- Моделирование социально-экономических процессов в экономике

Содержание
- 2. То, что видим мы – видимость только одна. Далеко от поверхности моря до дна. Полагай несущественным
- 3. Рекомендуемая литература Аникин П.В., Королев В.А., Тороповцев Е.А Математические и инструментальные методы. Изд-во «Кнорус». 2014. Можно
- 4. Прикладная статистика. Основы эконометрики: Учебник для вузов: В 2 т. Айвазян А.А., Мхитарян В.С.-- М.; ЮНИТИ-ДАНА.
- 5. 19. Мастицкий С.Э., Шитиков В.К. Статистический анализ и визуализация данных с помощью R. ДМК Пресс. 2015.
- 6. Главный враг Знания – не невежество, а иллюзия знаний.
- 7. Необходимость моделирования Каждое лицо принимающее на практике какие-либо решения (ЛПР) руководствуется правилами (моральными, юридическими, санитарными и
- 8. Неопределенность описывается теорией вероятностей и/или теорией нечетких множеств (fuzzy sets) и нечеткой логикой (fuzzy logic)
- 9. Нечеткая логика - раздел современной математики, позволяющий формализовать и перевести на компьютерный язык интуитивные знания и
- 10. Понятия нечеткой логики (нечеткие множества и высказывания) появились в середине 1960-годов в публикациях американского математика Лотфи
- 11. Первый период характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде
- 12. Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы
- 13. . Лаплас, Пуассон, Гаусс, Бернулли, П.Л. Чебышев, А.М. Ляпунов А.А. Марков, А.Н. Колмогоров и др. социально
- 14. Семинары. №1. Модели. Параметрические (аналитические) модели, виды, свойства, атлас моделей для их предложения к реальным временным
- 15. 2.Выбор подхода при выборе методов моделирования и прогнозирования 2.1.Параметрический (аналитический) подход: Достоинства: относительно малые выборки (до
- 16. 2.2.Свойства аналитических функций при их выборе для моделирования трендов (временных и пространственных) Функция У=f(x) , где
- 17. Монотонность, асимптоты (вертикальные, горизонтальные, наклонные), ограниченные функции, обратная функция и ее график), сложная функция, неявная функция
- 18. Геометрический смысл производной. Экстремумы – минимумы и максимумы. Необходимые и достаточные условия экстремума функций одной и
- 19. Например, в экономической литературе по курсу «методы принятия оптимальных решений» рассматривалась ситуации принятия решений на основе
- 20. Точность моделирования характеризуется абсолютными или относительными значениями. Наиболее известен - коэффициент детерминации c диапазоном изменения [0,
- 21. Использование результатов моделирования объекта для прогнозирования его будущего состояния Модель обычно имеет целью прогнозирование траектории объекта
- 22. Нам кажется, что мы - заложники неведомого будущего… На самом деле мы – пленники хорошо известного
- 23. Самой простой и популярной моделью является парная линейная регрессия Отрицательная функциональная зависимость Положительная функциональная зависимость полное
- 24. Ряды Тейлора и Фурье Более общим решением аналитического моделирования сложных моделей трендов являются ряды. Например, если
- 25. Колебания пилообразной формы (см.теория управления запасами), Колебания треугольной формы, . Колебания куполообразной формы (моделирование сезонных отпусков)
- 26. Мы сами убедились в глобальной нелинейности эволюционной динамики (при эволюции социально-экономическая система приобретает – или теряет
- 27. Оценки параметров парной линейной регрессии решением «нормальной» системы алгебраических линейных уравнений (СЛАУ) оценки матожидания, центрированная с.в.:
- 28. Точечные оценки точности прогнозирования и моделирования « для оценки точности моделирования наиболее распространен коэффициент детерминации: отношение
- 29. Толкование смысла коэффициента детерминации и нелинейность доверительного интервала для парной линейной регрессии В числителе – мера
- 30. Точечные оценки точности оценок (статистик) генеральных числовых характеристик ………………………….. По выборке объемом n найдем k оценок
- 31. Гетероскедастичность (неравноточность оценок по оси аргумента) является одним из наиболее нежелательных проблем при идентификации и, силу
- 32. Интервальная оценка точности (надежность) генеральных математического ожидания и дисперсии t- аргумент, соответствующий значению функции Лапласа, равной
- 33. Скорректированный коэффициент детерминации при оценки точности моделирования
- 34. Обоснование выбора вида моделей при моделировании и прогнозировании Параметрический (аналитический) подход к выбору вида модели: Достоинства:
- 35. Эконометрика - «существует только то, что можно измерить» Экономика Метрика (измерение) Макроэкономика Микроэкономика - основы образования
- 36. Пример иллюстрации задач СППР Измерение показателей ( насколько корректно они измерены, представляют ли они то, что
- 37. Задача «спецификации» модели Нет ли переменных, которые следовало бы дополнительно включить в уравнение (например, цены на
- 38. Конструкция и задачи СППР в эконометрике: Конструкция: предназначена для различного уровня агрегирования объекта анализа, может быть
- 39. должна быть гибкой, адаптироваться к изменениям как организации, так и ее окружения, должна быть проста в
- 40. Моделирование и прогнозирование (наш курс и не только): Анализ каналов снабжения и распределения (логистика); Анализ производства;
- 41. Примеры решения конкретных задач с помощью СППР: - обоснование направлений развития систем высшего образования; - выбор
- 42. Архитектурно-технологическая схема СППР Первоначально информация хранится в оперативных базах данных (OLTP). Она используется в процедурах многомерного
- 43. СППР предназначены для выбора субъекта кредитования, исполнителя работы, назначения на должность, использования в торговых предприятиях, торгующих
- 44. Структуры траекторий определяемого параметра. Декомпозиция
- 45. Ряды Тейлора и Фурье Более общим решением аналитического моделирования сложных моделей трендов являются ряды. Например, если
- 46. Условие формирования рядов экономической (пространственной и временной) динамики Вместо дифференциальных уравнений широко используют разностные модели. Спектр
- 47. Формирование эквидистантных временных рядов: - максимальная частота спектра траектории, интервал дискретизации . Условие Найквиста (Котельникова) выбора
- 48. Колебания пилообразной формы, Колебания треугольной формы, . Колебания куполообразной формы . Три члена разложения в ряд
- 49. Мультитренды, как более сложное и гибкое представление тенденции Наряду с десятками аналитических моделей трендов, начиная с
- 50. Структуры (канонические) трендовой модели с детерминированной компонентой Аддитивная структура трендовой модели (условного математического ожидания от времени)
- 51. При реализации системного подхода для слабоагрегированного объекта анализа выполняется тренд-колебательная (неоднозначная) декомпозиция, которая включает в себя
- 52. Многообразие возможных структур декомпозиции: при взаимодействии тренда и колебательных (сезонной и циклической) компонент Предложены: и другие
- 53. Пример тренда: дифференциальное уравнение для тренда Гомпертца: . Аналитическое решение данного уравнения – известная «кумулятивная» или
- 54. Производная от кумулятивной (накопленной) логисты – «импульсная логиста». Используют и формирование импульсных и кумулятивных логист алгеброй
- 55. Выбор модели путем сравнения разных функций и атласы функций с разными параметрами для ВИЗУАЛЬНОГО предложения той
- 56. Многообразие (универсальность) форм (и далеко не всех приложений) логистических моделей (основных моделей эволюции) Динамика развития инфраструктуры
- 57. Жизненные цикла продукта, как примеры эволюции экономических объектов Этапы модели ЖЦП. Ранее были известны были лишь
- 58. Другие функции (линейные и нелинейные) по параметрам и определяющим переменным. Функции Гомпертца при различных значениях параметров
- 59. Популярные виды (линейные и нелинейные по параметрам и переменным) парные модели Квадратический полином Кубический полином (применяют
- 60. Формирование многообразия видов логистических трендов 1. Решение дифференциальных уравнений, описывающих динамику объектов. 2. Дифференцирование кумулятивных логист
- 61. Преимущества феноменологических моделей, получаемых обработкой реальных данных: -удобство количественного анализа динамики комплекса моделей через исследования нулей
- 62. Канонические (аддитивная и мультипликативная) структуры временных рядов Аддитивная структура Мультипликативная структура , , – ненаблюдаемые (unobserved)
- 63. Метод Census I Непараметрический метод, разработан американским агентством Census Bureau в 1954г. В результате получают значения
- 64. В начале выполняется сглаживание исходного ряда (простое скользящее среднее - материал уже был): Результат: предварительный ряд
- 65. Детрендирование- удаление полученного тренда из исходного ряда: А: М: Результат: зашумленный ряд значений сезонной компоненты. k
- 66. Выделение сезонной компоненты Берутся средние значения сезонных колебаний для каждого квартала (месяца): Результат: таблица сезонных корректировок.
- 67. Десезонализация- удаление сезонной компоненты из исходного ряда: А: М: Результат: «зашумленный» ряд значений тренда.
- 68. Повторное выделение тренда Используется взвешенное сглаживание глубиной 1-3 значения: Результат: окончательный ряд значений тренда.
- 69. Выделение стохастической компоненты Удаление сглаженных значений из исходного ряда: А: М: Результат: ряд случайных остатков и
- 70. Метод Census II Census II (1967г.) объединяет различные приемы и улучшения метода Census I. Наиболее известные
- 71. Метод итерационной параметрической декомпозиции Результат: математические модели тренда и сезонной компоненты, ряд значений стохастической компоненты (достоинство
- 72. Метод параметрической декомпозиции Тренд (идентификация с помощью МНК): Сезонная компонента:
- 73. Эволюция компонент моделей Для реальной экономической практики актуальна идентификация моделей на относительно коротких выборках – для
- 74. Интерполяция, экстраполяция, аппроксимация Интерполяция – метод восстановление тех значений определяемой переменной Y объекта, которые находятся «между»
- 75. Экстраполяция - определение значений модели вне известных узлов интервала значений (больших или меньших) аргумента модели. Она
- 76. Графическая иллюстрация интерполяции, экстраполяции и среднеквадратического приближения (аппроксимации) На рис. 4.1 показано сравнение интерполяционного полинома 6–й
- 77. Квантили распределения, как характеристика формы распределения, и возможность оценки ее параметров Через квантили может быть реализована
- 78. Квартили
- 79. Сравнение и обоснование выбора модели трендов на выборке Для обоснованного выбора модели могут быть необходимы дополнительные
- 80. О моделировании в случаях, когда размерности переменных существенно различаются Целесообразно использовать при больших различиях определяющей и
- 81. Линеаризация модели по переменным Квадратичный полином: (применяют для моделей с одной точкой экстремума) Гиперболический полином: Эта
- 82. Моделирование неслучайной компоненты D обратной функцией
- 83. Обобщим моделирование неслучайной компоненты обратной функцией Зависимость между объемом выпуска X и средними фиксированными издержками Y
- 84. При пропорционально-мультипликативном вхождении стохастической компоненты получим гетероскедастическую стохастическую компоненту (нужно применять методы ее компенсации, указанные выше).
- 85. Часто моделируют неслучайную компоненту дробно-рациональными функциями - в случае «пространственной» динамики моделирует спрос на определенный вид
- 86. Вид моделей Торквиста и другие модели спроса Для некоторых товаров длительного пользования используют и логарифмические модели,
- 87. Товар Гиффена — товар, потребление которого (при прочих равных условиях) увеличивается при повышении цены (то есть,
- 88. Подходы и методы прогнозирования емкости рынка:
- 89. Моделирование неслучайной компоненты степенной функцией (например, при изучении уровня оплаты труда от его производительности) Для (1)
- 90. Для модели (2) логарифмирование дает: При этом значения должно быть неотрицательны, т.е. также имеется существенное ограничение
- 91. Выявление детерминированных компонент ряда динамики «сглаживанием» (уменьшением стохастической компоненты) Сглаживание Аналитическое Алгоритмическое МНК НМНК СЛАУ Градиентные
- 92. Алгоритмические методы поиска экстремума функции потерь для двух параметрической нелинейной по параметрам модели Градиент, , ,
- 93. Возможности алгоритмического сглаживания: простого и текущего n- объем выборки ~ - символ сглаживания k=2, i=1, 2,
- 95. Моделирование треда алгоритмическим простым симметричным скользящим сглаживанием Простые скользящие средние (simple moving average, SMA) – значения
- 96. Пример простого (симметричного) сглаживания Чем больше глубина сглаживания r, тем более гладким получается ряд. Сглаженный ряд
- 97. k=3, i=1, 2, 3, 4, 5 k=4, i=2, 3, 4, 5, 6 …………………… равные веса Чем
- 98. Экспоненциальное сглаживание где - значение экспоненциальной средней (сглаженное значение исходного ряда динамики в момент наблюдения «k»
- 99. Для устранения сезонных колебаний на практике часто приходится использовать скользящее значение среднее с длиной интервала сглаживания,
- 100. Представим (1) в виде (раскроем ) т.е. является суммой и доли α от разности Последовательно подставляя
- 101. Экспоненциальное сглаживание сглаживает весь ряд в целом (выступающие значения (выбросы) ). Оператор экспоненциального сглаживания можно применить
- 102. Компенсация гетероскедастичности (ведет к неэффективности оценок регресии) Тестирование (не только визуальным наблюдением корреляционного поля) гетероскедастичности: тесты
- 103. Проблемы при выполнении приема логарифмирования при реализации линеаризации
- 104. Роль логнормального распределения при мультипликативной структуре стохастической компоненты в модели У многих моделей мультипликативная структура взаимодействия
- 105. О упрощениях при линеаризации: «дело не в том, люди зачастую не могут найти решение, а в
- 106. Модели роста и эволюции Логистическую тенденцию тренда (например, модели роста Гомпертца, Ферхульста и другие) упрощенно можно
- 107. Определение технологического уклада Технологические уклады — группы технологических совокупностей, связанные друг с другом однотипными технологическими цепями
- 108. Демонстрация технологического разрыва и объемов средств, требуемых для вложения в новую технологию Обычно в экономике одновременно
- 109. Диффузия инноваций Исследователи склоняются к тому, что именно на периоды депрессий приходятся основные инновации – технологические
- 110. Диффузия инноваций вдоль подъемов циклов экономической активности Кондратьева Циклы Кондратьева (живем и «учимся» в 5-ом). Известны
- 111. Модели производственных функций (ПФ) (известное количество ПФ - более 10) Модель производства можно представить, как некоторую
- 112. Прогнозирование с использованием производственных функций Очевидно, что изучив структуру объекта анализа (общую динамику показателей и их
- 113. Простейшая производственная функция – один продукт из одного ресурса: y = f(x) В реальности продуктов из
- 115. Свойства неоклассической производственной функции (для любого числа ресурсов): Необходимость всех ресурсов – без любого из них
- 121. 2. Степенная однофакторная производственная функция: При положительных значениях , производственная функция с ростом затрат ресурса объем
- 123. В ПФ Леонтьева может быть лишь единственная рациональная структура производственных ресурсов. ПФ Леонтьева предназначена для моделирования
- 124. Функция Кобба-Дугласа Пусть Y-объем выпущенной продукции (в стоимостном или натуральном выражении), K-объем основного капитала или основных
- 128. ПФ постоянной эластичности замены факторов (CES) и с линейной эластичностью замены факторов (LES) CES применяется в
- 129. ПФ Солоу и ПФ с большим числом факторов ПФ Солоу может применяться примерно в тех же
- 130. Задача агрегирования производственных функций на различных уровнях экономики ПФ – это технологическое соотношение, стоящее перед фирмой.
- 131. Преимущества пространственных выборок для моделирования ПФ Значения переменных в пространственных выборках имеют, как правило, значительно больший
- 132. Когда исследователь работает с временными рядами агрегированных показателей выпуска и затрат ресурсов, то полученная ПФ отражает
- 133. Множественная линейная регрессия Недостатки: «проклятие размерности», ее уменьшение (редукция), мнимая точность (линейность связи по параметрам и
- 134. Мультиколлинеарность при идентификации ПФ Большой проблемой при идентификации может быть мультиколлинеарность: все или некоторые независимые переменные
- 135. Генетический алгоритм (ГА) оптимизации функции потерь при идентификации моделей ГА является одним из наиболее универсальных и
- 136. Так и воспроизводится вся новая популяция, выбирая лучших представителей предыдущего поколения, скрещивая их и получая множество
- 137. В процессе «селекции» отбирают только несколько лучших «пробных» решений, на основании заданного критерия (например, МНК). «Скрещивание»
- 138. ГА применяются для решения следующих задач: оптимизация функций; разнообразные задачи на графах (задача коммивояжера, раскраска вершин
- 139. Критерии останова ГА Важный момент функционирования алгоритма ГА – определение критериев останова. В качестве критериев останова
- 140. Лаги в экономических моделях При анализе многих экономических показателей (особенно в макроэкономике) часто используются ежегодные, ежеквартальные,
- 141. Причин наличия лагов в экономике достаточно много, и среди них можно выделить следующие: Психологические причины –
- 142. Модели авторегрессии (применяют более 100 видов авторегрессий) Наиболее известны следующие виды моделей: собственно модели авторегрессии (AR
- 143. Частные виды авторегрессий Модель парной пространственной линейной регрессии: Авторегрессионные модели (AР-модели): первого порядка порядка P Пространственная
- 144. авторегрессии - проинтегрированного скользящего среднего (ARIMA - autoregressive integrated moving average) – они оправданы в первую
- 145. Конструирование моделей авторегрессии Прямое Z-преобразование (и его свойства): Дискретные наблюдения действительной переменной (времени) становятся функцией комплексной
- 146. Экспоненциальная функция, обобщенная экспоненциальная функция, экспоненциальные полиномы Экспонента относится к числу самых распространенных моделей в экономике,
- 147. Для экспоненты Z – преобразование при дает разностную схему первого порядка: Запишем теперь разностную схему через
- 148. Рассмотрим теперь гармонику с аддитивной стохастической компонентой 1 этап: модель авторегрессии для оценки частоты: МНК, СЛАУ
- 149. Колебания пилообразной формы, Колебания треугольной формы, Колебания куполообразной формы. . Напомню, что три члена разложения передают
- 150. Автокорреляция стохастических компонент в моделях регрессии, методы их компенсации Из анализа автокорреляции можно, как уже показано
- 151. Преимущества и недостатки моделей трендов Преимущества: - возможность реализации и двух подходов к моделированию – в
- 152. Модели Койка Модель (с геометрически распределенными лагами) Модель адаптивных ожиданий по определяющему фактору Модель частичной корректировки
- 153. Модель с геометрически распределенными лагами (1 метод) Предполагается, что коэффициенты модели убывают в геометрической прогрессии: .
- 154. Модель с геометрически распределенными лагами (2 метод - преобразование Койка) Получим авторегрессионную модель Койка: К данной
- 155. Пример сравнения методик расчета параметров Имеются данные о динамики цен на сырье Xk и цен на
- 156. Модель адаптивных ожиданий и корректировки Модели используются для эмпирической верификации макроэкономических моделей, в которых учитываются ожидания
- 157. Модель адаптивных ожиданий определяющего фактора коррекция прогноза на шаг вперед -коэффициент ожидания ошибка прогноза Если стремится
- 158. Преобразование модели адаптивных ожиданий использует подстановку (3) в модель авторегрессии (1), что дает: Получим авторегрессионная модель
- 159. Обратное преобразование Койка … Получим модель с геометрически распределенными лагами для которого вновь возможен перебор по
- 160. Модель частичной корректировки Авторегрессионная модель Койка, для идентификации которой можно применить МНК: Частичная корректировка:
- 161. Модель частичной корректировки Вновь приходим к авторегрессионной модели Койка и известным способам её решения: Частичная корректировка:
- 162. Примеры применения моделей авторегрессии: определяемая переменная - реальная заработанная плата, а определяющий фактор - ожидаемая величина
- 163. Варианты структуры лага в авторегрессиях с распределенными лагами полиномиальная структура лага
- 164. Метод Алмон для динамических моделей с распределенными размерами Не имеют тенденции убывать во времени Имеют тенденции
- 165. Распределенные лаги Ш. Алмон Предполагается, что коэффициенты изменяются по полиномиальному закону: m - выбранный порядок полинома
- 166. Характеристики метода Алмон для динамических моделей с распределенными размерами Основные недостатки метода Алмон: -величины лага L
- 167. Задачи формирования инструментария моделирования и прогнозирования сравнить современные аналитические и численные методы решения ДУ: Левенберга -
- 168. Актуальные области моделирования и прогнозирования моделями, рассматриваемыми в рамках курса динамика добычи невосполняемых ресурсов: нефти, газа,
- 169. Компьютерно-интенсивные методы моделирования (рандомизация, бутстреп и методы Монте-Карло) Семейство процедур Монте-Карло (метода статистических испытаний) – многократная
- 170. Идея бутстрепа (бутстрапа) по Б. Эфрону (1979г.) Приближенную оценку статистик стохастической компоненты, доверительных интервалов параметров и
- 171. На основе только исходной выборки, мы всегда можем получить бутстреп-модели генеральных распределений и для нулевой и
- 172. Примеры применения методов моделирования и прогнозирования в экономической практике
- 173. Примеры приложений дробно-рациональных моделей на примерах ЖЦ IT-технологий Доли ОС семейства Windows на рынке Моделирование жизненного
- 174. Примеры применения сумм дробно-рациональных моделей для безработицы в Самарской области Результаты моделирования численности безработных в Самарской
- 175. ЖЦП Electronic Arts (EA), разработчик компьютерных видеоигр
- 176. ЖЦП Electronic Arts (EA) - разработчик компьютерных видеоигр Динамика развития сотовой связи имеет логистический характер. Уровень
- 177. Моделирование циклов продаж товара одного из самарских производителей: мультимодельность (повторный цикл) R2 = 0,790; MAPE =
- 178. Численность населения г.о. Самара
- 179. Мониторинг цен на бензин Полиномиальная модель с аддитивно-мультипликативными колебательными компонентами Динамика изменения цен на бензин на
- 180. Динамики цен на бензин на территории Самарской области (руб./л)
- 181. Инвестиции в основной капитал Самарской области
- 182. Модели добычи нефти Новые месторождения Опора на полевые исследования пласта Фильтрационные модели разработки месторождений Феноменологические модели
- 183. Годовая добыча нефти месторождения Самарской области функцией Рамсея
- 184. Колоколообразные модели (импульсные логисты)тренда добычи нефти (и других невосполняемых ресурсов) Хабберта Эмпирические (феноменологические) модели добычи: Коши-Капицы
- 185. Задание асимметрии путем введения функции σ = σ(t) Брандт: исследовано 67 месторождений, уровень падения в среднем
- 186. Ферхюльста Ричардса Гомперца Рамсея
- 187. Выбор предпочтительной феноменологической модели для анализа добычи нефти и газа на отдельных месторождениях Для выбора лучших
- 188. Учет колебательной компоненты
- 189. На сегодняшний день в мире насчитывается больше 1000 статистических пакетов. Статистические пакеты делятся на несколько категорий.
- 191. Скачать презентацию

То, что видим мы – видимость только одна.
Далеко от поверхности моря
То, что видим мы – видимость только одна.
Далеко от поверхности моря

Рекомендуемая литература
Аникин П.В., Королев В.А., Тороповцев Е.А Математические и инструментальные методы.
Рекомендуемая литература
Аникин П.В., Королев В.А., Тороповцев Е.А Математические и инструментальные методы.

Прикладная статистика. Основы эконометрики: Учебник для вузов: В 2 т.
Прикладная статистика. Основы эконометрики: Учебник для вузов: В 2 т.

19. Мастицкий С.Э., Шитиков В.К. Статистический анализ и визуализация данных с
19. Мастицкий С.Э., Шитиков В.К. Статистический анализ и визуализация данных с

Главный враг Знания
– не невежество, а иллюзия знаний.
Главный враг Знания
– не невежество, а иллюзия знаний.

Необходимость моделирования
Каждое лицо принимающее на практике какие-либо решения (ЛПР) руководствуется
Необходимость моделирования
Каждое лицо принимающее на практике какие-либо решения (ЛПР) руководствуется

Неопределенность описывается
теорией вероятностей
и/или
теорией нечетких множеств (fuzzy sets)
и
нечеткой логикой
Неопределенность описывается
теорией вероятностей
и/или
теорией нечетких множеств (fuzzy sets)
и
нечеткой логикой

Нечеткая логика - раздел современной математики, позволяющий формализовать и перевести на
Нечеткая логика - раздел современной математики, позволяющий формализовать и перевести на

Понятия нечеткой логики
(нечеткие множества и высказывания) появились в середине 1960-годов
Понятия нечеткой логики
(нечеткие множества и высказывания) появились в середине 1960-годов

Первый период характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э.
Первый период характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э.

Триумфальное шествие нечеткой логики по миру началось после доказательства в конце
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце

.
Лаплас, Пуассон, Гаусс, Бернулли, П.Л. Чебышев, А.М. Ляпунов А.А. Марков,
.
Лаплас, Пуассон, Гаусс, Бернулли, П.Л. Чебышев, А.М. Ляпунов А.А. Марков,

Семинары.
№1. Модели. Параметрические (аналитические) модели, виды, свойства, атлас моделей для их
Семинары. №1. Модели. Параметрические (аналитические) модели, виды, свойства, атлас моделей для их

2.Выбор подхода при выборе методов моделирования и прогнозирования
2.1.Параметрический (аналитический) подход:
Достоинства:
2.Выбор подхода при выборе методов моделирования и прогнозирования
2.1.Параметрический (аналитический) подход:
Достоинства:

2.2.Свойства аналитических функций при их выборе для моделирования трендов (временных и
2.2.Свойства аналитических функций при их выборе для моделирования трендов (временных и

Монотонность, асимптоты (вертикальные, горизонтальные, наклонные), ограниченные функции, обратная функция и ее
Монотонность, асимптоты (вертикальные, горизонтальные, наклонные), ограниченные функции, обратная функция и ее

Геометрический смысл производной.
Экстремумы – минимумы и максимумы.
Необходимые и достаточные условия
Геометрический смысл производной.
Экстремумы – минимумы и максимумы.
Необходимые и достаточные условия

Например, в экономической литературе по курсу «методы принятия оптимальных решений» рассматривалась
Например, в экономической литературе по курсу «методы принятия оптимальных решений» рассматривалась

Точность моделирования характеризуется абсолютными или относительными значениями. Наиболее известен -
Точность моделирования характеризуется абсолютными или относительными значениями. Наиболее известен -

Использование результатов моделирования объекта для прогнозирования его будущего состояния
Модель
Использование результатов моделирования объекта для прогнозирования его будущего состояния
Модель

Нам кажется, что мы - заложники неведомого будущего…
На самом
Нам кажется, что мы - заложники неведомого будущего…
На самом

Самой простой и популярной моделью является парная линейная регрессия
Отрицательная функциональная
зависимость
Самой простой и популярной моделью является парная линейная регрессия
Отрицательная функциональная
зависимость

Ряды Тейлора и Фурье
Более общим решением аналитического моделирования сложных
Ряды Тейлора и Фурье
Более общим решением аналитического моделирования сложных
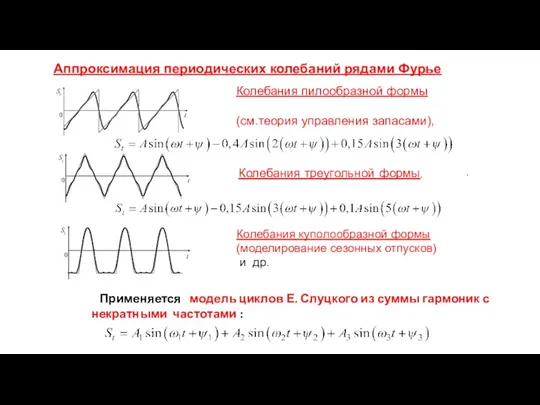
Колебания пилообразной формы
(см.теория управления запасами),
Колебания треугольной формы,
.
Колебания куполообразной формы
(моделирование сезонных
Колебания пилообразной формы
(см.теория управления запасами),
Колебания треугольной формы,
.
Колебания куполообразной формы
(моделирование сезонных

Мы сами убедились в глобальной нелинейности эволюционной динамики (при эволюции социально-экономическая
Мы сами убедились в глобальной нелинейности эволюционной динамики (при эволюции социально-экономическая

Оценки параметров парной линейной регрессии решением
«нормальной» системы алгебраических линейных уравнений
Оценки параметров парной линейной регрессии решением
«нормальной» системы алгебраических линейных уравнений

Точечные оценки точности прогнозирования и моделирования
«
для оценки точности моделирования наиболее
Точечные оценки точности прогнозирования и моделирования
«
для оценки точности моделирования наиболее

Толкование смысла коэффициента детерминации и нелинейность доверительного интервала для парной линейной
Толкование смысла коэффициента детерминации и нелинейность доверительного интервала для парной линейной

Точечные оценки точности оценок (статистик) генеральных числовых характеристик
…………………………..
По выборке объемом
Точечные оценки точности оценок (статистик) генеральных числовых характеристик
…………………………..
По выборке объемом

Гетероскедастичность (неравноточность оценок по оси аргумента) является одним из наиболее
Гетероскедастичность (неравноточность оценок по оси аргумента) является одним из наиболее

Интервальная оценка точности (надежность)
генеральных математического ожидания и дисперсии
t- аргумент, соответствующий
Интервальная оценка точности (надежность)
генеральных математического ожидания и дисперсии
t- аргумент, соответствующий

Скорректированный коэффициент детерминации при оценки точности моделирования
Скорректированный коэффициент детерминации при оценки точности моделирования

Обоснование выбора вида моделей при моделировании и прогнозировании
Параметрический (аналитический)
Обоснование выбора вида моделей при моделировании и прогнозировании
Параметрический (аналитический)

Эконометрика - «существует только то, что можно измерить»
Экономика Метрика (измерение)
Макроэкономика
Микроэкономика - основы образования
Эконометрика - «существует только то, что можно измерить»
Экономика Метрика (измерение)
Макроэкономика
Микроэкономика - основы образования

Пример иллюстрации задач СППР
Измерение показателей ( насколько корректно они измерены, представляют
Пример иллюстрации задач СППР
Измерение показателей ( насколько корректно они измерены, представляют

Задача «спецификации» модели
Нет ли переменных, которые следовало бы дополнительно включить в
Задача «спецификации» модели
Нет ли переменных, которые следовало бы дополнительно включить в

Конструкция и задачи СППР в эконометрике:
Конструкция: предназначена для различного уровня
Конструкция и задачи СППР в эконометрике:
Конструкция: предназначена для различного уровня

должна быть гибкой, адаптироваться к изменениям как организации, так и ее
должна быть гибкой, адаптироваться к изменениям как организации, так и ее

Моделирование и прогнозирование (наш курс и не только):
Анализ каналов снабжения
Моделирование и прогнозирование (наш курс и не только):
Анализ каналов снабжения

Примеры решения конкретных задач с помощью СППР:
- обоснование направлений развития
Примеры решения конкретных задач с помощью СППР:
- обоснование направлений развития

Архитектурно-технологическая схема СППР
Первоначально информация хранится в оперативных базах данных (OLTP). Она
Архитектурно-технологическая схема СППР
Первоначально информация хранится в оперативных базах данных (OLTP). Она

СППР предназначены для выбора субъекта кредитования, исполнителя работы, назначения на должность,
СППР предназначены для выбора субъекта кредитования, исполнителя работы, назначения на должность,

Структуры траекторий определяемого параметра. Декомпозиция
Структуры траекторий определяемого параметра. Декомпозиция

Ряды Тейлора и Фурье
Более общим решением аналитического моделирования сложных
Ряды Тейлора и Фурье
Более общим решением аналитического моделирования сложных
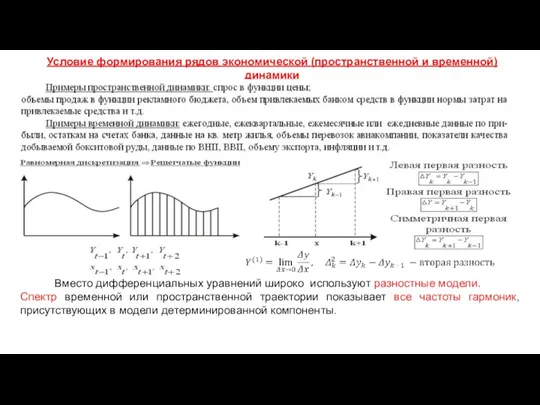
Условие формирования рядов экономической (пространственной и временной) динамики
Вместо дифференциальных
Условие формирования рядов экономической (пространственной и временной) динамики
Вместо дифференциальных
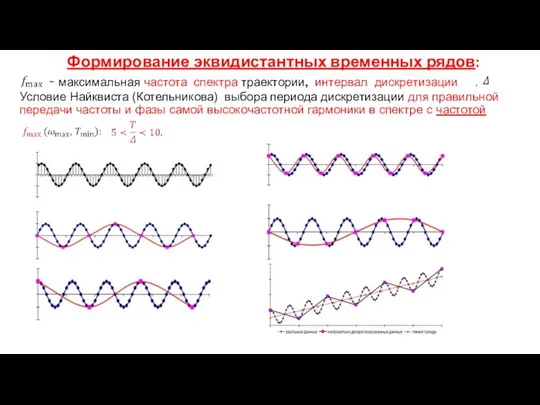
Формирование эквидистантных временных рядов:
- максимальная частота спектра траектории, интервал
Формирование эквидистантных временных рядов: - максимальная частота спектра траектории, интервал
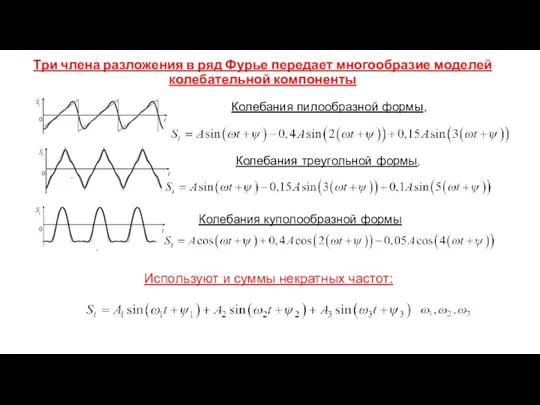
Колебания пилообразной формы,
Колебания треугольной формы,
.
Колебания куполообразной формы
.
Три члена
Колебания пилообразной формы,
Колебания треугольной формы,
.
Колебания куполообразной формы
.
Три члена
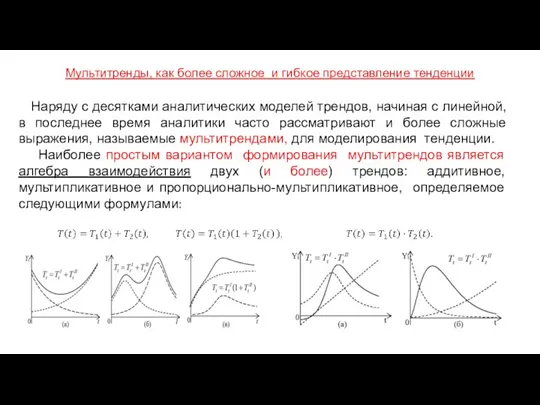
Мультитренды, как более сложное и гибкое представление тенденции
Наряду с
Мультитренды, как более сложное и гибкое представление тенденции
Наряду с

Структуры (канонические) трендовой модели с детерминированной компонентой
Аддитивная структура
Структуры (канонические) трендовой модели с детерминированной компонентой
Аддитивная структура

При реализации системного подхода для слабоагрегированного объекта анализа выполняется тренд-колебательная (неоднозначная)
При реализации системного подхода для слабоагрегированного объекта анализа выполняется тренд-колебательная (неоднозначная)

Многообразие возможных структур декомпозиции: при взаимодействии тренда и колебательных (сезонной
Многообразие возможных структур декомпозиции: при взаимодействии тренда и колебательных (сезонной

Пример тренда: дифференциальное уравнение для тренда Гомпертца:
.
Аналитическое решение
Пример тренда: дифференциальное уравнение для тренда Гомпертца:
.
Аналитическое решение
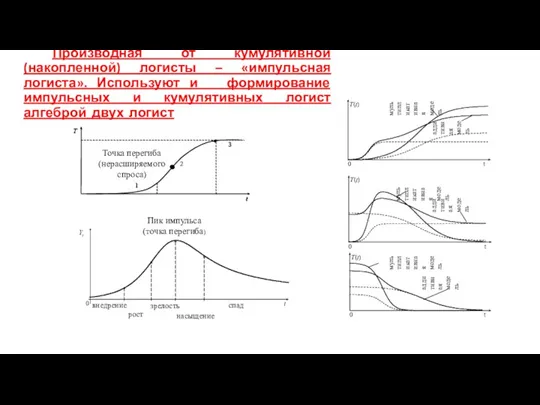
Производная от кумулятивной (накопленной) логисты – «импульсная логиста». Используют и
Производная от кумулятивной (накопленной) логисты – «импульсная логиста». Используют и

Выбор модели путем сравнения разных функций и атласы функций с разными
Выбор модели путем сравнения разных функций и атласы функций с разными
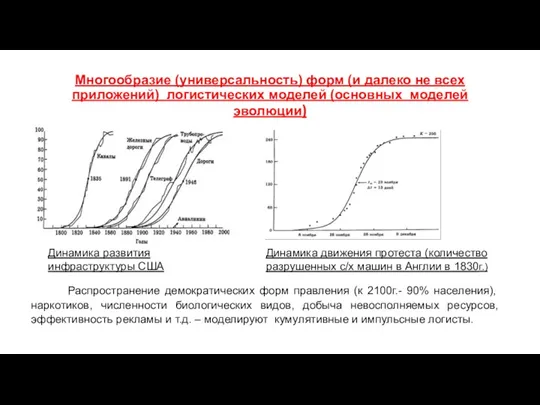
Многообразие (универсальность) форм (и далеко не всех приложений) логистических моделей (основных
Многообразие (универсальность) форм (и далеко не всех приложений) логистических моделей (основных
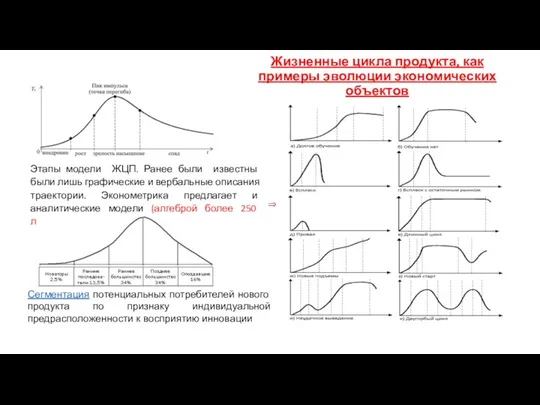
Жизненные цикла продукта, как
примеры эволюции экономических объектов
Этапы модели ЖЦП. Ранее
Жизненные цикла продукта, как
примеры эволюции экономических объектов
Этапы модели ЖЦП. Ранее
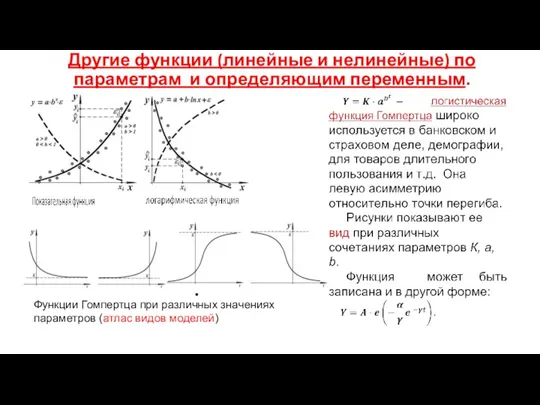
Другие функции (линейные и нелинейные) по параметрам и определяющим переменным.
Функции Гомпертца
Другие функции (линейные и нелинейные) по параметрам и определяющим переменным.
Функции Гомпертца
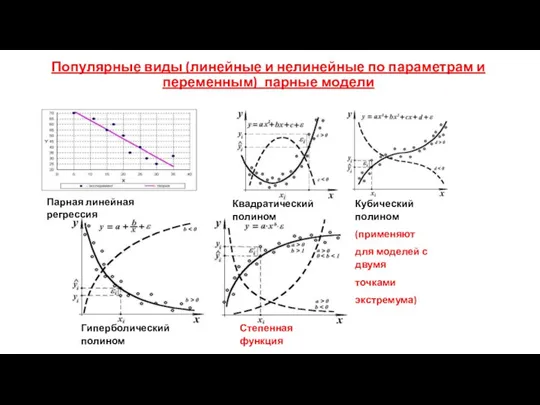
Популярные виды (линейные и нелинейные по параметрам и переменным) парные модели
Квадратический
Популярные виды (линейные и нелинейные по параметрам и переменным) парные модели
Квадратический

Формирование многообразия видов логистических трендов
1. Решение дифференциальных уравнений, описывающих динамику объектов.
2.
Формирование многообразия видов логистических трендов
1. Решение дифференциальных уравнений, описывающих динамику объектов.
2.

Преимущества феноменологических моделей, получаемых обработкой реальных данных:
-удобство количественного анализа динамики комплекса
Преимущества феноменологических моделей, получаемых обработкой реальных данных:
-удобство количественного анализа динамики комплекса

Канонические (аддитивная и мультипликативная) структуры временных рядов
Аддитивная структура
Мультипликативная структура
Канонические (аддитивная и мультипликативная) структуры временных рядов
Аддитивная структура
Мультипликативная структура

Метод Census I
Непараметрический метод, разработан американским агентством Census Bureau в 1954г.
В
Метод Census I
Непараметрический метод, разработан американским агентством Census Bureau в 1954г.
В
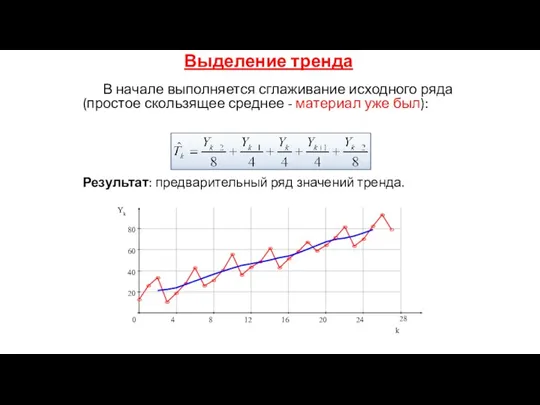
В начале выполняется сглаживание исходного ряда (простое скользящее среднее - материал
В начале выполняется сглаживание исходного ряда (простое скользящее среднее - материал
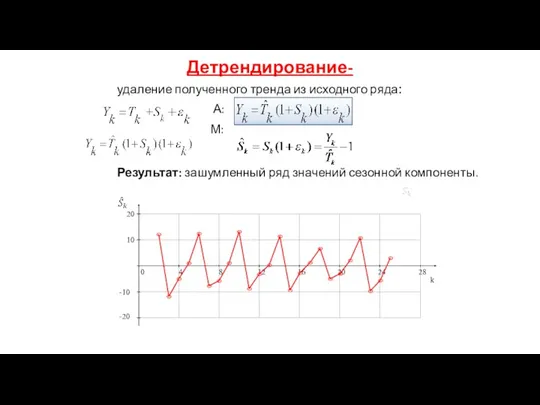
Детрендирование-
удаление полученного тренда из исходного ряда:
А:
М:
Результат: зашумленный ряд значений
Детрендирование-
удаление полученного тренда из исходного ряда:
А:
М:
Результат: зашумленный ряд значений
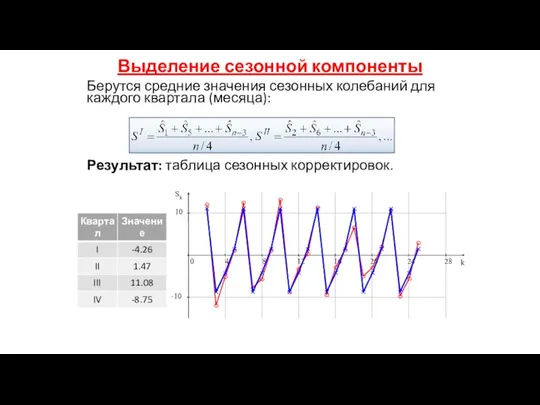
Выделение сезонной компоненты
Берутся средние значения сезонных колебаний для каждого квартала (месяца):
Результат:
Выделение сезонной компоненты
Берутся средние значения сезонных колебаний для каждого квартала (месяца):
Результат:
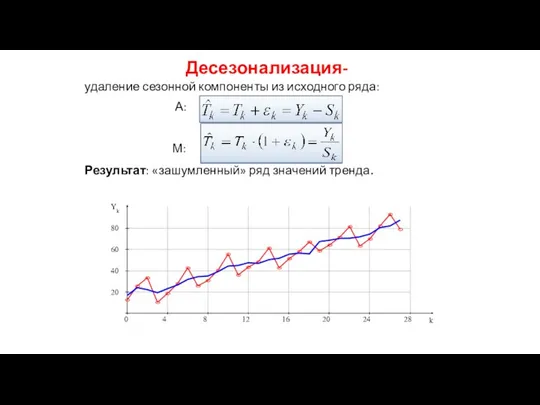
Десезонализация-
удаление сезонной компоненты из исходного ряда:
А:
М:
Результат: «зашумленный» ряд значений
Десезонализация-
удаление сезонной компоненты из исходного ряда:
А:
М:
Результат: «зашумленный» ряд значений
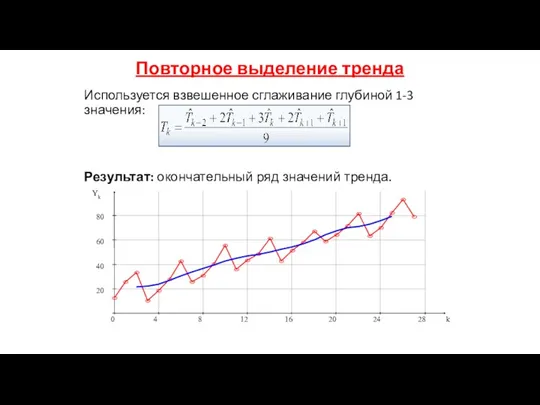
Повторное выделение тренда
Используется взвешенное сглаживание глубиной 1-3 значения:
Результат: окончательный ряд значений
Повторное выделение тренда
Используется взвешенное сглаживание глубиной 1-3 значения:
Результат: окончательный ряд значений
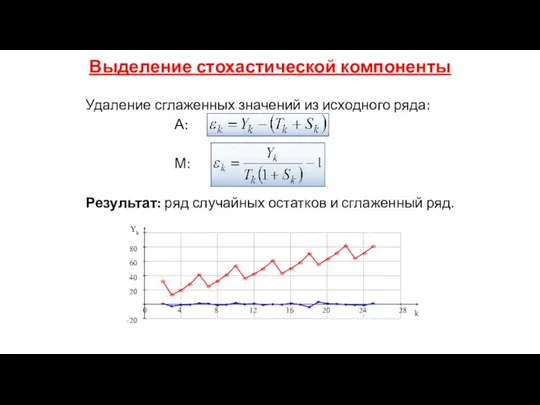
Выделение стохастической компоненты
Удаление сглаженных значений из исходного ряда:
А:
М:
Результат: ряд
Выделение стохастической компоненты
Удаление сглаженных значений из исходного ряда:
А:
М:
Результат: ряд

Метод Census II
Census II (1967г.) объединяет различные приемы и улучшения метода Census I.
Метод Census II
Census II (1967г.) объединяет различные приемы и улучшения метода Census I.

Метод итерационной параметрической декомпозиции
Результат:
математические модели тренда и сезонной компоненты, ряд
Метод итерационной параметрической декомпозиции
Результат:
математические модели тренда и сезонной компоненты, ряд
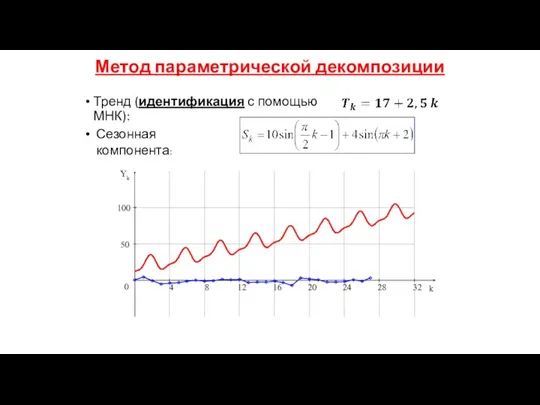
Метод параметрической декомпозиции
Тренд (идентификация с помощью МНК):
Сезонная компонента:
Метод параметрической декомпозиции
Тренд (идентификация с помощью МНК):
Сезонная компонента:

Эволюция компонент моделей
Для реальной экономической практики актуальна идентификация моделей на
Эволюция компонент моделей
Для реальной экономической практики актуальна идентификация моделей на

Интерполяция, экстраполяция, аппроксимация
Интерполяция – метод восстановление тех значений определяемой переменной Y
Интерполяция, экстраполяция, аппроксимация
Интерполяция – метод восстановление тех значений определяемой переменной Y

Экстраполяция - определение значений модели вне известных узлов интервала значений
Экстраполяция - определение значений модели вне известных узлов интервала значений

Графическая иллюстрация интерполяции, экстраполяции и среднеквадратического приближения (аппроксимации)
На рис. 4.1
Графическая иллюстрация интерполяции, экстраполяции и среднеквадратического приближения (аппроксимации)
На рис. 4.1

Квантили распределения, как характеристика формы
распределения, и возможность оценки ее параметров
Квантили распределения, как характеристика формы
распределения, и возможность оценки ее параметров
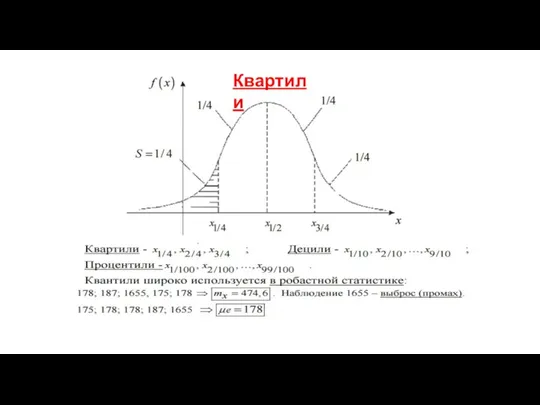
Квартили
Квартили

Сравнение и обоснование выбора модели трендов на выборке
Для обоснованного выбора
Сравнение и обоснование выбора модели трендов на выборке
Для обоснованного выбора

О моделировании в случаях, когда размерности переменных существенно различаются
Целесообразно использовать
О моделировании в случаях, когда размерности переменных существенно различаются
Целесообразно использовать

Линеаризация модели по переменным
Квадратичный полином:
(применяют для моделей с одной
точкой экстремума)
Линеаризация модели по переменным
Квадратичный полином:
(применяют для моделей с одной
точкой экстремума)

Моделирование неслучайной компоненты D обратной функцией
Моделирование неслучайной компоненты D обратной функцией

Обобщим моделирование неслучайной компоненты обратной функцией
Зависимость между объемом выпуска X
Обобщим моделирование неслучайной компоненты обратной функцией
Зависимость между объемом выпуска X

При пропорционально-мультипликативном вхождении стохастической компоненты
получим гетероскедастическую стохастическую компоненту (нужно применять
При пропорционально-мультипликативном вхождении стохастической компоненты
получим гетероскедастическую стохастическую компоненту (нужно применять

Часто моделируют неслучайную компоненту дробно-рациональными функциями
- в случае «пространственной» динамики моделирует
Часто моделируют неслучайную компоненту дробно-рациональными функциями
- в случае «пространственной» динамики моделирует

Вид моделей Торквиста и другие модели спроса
Для некоторых товаров длительного
Вид моделей Торквиста и другие модели спроса
Для некоторых товаров длительного

Товар Гиффена — товар, потребление которого (при прочих равных условиях) увеличивается
Товар Гиффена — товар, потребление которого (при прочих равных условиях) увеличивается

Подходы и методы прогнозирования емкости рынка:
Подходы и методы прогнозирования емкости рынка:

Моделирование неслучайной компоненты степенной функцией (например, при изучении уровня оплаты труда
Моделирование неслучайной компоненты степенной функцией (например, при изучении уровня оплаты труда

Для модели (2) логарифмирование дает:
При этом значения должно быть неотрицательны,
Для модели (2) логарифмирование дает:
При этом значения должно быть неотрицательны,

Выявление детерминированных компонент ряда динамики «сглаживанием» (уменьшением стохастической компоненты)
Сглаживание
Аналитическое
Алгоритмическое
МНК
НМНК
СЛАУ
Градиентные методы (Гаусса,
Сглаживание
Аналитическое
Алгоритмическое
МНК
НМНК
СЛАУ
Градиентные методы (Гаусса,

Алгоритмические методы поиска экстремума функции потерь для двух параметрической нелинейной по
Алгоритмические методы поиска экстремума функции потерь для двух параметрической нелинейной по
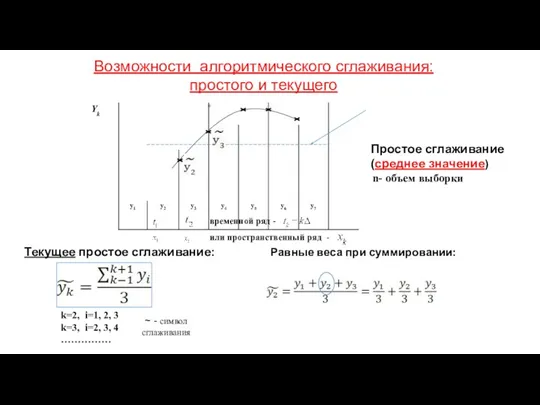
Возможности алгоритмического сглаживания:
простого и текущего
n- объем выборки
~ -
Возможности алгоритмического сглаживания:
простого и текущего
n- объем выборки
~ -


Моделирование треда алгоритмическим простым симметричным скользящим сглаживанием
Простые скользящие средние (simple
Моделирование треда алгоритмическим простым симметричным скользящим сглаживанием
Простые скользящие средние (simple
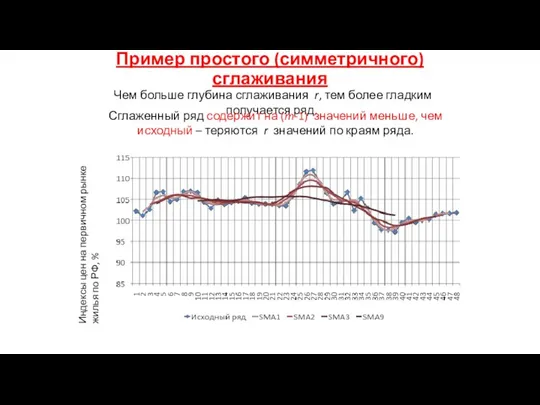
Пример простого (симметричного) сглаживания
Чем больше глубина сглаживания r, тем более
Пример простого (симметричного) сглаживания
Чем больше глубина сглаживания r, тем более

k=3, i=1, 2, 3, 4, 5
k=4, i=2, 3, 4, 5,
k=3, i=1, 2, 3, 4, 5
k=4, i=2, 3, 4, 5,

Экспоненциальное сглаживание
где - значение экспоненциальной средней (сглаженное значение исходного ряда динамики
Экспоненциальное сглаживание
где - значение экспоненциальной средней (сглаженное значение исходного ряда динамики

Для устранения сезонных колебаний на практике часто приходится использовать скользящее значение
Для устранения сезонных колебаний на практике часто приходится использовать скользящее значение

Представим (1) в виде (раскроем )
т.е. является суммой и доли
Представим (1) в виде (раскроем )
т.е. является суммой и доли

Экспоненциальное сглаживание сглаживает весь ряд в целом (выступающие значения (выбросы) ).
Экспоненциальное сглаживание сглаживает весь ряд в целом (выступающие значения (выбросы) ).

Компенсация гетероскедастичности (ведет к неэффективности оценок регресии)
Тестирование (не только визуальным наблюдением
Компенсация гетероскедастичности (ведет к неэффективности оценок регресии)
Тестирование (не только визуальным наблюдением

Проблемы при выполнении приема логарифмирования при реализации линеаризации
Проблемы при выполнении приема логарифмирования при реализации линеаризации

Роль логнормального распределения при мультипликативной структуре стохастической компоненты в модели
У многих
Роль логнормального распределения при мультипликативной структуре стохастической компоненты в модели
У многих

О упрощениях при линеаризации: «дело не в том, люди зачастую не
О упрощениях при линеаризации: «дело не в том, люди зачастую не

Модели роста и эволюции
Логистическую тенденцию тренда (например, модели роста Гомпертца,
Модели роста и эволюции
Логистическую тенденцию тренда (например, модели роста Гомпертца,

Определение технологического уклада
Технологические уклады — группы технологических совокупностей, связанные друг
Определение технологического уклада
Технологические уклады — группы технологических совокупностей, связанные друг
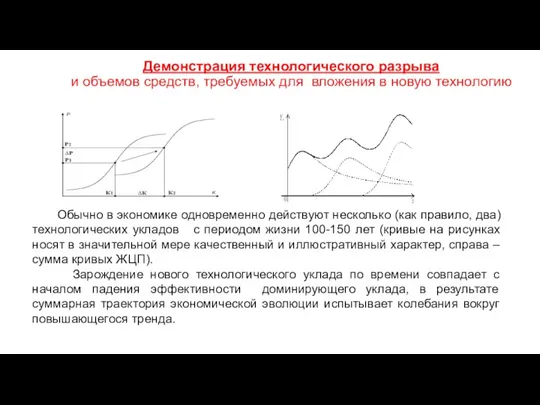
Демонстрация технологического разрыва
и объемов средств, требуемых для вложения в новую
Демонстрация технологического разрыва и объемов средств, требуемых для вложения в новую

Диффузия инноваций
Исследователи склоняются к тому, что именно на периоды депрессий
Диффузия инноваций
Исследователи склоняются к тому, что именно на периоды депрессий

Диффузия инноваций вдоль подъемов циклов экономической активности Кондратьева
Циклы Кондратьева (живем и
Диффузия инноваций вдоль подъемов циклов экономической активности Кондратьева
Циклы Кондратьева (живем и

Модели производственных функций (ПФ)
(известное количество ПФ - более 10)
Модель производства
Модели производственных функций (ПФ)
(известное количество ПФ - более 10)
Модель производства

Прогнозирование с использованием производственных функций
Очевидно, что изучив структуру объекта анализа (общую
Прогнозирование с использованием производственных функций
Очевидно, что изучив структуру объекта анализа (общую

Простейшая производственная функция – один продукт из одного ресурса:
y = f(x)
В
Простейшая производственная функция – один продукт из одного ресурса:
y = f(x)
В


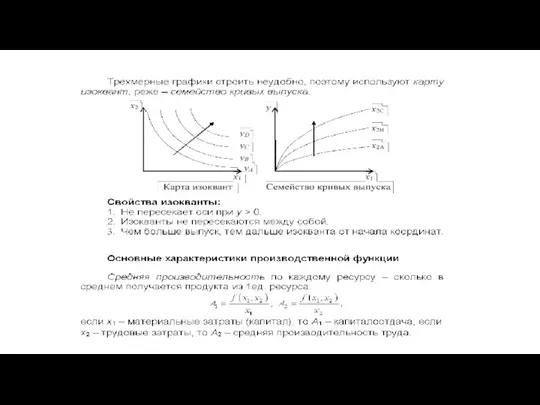
Свойства неоклассической производственной функции (для любого числа ресурсов):
Необходимость всех ресурсов
Свойства неоклассической производственной функции (для любого числа ресурсов):
Необходимость всех ресурсов





2. Степенная однофакторная производственная функция:
При положительных значениях , производственная функция
2. Степенная однофакторная производственная функция: При положительных значениях , производственная функция
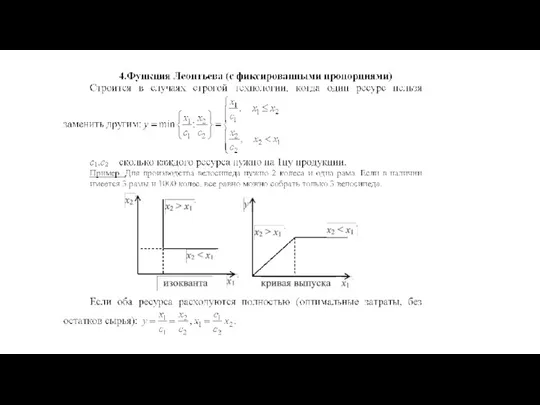

В ПФ Леонтьева может быть лишь единственная рациональная структура
В ПФ Леонтьева может быть лишь единственная рациональная структура

Функция Кобба-Дугласа
Пусть Y-объем выпущенной продукции (в стоимостном или натуральном выражении),
Функция Кобба-Дугласа
Пусть Y-объем выпущенной продукции (в стоимостном или натуральном выражении),

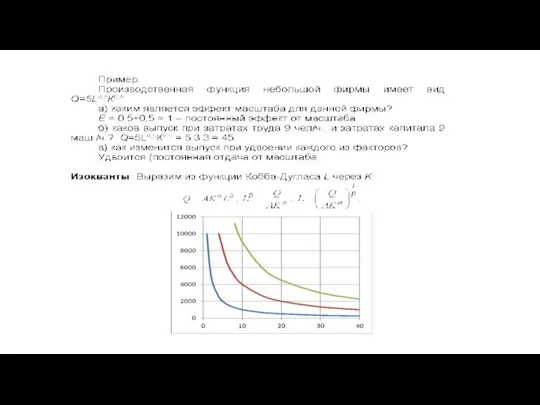


ПФ постоянной эластичности замены факторов (CES) и с линейной эластичностью замены
ПФ постоянной эластичности замены факторов (CES) и с линейной эластичностью замены

ПФ Солоу и ПФ с большим числом факторов
ПФ Солоу может
ПФ Солоу и ПФ с большим числом факторов
ПФ Солоу может

Задача агрегирования производственных функций на различных уровнях экономики
ПФ – это
Задача агрегирования производственных функций на различных уровнях экономики
ПФ – это

Преимущества пространственных выборок для моделирования ПФ
Значения переменных в пространственных выборках
Преимущества пространственных выборок для моделирования ПФ
Значения переменных в пространственных выборках

Когда исследователь работает с временными рядами агрегированных показателей выпуска и
Когда исследователь работает с временными рядами агрегированных показателей выпуска и

Множественная линейная регрессия
Недостатки: «проклятие размерности», ее уменьшение (редукция), мнимая точность
Множественная линейная регрессия
Недостатки: «проклятие размерности», ее уменьшение (редукция), мнимая точность

Мультиколлинеарность при идентификации ПФ
Большой проблемой при идентификации может быть мультиколлинеарность: все
Мультиколлинеарность при идентификации ПФ
Большой проблемой при идентификации может быть мультиколлинеарность: все

Генетический алгоритм (ГА) оптимизации функции потерь при идентификации моделей
Генетический алгоритм (ГА) оптимизации функции потерь при идентификации моделей

Так и воспроизводится вся новая популяция, выбирая лучших представителей предыдущего
Так и воспроизводится вся новая популяция, выбирая лучших представителей предыдущего

В процессе «селекции» отбирают только несколько лучших «пробных» решений, на
В процессе «селекции» отбирают только несколько лучших «пробных» решений, на

ГА применяются для решения следующих задач: оптимизация функций; разнообразные задачи
ГА применяются для решения следующих задач: оптимизация функций; разнообразные задачи

Критерии останова ГА
Важный момент функционирования алгоритма ГА – определение критериев
Критерии останова ГА
Важный момент функционирования алгоритма ГА – определение критериев

Лаги в экономических моделях
При анализе многих экономических показателей (особенно в
Лаги в экономических моделях
При анализе многих экономических показателей (особенно в

Причин наличия лагов в экономике достаточно много, и среди них
Причин наличия лагов в экономике достаточно много, и среди них

Модели авторегрессии
(применяют более 100 видов авторегрессий)
Наиболее известны следующие
Модели авторегрессии
(применяют более 100 видов авторегрессий)
Наиболее известны следующие

Частные виды авторегрессий
Модель парной пространственной
линейной регрессии:
Авторегрессионные модели (AР-модели):
первого порядка
порядка P
Пространственная
Частные виды авторегрессий
Модель парной пространственной
линейной регрессии:
Авторегрессионные модели (AР-модели):
первого порядка
порядка P
Пространственная

авторегрессии - проинтегрированного скользящего среднего (ARIMA - autoregressive integrated moving average)

Конструирование моделей авторегрессии
Прямое Z-преобразование (и его свойства):
Дискретные наблюдения действительной
Конструирование моделей авторегрессии
Прямое Z-преобразование (и его свойства):
Дискретные наблюдения действительной

Экспоненциальная функция, обобщенная экспоненциальная функция, экспоненциальные полиномы
Экспонента относится к числу
Экспоненциальная функция, обобщенная экспоненциальная функция, экспоненциальные полиномы
Экспонента относится к числу

Для экспоненты Z – преобразование при дает разностную схему первого
Для экспоненты Z – преобразование при дает разностную схему первого

Рассмотрим теперь гармонику с аддитивной стохастической компонентой
1 этап: модель авторегрессии для
Рассмотрим теперь гармонику с аддитивной стохастической компонентой
1 этап: модель авторегрессии для

Колебания пилообразной формы,
Колебания треугольной формы,
Колебания куполообразной формы.
.
Напомню, что
Колебания пилообразной формы,
Колебания треугольной формы,
Колебания куполообразной формы.
.
Напомню, что

Автокорреляция стохастических компонент в моделях регрессии, методы их компенсации
Из анализа
Автокорреляция стохастических компонент в моделях регрессии, методы их компенсации
Из анализа

Преимущества и недостатки моделей трендов
Преимущества:
- возможность реализации и двух
Преимущества и недостатки моделей трендов
Преимущества:
- возможность реализации и двух

Модели Койка
Модель (с геометрически распределенными лагами)
Модель адаптивных ожиданий по определяющему фактору
Модель
Модели Койка
Модель (с геометрически распределенными лагами)
Модель адаптивных ожиданий по определяющему фактору
Модель
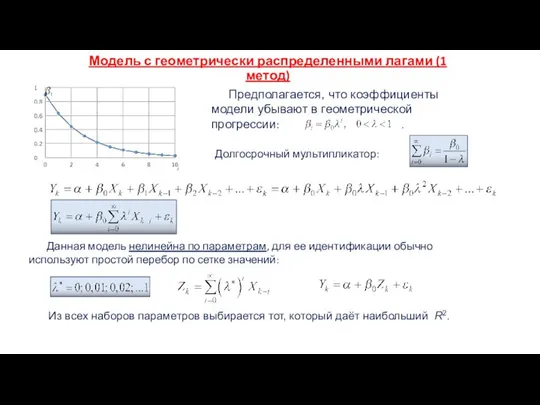
Модель с геометрически распределенными лагами (1 метод)
Предполагается, что коэффициенты модели
Модель с геометрически распределенными лагами (1 метод)
Предполагается, что коэффициенты модели

Модель с геометрически распределенными лагами
(2 метод - преобразование Койка)
Получим авторегрессионную
Модель с геометрически распределенными лагами
(2 метод - преобразование Койка)
Получим авторегрессионную

Пример сравнения методик расчета параметров
Имеются данные о динамики цен на
Пример сравнения методик расчета параметров
Имеются данные о динамики цен на

Модель адаптивных ожиданий и корректировки
Модели используются для эмпирической верификации макроэкономических
Модель адаптивных ожиданий и корректировки
Модели используются для эмпирической верификации макроэкономических

Модель адаптивных ожиданий определяющего фактора
коррекция
прогноза на
шаг вперед
-коэффициент ожидания
ошибка прогноза
Модель адаптивных ожиданий определяющего фактора
коррекция
прогноза на
шаг вперед
-коэффициент ожидания
ошибка прогноза

Преобразование модели адаптивных ожиданий использует подстановку (3) в модель авторегрессии
Преобразование модели адаптивных ожиданий использует подстановку (3) в модель авторегрессии

Обратное преобразование Койка
…
Получим модель с геометрически распределенными лагами для которого
Обратное преобразование Койка
…
Получим модель с геометрически распределенными лагами для которого

Модель частичной корректировки
Авторегрессионная модель Койка, для идентификации которой
можно применить
Модель частичной корректировки
Авторегрессионная модель Койка, для идентификации которой
можно применить

Модель частичной корректировки
Вновь приходим к авторегрессионной модели Койка и известным
Модель частичной корректировки
Вновь приходим к авторегрессионной модели Койка и известным

Примеры применения моделей авторегрессии:
определяемая переменная - реальная заработанная плата,
а
Примеры применения моделей авторегрессии:
определяемая переменная - реальная заработанная плата, а
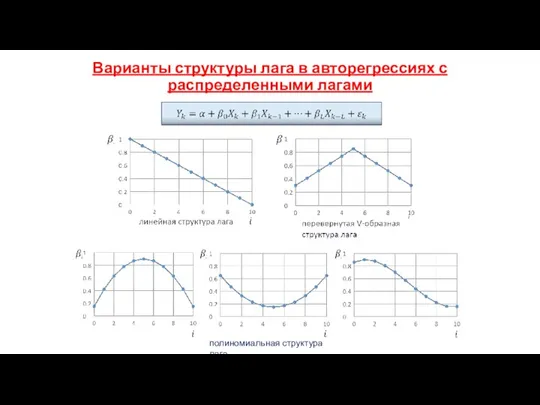
Варианты структуры лага в авторегрессиях с распределенными лагами
полиномиальная структура лага
Варианты структуры лага в авторегрессиях с распределенными лагами
полиномиальная структура лага
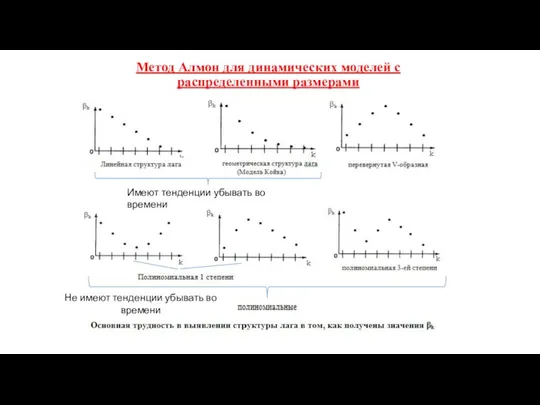
Метод Алмон для динамических моделей с распределенными размерами
Не имеют тенденции убывать
Метод Алмон для динамических моделей с распределенными размерами
Не имеют тенденции убывать

Распределенные лаги Ш. Алмон
Предполагается, что коэффициенты изменяются по полиномиальному закону:
m -
Распределенные лаги Ш. Алмон
Предполагается, что коэффициенты изменяются по полиномиальному закону:
m -

Характеристики метода Алмон для динамических моделей с распределенными размерами
Основные недостатки метода
Характеристики метода Алмон для динамических моделей с распределенными размерами
Основные недостатки метода

Задачи формирования инструментария моделирования и прогнозирования
сравнить современные аналитические и численные методы
Задачи формирования инструментария моделирования и прогнозирования
сравнить современные аналитические и численные методы

Актуальные области моделирования и прогнозирования моделями, рассматриваемыми в рамках курса
динамика
Актуальные области моделирования и прогнозирования моделями, рассматриваемыми в рамках курса
динамика

Компьютерно-интенсивные методы моделирования
(рандомизация, бутстреп и методы Монте-Карло)
Семейство процедур Монте-Карло (метода
Компьютерно-интенсивные методы моделирования
(рандомизация, бутстреп и методы Монте-Карло)
Семейство процедур Монте-Карло (метода

Идея бутстрепа (бутстрапа) по Б. Эфрону (1979г.)
Приближенную оценку статистик стохастической
Идея бутстрепа (бутстрапа) по Б. Эфрону (1979г.)
Приближенную оценку статистик стохастической

На основе только исходной выборки, мы всегда можем получить бутстреп-модели
На основе только исходной выборки, мы всегда можем получить бутстреп-модели

Примеры применения методов моделирования и прогнозирования в экономической практике
Примеры применения методов моделирования и прогнозирования в экономической практике
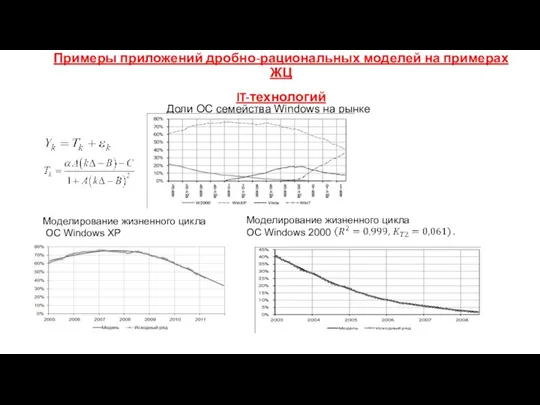
Примеры приложений дробно-рациональных моделей на примерах ЖЦ
IT-технологий
Доли ОС семейства Windows
Примеры приложений дробно-рациональных моделей на примерах ЖЦ
IT-технологий
Доли ОС семейства Windows
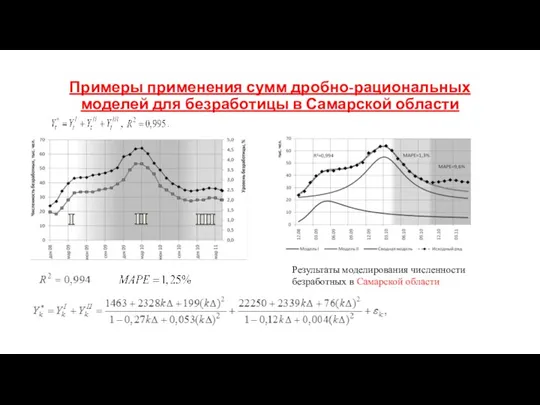
Примеры применения сумм дробно-рациональных моделей для безработицы в Самарской области
Результаты моделирования
Примеры применения сумм дробно-рациональных моделей для безработицы в Самарской области
Результаты моделирования
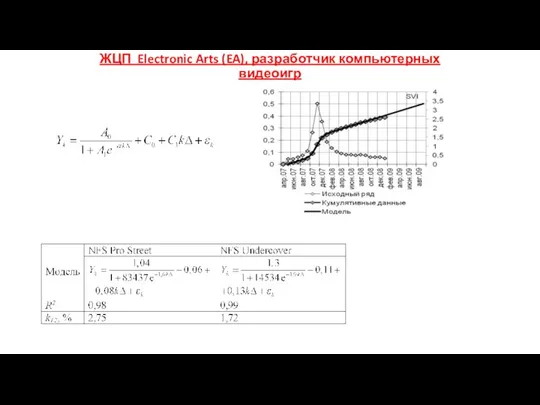
ЖЦП Electronic Arts (EA), разработчик компьютерных видеоигр
ЖЦП Electronic Arts (EA), разработчик компьютерных видеоигр
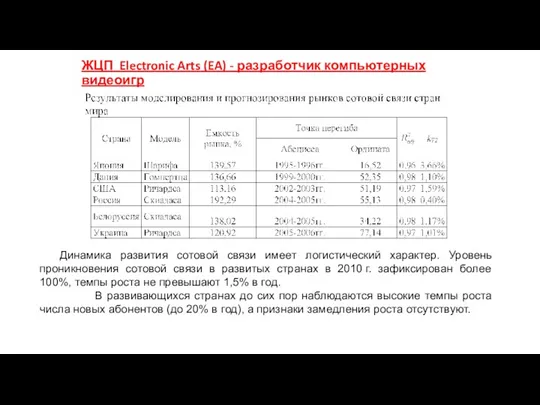
ЖЦП Electronic Arts (EA) - разработчик компьютерных видеоигр
Динамика развития сотовой
ЖЦП Electronic Arts (EA) - разработчик компьютерных видеоигр
Динамика развития сотовой
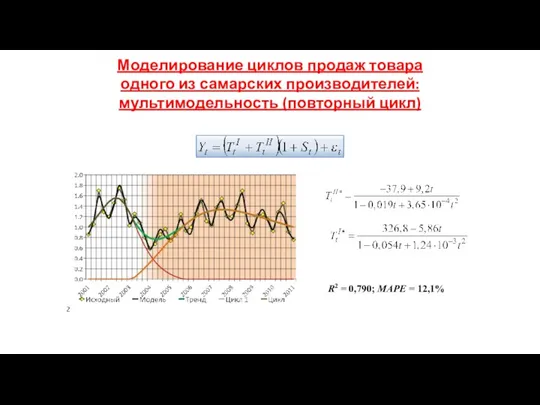
Моделирование циклов продаж товара одного из самарских производителей:
мультимодельность (повторный цикл)
R2 = 0,790; MAPE = 12,1%
Моделирование циклов продаж товара одного из самарских производителей:
мультимодельность (повторный цикл)
R2 = 0,790; MAPE = 12,1%
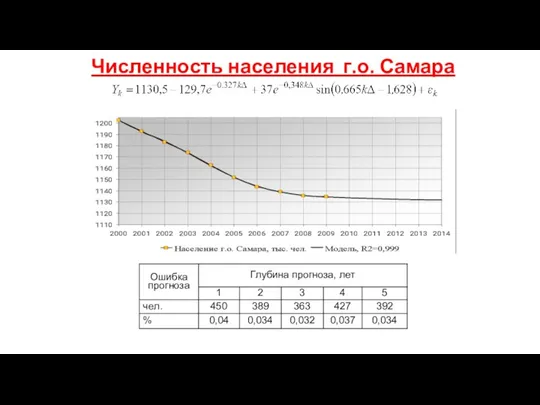
Численность населения г.о. Самара
Численность населения г.о. Самара
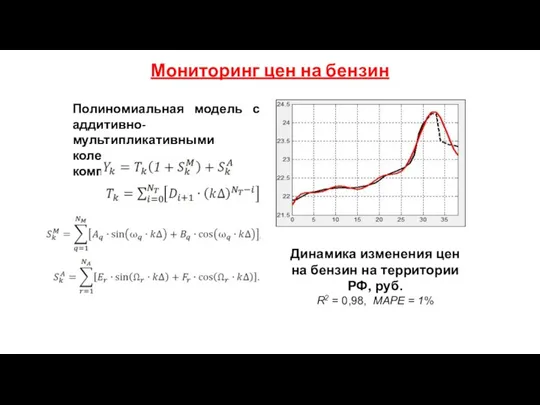
Мониторинг цен на бензин
Полиномиальная модель с аддитивно-мультипликативными колебательными компонентами
Динамика изменения цен
Мониторинг цен на бензин
Полиномиальная модель с аддитивно-мультипликативными колебательными компонентами
Динамика изменения цен
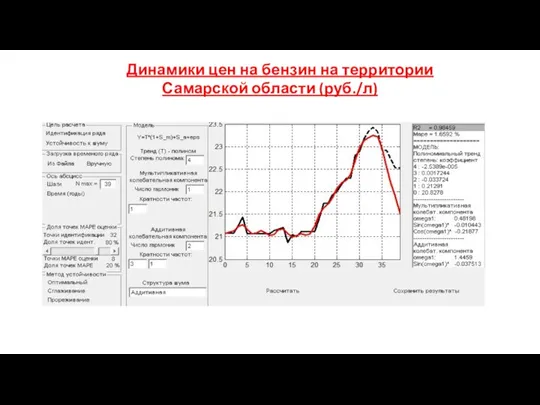
Динамики цен на бензин на территории Самарской области (руб./л)
Динамики цен на бензин на территории Самарской области (руб./л)
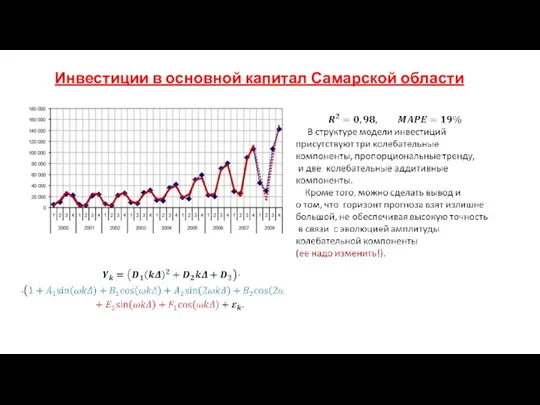
Инвестиции в основной капитал Самарской области
Инвестиции в основной капитал Самарской области

Модели добычи нефти
Новые месторождения
Опора на полевые исследования пласта
Фильтрационные модели
разработки месторождений
Феноменологические модели
Модели добычи нефти
Новые месторождения
Опора на полевые исследования пласта
Фильтрационные модели
разработки месторождений
Феноменологические модели
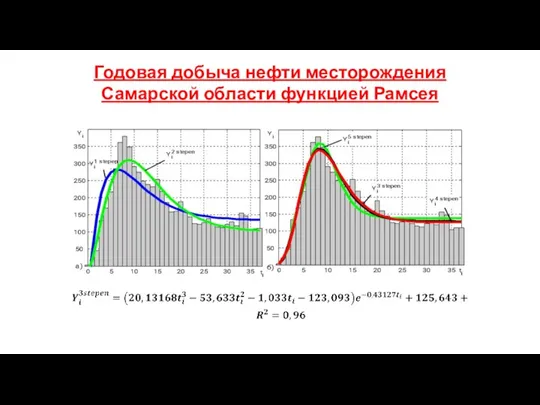
Годовая добыча нефти месторождения Самарской области функцией Рамсея
Годовая добыча нефти месторождения Самарской области функцией Рамсея
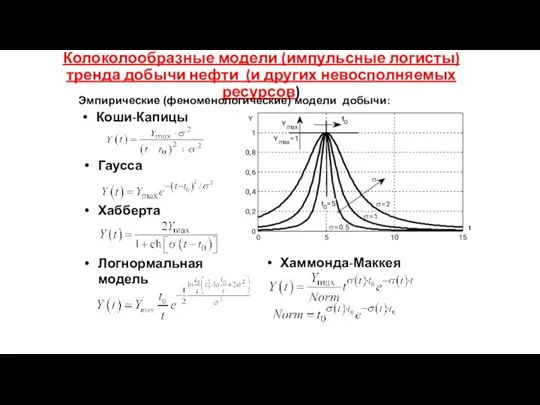
Колоколообразные модели (импульсные логисты)тренда добычи нефти (и других невосполняемых ресурсов)
Хабберта
Эмпирические (феноменологические)
Колоколообразные модели (импульсные логисты)тренда добычи нефти (и других невосполняемых ресурсов)
Хабберта
Эмпирические (феноменологические)
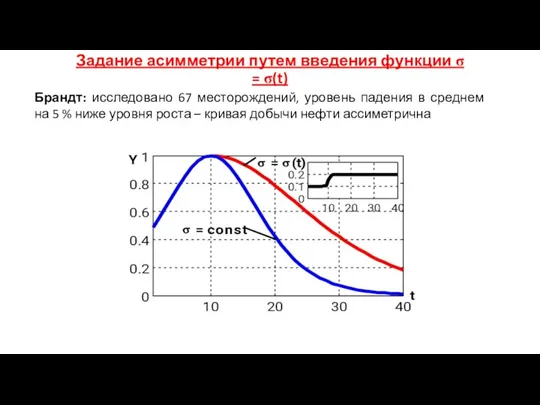
Задание асимметрии путем введения функции σ = σ(t)
Брандт: исследовано 67 месторождений,
Задание асимметрии путем введения функции σ = σ(t)
Брандт: исследовано 67 месторождений,

Ферхюльста
Ричардса
Гомперца
Рамсея
Ферхюльста
Ричардса
Гомперца
Рамсея

Выбор предпочтительной феноменологической модели для анализа добычи нефти и газа на
Выбор предпочтительной феноменологической модели для анализа добычи нефти и газа на
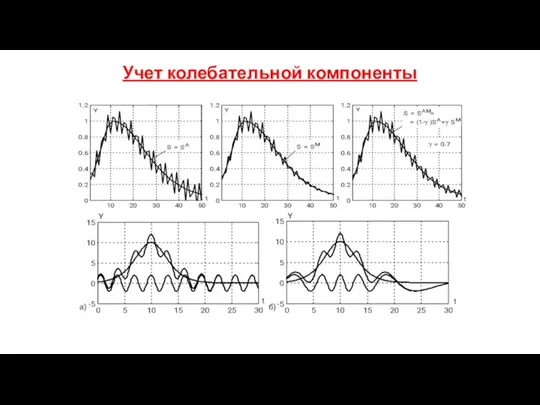
Учет колебательной компоненты
Учет колебательной компоненты

На сегодняшний день в мире насчитывается больше 1000 статистических пакетов.
На сегодняшний день в мире насчитывается больше 1000 статистических пакетов.
 Статистика міжнародного туризму
Статистика міжнародного туризму Информатизация отрасли ЖКХ. (Тема 13)
Информатизация отрасли ЖКХ. (Тема 13) Португалия. Оценка логистического потенциала в условиях глобализирующейся экономики
Португалия. Оценка логистического потенциала в условиях глобализирующейся экономики Научно-техническая революция (НТР)
Научно-техническая революция (НТР) Экономика России
Экономика России Определение оптимального объёма производства в условиях совершенной конкуренции
Определение оптимального объёма производства в условиях совершенной конкуренции Табиғи ресурстарды пайдалану
Табиғи ресурстарды пайдалану Инновационная экономика. Национальная инновационная система. (Лекция 5)
Инновационная экономика. Национальная инновационная система. (Лекция 5) Макроэкономическое равновесие и экономический рост
Макроэкономическое равновесие и экономический рост Социально-экономические последствия инфляции
Социально-экономические последствия инфляции Основы предпринимательства
Основы предпринимательства Экономическая оценка природных ресурсов
Экономическая оценка природных ресурсов География основных типов экономики на территории России
География основных типов экономики на территории России Инфляция, ее сущность и причины
Инфляция, ее сущность и причины Калькуляция продукции в общественном питании. Его особенности
Калькуляция продукции в общественном питании. Его особенности Macroeconomics. Consumption, Savings & Investment
Macroeconomics. Consumption, Savings & Investment Европейский союз как экономическая организация
Европейский союз как экономическая организация Моделирование бизнес-процессов. Имитационное моделирование с помощью MATLAB. Циклы и кризисы. (Занятие 7)
Моделирование бизнес-процессов. Имитационное моделирование с помощью MATLAB. Циклы и кризисы. (Занятие 7) Издержки производства в краткосрочном и долгосрочном периодах. Тема 9
Издержки производства в краткосрочном и долгосрочном периодах. Тема 9 Арктическая экономика: закономерности, специфика, современное развитие
Арктическая экономика: закономерности, специфика, современное развитие Критерии и показатели устойчивого развития
Критерии и показатели устойчивого развития Развитие малого и среднего предпринимательства в Тульской области
Развитие малого и среднего предпринимательства в Тульской области Издержки производства и себестоимость продукции работ и услуг
Издержки производства и себестоимость продукции работ и услуг Всемирные (международные) экономические отношения
Всемирные (международные) экономические отношения Сущность и функции планирования в управлении
Сущность и функции планирования в управлении Стратегический анализ системы управления человеческими ресурсами в ООО Surf Coffee
Стратегический анализ системы управления человеческими ресурсами в ООО Surf Coffee Продовольственная проблема
Продовольственная проблема Причины образования потерь
Причины образования потерь