- Технологии создания параллельных программ. Лекция 7

Содержание
- 2. Формы параллелизма Параллелизм по задачам Параллелизм по данным
- 3. Формы параллелизма Задача: 1. Найти число нулей. 2. Найти число единиц. 3. Определить чего больше. 1.
- 4. Средства разработки параллельных программ https://parallel.ru/tech/tech_dev/
- 5. Средства разработки параллельных программ https://parallel.ru/tech/tech_dev/
- 6. Средства разработки параллельных программ https://parallel.ru/tech/tech_dev/
- 7. MIMD Параллельные компьютеры MIMD С общей памятью С распределенной памятью Пример: Symmetric Multi Processors (SMP); Parallel
- 8. MPI (message passing interface) Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для
- 9. MPI_COMM_WORLD MPI. Терминология и обозначения MPI - message passing interface Процесс 1 Процессоры Процесс 2 Процесс
- 10. MPI. Терминология и обозначения Процессор - интегральная схема, исполняющая машинные инструкции. Процесс - совокупность команд, выполняемых
- 11. MPI. 130 функций функции инициализации и закрытия MPI процессов; функции, реализующие коммуникационные операции типа точка-точка; функции,
- 12. MPI: Hello, World!
- 13. Точки синхронизации
- 14. Точки синхронизации
- 15. Точки синхронизации MPI_BARRIER (COMM) Внимание! Функция MPI_Barrier определяет коллективную операцию, и, тем самым, при использовании она
- 16. POSIX Threads POSIX - Portable Operating System Interface for UNIX POSIX - это стандарт, описывающий интерфейс
- 17. Потоки
- 18. Модель разделяемой памяти Все потоки имеют доступ к разделяемой глобальной памяти Данные могут быть как приватными
- 19. Симметричные мультипроцессорные системы (SMP)
- 20. Архитектура многопроцессорных систем с общей (разделяемой) с однородным доступом памятью
- 21. POSIX threads POSIX threads или Pthreads определяет набор типов и функций для программирования потоков. Типы данных:
- 22. POSIX threads. Пример 1 Пример: несколько потоков обращаются к одной общей переменной. Часть потоков эту переменную
- 23. POSIX threads. Пример 1 1 запуск: Ответ: 0 2 запуск: Ответ: 1 3 запуск: Ответ: 4
- 24. POSIX threads. Пример 1 Причины: Наличие локальной переменной local. Использование тяжёлой и медленной функция printf. Отсутствие
- 25. POSIX threads. Мьютекс Захват Освобождение Захват Освобождение Объявление
- 26. POSIX threads. Мьютекс Инициализация Уничтожение
- 27. POSIX threads. Мьютекс Ожидаемый сценарий Плохой сценарий Хороший сценарий
- 28. POSIX threads. Мьютекс При использовании мьютекса: исполнение защищённого участка кода происходит последовательно всеми потоками, а не
- 29. POSIX threads. Условные переменные (conditional variables) - pthread_cond_init() – создание условной переменной; - pthread_cond_signal() – разблокировка
- 30. Сценарий производитель-потребитель Наивное решение int buf[N]; int count = 0; void producer() { while (1) {
- 31. Проблемы «наивного» решения 0,?,2,…, N-1 void producer() { while (1) { int item = produce_item(); while
- 32. Сценарий производитель-потребитель Основная процедура создает три потока. Два потока выполняют работу и обновляют переменную count. 2-й
- 33. Сценарий производитель-потребитель https://computing.llnl.gov/tutorials/pthreads/#ConditionVariables Число потоков Число срабатываний 2-го и 3-го потока Создаваемые числа Момент срабатывания 1-го
- 34. Сценарий производитель-потребитель Поставщик
- 35. Сценарий производитель-потребитель
- 36. Сценарий производитель-потребитель
- 37. Сценарий производитель-потребитель
- 38. Классические задачи синхронизации Классические задачи синхронизации — это модельные задачи, на которых исследуются различные ситуации, которые
- 39. Модель "пульсирующего" параллелизма FORK-JOIN Программа–полновесный процесс. Процесс может запускать легковесные процессы (нити), выполняющиеся в фоновом режиме.
- 40. Модель "пульсирующего" параллелизма FORK-JOIN
- 41. OpenMP OpenMP можно рассматривать как высокоуровневую надстройку над Pthreads (или аналогичными библиотеками нитей) Отсутствие межпроцессорных передач
- 42. Структура OpenMP. Директивы. Конструктивно в составе технологии OpenMP можно выделить: Директивы, Библиотеку функций, Набор переменных окружения.
- 43. Директива parallel для определения параллельных фрагментов Синтаксис: #pragma omp parallel [ ...] Пример параллельной программы
- 44. Пример простой программы
- 45. Частные и общие переменные
- 46. Конструкции OpenMP для распределения работ ● параллельный цикл for/DO ● параллельные секции (sections) ● конструкция single
- 47. Распараллеливание по данным для циклов Счетчик цикла по умолчанию является частной переменной. По умолчанию вычисления распределяются
- 48. Параллельные секции #pragma omp parallel sections { #pragma omp section { printf("T%d: foo\n", omp_get_thread_num()); } #pragma
- 49. Конструкция single
- 50. Конструкция master
- 51. Условия выполнения Пример. Цикл должен быть распараллелен при условии, что итераций цикла больше, чем 2000
- 52. Синхронизация вычислений В OpenMP предусмотрены следующие конструкции синхронизации: critical – критическая секция atomic – атомарность операции
- 53. Синхронизация вычислений. Директива critical Определяет критическую секцию –участок кода, выполняемый одновременно не более чем одной нитью.
- 54. Синхронизация вычислений. Директива barrier Определяет барьер –точку в программе, которую должна достигнуть каждая нить, чтобы все
- 55. Синхронизация вычислений. Директива atomic Определяет переменную в левой части оператора присваивания, которая должна корректно обновляться несколькими
- 56. Синхронизация вычислений. Директива ordered Синхронизация типа ordered используется для определения потоков в параллельной области программы, которые
- 57. Синхронизация вычислений. Директива flush Эта конструкция осуществляет немедленный сброс значений разделяемых переменных в память. Таким образом
- 58. Сравнение стандартов
- 59. Архитектура MPI+OpenMP: плюсы и минусы Удобное применение для кластеров с SMP-узлами: MPI –между узлами Избегаем накладных
- 60. MPI, OpenMP, MPI+OpenMP MPI OpenMP MPI+OpenMP
- 61. MPI+OpenMP программа
- 62. Уровни поддержки нитей в MPI
- 63. MPI-программа с поддержкой нитей
- 65. Скачать презентацию
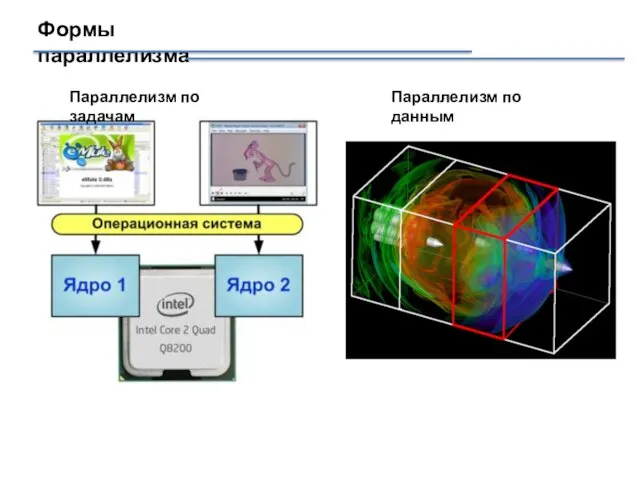
Формы параллелизма
Параллелизм по задачам
Параллелизм по данным
Формы параллелизма
Параллелизм по задачам
Параллелизм по данным
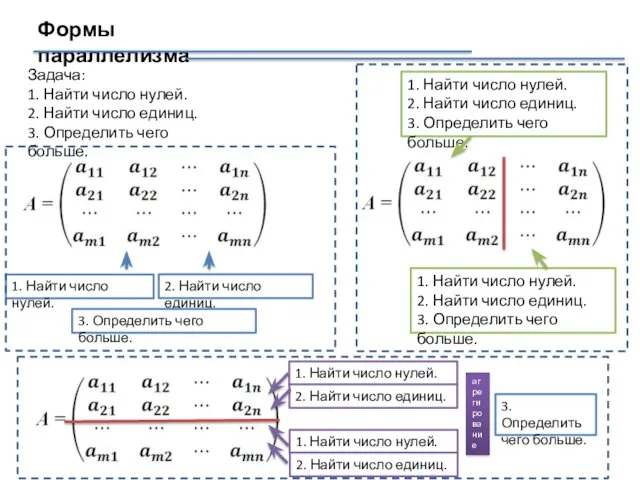
Формы параллелизма
Задача:
1. Найти число нулей.
2. Найти число единиц.
3. Определить чего
Формы параллелизма
Задача:
1. Найти число нулей.
2. Найти число единиц.
3. Определить чего

Средства разработки параллельных программ
https://parallel.ru/tech/tech_dev/
Средства разработки параллельных программ
https://parallel.ru/tech/tech_dev/

Средства разработки параллельных программ
https://parallel.ru/tech/tech_dev/
Средства разработки параллельных программ
https://parallel.ru/tech/tech_dev/
Средства разработки параллельных программ
https://parallel.ru/tech/tech_dev/
Средства разработки параллельных программ
https://parallel.ru/tech/tech_dev/
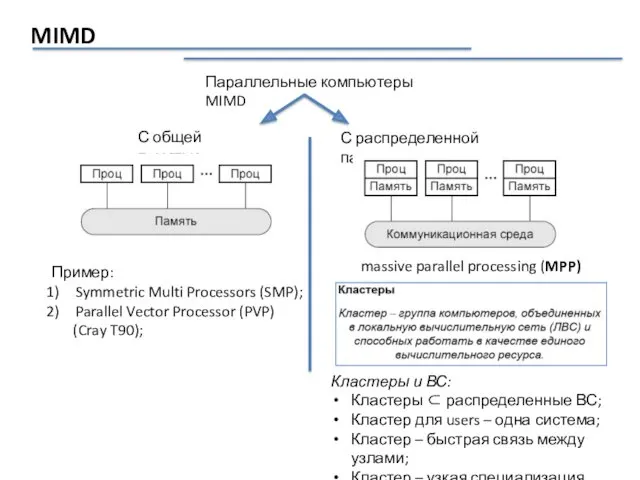
MIMD
Параллельные компьютеры MIMD
С общей памятью
С распределенной памятью
Пример:
Symmetric Multi Processors
MIMD
Параллельные компьютеры MIMD
С общей памятью
С распределенной памятью
Пример:
Symmetric Multi Processors

MPI (message passing interface)
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный
MPI (message passing interface)
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный
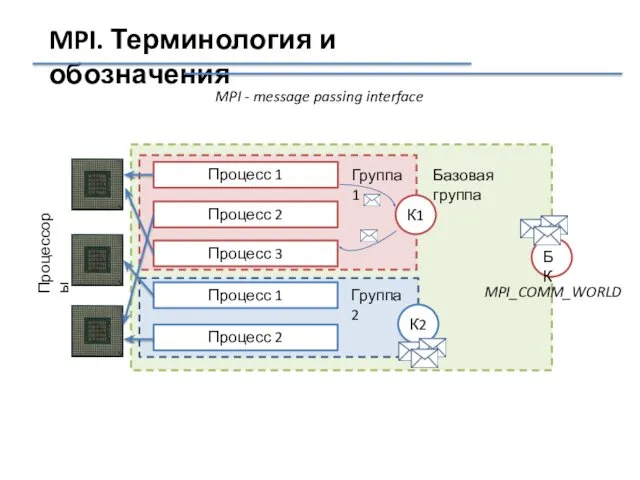
MPI_COMM_WORLD
MPI. Терминология и обозначения
MPI - message passing interface
Процесс 1
Процессоры
Процесс 2
Процесс
MPI_COMM_WORLD
MPI. Терминология и обозначения
MPI - message passing interface
Процесс 1
Процессоры
Процесс 2
Процесс

MPI. Терминология и обозначения
Процессор - интегральная схема, исполняющая машинные инструкции.
Процесс - совокупность команд, выполняемых
MPI. Терминология и обозначения
Процессор - интегральная схема, исполняющая машинные инструкции.
Процесс - совокупность команд, выполняемых
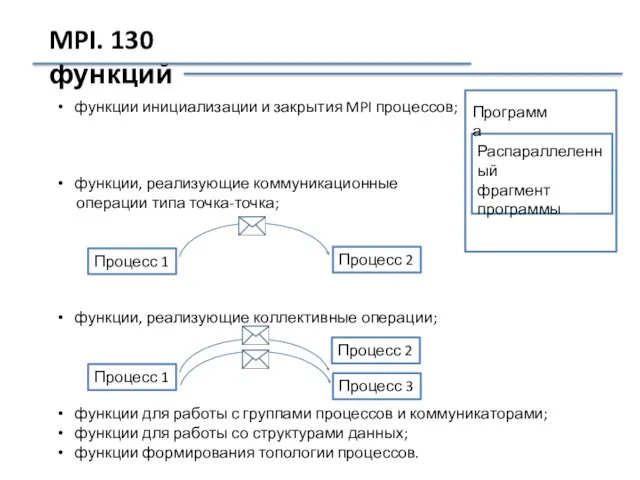
MPI. 130 функций
функции инициализации и закрытия MPI процессов;
функции, реализующие коммуникационные
MPI. 130 функций
функции инициализации и закрытия MPI процессов;
функции, реализующие коммуникационные
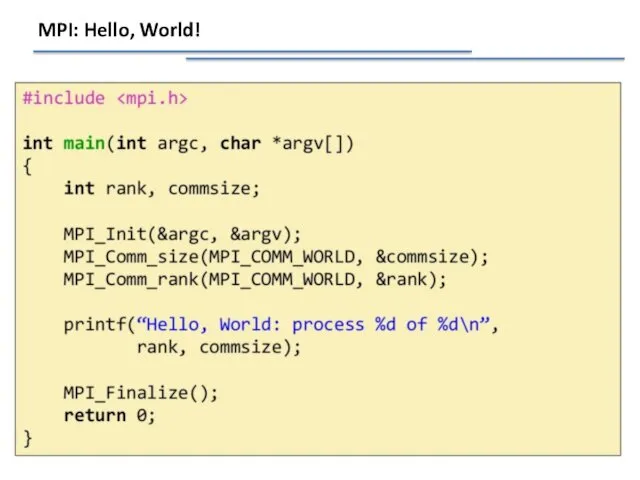
MPI: Hello, World!
MPI: Hello, World!
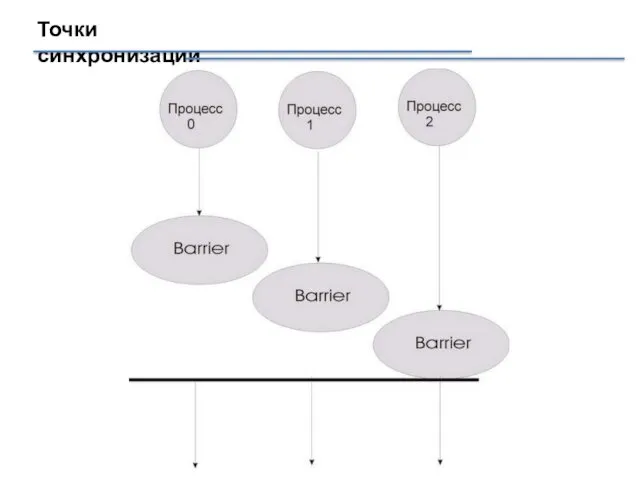
Точки синхронизации
Точки синхронизации

Точки синхронизации
Точки синхронизации

Точки синхронизации
MPI_BARRIER (COMM)
Внимание!
Функция MPI_Barrier определяет коллективную операцию, и, тем самым,
Точки синхронизации
MPI_BARRIER (COMM)
Внимание!
Функция MPI_Barrier определяет коллективную операцию, и, тем самым,

POSIX Threads
POSIX - Portable Operating System Interface for UNIX
POSIX - это
POSIX Threads
POSIX - Portable Operating System Interface for UNIX
POSIX - это
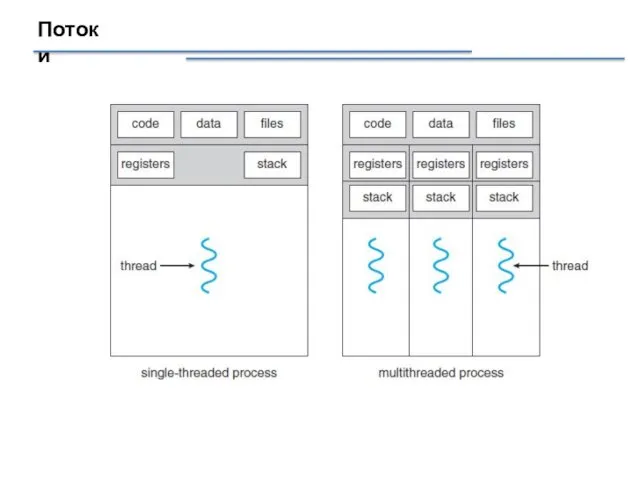
Потоки
Потоки
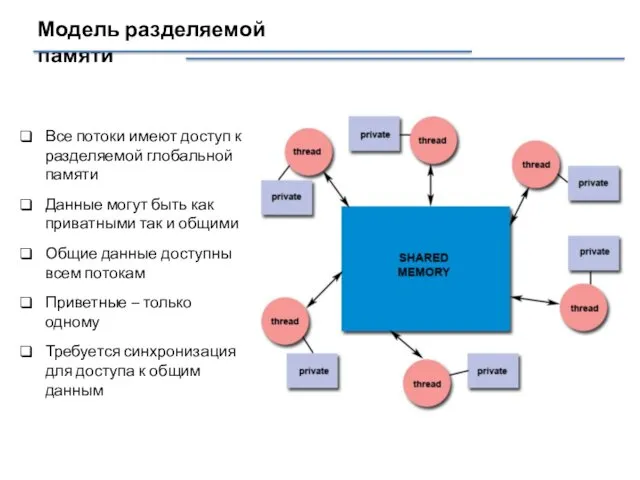
Модель разделяемой памяти
Все потоки имеют доступ к разделяемой глобальной памяти
Данные могут
Модель разделяемой памяти
Все потоки имеют доступ к разделяемой глобальной памяти
Данные могут
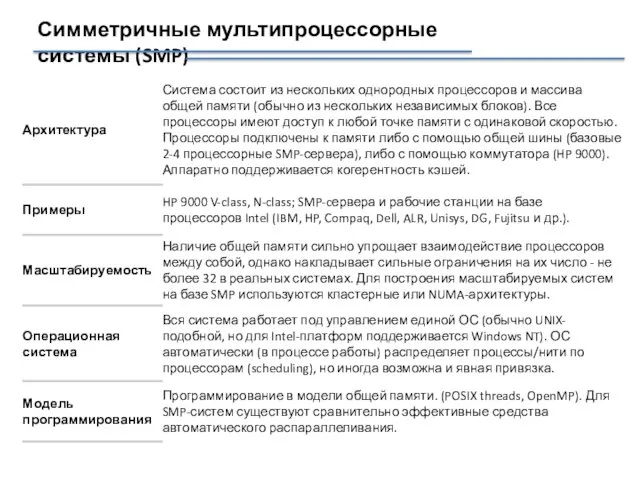
Симметричные мультипроцессорные системы (SMP)
Симметричные мультипроцессорные системы (SMP)
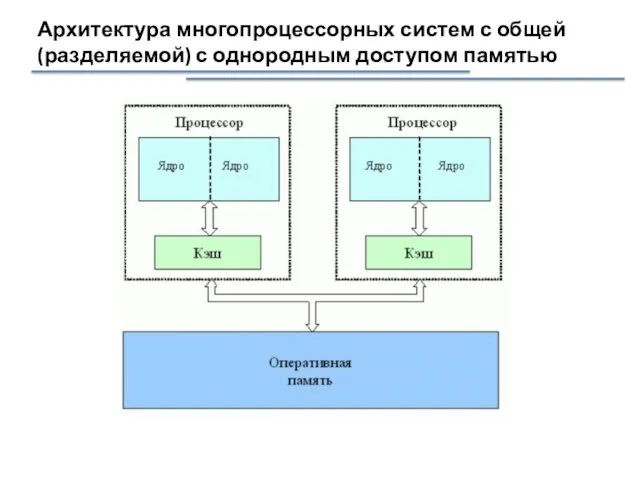
Архитектура многопроцессорных систем с общей (разделяемой) с однородным доступом памятью
Архитектура многопроцессорных систем с общей (разделяемой) с однородным доступом памятью

POSIX threads
POSIX threads или Pthreads определяет набор типов и функций для программирования
POSIX threads
POSIX threads или Pthreads определяет набор типов и функций для программирования
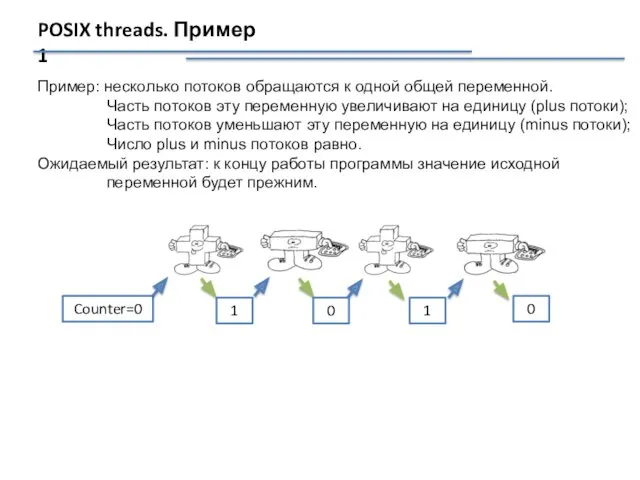
POSIX threads. Пример 1
Пример: несколько потоков обращаются к одной общей
POSIX threads. Пример 1
Пример: несколько потоков обращаются к одной общей
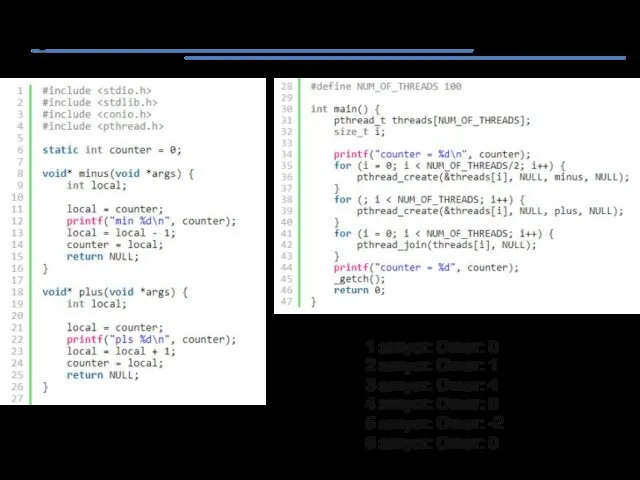
POSIX threads. Пример 1
1 запуск: Ответ: 0
2 запуск: Ответ: 1
3
POSIX threads. Пример 1
1 запуск: Ответ: 0
2 запуск: Ответ: 1
3
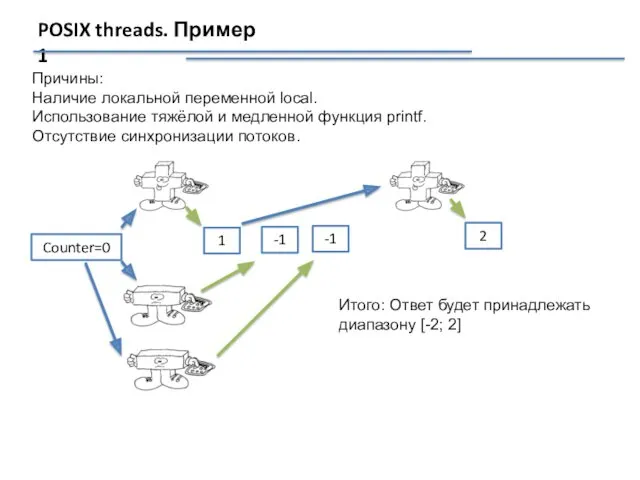
POSIX threads. Пример 1
Причины:
Наличие локальной переменной local.
Использование тяжёлой и
POSIX threads. Пример 1
Причины:
Наличие локальной переменной local.
Использование тяжёлой и

POSIX threads. Мьютекс
Захват
Освобождение
Захват
Освобождение
Объявление
POSIX threads. Мьютекс
Захват
Освобождение
Захват
Освобождение
Объявление
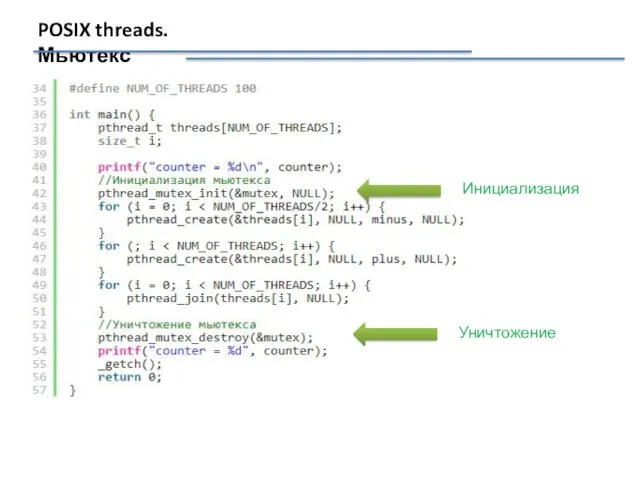
POSIX threads. Мьютекс
Инициализация
Уничтожение
POSIX threads. Мьютекс
Инициализация
Уничтожение
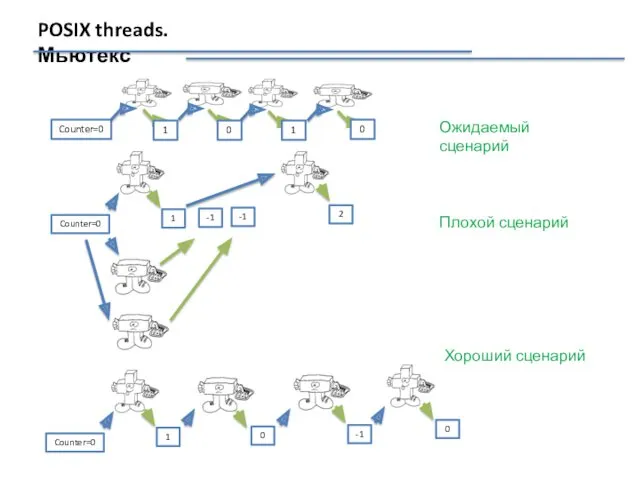
POSIX threads. Мьютекс
Ожидаемый сценарий
Плохой сценарий
Хороший сценарий
POSIX threads. Мьютекс
Ожидаемый сценарий
Плохой сценарий
Хороший сценарий
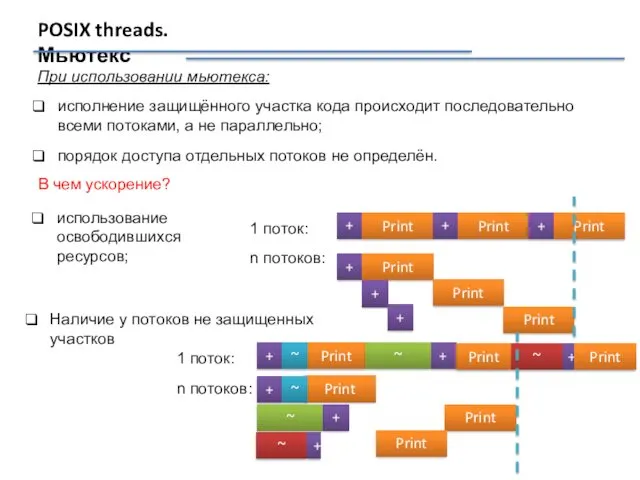
POSIX threads. Мьютекс
При использовании мьютекса:
исполнение защищённого участка кода происходит последовательно всеми
POSIX threads. Мьютекс
При использовании мьютекса:
исполнение защищённого участка кода происходит последовательно всеми
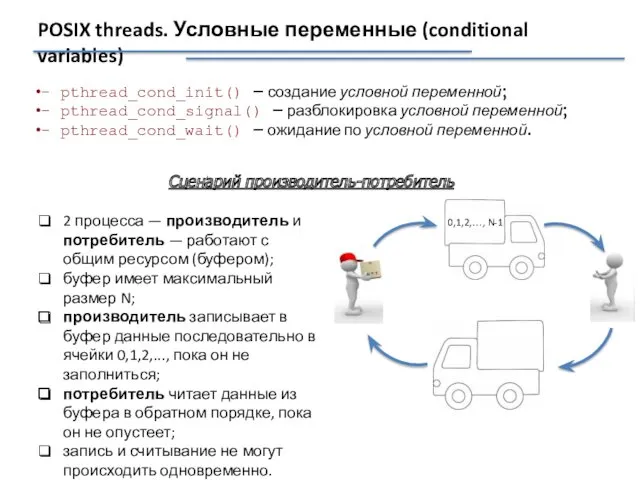
POSIX threads. Условные переменные (conditional variables)
- pthread_cond_init() – создание условной переменной;
- pthread_cond_signal() – разблокировка условной
POSIX threads. Условные переменные (conditional variables)
- pthread_cond_init() – создание условной переменной;
- pthread_cond_signal() – разблокировка условной
![Сценарий производитель-потребитель Наивное решение int buf[N]; int count = 0;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/83723/slide-29.jpg)
Сценарий производитель-потребитель
Наивное решение
int buf[N];
int count = 0;
void producer()
{ while (1)
Сценарий производитель-потребитель
Наивное решение
int buf[N];
int count = 0;
void producer()
{ while (1)
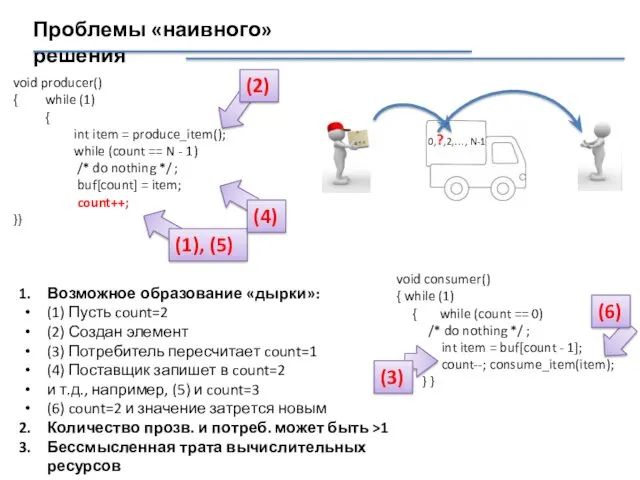
Проблемы «наивного» решения
0,?,2,…, N-1
void producer()
{ while (1)
{
int
Проблемы «наивного» решения
0,?,2,…, N-1
void producer()
{ while (1)
{
int
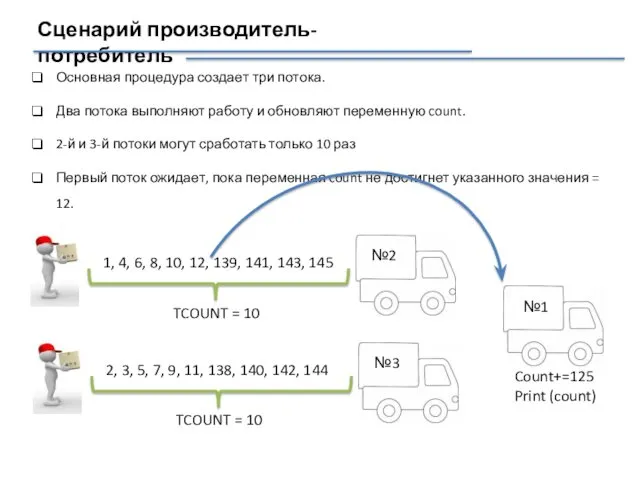
Сценарий производитель-потребитель
Основная процедура создает три потока.
Два потока выполняют работу и обновляют переменную
Сценарий производитель-потребитель
Основная процедура создает три потока.
Два потока выполняют работу и обновляют переменную

Сценарий производитель-потребитель
https://computing.llnl.gov/tutorials/pthreads/#ConditionVariables
Число потоков
Число срабатываний 2-го и 3-го потока
Создаваемые числа
Момент срабатывания 1-го потока
Сценарий производитель-потребитель
https://computing.llnl.gov/tutorials/pthreads/#ConditionVariables
Число потоков
Число срабатываний 2-го и 3-го потока
Создаваемые числа
Момент срабатывания 1-го потока
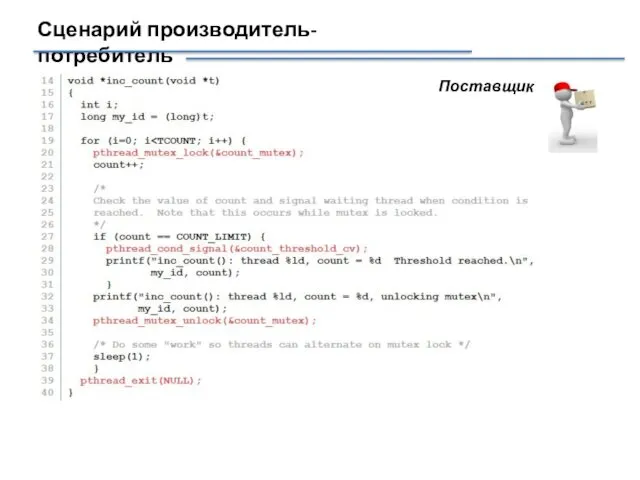
Сценарий производитель-потребитель
Поставщик
Сценарий производитель-потребитель
Поставщик
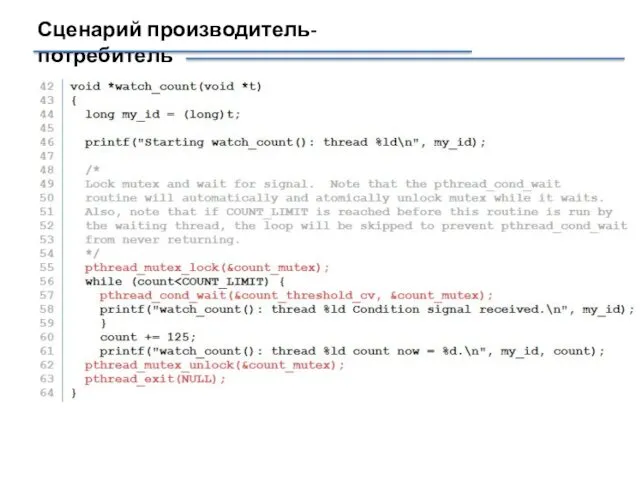
Сценарий производитель-потребитель
Сценарий производитель-потребитель

Сценарий производитель-потребитель
Сценарий производитель-потребитель

Сценарий производитель-потребитель
Сценарий производитель-потребитель

Классические задачи синхронизации
Классические задачи синхронизации — это модельные задачи, на которых
Классические задачи синхронизации
Классические задачи синхронизации — это модельные задачи, на которых
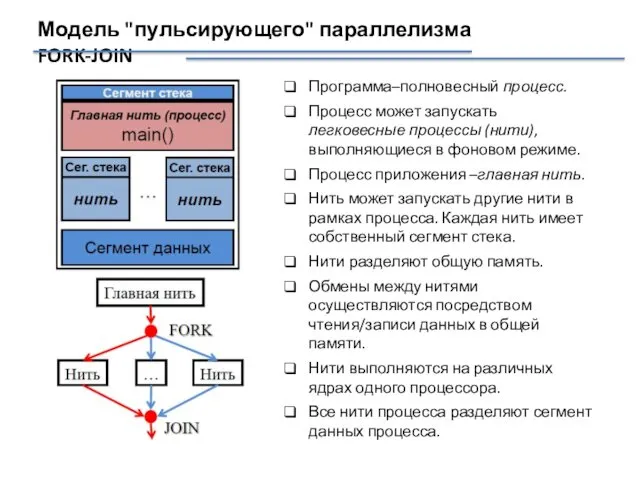
Модель "пульсирующего" параллелизма FORK-JOIN
Программа–полновесный процесс.
Процесс может запускать легковесные процессы (нити), выполняющиеся
Модель "пульсирующего" параллелизма FORK-JOIN
Программа–полновесный процесс.
Процесс может запускать легковесные процессы (нити), выполняющиеся
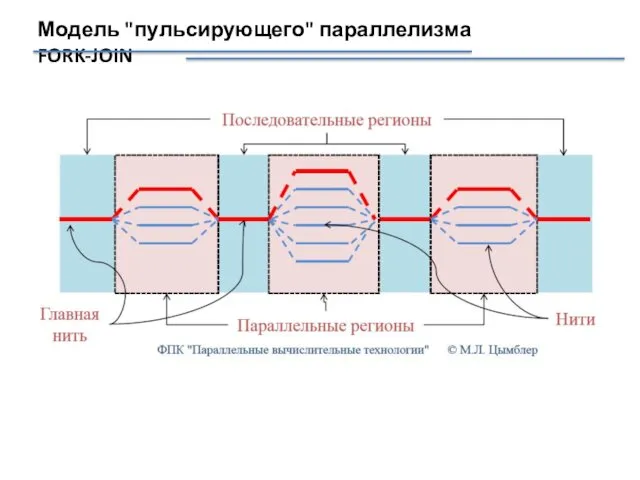
Модель "пульсирующего" параллелизма FORK-JOIN
Модель "пульсирующего" параллелизма FORK-JOIN

OpenMP
OpenMP можно рассматривать как высокоуровневую надстройку над Pthreads (или аналогичными библиотеками
OpenMP
OpenMP можно рассматривать как высокоуровневую надстройку над Pthreads (или аналогичными библиотеками
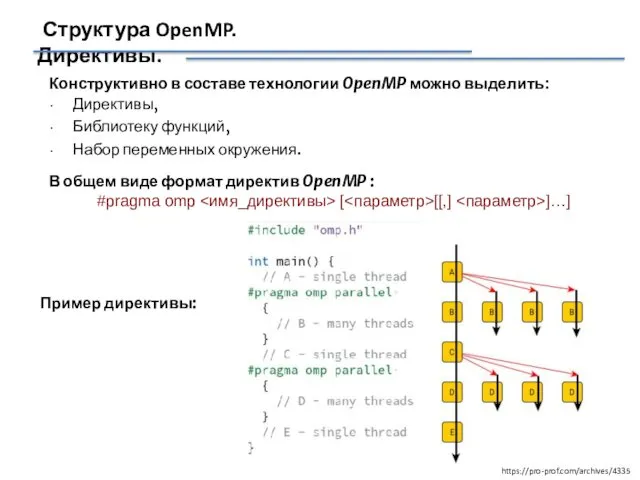
Структура OpenMP. Директивы.
Конструктивно в составе технологии OpenMP можно выделить:
Директивы,
Библиотеку функций,
Набор переменных окружения.
В общем
Структура OpenMP. Директивы.
Конструктивно в составе технологии OpenMP можно выделить:
Директивы,
Библиотеку функций,
Набор переменных окружения.
В общем
![Директива parallel для определения параллельных фрагментов Синтаксис: #pragma omp parallel [ ...] Пример параллельной программы](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/83723/slide-42.jpg)
Директива parallel для определения параллельных фрагментов
Синтаксис:
#pragma omp parallel [<параметр> ...] <блок_программы>
Пример
Директива parallel для определения параллельных фрагментов
Синтаксис:
#pragma omp parallel [<параметр> ...] <блок_программы>
Пример

Пример простой программы
Пример простой программы
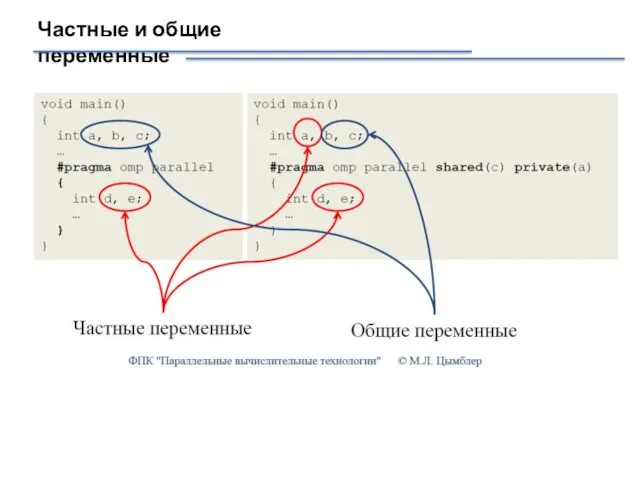
Частные и общие переменные
Частные и общие переменные

Конструкции OpenMP для распределения работ
● параллельный цикл for/DO
● параллельные секции
Конструкции OpenMP для распределения работ
● параллельный цикл for/DO
● параллельные секции
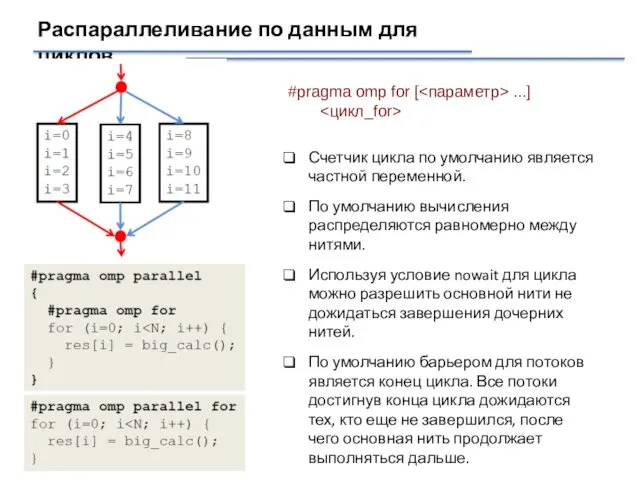
Распараллеливание по данным для циклов
Счетчик цикла по умолчанию является частной переменной.
По
Распараллеливание по данным для циклов
Счетчик цикла по умолчанию является частной переменной.
По

Параллельные секции
#pragma omp parallel sections
{
#pragma omp section
{
printf("T%d: foo\n",
Параллельные секции
#pragma omp parallel sections
{
#pragma omp section
{
printf("T%d: foo\n",

Конструкция single
Конструкция single

Конструкция master
Конструкция master
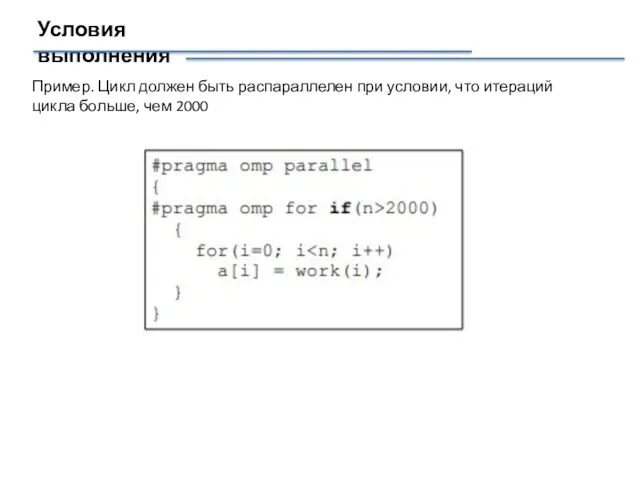
Условия выполнения
Пример. Цикл должен быть распараллелен при условии, что итераций
Условия выполнения
Пример. Цикл должен быть распараллелен при условии, что итераций

Синхронизация вычислений
В OpenMP предусмотрены следующие конструкции синхронизации:
critical – критическая секция
Синхронизация вычислений
В OpenMP предусмотрены следующие конструкции синхронизации:
critical – критическая секция

Синхронизация вычислений. Директива critical
Определяет критическую секцию –участок кода, выполняемый одновременно не
Синхронизация вычислений. Директива critical
Определяет критическую секцию –участок кода, выполняемый одновременно не
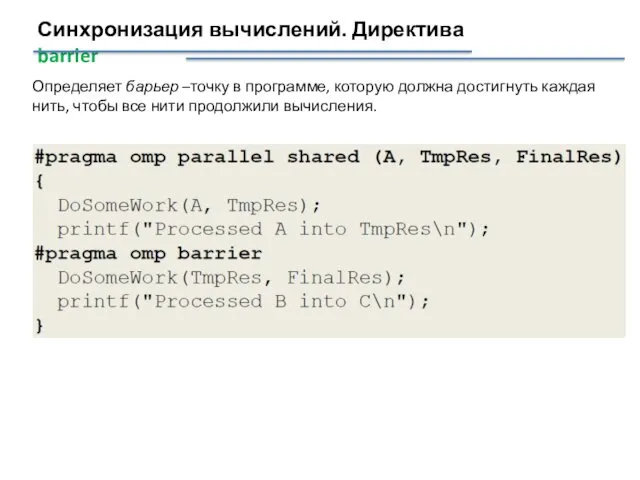
Синхронизация вычислений. Директива barrier
Определяет барьер –точку в программе, которую должна достигнуть
Синхронизация вычислений. Директива barrier
Определяет барьер –точку в программе, которую должна достигнуть

Синхронизация вычислений. Директива atomic
Определяет переменную в левой части оператора присваивания, которая
Синхронизация вычислений. Директива atomic
Определяет переменную в левой части оператора присваивания, которая

Синхронизация вычислений. Директива ordered
Синхронизация типа ordered используется для определения потоков в параллельной области
Синхронизация вычислений. Директива ordered
Синхронизация типа ordered используется для определения потоков в параллельной области

Синхронизация вычислений. Директива flush
Эта конструкция осуществляет немедленный сброс значений разделяемых переменных
Синхронизация вычислений. Директива flush
Эта конструкция осуществляет немедленный сброс значений разделяемых переменных

Сравнение стандартов
Сравнение стандартов

Архитектура MPI+OpenMP: плюсы и минусы
Удобное применение для кластеров с SMP-узлами:
MPI –между
Архитектура MPI+OpenMP: плюсы и минусы
Удобное применение для кластеров с SMP-узлами:
MPI –между
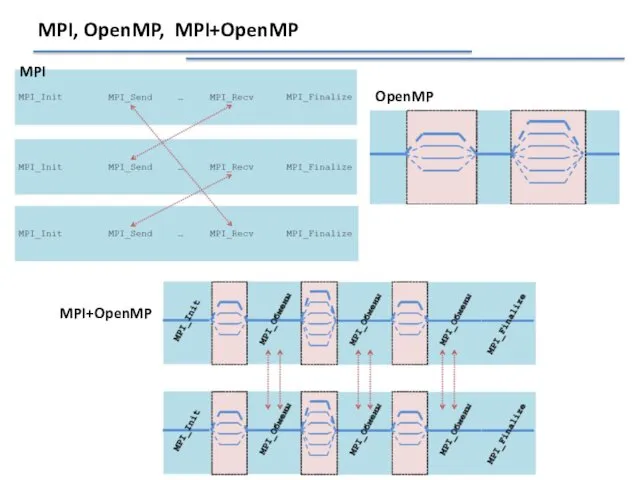
MPI, OpenMP, MPI+OpenMP
MPI
OpenMP
MPI+OpenMP
MPI, OpenMP, MPI+OpenMP
MPI
OpenMP
MPI+OpenMP
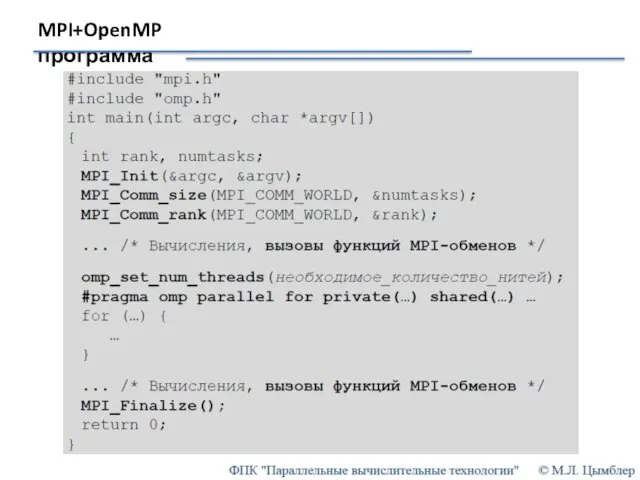
MPI+OpenMP программа
MPI+OpenMP программа

Уровни поддержки нитей в MPI
Уровни поддержки нитей в MPI

MPI-программа с поддержкой нитей
MPI-программа с поддержкой нитей
 Самоиндукция. Индуктивность
Самоиндукция. Индуктивность Термическая подготовка добавочной воды. Лекция 5
Термическая подготовка добавочной воды. Лекция 5 Доставка опасных грузов и грузов повышенной (особой) опасности
Доставка опасных грузов и грузов повышенной (особой) опасности Обработка готовых плит
Обработка готовых плит ВКР: Действия локомотивной бригады при отправлении поезда
ВКР: Действия локомотивной бригады при отправлении поезда Действия работников при обнаружении задымления и возгорания, а также по сигналам оповещения о пожаре
Действия работников при обнаружении задымления и возгорания, а также по сигналам оповещения о пожаре Страны Европы и США в 20-е годы ХХ века
Страны Европы и США в 20-е годы ХХ века Полиграфия. Получение большого количества идентичных оттисков
Полиграфия. Получение большого количества идентичных оттисков Презентация Школьный музей русского быта
Презентация Школьный музей русского быта Пневматический привод. Особенности пневматического привода
Пневматический привод. Особенности пневматического привода Мультимедийные технологии
Мультимедийные технологии Презентация Игрушки
Презентация Игрушки учебное занятие для младшего школьного возраста по теме Мир бумаги
учебное занятие для младшего школьного возраста по теме Мир бумаги Родительское собрание для родителей выпускников.
Родительское собрание для родителей выпускников. Химический куб
Химический куб Сестринский уход при пиелонефритах
Сестринский уход при пиелонефритах урок по геометрии
урок по геометрии Алгоритмические конструкции. Ветвление
Алгоритмические конструкции. Ветвление Принцип работы новых контрольно-измерительных аппаратов
Принцип работы новых контрольно-измерительных аппаратов Вместе сделаем Россию чистой
Вместе сделаем Россию чистой Классный час Лесные опасности
Классный час Лесные опасности Одномерные массивы. Сортировка методом прямого выбора
Одномерные массивы. Сортировка методом прямого выбора Сільське господарство України. Рослинництво
Сільське господарство України. Рослинництво Основы материаловедения. Керамические материалы: стоматологический фарфор, ситалл
Основы материаловедения. Керамические материалы: стоматологический фарфор, ситалл Банкострахование в развитии финансового рынка России
Банкострахование в развитии финансового рынка России Логопедическое занятие День рождения Речевика
Логопедическое занятие День рождения Речевика Біоенергетика. Потенціал енергії біомаси України
Біоенергетика. Потенціал енергії біомаси України Одежда для активного отдыха и занятий зимними видами спорта
Одежда для активного отдыха и занятий зимними видами спорта