- Робота з суперкомп’ютером Інституту кібернетики Нан України

Содержание
- 2. 1. Загальні відомості Суперкомп’ютер – спеціалізована обчислювальна машина, яка значно переважає за своїми параметрами та швидкістю
- 3. Основним завданням суперкомп’ютера є запуск на ньому паралельних програм, тобто програм, призначених для запуску одразу на
- 4. Сайт суперкомп’ютера Інституту кібернетики НАН України – http://icybcluster.org.ua/
- 5. Різноманітна інформація про обчислювальний кластер знаходиться у розділі «Документація»
- 6. Найбільш корисним є розділ «Інструкція для користувачів»
- 7. На жаль, сайт суперкомп’ютера не є надто зручним, а матеріали сайту часто не дублюються між різними
- 8. Суперкомп’ютер Інституту кібернетики складається з чотирьох обчислювальних кластерів: СКІТ-1, СКІТ-2, СКІТ-3, СКІТ-4. З них перші два
- 9. СКІТ-4 – 28-вузловий кластер на 16-ядерних процесорах Intel Xeon E5-2600. Тактова частота – 2,6 ГГц. Число
- 10. 2. Про паралельні технології Існує декілька способів зайняти обчислювальні потужності кластера: 1. Запускання багатьох однопроцесорних завдань.
- 11. Якщо звертання до таких підзадач становить більшу частину обчислювальних операцій програми, то використання такої паралельної бібліотеки
- 12. На суперкомп’ютері встановлені компілятори мов C, C++ та Fortran. Можна встановлювати компілятори й інших мов, але
- 13. Суперкомп’ютер підтримує такі паралельні технології: 1. MPI. Програмний інтерфейс для передачі інформації, який дозволяє обмінюватися повідомленнями
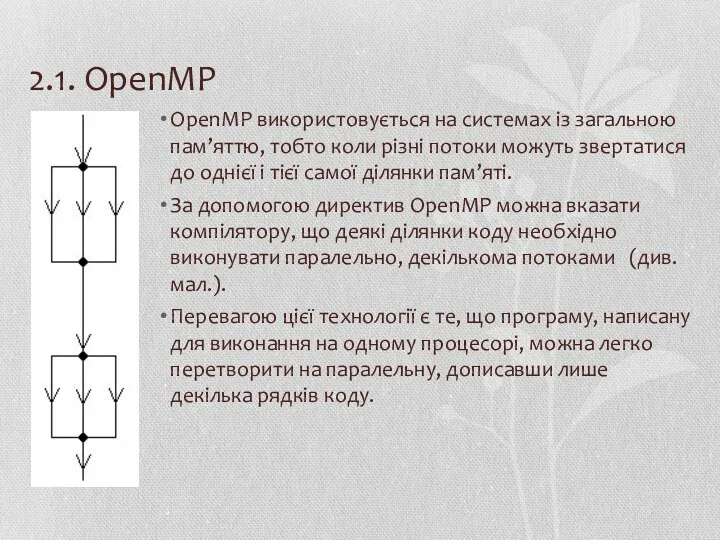
- 14. 2.1. OpenMP OpenMP використовується на системах із загальною пам’яттю, тобто коли різні потоки можуть звертатися до
- 15. OpenMP підтримується, зокрема, такими компіляторами: компілятори GCC, починаючи з версії 4.2; Visual C++ 2005 та 2008
- 17. У код послідовної програми вставлено лише одну стрічку: #pragma omp parallel for private(x) reduction(+:sum) – і
- 18. Інструкція parallel вказує на те, що код, записаний у наступному блоці виконуватиметься одночасно усіма потоками. Інструкція
- 19. 2.2. MPI Message Passing Interface (MPI) використовується на системах з роздільною пам’яттю, коли кожному процесору виділено
- 20. MPI є найбільш розповсюдженим стандартом інтерфейсу обміну даними в паралельному програмуванні та є найбільш природною технологією
- 21. Для порівняння технологій знову наводиться програма обчислення числа π, але вже з використанням MPI.
- 22. Деякі пояснення: Абсолютно усі команди MPI мають знаходитися між функціями MPI_Init, у яку передаються параметри командного
- 23. Після виконання функції MPI_Init створюється група потоків, кожний з яких виконуватиме один і той самий код,
- 24. На відміну від OpenMP, де компілятор сам забезпечував розподіл ітерацій циклу між потоками, у MPI контроль
- 25. У цьому прикладі механізм передачі повідомлень застосовано неявно – у функціях MPI_Bcast та MPI_Reduce. Стандарт MPI
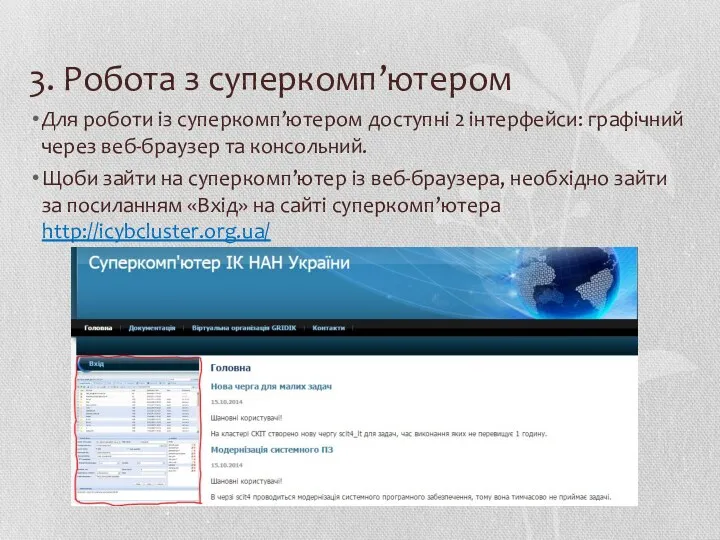
- 26. 3. Робота з суперкомп’ютером Для роботи із суперкомп’ютером доступні 2 інтерфейси: графічний через веб-браузер та консольний.
- 27. Необхідно буде ввести облікові дані:
- 28. Відкриється наступна сторінка:
- 29. Зверху розташоване меню, звідки можна перемикатися між різними вікнами стану суперкомп’ютера. На відкритій закладці «Запуск задач»
- 30. У Windows доводиться користуватися сторонніми програмними засобами, наприклад, PuTTY (http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html)
- 31. У полі Host Name необхідно ввести адресу icybcluster.org.ua та натиснути кнопку Open, після чого відкриється наступне
- 32. Необхідно ввести логін та пароль, після чого можна буде працювати із суперкомп’ютером:
- 33. На суперкомп’ютері встановлена операційна система CentOS Linux, тому у консольному режимі працюють усі стандартні команди Linux,
- 34. Папка /home/users/pmchnu є домашньою, тобто зайшовши під іменем pmchnu, користувач отримує повний доступ над файлами у
- 35. Щоби подивитися на завантаженість черг у графічному режимі, треба зайти на закладку «Ресурси»:
- 36. У консольному режимі треба виконати команду sinfo:
- 37. Щоби подивитися на список задач, які чекають своєї черги, треба зайти на закладку «Задачі»:
- 38. У консольному режимі цьому відповідає команда squeue:
- 39. 3.1. Обмін файлами Щоби завантажити деякий файл із сервера у графічному режимі, потрібно виділити необхідні файли
- 40. У Windows необхідно встановити додатковий SCP-клієнт, наприклад, WinSCP:
- 41. Відкриється наступне вікно:
- 42. WinSCP відкриває одразу два дерева вибору файлів: на локальному комп’ютері та на суперкомп’ютері. За допомогою кнопок
- 43. 3.2. Запуск MPI-програм Щоби запускати свої завдання на суперкомп’ютері, необхідно зробити 3 речі: Завантажити на сервер
- 44. Спочатку розглянемо запуск програм у консольному режимі. На жаль, на керуючому вузлі, який одразу доступний для
- 45. По виділенні ресурсів необхідно з’єднатися із цим вузлом за допомогою команди ssh. У наведеному вище випадку
- 46. Для того щоб підтягнути усі необхідні заголовні файли та файли бібліотек, адміністраторами суперкомп’ютера були розроблені спеціальні
- 47. Скрипти для бібліотеки OpenMPI треба шукати у папці /opt/ompi Скрипти для бібліотеки MVAPICH2 треба шукати у
- 48. Як бачимо, у нашому прикладі компілятор видав попередження, яке втім ніяк не позначається на подальшій роботі
- 49. Скомпільований бінарний файл можна ставити у чергу виконання. Для цього можна виконати команду srun з наступним
- 50. Приклад запуску програми обчислення числа π у черзі lite_task з чотирма процесорами. Використано бібліотеку MVAPICH2 з
- 51. Більш розповсюдженим варіантом запуску задач є використання команди sbatch, яка виконує задачу у фоновому режимі. Синтаксис
- 52. Приклад запуску програми обчислення числа π у черзі lite_task з чотирма процесорами. Використано бібліотеку OpenMPI з
- 53. За станом виконання задачі можна стежити, виконавши команду squeue: Якщо треба відмінити завдання, то виконується команда
- 54. Також слідкувати за цим можна на сайті, попередньо натиснувши на кнопку «Оновити» у третьому зверху рядку:
- 55. Дослідити вміст цього файлу можна за допомогою команди cat:
- 56. З сайту також можна подивитись на вміст цього файлу, попередньо натиснувши кнопку «Оновити»
- 57. Запускати задачу можна і з веб-інтерфейсу. Форма запуску на закладці «Запуск задач» є оболонкою для команди
- 58. Запуск з форми відбувається таким чином: При цьому у каталозі, звідки було запущено задачу, створюється папка
- 59. 3.3. Запуск OpenMP-програм Щоби скомпілювати OpenMP-програму, як і у випадку з MPI, необхідно з’єднатися з додатковим
- 60. Найновіші компілятори Intel зберігаються у папці /opt/intel/composerxe/bin і мають такі назви: icc для мов C++ та
- 61. Виконання за допомогою команди srun виконується в 2 етапи: Спочатку встановлюється значення змінної середовища: export OMP_NUM_THREADS=
- 62. Виконання за допомогою команди sbatch потребує скрипта, який треба написати вручну. Найпростіше це зробити з веб-інтерфейсу.
- 63. Параметри c і n визначені у скрипті, тому залишилося вказати лише чергу завдань.
- 64. Для полегшення запуску OpenMP-програм можна написати нижченаведений скрипт. Наразі він зберігається у домашньому каталозі. Тоді виклик
- 65. Відповідним чином заповнюється і форма запуску:
- 66. 4. Деякі результати тестування Тестування проводились на комп’ютері з 4-ядерним процесором Intel Core i3-2310M та на
- 67. Програма розв’язування СЛАР з квадратною матрицею із застосуванням паралельного алгоритму LU-розкладу.
- 68. Програма розв’язування СЛАР з тридіагональною матрицею із застосуванням паралельного алгоритму редукції. Використовувалась бібліотека OpenMP. Як видно,
- 69. Програма розв’язування СЛАР з тридіагональною матрицею із застосуванням паралельного алгоритму прогонки. Використовувалась бібліотека MPI.
- 70. Програма розв’язування СЛАР з квадратною матрицею із застосуванням паралельного алгоритму LU-розкладу. Більша кількість тестів на суперкомп’ютері
- 72. Скачать презентацию

1. Загальні відомості
Суперкомп’ютер – спеціалізована обчислювальна машина, яка значно переважає за
1. Загальні відомості
Суперкомп’ютер – спеціалізована обчислювальна машина, яка значно переважає за

Основним завданням суперкомп’ютера є запуск на ньому паралельних програм, тобто програм,
Основним завданням суперкомп’ютера є запуск на ньому паралельних програм, тобто програм,
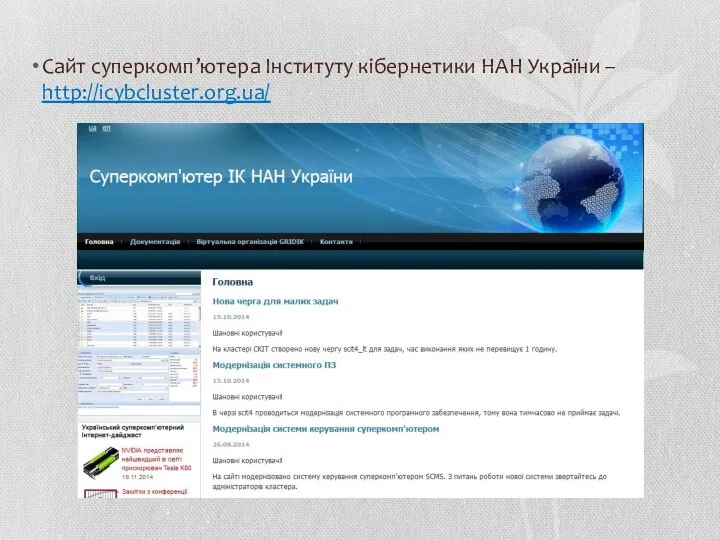
Сайт суперкомп’ютера Інституту кібернетики НАН України – http://icybcluster.org.ua/
Сайт суперкомп’ютера Інституту кібернетики НАН України – http://icybcluster.org.ua/
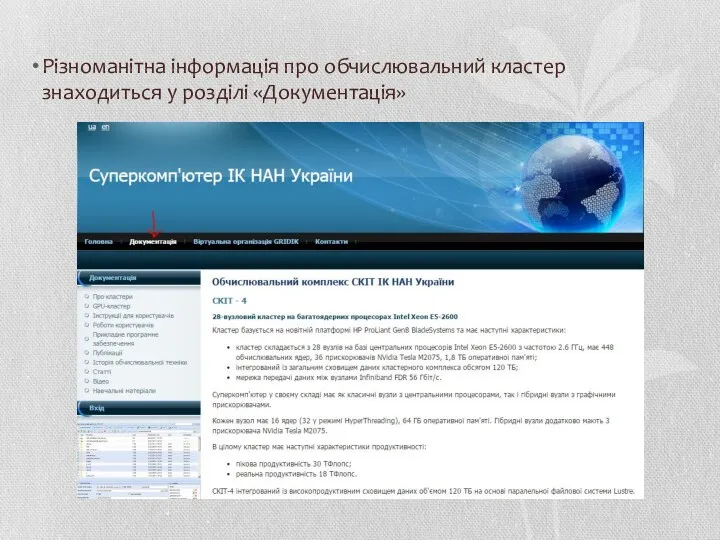
Різноманітна інформація про обчислювальний кластер знаходиться у розділі «Документація»
Різноманітна інформація про обчислювальний кластер знаходиться у розділі «Документація»
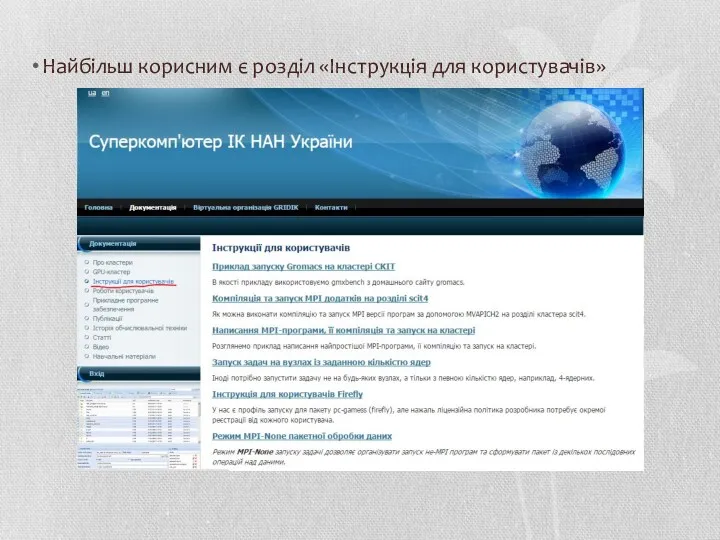
Найбільш корисним є розділ «Інструкція для користувачів»
Найбільш корисним є розділ «Інструкція для користувачів»
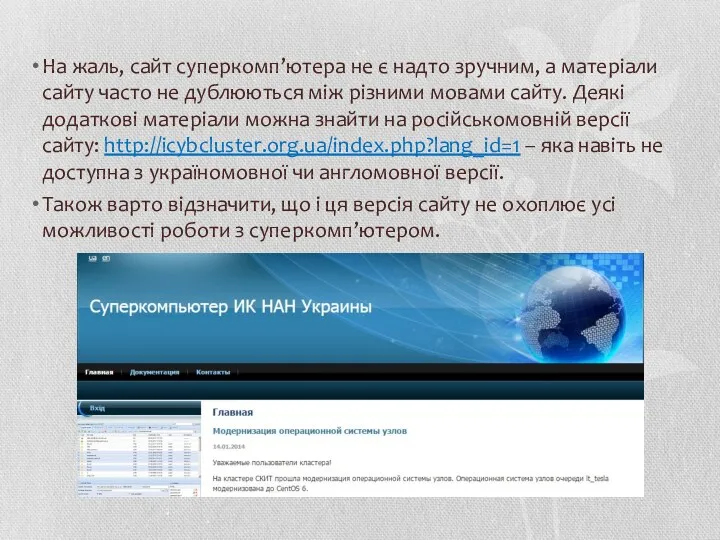
На жаль, сайт суперкомп’ютера не є надто зручним, а матеріали сайту
На жаль, сайт суперкомп’ютера не є надто зручним, а матеріали сайту

Суперкомп’ютер Інституту кібернетики складається з чотирьох обчислювальних кластерів: СКІТ-1, СКІТ-2, СКІТ-3,
Суперкомп’ютер Інституту кібернетики складається з чотирьох обчислювальних кластерів: СКІТ-1, СКІТ-2, СКІТ-3,

СКІТ-4 – 28-вузловий кластер на 16-ядерних процесорах Intel Xeon E5-2600.
Тактова частота
СКІТ-4 – 28-вузловий кластер на 16-ядерних процесорах Intel Xeon E5-2600.
Тактова частота

2. Про паралельні технології
Існує декілька способів зайняти обчислювальні потужності кластера:
1. Запускання
2. Про паралельні технології
Існує декілька способів зайняти обчислювальні потужності кластера:
1. Запускання

Якщо звертання до таких підзадач становить більшу частину обчислювальних операцій програми,
Якщо звертання до таких підзадач становить більшу частину обчислювальних операцій програми,

На суперкомп’ютері встановлені компілятори мов C, C++ та Fortran.
Можна встановлювати компілятори
На суперкомп’ютері встановлені компілятори мов C, C++ та Fortran.
Можна встановлювати компілятори

Суперкомп’ютер підтримує такі паралельні технології:
1. MPI. Програмний інтерфейс для передачі інформації,
Суперкомп’ютер підтримує такі паралельні технології:
1. MPI. Програмний інтерфейс для передачі інформації,
2.1. OpenMP
OpenMP використовується на системах із загальною пам’яттю, тобто коли різні
2.1. OpenMP
OpenMP використовується на системах із загальною пам’яттю, тобто коли різні

OpenMP підтримується, зокрема, такими компіляторами:
компілятори GCC, починаючи з версії 4.2;
Visual C++
OpenMP підтримується, зокрема, такими компіляторами:
компілятори GCC, починаючи з версії 4.2;
Visual C++


У код послідовної програми вставлено лише одну стрічку:
#pragma omp parallel for
У код послідовної програми вставлено лише одну стрічку:
#pragma omp parallel for

Інструкція parallel вказує на те, що код, записаний у наступному блоці
Інструкція parallel вказує на те, що код, записаний у наступному блоці

2.2. MPI
Message Passing Interface (MPI) використовується на системах з роздільною пам’яттю,
2.2. MPI
Message Passing Interface (MPI) використовується на системах з роздільною пам’яттю,

MPI є найбільш розповсюдженим стандартом інтерфейсу обміну даними в паралельному програмуванні
MPI є найбільш розповсюдженим стандартом інтерфейсу обміну даними в паралельному програмуванні

Для порівняння технологій знову наводиться програма обчислення числа π, але вже
Для порівняння технологій знову наводиться програма обчислення числа π, але вже

Деякі пояснення:
Абсолютно усі команди MPI мають знаходитися між функціями MPI_Init, у
Деякі пояснення:
Абсолютно усі команди MPI мають знаходитися між функціями MPI_Init, у

Після виконання функції MPI_Init створюється група потоків, кожний з яких виконуватиме
Після виконання функції MPI_Init створюється група потоків, кожний з яких виконуватиме

На відміну від OpenMP, де компілятор сам забезпечував розподіл ітерацій циклу
На відміну від OpenMP, де компілятор сам забезпечував розподіл ітерацій циклу

У цьому прикладі механізм передачі повідомлень застосовано неявно – у функціях
У цьому прикладі механізм передачі повідомлень застосовано неявно – у функціях
3. Робота з суперкомп’ютером
Для роботи із суперкомп’ютером доступні 2 інтерфейси: графічний
3. Робота з суперкомп’ютером
Для роботи із суперкомп’ютером доступні 2 інтерфейси: графічний
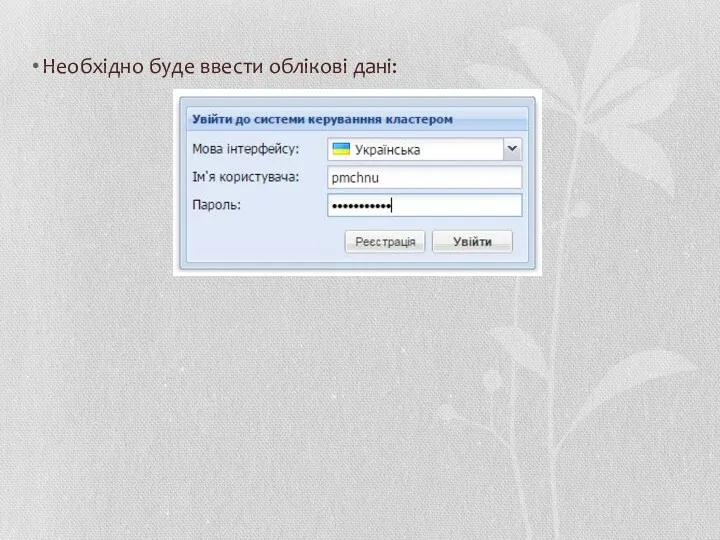
Необхідно буде ввести облікові дані:
Необхідно буде ввести облікові дані:
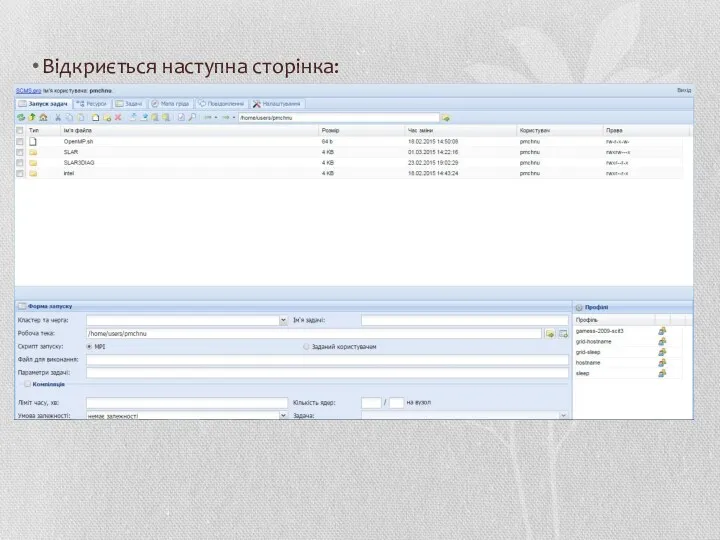
Відкриється наступна сторінка:
Відкриється наступна сторінка:

Зверху розташоване меню, звідки можна перемикатися між різними вікнами стану суперкомп’ютера.
На
Зверху розташоване меню, звідки можна перемикатися між різними вікнами стану суперкомп’ютера.
На
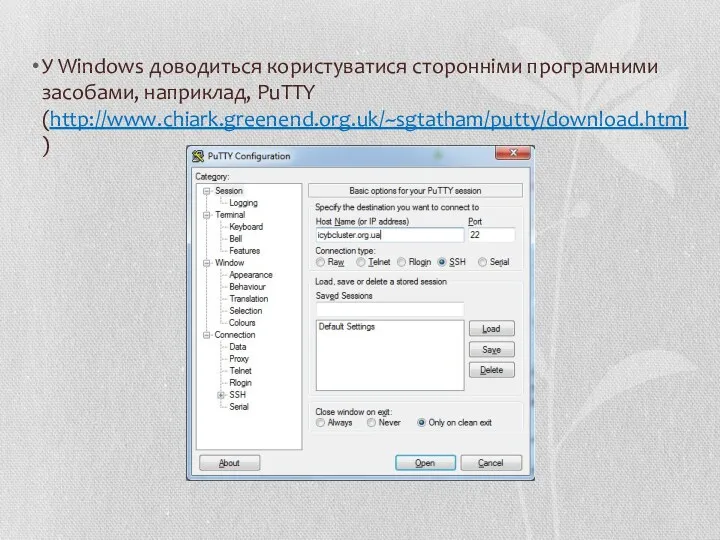
У Windows доводиться користуватися сторонніми програмними засобами, наприклад, PuTTY (http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html)
У Windows доводиться користуватися сторонніми програмними засобами, наприклад, PuTTY (http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html)
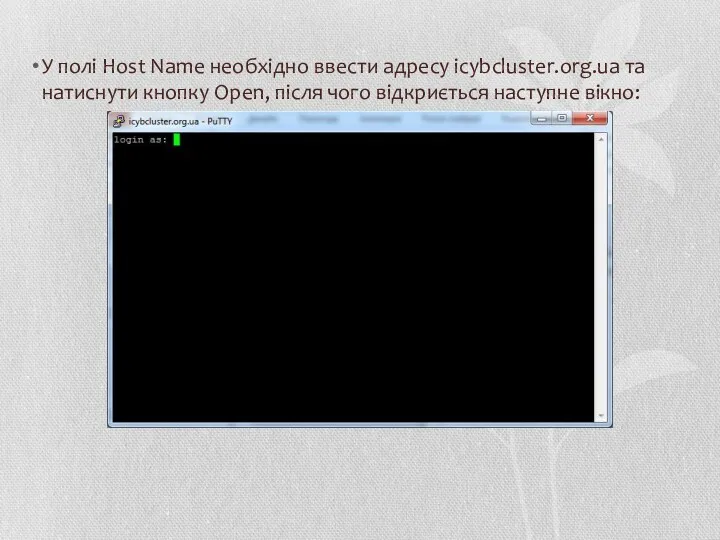
У полі Host Name необхідно ввести адресу icybcluster.org.ua та натиснути кнопку
У полі Host Name необхідно ввести адресу icybcluster.org.ua та натиснути кнопку
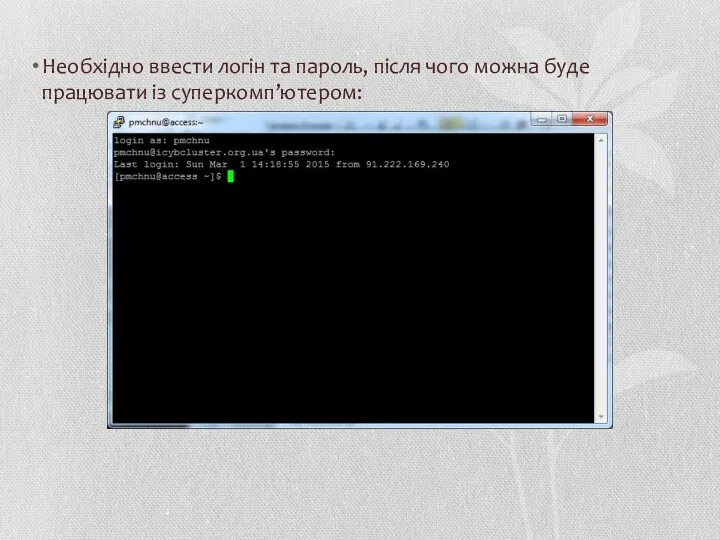
Необхідно ввести логін та пароль, після чого можна буде працювати із
Необхідно ввести логін та пароль, після чого можна буде працювати із
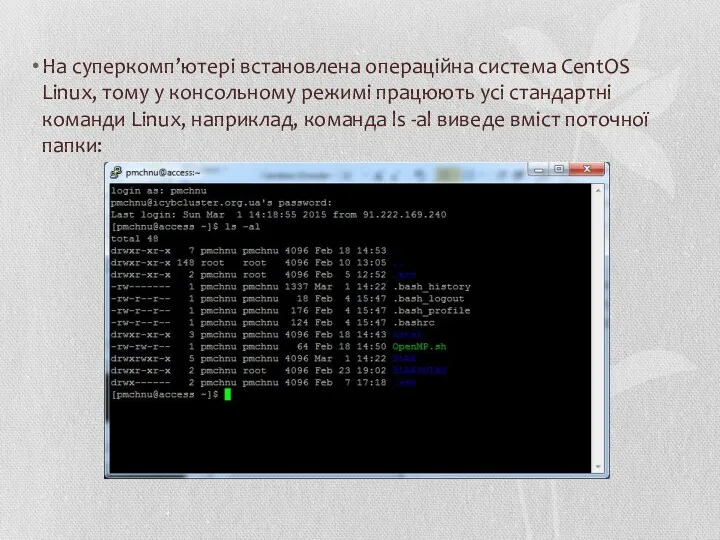
На суперкомп’ютері встановлена операційна система CentOS Linux, тому у консольному режимі
На суперкомп’ютері встановлена операційна система CentOS Linux, тому у консольному режимі

Папка /home/users/pmchnu є домашньою, тобто зайшовши під іменем pmchnu, користувач отримує
Папка /home/users/pmchnu є домашньою, тобто зайшовши під іменем pmchnu, користувач отримує
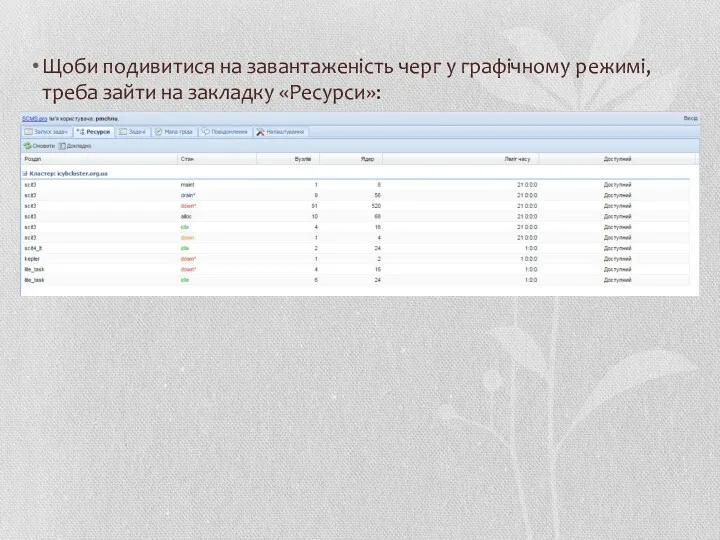
Щоби подивитися на завантаженість черг у графічному режимі, треба зайти на
Щоби подивитися на завантаженість черг у графічному режимі, треба зайти на
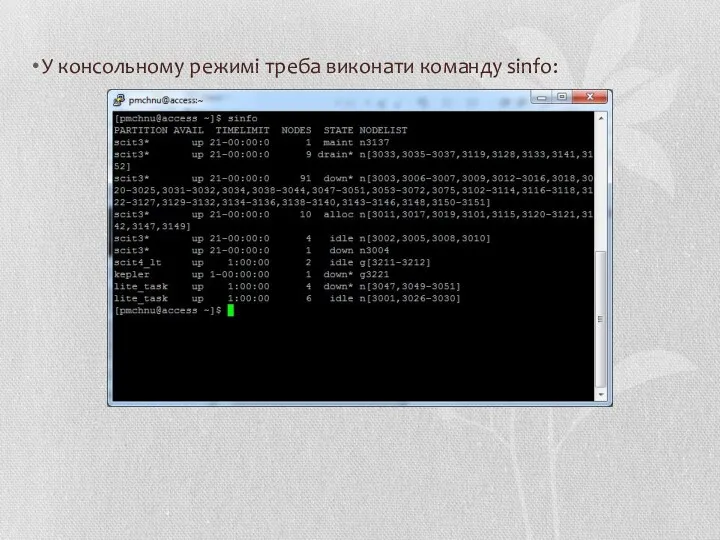
У консольному режимі треба виконати команду sinfo:
У консольному режимі треба виконати команду sinfo:
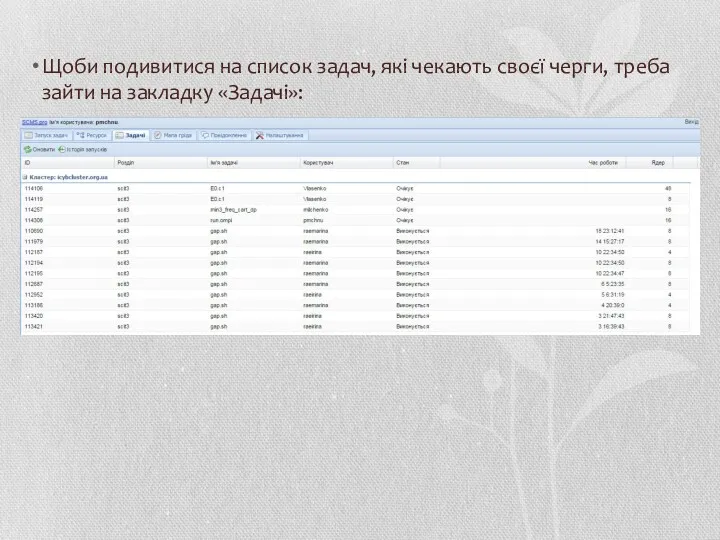
Щоби подивитися на список задач, які чекають своєї черги, треба зайти
Щоби подивитися на список задач, які чекають своєї черги, треба зайти
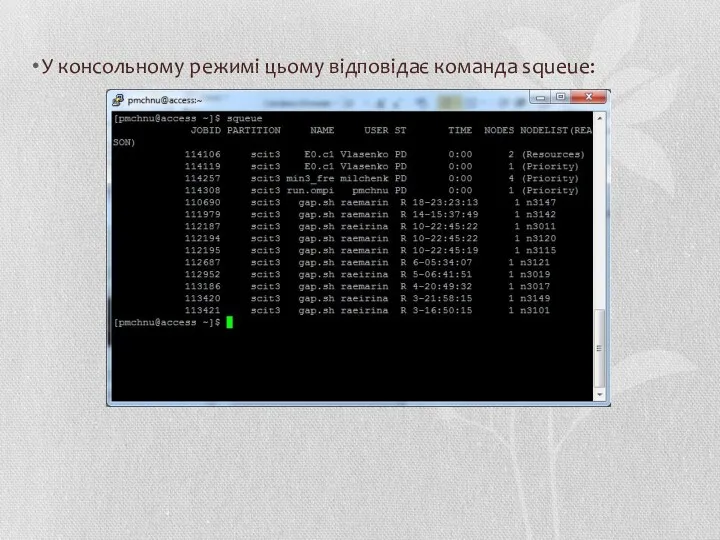
У консольному режимі цьому відповідає команда squeue:
У консольному режимі цьому відповідає команда squeue:
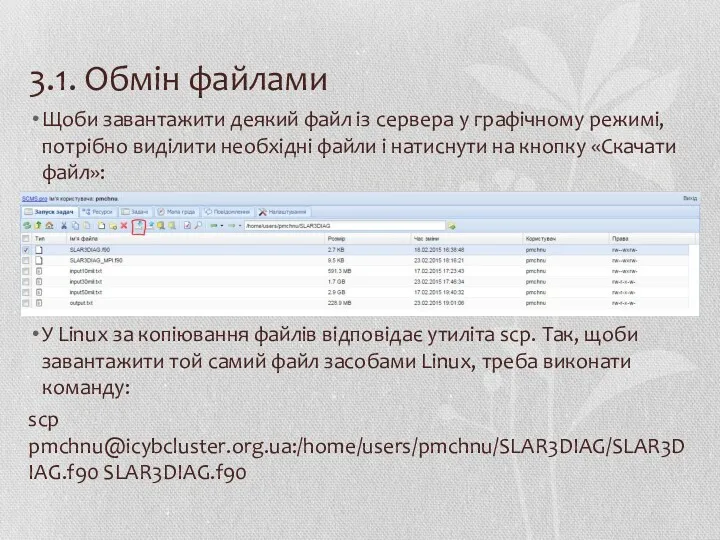
3.1. Обмін файлами
Щоби завантажити деякий файл із сервера у графічному режимі,
3.1. Обмін файлами
Щоби завантажити деякий файл із сервера у графічному режимі,
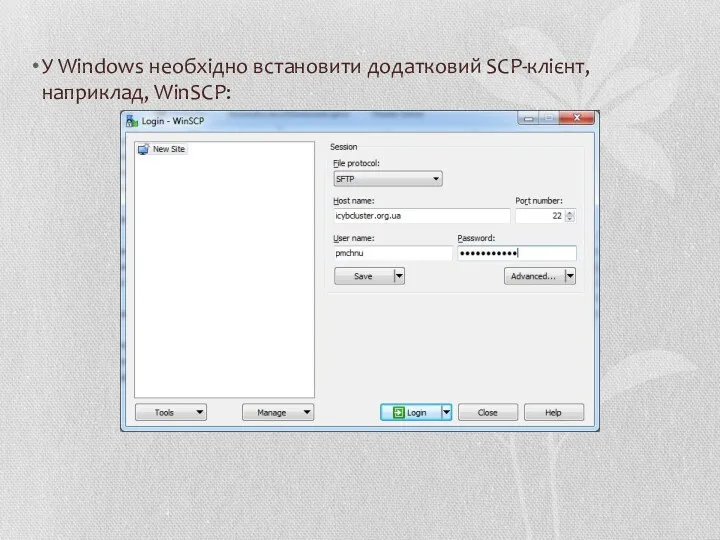
У Windows необхідно встановити додатковий SCP-клієнт, наприклад, WinSCP:
У Windows необхідно встановити додатковий SCP-клієнт, наприклад, WinSCP:
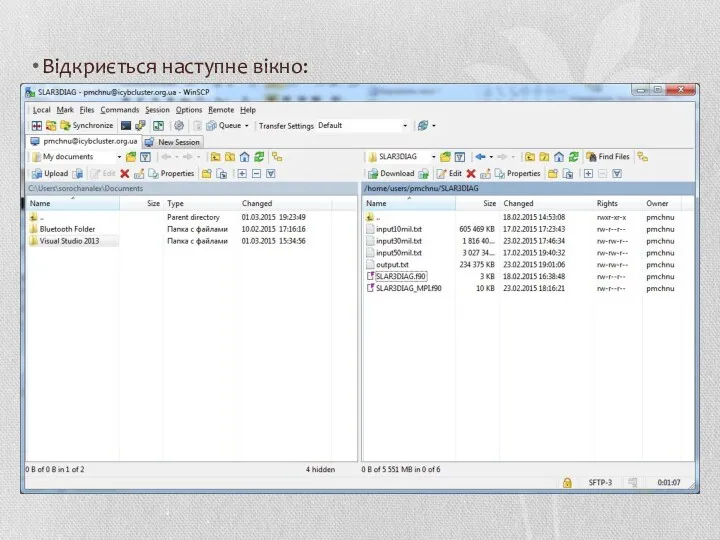
Відкриється наступне вікно:
Відкриється наступне вікно:
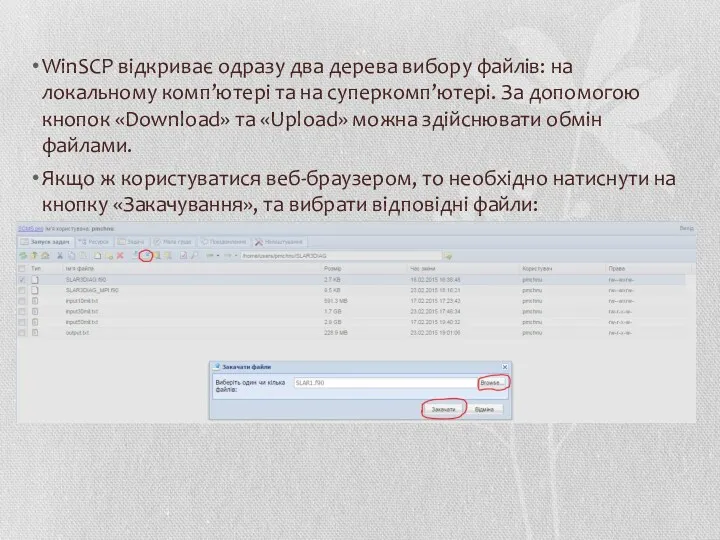
WinSCP відкриває одразу два дерева вибору файлів: на локальному комп’ютері та
WinSCP відкриває одразу два дерева вибору файлів: на локальному комп’ютері та

3.2. Запуск MPI-програм
Щоби запускати свої завдання на суперкомп’ютері, необхідно зробити 3
3.2. Запуск MPI-програм
Щоби запускати свої завдання на суперкомп’ютері, необхідно зробити 3

Спочатку розглянемо запуск програм у консольному режимі.
На жаль, на керуючому вузлі,
Спочатку розглянемо запуск програм у консольному режимі.
На жаль, на керуючому вузлі,
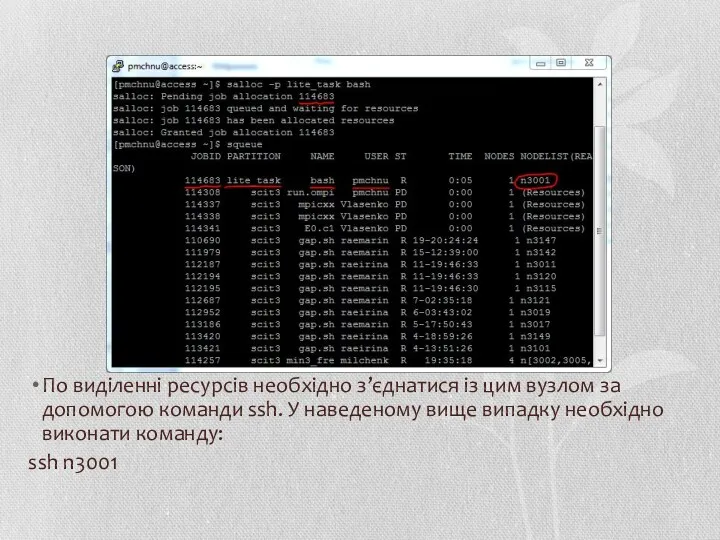
По виділенні ресурсів необхідно з’єднатися із цим вузлом за допомогою команди
По виділенні ресурсів необхідно з’єднатися із цим вузлом за допомогою команди

Для того щоб підтягнути усі необхідні заголовні файли та файли бібліотек,
Для того щоб підтягнути усі необхідні заголовні файли та файли бібліотек,

Скрипти для бібліотеки OpenMPI треба шукати у папці /opt/ompi
Скрипти для бібліотеки
Скрипти для бібліотеки OpenMPI треба шукати у папці /opt/ompi
Скрипти для бібліотеки
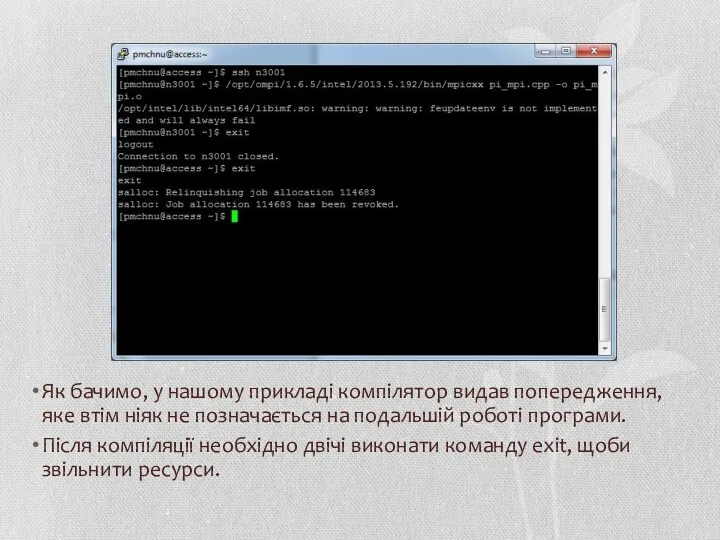
Як бачимо, у нашому прикладі компілятор видав попередження, яке втім ніяк
Як бачимо, у нашому прикладі компілятор видав попередження, яке втім ніяк

Скомпільований бінарний файл можна ставити у чергу виконання. Для цього можна
Скомпільований бінарний файл можна ставити у чергу виконання. Для цього можна
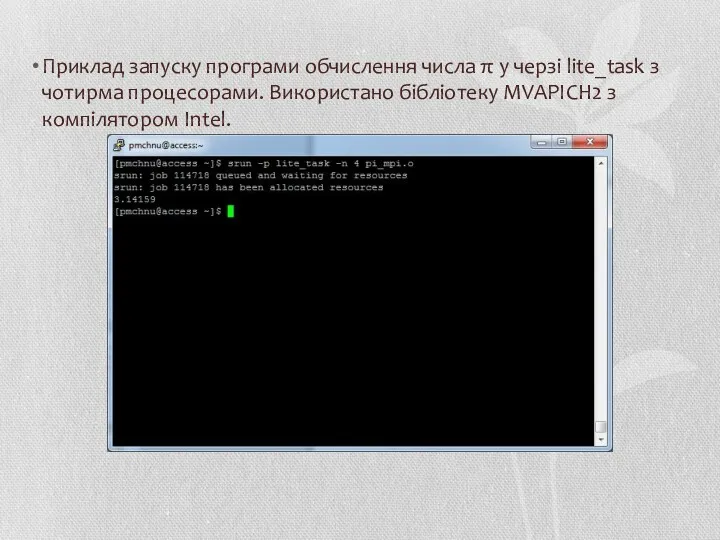
Приклад запуску програми обчислення числа π у черзі lite_task з чотирма
Приклад запуску програми обчислення числа π у черзі lite_task з чотирма

Більш розповсюдженим варіантом запуску задач є використання команди sbatch, яка виконує
Більш розповсюдженим варіантом запуску задач є використання команди sbatch, яка виконує
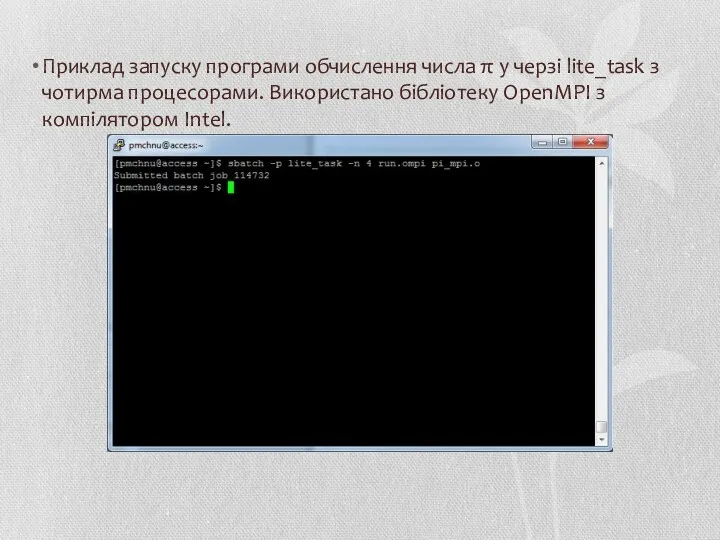
Приклад запуску програми обчислення числа π у черзі lite_task з чотирма
Приклад запуску програми обчислення числа π у черзі lite_task з чотирма
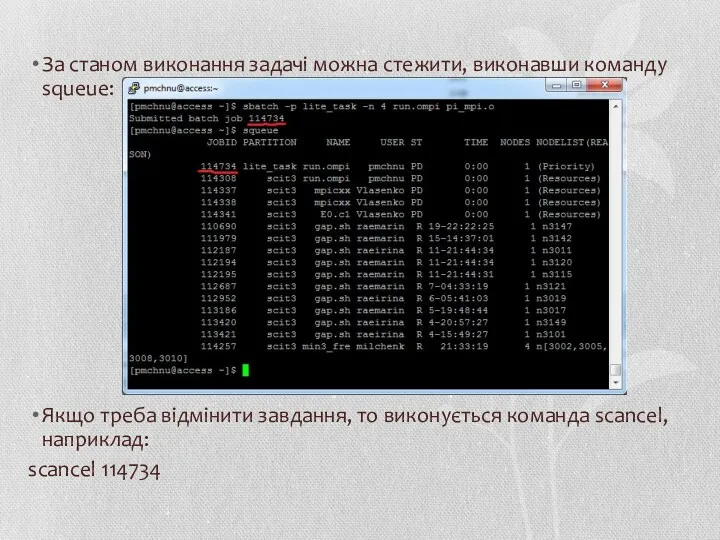
За станом виконання задачі можна стежити, виконавши команду squeue:
Якщо треба відмінити
За станом виконання задачі можна стежити, виконавши команду squeue:
Якщо треба відмінити
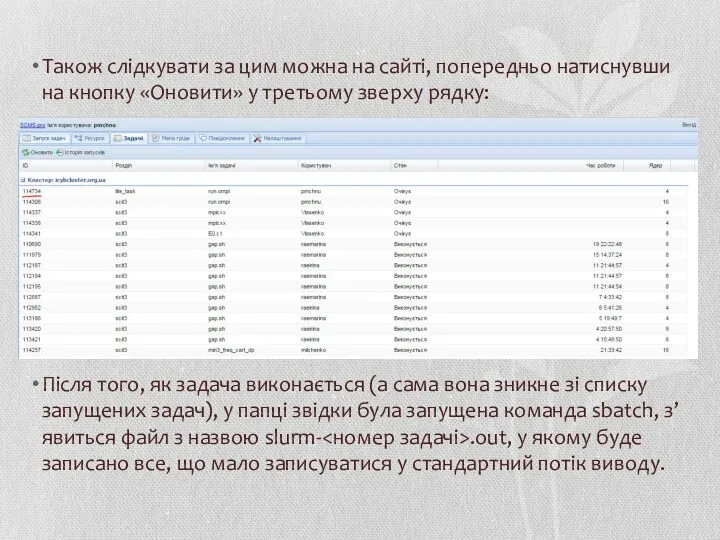
Також слідкувати за цим можна на сайті, попередньо натиснувши на кнопку
Також слідкувати за цим можна на сайті, попередньо натиснувши на кнопку
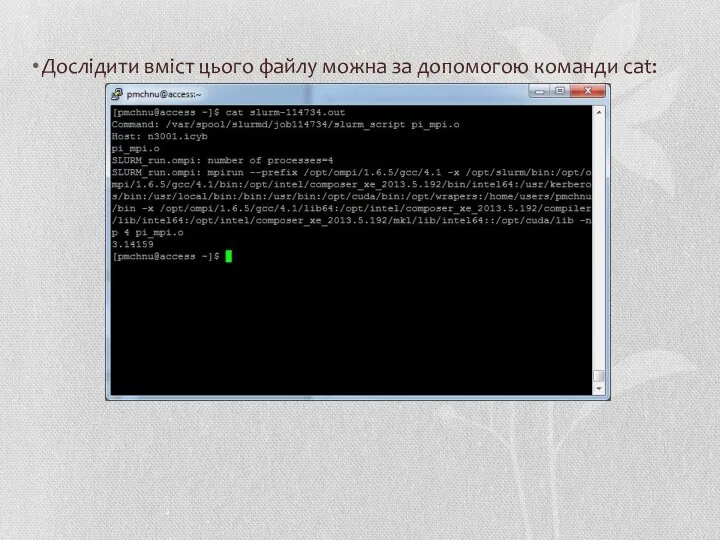
Дослідити вміст цього файлу можна за допомогою команди cat:
Дослідити вміст цього файлу можна за допомогою команди cat:
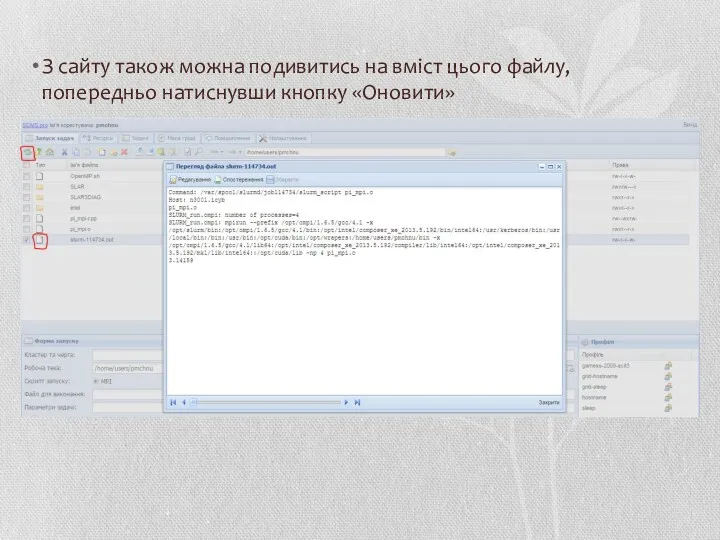
З сайту також можна подивитись на вміст цього файлу, попередньо натиснувши
З сайту також можна подивитись на вміст цього файлу, попередньо натиснувши

Запускати задачу можна і з веб-інтерфейсу. Форма запуску на закладці «Запуск
Запускати задачу можна і з веб-інтерфейсу. Форма запуску на закладці «Запуск
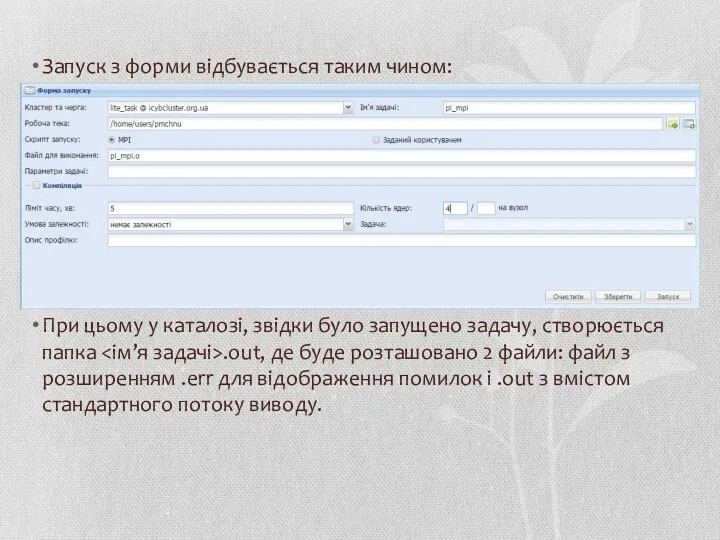
Запуск з форми відбувається таким чином:
При цьому у каталозі, звідки було
Запуск з форми відбувається таким чином:
При цьому у каталозі, звідки було

3.3. Запуск OpenMP-програм
Щоби скомпілювати OpenMP-програму, як і у випадку з MPI,
3.3. Запуск OpenMP-програм
Щоби скомпілювати OpenMP-програму, як і у випадку з MPI,
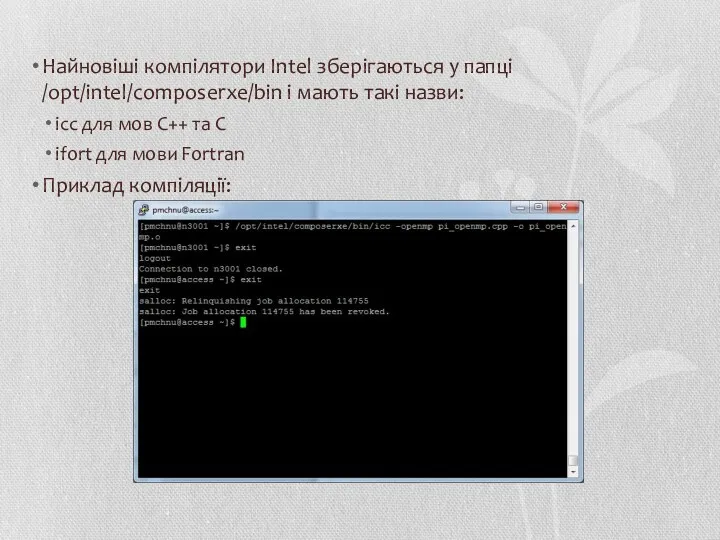
Найновіші компілятори Intel зберігаються у папці /opt/intel/composerxe/bin і мають такі назви:
icc
Найновіші компілятори Intel зберігаються у папці /opt/intel/composerxe/bin і мають такі назви:
icc
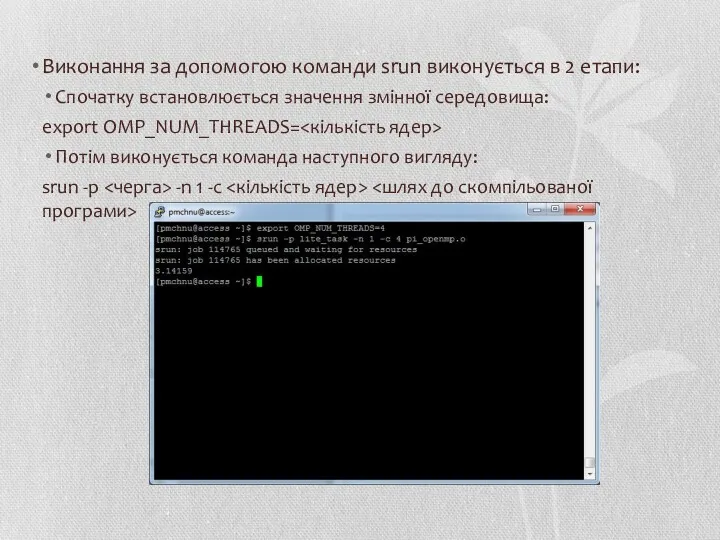
Виконання за допомогою команди srun виконується в 2 етапи:
Спочатку встановлюється значення
Виконання за допомогою команди srun виконується в 2 етапи:
Спочатку встановлюється значення
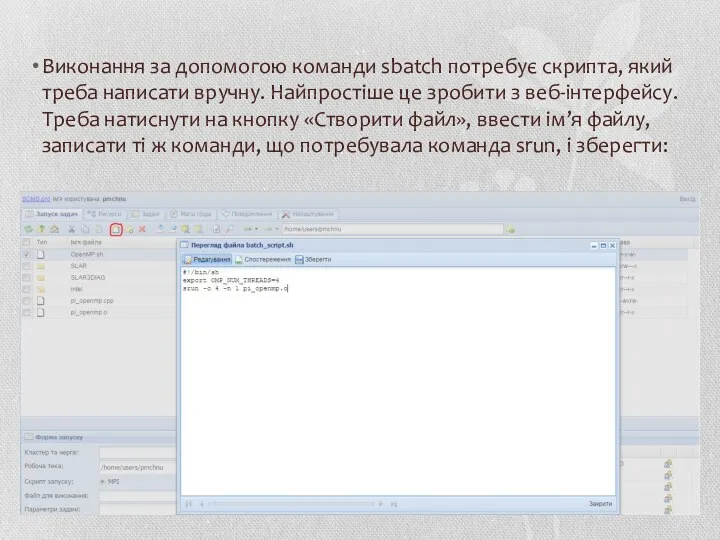
Виконання за допомогою команди sbatch потребує скрипта, який треба написати вручну.
Виконання за допомогою команди sbatch потребує скрипта, який треба написати вручну.
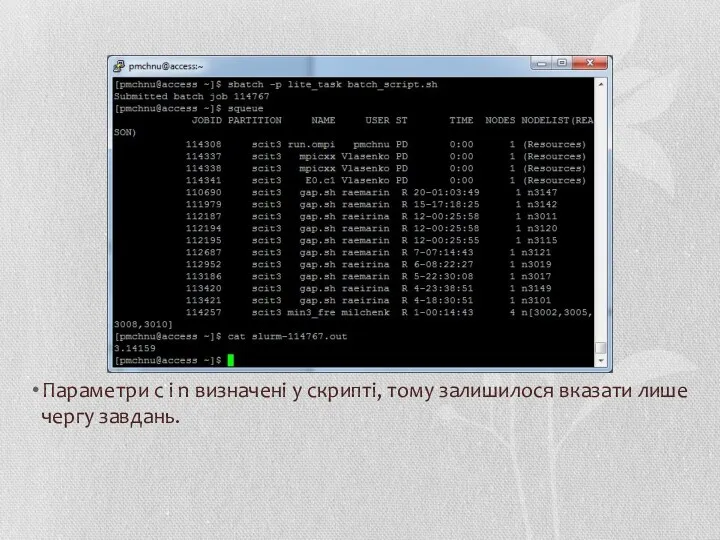
Параметри c і n визначені у скрипті, тому залишилося вказати лише
Параметри c і n визначені у скрипті, тому залишилося вказати лише
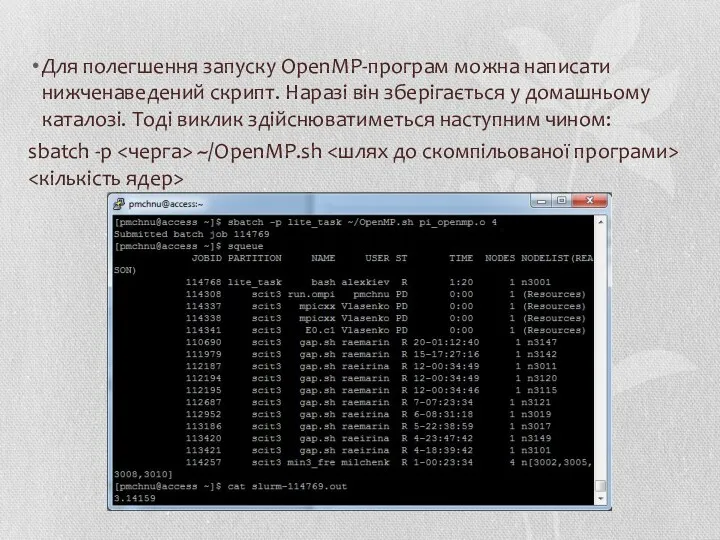
Для полегшення запуску OpenMP-програм можна написати нижченаведений скрипт. Наразі він зберігається
Для полегшення запуску OpenMP-програм можна написати нижченаведений скрипт. Наразі він зберігається
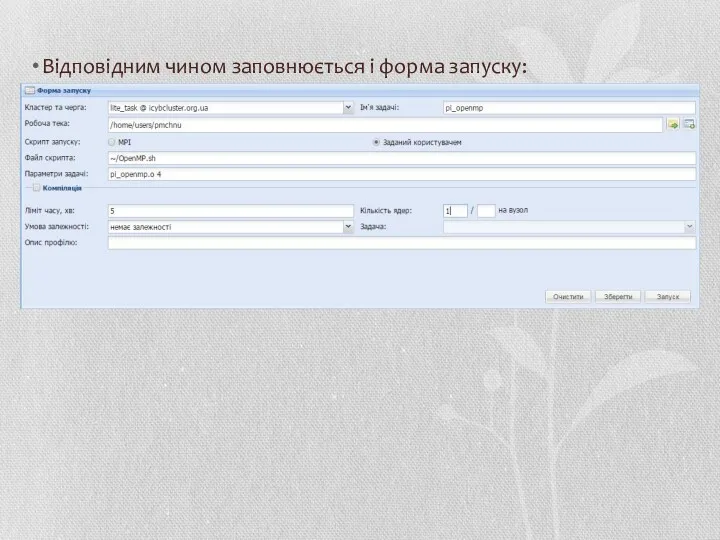
Відповідним чином заповнюється і форма запуску:
Відповідним чином заповнюється і форма запуску:

4. Деякі результати тестування
Тестування проводились на комп’ютері з 4-ядерним процесором Intel
4. Деякі результати тестування
Тестування проводились на комп’ютері з 4-ядерним процесором Intel
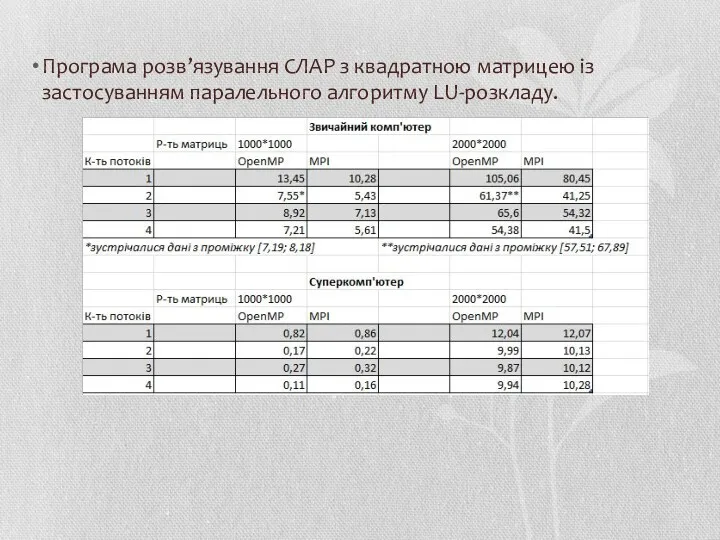
Програма розв’язування СЛАР з квадратною матрицею із застосуванням паралельного алгоритму LU-розкладу.
Програма розв’язування СЛАР з квадратною матрицею із застосуванням паралельного алгоритму LU-розкладу.
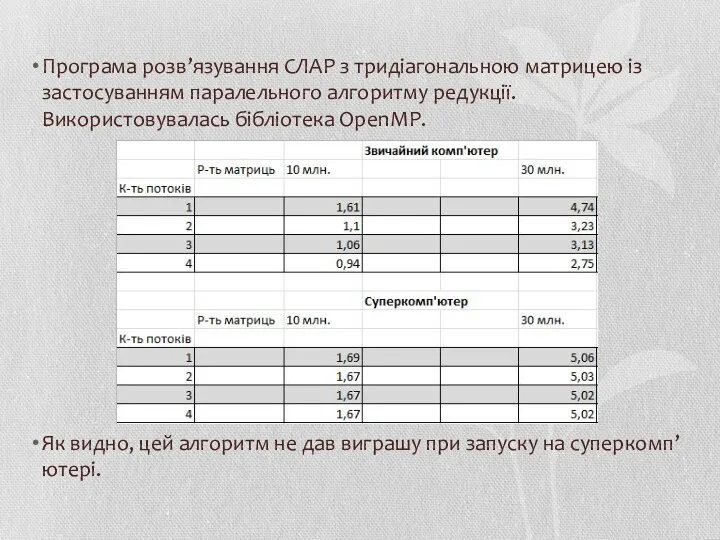
Програма розв’язування СЛАР з тридіагональною матрицею із застосуванням паралельного алгоритму редукції.
Програма розв’язування СЛАР з тридіагональною матрицею із застосуванням паралельного алгоритму редукції.
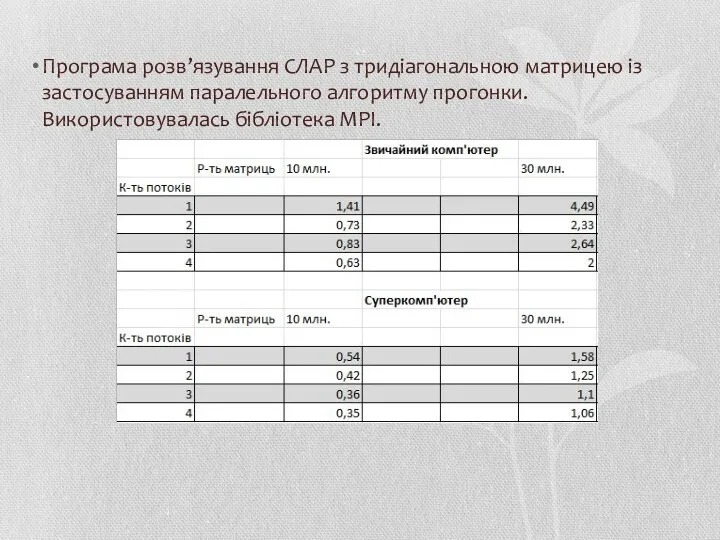
Програма розв’язування СЛАР з тридіагональною матрицею із застосуванням паралельного алгоритму прогонки.
Програма розв’язування СЛАР з тридіагональною матрицею із застосуванням паралельного алгоритму прогонки.
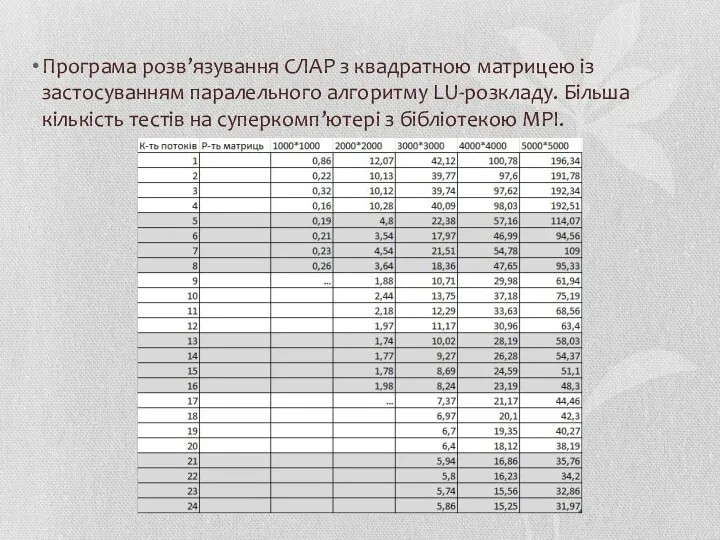
Програма розв’язування СЛАР з квадратною матрицею із застосуванням паралельного алгоритму LU-розкладу.
Програма розв’язування СЛАР з квадратною матрицею із застосуванням паралельного алгоритму LU-розкладу.
 № 3Герои в нашей семье - копия
№ 3Герои в нашей семье - копия Взаимодействие с семьей по формированию трудовых навыков у детей у дошкольников
Взаимодействие с семьей по формированию трудовых навыков у детей у дошкольников 1769 год - первые бумажные деньги в России. Ассигнационный рубль
1769 год - первые бумажные деньги в России. Ассигнационный рубль Электронные таблицы
Электронные таблицы Можно ли есть снег. Проект
Можно ли есть снег. Проект Права и обязанности граждан в области гражданской обороны и защиты от чрезвычайных ситуаций природного и техногенного характера
Права и обязанности граждан в области гражданской обороны и защиты от чрезвычайных ситуаций природного и техногенного характера Экономика: наука и хозяйство
Экономика: наука и хозяйство Механические свойства металлов и сплавов
Механические свойства металлов и сплавов Становление советской власти. 1918-1920 годы
Становление советской власти. 1918-1920 годы Деревянное панельное домостроение. Состояние и перспективы развития
Деревянное панельное домостроение. Состояние и перспективы развития Предложения по организации диаметрального движения в Московском транспортном узле в увязке с существующим радиальным движением
Предложения по организации диаметрального движения в Московском транспортном узле в увязке с существующим радиальным движением Закон и власть
Закон и власть Салон Анны Павловны Шерер. Л. Н. Толстой Война и мир
Салон Анны Павловны Шерер. Л. Н. Толстой Война и мир Сюжетно-ролевая игра В магазине
Сюжетно-ролевая игра В магазине Мастер класс Лабораторный практикум по теме: Организация деятельностного подхода в обучении 4 часть
Мастер класс Лабораторный практикум по теме: Организация деятельностного подхода в обучении 4 часть Основные понятия, термины и определения механики грунтов
Основные понятия, термины и определения механики грунтов презентация игры прабабушек
презентация игры прабабушек Созылмалы холецистит. Дискинезиясы
Созылмалы холецистит. Дискинезиясы Олимпийский урок.Сочи - 2014.1Б класс
Олимпийский урок.Сочи - 2014.1Б класс великобритания Диск
великобритания Диск Фитотерапия. Предмет, задачи история развития фармакогнозии. Основные понятия
Фитотерапия. Предмет, задачи история развития фармакогнозии. Основные понятия Күйістілердің эуритремозын балау, емдеу және алдын алу шаралары
Күйістілердің эуритремозын балау, емдеу және алдын алу шаралары Путешествие по Юрге
Путешествие по Юрге Скифская культура
Скифская культура Шаблон презентации В нотке - целый мир!
Шаблон презентации В нотке - целый мир! Правила дорожного движения
Правила дорожного движения Презентация по теме Работа со слабуспевающими детьми в начальных классах
Презентация по теме Работа со слабуспевающими детьми в начальных классах Бытовые электронагревательные приборы
Бытовые электронагревательные приборы