- Projektowanie systemów informacyjnych

Содержание
- 2. Zagadnienia Podejście obiektowe kontra relacyjne Garby modelu relacyjnego Projektowanie logiczne Odwzorowanie atrybutów powtarzalnych Odwzorowanie związków asocjacji
- 3. Dlaczego obiektowość? W modelu relacyjnym odwzorowanie percepcji świata jest ograniczone środkami implementacyjnymi. W rezultacie, schemat relacyjny
- 4. Obiektowość kontra model relacyjny Model relacyjny przegrał konfrontację z obiektowością w strefie intelektualnej; trwał w tej
- 5. Garby modelu relacyjnego (1) Z góry ustalony konstruktor typu danych (relacja), rozszerzany ad hoc przez wytwórców
- 6. Garby modelu relacyjnego (2) Brak uniwersalnych środków do manipulowania danymi, co powoduje konieczność zanurzenia w języki
- 7. Czy model relacyjny był pomyłką? Poglądy są podzielone. Na korzyść tej tezy przemawia fakt, że podstawowym
- 8. Rzeczywistość (1) Wiele aplikacji potrzebuje tylko warstwy trwałych danych, która w istocie jest ukryta przed użytkownikiem.
- 9. Rzeczywistość (2) Sprzymierzeńcem wszystkich wdrożonych technologii baz danych, w tym relacyjnych, jest ogromna bezwładność rynku zastosowań,
- 10. Schemat pojęciowy a systemy relacyjne System relacyjny jako back-end, tj. baza implementacyjna. Na czubku systemu relacyjnego
- 11. Projektowanie logiczne Termin oznaczający odwzorowanie modelu pojęciowego (np. encja-związek lub obiektowego) na model lub wyrażenia języka
- 12. Charakterystyka ilościowa danych ZAJĘTOŚĆ PAMIĘCI (liczba wystąpień danych), ZMIENNOŚĆ (spodziewany przyrost w czasie). KLIENT TOWAR zakupił
- 13. Charakterystyka ilościowa procesów OPERACJE ELEMENTARNE (FUNKCJE UŻYTKOWE), TYP (on-line, batch), CZĘSTOTLIWOŚĆ ZACHODZENIA (ew. dodatkowo rozkład w
- 14. Proces projektowania logicznego PROJEKTOWANIE LOGICZNE wysokiego poziomu NIEZALEŻNE OD TYPU BD PROJEKTOWANIE LOGICZNE ZALEŻNE OD TYPU
- 15. Odwzorowanie atrybutów powtarzalnych Tabele relacyjne nie mogą przechowywać wielokrotnych wartości atrybutów. Model obiektowy (np. w UML)
- 16. Odwzorowanie asocjacji Dla liczności 1:1 można zaimplementować jako jedną tablelę. Państwo Nazwa Stolica Miasto IdPaństwa Nazwa
- 17. Odwzorowanie złożonych obiektów Podstawowa metoda odwzorowania obiektów złożonych polega na spłaszczaniu ich struktury (poprzez zamianę atrybutów
- 18. Odwzorowanie metod/operacji Model relacyjny nie przewiduje specjalnych środków. Najczęściej są one odwzorowane na poziomie programów aplikacyjnych
- 19. Trzy metody obejścia braku dziedziczenia Użycie jednej tabeli dla całego drzewa klas poprzez zsumowanie wszystkich występujących
- 20. Przykład obejścia braku dziedziczenia Kwota do zwrotu Należny podatek Podstawa opodatkowania Rok PIT pojedyncz podatnika Adres
- 21. Zalety i wady każdej z trzech metod Łatwość implementacji Łatwość dostępu do danych Łatwość przypisania OID
- 22. Prowadzenie słownika danych Prowadzenie słownika jest konieczne dla przechowania informacji o sposobie odwzorowania modelu obiektowego na
- 23. Zależność funkcyjna pomiędzy atrybutami: wartość atrybutu A2 zależy od wartości atrybutu A1, jeżeli dla każdego wyobrażalnego
- 24. Analiza wartości zerowych Analiza ta, podobnie do zależności funkcyjnych, może nam przynieść informację o konieczności zdekomponowania
- 25. Analiza długich/złożonych wartości Podobnie do wartości zerowych i zależności funkcyjnych, analiza długich wartości może być również
- 26. Klucze kandydujące Firma Osoba posiada_akcje Klucz kandydujący: {(Osoba, Firma)} Firma Osoba pracuje_w Klucz kandydujący: {(Osoba)} Miasto
- 27. Wybór klucza Może być wiele kluczy kandydujących, ale tylko jeden klucz główny. Nazwisko Data_ur Nr_PESEL Nr_prac
- 28. Przejście na model relacyjny; przykłady (1) KlientDostawa (IdKlienta, NazwaKlienta, AdresDostawy) Klient (IdKlienta, NazwaKlienta) KartaKredytowa (IdKarty, TypKarty,
- 29. Przejście na model relacyjny; przykłady (2) Ślub DataŚlubu Kobieta( IdKobiety, NazwiskoKobiety ) Mężczyzna( IdMężczyzny, NazwiskoMężczyzny )
- 30. Przejście na model relacyjny; przykłady (3) Sprzedawca(IdSprzedawcy, Nazwisko, NrTel) Sprzedaż(IdSprzedaży, Data) Sprzedaż_Sprzedawca (IdSprzedaży, IdSprzedawcy, NazwaTowaru, Ilość)
- 31. Przejście na model relacyjny; przykłady (4) podległość jest_podwładnym jest_przełożonym M:N Pracownik (IdPracownika, NazwiskoPrac, DataUrodzPrac) Podległość (IdPracPodwład,
- 32. Przejście na model relacyjny; przykłady (5) Klient (Id_Klienta, Nazwa_Klienta) Towar (Id_Towaru, Nazwa_Towaru) Sprzedawca (Id_Sprzedwcy, Nazwa_Sprzedawcy) Sprzedaż
- 34. Скачать презентацию

Zagadnienia
Podejście obiektowe kontra relacyjne
Garby modelu relacyjnego
Projektowanie logiczne
Odwzorowanie atrybutów powtarzalnych
Odwzorowanie związków asocjacji
Odwzorowanie
Zagadnienia
Podejście obiektowe kontra relacyjne
Garby modelu relacyjnego
Projektowanie logiczne
Odwzorowanie atrybutów powtarzalnych
Odwzorowanie związków asocjacji
Odwzorowanie
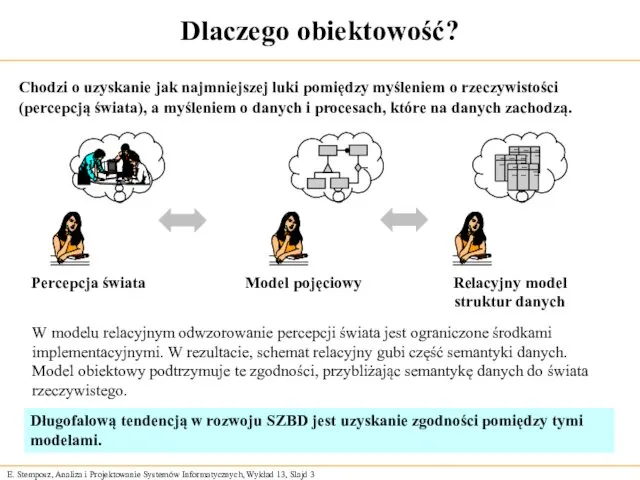
Dlaczego obiektowość?
W modelu relacyjnym odwzorowanie percepcji świata jest ograniczone środkami implementacyjnymi.
Dlaczego obiektowość?
W modelu relacyjnym odwzorowanie percepcji świata jest ograniczone środkami implementacyjnymi.

Obiektowość kontra model relacyjny
Model relacyjny przegrał konfrontację z obiektowością w strefie
Obiektowość kontra model relacyjny
Model relacyjny przegrał konfrontację z obiektowością w strefie

Garby modelu relacyjnego (1)
Z góry ustalony konstruktor typu danych (relacja), rozszerzany
Garby modelu relacyjnego (1)
Z góry ustalony konstruktor typu danych (relacja), rozszerzany

Garby modelu relacyjnego (2)
Brak uniwersalnych środków do manipulowania danymi, co powoduje
Garby modelu relacyjnego (2)
Brak uniwersalnych środków do manipulowania danymi, co powoduje

Czy model relacyjny był pomyłką?
Poglądy są podzielone. Na korzyść tej tezy
Czy model relacyjny był pomyłką?
Poglądy są podzielone. Na korzyść tej tezy

Rzeczywistość (1)
Wiele aplikacji potrzebuje tylko warstwy trwałych danych, która w istocie
Rzeczywistość (1)
Wiele aplikacji potrzebuje tylko warstwy trwałych danych, która w istocie

Rzeczywistość (2)
Sprzymierzeńcem wszystkich wdrożonych technologii baz danych, w tym relacyjnych, jest
Rzeczywistość (2)
Sprzymierzeńcem wszystkich wdrożonych technologii baz danych, w tym relacyjnych, jest

Schemat pojęciowy a systemy relacyjne
System relacyjny jako back-end, tj. baza implementacyjna.
Schemat pojęciowy a systemy relacyjne
System relacyjny jako back-end, tj. baza implementacyjna.

Projektowanie logiczne
Termin oznaczający odwzorowanie modelu pojęciowego (np. encja-związek lub obiektowego) na
Projektowanie logiczne
Termin oznaczający odwzorowanie modelu pojęciowego (np. encja-związek lub obiektowego) na

Charakterystyka ilościowa danych
ZAJĘTOŚĆ PAMIĘCI (liczba wystąpień danych),
ZMIENNOŚĆ (spodziewany przyrost w czasie).
KLIENT
TOWAR
zakupił
Charakterystyki
Charakterystyka ilościowa danych
ZAJĘTOŚĆ PAMIĘCI (liczba wystąpień danych),
ZMIENNOŚĆ (spodziewany przyrost w czasie).
KLIENT
TOWAR
zakupił
Charakterystyki

Charakterystyka ilościowa procesów
OPERACJE ELEMENTARNE (FUNKCJE UŻYTKOWE),
TYP (on-line, batch),
CZĘSTOTLIWOŚĆ ZACHODZENIA
(ew.
Charakterystyka ilościowa procesów
OPERACJE ELEMENTARNE (FUNKCJE UŻYTKOWE),
TYP (on-line, batch),
CZĘSTOTLIWOŚĆ ZACHODZENIA
(ew.
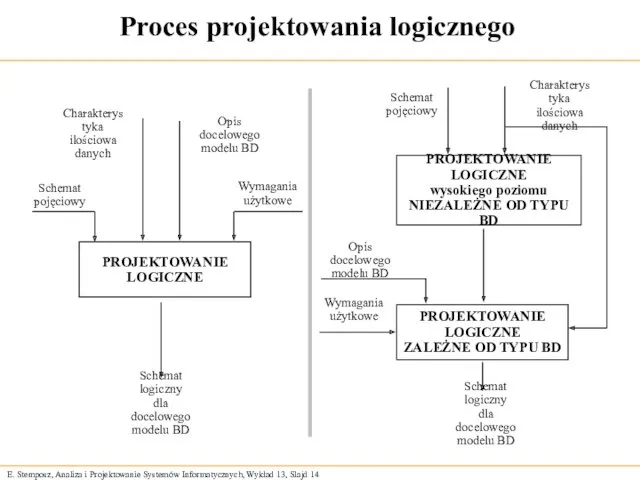
Proces projektowania logicznego
PROJEKTOWANIE
LOGICZNE
wysokiego poziomu
NIEZALEŻNE OD TYPU BD
PROJEKTOWANIE
LOGICZNE
ZALEŻNE OD TYPU BD
Schemat
pojęciowy
Charakterystyka
ilościowa danych
Opis
Proces projektowania logicznego
PROJEKTOWANIE
LOGICZNE
wysokiego poziomu
NIEZALEŻNE OD TYPU BD
PROJEKTOWANIE
LOGICZNE
ZALEŻNE OD TYPU BD
Schemat
pojęciowy
Charakterystyka
ilościowa danych
Opis

Odwzorowanie atrybutów powtarzalnych
Tabele relacyjne nie mogą przechowywać wielokrotnych wartości atrybutów. Model
Odwzorowanie atrybutów powtarzalnych
Tabele relacyjne nie mogą przechowywać wielokrotnych wartości atrybutów. Model
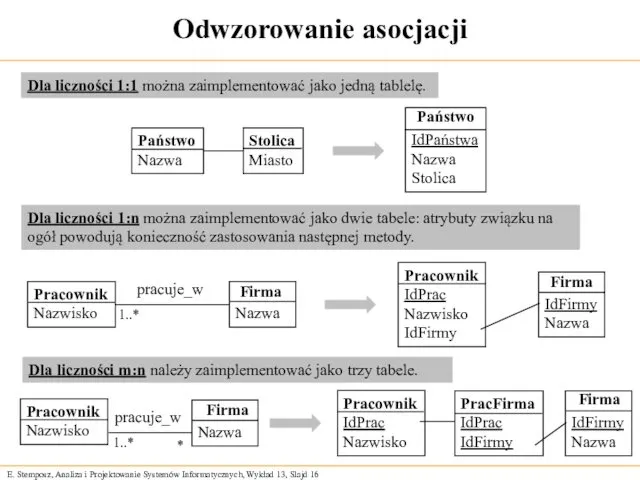
Odwzorowanie asocjacji
Dla liczności 1:1 można zaimplementować jako jedną tablelę.
Państwo
Nazwa
Stolica
Miasto
IdPaństwa
Nazwa
Stolica
Dla liczności
Odwzorowanie asocjacji
Dla liczności 1:1 można zaimplementować jako jedną tablelę.
Państwo
Nazwa
Stolica
Miasto
IdPaństwa
Nazwa
Stolica
Dla liczności

Odwzorowanie złożonych obiektów
Podstawowa metoda odwzorowania obiektów złożonych polega na spłaszczaniu ich
Odwzorowanie złożonych obiektów
Podstawowa metoda odwzorowania obiektów złożonych polega na spłaszczaniu ich

Odwzorowanie metod/operacji
Model relacyjny nie przewiduje specjalnych środków.
Najczęściej są one odwzorowane na
Odwzorowanie metod/operacji
Model relacyjny nie przewiduje specjalnych środków.
Najczęściej są one odwzorowane na
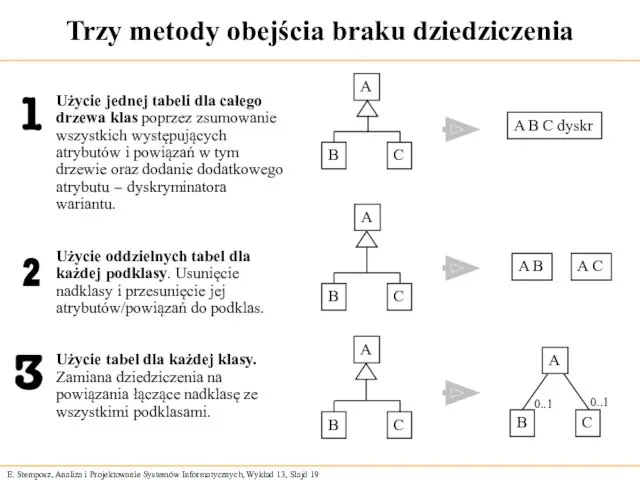
Trzy metody obejścia braku dziedziczenia
Użycie jednej tabeli dla całego drzewa klas
Trzy metody obejścia braku dziedziczenia
Użycie jednej tabeli dla całego drzewa klas
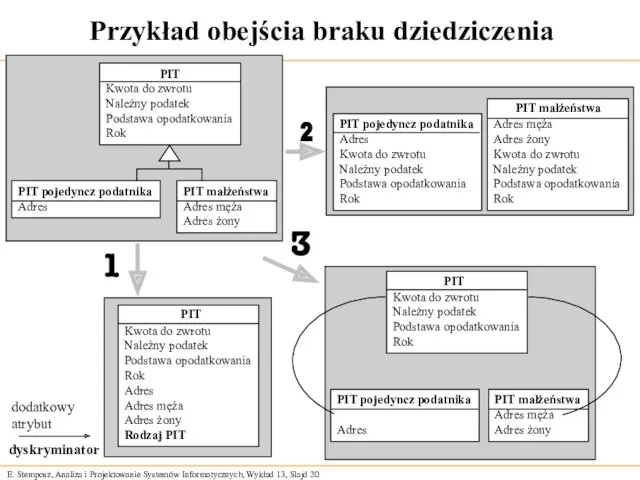
Przykład obejścia braku dziedziczenia
Kwota do zwrotu
Należny podatek
Podstawa opodatkowania
Rok
PIT pojedyncz podatnika
Adres
PIT małżeństwa
Adres
Przykład obejścia braku dziedziczenia
Kwota do zwrotu
Należny podatek
Podstawa opodatkowania
Rok
PIT pojedyncz podatnika
Adres
PIT małżeństwa
Adres
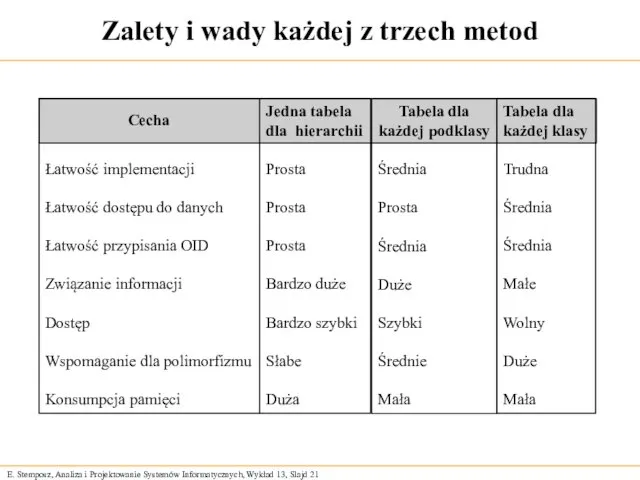
Zalety i wady każdej z trzech metod
Łatwość implementacji
Łatwość dostępu do danych
Łatwość
Zalety i wady każdej z trzech metod
Łatwość implementacji
Łatwość dostępu do danych
Łatwość

Prowadzenie słownika danych
Prowadzenie słownika jest konieczne dla przechowania informacji o sposobie
Prowadzenie słownika danych
Prowadzenie słownika jest konieczne dla przechowania informacji o sposobie

Zależność funkcyjna pomiędzy atrybutami: wartość atrybutu A2 zależy od wartości atrybutu
Zależność funkcyjna pomiędzy atrybutami: wartość atrybutu A2 zależy od wartości atrybutu
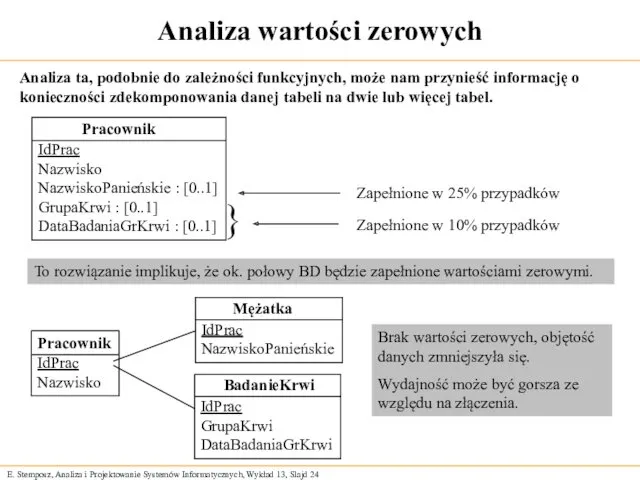
Analiza wartości zerowych
Analiza ta, podobnie do zależności funkcyjnych, może nam przynieść
Analiza wartości zerowych
Analiza ta, podobnie do zależności funkcyjnych, może nam przynieść

Analiza długich/złożonych wartości
Podobnie do wartości zerowych i zależności funkcyjnych, analiza długich
Analiza długich/złożonych wartości
Podobnie do wartości zerowych i zależności funkcyjnych, analiza długich
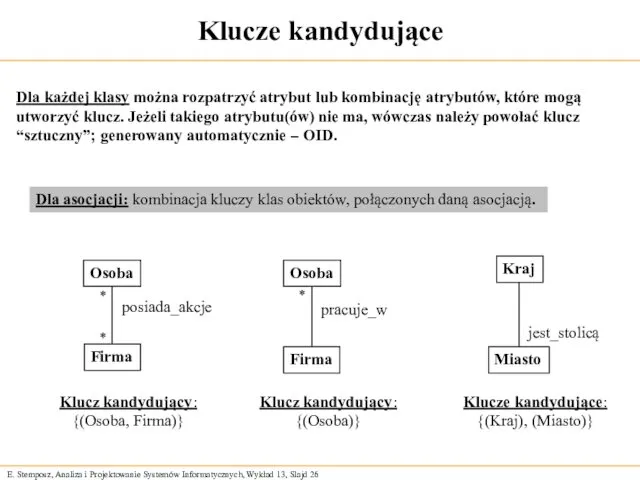
Klucze kandydujące
Firma
Osoba
posiada_akcje
Klucz kandydujący:
{(Osoba, Firma)}
Firma
Osoba
pracuje_w
Klucz kandydujący:
{(Osoba)}
Miasto
Kraj
jest_stolicą
Klucze kandydujące:
{(Kraj), (Miasto)}
Dla każdej klasy można rozpatrzyć
Klucze kandydujące
Firma
Osoba
posiada_akcje
Klucz kandydujący:
{(Osoba, Firma)}
Firma
Osoba
pracuje_w
Klucz kandydujący:
{(Osoba)}
Miasto
Kraj
jest_stolicą
Klucze kandydujące:
{(Kraj), (Miasto)}
Dla każdej klasy można rozpatrzyć

Wybór klucza
Może być wiele kluczy kandydujących, ale tylko jeden klucz główny.
Nazwisko
Data_ur
Nr_PESEL
Nr_prac
Nr_na_wydziale
Id_wydziału
1
2
3
4
Nazwisko
Wybór klucza
Może być wiele kluczy kandydujących, ale tylko jeden klucz główny.
Nazwisko
Data_ur
Nr_PESEL
Nr_prac
Nr_na_wydziale
Id_wydziału
1
2
3
4
Nazwisko
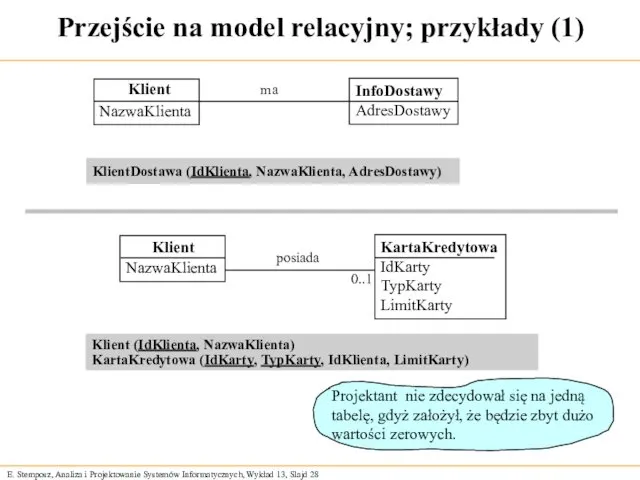
Przejście na model relacyjny; przykłady (1)
KlientDostawa (IdKlienta, NazwaKlienta, AdresDostawy)
Klient (IdKlienta, NazwaKlienta)
KartaKredytowa
Przejście na model relacyjny; przykłady (1)
KlientDostawa (IdKlienta, NazwaKlienta, AdresDostawy)
Klient (IdKlienta, NazwaKlienta)
KartaKredytowa
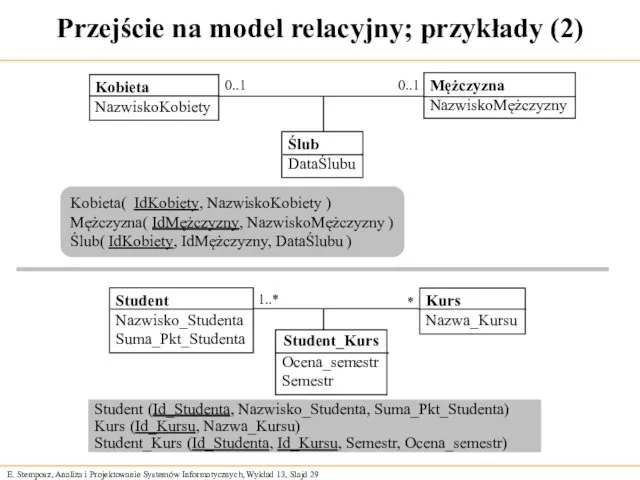
Przejście na model relacyjny; przykłady (2)
Ślub
DataŚlubu
Kobieta( IdKobiety, NazwiskoKobiety )
Mężczyzna( IdMężczyzny, NazwiskoMężczyzny
Przejście na model relacyjny; przykłady (2)
Ślub
DataŚlubu
Kobieta( IdKobiety, NazwiskoKobiety )
Mężczyzna( IdMężczyzny, NazwiskoMężczyzny
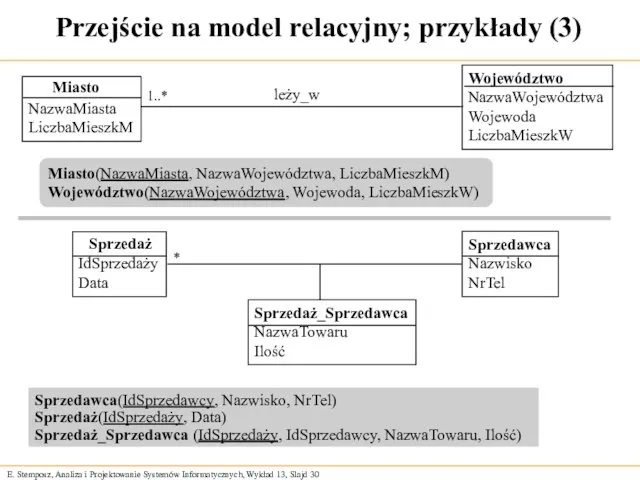
Przejście na model relacyjny; przykłady (3)
Sprzedawca(IdSprzedawcy, Nazwisko, NrTel)
Sprzedaż(IdSprzedaży, Data)
Sprzedaż_Sprzedawca (IdSprzedaży, IdSprzedawcy,
Przejście na model relacyjny; przykłady (3)
Sprzedawca(IdSprzedawcy, Nazwisko, NrTel)
Sprzedaż(IdSprzedaży, Data)
Sprzedaż_Sprzedawca (IdSprzedaży, IdSprzedawcy,
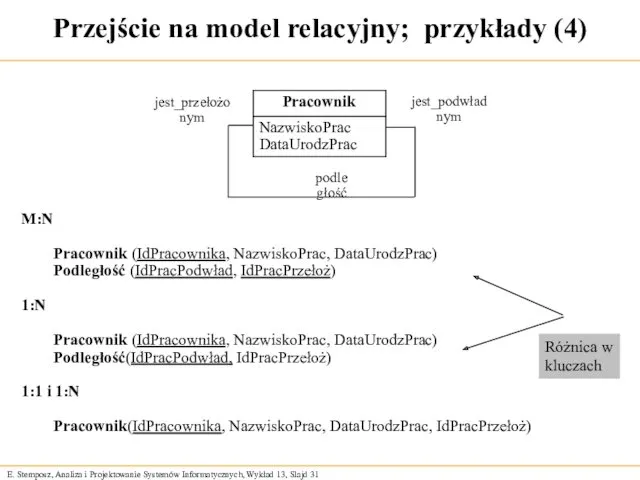
Przejście na model relacyjny; przykłady (4)
podległość
jest_podwładnym
jest_przełożonym
M:N
Pracownik (IdPracownika, NazwiskoPrac, DataUrodzPrac)
Podległość (IdPracPodwład, IdPracPrzełoż)
1:N
Pracownik
Przejście na model relacyjny; przykłady (4)
podległość
jest_podwładnym
jest_przełożonym
M:N
Pracownik (IdPracownika, NazwiskoPrac, DataUrodzPrac)
Podległość (IdPracPodwład, IdPracPrzełoż)
1:N
Pracownik
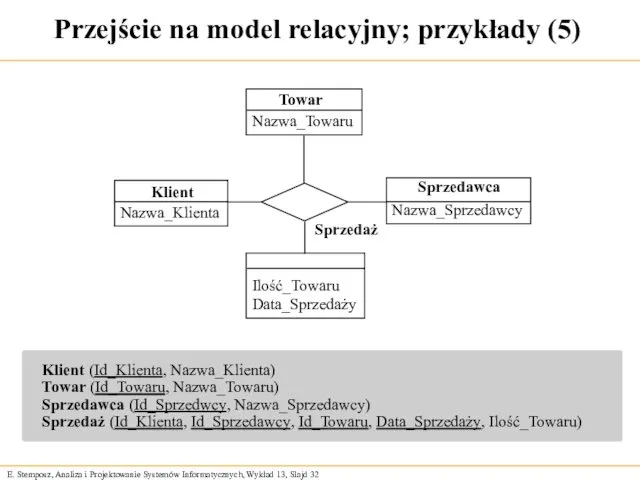
Przejście na model relacyjny; przykłady (5)
Klient (Id_Klienta, Nazwa_Klienta)
Towar (Id_Towaru, Nazwa_Towaru)
Sprzedawca (Id_Sprzedwcy,
Przejście na model relacyjny; przykłady (5)
Klient (Id_Klienta, Nazwa_Klienta)
Towar (Id_Towaru, Nazwa_Towaru)
Sprzedawca (Id_Sprzedwcy,
 И.Ф. Стравинский. Балет Петрушка
И.Ф. Стравинский. Балет Петрушка Национальный центр тестирования. Функции и действия представителей министерства образования и науки
Национальный центр тестирования. Функции и действия представителей министерства образования и науки Анатомия и физиология зрительного анализатора
Анатомия и физиология зрительного анализатора Географический туризм Камчатки
Географический туризм Камчатки Present Simple, Present Continuous, Future Tenses
Present Simple, Present Continuous, Future Tenses Знакомство с графическими возможностями табличного процессора MS Excel
Знакомство с графическими возможностями табличного процессора MS Excel Начало Великого княжества Литовского
Начало Великого княжества Литовского Смута в России в начале XVII века
Смута в России в начале XVII века презентация Ферменты
презентация Ферменты Первые шаги в науку. Веселое путешествие
Первые шаги в науку. Веселое путешествие Мультимедийная презентация для урока технологии в 3 классе по теме Изготовлении пингвина.3D.
Мультимедийная презентация для урока технологии в 3 классе по теме Изготовлении пингвина.3D. Использование методов наукометрии, библиометрии в библиотеках
Использование методов наукометрии, библиометрии в библиотеках Презентация Галогены
Презентация Галогены Электрическое оборудование вагонов 81-765/766/767. Альбом фотографий электрического оборудования вагоно
Электрическое оборудование вагонов 81-765/766/767. Альбом фотографий электрического оборудования вагоно Текстовый редактор . Теория и практика. 8 класс
Текстовый редактор . Теория и практика. 8 класс Презентация Работа с родителями
Презентация Работа с родителями Применение новых современных технологи в обучении и воспитании
Применение новых современных технологи в обучении и воспитании Государственный бюджет. Дефицит государственного бюджета и способы его финансирования. Государственный долг
Государственный бюджет. Дефицит государственного бюджета и способы его финансирования. Государственный долг Открытый урок в 5 классе
Открытый урок в 5 классе Mobile phone
Mobile phone Токсикозы . Гестозы
Токсикозы . Гестозы 20191028_proverka_adekvatnosti_modeli_10_klass
20191028_proverka_adekvatnosti_modeli_10_klass Схема поверхностных течений
Схема поверхностных течений Всемирная паутина
Всемирная паутина Какого фрагмента не хватает на картинке?
Какого фрагмента не хватает на картинке? Разговор о профессиях в средней группе детского сада
Разговор о профессиях в средней группе детского сада Инфографика: графическое представление сложной информации
Инфографика: графическое представление сложной информации Великая Отечественная война. Блокада Ленинграда
Великая Отечественная война. Блокада Ленинграда