- Расстояния между строками и меры близости

Содержание
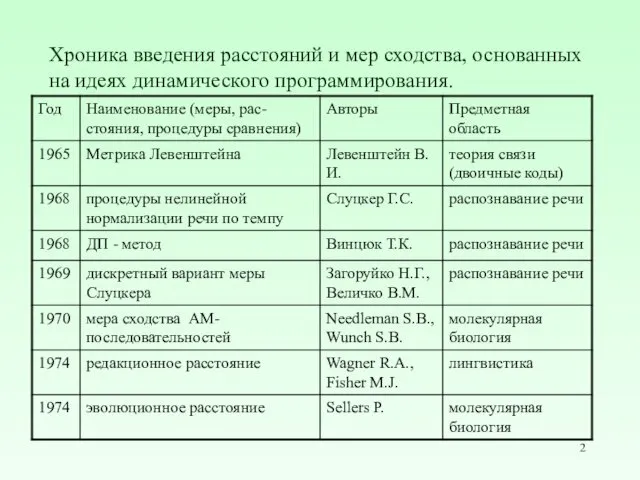
- 2. Хроника введения расстояний и мер сходства, основанных на идеях динамического программирования.
- 3. Схема динамического программирования для вычисления редакционного расстояния: d(0,0) = 0; d(i,0) = i, 1 ≤ i
- 4. Этап 1: заполнение матрицы динамического программирования. Этап 2: обратный ход. Построение выравнивания. ∀ d(i,j) на этапе
- 5. В общем случае число редакционных операций можно расширить, например, добавить перестановку соседних символов или блочные вставки
- 6. Возможные обобщения Поиск участков текста, близких к заданному образцу. Может формулироваться в виде: найти все фрагменты
- 7. Возможные обобщения: Поиск «похожих» фрагментов текста. Схема динамического программирования, но с начальными условиями: d[0, j] =
- 8. r (i, j) = max{0, r(i – 1, j – 1) + δ (ai, bj), r(i
- 9. Алгоритм Мазека-Патерсона. Для вычисления подматрицы D размера k × k должны быть известны начальные векторы и
- 10. Максимально длинная общая подпоследовательность (МДП, LCS) Последовательность U является подпоследовательностью А, если существует монотонно возрастающая последовательность
- 11. Вычисление длины МПД: L(0, j) = 0; L(i, 0) = 0; 0 ≤ i ≤ m;
- 12. Алгоритм Хишберга (Hirschberg D.S.) Пусть L*(i, j) – длина МДП текстов А[i + 1 : m]
- 13. Адаптивные алгоритмы вычисления длины МПД: Hunt - Shimanski Qi k – наим. j, такое что (L(A[1
- 14. Адаптивные алгоритмы вычисления длины МПД: Nakatsu-Kambayashi-Yajima Ri k – наиб. j, такое что (L(A[i : m],
- 15. Близкие задачи: задача о наикратчайшей надпоследовательности задача о медиане (string merging): построение текста Т3, сумма переходов
- 16. Меры сходства а) Пусть T1 и T2 два текста. Назовем совместной частотной характеристикой l-го порядка текстов
- 17. б) более сложный вариант, учитывающий частоты встречаемости l-грамм: где α – произвольная цепочка текстов T1 и
- 18. г) ранговая мера близости: Пусть l-граммы в Φ l(T1) и Φ l(T2) упорядочены по убыванию частот;
- 19. Обобщение подхода Лемпеля-Зива Представление S1 в виде конкатенации фрагментов из S2 назовем сложностным разложением S1 по
- 20. Относительная сложность и редакционное расстояние S2 = aaaa a cccc c ttttttttttttt – acacacac a atatatat
- 21. Трансформационное расстояние Трансформационое расстояние и относительная сложность идейно близки. Операция «вставка сегмента» используется, если посимвольная генерация
- 22. Инверсионное расстояние Инверсионное расстояние dI(π,σ) между последовательностями π и σ определяется минимальным числом инверсий, переводящих одну
- 23. Точки разрыва π0 = 0 and πN+1 = N + 1 π and σ − произвольные
- 25. Скачать презентацию
Хроника введения расстояний и мер сходства, основанных на идеях динамического программирования.
Хроника введения расстояний и мер сходства, основанных на идеях динамического программирования.

Схема динамического программирования для вычисления редакционного расстояния:
d(0,0) = 0;
d(i,0) = i,
Схема динамического программирования для вычисления редакционного расстояния:
d(0,0) = 0;
d(i,0) = i,

Этап 1: заполнение матрицы динамического программирования.
Этап 2: обратный ход. Построение
Этап 1: заполнение матрицы динамического программирования.
Этап 2: обратный ход. Построение

В общем случае число редакционных операций можно расширить, например, добавить перестановку
В общем случае число редакционных операций можно расширить, например, добавить перестановку
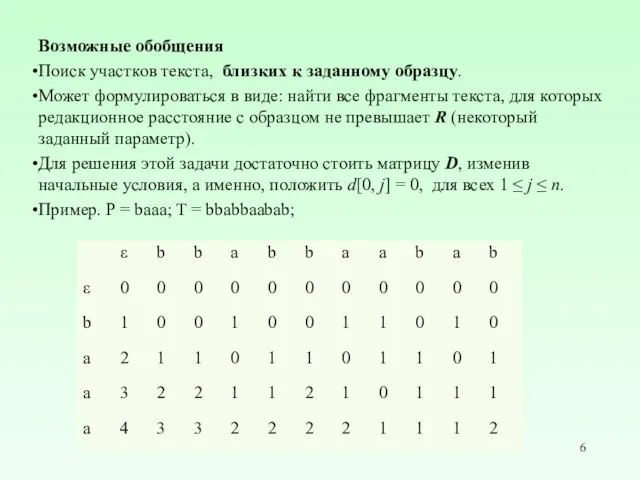
Возможные обобщения
Поиск участков текста, близких к заданному образцу.
Может формулироваться в
Возможные обобщения
Поиск участков текста, близких к заданному образцу.
Может формулироваться в

Возможные обобщения:
Поиск «похожих» фрагментов текста.
Схема динамического программирования, но с начальными условиями:
Возможные обобщения:
Поиск «похожих» фрагментов текста.
Схема динамического программирования, но с начальными условиями:
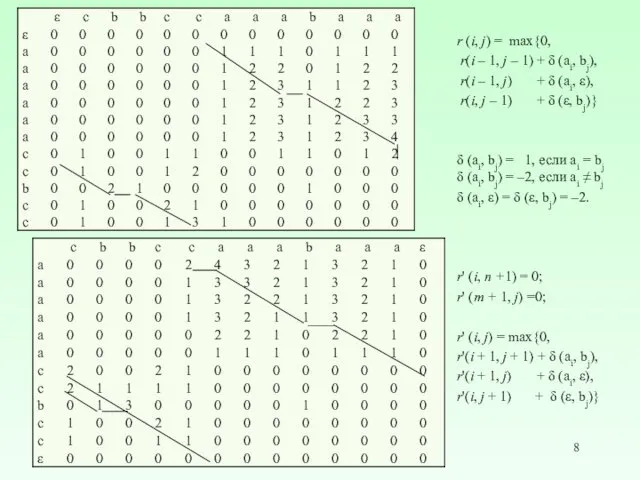
r (i, j) = max{0,
r(i – 1, j – 1)
r (i, j) = max{0,
r(i – 1, j – 1)

Алгоритм Мазека-Патерсона. Для вычисления подматрицы D размера k × k должны
Алгоритм Мазека-Патерсона. Для вычисления подматрицы D размера k × k должны

Максимально длинная общая подпоследовательность (МДП, LCS)
Последовательность U является подпоследовательностью А, если
Максимально длинная общая подпоследовательность (МДП, LCS)
Последовательность U является подпоследовательностью А, если

Вычисление длины МПД:
L(0, j) = 0; L(i, 0) = 0;
0
Вычисление длины МПД:
L(0, j) = 0; L(i, 0) = 0;
0
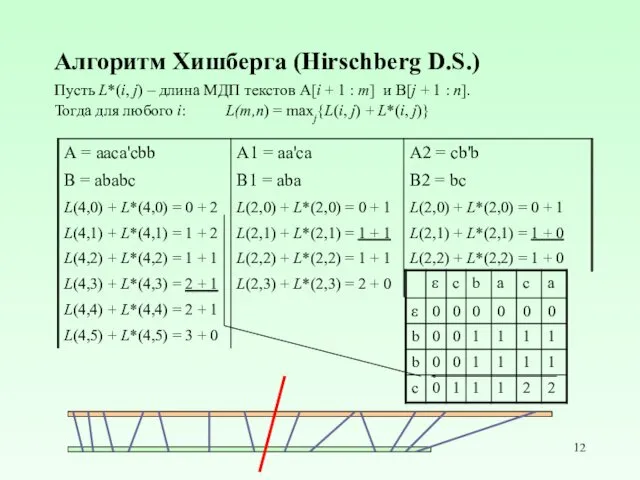
Алгоритм Хишберга (Hirschberg D.S.)
Пусть L*(i, j) – длина МДП текстов А[i
Алгоритм Хишберга (Hirschberg D.S.)
Пусть L*(i, j) – длина МДП текстов А[i

Адаптивные алгоритмы вычисления длины МПД:
Hunt - Shimanski
Qi k – наим. j,
Адаптивные алгоритмы вычисления длины МПД: Hunt - Shimanski Qi k – наим. j,

Адаптивные алгоритмы вычисления длины МПД:
Nakatsu-Kambayashi-Yajima
Ri k – наиб. j, такое что
Адаптивные алгоритмы вычисления длины МПД: Nakatsu-Kambayashi-Yajima Ri k – наиб. j, такое что

Близкие задачи:
задача о наикратчайшей надпоследовательности
задача о медиане (string merging): построение текста
Близкие задачи:
задача о наикратчайшей надпоследовательности
задача о медиане (string merging): построение текста

Меры сходства
а) Пусть T1 и T2 два текста.
Назовем
Меры сходства
а) Пусть T1 и T2 два текста.
Назовем

б) более сложный вариант, учитывающий частоты встречаемости l-грамм:
где α
б) более сложный вариант, учитывающий частоты встречаемости l-грамм:
где α

г) ранговая мера близости:
Пусть l-граммы в Φ l(T1) и Φ l(T2)
г) ранговая мера близости:
Пусть l-граммы в Φ l(T1) и Φ l(T2)
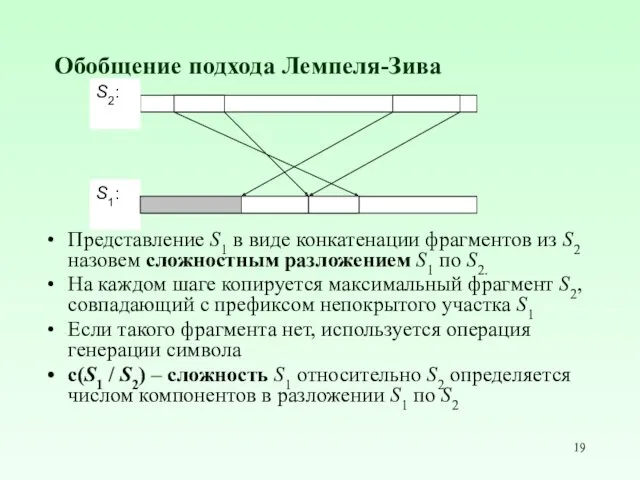
Обобщение подхода Лемпеля-Зива
Представление S1 в виде конкатенации фрагментов из S2
Обобщение подхода Лемпеля-Зива
Представление S1 в виде конкатенации фрагментов из S2

Относительная сложность и редакционное расстояние
S2 = aaaa a cccc c ttttttttttttt
Относительная сложность и редакционное расстояние
S2 = aaaa a cccc c ttttttttttttt
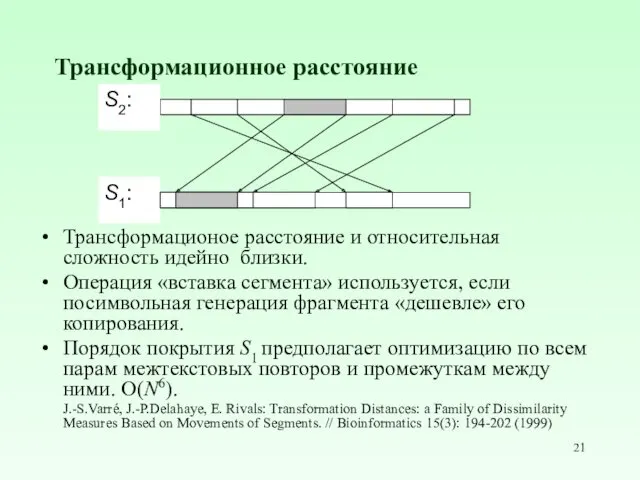
Трансформационное расстояние
Трансформационое расстояние и относительная сложность идейно близки.
Операция «вставка сегмента»
Трансформационное расстояние
Трансформационое расстояние и относительная сложность идейно близки.
Операция «вставка сегмента»

Инверсионное расстояние
Инверсионное расстояние dI(π,σ) между последовательностями π и σ определяется
Инверсионное расстояние
Инверсионное расстояние dI(π,σ) между последовательностями π и σ определяется

Точки разрыва
π0 = 0 and πN+1 = N + 1
π
Точки разрыва
π0 = 0 and πN+1 = N + 1
π
 Инфекционные заболевания и их классификация
Инфекционные заболевания и их классификация Экологическая безопасность как основа ЗОЖ
Экологическая безопасность как основа ЗОЖ Религия, мировые религии
Религия, мировые религии Контроль качества шероховатости поверхности при различных видах обработки
Контроль качества шероховатости поверхности при различных видах обработки Nice to meet you!
Nice to meet you! Богатства, отданные людям
Богатства, отданные людям Значение транспортного законодательства для страхования грузов и транспортных средств
Значение транспортного законодательства для страхования грузов и транспортных средств Исторические личности IX-XVII веков
Исторические личности IX-XVII веков Экологическая акция Ёлочка, живи!
Экологическая акция Ёлочка, живи! КТД Новогодняя открытка своими руками Новогодний хоровод
КТД Новогодняя открытка своими руками Новогодний хоровод Орфограмма в корне. Готовимся к ГИА
Орфограмма в корне. Готовимся к ГИА Вирус иммунодефицита (ВИЧ
Вирус иммунодефицита (ВИЧ Степенная функция
Степенная функция Альпийские виды лыжного спорта. Скоростной спуск
Альпийские виды лыжного спорта. Скоростной спуск Организация перевозок и управления на транспорте (по видам)
Организация перевозок и управления на транспорте (по видам) Требования безопасности при эксплуатации сосудов, работающих под давлением
Требования безопасности при эксплуатации сосудов, работающих под давлением Типы общественных зданий
Типы общественных зданий терминальные состояния
терминальные состояния Построение (формы) музыки
Построение (формы) музыки Шұжық өндірісі
Шұжық өндірісі Каждой пичужке - моя кормушка
Каждой пичужке - моя кормушка Наш посёлок - Мизур Диск
Наш посёлок - Мизур Диск По одёжке встречают.
По одёжке встречают. Проект Лента Мёбиуса
Проект Лента Мёбиуса Информационный проект Чесма. История морского сражения
Информационный проект Чесма. История морского сражения Конкурс Хочу учиться так! Семинар мечты Финмонополия
Конкурс Хочу учиться так! Семинар мечты Финмонополия Развитие представлений о возникновении жизни на Земле
Развитие представлений о возникновении жизни на Земле Стили речи
Стили речи