- Технология баз данных в системах поддержки принятия решений

Содержание
- 2. Вопросы Компоненты систем поддержки принятия решений. Структура хранилища данных. Материализованные представления. Оперативные аналитические приложения.
- 3. Системы поддержки принятия решений – основа ИТ-инфрас-труктуры различных компаний, поскольку эти системы дают возможность преобразовывать обширную
- 5. 1 Компоненты систем поддержки принятия решений Система поддержки принятия решений – сложная структу-ра с многочисленными компонентами.
- 7. 1.1 Хранилища данных Хранилища данных содержат информацию, собранную из нескольких оперативных баз данных. Хранилища, как правило,
- 8. Поскольку конструирование хранилища данных – сложный процесс, который может занять несколько лет, некоторые организации вместо этого
- 9. 2 Структура хранилища данных Большинство хранилищ используют технологию реля-ционных баз данных, поскольку она предлагает наде-жные, проверенные
- 10. 2.1 Логическая архитектура базы данных В архитектуре, основанной на схеме «звезда», база данных состоит из таблицы
- 11. 2.2 Физическая архитектура базы данных Системы баз данных используют избыточные структуры, такие как индексы и материализованные
- 12. 2.3 Индексные структуры Методы обработки запросов, которые используют операции пересечения и объединения индексов, полезны при ответе
- 13. 3 Материализованные представления Многие хранилища данных используют запросы, которые требуют сводных данных и потому работают с
- 14. 4 Оперативные аналитические приложения
- 15. 4.1 Концептуальная модель данных Многомерная модель, изображенная на рисунке, ис-пользует численные параметры как объекты своего анализа.
- 16. Каждый численный параметр в концептуальной модели дан-ных зависит от измерений, которые описывают сущности в транзакции. Например,
- 18. Скачать презентацию

Вопросы
Компоненты систем поддержки принятия решений.
Структура хранилища данных.
Материализованные представления.
Оперативные аналитические приложения.
Вопросы
Компоненты систем поддержки принятия решений.
Структура хранилища данных.
Материализованные представления.
Оперативные аналитические приложения.

Системы поддержки принятия решений – основа ИТ-инфрас-труктуры различных компаний, поскольку эти
Системы поддержки принятия решений – основа ИТ-инфрас-труктуры различных компаний, поскольку эти
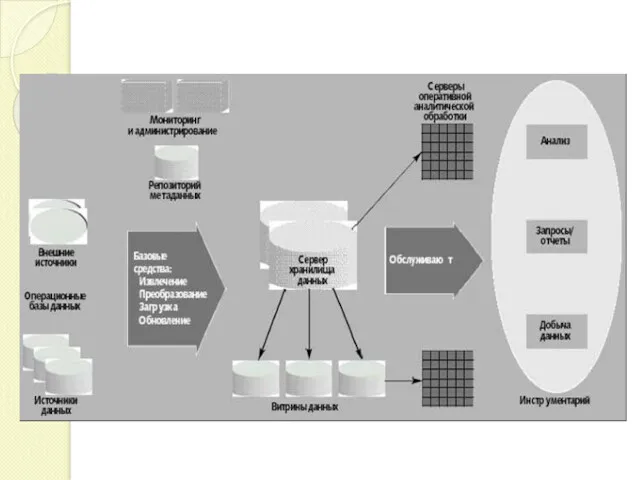

1 Компоненты систем поддержки принятия решений
Система поддержки принятия решений – сложная
1 Компоненты систем поддержки принятия решений
Система поддержки принятия решений – сложная


1.1 Хранилища данных
Хранилища данных содержат информацию, собранную из нескольких оперативных баз
1.1 Хранилища данных
Хранилища данных содержат информацию, собранную из нескольких оперативных баз

Поскольку конструирование хранилища данных – сложный процесс, который может занять несколько
Поскольку конструирование хранилища данных – сложный процесс, который может занять несколько

2 Структура хранилища данных
Большинство хранилищ используют технологию реля-ционных баз данных, поскольку
2 Структура хранилища данных
Большинство хранилищ используют технологию реля-ционных баз данных, поскольку

2.1 Логическая архитектура базы данных
В архитектуре, основанной на схеме «звезда», база
2.1 Логическая архитектура базы данных
В архитектуре, основанной на схеме «звезда», база

2.2 Физическая архитектура базы данных
Системы баз данных используют избыточные структуры, такие
2.2 Физическая архитектура базы данных
Системы баз данных используют избыточные структуры, такие

2.3 Индексные структуры
Методы обработки запросов, которые используют операции пересечения и объединения
2.3 Индексные структуры
Методы обработки запросов, которые используют операции пересечения и объединения

3 Материализованные представления
Многие хранилища данных используют запросы, которые требуют сводных данных
3 Материализованные представления
Многие хранилища данных используют запросы, которые требуют сводных данных

4 Оперативные аналитические приложения
4 Оперативные аналитические приложения
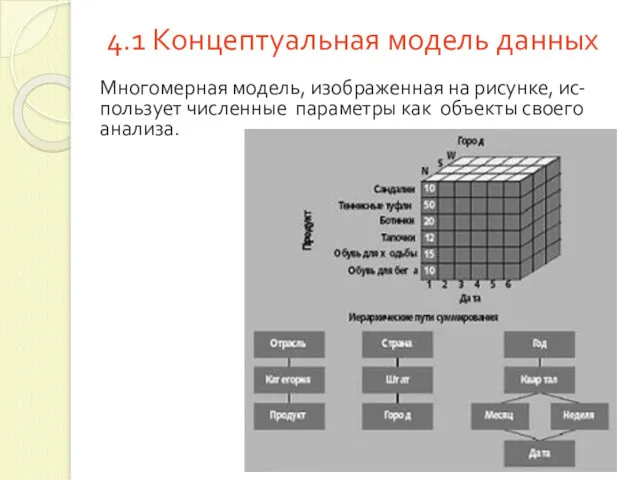
4.1 Концептуальная модель данных
Многомерная модель, изображенная на рисунке, ис-пользует численные параметры
4.1 Концептуальная модель данных
Многомерная модель, изображенная на рисунке, ис-пользует численные параметры

Каждый численный параметр в концептуальной модели дан-ных зависит от измерений, которые
Каждый численный параметр в концептуальной модели дан-ных зависит от измерений, которые
 Java Script
Java Script Формирование изображений на экране монитора
Формирование изображений на экране монитора 3DMask. Разработка приложения для мобильных устройств
3DMask. Разработка приложения для мобильных устройств Презентация к уроку информатики на тему: Правила поведения в компьютерном классе.
Презентация к уроку информатики на тему: Правила поведения в компьютерном классе. Технология и процесс разработки ПО. Лекция 6
Технология и процесс разработки ПО. Лекция 6 Виды писем. Порядок отправления писем различных видов
Виды писем. Порядок отправления писем различных видов Решение задач. Выполнение алгоритмов для исполнителя Робот.
Решение задач. Выполнение алгоритмов для исполнителя Робот. Библиографическое описание документов как одно из условий повышения цитируемости авторов. Оформление списков литературы и ссылок
Библиографическое описание документов как одно из условий повышения цитируемости авторов. Оформление списков литературы и ссылок Моделирование как метод познания. Модель и Моделирование
Моделирование как метод познания. Модель и Моделирование Подпрограммы – параметры других подпрограмм. Указатели на функции в Си. Лекция 5
Подпрограммы – параметры других подпрограмм. Указатели на функции в Си. Лекция 5 CASE – технологии разработки программных систем
CASE – технологии разработки программных систем Понятие алгоритма и его свойства
Понятие алгоритма и его свойства МЕТОДИЧЕСКАЯ РАЗРАБОТКА к занятию по теме Реализация творческого проекта на занятиях компьютерной графики
МЕТОДИЧЕСКАЯ РАЗРАБОТКА к занятию по теме Реализация творческого проекта на занятиях компьютерной графики Складання та виконання алгоритмів з повтореннями та розгалуженнями для опрацювання величин
Складання та виконання алгоритмів з повтореннями та розгалуженнями для опрацювання величин 20230928_2-5_sistemy_schisleniya
20230928_2-5_sistemy_schisleniya ООП. Инкапсуляция, классы и объекты
ООП. Инкапсуляция, классы и объекты Информатика как наука
Информатика как наука Introduction to C++
Introduction to C++ Устройства ввода и вывода информации
Устройства ввода и вывода информации Автоматизация учета работы ресторана в системе 1С: Предприятие 7.7
Автоматизация учета работы ресторана в системе 1С: Предприятие 7.7 Основы программирования на языку С++. Лекция 2
Основы программирования на языку С++. Лекция 2 Cyber-Safety
Cyber-Safety Спам и защита от него
Спам и защита от него Розробка системи автоматизованої перевірки (тестування) знань курсантів
Розробка системи автоматизованої перевірки (тестування) знань курсантів Текстовый и символьный типы данных
Текстовый и символьный типы данных Розробка мобільного додатку на базі Android для підрахунку кількості кроків
Розробка мобільного додатку на базі Android для підрахунку кількості кроків Встраивание музыки в документы
Встраивание музыки в документы Памятка волонтеру группы в Квартале
Памятка волонтеру группы в Квартале