Выбор алгоритма классификации для дистанционного зондирования Земли. Характеристики данных Landsat 8 презентация
- Выбор алгоритма классификации для дистанционного зондирования Земли. Характеристики данных Landsat 8

Содержание
- 2. Для распределения пикселов снимка по классам можно использовать разные методы, причем выбор того или иного классифицирующего
- 3. Алгоритм классификации на основе определения наименьшего расстояния Этот алгоритм является одним из самых простых и наиболее
- 4. Алгоритм параллелепипеда Этот алгоритм классификации основан на обычной булевой логике и статистических показателях обучающей выборки в
- 5. Множество точек, подчиняющихся этому условию, образует параллелепипед в n-мерном пространстве спектральных признаков. Если значения яркости пиксела
- 6. Алгоритм максимального правдоподобия В рассмотренных методах классификации не учитывались возможные вариации спектральных признаков и проблемы, возникающие
- 7. Если нет дополнительных сведений о пространственных объектах, вероятность р для всех классов будет одинаковой. Если же
- 8. Методы неконтролируемой классификации При использовании методов неконтролируемой классификации от оператора практически не требуется вводить каких-либо входных
- 9. Этап 1. Выделение кластеров Для выполнения этого этапа от оператора могут потребоваться следующие данные: Процесс анализа
- 10. Этап 2. Классификация пикселов снимка После выделения центров кластеров каждый пиксел снимка присваивается одному из выделенных
- 11. Оценка точности классификации Классификацию данных дистанционного зондирования нельзя считать завершенной, пока не получена оценка ее точности.
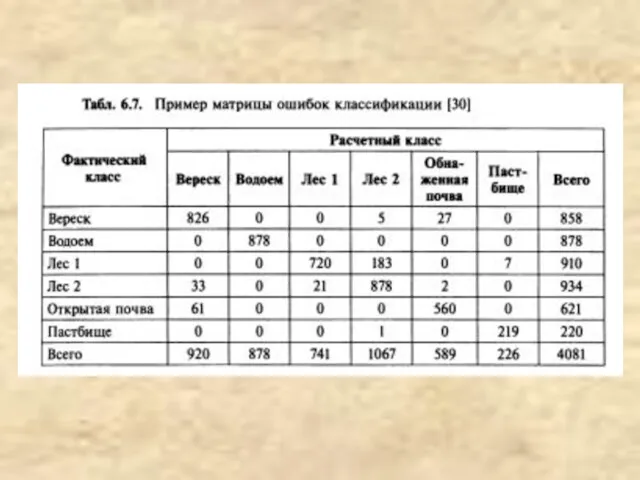
- 12. Матрица ошибок Стандартной формой представления оценки точности классификации для определенного местоположения является матрица ошибок, которая характеризует
- 14. Запущен весной 1984 . Прекратил работу осенью 2011. Характеристики снимков Landsat 5 TM
- 16. Покрытие снимками Landsat 5 TM Белгородской области
- 17. Характеристики данных Landsat 8 Запущен в феврале 2013 . Доступен для скачивания с конца мая 2013
- 18. Дешифрование гарей разного возраста 22 апреля 2011 6 мая 2007 1 – свежие, 2 – среднего
- 19. 4:3:2 5:4:3 7:4:2 3:2:1
- 20. Дешифрование пламени В комбинации каналов Landsat 7:5:3 пламя выглядит как небольшой по площади объект, площадью от
- 21. 16 апреля 1994 года. Видно 26 очагов пламени. Дешифрование пламени 1 – пожар у взлетной полосы
- 22. Дешифрование дыма Дым лучше всего виден в комбинации каналов Landsat 3:2:1 (каналы видимой части спектра). Он
- 23. Травяные палы на западе Белгородской области 22 апреля 2011 года. Травяные палы тяготеют к окраинам крупных
- 24. Палы на территории ООПТ 6 мая 2007 На снимке видна выгоревшая пойма в охранной зоне Леса
- 25. Весенние травяные палы в региональном природном парке «Ровеньский» и его окрестностях в 2011 году Снимок Landsat
- 27. Скачать презентацию

Для распределения пикселов снимка по классам можно использовать разные методы, причем
Для распределения пикселов снимка по классам можно использовать разные методы, причем

Алгоритм классификации на основе определения наименьшего расстояния
Этот алгоритм является одним из
Алгоритм классификации на основе определения наименьшего расстояния
Этот алгоритм является одним из

Алгоритм параллелепипеда
Этот алгоритм классификации основан на обычной булевой логике и статистических
Алгоритм параллелепипеда
Этот алгоритм классификации основан на обычной булевой логике и статистических

Множество точек, подчиняющихся этому условию, образует параллелепипед в n-мерном пространстве спектральных
Множество точек, подчиняющихся этому условию, образует параллелепипед в n-мерном пространстве спектральных

Алгоритм максимального правдоподобия
В рассмотренных методах классификации не учитывались возможные вариации спектральных
Алгоритм максимального правдоподобия
В рассмотренных методах классификации не учитывались возможные вариации спектральных

Если нет дополнительных сведений о пространственных объектах, вероятность р для всех
Если нет дополнительных сведений о пространственных объектах, вероятность р для всех

Методы неконтролируемой классификации
При использовании методов неконтролируемой классификации от оператора практически не
Методы неконтролируемой классификации
При использовании методов неконтролируемой классификации от оператора практически не

Этап 1. Выделение кластеров
Для выполнения этого этапа от оператора могут потребоваться
Этап 1. Выделение кластеров
Для выполнения этого этапа от оператора могут потребоваться

Этап 2. Классификация пикселов снимка
После выделения центров кластеров каждый пиксел снимка
Этап 2. Классификация пикселов снимка
После выделения центров кластеров каждый пиксел снимка

Оценка точности классификации
Классификацию данных дистанционного зондирования нельзя считать завершенной, пока не
Оценка точности классификации
Классификацию данных дистанционного зондирования нельзя считать завершенной, пока не

Матрица ошибок
Стандартной формой представления оценки точности классификации для определенного местоположения является
Матрица ошибок
Стандартной формой представления оценки точности классификации для определенного местоположения является


Запущен весной 1984 .
Прекратил работу осенью 2011.
Характеристики снимков Landsat 5 TM
Запущен весной 1984 .
Прекратил работу осенью 2011.
Характеристики снимков Landsat 5 TM
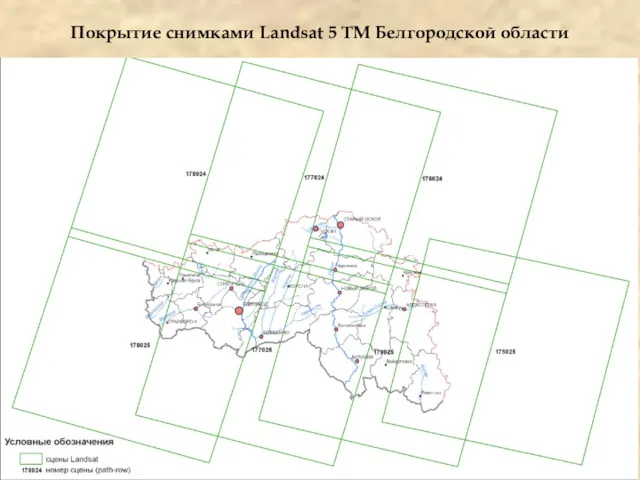
Покрытие снимками Landsat 5 TM Белгородской области
Покрытие снимками Landsat 5 TM Белгородской области

Характеристики данных Landsat 8
Запущен в феврале 2013 .
Доступен для скачивания с
Характеристики данных Landsat 8
Запущен в феврале 2013 .
Доступен для скачивания с

Дешифрование гарей разного возраста
22 апреля 2011
6 мая 2007
1 – свежие, 2
Дешифрование гарей разного возраста
22 апреля 2011
6 мая 2007
1 – свежие, 2
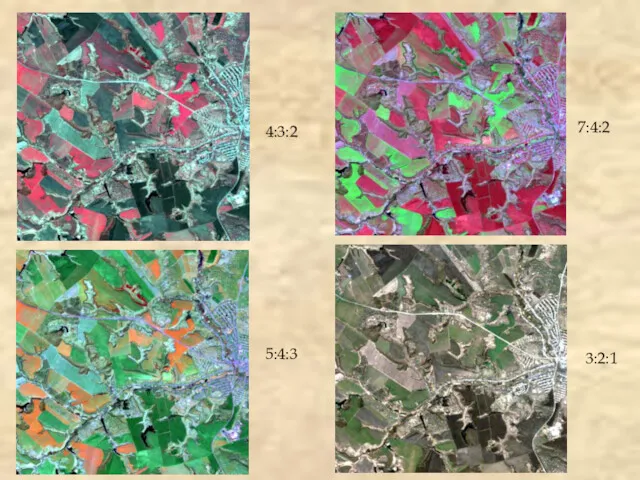
4:3:2
5:4:3
7:4:2
3:2:1
4:3:2
5:4:3
7:4:2
3:2:1

Дешифрование пламени
В комбинации каналов Landsat 7:5:3 пламя выглядит как небольшой по
Дешифрование пламени
В комбинации каналов Landsat 7:5:3 пламя выглядит как небольшой по

16 апреля 1994 года. Видно 26 очагов пламени.
Дешифрование пламени
1 – пожар
16 апреля 1994 года. Видно 26 очагов пламени.
Дешифрование пламени
1 – пожар
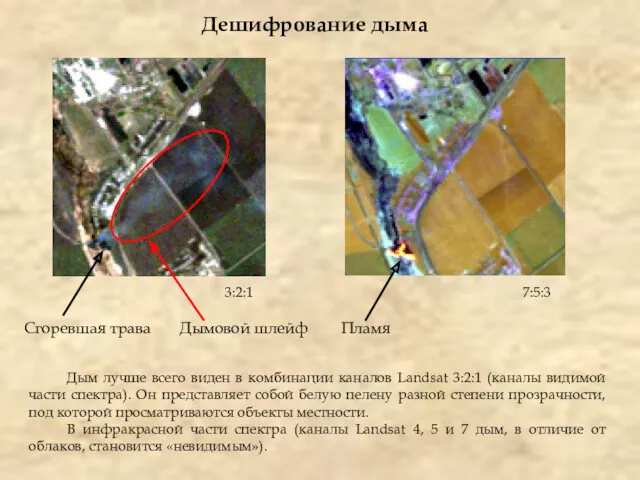
Дешифрование дыма
Дым лучше всего виден в комбинации каналов Landsat 3:2:1 (каналы
Дешифрование дыма
Дым лучше всего виден в комбинации каналов Landsat 3:2:1 (каналы
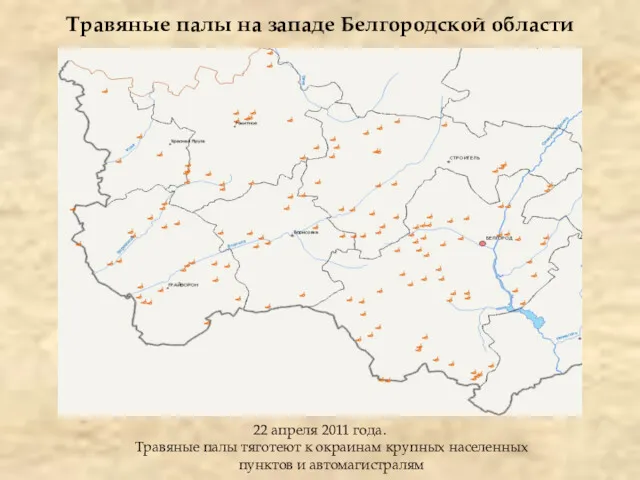
Травяные палы на западе Белгородской области
22 апреля 2011 года.
Травяные палы тяготеют
Травяные палы на западе Белгородской области
22 апреля 2011 года.
Травяные палы тяготеют
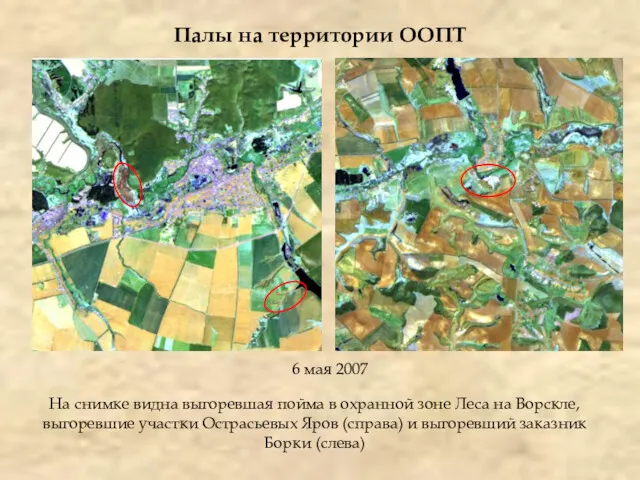
Палы на территории ООПТ
6 мая 2007
На снимке видна выгоревшая пойма в
Палы на территории ООПТ
6 мая 2007
На снимке видна выгоревшая пойма в
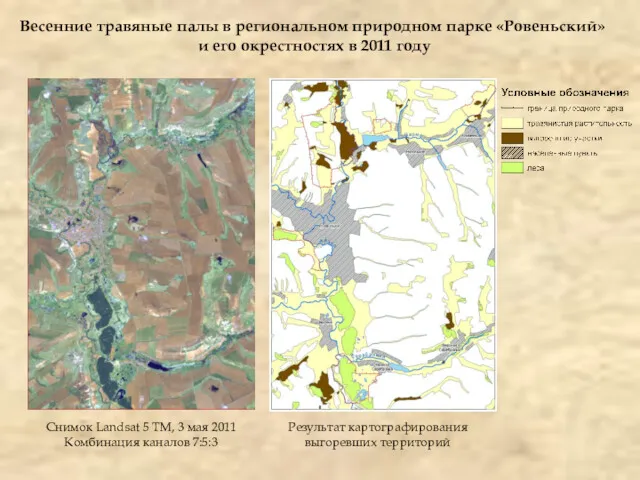
Весенние травяные палы в региональном природном парке «Ровеньский»
и его окрестностях
Весенние травяные палы в региональном природном парке «Ровеньский»
и его окрестностях
 система СИ
система СИ Пневматична система
Пневматична система Напряженность электрического поля. Урок физики в 10 классе
Напряженность электрического поля. Урок физики в 10 классе Механизм газораспределения автомобиля ВАЗ 2107
Механизм газораспределения автомобиля ВАЗ 2107 Тиристор деп төрт деңгейлі жартылай өткізгіш құрылғылардын
Тиристор деп төрт деңгейлі жартылай өткізгіш құрылғылардын Электроемкость. Конденсаторы
Электроемкость. Конденсаторы Удельная теплоёмкость
Удельная теплоёмкость презентация по теме Сила трения 7 класс
презентация по теме Сила трения 7 класс Лампа накаливания
Лампа накаливания Передача давления жидкостями и газами. Закон Паскаля
Передача давления жидкостями и газами. Закон Паскаля Скорость света
Скорость света Решение задач на применение законов Ньютона
Решение задач на применение законов Ньютона Сила тока. Закон Ома для участка цепи. Сопротивление. 10 класс
Сила тока. Закон Ома для участка цепи. Сопротивление. 10 класс Радиометрия и спектрометрия ионизирующих излучений. (Лекция 9)
Радиометрия и спектрометрия ионизирующих излучений. (Лекция 9) Инструкции по технике безопасности в кабинете физики.
Инструкции по технике безопасности в кабинете физики. От порядка к хаосу. Сценарии перехода к хаосу
От порядка к хаосу. Сценарии перехода к хаосу урок в 7 классе Давление твёрдых тел
урок в 7 классе Давление твёрдых тел Тепломассообмен. Поперечное обтекание одиночных труб и трубных пучков
Тепломассообмен. Поперечное обтекание одиночных труб и трубных пучков Основы атомной физики. Основы квантовой механики. Строение вещества
Основы атомной физики. Основы квантовой механики. Строение вещества Адаптация обучающихся в учебном пространстве предмета - физика
Адаптация обучающихся в учебном пространстве предмета - физика Своя игра. Физика. 7 класс.
Своя игра. Физика. 7 класс. Кристаллооптический анализ
Кристаллооптический анализ Биомеханика двигательных действий: составные движения в биокинематических цепях
Биомеханика двигательных действий: составные движения в биокинематических цепях Електростатичне поле
Електростатичне поле Электростатическое поле в вакууме. Принцип суперпозиции. Проводники в электростатическом поле
Электростатическое поле в вакууме. Принцип суперпозиции. Проводники в электростатическом поле Литий-ионные (Li-ion) аккумуляторы
Литий-ионные (Li-ion) аккумуляторы Заттың магниттік қасиеттері. Ақпараттың магниттік жазылуы
Заттың магниттік қасиеттері. Ақпараттың магниттік жазылуы Теплотехника. Основы теории тепло- и массообмена. (Лекция 11)
Теплотехника. Основы теории тепло- и массообмена. (Лекция 11)