- ذخیره و بازیابی اطلاعات(3)

Содержание
- 2. جلسه اول: آشنايي با طراحي و مشخصات ساختار فايلها، عمليات مهم پردازش فايل، حافظه جانبي و
- 3. جلسه هفتم: ادامه مبحث سازماندهي فايلها براي کارايي، شاخص گذاري جلسه هشتم: ادامه مبحث شاخص گذاري
- 4. جلسه سيزدهم: دستيابي به فايل هاي ترتيبي شاخص دار و درخت هاي B+ جلسه چهاردهم: ادامه
- 5. جلسه اول آشنايي با طراحي و مشخصات ساختار فايلها عمليات مهم پردازش فايل حافظه جانبي و
- 6. آشنايي با طراحي و مشخصات ساختار فايلها
- 7. ساختار فايل ترکيبي از نحوه نمايش داده ها در فايل ها و عمليات لازم براي دستيابي
- 8. طي سه دهه اخير با بررسي تکامل ساختارهاي فايل مشاهده مي کنيم که طراحي ساختار فايل
- 9. يک مشکل اصلي در توصيف کلاس هايي که بتوان براي طراحي ساختار فايل آنها را به
- 10. در يک سيستم اطلاعاتي شيء گرا محتوا و رفتار داده ها ، در يک طراحي منسجم
- 11. مشکل اصلي در طراحي ساختار فايل زمان نسبتاً زيادي است که براي گرفتن تطلاعات از ديسک
- 12. عمليات مهم پردازش فايل
- 13. هنگامي که درباره فايلي روي يک ديسک يا نوار صحبت مي کنيم ،منظور ما مجموعه اي
- 14. برنامه غالباً نمي داند بايت ها از کجا مي آيند يا به کجا مي روند ،
- 15. هنگامي که شناسه (identifier) فايل منطقي با دستگاه يا فايل فيزيکي ارتباط پيدا کرد ،بايد اعلام
- 16. هنگامي که برنامه اي به صورت عادي پايان مي يابد فايل ها معمولاً به طور خودکار
- 17. خواندن و نوشتن در پردازش فايل اهميت بنيادي دارند ،اينها اعمالي هستند که پردازش فايل را
- 18. براي دستيابي آسان به تعداد زياد از فايل ها کامپيوتر روشي براي سازماندهي فايل ها دارد.
- 19. يکي از پر قدرت ترين ايده ها در يونيکس تعريفي است که از فايل مي شود.
- 20. يونيکس فرمان هاي بسياري براي دستکاري فايل ها دارد که عبارتند از : cat, tail, cp,
- 21. حافظه جانبي و نرم افزار سيستم
- 22. دستگاه هاي حافظه جانبي ،با حافظه تفاوت بسيار دارند. همان طور که پيش از اين نيز
- 23. ديسک ها انواع مختلفي دارند : ۱) ديسک هاي سخت (hard disks) ۲) ديسک هاي فلاپي
- 24. جلسه دوم ادامه مبحث حافظه جانبي و نرم افزار سيستم
- 25. اطلاعات ذخيره شده روي ديسک ،در سطح يک يا چند صفحه نگهداري مي شود. ترتيب کار
- 27. ديسک گردان ها معمولاً چند صفحه دارند. شيارهايي که مستقيماً در بالا و پايين يکديگر قرار
- 29. ظرفيت ديسک تابعي از تعداد سيلندرها ،تعدا شيارها به ازاي هر سيلندر و ظرفيت هر شيار
- 30. دو روش براي سازماندهي داده ها بر روي ديسک وجود دارد : ۱) بر اساس سکتور
- 31. کلاستر عبارت از تعداد ثابتي از سکتورهاي پيوسته است. مديريت فايل براي در نظر گرفتن فايل
- 32. اگر فضاي زيادي روي ديسک باشد ، ممکن است بتوان کاري کرد که فايل به طور
- 34. اتلاف فضا در داخل يک سکتور را پراکندگي داخلي مي نامند. سازماندهي بلوک ها مشکلات پوشايي
- 35. بلوک معمولاً طوري سازماندهي مي شود که تعداد مناسبي از رکوردهاي منطقي را نگهداري کند. براي
- 36. در الگوهاي آدرس دهي بلاکي هر بلوک از داده ها معمولاً با يک يا چند زير
- 37. هم بلاک ها و هم سکتورها نيازمند آنند که مقدار معيني از فضاي ديسک را به
- 38. فرمت کردن موجب مي شود تا شکاف (gap) و علامت هاي هم زمان سازي ،بين فيلدهاي
- 39. دستيابي به ديسک را مي توان به سه عمل فيزيکي متمايز تقسيم کرد که هر يک
- 40. جلسه سوم ادامه مبحث حافظه جانبي و نرم افزار سيستم
- 41. زمان پيگرد عبارت است از زمان لازم انتقال بازوي دستيابي ،به سيلندر مناسب.
- 42. تأخير در چرخش عبارت است از زمان لازم براي چرخش ديسک ،تا سکتور مورد نظر زير
- 43. علي رغم افزايش کارايي ديسک ها ،سرعت شبکه ها به حدي بالا رفته است که دستيابي
- 44. نوارهاي مغناطيسي به دستگاه هايي تعلق دارند که دستيابي مستقيم به داده ها را فراهم نمي
- 45. نقاط قوت CD-ROM شامل ظرفيت ذخيره سازي بالا،بهاي کم و دوام آن است. نقطه ضعف اصلي
- 46. در قالب سرعت خطي ثابت (CLV) ،سرعت چرخش ديسک هنگام خواندن لبه هاي بيروني ،کندتر از
- 48. بافر I/O سيستم ،به مديريت فايل اين امکان را مي دهد تا داده ها را در
- 49. عمل کنترل عمليات ديسک توسط دستگاهي انجام مي شود که کنترلگر ديسک ناميده مي شود.
- 50. سيستم هاي I/O تقريباً هميشه حداقل دو بافر دارند. يکي براي ورودي و ديگري براي خروجي.
- 51. با پراکنش ورودي ،با يک بار خواندن ،نه يک بار بافر بلکه مجموعه اي از بافرهايي
- 52. هسته به نوبت به اين چهار جدول زير مراجعه مي کند تا اطلاعاتي را که براي
- 54. اشاره گري از يک فهرست به اينود فايل را اتصال سخت (hard link) مي نامند و
- 55. سه نوع سيستم I/O متفاوت داريم : ۱) سيستم I/O بلوکي ۲) سيستم I/O کاراکتري ۳)
- 56. براي هر دستگاه جانبي مجموعه اي از روال هاي جداگانه وجود دارد که راه انداز دستگاه
- 57. جلسه چهارم مفاهيم اساسي ساختار فايل مديريت فايلهايي از رکوردها
- 58. مفاهيم اساسي ساختار فايل
- 59. واحد اصلي داده ها،فيلد است که حاوي يک مقدار داده است. فيلدها به صورت مجموعه اي
- 60. هنگامي که رکوردي در حافظه نگهداري شد آن را يک شيء و فيلدهاي آن را اعضاي
- 61. راههاي فراواني براي افزودن ساختار به فايل وجود دارد تا هويت فيلد حفظ شود. چهار روش
- 62. رکورد مجموعه اي از فيلد ها است و مجموعه اي از رکوردها فايل را نشان مي
- 63. بعضي از روش هاي سازماندهي رکوردهاي فايل عبارتند از : ۱) قابل پيش بيني کردن طول
- 64. دو روش براي نمايش طول رکورد وجود دارد : ۱) طول رکورد به صورت يک عدد
- 65. با روبرداري فايل مي توان بايت هاي واقعي نگهداري شده در آن را مشاهده کرد.
- 66. C++ وراثت را در اختيار قرار مي دهد تا چندين کلاس مي توانند از اعضا و
- 68. مديريت فايلهايي از رکوردها
- 69. هنگامي که کارايي جستجوهاي انجام شده در حافظه الکترونيکي را توصيف مي کنيم معمولاً از تعداد
- 70. به طورکلي ،کار مورد نياز براي جستجوي ترتيبي ، در فايلي با n رکورد با n
- 71. در تحليل و بحث درباره بلوک بندي رکورد چند چيز را بايد مورد توجه قرار داد
- 72. جستجوي ترتيبي براي اکثر شرايط بازيابي زمان بسيار مي برد. اين که آيا جستجوي ترتيبي توصيه
- 73. متداول ترين ساختار فايل که در يونيکس وجود دارد ، يک فايل اسکي با کاراکتر خط
- 74. روش ديگري که با جستجوي ترتيبي تفاوت بنيادي دارد ، دستيابي مستقيم است. هنگامي که بتوانيم
- 75. جلسه پنجم ادامه مبحث مديريت فايلهايي از رکوردها
- 76. غالباً لازم است از برخي اطلاعات عمومي مربوط به فايل آگاه باشيم تا در آينده به
- 77. هر فايل داراي يک رکورد سرآيند (header) است که حاوي سه مقدار در پايين است :
- 78. دو ساختار مختلف از رکوردها که حاوي فيلدهاي طول متغير در يک رکورد با طول ثابت
- 79. يک طراحي شيءگراي خوب ،براي ماندگار شدن اشياء بايد عملياتي براي خواندن و نوشتن مستقيم اشياء
- 80. تا کنون عمل نوشتن نيازمند به دو عمل جداگانه بود : ۱) فشرده سازي در يک
- 81. در اين بخش ،کلاس recordfile را معرفي مي کنيم که نوعي عمل خواندن را پشتيباني مي
- 82. در بحث هايي که طي اين فصل و فصل قبل داشتيم به موارد زير پرداختيم :
- 83. داده هايي مثل صوت ،تصاوير ،و اسناد به صورت فيلدها و رکوردها ذخيره نمي شوند.
- 84. اگر در زبان برنامه نويسي امکان داشته باشد، مي توانيم اطلاعات کاربردي بيشتري درباره ساختار فايل
- 85. شبه داده ها را مي توان با هر فايلي همراه ساخت ،که داده هاي اصلي آن
- 86. تصوير راستر رنگي ،آرايه اي راست گوشه از نقاط رنگي يا پيکسل ها است ،که روي
- 87. انواع متفاوت فراواني از شبه داده ها وجود دارند که مي توانند با يک تصوير همراه
- 88. متدهايي براي کار با تصاوير به عنوان اشياي خاصي وجود دارد : ۱) نمايش يک تصوير
- 89. ايده دنبال کردن فايل ها براي قرار دادن دامنه وسيعي از اشياي گوناگون ،اجتناب ناپذير است
- 90. براي توصيف ديدي که يک برنامه کاربردي از اشياي داده اي دارد ،از اصطلاح مدل داد
- 91. جلسه ششم ادامه مبحث مديريت فايلهايي از رکوردها سازماندهي فايلها براي کارايي
- 92. يکي از مزاياي استفاده از برچسب ها براي شناسايي اشياي موجود در فايل ها آن است
- 93. اختلاف ميان زبان ها ،سيستم هاي عامل ،و معماري ماشين ،سه مشکل اصلي هستند که هنگام
- 94. چند راه حل براي دستيابي به قابليت حمل : ۱) توافق بر سر يک فرمت فيزيکي
- 95. سازماندهي فايلها براي کارايي
- 96. فشرده سازي يک فرايند دسته اي (batch) است که براي حذف حفره هاي خالي فايلي به
- 97. دلايل زيادي براي کوچک کردن فايلها وجود دارد : ۱) فايل هاي کوچکتر نياز به حافظه
- 98. فشرده سازي داده ها عبارت است از رمزگذاري اطلاعات در فايل ،به صورتي که جاي کمتري
- 99. تکنيک فشرده سازي که در آن تعداد بيت ها با استفاده از يک نمادگذاري فشرده تر
- 100. آرايه هاي اسپارس براي نوعي فشرده سازي به نام رمزگذاري طول رانش مناسب اند. ابتدا مقدار
- 101. الگوريتم آ رايه هاي اسپارس را به صورت زير اجرا مي کنيم : ۱) پيکسل هاي
- 102. نوع ديگري از فشرده سازي کدهاي با طول متغير را بسته به تعداد دفعات ظاهر شدن
- 103. راهي ديگر براي صرفه جويي فضا در يک فايل، بازيابي فضا در آن فايل پس از
- 104. تغييرات فايل به سه شکل انجام مي شود : ۱) اضافه کردن رکورد ۲) بهنگام سازي
- 105. متراکم کردن فايل از طريق پيدا کردن مکان هايي در فايل که حاوي هيچ داده اي
- 106. متراکم کردن فايل آسان ترين و رايج ترين روش هاي بازيابي فضا است.
- 107. به طور کلي براي فراهم کردن مکانيسمي براي حذف رکوردها و به دنبال آن استفاده دوباره
- 108. جلسه هفتم ادامه مبحث سازماندهي فايلها براي کارايي شاخص گذاري
- 109. براي بازيابي سريعتر فضا به وارد زير نيازمنديم : ۱) راهي که بلافاصله بدانيم که حفره
- 110. استفاده از ليست هاي پيوندي براي پيوند دادن تمام رکوردها هر دو نياز فوق را برآورده
- 111. آسان ترين راه براي کار کردن با ليست استفاده از آن به صورت پشته است. پشته
- 112. براي بازيابي رکوردها از طريق ليست پيوندي به موارد زير نياز داريم : ۱) راهي براي
- 113. براي مقابله با پراکندگي خارجي يک روش متراکم کردن فايل است و دو راه ديگر به
- 114. هنگامي که نياز داريم يک حفره رکورد را از ليست خارج کنيم با شروع از ابتداي
- 115. سه مشکل اساسي مربوط به مرتب سازي و جستجوي دودويي عبارتند از : ۱) جستجوي دودويي
- 116. مرتب سازي کليدي که گاهي به آن مرتب سازي با برچسب مي گويند بر اين ايده
- 117. عيب مرتب سازي کليدي اين است که مرتب کردن فايلي با n رکورد نياز به n
- 118. شاخص گذاري
- 119. همه شاخص ها بر اساس يک مفهوم اصلي واحد عمل مي کنند: کليدها و آدرس فيلدها.
- 120. انواع شاخص هايي که در اين فصل بررسي مي کنيم شاخص ساده ناميده مي شوند زيرا
- 121. چون شاخص ها به طور غير مستقيم عمل مي کنند ، بدون دستکاري محتويات فايل ،به
- 122. کاتالوگ کارتي در واقع مجموعه اي از سه شاخص است که هر کدام از يک فيلد
- 123. بنابراين کاربرد ديگر شاخص بندي اين است که مي توان از طريق مسيرهاي گوناگوني به فايل
- 124. در جستجوي دودويي لازم است امکان پرش به وسط فايل را داشته باشيم.
- 125. جلسه هشتم ادامه مبحث شاخص گذاري
- 126. راه ديگر براي مرتب سازي ، ايجاد شاخص براي فايل است.
- 127. ساختار شيء شاخص بسيار ساده است. اين ساختار ليستي است که هر عنصر آن دو فيلد
- 128. عملياتي که براي يافتن داده هاي مورد نظر ،از طريق شاخص لازمند عبارتند از : ۱)
- 129. مزيت بزرگي که روش شيء گرا دارد آن است که براي اجراي اين عمليات به هرچه
- 130. در ايجاد فايل ها بايد دو فايل ايجاد شوند : ۱) فايل داده ها براي نگهداري
- 131. بهنگام سازي رکوردها به دو صورت انجام مي شود : ۱) بهنگام سازي ،تعداد فيلد و
- 132. آشکارترين بهينه سازي ،استفاده از جستجوي دودويي در متد find است که توسط : insert ,
- 133. منبع ديگر بهينه سازي ،چنانچه رکورد شاخص تغيير نکرده باشد ، نوشتن درباره رکورد شاخص در
- 134. دستيابي به شاخص روي ديسک داراي معايب زير است : ۱) جستجوي دودويي شاخص به جاي
- 135. هرگاه يک شاخص ساده در حافظه جا نشود بايد از موارد زير استفاده کرد : ۱)
- 136. شاخص هاي ساده نسبت به استفاده از فايل داده اي که بر حسب کليد مرتب شده
- 137. هنگاميکه شاخص ثانويه اي موجود باشد ،افزودن يک رکورد به فايل به معناي افزودن يک ورودي
- 138. يک اختلاف مهم شاخص ثانويه و شاخص اوليه آن است که شاخص ثانويه مي تواند حاوي
- 139. حذف يک رکورد معمولاً به معناي حذف تمامي آدرس هاي آن رکورد در سيستم فايل است.
- 140. مشکل اين است که شاخص هاي ثانويه همانند شاخص اوليه به ترتيب کليدها نگهداري مي شوند.
- 141. جلسه نهم ادامه مبحث شاخص گذاري پردازش کمک ترتيبي و مرتب سازي فايل هاي بزرگ
- 142. بهنگام سا زي فايل داده ها فقط هنگامي شاخص ثانويه را تحت تأثير قرار مي دهد
- 143. ساختارهاي شاخص ثانويه اي که تا کنون ارائه کرديم دو مشکل دارند : ۱) هربارکه رکورد
- 144. درسيستم فايلي که طي اين فصل طراحي کرديم ، انقياد کليدهاي اوليه به آدرس در زمان
- 145. پردازش کمک ترتيبي و مرتب سازي فايل هاي بزرگ
- 146. عمليات کمک ترتيبي شامل پردازش هماهنگ دو يا چند ليست ترتيبي براي ايجاد يک ليست خروجي
- 147. گرچه روال همخواني بسيار ساده به نظر مي رسد ،براي آن که اين روال بهتر عمل
- 148. اگر قرار باشد تعداد زيادي از ليست ها با هم ادغام شوند ،مي توان به جاي
- 149. مرتب سازي در حافظه شامل سه مرحله است : ۱) خواندن کل فايل از روي ديسک
- 150. آيا يک الگوريتم مرتب سازي داخلي وجود دارد که به قدر کافي سريع باشد و بتواند
- 151. هرم درختي دودويي با ويژگي هاي زير است : ۱) هر گره داراي کليدي است که
- 153. الگوريتم مرتب سازي هرمي دو بخش دارد: ابتدا هرم را ايجاد مي کنيم سپس کليدها را
- 154. بازيابي ترتيبي کليدها به صورت زير انجام مي شود : ۱) تعيين مقدار کليد موجود در
- 155. مرتب سازي کليدي دو نارسايي دارد : ۱) هنگاميکه کليدها مرتب سازيمي شوند ،بايد زمان زيادي
- 156. رانش داراي ويژگي هاي زير است : ۱) واقعاً قادر به مرتب سازي فايل هاي بزرگ
- 157. I/O چهار بار اجرا مي گردد. در مرحله مرتب سازي : ۱) خواندن همه رکوردها به
- 158. جلسه دهم ادامه مبحث پردازش کمک ترتيبي و مرتب سازي فايل هاي بزرگ
- 159. يک اختلاف عمده ميان مرحله مرتب سازي و مرحله ادغام ،در تعداد دستيابي ترتيبي (در مقابل
- 160. به طور خلاصه چون مرحله ادغام تنها مرحله اي است که در آن مي توان بازدهي
- 161. با بزرگ شدن فايل ها زمان لازم براي مرتب سازي ادغامي به سرعت افزايش مي يابد.
- 162. در اين بخش سه تغيير ممکن در پيکربندي سيستم را در نظر مي گيريم که مي
- 164. هدف اصلي اين مرتب سازي ادغامي آن است که قادر باشيم فايلهايي را مرتب سازي کنيم
- 165. در ادغام چند مرحله اي، سعي نمي کنيم همه رانش ها را به يکباره ادغام کنيم.
- 166. اساس انتخاب جايگزيني ،اين ايده است : انتخاب هميشگي کليدي از حافظه که داراي کمترين مقدار
- 167. الگوريتم انتخاب جايگزيني را مي توان به طريق زير پياده سازي نمود : ۱) خواندن مجموعه
- 168. ۳) آوردن يک رکورد جديد و مقايسه مقدار کليد آن با مقدار کليدي که به تازگي
- 169. گزينش جايگزيني ابزاري سودمند براي فايل هاي ورودي است که قدري مرتب هستند و اين گزينش
- 170. در گزينش جايگزيني اگر دو ديسک در اختيار داشته باشيم ،بايد حافظه را نيز طوري پيکربندي
- 171. اختصاص دادن بيش از يک پردازنده به يک کار امري است متداول که به حالات زير
- 172. اگر در سيستمي برنامه نويسي چندگانه امکان پذير باشد زمان کل براي I/O ممکن است طولاني
- 173. يکي از دلايل برنامه ريزي چندگانه آن است که به سيستم عامل امکان دهيم تا راههايي
- 174. جلسه يازدهم ادامه مبحث پردازش کمک ترتيبي و مرتب سازي فايل هاي بزرگ شاخص بندي چند
- 175. ليست کاملي از مجموعه جديد ابزاهايي که کارايي مرتب سازي خارجي را بهبود مي بخشند شامل
- 176. درادغام موازنه شده دوجانبه ،توزيع اوليه بايد روي دو نوارگردان صورت پذيرد و در هر مرحله
- 177. ايده هاي استفاده از الگوريتم هاي ادغام مرتبه بالاتر و ادغام رانش ها از روي يک
- 178. چون ديسک ها دستگاههاي دستيابي مستقيم هستند ادغام هاي با مرتبه بسيار بزرگ را مي توان
- 179. شاخص بندي چند سطحي و درختهاي B
- 180. مشکل اصلي نگهداشتن شاخص در حافظه جانبي اين است که دستيابي به حافظه جانبي کند است.
- 181. درخت جستجوي دودويي چه اشکالي دارد؟ ۱) براي شاخص بندي روي ديسک سرعت لازم را ندارد.
- 182. تلاشهايي براي حل مشکلات درخت جستجوي دودويي انجام گرفت که دو تا از آنها عبارتند از
- 183. درخت AVL درختي با ارتفاع موازنه شده است. يعني اينکه ،اختلاف مجاز ميان هر دو زيردرخت
- 185. دو مزيت که درخت هاي AVL را با اهميت مي کنند عبارتند از : ۱) با
- 186. درخت دودويي صفحه اي ،سعي مي کند با قرار دادن چندين گره دودويي در يک صفحه
- 188. واضح است که تقسيم کردن درخت به چندين صفحه امکان جستجوي سريعتر در حافظه جانبي را
- 189. مشکل اصلي درخت هاي صفحه اي هنوز هم استفاده از ديسک است.
- 190. درخت هاي B شاخص هاي چند سطحي هستندکه مشکل هزينه خطي درج و حذف کردن را
- 191. جلسه دوازدهم ادامه مبحث شاخص بندي چند سطحي و درختهاي B
- 192. جستجو در درخت B : ۱) به صورت تکراري عمل مي کنند. ۲) در دو مرحله
- 193. در مورد فرايند درج کردن ،تقسيم کردن و ارتقاء ملاحظات زير را در نظر مي گيريم
- 194. از مرتبه درخت B به عنوان حداقل تعداد کليدهايي که مي تواند در يک صفحه درخت
- 195. پايين ترين سطح کليدها در درخت B را برگ مي نامند.
- 196. با استفاده از تعاريف ارائه شده از مرتبه و برگ ،مي توانيم خواص يک درخت B
- 197. تضمين اين که درخت پهن و کم عمق باشد ،نه باريک و عميق ،مربوط به اين
- 198. قوانين حذف کليد k از گره n در يک درخت B به اين ترتيبند : ۱)
- 199. توزيع دوباره در هنگام درج ،راهي براي جلوگيري يا حداقل به تعويق انداختن ايجاد صفحات جديد
- 200. به جاي تقسيم کردن يک صفحه پر و ايجاد دو صفحه نيمه پر، توزيع دوباره اين
- 201. يک نوع جديد از درخت B را به عنوان درخت B* تعريف مي کنيم که خواص
- 202. فرايند دستيابي به ديسک براي خواندن صفحه اي که در بافر وجود ندارد، نقص صفحه اي
- 203. دو علت براي نقص صفحه وجود دارد : ۱) هيچگاه تا کنون از آن صفحه استفاده
- 204. يک راه براي مورد دوم صفحه قبل اين است که صفحه اي را که زودتر از
- 205. استفاده از رکوردهاي با طول متغير باعث صرفه جويي در فضا و در نتيجه کاهش ارتفاع
- 206. جلسه سيزدهم دستيابي به فايلهاي ترتيبي شاخصدار و درختهاي B+
- 207. دستيابي به فايل هاي ترتيبي شاخص دار و درخت هاي
- 208. ساختارهاي فايل ترتيبي انديس دار ،امکان انتخاب از ميان دو ديدگاه متفاوت نسبت به فايل را
- 209. مجموعه اي از رکوردها که به طور فيزيکي توسط کليدها مرتب شده اند و رکوردهايي به
- 210. هنگاميکه رکوردها را بلوک بندي مي کنيم ، بلوک واحد اصلي ورودي و خروجي مي شود.
- 211. همانند درخت هاي B ،درج رکوردهاي جديد در يک بلوک مي تواند باعث سرريز شدن بلوک
- 212. مشکل سرريز شدن را مي توان توسط يک فرايند شکستن بلوک ها کنترل کرد که شبيه
- 213. ته ريز شدن در درخت B مي تواند منجر به يکي از دو راه حل زير
- 214. مسئله اندازه بلوک به تعيين حدود (limits) اندازه بلوک تبديل مي شود.
- 215. دو شرطي که در رابطه با حد بالايي اندازه بلوک در نظر مي گيريم عبارت است
- 216. ساختار مختلط يک شاخص B بعلاوه يک مجموعه ترتيبي که رکوردها را نگه مي دارد درخت
- 217. هدف از ساختن شاخص آن است که هنگام جستجوي رکوردي با يک کليد مشخص ،به ما
- 218. محتويات شاخص فقط تا آن حد مورد علاقه ما هستند که بتوانند ما را در رسيدن
- 219. با در نظر گرفتن مجموعه شاخص به عنوان يک نقشه راهنما مي توانيم اين گام بسيار
- 220. شاخص درخت B را مجموعه شاخص مي نامند. اين شاخص به همراه مجموعه ترتيبي ،ساختار فايلي
- 221. عبارت پيشوندي ساده (simple prefix) نشانگر آن است که مجموعه شاخص حاوي کوتاهترين جداکننده ها يا
- 222. اگر حذف رکوردها از مجموعه ترتيبي و اضافه کردن رکوردها به آن ،تعداد رکوردها را در
- 223. جلسه چهاردهم ادامه مبحث دستيابي به فايل هاي ترتيبي شاخص دار و درخت هايB+ درهم سازي
- 224. درج و حذف رکوردها همواره در مجموعه ترتيبي رخ مي دهد ،زيرا رکوردها در آنجا قرار
- 225. اگر شکافتگي ،ادغام يا توزيع دوباره مورد نياز باشد ، عمليات را درست طوري انجام مي
- 226. پس از کامل شدن عمليات مربوط به رکورد در مجموعه ترتيبي تغييرات مورد نياز در مجموعه
- 227. چند دليل براي استفاده از ا ندازه بلوک مشترک ميان مجموعه هاي ترتيبي و انديسي وجود
- 228. علاوه بر بردار جداکننده ها ،شاخص اين جداکننده ها و ليست شماره هاي بلوک مربوط ،ساختار
- 229. فرايند بارگذاري بسيار سريع پيش مي رود زيرا : ۱) خروجي را مي توان به طور
- 230. تفاوت ميان درخت پيشوندي ساده و درخت آن است که از پيشوندهايي به عنوان جداکننده استفاده
- 231. هر دو نوع درخت پيشوندي ساده و درخت ، از يک مجموعه رکورد تشکيل مي شود
- 232. دو عامل وجود دارد که ممکن است وضعيت را به نفع درخت که در آن ،کپي
- 233. درخت B ، درخت پيشوندي ساده و درخت در خصوصيات زير مشترکند : ۱) همگي ساختارهاي
- 234. ساختار درخت سه مزيت مهم ير درخت B دارد: ۱) مجموعه ترتيبي را مي توان به
- 235. درهم سازي
- 236. دستيابي O(1) به فايل به اين معنا است که مهم نيست فايل تا چه اندازه بزرگ
- 237. تابع درهم سازي مانند يک جعبه سياه است که هرگاه کليدي در داخل آن انداخته مي
- 238. درهم سازي را تصادفي کردن نيز مي گويند. درهم سازي ،از اين نظر که يک کليد
- 239. درهم سازي و انديس سازي از دو جهت با هم تفاوت دارند : ۱) آدرس هايي
- 240. جلسه پانزدهم ادامه مبحث درهم سازي
- 241. اگر دو رکورد به يک مکان در فايل انتقال يابند به آن برخورد مي گويند.
- 242. روش ايده آل مقابله با برخوردها اين است که بتوان الگوريتم تبديلي پيدا کرد که به
- 243. چندين راه مختلف براي کاهش تعداد برخوردها وجود دارد که بعضي از آنها عبارتند از :
- 244. به آدرس هايي که مي توانند چندين رکورد را نگهداري کنند باکت مي گويند.
- 245. در اين فصل يک الگوريتم درهم سازي ساده نوشته تا انواع اعمالي را که در الگوريتم
- 246. در حالت ايده آل تابع درهم سازي ،رکوردها را به گونه اي توزيع مي کند که
- 248. بعضي از روشهايي که به صورت بالقوه بهتر از درهم سازي هستند نام مي بريم: ۱)
- 249. توزيع پوآسون ابزاري رياضي را براي بررسي اثرات توزيع تصادفي ارائه مي کند. از توابع پوآسون
- 250. گرچه مي توانيم تعداد برخوردها را کم کنيم ،بايد ابزارهايي داشته باشيم که در صورت وقوع
- 251. اگر جستجو براي يافتن رکورد آغاز شود اما رکورد در فايل ذخيره نشده باشد چه اتفاقي
- 252. منظور از طول جستجو ،تعداد دستيابي هاي لازم براي بازيابي يک رکورد از حافظه ثانويه است.
- 254. هنگاميکه قرار است که يک رکورد ذخيره يا بازيابي شود ،آدرس باکت خانگي ،توسط درهم سازي
- 255. براي محاسبه دانسيته فشردگي فايل بايد هم به تعداد آدرس ها (باکت ها) و هم به
- 256. جلسه شانزدهم ادامه مبحث درهم سازي درهم سازي قابل توسعه
- 257. به عنوان يک اصل معمولاً استفاده از باکت هاي بزرگتر از شيار ،ايده خوبي نيست(مگر در
- 258. فايلهاي درهم سازي به دو روش با فايلهايي که تا کنون مورد بررسي قرار گرفته ان
- 259. تنها تفاوت بين فايل هايي که باکت دارند و فايل هايي که تنها مي توانند يک
- 260. به دو دليل حذف کردن يک رکورد از فايل درهم سازي شده پيچيده تر از اضافه
- 261. خوبي علائم ويژه اين است که ،دو مشکلي را که درقبل آن اشاره شد حل مي
- 262. چون رکوردهاي سرريز ،تأثير بسزايي در کارايي دارند تکنيک هاي زيادي براي جلوگيري از برخوردها پيشنهاد
- 263. درهم سازي قابل توسعه
- 264. ويژگي مهم در درخت AVL و درخت B آن است که اين ساختارها خود تنظيم هستند
- 265. ايده کليدي در فرايند درهم سازي قابل توسعه ،ترکيب کردن درهم سازي معمولي با يک روش
- 266. اگر رکوردي اضافه کنيم وجايي براي آن در باکت وجود نداشته باشد ،باکت را مي شکافيم.
- 267. هدف از سيستم درهم سازي قابل توسعه ،يافتن راهي براي افزايش فضاي آدرس ،در پاسخ به
- 268. عمليات اصلي روي باکت ها دقيقاً همانند عمليات رکوردهاي شاخص است : افزودن يک جفت کليد-
- 269. حذف ،عکس فرايند اضافه کردن است ،با ذکر اين نکته که فقط در صورتي مي توان
- 270. عمل تنزل شامل تخصيص فضا به آرايه جديدي از آدرس هاي باکت است که اندازه آن
- 271. درهم سازي پويا و درهم سازي قابل توسعه از نظر عملکرد شباهت بسيار دارند. هر دو
- 273. Скачать презентацию

جلسه اول: آشنايي با طراحي و مشخصات ساختار فايلها، عمليات مهم
جلسه اول: آشنايي با طراحي و مشخصات ساختار فايلها، عمليات مهم

جلسه هفتم: ادامه مبحث سازماندهي فايلها براي کارايي، شاخص گذاري
جلسه
جلسه هفتم: ادامه مبحث سازماندهي فايلها براي کارايي، شاخص گذاري
جلسه

جلسه سيزدهم: دستيابي به فايل هاي ترتيبي شاخص دار و درخت
جلسه سيزدهم: دستيابي به فايل هاي ترتيبي شاخص دار و درخت

جلسه اول
آشنايي با طراحي و مشخصات ساختار فايلها
عمليات
جلسه اول
آشنايي با طراحي و مشخصات ساختار فايلها
عمليات

آشنايي با طراحي و مشخصات ساختار فايلها
آشنايي با طراحي و مشخصات ساختار فايلها

ساختار فايل ترکيبي از نحوه نمايش داده ها در فايل ها
ساختار فايل ترکيبي از نحوه نمايش داده ها در فايل ها

طي سه دهه اخير با بررسي تکامل ساختارهاي فايل مشاهده
طي سه دهه اخير با بررسي تکامل ساختارهاي فايل مشاهده

يک مشکل اصلي در توصيف کلاس هايي که بتوان براي
يک مشکل اصلي در توصيف کلاس هايي که بتوان براي

در يک سيستم اطلاعاتي شيء گرا محتوا و رفتار داده
در يک سيستم اطلاعاتي شيء گرا محتوا و رفتار داده

مشکل اصلي در طراحي ساختار فايل زمان نسبتاً زيادي است
مشکل اصلي در طراحي ساختار فايل زمان نسبتاً زيادي است

عمليات مهم پردازش فايل
عمليات مهم پردازش فايل

هنگامي که درباره فايلي روي يک ديسک يا نوار صحبت
هنگامي که درباره فايلي روي يک ديسک يا نوار صحبت

برنامه غالباً نمي داند بايت ها از کجا مي آيند
برنامه غالباً نمي داند بايت ها از کجا مي آيند

هنگامي که شناسه (identifier) فايل منطقي با دستگاه يا فايل
هنگامي که شناسه (identifier) فايل منطقي با دستگاه يا فايل

هنگامي که برنامه اي به صورت عادي پايان مي يابد
هنگامي که برنامه اي به صورت عادي پايان مي يابد

خواندن و نوشتن در پردازش فايل اهميت بنيادي دارند ،اينها
خواندن و نوشتن در پردازش فايل اهميت بنيادي دارند ،اينها

براي دستيابي آسان به تعداد زياد از فايل ها کامپيوتر
براي دستيابي آسان به تعداد زياد از فايل ها کامپيوتر

يکي از پر قدرت ترين ايده ها در يونيکس تعريفي
يکي از پر قدرت ترين ايده ها در يونيکس تعريفي

يونيکس فرمان هاي بسياري براي دستکاري فايل ها دارد که
يونيکس فرمان هاي بسياري براي دستکاري فايل ها دارد که

حافظه جانبي و نرم افزار سيستم
حافظه جانبي و نرم افزار سيستم

دستگاه هاي حافظه جانبي ،با حافظه تفاوت بسيار دارند. همان
دستگاه هاي حافظه جانبي ،با حافظه تفاوت بسيار دارند. همان

ديسک ها انواع مختلفي دارند :
۱) ديسک هاي سخت (hard
ديسک ها انواع مختلفي دارند :
۱) ديسک هاي سخت (hard

جلسه دوم
ادامه مبحث حافظه جانبي و نرم افزار سيستم
جلسه دوم
ادامه مبحث حافظه جانبي و نرم افزار سيستم

اطلاعات ذخيره شده روي ديسک ،در سطح يک يا چند
اطلاعات ذخيره شده روي ديسک ،در سطح يک يا چند


ديسک گردان ها معمولاً چند صفحه دارند. شيارهايي که مستقيماً
ديسک گردان ها معمولاً چند صفحه دارند. شيارهايي که مستقيماً


ظرفيت ديسک تابعي از تعداد سيلندرها ،تعدا شيارها به ازاي هر
ظرفيت ديسک تابعي از تعداد سيلندرها ،تعدا شيارها به ازاي هر

دو روش براي سازماندهي داده ها بر روي ديسک وجود
دو روش براي سازماندهي داده ها بر روي ديسک وجود

کلاستر عبارت از تعداد ثابتي از سکتورهاي پيوسته است.
مديريت فايل
کلاستر عبارت از تعداد ثابتي از سکتورهاي پيوسته است.
مديريت فايل

اگر فضاي زيادي روي ديسک باشد ، ممکن است بتوان
اگر فضاي زيادي روي ديسک باشد ، ممکن است بتوان


اتلاف فضا در داخل يک سکتور را پراکندگي داخلي مي
اتلاف فضا در داخل يک سکتور را پراکندگي داخلي مي

بلوک معمولاً طوري سازماندهي مي شود که تعداد مناسبي از
بلوک معمولاً طوري سازماندهي مي شود که تعداد مناسبي از

در الگوهاي آدرس دهي بلاکي هر بلوک از داده ها
در الگوهاي آدرس دهي بلاکي هر بلوک از داده ها

هم بلاک ها و هم سکتورها نيازمند آنند که مقدار
هم بلاک ها و هم سکتورها نيازمند آنند که مقدار

فرمت کردن موجب مي شود تا شکاف (gap) و علامت
فرمت کردن موجب مي شود تا شکاف (gap) و علامت

دستيابي به ديسک را مي توان به سه عمل فيزيکي
دستيابي به ديسک را مي توان به سه عمل فيزيکي

جلسه سوم
ادامه مبحث حافظه جانبي و نرم افزار سيستم
جلسه سوم
ادامه مبحث حافظه جانبي و نرم افزار سيستم

زمان پيگرد عبارت است از زمان لازم انتقال بازوي دستيابي
زمان پيگرد عبارت است از زمان لازم انتقال بازوي دستيابي

تأخير در چرخش عبارت است از زمان لازم براي چرخش
تأخير در چرخش عبارت است از زمان لازم براي چرخش

علي رغم افزايش کارايي ديسک ها ،سرعت شبکه ها به
علي رغم افزايش کارايي ديسک ها ،سرعت شبکه ها به

نوارهاي مغناطيسي به دستگاه هايي تعلق دارند که دستيابي مستقيم
نوارهاي مغناطيسي به دستگاه هايي تعلق دارند که دستيابي مستقيم

نقاط قوت CD-ROM شامل ظرفيت ذخيره سازي بالا،بهاي کم و
نقاط قوت CD-ROM شامل ظرفيت ذخيره سازي بالا،بهاي کم و

در قالب سرعت خطي ثابت (CLV) ،سرعت چرخش ديسک هنگام
در قالب سرعت خطي ثابت (CLV) ،سرعت چرخش ديسک هنگام


بافر I/O سيستم ،به مديريت فايل اين امکان را مي
بافر I/O سيستم ،به مديريت فايل اين امکان را مي

عمل کنترل عمليات ديسک توسط دستگاهي انجام مي شود که
عمل کنترل عمليات ديسک توسط دستگاهي انجام مي شود که

سيستم هاي I/O تقريباً هميشه حداقل دو بافر دارند. يکي
سيستم هاي I/O تقريباً هميشه حداقل دو بافر دارند. يکي

با پراکنش ورودي ،با يک بار خواندن ،نه يک بار
با پراکنش ورودي ،با يک بار خواندن ،نه يک بار

هسته به نوبت به اين چهار جدول زير مراجعه مي
هسته به نوبت به اين چهار جدول زير مراجعه مي


اشاره گري از يک فهرست به اينود فايل را اتصال
اشاره گري از يک فهرست به اينود فايل را اتصال

سه نوع سيستم I/O متفاوت داريم :
۱) سيستم I/O بلوکي
۲) سيستم
سه نوع سيستم I/O متفاوت داريم :
۱) سيستم I/O بلوکي
۲) سيستم

براي هر دستگاه جانبي مجموعه اي از روال هاي جداگانه
براي هر دستگاه جانبي مجموعه اي از روال هاي جداگانه

جلسه چهارم
مفاهيم اساسي ساختار فايل
مديريت فايلهايي از رکوردها
جلسه چهارم
مفاهيم اساسي ساختار فايل
مديريت فايلهايي از رکوردها

مفاهيم اساسي ساختار فايل
مفاهيم اساسي ساختار فايل

واحد اصلي داده ها،فيلد است که حاوي يک مقدار داده
واحد اصلي داده ها،فيلد است که حاوي يک مقدار داده

هنگامي که رکوردي در حافظه نگهداري شد آن را يک
هنگامي که رکوردي در حافظه نگهداري شد آن را يک

راههاي فراواني براي افزودن ساختار به فايل وجود دارد تا
راههاي فراواني براي افزودن ساختار به فايل وجود دارد تا

رکورد مجموعه اي از فيلد ها است و مجموعه اي
رکورد مجموعه اي از فيلد ها است و مجموعه اي

بعضي از روش هاي سازماندهي رکوردهاي فايل عبارتند از :
۱) قابل
بعضي از روش هاي سازماندهي رکوردهاي فايل عبارتند از :
۱) قابل

دو روش براي نمايش طول رکورد وجود دارد :
۱) طول رکورد
دو روش براي نمايش طول رکورد وجود دارد :
۱) طول رکورد

با روبرداري فايل مي توان بايت هاي واقعي نگهداري شده
با روبرداري فايل مي توان بايت هاي واقعي نگهداري شده

C++ وراثت را در اختيار قرار مي دهد تا چندين کلاس
C++ وراثت را در اختيار قرار مي دهد تا چندين کلاس


مديريت فايلهايي از رکوردها
مديريت فايلهايي از رکوردها

هنگامي که کارايي جستجوهاي انجام شده در حافظه الکترونيکي را
هنگامي که کارايي جستجوهاي انجام شده در حافظه الکترونيکي را

به طورکلي ،کار مورد نياز براي جستجوي ترتيبي ، در
به طورکلي ،کار مورد نياز براي جستجوي ترتيبي ، در

در تحليل و بحث درباره بلوک بندي رکورد چند چيز را
در تحليل و بحث درباره بلوک بندي رکورد چند چيز را

جستجوي ترتيبي براي اکثر شرايط بازيابي زمان بسيار مي برد.
اين که
جستجوي ترتيبي براي اکثر شرايط بازيابي زمان بسيار مي برد.
اين که

متداول ترين ساختار فايل که در يونيکس وجود دارد ،
متداول ترين ساختار فايل که در يونيکس وجود دارد ،

روش ديگري که با جستجوي ترتيبي تفاوت بنيادي دارد ، دستيابي
روش ديگري که با جستجوي ترتيبي تفاوت بنيادي دارد ، دستيابي

جلسه پنجم
ادامه مبحث مديريت فايلهايي از رکوردها
جلسه پنجم
ادامه مبحث مديريت فايلهايي از رکوردها

غالباً لازم است از برخي اطلاعات عمومي مربوط به فايل آگاه
غالباً لازم است از برخي اطلاعات عمومي مربوط به فايل آگاه

هر فايل داراي يک رکورد سرآيند (header) است که حاوي سه
هر فايل داراي يک رکورد سرآيند (header) است که حاوي سه

دو ساختار مختلف از رکوردها که حاوي فيلدهاي طول متغير در
دو ساختار مختلف از رکوردها که حاوي فيلدهاي طول متغير در

يک طراحي شيءگراي خوب ،براي ماندگار شدن اشياء بايد عملياتي براي
يک طراحي شيءگراي خوب ،براي ماندگار شدن اشياء بايد عملياتي براي

تا کنون عمل نوشتن نيازمند به دو عمل جداگانه بود :
۱)
تا کنون عمل نوشتن نيازمند به دو عمل جداگانه بود :
۱)

در اين بخش ،کلاس recordfile را معرفي مي کنيم که نوعي
در اين بخش ،کلاس recordfile را معرفي مي کنيم که نوعي

در بحث هايي که طي اين فصل و فصل قبل
در بحث هايي که طي اين فصل و فصل قبل

داده هايي مثل صوت ،تصاوير ،و اسناد به صورت فيلدها
داده هايي مثل صوت ،تصاوير ،و اسناد به صورت فيلدها

اگر در زبان برنامه نويسي امکان داشته باشد، مي توانيم
اگر در زبان برنامه نويسي امکان داشته باشد، مي توانيم

شبه داده ها را مي توان با هر فايلي همراه
شبه داده ها را مي توان با هر فايلي همراه

تصوير راستر رنگي ،آرايه اي راست گوشه از نقاط رنگي يا
تصوير راستر رنگي ،آرايه اي راست گوشه از نقاط رنگي يا

انواع متفاوت فراواني از شبه داده ها وجود دارند که مي
انواع متفاوت فراواني از شبه داده ها وجود دارند که مي

متدهايي براي کار با تصاوير به عنوان اشياي خاصي وجود دارد
متدهايي براي کار با تصاوير به عنوان اشياي خاصي وجود دارد

ايده دنبال کردن فايل ها براي قرار دادن دامنه وسيعي
ايده دنبال کردن فايل ها براي قرار دادن دامنه وسيعي

براي توصيف ديدي که يک برنامه کاربردي از اشياي داده
براي توصيف ديدي که يک برنامه کاربردي از اشياي داده

جلسه ششم
ادامه مبحث مديريت فايلهايي از رکوردها
سازماندهي فايلها
جلسه ششم
ادامه مبحث مديريت فايلهايي از رکوردها
سازماندهي فايلها

يکي از مزاياي استفاده از برچسب ها براي شناسايي اشياي
يکي از مزاياي استفاده از برچسب ها براي شناسايي اشياي

اختلاف ميان زبان ها ،سيستم هاي عامل ،و معماري ماشين
اختلاف ميان زبان ها ،سيستم هاي عامل ،و معماري ماشين

چند راه حل براي دستيابي به قابليت حمل :
۱) توافق بر
چند راه حل براي دستيابي به قابليت حمل :
۱) توافق بر

سازماندهي فايلها براي کارايي
سازماندهي فايلها براي کارايي

فشرده سازي يک فرايند دسته اي (batch) است که براي
فشرده سازي يک فرايند دسته اي (batch) است که براي

دلايل زيادي براي کوچک کردن فايلها وجود دارد :
۱) فايل هاي
دلايل زيادي براي کوچک کردن فايلها وجود دارد :
۱) فايل هاي

فشرده سازي داده ها عبارت است از رمزگذاري اطلاعات در فايل
فشرده سازي داده ها عبارت است از رمزگذاري اطلاعات در فايل

تکنيک فشرده سازي که در آن تعداد بيت ها با
تکنيک فشرده سازي که در آن تعداد بيت ها با

آرايه هاي اسپارس براي نوعي فشرده سازي به نام رمزگذاري
آرايه هاي اسپارس براي نوعي فشرده سازي به نام رمزگذاري

الگوريتم آ رايه هاي اسپارس را به صورت زير اجرا مي
الگوريتم آ رايه هاي اسپارس را به صورت زير اجرا مي

نوع ديگري از فشرده سازي کدهاي با طول متغير را بسته
نوع ديگري از فشرده سازي کدهاي با طول متغير را بسته

راهي ديگر براي صرفه جويي فضا در يک فايل، بازيابي فضا
راهي ديگر براي صرفه جويي فضا در يک فايل، بازيابي فضا

تغييرات فايل به سه شکل انجام مي شود :
۱) اضافه
تغييرات فايل به سه شکل انجام مي شود :
۱) اضافه

متراکم کردن فايل از طريق پيدا کردن مکان هايي در
متراکم کردن فايل از طريق پيدا کردن مکان هايي در

متراکم کردن فايل آسان ترين و رايج ترين روش هاي بازيابي
متراکم کردن فايل آسان ترين و رايج ترين روش هاي بازيابي

به طور کلي براي فراهم کردن مکانيسمي براي حذف رکوردها و
به طور کلي براي فراهم کردن مکانيسمي براي حذف رکوردها و

جلسه هفتم
ادامه مبحث سازماندهي فايلها براي کارايي
شاخص
جلسه هفتم
ادامه مبحث سازماندهي فايلها براي کارايي
شاخص

براي بازيابي سريعتر فضا به وارد زير نيازمنديم :
۱) راهي که
براي بازيابي سريعتر فضا به وارد زير نيازمنديم :
۱) راهي که

استفاده از ليست هاي پيوندي براي پيوند دادن تمام رکوردها هر
استفاده از ليست هاي پيوندي براي پيوند دادن تمام رکوردها هر

آسان ترين راه براي کار کردن با ليست استفاده از آن
آسان ترين راه براي کار کردن با ليست استفاده از آن

براي بازيابي رکوردها از طريق ليست پيوندي به موارد زير نياز
براي بازيابي رکوردها از طريق ليست پيوندي به موارد زير نياز

براي مقابله با پراکندگي خارجي يک روش متراکم کردن فايل
براي مقابله با پراکندگي خارجي يک روش متراکم کردن فايل

هنگامي که نياز داريم يک حفره رکورد را از ليست
هنگامي که نياز داريم يک حفره رکورد را از ليست

سه مشکل اساسي مربوط به مرتب سازي و جستجوي دودويي
سه مشکل اساسي مربوط به مرتب سازي و جستجوي دودويي

مرتب سازي کليدي که گاهي به آن مرتب سازي با برچسب
مرتب سازي کليدي که گاهي به آن مرتب سازي با برچسب

عيب مرتب سازي کليدي اين است که مرتب کردن فايلي با
عيب مرتب سازي کليدي اين است که مرتب کردن فايلي با

شاخص گذاري
شاخص گذاري

همه شاخص ها بر اساس يک مفهوم اصلي واحد عمل
همه شاخص ها بر اساس يک مفهوم اصلي واحد عمل

انواع شاخص هايي که در اين فصل بررسي مي کنيم
انواع شاخص هايي که در اين فصل بررسي مي کنيم

چون شاخص ها به طور غير مستقيم عمل مي کنند
چون شاخص ها به طور غير مستقيم عمل مي کنند

کاتالوگ کارتي در واقع مجموعه اي از سه شاخص است
کاتالوگ کارتي در واقع مجموعه اي از سه شاخص است

بنابراين کاربرد ديگر شاخص بندي اين است که مي توان
بنابراين کاربرد ديگر شاخص بندي اين است که مي توان

در جستجوي دودويي لازم است امکان پرش به وسط فايل
در جستجوي دودويي لازم است امکان پرش به وسط فايل

جلسه هشتم
ادامه مبحث شاخص گذاري
جلسه هشتم
ادامه مبحث شاخص گذاري

راه ديگر براي مرتب سازي ، ايجاد شاخص براي فايل است.
راه ديگر براي مرتب سازي ، ايجاد شاخص براي فايل است.

ساختار شيء شاخص بسيار ساده است.
اين ساختار ليستي است که
ساختار شيء شاخص بسيار ساده است.
اين ساختار ليستي است که

عملياتي که براي يافتن داده هاي مورد نظر ،از طريق شاخص
عملياتي که براي يافتن داده هاي مورد نظر ،از طريق شاخص

مزيت بزرگي که روش شيء گرا دارد آن است که
مزيت بزرگي که روش شيء گرا دارد آن است که

در ايجاد فايل ها بايد دو فايل ايجاد شوند :
۱) فايل
در ايجاد فايل ها بايد دو فايل ايجاد شوند :
۱) فايل

بهنگام سازي رکوردها به دو صورت انجام مي شود :
۱)
بهنگام سازي رکوردها به دو صورت انجام مي شود :
۱)

آشکارترين بهينه سازي ،استفاده از جستجوي دودويي در متد find است
آشکارترين بهينه سازي ،استفاده از جستجوي دودويي در متد find است

منبع ديگر بهينه سازي ،چنانچه رکورد شاخص تغيير نکرده باشد
منبع ديگر بهينه سازي ،چنانچه رکورد شاخص تغيير نکرده باشد

دستيابي به شاخص روي ديسک داراي معايب زير است :
۱)
دستيابي به شاخص روي ديسک داراي معايب زير است :
۱)

هرگاه يک شاخص ساده در حافظه جا نشود بايد از موارد
هرگاه يک شاخص ساده در حافظه جا نشود بايد از موارد

شاخص هاي ساده نسبت به استفاده از فايل داده اي
شاخص هاي ساده نسبت به استفاده از فايل داده اي

هنگاميکه شاخص ثانويه اي موجود باشد ،افزودن يک رکورد به
هنگاميکه شاخص ثانويه اي موجود باشد ،افزودن يک رکورد به

يک اختلاف مهم شاخص ثانويه و شاخص اوليه آن است
يک اختلاف مهم شاخص ثانويه و شاخص اوليه آن است

حذف يک رکورد معمولاً به معناي حذف تمامي آدرس هاي
حذف يک رکورد معمولاً به معناي حذف تمامي آدرس هاي

مشکل اين است که شاخص هاي ثانويه همانند شاخص اوليه
مشکل اين است که شاخص هاي ثانويه همانند شاخص اوليه

جلسه نهم
ادامه مبحث شاخص گذاري
پردازش کمک ترتيبي
جلسه نهم
ادامه مبحث شاخص گذاري
پردازش کمک ترتيبي

بهنگام سا زي فايل داده ها فقط هنگامي شاخص ثانويه
بهنگام سا زي فايل داده ها فقط هنگامي شاخص ثانويه

ساختارهاي شاخص ثانويه اي که تا کنون ارائه کرديم دو مشکل
ساختارهاي شاخص ثانويه اي که تا کنون ارائه کرديم دو مشکل

درسيستم فايلي که طي اين فصل طراحي کرديم ، انقياد
درسيستم فايلي که طي اين فصل طراحي کرديم ، انقياد

پردازش کمک ترتيبي و مرتب سازي فايل هاي بزرگ
پردازش کمک ترتيبي و مرتب سازي فايل هاي بزرگ

عمليات کمک ترتيبي شامل پردازش هماهنگ دو يا چند ليست
عمليات کمک ترتيبي شامل پردازش هماهنگ دو يا چند ليست

گرچه روال همخواني بسيار ساده به نظر مي رسد ،براي
گرچه روال همخواني بسيار ساده به نظر مي رسد ،براي

اگر قرار باشد تعداد زيادي از ليست ها با هم
اگر قرار باشد تعداد زيادي از ليست ها با هم

مرتب سازي در حافظه شامل سه مرحله است :
۱) خواندن
مرتب سازي در حافظه شامل سه مرحله است :
۱) خواندن

آيا يک الگوريتم مرتب سازي داخلي وجود دارد که به
آيا يک الگوريتم مرتب سازي داخلي وجود دارد که به

هرم درختي دودويي با ويژگي هاي زير است :
۱) هر گره
هرم درختي دودويي با ويژگي هاي زير است :
۱) هر گره


الگوريتم مرتب سازي هرمي دو بخش دارد:
ابتدا هرم را
الگوريتم مرتب سازي هرمي دو بخش دارد:
ابتدا هرم را

بازيابي ترتيبي کليدها به صورت زير انجام مي شود :
۱)
بازيابي ترتيبي کليدها به صورت زير انجام مي شود :
۱)

مرتب سازي کليدي دو نارسايي دارد :
۱) هنگاميکه کليدها مرتب
مرتب سازي کليدي دو نارسايي دارد :
۱) هنگاميکه کليدها مرتب

رانش داراي ويژگي هاي زير است :
۱) واقعاً قادر به
رانش داراي ويژگي هاي زير است :
۱) واقعاً قادر به

I/O چهار بار اجرا مي گردد.
در مرحله مرتب سازي :
I/O چهار بار اجرا مي گردد.
در مرحله مرتب سازي :

جلسه دهم
ادامه مبحث پردازش کمک ترتيبي و مرتب سازي
جلسه دهم
ادامه مبحث پردازش کمک ترتيبي و مرتب سازي

يک اختلاف عمده ميان مرحله مرتب سازي و مرحله ادغام
يک اختلاف عمده ميان مرحله مرتب سازي و مرحله ادغام

به طور خلاصه چون مرحله ادغام تنها مرحله اي است
به طور خلاصه چون مرحله ادغام تنها مرحله اي است

با بزرگ شدن فايل ها زمان لازم براي مرتب سازي
با بزرگ شدن فايل ها زمان لازم براي مرتب سازي

در اين بخش سه تغيير ممکن در پيکربندي سيستم را
در اين بخش سه تغيير ممکن در پيکربندي سيستم را


هدف اصلي اين مرتب سازي ادغامي آن است که قادر
هدف اصلي اين مرتب سازي ادغامي آن است که قادر

در ادغام چند مرحله اي، سعي نمي کنيم همه رانش
در ادغام چند مرحله اي، سعي نمي کنيم همه رانش

اساس انتخاب جايگزيني ،اين ايده است :
انتخاب هميشگي کليدي از
اساس انتخاب جايگزيني ،اين ايده است :
انتخاب هميشگي کليدي از

الگوريتم انتخاب جايگزيني را مي توان به طريق زير پياده سازي
الگوريتم انتخاب جايگزيني را مي توان به طريق زير پياده سازي

۳) آوردن يک رکورد جديد و مقايسه مقدار کليد آن با
۳) آوردن يک رکورد جديد و مقايسه مقدار کليد آن با

گزينش جايگزيني ابزاري سودمند براي فايل هاي ورودي است که
گزينش جايگزيني ابزاري سودمند براي فايل هاي ورودي است که

در گزينش جايگزيني اگر دو ديسک در اختيار داشته باشيم
در گزينش جايگزيني اگر دو ديسک در اختيار داشته باشيم

اختصاص دادن بيش از يک پردازنده به يک کار امري
اختصاص دادن بيش از يک پردازنده به يک کار امري

اگر در سيستمي برنامه نويسي چندگانه امکان پذير باشد زمان
اگر در سيستمي برنامه نويسي چندگانه امکان پذير باشد زمان

يکي از دلايل برنامه ريزي چندگانه آن است که به
يکي از دلايل برنامه ريزي چندگانه آن است که به

جلسه يازدهم
ادامه مبحث پردازش کمک ترتيبي و مرتب سازي
جلسه يازدهم
ادامه مبحث پردازش کمک ترتيبي و مرتب سازي

ليست کاملي از مجموعه جديد ابزاهايي که کارايي مرتب سازي
ليست کاملي از مجموعه جديد ابزاهايي که کارايي مرتب سازي

درادغام موازنه شده دوجانبه ،توزيع اوليه بايد روي دو نوارگردان
درادغام موازنه شده دوجانبه ،توزيع اوليه بايد روي دو نوارگردان

ايده هاي استفاده از الگوريتم هاي ادغام مرتبه بالاتر و
ايده هاي استفاده از الگوريتم هاي ادغام مرتبه بالاتر و

چون ديسک ها دستگاههاي دستيابي مستقيم هستند ادغام هاي با
چون ديسک ها دستگاههاي دستيابي مستقيم هستند ادغام هاي با

شاخص بندي چند سطحي و درختهاي B
شاخص بندي چند سطحي و درختهاي B

مشکل اصلي نگهداشتن شاخص در حافظه جانبي اين است که
مشکل اصلي نگهداشتن شاخص در حافظه جانبي اين است که

درخت جستجوي دودويي چه اشکالي دارد؟
۱) براي شاخص بندي روي
درخت جستجوي دودويي چه اشکالي دارد؟
۱) براي شاخص بندي روي

تلاشهايي براي حل مشکلات درخت جستجوي دودويي انجام گرفت که
تلاشهايي براي حل مشکلات درخت جستجوي دودويي انجام گرفت که

درخت AVL درختي با ارتفاع موازنه شده است.
يعني اينکه
درخت AVL درختي با ارتفاع موازنه شده است.
يعني اينکه


دو مزيت که درخت هاي AVL را با اهميت مي کنند
دو مزيت که درخت هاي AVL را با اهميت مي کنند

درخت دودويي صفحه اي ،سعي مي کند با قرار دادن
درخت دودويي صفحه اي ،سعي مي کند با قرار دادن
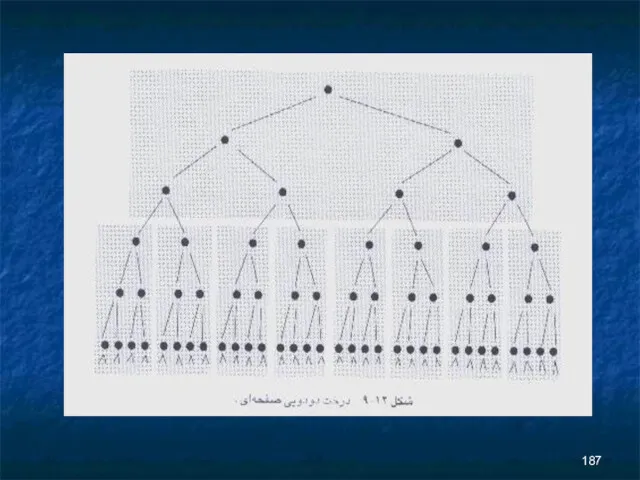

واضح است که تقسيم کردن درخت به چندين صفحه امکان
واضح است که تقسيم کردن درخت به چندين صفحه امکان

مشکل اصلي درخت هاي صفحه اي هنوز هم استفاده از
مشکل اصلي درخت هاي صفحه اي هنوز هم استفاده از

درخت هاي B شاخص هاي چند سطحي هستندکه مشکل هزينه
درخت هاي B شاخص هاي چند سطحي هستندکه مشکل هزينه

جلسه دوازدهم
ادامه مبحث شاخص بندي چند سطحي و درختهاي
جلسه دوازدهم
ادامه مبحث شاخص بندي چند سطحي و درختهاي

جستجو در درخت B :
۱) به صورت تکراري عمل مي
جستجو در درخت B :
۱) به صورت تکراري عمل مي

در مورد فرايند درج کردن ،تقسيم کردن و ارتقاء ملاحظات
در مورد فرايند درج کردن ،تقسيم کردن و ارتقاء ملاحظات

از مرتبه درخت B به عنوان حداقل تعداد کليدهايي که
از مرتبه درخت B به عنوان حداقل تعداد کليدهايي که

پايين ترين سطح کليدها در درخت B را برگ مي
پايين ترين سطح کليدها در درخت B را برگ مي

با استفاده از تعاريف ارائه شده از مرتبه و برگ
با استفاده از تعاريف ارائه شده از مرتبه و برگ

تضمين اين که درخت پهن و کم عمق باشد ،نه
تضمين اين که درخت پهن و کم عمق باشد ،نه

قوانين حذف کليد k از گره n در يک درخت B
قوانين حذف کليد k از گره n در يک درخت B

توزيع دوباره در هنگام درج ،راهي براي جلوگيري يا حداقل
توزيع دوباره در هنگام درج ،راهي براي جلوگيري يا حداقل

به جاي تقسيم کردن يک صفحه پر و ايجاد دو
به جاي تقسيم کردن يک صفحه پر و ايجاد دو

يک نوع جديد از درخت B را به عنوان درخت
يک نوع جديد از درخت B را به عنوان درخت

فرايند دستيابي به ديسک براي خواندن صفحه اي که در
فرايند دستيابي به ديسک براي خواندن صفحه اي که در

دو علت براي نقص صفحه وجود دارد :
۱) هيچگاه تا
دو علت براي نقص صفحه وجود دارد :
۱) هيچگاه تا

يک راه براي مورد دوم صفحه قبل اين است که
يک راه براي مورد دوم صفحه قبل اين است که

استفاده از رکوردهاي با طول متغير باعث صرفه جويي در
استفاده از رکوردهاي با طول متغير باعث صرفه جويي در

جلسه سيزدهم
دستيابي به فايلهاي ترتيبي شاخصدار و درختهاي B+
جلسه سيزدهم
دستيابي به فايلهاي ترتيبي شاخصدار و درختهاي B+

دستيابي به فايل هاي ترتيبي شاخص دار و درخت هاي
دستيابي به فايل هاي ترتيبي شاخص دار و درخت هاي

ساختارهاي فايل ترتيبي انديس دار ،امکان انتخاب از ميان دو
ساختارهاي فايل ترتيبي انديس دار ،امکان انتخاب از ميان دو

مجموعه اي از رکوردها که به طور فيزيکي توسط کليدها
مجموعه اي از رکوردها که به طور فيزيکي توسط کليدها

هنگاميکه رکوردها را بلوک بندي مي کنيم ، بلوک واحد اصلي
هنگاميکه رکوردها را بلوک بندي مي کنيم ، بلوک واحد اصلي

همانند درخت هاي B ،درج رکوردهاي جديد در يک بلوک
همانند درخت هاي B ،درج رکوردهاي جديد در يک بلوک

مشکل سرريز شدن را مي توان توسط يک فرايند شکستن
مشکل سرريز شدن را مي توان توسط يک فرايند شکستن

ته ريز شدن در درخت B مي تواند منجر به
ته ريز شدن در درخت B مي تواند منجر به

مسئله اندازه بلوک به تعيين حدود (limits) اندازه بلوک تبديل
مسئله اندازه بلوک به تعيين حدود (limits) اندازه بلوک تبديل

دو شرطي که در رابطه با حد بالايي اندازه بلوک
دو شرطي که در رابطه با حد بالايي اندازه بلوک

ساختار مختلط يک شاخص B بعلاوه يک مجموعه ترتيبي که
ساختار مختلط يک شاخص B بعلاوه يک مجموعه ترتيبي که

هدف از ساختن شاخص آن است که هنگام جستجوي رکوردي
هدف از ساختن شاخص آن است که هنگام جستجوي رکوردي

محتويات شاخص فقط تا آن حد مورد علاقه ما هستند
محتويات شاخص فقط تا آن حد مورد علاقه ما هستند

با در نظر گرفتن مجموعه شاخص به عنوان يک نقشه
با در نظر گرفتن مجموعه شاخص به عنوان يک نقشه

شاخص درخت B را مجموعه شاخص مي نامند.
اين شاخص
شاخص درخت B را مجموعه شاخص مي نامند.
اين شاخص

عبارت پيشوندي ساده (simple prefix) نشانگر آن است که مجموعه
عبارت پيشوندي ساده (simple prefix) نشانگر آن است که مجموعه

اگر حذف رکوردها از مجموعه ترتيبي و اضافه کردن رکوردها
اگر حذف رکوردها از مجموعه ترتيبي و اضافه کردن رکوردها

جلسه چهاردهم
ادامه مبحث دستيابي به فايل هاي ترتيبي شاخص
جلسه چهاردهم
ادامه مبحث دستيابي به فايل هاي ترتيبي شاخص

درج و حذف رکوردها همواره در مجموعه ترتيبي رخ مي
درج و حذف رکوردها همواره در مجموعه ترتيبي رخ مي

اگر شکافتگي ،ادغام يا توزيع دوباره مورد نياز باشد ،
اگر شکافتگي ،ادغام يا توزيع دوباره مورد نياز باشد ،

پس از کامل شدن عمليات مربوط به رکورد در مجموعه
پس از کامل شدن عمليات مربوط به رکورد در مجموعه

چند دليل براي استفاده از ا ندازه بلوک مشترک
چند دليل براي استفاده از ا ندازه بلوک مشترک

علاوه بر بردار جداکننده ها ،شاخص اين جداکننده ها و
علاوه بر بردار جداکننده ها ،شاخص اين جداکننده ها و

فرايند بارگذاري بسيار سريع پيش مي رود زيرا :
۱) خروجي
فرايند بارگذاري بسيار سريع پيش مي رود زيرا :
۱) خروجي

تفاوت ميان درخت پيشوندي ساده و درخت آن است که
تفاوت ميان درخت پيشوندي ساده و درخت آن است که

هر دو نوع درخت پيشوندي ساده و درخت ، از
هر دو نوع درخت پيشوندي ساده و درخت ، از

دو عامل وجود دارد که ممکن است وضعيت را به
دو عامل وجود دارد که ممکن است وضعيت را به

درخت B ، درخت پيشوندي ساده و درخت در خصوصيات زير
درخت B ، درخت پيشوندي ساده و درخت در خصوصيات زير

ساختار درخت سه مزيت مهم ير درخت B دارد:
۱) مجموعه
ساختار درخت سه مزيت مهم ير درخت B دارد:
۱) مجموعه

درهم سازي
درهم سازي

دستيابي O(1) به فايل به اين معنا است که مهم
دستيابي O(1) به فايل به اين معنا است که مهم

تابع درهم سازي مانند يک جعبه سياه است که هرگاه
تابع درهم سازي مانند يک جعبه سياه است که هرگاه

درهم سازي را تصادفي کردن نيز مي گويند.
درهم سازي ،از اين
درهم سازي را تصادفي کردن نيز مي گويند.
درهم سازي ،از اين

درهم سازي و انديس سازي از دو جهت با هم تفاوت
درهم سازي و انديس سازي از دو جهت با هم تفاوت

جلسه پانزدهم
ادامه مبحث درهم سازي
جلسه پانزدهم
ادامه مبحث درهم سازي

اگر دو رکورد به يک مکان در فايل انتقال يابند
اگر دو رکورد به يک مکان در فايل انتقال يابند

روش ايده آل مقابله با برخوردها اين است که بتوان
روش ايده آل مقابله با برخوردها اين است که بتوان

چندين راه مختلف براي کاهش تعداد برخوردها وجود دارد که
چندين راه مختلف براي کاهش تعداد برخوردها وجود دارد که

به آدرس هايي که مي توانند چندين رکورد را نگهداري
به آدرس هايي که مي توانند چندين رکورد را نگهداري

در اين فصل يک الگوريتم درهم سازي ساده نوشته تا
در اين فصل يک الگوريتم درهم سازي ساده نوشته تا

در حالت ايده آل تابع درهم سازي ،رکوردها را به
در حالت ايده آل تابع درهم سازي ،رکوردها را به


بعضي از روشهايي که به صورت بالقوه بهتر از
بعضي از روشهايي که به صورت بالقوه بهتر از

توزيع پوآسون ابزاري رياضي را براي بررسي اثرات توزيع تصادفي
توزيع پوآسون ابزاري رياضي را براي بررسي اثرات توزيع تصادفي

گرچه مي توانيم تعداد برخوردها را کم کنيم ،بايد ابزارهايي
گرچه مي توانيم تعداد برخوردها را کم کنيم ،بايد ابزارهايي

اگر جستجو براي يافتن رکورد آغاز شود اما رکورد در
اگر جستجو براي يافتن رکورد آغاز شود اما رکورد در

منظور از طول جستجو ،تعداد دستيابي هاي لازم براي بازيابي
منظور از طول جستجو ،تعداد دستيابي هاي لازم براي بازيابي
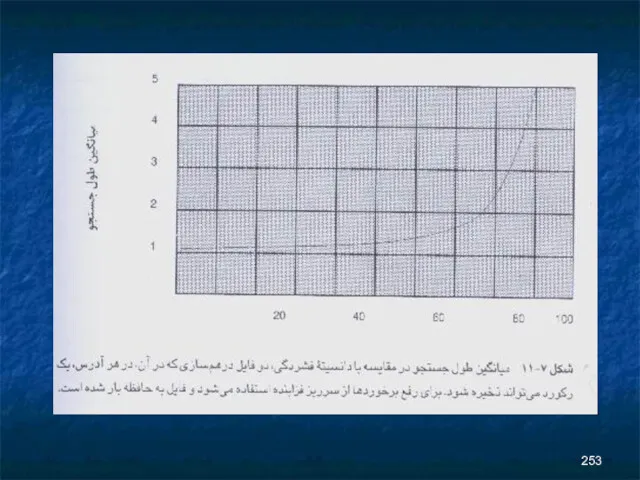

هنگاميکه قرار است که يک رکورد ذخيره يا بازيابي شود
هنگاميکه قرار است که يک رکورد ذخيره يا بازيابي شود

براي محاسبه دانسيته فشردگي فايل بايد هم به تعداد آدرس
براي محاسبه دانسيته فشردگي فايل بايد هم به تعداد آدرس

جلسه شانزدهم
ادامه مبحث درهم سازي
درهم سازي قابل توسعه
جلسه شانزدهم
ادامه مبحث درهم سازي
درهم سازي قابل توسعه

به عنوان يک اصل معمولاً استفاده از باکت هاي بزرگتر
به عنوان يک اصل معمولاً استفاده از باکت هاي بزرگتر

فايلهاي درهم سازي به دو روش با فايلهايي که تا
فايلهاي درهم سازي به دو روش با فايلهايي که تا

تنها تفاوت بين فايل هايي که باکت دارند و فايل
تنها تفاوت بين فايل هايي که باکت دارند و فايل

به دو دليل حذف کردن يک رکورد از فايل درهم
به دو دليل حذف کردن يک رکورد از فايل درهم

خوبي علائم ويژه اين است که ،دو مشکلي را که
خوبي علائم ويژه اين است که ،دو مشکلي را که

چون رکوردهاي سرريز ،تأثير بسزايي در کارايي دارند تکنيک هاي
چون رکوردهاي سرريز ،تأثير بسزايي در کارايي دارند تکنيک هاي

درهم سازي قابل توسعه
درهم سازي قابل توسعه

ويژگي مهم در درخت AVL و درخت B آن است
ويژگي مهم در درخت AVL و درخت B آن است

ايده کليدي در فرايند درهم سازي قابل توسعه ،ترکيب کردن
ايده کليدي در فرايند درهم سازي قابل توسعه ،ترکيب کردن

اگر رکوردي اضافه کنيم وجايي براي آن در باکت وجود
اگر رکوردي اضافه کنيم وجايي براي آن در باکت وجود

هدف از سيستم درهم سازي قابل توسعه ،يافتن راهي براي
هدف از سيستم درهم سازي قابل توسعه ،يافتن راهي براي

عمليات اصلي روي باکت ها دقيقاً همانند عمليات رکوردهاي شاخص
عمليات اصلي روي باکت ها دقيقاً همانند عمليات رکوردهاي شاخص

حذف ،عکس فرايند اضافه کردن است ،با ذکر اين نکته
حذف ،عکس فرايند اضافه کردن است ،با ذکر اين نکته

عمل تنزل شامل تخصيص فضا به آرايه جديدي از آدرس
عمل تنزل شامل تخصيص فضا به آرايه جديدي از آدرس

درهم سازي پويا و درهم سازي قابل توسعه از نظر
درهم سازي پويا و درهم سازي قابل توسعه از نظر
 Сущность программной инженерии. Программное обеспечение. Свойства ПО (лекция 1)
Сущность программной инженерии. Программное обеспечение. Свойства ПО (лекция 1) Различные подходы к измерению количества информации
Различные подходы к измерению количества информации Урок по теме: Рисование линии в среде программирования Basic
Урок по теме: Рисование линии в среде программирования Basic Операторы цикла
Операторы цикла Презентация Условный оператор по программированию.
Презентация Условный оператор по программированию. Информация. Понятие. Свойства. Виды. Информационные процессы. Измерение
Информация. Понятие. Свойства. Виды. Информационные процессы. Измерение Медичні та фармацевтичні інформаційні системи
Медичні та фармацевтичні інформаційні системи Дидактическая игра Сравниваем предметы наложением
Дидактическая игра Сравниваем предметы наложением Передача информации. Компьютерные сети
Передача информации. Компьютерные сети Информационное моделирование: основные направления и перспективы развития
Информационное моделирование: основные направления и перспективы развития QR-коды. Их создание и применение
QR-коды. Их создание и применение Introduction to Databases
Introduction to Databases Инструкция по выполнению домашних заданий учащимися при дистанционном обучении
Инструкция по выполнению домашних заданий учащимися при дистанционном обучении Позиционирование и продвижение в соцсетях
Позиционирование и продвижение в соцсетях Смешанные системы счисления
Смешанные системы счисления Как создать анимацию в PowerPoint
Как создать анимацию в PowerPoint المحاضرة الثانية. مفهوم علم المعلومات
المحاضرة الثانية. مفهوم علم المعلومات Создание презентации, состоящей из нескольких слайдов. Урок №6
Создание презентации, состоящей из нескольких слайдов. Урок №6 Інформаційні технології
Інформаційні технології Онлайн конференции, анкетирование, дистанционные курсы, интернет-олимпиады, компьютерное тестирование
Онлайн конференции, анкетирование, дистанционные курсы, интернет-олимпиады, компьютерное тестирование Кодирование звуковой информации
Кодирование звуковой информации Своя игра
Своя игра Графический редактор Paint. Инструменты
Графический редактор Paint. Инструменты CodeEvening - CPMD. Rest Api
CodeEvening - CPMD. Rest Api Антивирус Касперского
Антивирус Касперского Стандартные предикаты SWI Prolog
Стандартные предикаты SWI Prolog Технология баз данных в системах поддержки принятия решений
Технология баз данных в системах поддержки принятия решений Информационное обеспечение САПР
Информационное обеспечение САПР