВС – Векторно-конвейерные процессоры Вектор - набор данных, которые должны быть обработаны по одному алгоритму.
- 34. Векторно-конвейерные процессоры - Типичная архитектура
- 35. Векторно-конвейерные процессоры - Cray - 1 Компания Cray Research в 1976г. выпускает первый векторно-конвейерный компьютер CRAY-1:
- 36. Развитие векторных процессоров - Параллельно-векторные процессоры (PVP) Архитектура. PVP-системы строятся из векторно-конвейерных процессоров, в которых предусмотрены
- 37. Развитие векторных процессоров - Параллельно-векторные процессоры (PVP) Примеры. NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1,
- 38. Параллельные вычислительные системы Конвейеризация однопроцессорных ЭВМ
- 39. Конвейеризация однопроцессорных ЭВМ Конвейеризация - метод проектирования, в результате применения которого в вычислительной системе обеспечивается совмещение
- 40. Конвейеризация однопроцессорных ЭВМ БЭСМ-6
- 41. Конвейеризация однопроцессорных ЭВМ. Первый этап – предварительная выборка Предварительная (опережающая) выборка команд - выборка следующей команды
- 42. Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
- 43. Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
- 44. Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП. При проектировании конвейера для процессора машины с архитектурой
- 45. Конвейеризация однопроцессорных ЭВМ. Помехи. Помеха возникает, когда к одному элементу данных (ячейке памяти, регистру, разряду слова
- 46. Конвейеризация однопроцессорных ЭВМ. Помехи. Три класса помех: чтение после записи (RAW); запись после чтения (WAR); запись
- 47. Конвейеризация однопроцессорных ЭВМ. КЭШ-память. Введение в систему кэш-памяти можно рассматривать, как еще один вариант конвейеризации с
- 48. Параллельные вычислительные системы Класс ОКМД
- 49. Параллельные ВС класса ОКМД Один поток команд – много потоков данных, ОКМД (single instruction – multiple
- 50. Параллельные ВС класса ОКМД
- 51. ОКМД – Процессорная матрица Процессорная матрица - группа одинаковых процессорных элементов, объединенных единой коммутационной сетью, как
- 52. ОКМД – Процессорная матрица ILLIAC - IV
- 53. ОКМД – Процессорная матрица ПС - 2000
- 54. ОКМД – Однородная вычислительная среда Однородная вычислительная среда - регулярная решетка из однотипных процессорных элементов (ПЭ).
- 55. ОКМД – Однородная вычислительная среда Систолическая матрица - реализация однородной вычислительной среды на СБИС. Систолическая матрица
- 56. Архитектура ассоциативной ВС
- 57. Архитектура ассоциативной ВС Шина процессора
- 58. Полностью ассоциативная КЭШ-память
- 59. Параллельные вычислительные системы Класс МКМД (MIMD) Мультипроцессоры
- 60. Параллельные ВС класса МКМД Один из основных недостатков систематики Флинна - излишняя широта класса МКМД. Практически
- 61. Параллельные ВС класса МКМД (MIMD)
- 62. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP SMP (Symmetric MultiProcessing) – симметричная многопроцессорная архитектура. Главной
- 63. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP
- 64. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP Примеры. HP 9000 V-class, N-class; SMP-cервера и рабочие
- 65. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP Операционная система. Система работает под управлением единой ОС
- 66. МКМД – Мультипроцессоры с распределенной памятью (NUMA) Cache-Only Memory Architecture, COMA - для представления данных используется
- 67. Мультипроцессоры с распределенной памятью (NUMA) – схема «Бабочка»
- 68. Параллельные вычислительные системы Класс МКМД (MIMD) Мультипроцессоры
- 69. Параллельные ВС класса МКМД Один из основных недостатков систематики Флинна - излишняя широта класса МКМД. Практически
- 70. Параллельные ВС класса МКМД (MIMD)
- 71. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP SMP (Symmetric MultiProcessing) – симметричная многопроцессорная архитектура. Главной
- 72. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP
- 73. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP Примеры. HP 9000 V-class, N-class; SMP-cервера и рабочие
- 74. Параллельные ВС класса МКМД Симметричные мультипроцессоры - SMP Операционная система. Система работает под управлением единой ОС
- 75. МКМД – Мультипроцессоры с распределенной памятью (NUMA) Cache-Only Memory Architecture, COMA - для представления данных используется
- 76. Мультипроцессоры с распределенной памятью (NUMA) – схема «Бабочка»
- 77. Параллельные вычислительные системы СуперЭВМ
- 78. СуперЭВМ Впервые термин суперЭВМ был использован в начале 60-х годов, когда группа специалистов Иллинойского университета (США)
- 79. Суперкомпьютер – это … Компьютер с производительностью свыше 10 000 млн. теоретических операций в сек. Компьютер
- 80. Суперкомпьютеры 29-я редакция Top500 от 27.06.2007 1 - прототип будущего суперкомпьютера IBM BlueGene/L с производительностью на
- 81. Суперкомпьютер Blue Gene
- 82. Суперкомпьютер Blue Gene Архитектура
- 83. Суперкомпьютер Blue Gene Архитектура
- 84. Суперкомпьютер Blue Gene Базовый компонент (карта)
- 85. Параллельные вычислительные системы Элементная база Микропроцессоры
- 86. Элементная база параллельных ВС Микропроцессоры Основные требования к микропроцессорам, используемым в параллельных ВС: высокая производительность развитые
- 87. Элементная база параллельных ВС Микропроцессор AMD Opteron
- 88. Микропроцессор AMD Opteron Варианты объединения – 2 процессора
- 89. Микропроцессор AMD Opteron Варианты объединения – 4 процессора
- 90. Микропроцессор AMD Opteron Варианты объединения – 8 процессоров
- 91. Элементная база параллельных ВС Микропроцессор AMD Opteron 10 сентября 2007 года Компания AMD представила процессор Quad-Core
- 92. Элементная база параллельных ВС Микропроцессор IBM Power4
- 93. Микропроцессор IBM Power4 Многокристальный модуль – 4 процессора
- 94. Микропроцессор IBM Power4 Объединение многокристальных модулей
- 95. Элементная база параллельных ВС Микропроцессор Intel Core2 Duo
- 96. Параллельные вычислительные системы Элементная база. Коммутаторы и топология
- 97. Коммутирующие среды параллельных ВС Простые коммутаторы Типы простых коммутаторов: с временным разделением; с пространственным разделением.
- 98. Простые коммутаторы с временным разделением - шины
- 99. Простые коммутаторы с пространственным разделением Мультиплексор 1 Мультиплексор 2 Мультиплексор n Вход 1 Вход 2 Вход
- 100. Составные коммутаторы Коммутатор Клоза
- 101. Топологии параллельной ВС
- 102. Топологии параллельных ВС Convex Exemplar SPP1000
- 103. Топологии параллельных ВС Модуль МВС-100
- 104. Топологии параллельных ВС - МВС-100 Варианты соединения модулей
- 105. Параллельные вычислительные системы Элементная база. Коммутирующие среды
- 106. Коммутирующие среды параллельных ВС Myrinet Достоинства Myrinet: широкое распространение и высокая надежность; небольшое время задержки; хорошее
- 107. Коммутирующие среды параллельных ВС Myrinet Недостатки Myrinet: нестандартное решение, поддерживаемое всего одним производителем; ограниченная пропускная способность
- 108. Коммутирующие среды параллельных ВС Infiniband Достоинства Infiniband: стандарт Infiniband Trade Assotiation (IBTA); несколько производителей; небольшое время
- 109. Коммутирующие среды параллельных ВС Infiniband Недостатки Infiniband: сложность изменения физической и логической структуры; необходимость применения дополнительного
- 110. Коммутирующие среды параллельных ВС Ethernet Достоинства Ethernet: наличие развитого инструментария для управления и отладки; простая и
- 111. Коммутирующие среды параллельных ВС Ethernet Недостатки Ethernet: наличие задержки (сокращение времени задержки за счет применения TOE
- 112. Параллельные вычислительные системы Технологии GRID
- 113. Параллельные ВС GRID Технология GRID подразумевает слаженное взаимодействие множества ресурсов, гетерогенных по своей природе и расположенных
- 114. Параллельные ВС GRID
- 115. Параллельные ВС GRID – предпосылки возникновения Необходимость в концентрации огромного количества данных, хранящихся в разных организациях
- 116. Параллельные ВС GRID – предпосылки возникновения “Вероятно, мы скоро увидим распространение “компьютерных коммунальных услуг”, которые, подобно
- 117. Параллельные ВС Метакомпьютинг и GRID Метакомпьютинг - особый тип распределенного компьютинга, подразумевающего соединение суперкомпьютерных центров высокоскоростными
- 118. Параллельные ВС Свойства GRID масштабы вычислительного ресурса многократно превосходят ресурсы отдельного компьютера (вычислительного комплекса) гетерогенность среды
- 119. Параллельные ВС Области применения GRID массовая обработка потоков данных большого объема; многопараметрический анализ данных; моделирование на
- 120. Параллельные ВС Архитектура GRID – модель «песочных часов»
- 121. Параллельные ВС Архитектура протоколов GRID Архитектура протоколов GRID Архитектура протоколов Internet
- 122. Параллельные вычислительные системы Прикладное программное обеспечение
- 123. Параллельные ВС Прикладное программное обеспечение Проблемы разработки параллельного ПО проблема распараллеливания проблема отладки и верификации проблема
- 124. Параллельные ВС Прикладное ПО – закон Амдала S – ускорение программы по сравнению с последовательным выполнением
- 125. Параллельные ВС Прикладное ПО – подходы к созданию Написание параллельной программы «с нуля» Распараллеливание (автоматическое) существующих
- 126. Параллельные ВС Прикладное ПО – подходы к созданию Написание параллельной программы «с нуля» Достоинства: Возможность получения
- 127. Параллельные ВС Прикладное ПО – подходы к созданию Автоматическое распараллеливание последовательной программы Достоинства: Использование наработанного (последовательного)
- 128. Параллельные ВС Прикладное ПО – подходы к созданию Смешанный подход – автоматическое распараллеливание с последующей оптимизацией
- 129. Параллельные вычислительные системы Программирование параллельных ВС с разделяемой памятью
- 130. Параллельные ВС класса МКМД Системы с разделяемой памятью
- 131. Программирование параллельных ВС Системы с разделяемой памятью Программирование систем с разделяемой памятью осуществляется согласно модели обмена
- 132. Программирование параллельных ВС OpenMP – структура программы
- 133. Программирование параллельных ВС OpenMP – структура программы Основная нить и только она исполняет все последовательные области
- 134. Программирование параллельных ВС OpenMP – переменные В параллельной области все переменные программы разделяются общие (SHARED) и
- 135. Параллельные вычислительные системы Программирование кластерных и MPP параллельных ВС
- 136. Параллельные ВС класса МКМД Кластерные и массивно-параллельные ВС
- 137. Программирование параллельных ВС Кластеры и MPP Программирование кластерных и MPP параллельных ВС осуществляется в рамках модели
- 138. Программирование параллельных ВС MPI При запуске MPI-программы создается несколько ветвей; Все ветви программы запускаются загрузчиком одновременно
- 139. Программирование параллельных ВС MPI Библиотека MPI состоит примерно из 130 функций, в число которых входят: функции
- 140. Программирование параллельных ВС MPI Библиотека MPI состоит примерно из 130 функций, в число которых входят: функции
- 141. MPI - Функции инициализации и завершения int MPI_Init( int* argc, char*** argv) Инициализация параллельной части приложения.
- 142. MPI – информационные функции int MPI_Comm_size(MPI_Comm comm, int* size) Определение общего числа параллельных процессов в группе
- 143. MPI –функции обмена «точка-точка» int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int msgtag, MPI_Comm
- 144. MPI –функции обмена «точка-точка» int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int msgtag, MPI_comm
- 145. MPI – аргументы – «джокеры» функций обмена «точка-точка» MPI_ANY_SOURCE – заменяет аргумент «номер передающего процесса»; признак
- 146. Параллельные вычислительные системы Программирование кластерных и MPP параллельных ВС
- 147. Параллельные ВС класса МКМД Кластерные и массивно-параллельные ВС
- 148. Программирование параллельных ВС MPI Библиотека MPI состоит примерно из 130 функций, в число которых входят: функции
- 149. Программирование параллельных ВС MPI Библиотека MPI состоит примерно из 130 функций, в число которых входят: функции
- 150. MPI – коллективные функции Под термином "коллективные" в MPI подразумеваются три группы функций: функции коллективного обмена
- 151. MPI – коллективные функции int MPI_Barrier( MPI_Comm comm ); Останавливает выполнение вызвавшей ее задачи до тех
- 152. MPI –функции коллективного обмена Основные особенности и отличия от коммуникаций типа "точка-точка": на прием и/или передачу
- 153. MPI –функции коллективного обмена int MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int source, MPI_Comm comm) Рассылка
- 154. MPI –функции коллективного обмена MPI_Gather ("совок") собирает в приемный буфер задачи root передающие буфера остальных задач.
- 155. Параллельные вычислительные системы Проектирование кластера
- 156. Параллельные ВС класса МКМД: Кластеры
- 157. Параллельные ВС класса МКМД Кластеры Архитектура. Набор элементов высокой степени готовности, рабочих станций или ПК общего
- 158. Параллельные ВС класса МКМД Кластеры При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят
- 159. Параллельные ВС класса МКМД Кластеры Операционная система - стандартные ОС - Linux/FreeBSD, вместе со средствами поддержки
- 160. Кластеры высокой надежности в случае сбоя ПО на одном из узлов приложение продолжает функционировать или автоматически
- 161. Кластеры высокой надежности VAX/VMS кластер
- 162. Кластеры высокой надежности Switchover/UX компании Hewlett Packard
- 163. Высокопроизводительные кластеры Высокопроизводительный кластер - параллельная вычислительная система с распределенной памятью; построенная из компонент общего назначения;
- 164. Высокопроизводительные кластеры
- 165. Характеристики коммутирующих сред
- 166. Кластеры на основе локальной сети (Cluster Of Workstations – COW)
- 167. Параллельные вычислительные системы Системное ПО кластера
- 168. Кластеры - Системное ПО Windows Compute Cluster Server 2003 Упрощенная настройка параметров безопасности и проверки подлинности
- 169. Кластеры - Системное ПО Solaris (Sun Microsystems) Коммерческая верся UNIX. поддержка до 1 млн. одновременно работающих
- 170. Кластеры - Системное ПО HP-UX (Hewlett-Packard) Потомок AT&T System V. поддерживает до 256 процессоров; поддерживает кластеры
- 171. Параллельные вычислительные системы Кластер на основе локальной сети
- 172. Параллельные ВС класса МКМД: Кластеры
- 173. Кластеры на основе локальной (корпоративной) сети При объединении в кластер компьютеров разной мощности или разной архитектуры,
- 174. Операционная система - стандартные ОС - вместе со средствами поддержки параллельного программирования и распределения нагрузки. Модель
- 175. Кластер COW
- 177. Скачать презентацию

Чарльз Бэббидж:
первое упоминание о параллелизме
" В случае выполнения серии идентичных
Чарльз Бэббидж:
первое упоминание о параллелизме
" В случае выполнения серии идентичных

Чарльз Бэббидж:
вычислительная машина
Чарльз Бэббидж:
вычислительная машина

Определение параллелизма
А.С. Головкин
Параллельная вычислительная система -вычислительная система, у которой имеется
Определение параллелизма
А.С. Головкин
Параллельная вычислительная система -вычислительная система, у которой имеется

Определение параллелизма
П.М. Коуги
Параллелизм - воспроизведение в нескольких копиях некоторой аппаратной структуры,
Определение параллелизма
П.М. Коуги
Параллелизм - воспроизведение в нескольких копиях некоторой аппаратной структуры,

Определение параллелизма
Хокни, Джессхоуп
Параллелизм - способность к частичному совмещению или одновременному выполнению
Определение параллелизма
Хокни, Джессхоуп
Параллелизм - способность к частичному совмещению или одновременному выполнению
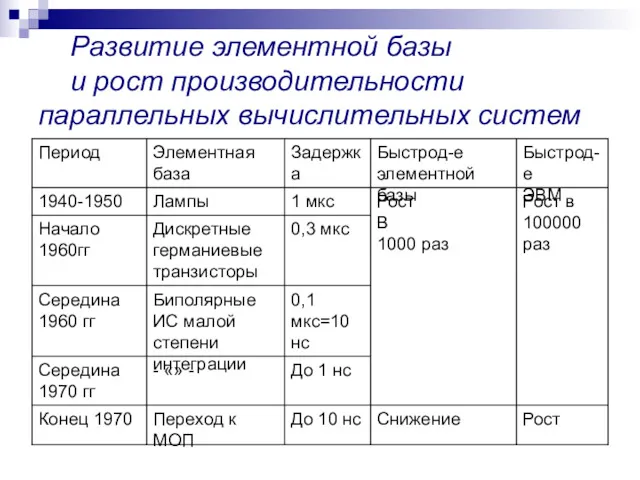
Развитие элементной базы
и рост производительности параллельных вычислительных систем
Развитие элементной базы
и рост производительности параллельных вычислительных систем

Области применения
параллельных вычислительных систем
предсказания погоды, климата и глобальных изменений в
Области применения
параллельных вычислительных систем
предсказания погоды, климата и глобальных изменений в

Области применения
параллельных вычислительных систем
квантовая хромодинамика;
астрономия;
транспортные задачи;
гидро- и
Области применения
параллельных вычислительных систем
квантовая хромодинамика;
астрономия;
транспортные задачи;
гидро- и

Области применения
параллельных вычислительных систем
разведка недр;
наука о мировом океане;
распознавание
Области применения
параллельных вычислительных систем
разведка недр;
наука о мировом океане;
распознавание

Оценка производительности параллельных вычислительных систем
Пиковая производительность - величина, равная произведению пиковой
Оценка производительности параллельных вычислительных систем
Пиковая производительность - величина, равная произведению пиковой

Параллельные вычислительные системы
Классификация
Параллельные вычислительные системы
Классификация

Классификация Флинна
Основана на том, как в машине увязываются команды с обрабатываемыми
Классификация Флинна
Основана на том, как в машине увязываются команды с обрабатываемыми

Классификация Флинна
ОКОД (SISD)
один поток команд, много потоков данных
МКОД (MISD)
много
Классификация Флинна
ОКОД (SISD)
один поток команд, много потоков данных
МКОД (MISD)
много
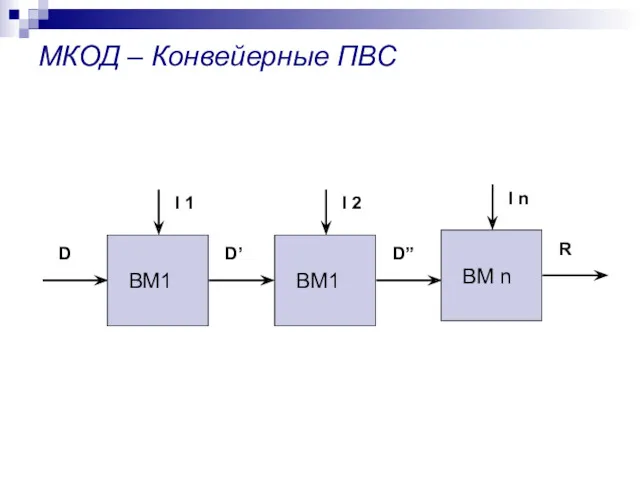
МКОД – Конвейерные ПВС
ВМ1
D’
I 1
D
D”
I 2
R
I n
МКОД – Конвейерные ПВС
ВМ1
D’
I 1
D
D”
I 2
R
I n
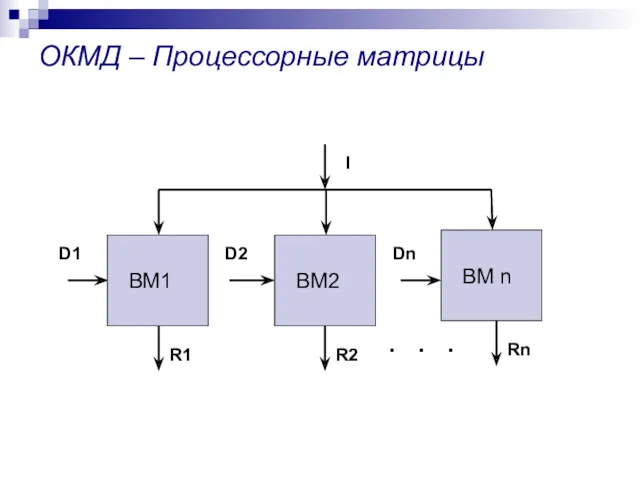
ОКМД – Процессорные матрицы
ВМ1
D2
D1
Dn
I
. . .
ОКМД – Процессорные матрицы
ВМ1
D2
D1
Dn
I
. . .

Классификация Флинна - МКМД
SMP –
симметричные мультипроцессорные системы
Кластерные вычислительные системы
Специализированные кластеры
Кластеры
Классификация Флинна - МКМД
SMP –
симметричные мультипроцессорные системы
Кластерные вычислительные системы
Специализированные кластеры
Кластеры

Симметричные мультипроцессоры (SMP) - состоят из совокупности процессоров, обладающих одинаковыми возможностями
Симметричные мультипроцессоры (SMP) - состоят из совокупности процессоров, обладающих одинаковыми возможностями
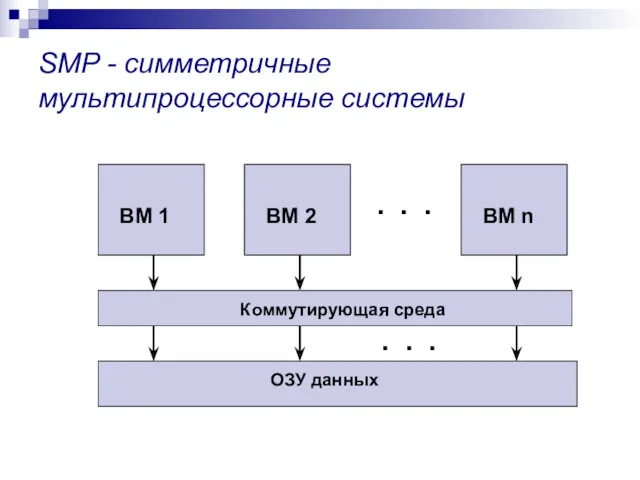
SMP - симметричные мультипроцессорные системы
Коммутирующая среда
ОЗУ данных
. . .
. . .
SMP - симметричные мультипроцессорные системы
Коммутирующая среда
ОЗУ данных
. . .
. . .

Кластеры
Кластерная система – параллельная вычислительная система, создаваемая из модулей высокой степени
Кластеры
Кластерная система – параллельная вычислительная система, создаваемая из модулей высокой степени

Массивно-параллельная система
МРР
Массивно-параллельная система – высокопроизводительная параллельная вычислительная система, создаваемая с
Массивно-параллельная система
МРР
Массивно-параллельная система – высокопроизводительная параллельная вычислительная система, создаваемая с
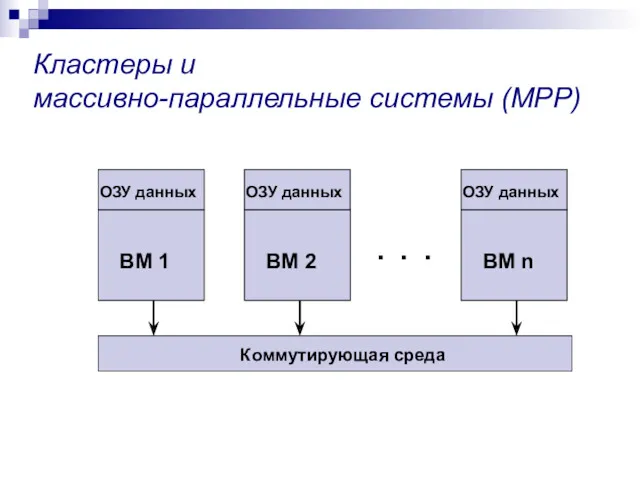
Кластеры и
массивно-параллельные системы (MPP)
Кластеры и
массивно-параллельные системы (MPP)

Параллельные вычислительные системы
Конвейерные ВС
Параллельные вычислительные системы
Конвейерные ВС

Конвейерные ВС
Конвейеризация - метод проектирования, в результате применения которого в вычислительной
Конвейерные ВС
Конвейеризация - метод проектирования, в результате применения которого в вычислительной

Конвейерные ВС – Условия конвейеризации
вычисление базовой функции эквивалентно вычислению некоторой последовательности
Конвейерные ВС – Условия конвейеризации
вычисление базовой функции эквивалентно вычислению некоторой последовательности

Конвейерные ВС – Условия конвейеризации
каждая подфункция может быть выполнена аппаратными блоками;
времена,
Конвейерные ВС – Условия конвейеризации
каждая подфункция может быть выполнена аппаратными блоками;
времена,
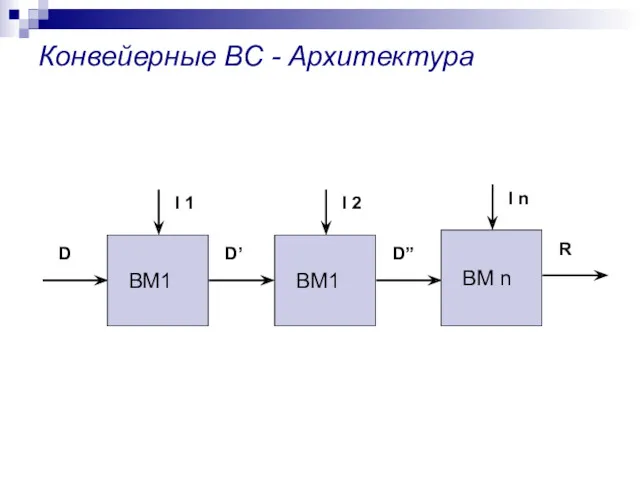
Конвейерные ВС - Архитектура
ВМ1
D’
I 1
D
D”
I 2
R
I n
Конвейерные ВС - Архитектура
ВМ1
D’
I 1
D
D”
I 2
R
I n
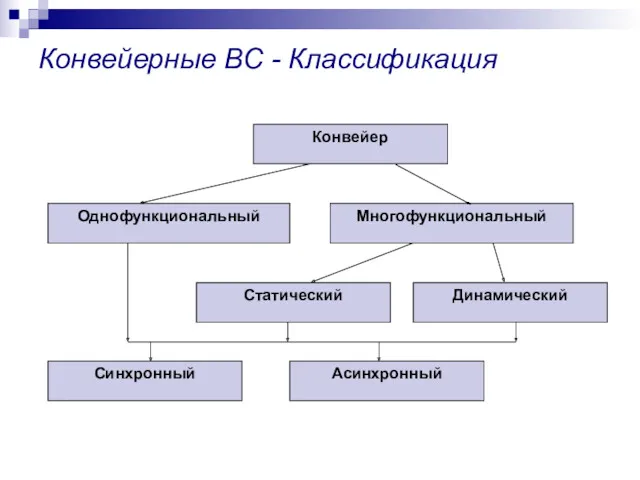
Конвейерные ВС - Классификация
Конвейер
Однофункциональный
Многофункциональный
Статический
Динамический
Синхронный
Асинхронный
Конвейерные ВС - Классификация
Конвейер
Однофункциональный
Многофункциональный
Статический
Динамический
Синхронный
Асинхронный
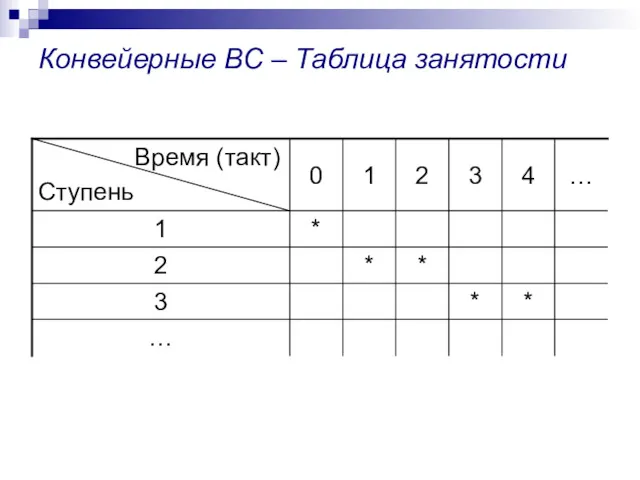
Конвейерные ВС – Таблица занятости
Конвейерные ВС – Таблица занятости

Конвейерные ВС – Задача управления
обеспечение входного потока данных (заполнение конвейера)
задача диспетчеризации
Конвейерные ВС – Задача управления
обеспечение входного потока данных (заполнение конвейера)
задача диспетчеризации

Конвейерные ВС – Проблемы управления
разный период времени обработки данных на разных
Конвейерные ВС – Проблемы управления
разный период времени обработки данных на разных

Конвейерные ВС – Стратегия управления
Стратегия управления - процедура, которая выбирает
Конвейерные ВС – Стратегия управления
Стратегия управления - процедура, которая выбирает

Конвейерные ВС –
Векторно-конвейерные процессоры
Вектор - набор данных, которые должны быть
Конвейерные ВС –
Векторно-конвейерные процессоры
Вектор - набор данных, которые должны быть
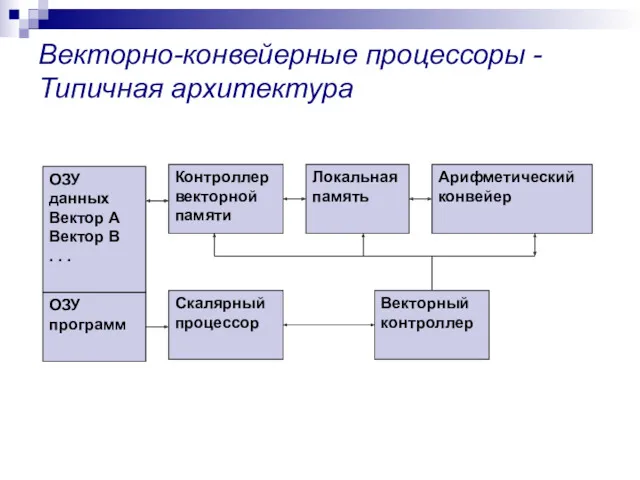
Векторно-конвейерные процессоры -
Типичная архитектура
Векторно-конвейерные процессоры -
Типичная архитектура

Векторно-конвейерные процессоры -
Cray - 1
Компания Cray Research в 1976г. выпускает
Векторно-конвейерные процессоры -
Cray - 1
Компания Cray Research в 1976г. выпускает

Развитие векторных процессоров -
Параллельно-векторные процессоры (PVP)
Архитектура. PVP-системы строятся из векторно-конвейерных
Развитие векторных процессоров -
Параллельно-векторные процессоры (PVP)
Архитектура. PVP-системы строятся из векторно-конвейерных

Развитие векторных процессоров -
Параллельно-векторные процессоры (PVP)
Примеры. NEC SX-4/SX-5, линия векторно-конвейерных
Развитие векторных процессоров -
Параллельно-векторные процессоры (PVP)
Примеры. NEC SX-4/SX-5, линия векторно-конвейерных

Параллельные вычислительные системы
Конвейеризация однопроцессорных ЭВМ
Параллельные вычислительные системы
Конвейеризация однопроцессорных ЭВМ

Конвейеризация однопроцессорных ЭВМ
Конвейеризация - метод проектирования, в результате применения которого в
Конвейеризация однопроцессорных ЭВМ
Конвейеризация - метод проектирования, в результате применения которого в

Конвейеризация однопроцессорных ЭВМ БЭСМ-6
Конвейеризация однопроцессорных ЭВМ БЭСМ-6

Конвейеризация однопроцессорных ЭВМ. Первый этап – предварительная выборка
Предварительная (опережающая) выборка команд
Конвейеризация однопроцессорных ЭВМ. Первый этап – предварительная выборка
Предварительная (опережающая) выборка команд
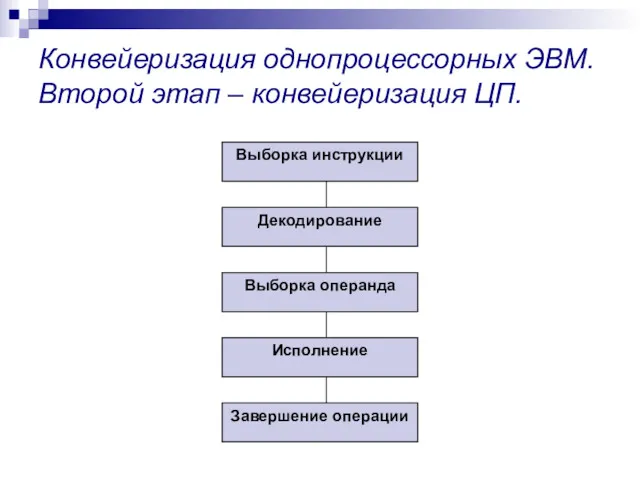
Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
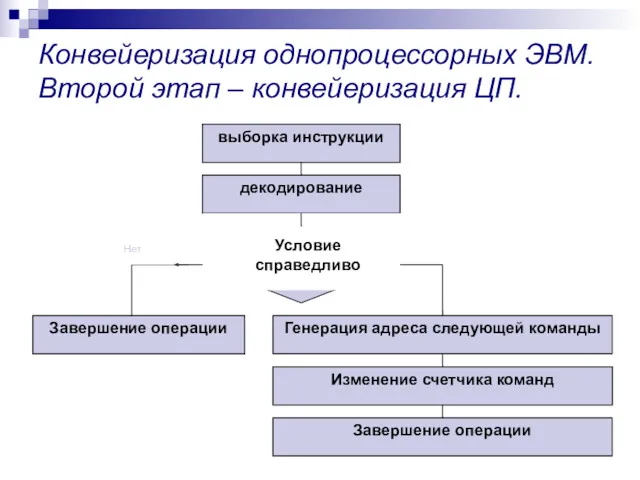
Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.

Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
При проектировании конвейера для
Конвейеризация однопроцессорных ЭВМ. Второй этап – конвейеризация ЦП.
При проектировании конвейера для

Конвейеризация однопроцессорных ЭВМ. Помехи.
Помеха возникает, когда к одному элементу данных (ячейке
Конвейеризация однопроцессорных ЭВМ. Помехи.
Помеха возникает, когда к одному элементу данных (ячейке

Конвейеризация однопроцессорных ЭВМ. Помехи.
Три класса помех:
чтение после записи (RAW);
запись после чтения
Конвейеризация однопроцессорных ЭВМ. Помехи.
Три класса помех:
чтение после записи (RAW);
запись после чтения

Конвейеризация однопроцессорных ЭВМ. КЭШ-память.
Введение в систему кэш-памяти можно рассматривать, как еще
Конвейеризация однопроцессорных ЭВМ. КЭШ-память.
Введение в систему кэш-памяти можно рассматривать, как еще

Параллельные вычислительные системы
Класс ОКМД
Параллельные вычислительные системы
Класс ОКМД

Параллельные ВС класса ОКМД
Один поток команд – много потоков данных, ОКМД
Параллельные ВС класса ОКМД
Один поток команд – много потоков данных, ОКМД
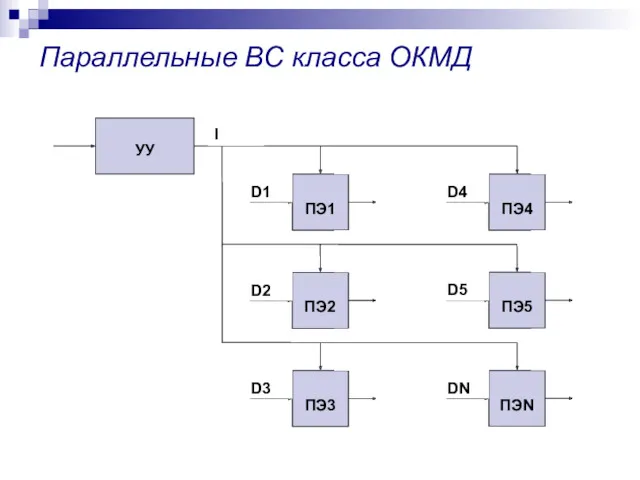
Параллельные ВС класса ОКМД
Параллельные ВС класса ОКМД

ОКМД – Процессорная матрица
Процессорная матрица - группа одинаковых процессорных элементов, объединенных
ОКМД – Процессорная матрица
Процессорная матрица - группа одинаковых процессорных элементов, объединенных

ОКМД – Процессорная матрица
ILLIAC - IV
ОКМД – Процессорная матрица
ILLIAC - IV

ОКМД – Процессорная матрица
ПС - 2000
ОКМД – Процессорная матрица
ПС - 2000

ОКМД –
Однородная вычислительная среда
Однородная вычислительная среда - регулярная решетка
ОКМД –
Однородная вычислительная среда
Однородная вычислительная среда - регулярная решетка

ОКМД –
Однородная вычислительная среда
Систолическая матрица - реализация однородной вычислительной
ОКМД –
Однородная вычислительная среда
Систолическая матрица - реализация однородной вычислительной
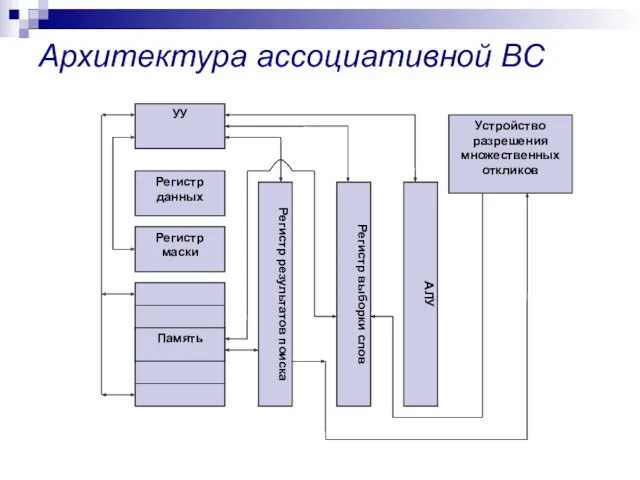
Архитектура ассоциативной ВС
Архитектура ассоциативной ВС
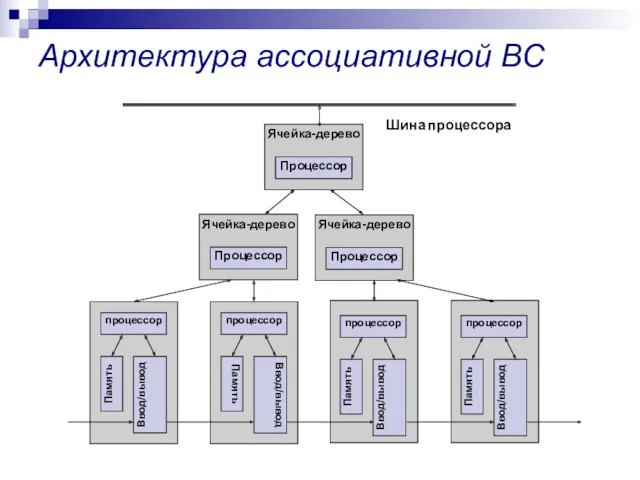
Архитектура ассоциативной ВС
Шина процессора
Архитектура ассоциативной ВС
Шина процессора
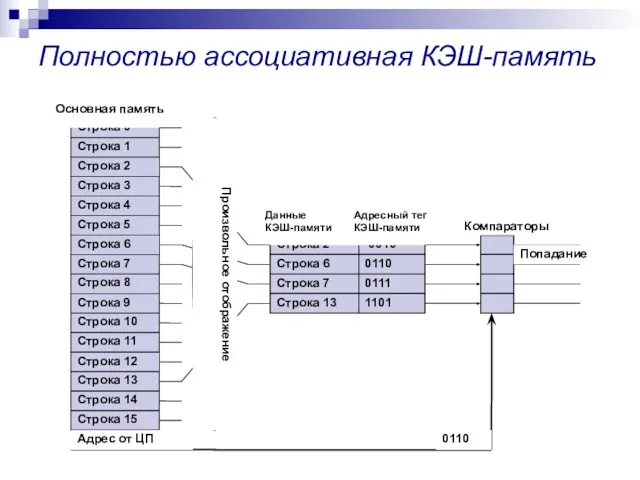
Полностью ассоциативная КЭШ-память
Полностью ассоциативная КЭШ-память

Параллельные вычислительные системы
Класс МКМД (MIMD)
Мультипроцессоры
Параллельные вычислительные системы
Класс МКМД (MIMD)
Мультипроцессоры

Параллельные ВС класса МКМД
Один из основных недостатков систематики Флинна - излишняя
Параллельные ВС класса МКМД
Один из основных недостатков систематики Флинна - излишняя
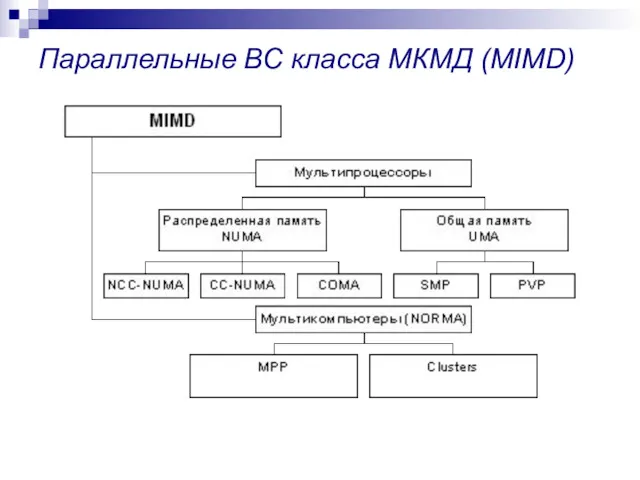
Параллельные ВС класса МКМД (MIMD)
Параллельные ВС класса МКМД (MIMD)

Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
SMP (Symmetric MultiProcessing) – симметричная
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
SMP (Symmetric MultiProcessing) – симметричная
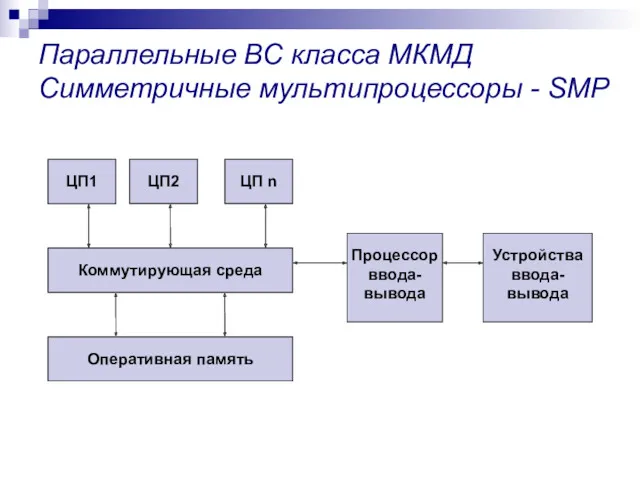
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP

Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Примеры. HP 9000 V-class, N-class;
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Примеры. HP 9000 V-class, N-class;

Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Операционная система. Система работает под
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Операционная система. Система работает под

МКМД – Мультипроцессоры
с распределенной памятью (NUMA)
Cache-Only Memory Architecture, COMA -
МКМД – Мультипроцессоры
с распределенной памятью (NUMA)
Cache-Only Memory Architecture, COMA -
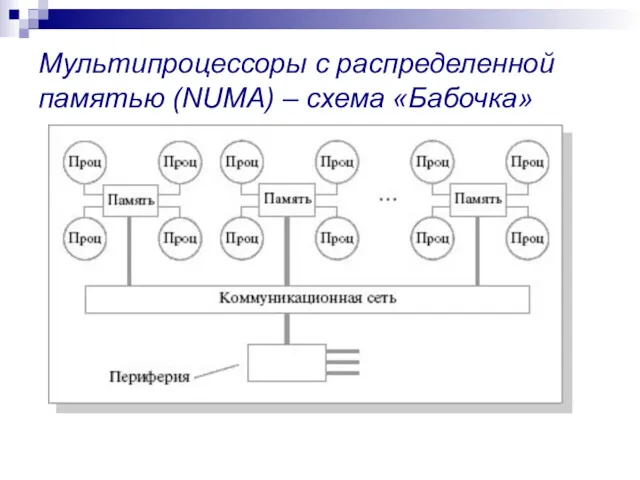
Мультипроцессоры с распределенной памятью (NUMA) – схема «Бабочка»
Мультипроцессоры с распределенной памятью (NUMA) – схема «Бабочка»

Параллельные вычислительные системы
Класс МКМД (MIMD)
Мультипроцессоры
Параллельные вычислительные системы
Класс МКМД (MIMD)
Мультипроцессоры

Параллельные ВС класса МКМД
Один из основных недостатков систематики Флинна - излишняя
Параллельные ВС класса МКМД
Один из основных недостатков систематики Флинна - излишняя
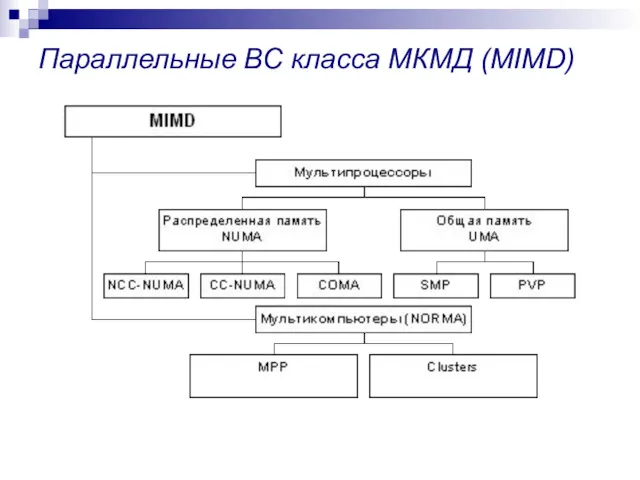
Параллельные ВС класса МКМД (MIMD)
Параллельные ВС класса МКМД (MIMD)

Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
SMP (Symmetric MultiProcessing) – симметричная
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
SMP (Symmetric MultiProcessing) – симметричная
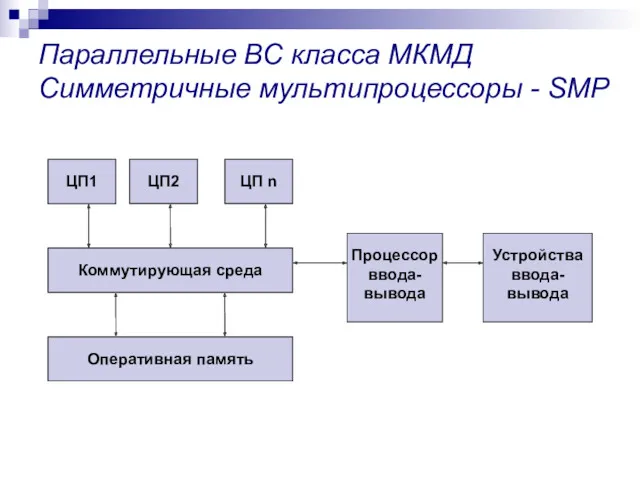
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP

Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Примеры. HP 9000 V-class, N-class;
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Примеры. HP 9000 V-class, N-class;

Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Операционная система. Система работает под
Параллельные ВС класса МКМД
Симметричные мультипроцессоры - SMP
Операционная система. Система работает под

МКМД – Мультипроцессоры
с распределенной памятью (NUMA)
Cache-Only Memory Architecture, COMA -
МКМД – Мультипроцессоры
с распределенной памятью (NUMA)
Cache-Only Memory Architecture, COMA -
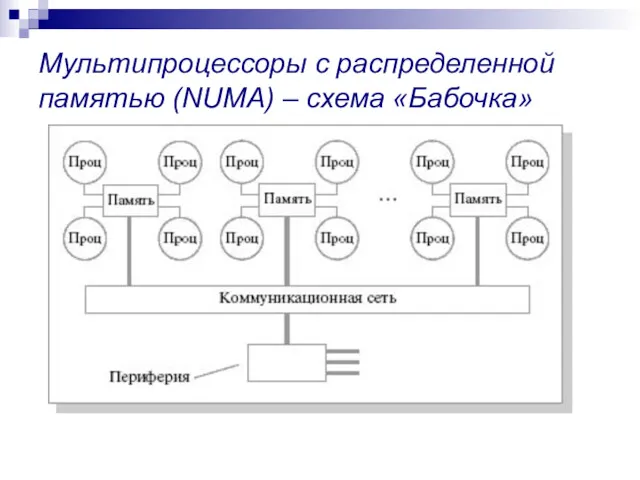
Мультипроцессоры с распределенной памятью (NUMA) – схема «Бабочка»
Мультипроцессоры с распределенной памятью (NUMA) – схема «Бабочка»

Параллельные вычислительные системы
СуперЭВМ
Параллельные вычислительные системы
СуперЭВМ

СуперЭВМ
Впервые термин суперЭВМ был использован в начале 60-х годов, когда группа
СуперЭВМ
Впервые термин суперЭВМ был использован в начале 60-х годов, когда группа

Суперкомпьютер – это …
Компьютер с производительностью свыше 10 000 млн. теоретических
Суперкомпьютер – это …
Компьютер с производительностью свыше 10 000 млн. теоретических

Суперкомпьютеры
29-я редакция Top500 от 27.06.2007
1 - прототип будущего суперкомпьютера IBM BlueGene/L
Суперкомпьютеры
29-я редакция Top500 от 27.06.2007
1 - прототип будущего суперкомпьютера IBM BlueGene/L

Суперкомпьютер Blue Gene
Суперкомпьютер Blue Gene
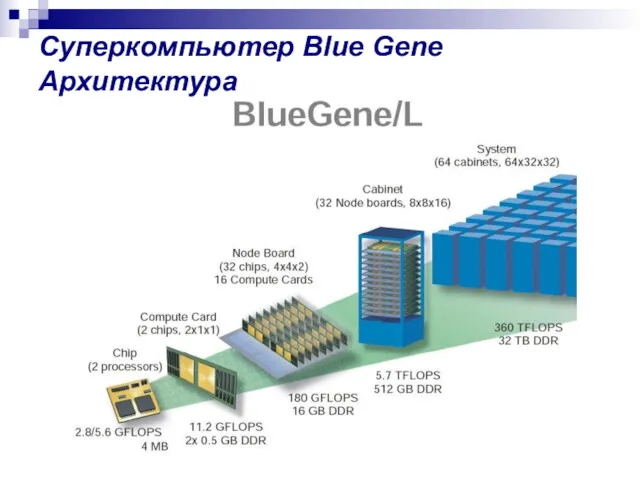
Суперкомпьютер Blue Gene
Архитектура
Суперкомпьютер Blue Gene
Архитектура
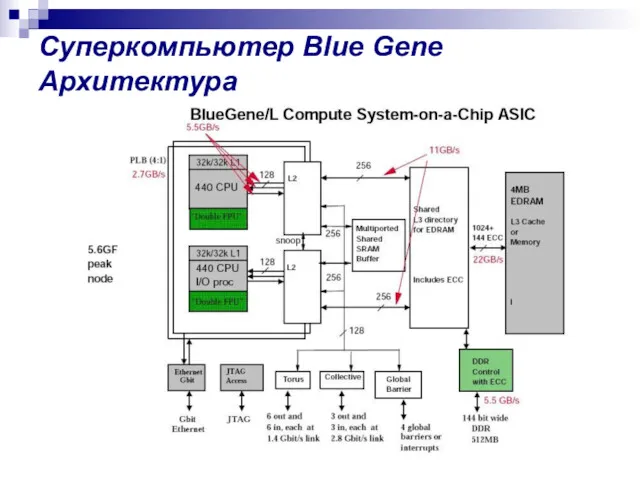
Суперкомпьютер Blue Gene
Архитектура
Суперкомпьютер Blue Gene
Архитектура

Суперкомпьютер Blue Gene
Базовый компонент (карта)
Суперкомпьютер Blue Gene
Базовый компонент (карта)

Параллельные вычислительные системы
Элементная база
Микропроцессоры
Параллельные вычислительные системы
Элементная база
Микропроцессоры

Элементная база параллельных ВС Микропроцессоры
Основные требования к микропроцессорам, используемым в параллельных
Элементная база параллельных ВС Микропроцессоры
Основные требования к микропроцессорам, используемым в параллельных
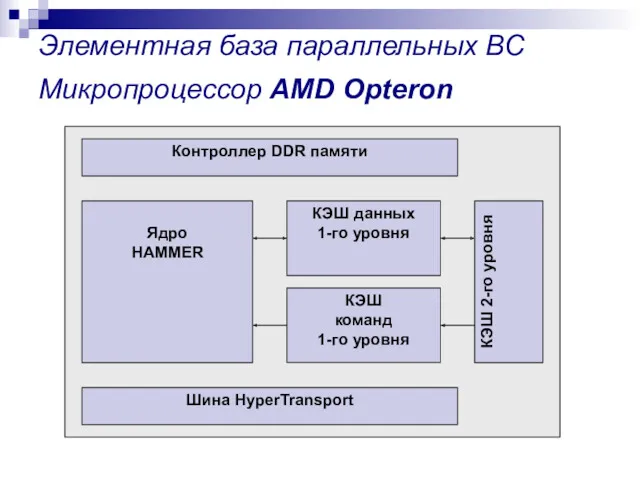
Элементная база параллельных ВС
Микропроцессор AMD Opteron
Элементная база параллельных ВС
Микропроцессор AMD Opteron
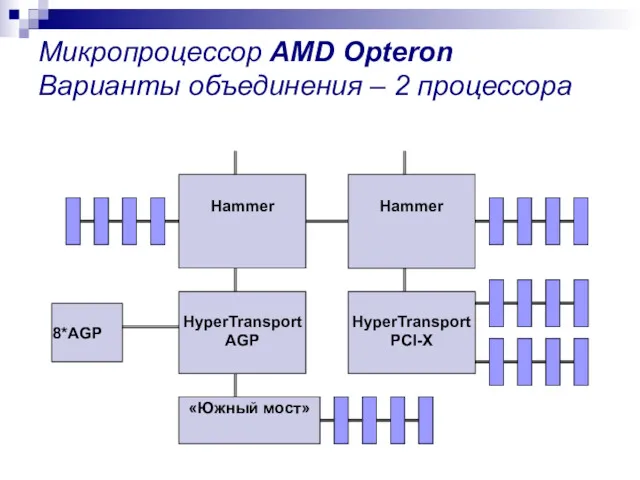
Микропроцессор AMD Opteron Варианты объединения – 2 процессора
Микропроцессор AMD Opteron Варианты объединения – 2 процессора
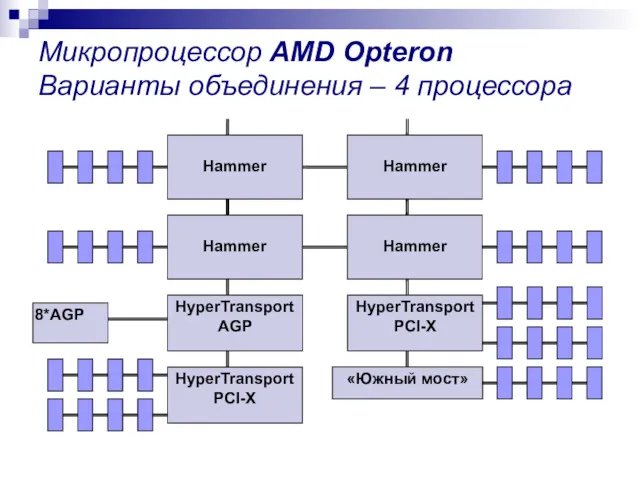
Микропроцессор AMD Opteron Варианты объединения – 4 процессора
Микропроцессор AMD Opteron Варианты объединения – 4 процессора
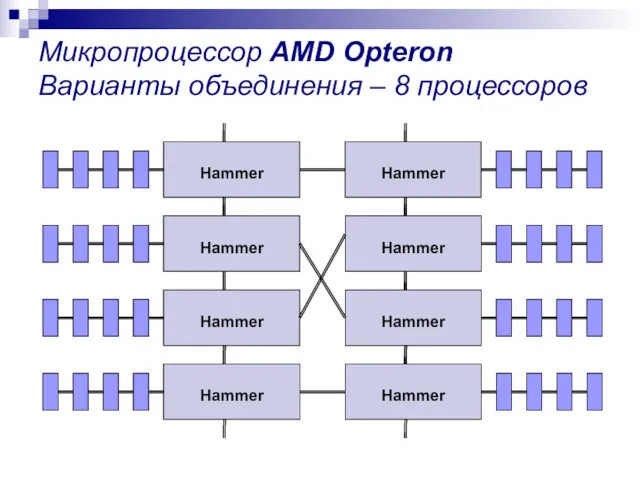
Микропроцессор AMD Opteron Варианты объединения – 8 процессоров
Микропроцессор AMD Opteron Варианты объединения – 8 процессоров

Элементная база параллельных ВС Микропроцессор AMD Opteron
10 сентября 2007 года
Элементная база параллельных ВС Микропроцессор AMD Opteron
10 сентября 2007 года
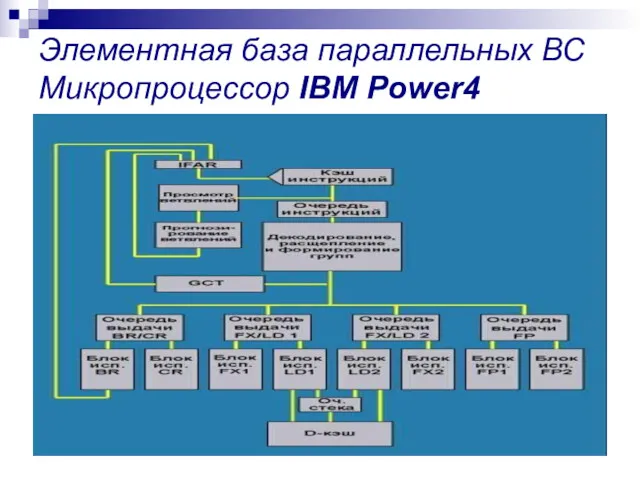
Элементная база параллельных ВС Микропроцессор IBM Power4
Элементная база параллельных ВС Микропроцессор IBM Power4
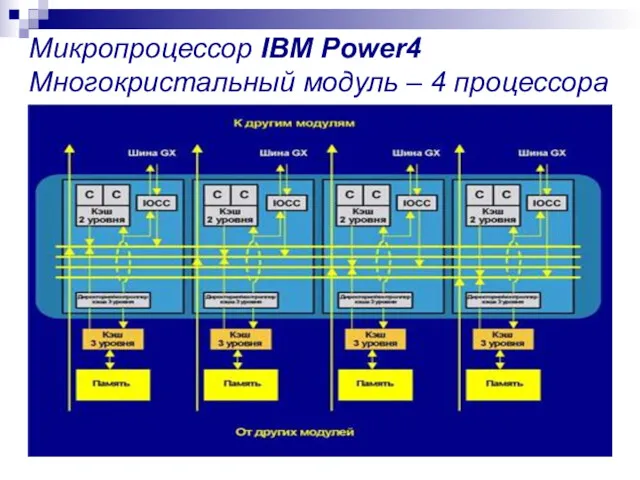
Микропроцессор IBM Power4
Многокристальный модуль – 4 процессора
Микропроцессор IBM Power4
Многокристальный модуль – 4 процессора

Микропроцессор IBM Power4
Объединение многокристальных модулей
Микропроцессор IBM Power4
Объединение многокристальных модулей
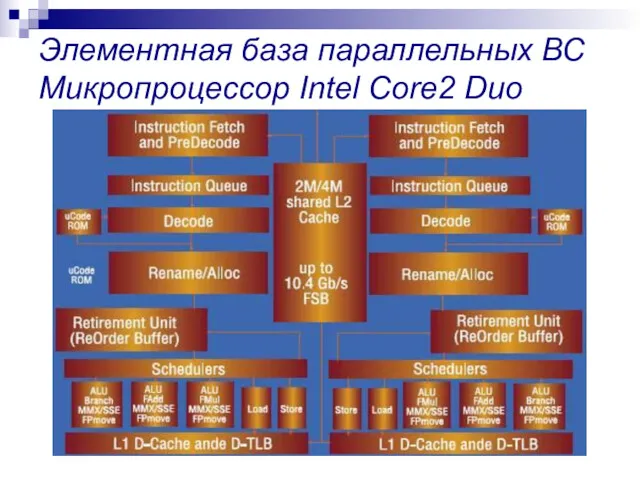
Элементная база параллельных ВС Микропроцессор Intel Core2 Duo
Элементная база параллельных ВС Микропроцессор Intel Core2 Duo

Параллельные вычислительные системы
Элементная база. Коммутаторы и топология
Параллельные вычислительные системы
Элементная база. Коммутаторы и топология

Коммутирующие среды параллельных ВС
Простые коммутаторы
Типы простых коммутаторов:
с временным разделением;
с пространственным
Коммутирующие среды параллельных ВС
Простые коммутаторы
Типы простых коммутаторов:
с временным разделением;
с пространственным
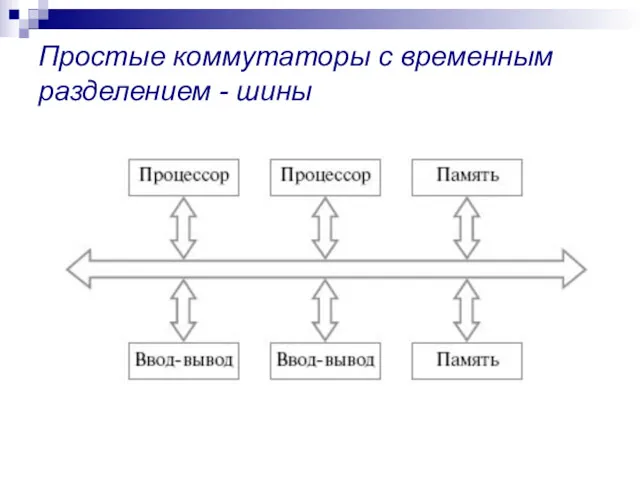
Простые коммутаторы с временным разделением - шины
Простые коммутаторы с временным разделением - шины
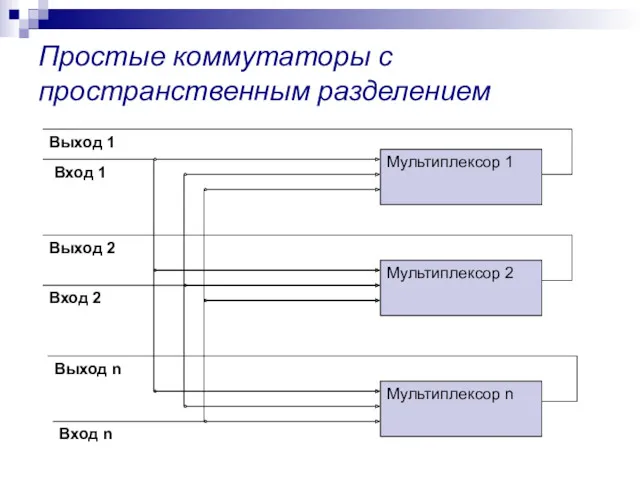
Простые коммутаторы с пространственным разделением
Мультиплексор 1
Мультиплексор 2
Мультиплексор n
Вход 1
Вход 2
Вход
Простые коммутаторы с пространственным разделением
Мультиплексор 1
Мультиплексор 2
Мультиплексор n
Вход 1
Вход 2
Вход
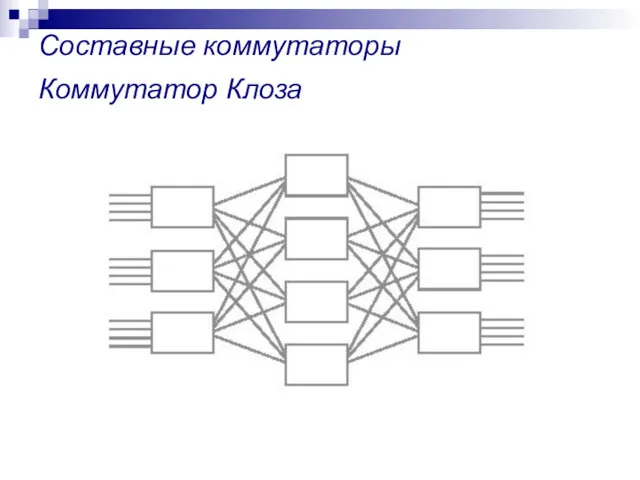
Составные коммутаторы
Коммутатор Клоза
Составные коммутаторы
Коммутатор Клоза
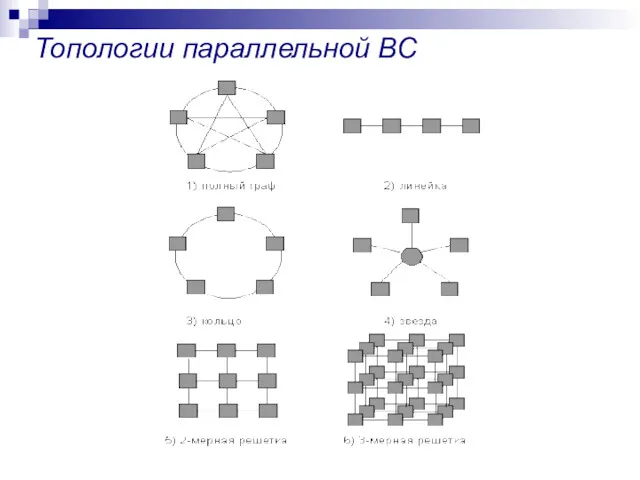
Топологии параллельной ВС
Топологии параллельной ВС
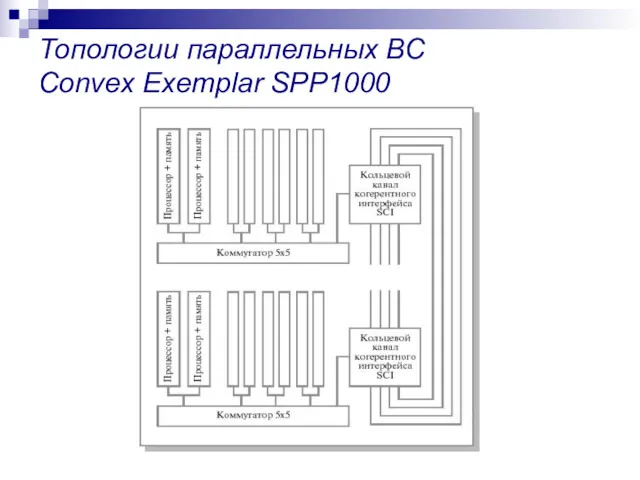
Топологии параллельных ВС
Convex Exemplar SPP1000
Топологии параллельных ВС
Convex Exemplar SPP1000
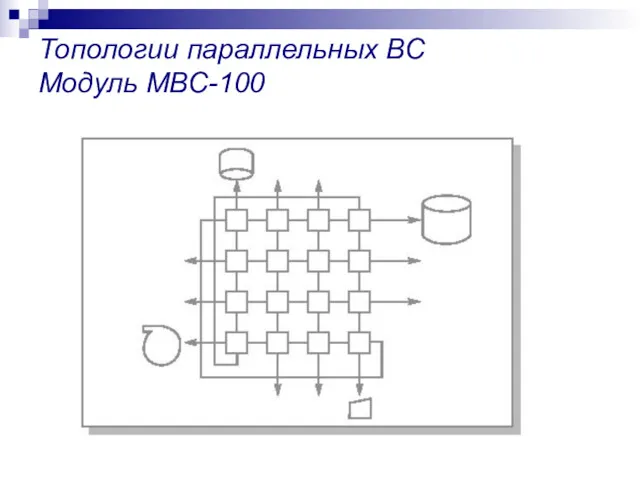
Топологии параллельных ВС
Модуль МВС-100
Топологии параллельных ВС
Модуль МВС-100
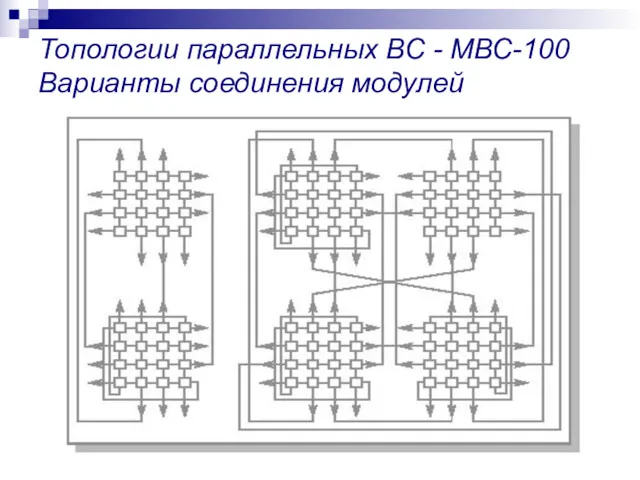
Топологии параллельных ВС - МВС-100 Варианты соединения модулей
Топологии параллельных ВС - МВС-100 Варианты соединения модулей

Параллельные вычислительные системы
Элементная база. Коммутирующие среды
Параллельные вычислительные системы
Элементная база. Коммутирующие среды

Коммутирующие среды параллельных ВС
Myrinet
Достоинства Myrinet:
широкое распространение и высокая надежность;
небольшое время
Коммутирующие среды параллельных ВС
Myrinet
Достоинства Myrinet:
широкое распространение и высокая надежность;
небольшое время

Коммутирующие среды параллельных ВС
Myrinet
Недостатки Myrinet:
нестандартное решение, поддерживаемое всего одним производителем;
ограниченная
Коммутирующие среды параллельных ВС
Myrinet
Недостатки Myrinet:
нестандартное решение, поддерживаемое всего одним производителем;
ограниченная

Коммутирующие среды параллельных ВС Infiniband
Достоинства Infiniband:
стандарт Infiniband Trade Assotiation (IBTA);
несколько
Коммутирующие среды параллельных ВС Infiniband
Достоинства Infiniband:
стандарт Infiniband Trade Assotiation (IBTA);
несколько

Коммутирующие среды параллельных ВС Infiniband
Недостатки Infiniband:
сложность изменения физической и логической структуры;
Коммутирующие среды параллельных ВС Infiniband
Недостатки Infiniband:
сложность изменения физической и логической структуры;

Коммутирующие среды параллельных ВС Ethernet
Достоинства Ethernet:
наличие развитого инструментария для управления и
Коммутирующие среды параллельных ВС Ethernet
Достоинства Ethernet:
наличие развитого инструментария для управления и

Коммутирующие среды параллельных ВС Ethernet
Недостатки Ethernet:
наличие задержки (сокращение времени задержки за
Коммутирующие среды параллельных ВС Ethernet
Недостатки Ethernet:
наличие задержки (сокращение времени задержки за

Параллельные вычислительные системы
Технологии GRID
Параллельные вычислительные системы
Технологии GRID

Параллельные ВС
GRID
Технология GRID подразумевает слаженное взаимодействие множества ресурсов, гетерогенных по
Параллельные ВС
GRID
Технология GRID подразумевает слаженное взаимодействие множества ресурсов, гетерогенных по
Параллельные ВС
GRID
Параллельные ВС
GRID

Параллельные ВС
GRID – предпосылки возникновения
Необходимость в концентрации огромного количества данных,
Параллельные ВС
GRID – предпосылки возникновения
Необходимость в концентрации огромного количества данных,

Параллельные ВС
GRID – предпосылки возникновения
“Вероятно, мы скоро увидим распространение “компьютерных
Параллельные ВС
GRID – предпосылки возникновения
“Вероятно, мы скоро увидим распространение “компьютерных

Параллельные ВС
Метакомпьютинг и GRID
Метакомпьютинг - особый тип распределенного компьютинга, подразумевающего
Параллельные ВС
Метакомпьютинг и GRID
Метакомпьютинг - особый тип распределенного компьютинга, подразумевающего

Параллельные ВС
Свойства GRID
масштабы вычислительного ресурса многократно превосходят ресурсы отдельного компьютера
Параллельные ВС
Свойства GRID
масштабы вычислительного ресурса многократно превосходят ресурсы отдельного компьютера

Параллельные ВС
Области применения GRID
массовая обработка потоков данных большого объема;
многопараметрический
Параллельные ВС
Области применения GRID
массовая обработка потоков данных большого объема;
многопараметрический
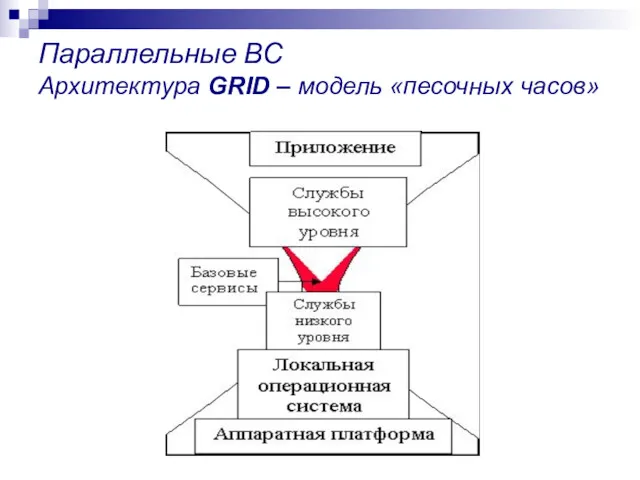
Параллельные ВС
Архитектура GRID – модель «песочных часов»
Параллельные ВС
Архитектура GRID – модель «песочных часов»
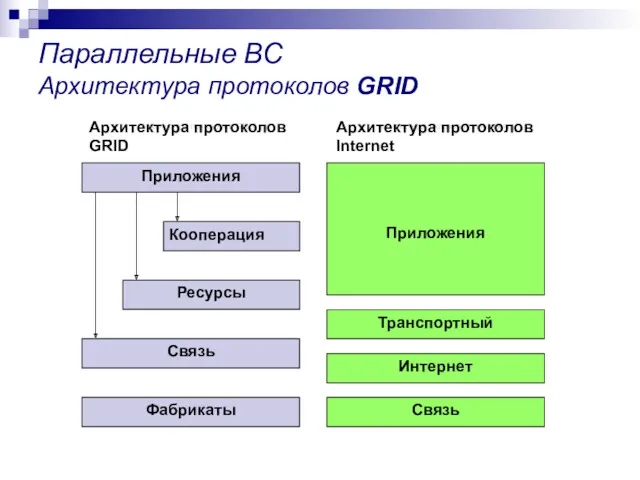
Параллельные ВС
Архитектура протоколов GRID
Архитектура протоколов GRID
Архитектура протоколов Internet
Параллельные ВС
Архитектура протоколов GRID
Архитектура протоколов GRID
Архитектура протоколов Internet

Параллельные вычислительные системы
Прикладное программное обеспечение
Параллельные вычислительные системы
Прикладное программное обеспечение

Параллельные ВС
Прикладное программное обеспечение
Проблемы разработки параллельного ПО
проблема распараллеливания
проблема отладки и
Параллельные ВС
Прикладное программное обеспечение
Проблемы разработки параллельного ПО
проблема распараллеливания
проблема отладки и

Параллельные ВС
Прикладное ПО – закон Амдала
S – ускорение программы по
Параллельные ВС
Прикладное ПО – закон Амдала
S – ускорение программы по

Параллельные ВС
Прикладное ПО – подходы к созданию
Написание параллельной программы «с
Параллельные ВС
Прикладное ПО – подходы к созданию
Написание параллельной программы «с

Параллельные ВС
Прикладное ПО – подходы к созданию
Написание параллельной программы «с
Параллельные ВС
Прикладное ПО – подходы к созданию
Написание параллельной программы «с

Параллельные ВС
Прикладное ПО – подходы к созданию
Автоматическое распараллеливание последовательной программы
Достоинства:
Параллельные ВС
Прикладное ПО – подходы к созданию
Автоматическое распараллеливание последовательной программы
Достоинства:

Параллельные ВС
Прикладное ПО – подходы к созданию
Смешанный подход – автоматическое
Параллельные ВС
Прикладное ПО – подходы к созданию
Смешанный подход – автоматическое

Параллельные вычислительные системы
Программирование параллельных ВС с разделяемой памятью
Параллельные вычислительные системы
Программирование параллельных ВС с разделяемой памятью
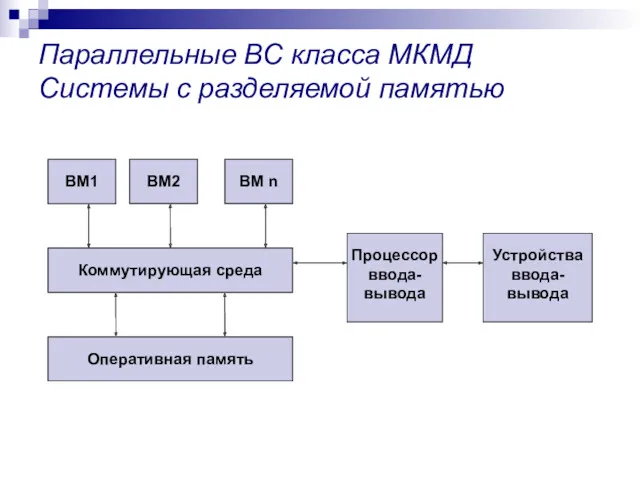
Параллельные ВС класса МКМД
Системы с разделяемой памятью
Параллельные ВС класса МКМД
Системы с разделяемой памятью

Программирование параллельных ВС
Системы с разделяемой памятью
Программирование систем с разделяемой памятью осуществляется
Программирование параллельных ВС
Системы с разделяемой памятью
Программирование систем с разделяемой памятью осуществляется
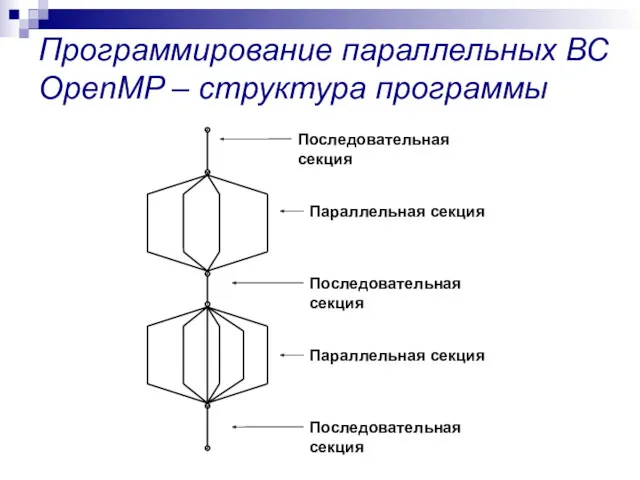
Программирование параллельных ВС
OpenMP – структура программы
Программирование параллельных ВС
OpenMP – структура программы

Программирование параллельных ВС
OpenMP – структура программы
Основная нить и только она исполняет
Программирование параллельных ВС
OpenMP – структура программы
Основная нить и только она исполняет

Программирование параллельных ВС
OpenMP – переменные
В параллельной области все переменные программы разделяются
Программирование параллельных ВС
OpenMP – переменные
В параллельной области все переменные программы разделяются

Параллельные вычислительные системы
Программирование кластерных и MPP параллельных ВС
Параллельные вычислительные системы
Программирование кластерных и MPP параллельных ВС
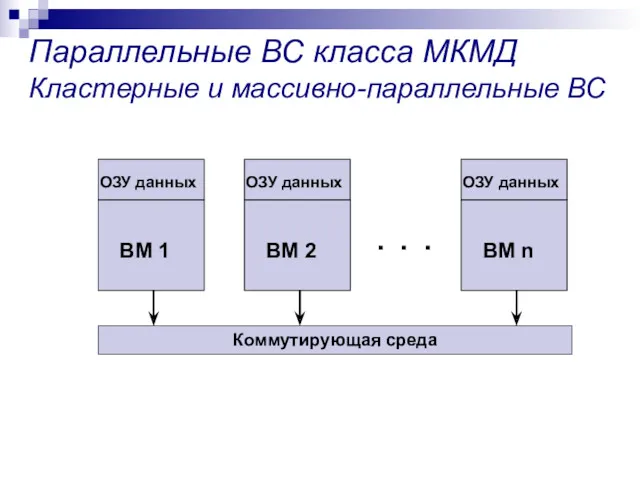
Параллельные ВС класса МКМД
Кластерные и массивно-параллельные ВС
Параллельные ВС класса МКМД
Кластерные и массивно-параллельные ВС

Программирование параллельных ВС Кластеры и MPP
Программирование кластерных и MPP параллельных ВС
Программирование параллельных ВС Кластеры и MPP
Программирование кластерных и MPP параллельных ВС

Программирование параллельных ВС
MPI
При запуске MPI-программы создается несколько ветвей;
Все ветви программы запускаются
Программирование параллельных ВС
MPI
При запуске MPI-программы создается несколько ветвей;
Все ветви программы запускаются

Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число
Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число

Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число
Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число

MPI - Функции инициализации и завершения
int MPI_Init( int* argc, char*** argv)
MPI - Функции инициализации и завершения
int MPI_Init( int* argc, char*** argv)

MPI – информационные функции
int MPI_Comm_size(MPI_Comm comm, int* size)
Определение общего числа
MPI – информационные функции
int MPI_Comm_size(MPI_Comm comm, int* size)
Определение общего числа

MPI –функции обмена «точка-точка»
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int
MPI –функции обмена «точка-точка»
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int

MPI –функции обмена «точка-точка»
int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int
MPI –функции обмена «точка-точка»
int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int

MPI – аргументы – «джокеры» функций обмена «точка-точка»
MPI_ANY_SOURCE – заменяет аргумент
MPI – аргументы – «джокеры» функций обмена «точка-точка»
MPI_ANY_SOURCE – заменяет аргумент

Параллельные вычислительные системы
Программирование кластерных и MPP параллельных ВС
Параллельные вычислительные системы
Программирование кластерных и MPP параллельных ВС
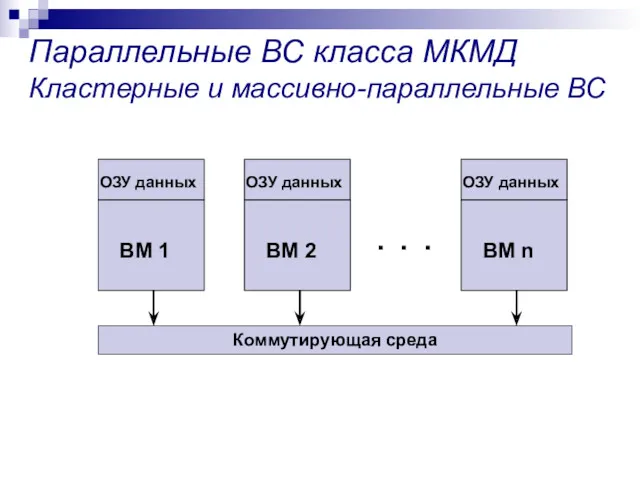
Параллельные ВС класса МКМД
Кластерные и массивно-параллельные ВС
Параллельные ВС класса МКМД
Кластерные и массивно-параллельные ВС

Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число
Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число

Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число
Программирование параллельных ВС
MPI
Библиотека MPI состоит примерно из 130 функций, в число

MPI – коллективные функции
Под термином "коллективные" в MPI подразумеваются три группы
MPI – коллективные функции
Под термином "коллективные" в MPI подразумеваются три группы

MPI – коллективные функции
int MPI_Barrier( MPI_Comm comm );
Останавливает выполнение вызвавшей
MPI – коллективные функции
int MPI_Barrier( MPI_Comm comm );
Останавливает выполнение вызвавшей

MPI –функции коллективного обмена
Основные особенности и отличия от коммуникаций типа "точка-точка":
MPI –функции коллективного обмена
Основные особенности и отличия от коммуникаций типа "точка-точка":

MPI –функции коллективного обмена
int MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int
MPI –функции коллективного обмена
int MPI_Bcast(void *buf, int count, MPI_Datatype datatype, int

MPI –функции коллективного обмена
MPI_Gather ("совок") собирает в приемный буфер задачи root
MPI –функции коллективного обмена
MPI_Gather ("совок") собирает в приемный буфер задачи root

Параллельные вычислительные системы
Проектирование кластера
Параллельные вычислительные системы
Проектирование кластера
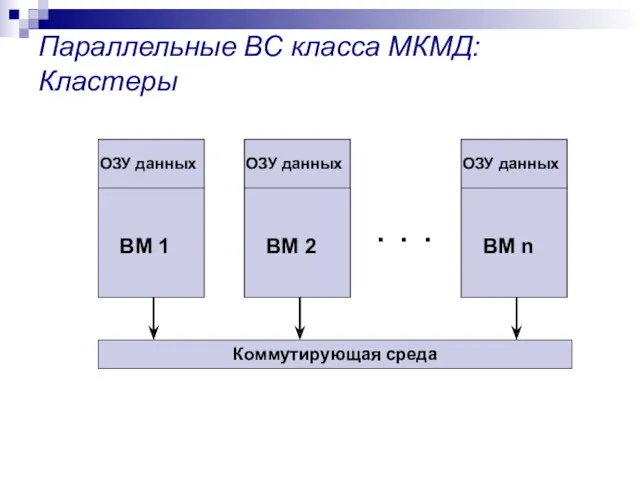
Параллельные ВС класса МКМД:
Кластеры
Параллельные ВС класса МКМД:
Кластеры

Параллельные ВС класса МКМД
Кластеры
Архитектура. Набор элементов высокой степени готовности, рабочих
Параллельные ВС класса МКМД
Кластеры
Архитектура. Набор элементов высокой степени готовности, рабочих

Параллельные ВС класса МКМД
Кластеры
При объединении в кластер компьютеров разной мощности
Параллельные ВС класса МКМД
Кластеры
При объединении в кластер компьютеров разной мощности

Параллельные ВС класса МКМД
Кластеры
Операционная система - стандартные ОС - Linux/FreeBSD,
Параллельные ВС класса МКМД
Кластеры
Операционная система - стандартные ОС - Linux/FreeBSD,

Кластеры высокой надежности
в случае сбоя ПО на одном из узлов приложение
Кластеры высокой надежности
в случае сбоя ПО на одном из узлов приложение
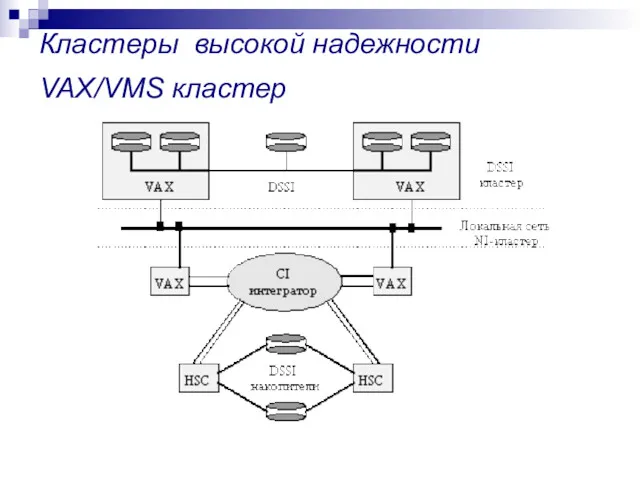
Кластеры высокой надежности VAX/VMS кластер
Кластеры высокой надежности VAX/VMS кластер
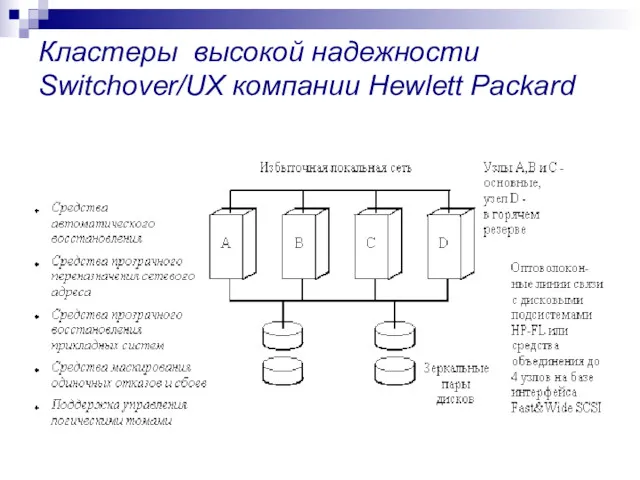
Кластеры высокой надежности
Switchover/UX компании Hewlett Packard
Кластеры высокой надежности
Switchover/UX компании Hewlett Packard

Высокопроизводительные кластеры
Высокопроизводительный кластер -
параллельная вычислительная система с распределенной памятью;
построенная из
Высокопроизводительные кластеры
Высокопроизводительный кластер -
параллельная вычислительная система с распределенной памятью;
построенная из
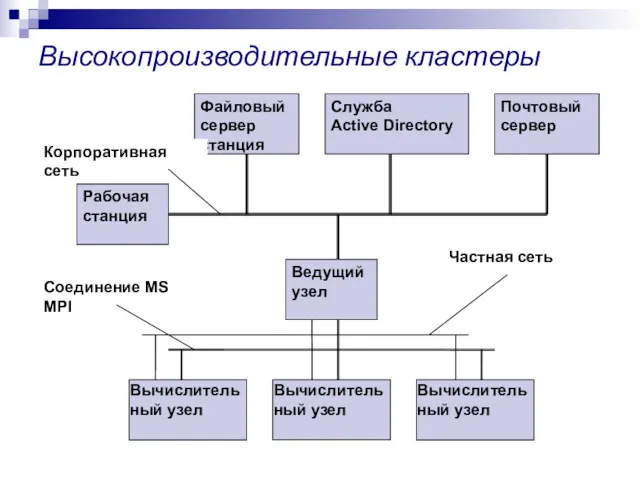
Высокопроизводительные кластеры
Высокопроизводительные кластеры

Характеристики коммутирующих сред
Характеристики коммутирующих сред
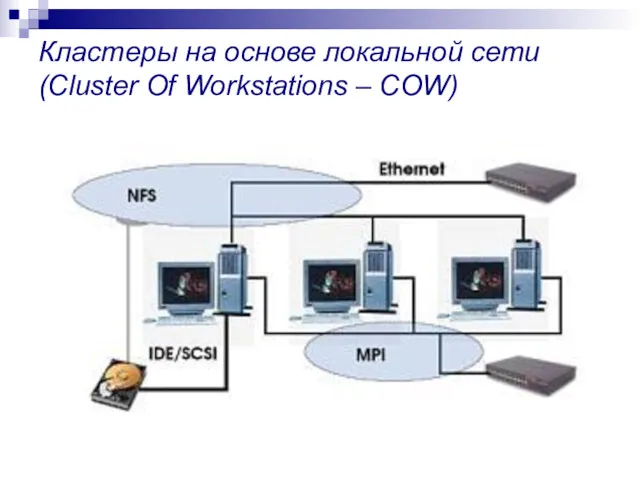
Кластеры на основе локальной сети (Cluster Of Workstations – COW)
Кластеры на основе локальной сети (Cluster Of Workstations – COW)

Параллельные вычислительные системы
Системное ПО кластера
Параллельные вычислительные системы
Системное ПО кластера

Кластеры - Системное ПО
Windows Compute Cluster Server 2003
Упрощенная настройка параметров
Кластеры - Системное ПО
Windows Compute Cluster Server 2003
Упрощенная настройка параметров

Кластеры - Системное ПО
Solaris (Sun Microsystems)
Коммерческая верся UNIX.
поддержка до
Кластеры - Системное ПО
Solaris (Sun Microsystems)
Коммерческая верся UNIX.
поддержка до

Кластеры - Системное ПО
HP-UX (Hewlett-Packard)
Потомок AT&T System V.
поддерживает до
Кластеры - Системное ПО
HP-UX (Hewlett-Packard)
Потомок AT&T System V.
поддерживает до

Параллельные вычислительные системы
Кластер на основе локальной сети
Параллельные вычислительные системы
Кластер на основе локальной сети
Параллельные ВС класса МКМД:
Кластеры
Параллельные ВС класса МКМД:
Кластеры

Кластеры на основе
локальной (корпоративной) сети
При объединении в кластер компьютеров
Кластеры на основе
локальной (корпоративной) сети
При объединении в кластер компьютеров

Операционная система - стандартные ОС - вместе со средствами поддержки параллельного
Операционная система - стандартные ОС - вместе со средствами поддержки параллельного
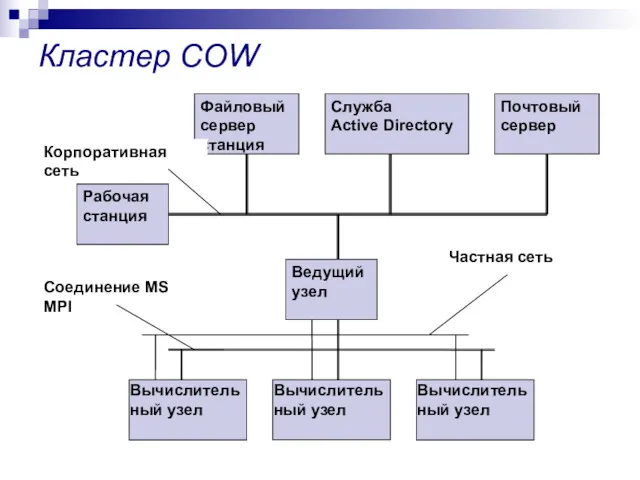
Кластер COW
Кластер COW
 Подготовка к написанию сочинения по повести А.С. Пушкина Капитанская дочка
Подготовка к написанию сочинения по повести А.С. Пушкина Капитанская дочка Адекватность, эквивалентность и переводимость, как качественные характеристики процесса перевода
Адекватность, эквивалентность и переводимость, как качественные характеристики процесса перевода Презентация Развитие артикуляционного аппарата – Веселый ротик.
Презентация Развитие артикуляционного аппарата – Веселый ротик. Переробка та відходи сільського господарства
Переробка та відходи сільського господарства Интерфейсы устройств хранения данных и RAID
Интерфейсы устройств хранения данных и RAID Радость- грусть
Радость- грусть Виды текстов. Текст-рассуждение. Урок русского языка в 3 классе
Виды текстов. Текст-рассуждение. Урок русского языка в 3 классе Российская открытая академия транспорта РУТ (МИИТ). День открытых дверей
Российская открытая академия транспорта РУТ (МИИТ). День открытых дверей Перспективный план по безопасному поведению детей старшего возраста в детском саду
Перспективный план по безопасному поведению детей старшего возраста в детском саду Проект по оказанию перинатальной помощи несовершеннолетним матерям и социальной адаптации воспитанников детских домов
Проект по оказанию перинатальной помощи несовершеннолетним матерям и социальной адаптации воспитанников детских домов Проектирование рабочей поверхности отвала плуга для бороздной вспашки
Проектирование рабочей поверхности отвала плуга для бороздной вспашки Россия – многонациональное государство
Россия – многонациональное государство Метрологічне обслуговування засобів вимірювальної техніки військового призначення
Метрологічне обслуговування засобів вимірювальної техніки військового призначення Наша любимая мамочка
Наша любимая мамочка Аппликация Новогоднее приглашение Диск
Аппликация Новогоднее приглашение Диск Антихолинэстеразные средства
Антихолинэстеразные средства Эмоции и сердце. Падма-пурана
Эмоции и сердце. Падма-пурана Презентация по легкой атлетике
Презентация по легкой атлетике права и обязанности
права и обязанности Создание презентаций. Демонстрационный учебный материл
Создание презентаций. Демонстрационный учебный материл Интерактивное ТВ 2.0. Продукт для дилера. Ростелеком
Интерактивное ТВ 2.0. Продукт для дилера. Ростелеком Сырье для производства строительной керамики. Часть 2
Сырье для производства строительной керамики. Часть 2 Технологии подключения фиксированного интернета
Технологии подключения фиксированного интернета Электрохимические процессы
Электрохимические процессы История преподавания психологии в начале XX века в средней школе
История преподавания психологии в начале XX века в средней школе Презентация к уроку технологии Работа с бумагой. 2 класс.
Презентация к уроку технологии Работа с бумагой. 2 класс. Культура стран халифата
Культура стран халифата Преступления против половой свободы и половой неприкосновенности личности
Преступления против половой свободы и половой неприкосновенности личности