- Разработка параллельных программ для систем с распределенной памятью

Содержание
- 2. СИСТЕМЫ С РАСПРЕДЕЛЕННОЙ ПАМЯТЬЮ Особенности систем с распределенной памятью
- 3. Распределенные системы (1) Мультикомпьютеры Кластерные системы (Clusters) Массивно-параллельные процессоры (MPP)
- 4. Распределенные системы (2) Своя оперативная память Своя операционная система Различные вычислительные мощности Неограниченное масштабирование
- 5. Распределенные системы (3) Возможно использовать только процессы Высокая стоимость коммуникаций
- 6. СОЗДАНИЕ РАСПРЕДЕЛЕННЫХ ПРИЛОЖЕНИЙ Способы создания распределенных программ
- 7. Распределенное приложение Распределенное приложение (программа) - множество одновременно выполняемых взаимодействующих процессов, которые могут выполняться на одном
- 8. Стоимость коммуникаций Выбор оптимальной топологии Минимизация количества связей Минимизация количества пересылок Минимизация размера сообщений Унификация и
- 9. Выбор технологии Специальные языки Erlang, Go и т.п. Общая шина сообщений RabbitMq и т.п. Высокоуровневые библиотеки
- 10. Специализированные языки Инкапсулируют сложность коммуникаций Основное внимание на прикладной задаче Простая запись математических алгоритмов Встроенные средства
- 11. Общая шина сообщений Инкапсулирует сложность коммуникаций Основное внимание на прикладной задаче Простая и очевидная схема взаимодействия
- 12. Высокоуровневые библиотеки Инкапсулируют сложность коммуникаций Основное внимание на прикладной задаче Асинхронность чаще реализуется вручную Произвольная схема
- 13. Низкоуровневые функции Сложность осуществления коммуникаций Гибкость осуществления коммуникаций Вероятная зависимость от платформы Произвольная схема взаимодействия
- 14. Combo? При разработке крупных систем зачастую используются разные подходы
- 15. ОСНОВЫ ТЕХНОЛОГИИ MPI Распараллеливание вычислительных алгоритмов с помощью MPI
- 16. Почему рассматриваем MPI? Позволяет раскрыть некоторые особенности реализации более высокоуровневых решений, а также дает хорошее представление
- 17. MPI «The MPI standard includes point-to-point message-passing, collective communications, group and communicator concepts, process topologies, environmental
- 18. Концепция MPI Определяет API и протокол обмена сообщениями между процессами распределенного приложения Базовые понятия касаются преимущественно
- 19. Коммуникатор
- 20. Виртуальные топологии Есть возможность задавать виртуальную топологию связей между процессами, которая будет отражать логическую взаимосвязь процессов
- 21. Структура кода MPI-процесса #include void main(int argc, char *argv[]) { MPI_Init(&argc, &argv); MPI_Finalize(); }
- 22. Ранг и количество процессов #include void main(int argc, char *argv[]) { MPI_Init(&argc, &argv); int rank, size;
- 23. Передача и прием сообщений int MPI_Send( void* buffer, int count, MPI_Datatype type, int dest, int tag,
- 24. Корневой процесс #include void main(int argc, char *argv[]) { int rank, size; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank);
- 25. Редукция Передача данных от всех процессов одному процессу (обычно корневому процессу) int MPI_Reduce( void* sendBuffer, void*
- 26. Барьерная синхронизация Точка синхронизации, которую должны достигнуть все процессы, прежде чем продолжат свое выполнение int MPI_Barrier(MPI_Comm
- 27. Время выполнения double startTime = MPI_Wtime();; double stopTime = MPI_Wtime();; double elapsed = stopTime - startTime;
- 28. Пример вычислений void CalculatePi(int rank, int size, int n) { double pi; MPI_Bcast(&n, 1, MPI_INT, 0,
- 30. Скачать презентацию

СИСТЕМЫ С РАСПРЕДЕЛЕННОЙ ПАМЯТЬЮ
Особенности систем с распределенной памятью
СИСТЕМЫ С РАСПРЕДЕЛЕННОЙ ПАМЯТЬЮ
Особенности систем с распределенной памятью

Распределенные системы (1)
Мультикомпьютеры
Кластерные системы (Clusters)
Массивно-параллельные процессоры (MPP)
Распределенные системы (1)
Мультикомпьютеры
Кластерные системы (Clusters)
Массивно-параллельные процессоры (MPP)

Распределенные системы (2)
Своя оперативная память
Своя операционная система
Различные вычислительные мощности
Неограниченное масштабирование
Распределенные системы (2)
Своя оперативная память
Своя операционная система
Различные вычислительные мощности
Неограниченное масштабирование

Распределенные системы (3)
Возможно использовать только процессы
Высокая стоимость коммуникаций
Распределенные системы (3)
Возможно использовать только процессы
Высокая стоимость коммуникаций

СОЗДАНИЕ РАСПРЕДЕЛЕННЫХ ПРИЛОЖЕНИЙ
Способы создания распределенных программ
СОЗДАНИЕ РАСПРЕДЕЛЕННЫХ ПРИЛОЖЕНИЙ
Способы создания распределенных программ

Распределенное приложение
Распределенное приложение (программа) - множество одновременно выполняемых взаимодействующих процессов, которые
Распределенное приложение
Распределенное приложение (программа) - множество одновременно выполняемых взаимодействующих процессов, которые

Стоимость коммуникаций
Выбор оптимальной топологии
Минимизация количества связей
Минимизация количества пересылок
Минимизация размера сообщений
Унификация и
Стоимость коммуникаций
Выбор оптимальной топологии
Минимизация количества связей
Минимизация количества пересылок
Минимизация размера сообщений
Унификация и

Выбор технологии
Специальные языки
Erlang, Go и т.п.
Общая шина сообщений
RabbitMq и т.п.
Высокоуровневые библиотеки
WCF
Выбор технологии
Специальные языки
Erlang, Go и т.п.
Общая шина сообщений
RabbitMq и т.п.
Высокоуровневые библиотеки
WCF

Специализированные языки
Инкапсулируют сложность коммуникаций
Основное внимание на прикладной задаче
Простая запись математических алгоритмов
Встроенные
Специализированные языки
Инкапсулируют сложность коммуникаций
Основное внимание на прикладной задаче
Простая запись математических алгоритмов
Встроенные
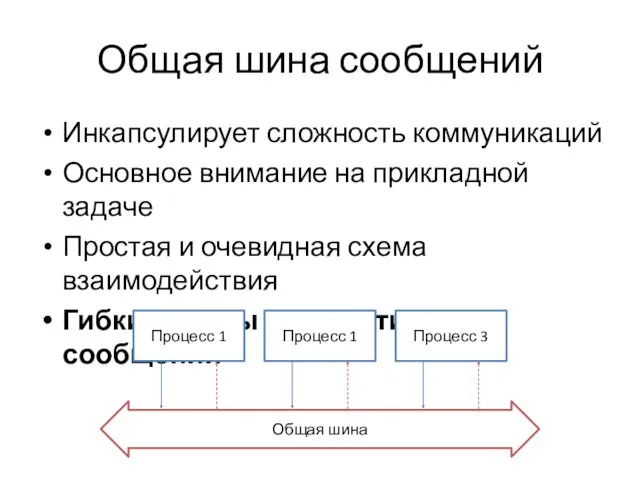
Общая шина сообщений
Инкапсулирует сложность коммуникаций
Основное внимание на прикладной задаче
Простая и очевидная
Общая шина сообщений
Инкапсулирует сложность коммуникаций
Основное внимание на прикладной задаче
Простая и очевидная

Высокоуровневые библиотеки
Инкапсулируют сложность коммуникаций
Основное внимание на прикладной задаче
Асинхронность чаще реализуется вручную
Произвольная
Высокоуровневые библиотеки
Инкапсулируют сложность коммуникаций
Основное внимание на прикладной задаче
Асинхронность чаще реализуется вручную
Произвольная

Низкоуровневые функции
Сложность осуществления коммуникаций
Гибкость осуществления коммуникаций
Вероятная зависимость от платформы
Произвольная схема взаимодействия
Низкоуровневые функции
Сложность осуществления коммуникаций
Гибкость осуществления коммуникаций
Вероятная зависимость от платформы
Произвольная схема взаимодействия

Combo?
При разработке крупных систем зачастую используются разные подходы
Combo?
При разработке крупных систем зачастую используются разные подходы

ОСНОВЫ ТЕХНОЛОГИИ MPI
Распараллеливание вычислительных алгоритмов с помощью MPI
ОСНОВЫ ТЕХНОЛОГИИ MPI
Распараллеливание вычислительных алгоритмов с помощью MPI

Почему рассматриваем MPI?
Позволяет раскрыть некоторые особенности реализации более высокоуровневых решений, а
Почему рассматриваем MPI?
Позволяет раскрыть некоторые особенности реализации более высокоуровневых решений, а

MPI
«The MPI standard includes point-to-point message-passing, collective communications, group and communicator
MPI
«The MPI standard includes point-to-point message-passing, collective communications, group and communicator

Концепция MPI
Определяет API и протокол обмена сообщениями между процессами распределенного приложения
Базовые
Концепция MPI
Определяет API и протокол обмена сообщениями между процессами распределенного приложения
Базовые
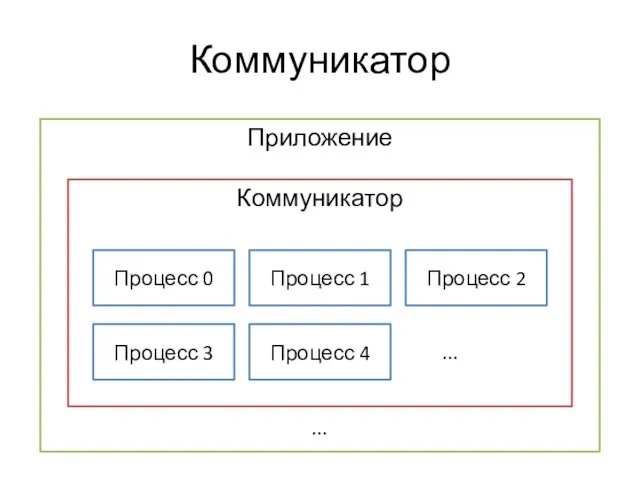
Коммуникатор
Коммуникатор

Виртуальные топологии
Есть возможность задавать виртуальную топологию связей между процессами, которая будет
Виртуальные топологии
Есть возможность задавать виртуальную топологию связей между процессами, которая будет
![Структура кода MPI-процесса #include void main(int argc, char *argv[]) { MPI_Init(&argc, &argv); MPI_Finalize(); }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/38592/slide-20.jpg)
Структура кода MPI-процесса
#include
void main(int argc, char *argv[])
{
<Программный код без использования
Структура кода MPI-процесса
#include
void main(int argc, char *argv[])
{
<Программный код без использования
![Ранг и количество процессов #include void main(int argc, char *argv[])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/38592/slide-21.jpg)
Ранг и количество процессов
#include
void main(int argc, char *argv[])
{
<Программный код без
Ранг и количество процессов
#include
void main(int argc, char *argv[])
{
<Программный код без

Передача и прием сообщений
int MPI_Send(
void* buffer,
int count,
MPI_Datatype type,
int dest,
int tag,
MPI_Comm comm
);
int
Передача и прием сообщений
int MPI_Send(
void* buffer,
int count,
MPI_Datatype type,
int dest,
int tag,
MPI_Comm comm
);
int
![Корневой процесс #include void main(int argc, char *argv[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/38592/slide-23.jpg)
Корневой процесс
#include
void main(int argc, char *argv[])
{
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD,
Корневой процесс
#include
void main(int argc, char *argv[])
{
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD,

Редукция
Передача данных от всех процессов одному процессу (обычно корневому процессу)
int MPI_Reduce(
void*
Редукция
Передача данных от всех процессов одному процессу (обычно корневому процессу)
int MPI_Reduce(
void*

Барьерная синхронизация
Точка синхронизации, которую должны достигнуть все процессы, прежде чем продолжат
Барьерная синхронизация
Точка синхронизации, которую должны достигнуть все процессы, прежде чем продолжат

Время выполнения
double startTime = MPI_Wtime();;
<Блок кода>
double stopTime = MPI_Wtime();;
double elapsed =
Время выполнения
double startTime = MPI_Wtime();;
<Блок кода>
double stopTime = MPI_Wtime();;
double elapsed =

Пример вычислений
void CalculatePi(int rank, int size, int n)
{
double pi;
MPI_Bcast(&n, 1, MPI_INT,
Пример вычислений
void CalculatePi(int rank, int size, int n)
{
double pi;
MPI_Bcast(&n, 1, MPI_INT,
 Образы романсов и песен русских композиторов. 6 класс
Образы романсов и песен русских композиторов. 6 класс Австралия
Австралия Метаболитикалық кома
Метаболитикалық кома Международный день борьбы со СПИДом - 1 декабря
Международный день борьбы со СПИДом - 1 декабря Викторина по произведениям Д.Роулинг Гарри Поттер
Викторина по произведениям Д.Роулинг Гарри Поттер Деление с остатком
Деление с остатком Григорий Остер - Детям
Григорий Остер - Детям Новый завет. Рождение и юность Марии
Новый завет. Рождение и юность Марии Аварии на радиационно-опасных объектах
Аварии на радиационно-опасных объектах Расчет смешивающих литейных бегунов с вертикально-вращающимися катками
Расчет смешивающих литейных бегунов с вертикально-вращающимися катками Пусть планета будет чистой. Проблема бытового мусора
Пусть планета будет чистой. Проблема бытового мусора Этапы развития молодежной работы на приходе
Этапы развития молодежной работы на приходе Химическое равновесие. Необратимые и обратимые реакции
Химическое равновесие. Необратимые и обратимые реакции Некариозные поражения, возникающие после прорезывания зуба. Этиология, клиника, диагностика, лечение
Некариозные поражения, возникающие после прорезывания зуба. Этиология, клиника, диагностика, лечение Проект благоустройства набережной Москва-реки в жилом квартале в городском округе Звенигород
Проект благоустройства набережной Москва-реки в жилом квартале в городском округе Звенигород Тригонометрические функции и их свойства
Тригонометрические функции и их свойства Фармакотерапия в акушерстве
Фармакотерапия в акушерстве Чорноморські дельфіни
Чорноморські дельфіни Тепловые двигатели и нагнетатели. Центробежные компрессоры
Тепловые двигатели и нагнетатели. Центробежные компрессоры Средства измерений, основные понятия и классификация. Метрологические характеристики средств измерений. Лекция 4
Средства измерений, основные понятия и классификация. Метрологические характеристики средств измерений. Лекция 4 Модульное оригами Ромашка
Модульное оригами Ромашка Детская игровая площадка - Остров сокровищ
Детская игровая площадка - Остров сокровищ Группы крови
Группы крови Четвероногие герои
Четвероногие герои Презентация Рельеф Южной Америки
Презентация Рельеф Южной Америки Правовые основы военной службы
Правовые основы военной службы Сертификация
Сертификация Для коллажа
Для коллажа