- 5_C__Dinamicheskie_struktury_dannykh (1)

Содержание
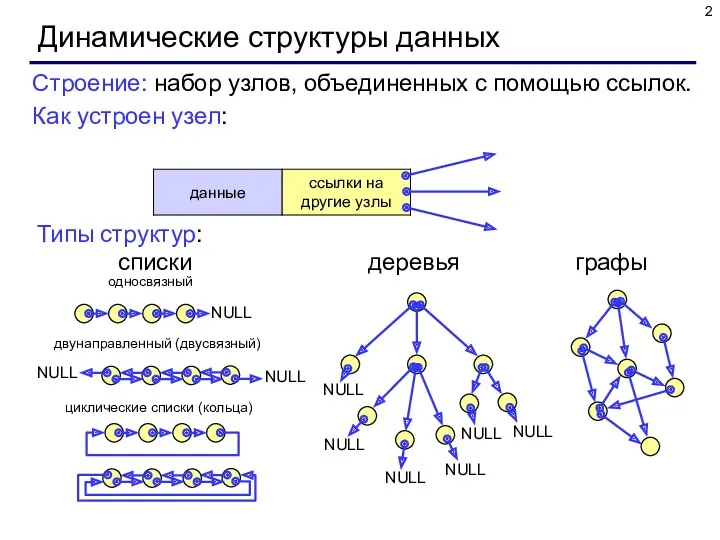
- 2. Динамические структуры данных Строение: набор узлов, объединенных с помощью ссылок. Как устроен узел: Типы структур: списки
- 3. Когда нужны списки? Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать в другой файл в
- 4. Что такое список: пустая структура – это список; список – это начальный узел (голова) и связанный
- 5. Что нужно уметь делать со списком? Создать новый узел. Добавить узел: в начало списка; в конец
- 6. Создание узла PNode CreateNode ( char NewWord[] ) { PNode NewNode = new Node; strcpy(NewNode->word, NewWord);
- 7. Добавление узла в начало списка 1) Установить ссылку нового узла на голову списка: NewNode->next = Head;
- 8. Добавление узла после заданного 1) Установить ссылку нового узла на узел, следующий за p: NewNode->next =
- 9. Задача: сделать что-нибудь хорошее с каждым элементом списка. Алгоритм: установить вспомогательный указатель q на голову списка;
- 10. Добавление узла в конец списка Задача: добавить новый узел в конец списка. Алгоритм: найти последний узел
- 11. Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя! Решение: найти предыдущий узел q (проход
- 12. Добавление узла перед заданным (II) Задача: вставить узел перед заданным без поиска предыдущего. Алгоритм: поменять местами
- 13. Поиск слова в списке Задача: найти в списке заданное слово или определить, что его нет. Функция
- 14. Куда вставить новое слово? Задача: найти узел, перед которым нужно вставить, заданное слово, так чтобы в
- 15. Удаление узла void DeleteNode ( PNode &Head, PNode p ) { PNode q = Head; if
- 16. Алфавитно-частотный словарь Алгоритм: открыть файл на чтение; прочитать слово: если файл закончился (n!=1), то перейти к
- 17. Двусвязные списки Структура узла: struct Node { char word[40]; // слово int count; // счетчик повторений
- 18. Стеки, очереди, деки Лекция 5.2
- 19. Стек Стек – это линейная структура данных, в которой добавление и удаление элементов возможно только с
- 20. Пример задачи Задача: вводится символьная строка, в которой записано выражение со скобками трех типов: [], {}
- 21. Решение задачи со скобками Алгоритм: в начале стек пуст; в цикле просматриваем все символы строки по
- 22. Реализация стека (массив) Структура-стек: const MAXSIZE = 100; struct Stack { char data[MAXSIZE]; // стек на
- 23. Реализация стека (массив) char Pop ( Stack &S ) { if ( S.size == 0 )
- 24. Программа void main() { char br1[3] = { '(', '[', '{' }; char br2[3] = {
- 25. Обработка строки (основной цикл) for ( i = 0; i { for ( k = 0;
- 26. Реализация стека (список) Добавление элемента: Структура узла: struct Node { char data; Node *next; }; typedef
- 27. Реализация стека (список) Снятие элемента с вершины: char Pop (PNode &Head) { char x; PNode q
- 28. Вычисление арифметических выражений a b + c d + 1 - / Как вычислять автоматически: Инфиксная
- 29. Вычисление выражений Постфиксная форма: a b + c d + 1 - / Алгоритм: взять очередной
- 30. Системный стек (Windows – 1 Мб) Используется для размещения локальных переменных; хранения адресов возврата (по которым
- 31. Очередь Очередь – это линейная структура данных, в которой добавление элементов возможно только с одного конца
- 32. Реализация очереди (массив) самый простой способ нужно заранее выделить массив; при выборке из очереди нужно сдвигать
- 33. Реализация очереди (кольцевой массив)
- 34. Реализация очереди (кольцевой массив) В очереди 1 элемент: Очередь пуста: Очередь полна: Head == Tail +
- 35. Реализация очереди (кольцевой массив) const MAXSIZE = 100; struct Queue { int data[MAXSIZE]; int head, tail;
- 36. Реализация очереди (кольцевой массив) Выборка из очереди: int Pop ( Queue &Q ) { int temp;
- 37. Реализация очереди (списки) struct Node { int data; Node *next; }; typedef Node *PNode; struct Queue
- 38. Реализация очереди (списки) void PushTail ( Queue &Q, int x ) { PNode NewNode; NewNode =
- 39. Реализация очереди (списки) int Pop ( Queue &Q ) { PNode top = Q.Head; int x;
- 40. Дек Дек (deque = double ended queue, очередь с двумя концами) – это линейная структура данных,
- 41. Деревья Лекция 5.3
- 42. Деревья
- 43. Деревья Дерево – это структура данных, состоящая из узлов и соединяющих их направленных ребер (дуг), причем
- 44. Деревья Предок узла x – это узел, из которого существует путь по стрелкам в узел x.
- 45. Дерево – рекурсивная структура данных Рекурсивное определение: Пустая структура – это дерево. Дерево – это корень
- 46. Двоичные деревья Структура узла: struct Node { int data; // полезные данные Node *left, *right; //
- 47. Двоичные деревья поиска Слева от каждого узла находятся узлы с меньшими ключами, а справа – с
- 48. Двоичные деревья поиска Поиск в массиве (N элементов): При каждом сравнении отбрасывается 1 элемент. Число сравнений
- 49. Реализация алгоритма поиска //--------------------------------------- // Функция Search – поиск по дереву // Вход: Tree - адрес
- 50. Как построить дерево поиска? //--------------------------------------------- // Функция AddToTree – добавить элемент к дереву // Вход: Tree
- 51. Обход дерева Обход дерева – это перечисление всех узлов в определенном порядке. Обход ЛКП («левый –
- 52. Обход дерева – реализация //--------------------------------------------- // Функция LKP – обход дерева в порядке ЛКП // (левый
- 53. Разбор арифметических выражений a b + c d + 1 - / Как вычислять автоматически: Инфиксная
- 54. Вычисление выражений Постфиксная форма: a b + c d + 1 - / Алгоритм: взять очередной
- 55. Вычисление выражений Задача: в символьной строке записано правильное арифметическое выражение, которое может содержать только однозначные числа
- 56. Построение дерева Алгоритм: если first=last (остался один символ – число), то создать новый узел и записать
- 57. Как найти последнюю операцию? Порядок выполнения операций умножение и деление; сложение и вычитание. Приоритет (старшинство) –
- 58. Приоритет операции //-------------------------------------------- // Функция Priority – приоритет операции // Вход: символ операции // Выход: приоритет
- 59. Номер последней операции //-------------------------------------------- // Функция LastOperation – номер последней операции // Вход: строка, номера первого
- 60. Построение дерева Структура узла struct Node { char data; Node *left, *right; }; typedef Node *PNode;
- 61. Построение дерева //-------------------------------------------- // Функция MakeTree – построение дерева // Вход: строка, номера первого и последнего
- 62. Вычисление выражения по дереву //-------------------------------------------- // Функция CalcTree – вычисление по дереву // Вход: адрес дерева
- 63. Основная программа //-------------------------------------------- // Основная программа: ввод и вычисление // выражения с помощью дерева //-------------------------------------------- void
- 64. Дерево игры Задача. Перед двумя игроками лежат две кучки камней, в первой из которых 3, а
- 65. Дерево игры 3, 2 игрок 1 3, 6 27, 2 3, 18 3, 3 4, 2
- 66. Графы Лекция 5.4
- 67. Определения Граф – это набор вершин (узлов) и соединяющих их ребер (дуг). Направленный граф (ориентированный, орграф)
- 68. Определения Связный граф – это граф, в котором существует цепь между каждой парой вершин. k-cвязный граф
- 69. Описание графа Матрица смежности – это матрица, элемент M[i][j] которой равен 1, если существует ребро из
- 70. Как обнаружить цепи и циклы? Задача: определить, существует ли цепь длины k из вершины i в
- 71. Как обнаружить цепи и циклы? M2 = M ⊗ M Логическое умножение матрицы на себя: матрица
- 72. Как обнаружить цепи и циклы? M3 = M2 ⊗ M Матрица путей длины 3: M3 =
- 73. Весовая матрица Весовая матрица – это матрица, элемент W[i][j] которой равен весу ребра из вершины i
- 74. Задача Прима-Краскала Задача: соединить N городов телефонной сетью так, чтобы длина телефонных линий была минимальная. Та
- 75. Жадный алгоритм Жадный алгоритм – это многошаговый алгоритм, в котором на каждом шаге принимается решение, лучшее
- 76. Реализация алгоритма Прима-Краскала Проблема: как проверить, что 1) ребро не выбрано, и 2) ребро не образует
- 77. Реализация алгоритма Прима-Краскала Структура «ребро»: struct rebro { int i, j; // номера вершин }; const
- 78. Реализация алгоритма Прима-Краскала for ( k = 0; k min = 30000; // большое число for
- 79. Сложность алгоритма Основной цикл: O(N3) for ( k = 0; k ... for ( i =
- 80. Кратчайшие пути (алгоритм Дейкстры) Задача: задана сеть дорог между городами, часть которых могут иметь одностороннее движение.
- 81. Алгоритм Дейкстры
- 82. Реализация алгоритма Дейкстры Массивы: массив a, такой что a[i]=1, если вершина уже рассмотрена, и a[i]=0, если
- 83. Реализация алгоритма Дейкстры Основной цикл: если все вершины рассмотрены, то стоп. среди всех нерассмотренных вершин (a[i]=0)
- 84. Реализация алгоритма Дейкстры Шаг 2: Шаг 3:
- 85. Как вывести маршрут? Результат работа алгоритма Дейкстры: длины путей Маршрут из вершины 0 в вершину 4:
- 86. Алгоритм Флойда-Уоршелла Задача: задана сеть дорог между городами, часть которых могут иметь одностороннее движение. Найти все
- 87. Алгоритм Флойда-Уоршелла Версия с запоминанием маршрута: for ( i = 0; i for ( j =
- 88. Задача коммивояжера Задача коммивояжера. Коммивояжер (бродячий торговец) должен выйти из первого города и, посетив по разу
- 90. Скачать презентацию
Динамические структуры данных
Строение: набор узлов, объединенных с помощью ссылок.
Как устроен узел:
Типы
Динамические структуры данных
Строение: набор узлов, объединенных с помощью ссылок.
Как устроен узел:
Типы

Когда нужны списки?
Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать
Когда нужны списки?
Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать
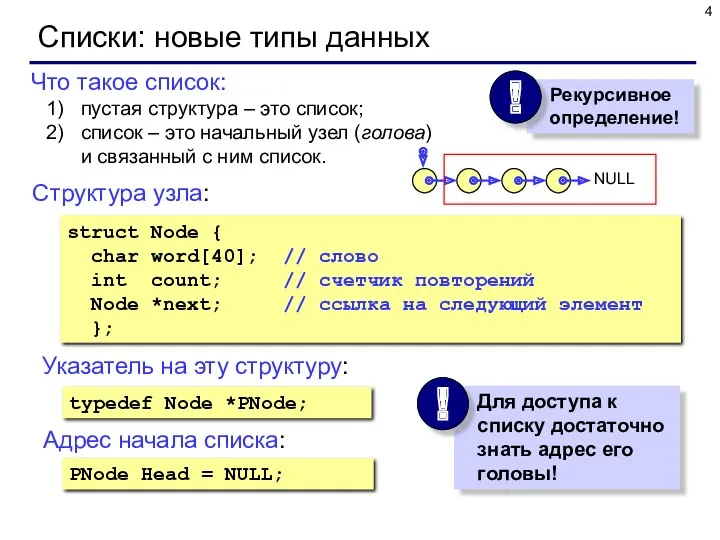
Что такое список:
пустая структура – это список;
список – это начальный узел
Что такое список:
пустая структура – это список;
список – это начальный узел

Что нужно уметь делать со списком?
Создать новый узел.
Добавить узел:
в начало списка;
в
Что нужно уметь делать со списком?
Создать новый узел.
Добавить узел:
в начало списка;
в
![Создание узла PNode CreateNode ( char NewWord[] ) { PNode](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/607719/slide-5.jpg)
Создание узла
PNode CreateNode ( char NewWord[] )
{
PNode NewNode = new
Создание узла
PNode CreateNode ( char NewWord[] )
{
PNode NewNode = new
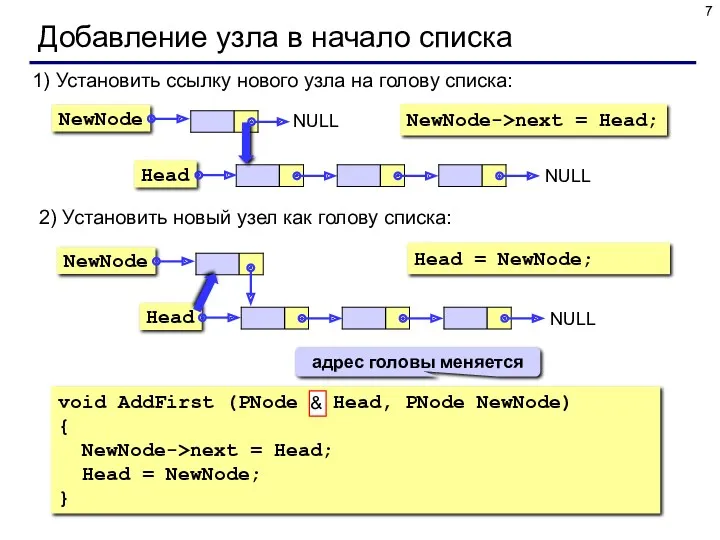
Добавление узла в начало списка
1) Установить ссылку нового узла на голову
Добавление узла в начало списка
1) Установить ссылку нового узла на голову
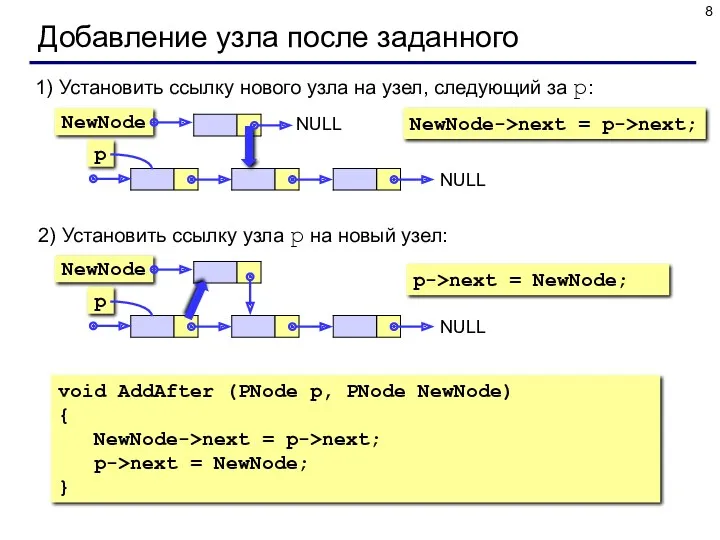
Добавление узла после заданного
1) Установить ссылку нового узла на узел, следующий
Добавление узла после заданного
1) Установить ссылку нового узла на узел, следующий
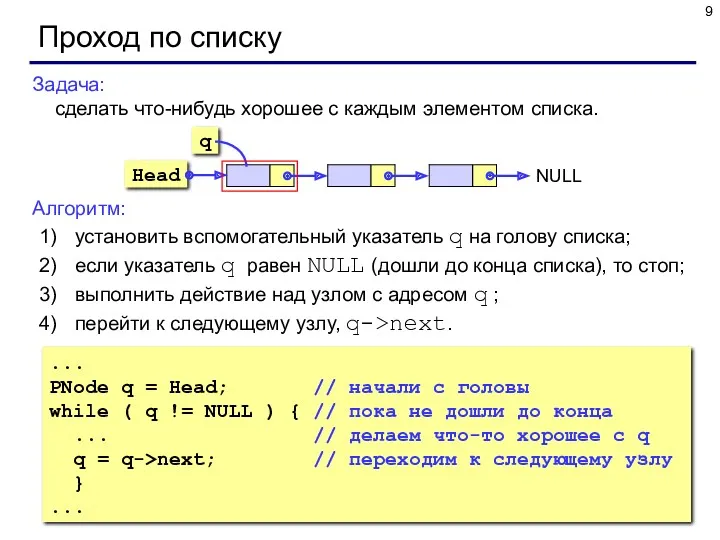
Задача:
сделать что-нибудь хорошее с каждым элементом списка.
Алгоритм:
установить вспомогательный указатель q
Задача:
сделать что-нибудь хорошее с каждым элементом списка.
Алгоритм:
установить вспомогательный указатель q

Добавление узла в конец списка
Задача: добавить новый узел в конец списка.
Алгоритм:
найти
Добавление узла в конец списка
Задача: добавить новый узел в конец списка.
Алгоритм:
найти
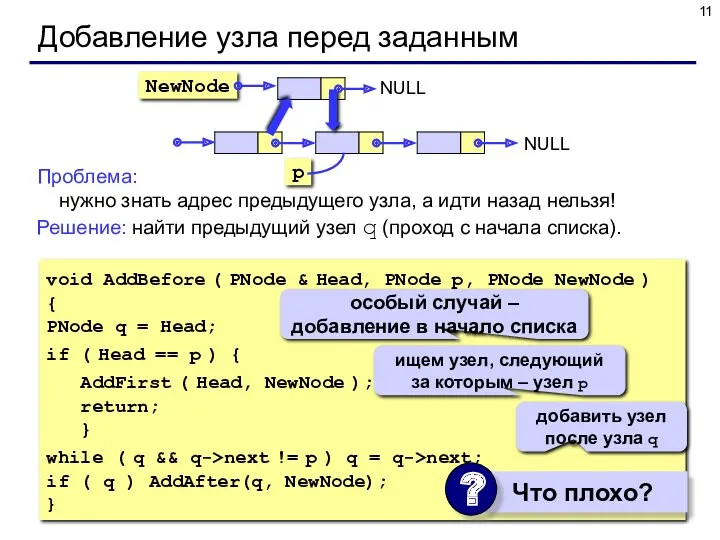
Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя!
Решение: найти
Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя!
Решение: найти
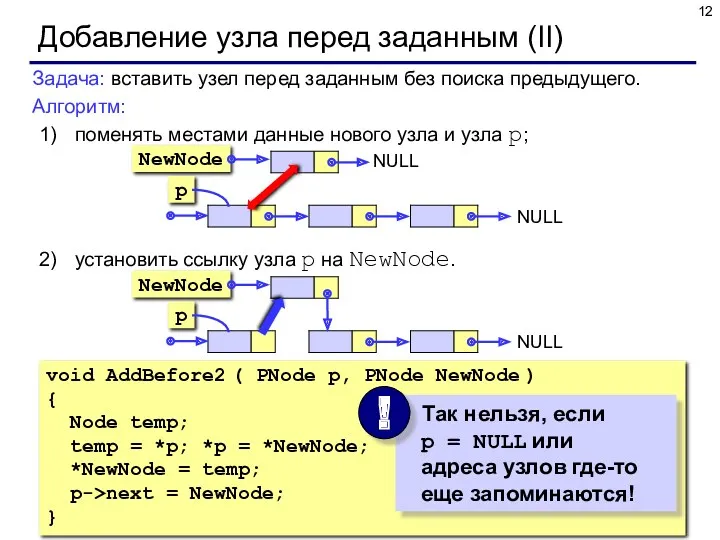
Добавление узла перед заданным (II)
Задача: вставить узел перед заданным без поиска
Добавление узла перед заданным (II)
Задача: вставить узел перед заданным без поиска

Поиск слова в списке
Задача:
найти в списке заданное слово или определить,
Поиск слова в списке
Задача: найти в списке заданное слово или определить,

Куда вставить новое слово?
Задача:
найти узел, перед которым нужно вставить, заданное
Куда вставить новое слово?
Задача: найти узел, перед которым нужно вставить, заданное
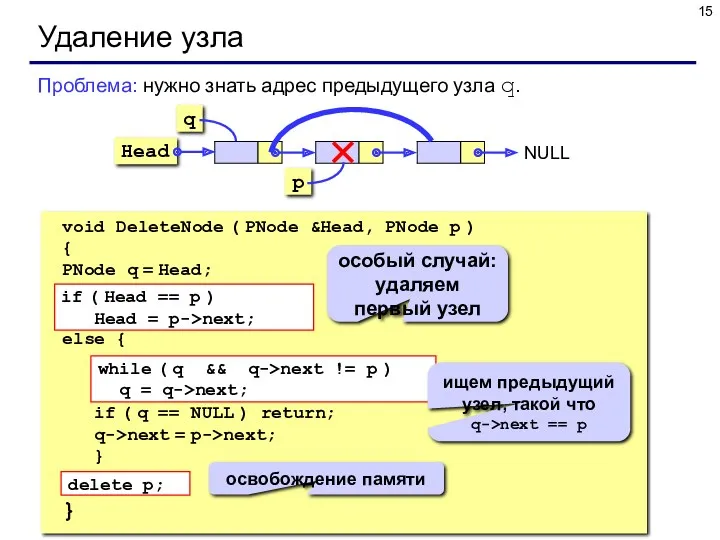
Удаление узла
void DeleteNode ( PNode &Head, PNode p )
{
PNode q =
Удаление узла
void DeleteNode ( PNode &Head, PNode p )
{
PNode q =

Алфавитно-частотный словарь
Алгоритм:
открыть файл на чтение;
прочитать слово:
если файл закончился (n!=1), то перейти
Алфавитно-частотный словарь
Алгоритм:
открыть файл на чтение;
прочитать слово:
если файл закончился (n!=1), то перейти
![Двусвязные списки Структура узла: struct Node { char word[40]; //](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/607719/slide-16.jpg)
Двусвязные списки
Структура узла:
struct Node {
char word[40]; // слово
int count;
Двусвязные списки
Структура узла:
struct Node {
char word[40]; // слово
int count;

Стеки, очереди, деки
Лекция 5.2
Стеки, очереди, деки
Лекция 5.2

Стек
Стек – это линейная структура данных, в которой добавление и удаление
Стек
Стек – это линейная структура данных, в которой добавление и удаление
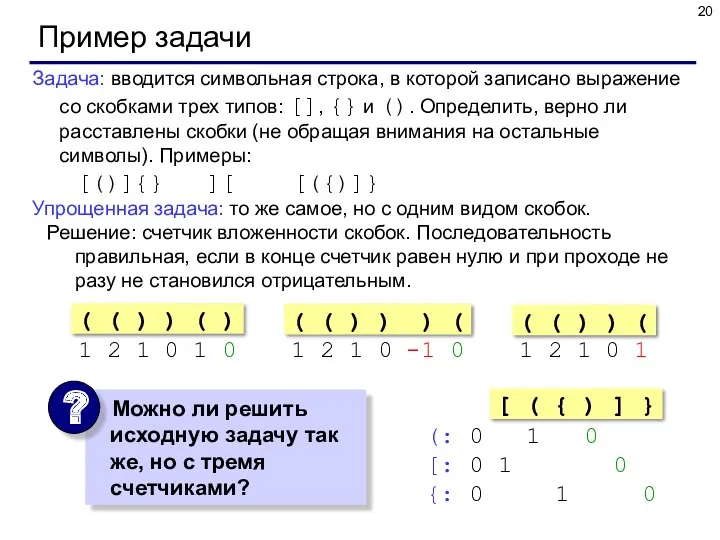
Пример задачи
Задача: вводится символьная строка, в которой записано выражение со скобками
Пример задачи
Задача: вводится символьная строка, в которой записано выражение со скобками
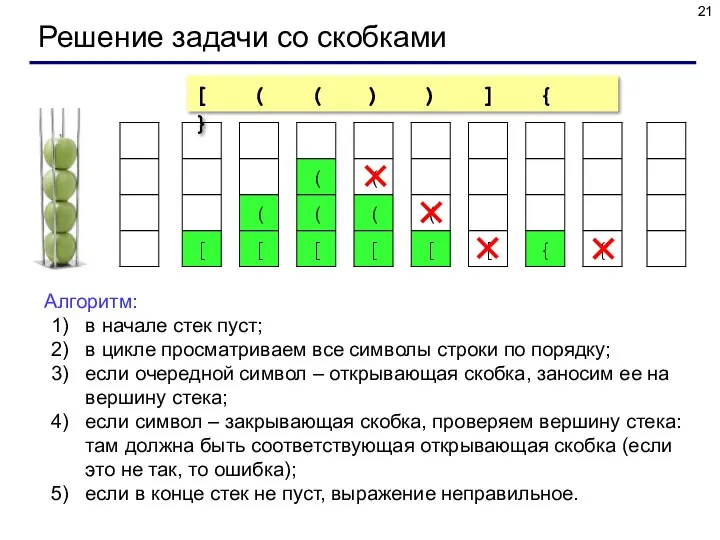
Решение задачи со скобками
Алгоритм:
в начале стек пуст;
в цикле просматриваем все символы
Решение задачи со скобками
Алгоритм:
в начале стек пуст;
в цикле просматриваем все символы

Реализация стека (массив)
Структура-стек:
const MAXSIZE = 100;
struct Stack {
char data[MAXSIZE]; //
Реализация стека (массив)
Структура-стек:
const MAXSIZE = 100;
struct Stack {
char data[MAXSIZE]; //

Реализация стека (массив)
char Pop ( Stack &S )
{
if ( S.size ==
Реализация стека (массив)
char Pop ( Stack &S )
{
if ( S.size ==
![Программа void main() { char br1[3] = { '(', '[',](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/607719/slide-23.jpg)
Программа
void main()
{
char br1[3] = { '(', '[', '{' };
char
Программа
void main()
{
char br1[3] = { '(', '[', '{' };
char

Обработка строки (основной цикл)
for ( i = 0; i < strlen(s);
Обработка строки (основной цикл)
for ( i = 0; i < strlen(s);

Реализация стека (список)
Добавление элемента:
Структура узла:
struct Node {
char data;
Node *next;
};
typedef
Реализация стека (список)
Добавление элемента:
Структура узла:
struct Node {
char data;
Node *next;
};
typedef

Реализация стека (список)
Снятие элемента с вершины:
char Pop (PNode &Head) {
char
Реализация стека (список)
Снятие элемента с вершины:
char Pop (PNode &Head) {
char

Вычисление арифметических выражений
a b + c d + 1 - /
Как
Вычисление арифметических выражений
a b + c d + 1 - /
Как
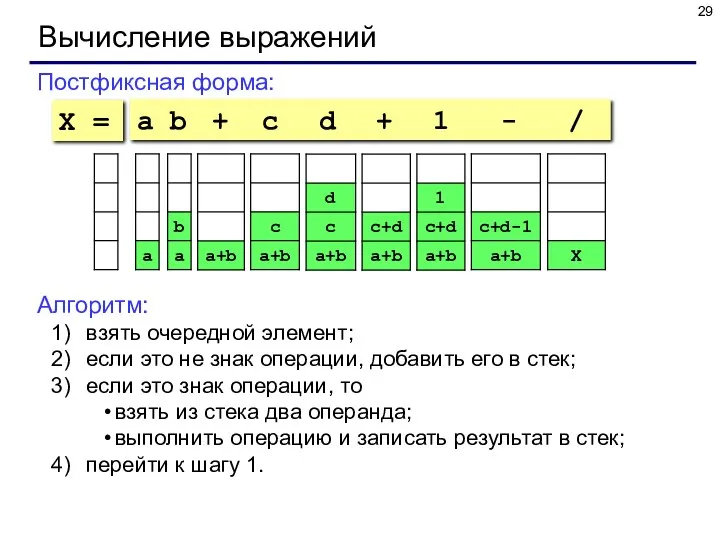
Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /
Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /

Системный стек (Windows – 1 Мб)
Используется для
размещения локальных переменных;
хранения адресов
Системный стек (Windows – 1 Мб)
Используется для
размещения локальных переменных;
хранения адресов

Очередь
Очередь – это линейная структура данных, в которой
добавление элементов возможно
Очередь
Очередь – это линейная структура данных, в которой добавление элементов возможно
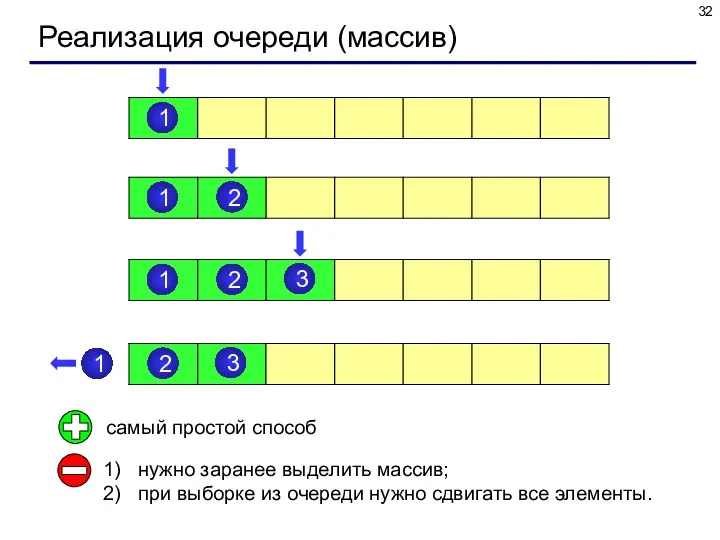
Реализация очереди (массив)
самый простой способ
нужно заранее выделить массив;
при выборке из очереди
Реализация очереди (массив)
самый простой способ
нужно заранее выделить массив;
при выборке из очереди
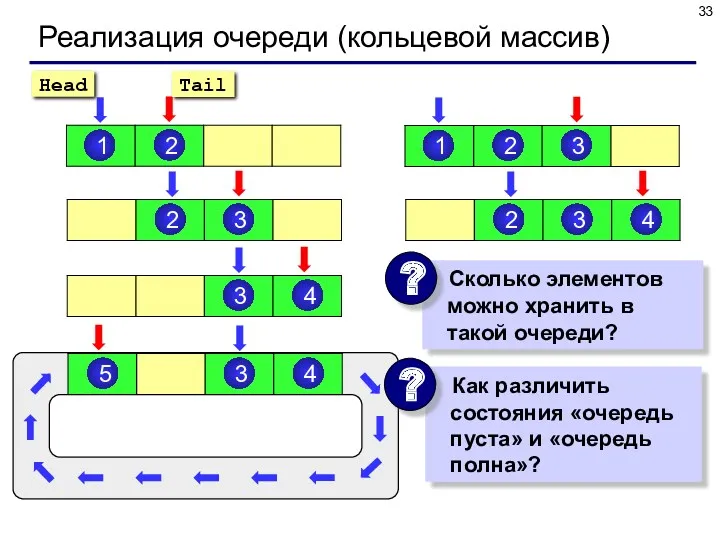
Реализация очереди (кольцевой массив)
Реализация очереди (кольцевой массив)
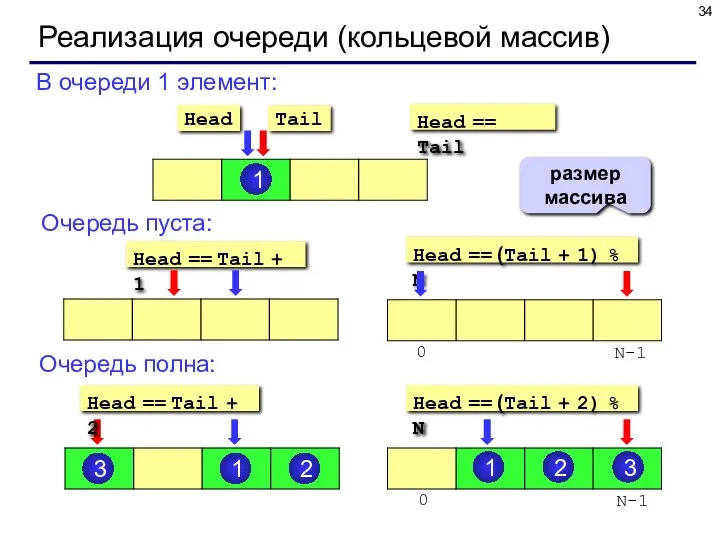
Реализация очереди (кольцевой массив)
В очереди 1 элемент:
Очередь пуста:
Очередь полна:
Head == Tail
Реализация очереди (кольцевой массив)
В очереди 1 элемент:
Очередь пуста:
Очередь полна:
Head == Tail
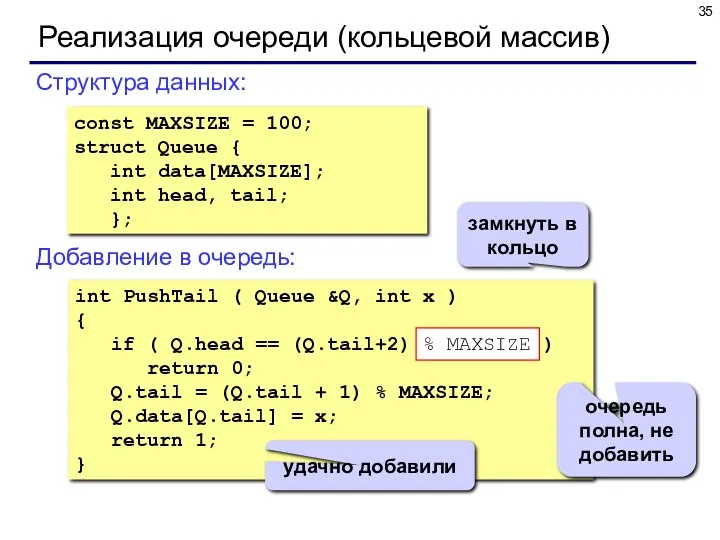
Реализация очереди (кольцевой массив)
const MAXSIZE = 100;
struct Queue {
int data[MAXSIZE];
Реализация очереди (кольцевой массив)
const MAXSIZE = 100;
struct Queue {
int data[MAXSIZE];
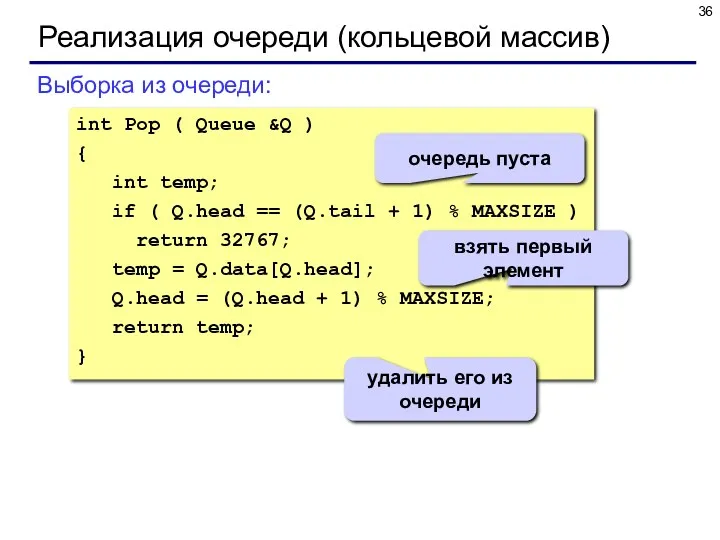
Реализация очереди (кольцевой массив)
Выборка из очереди:
int Pop ( Queue &Q )
{
Реализация очереди (кольцевой массив)
Выборка из очереди:
int Pop ( Queue &Q )
{

Реализация очереди (списки)
struct Node {
int data;
Node *next;
};
typedef Node
Реализация очереди (списки)
struct Node {
int data;
Node *next;
};
typedef Node
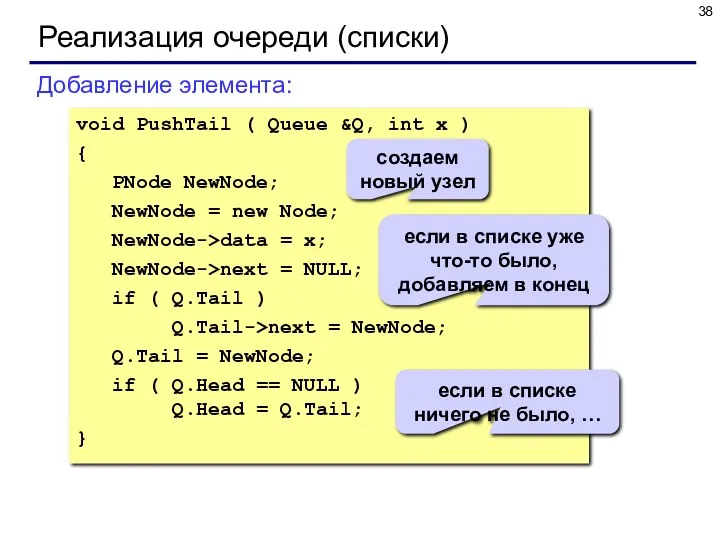
Реализация очереди (списки)
void PushTail ( Queue &Q, int x )
{
PNode
Реализация очереди (списки)
void PushTail ( Queue &Q, int x )
{
PNode
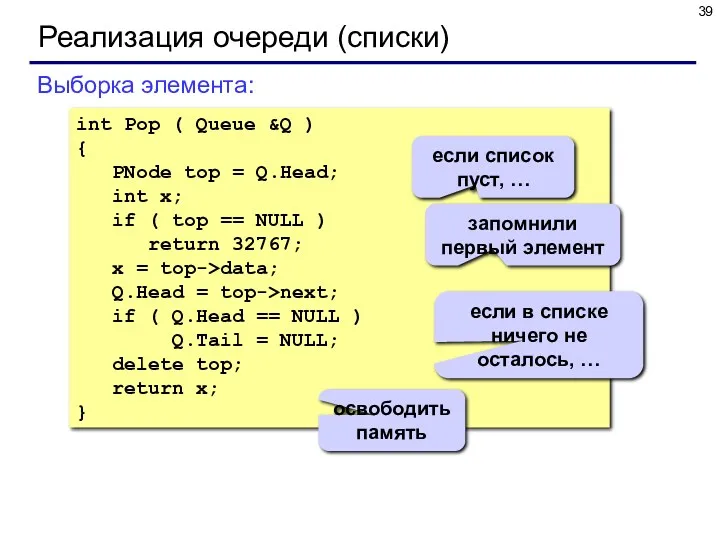
Реализация очереди (списки)
int Pop ( Queue &Q )
{
PNode top =
Реализация очереди (списки)
int Pop ( Queue &Q )
{
PNode top =

Дек
Дек (deque = double ended queue, очередь с двумя концами) –
Дек
Дек (deque = double ended queue, очередь с двумя концами) –

Деревья
Лекция 5.3
Деревья
Лекция 5.3
Деревья
Деревья
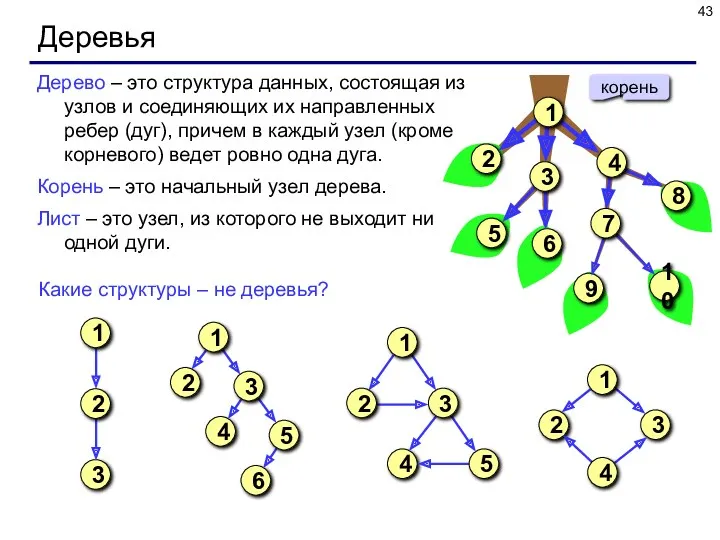
Деревья
Дерево – это структура данных, состоящая из узлов и соединяющих их
Деревья
Дерево – это структура данных, состоящая из узлов и соединяющих их

Деревья
Предок узла x – это узел, из которого существует путь по
Деревья
Предок узла x – это узел, из которого существует путь по

Дерево – рекурсивная структура данных
Рекурсивное определение:
Пустая структура – это дерево.
Дерево –
Дерево – рекурсивная структура данных
Рекурсивное определение:
Пустая структура – это дерево.
Дерево –

Двоичные деревья
Структура узла:
struct Node {
int data; // полезные данные
Node
Двоичные деревья
Структура узла:
struct Node {
int data; // полезные данные
Node
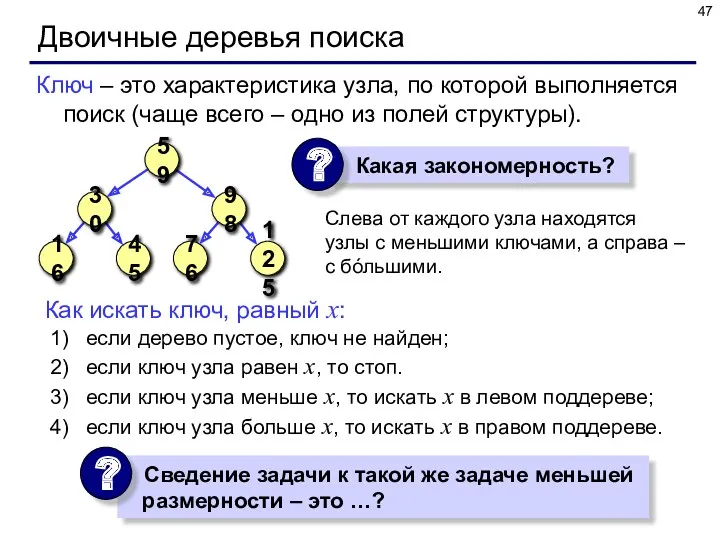
Двоичные деревья поиска
Слева от каждого узла находятся узлы с меньшими ключами,
Двоичные деревья поиска
Слева от каждого узла находятся узлы с меньшими ключами,
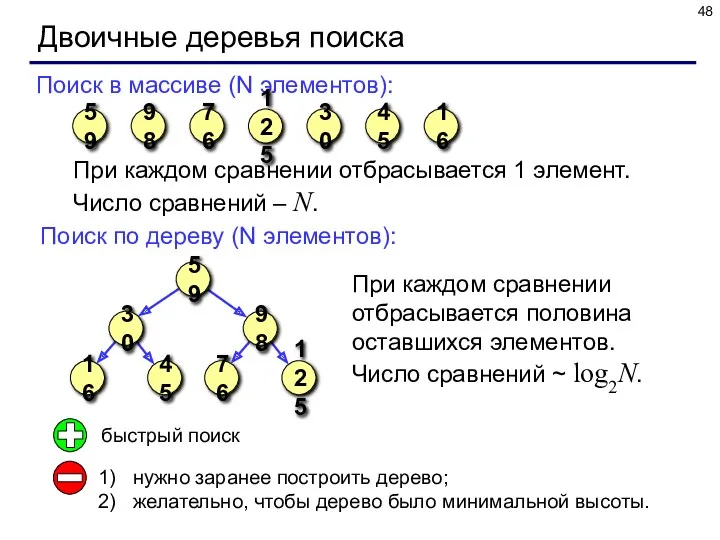
Двоичные деревья поиска
Поиск в массиве (N элементов):
При каждом сравнении отбрасывается 1
Двоичные деревья поиска
Поиск в массиве (N элементов):
При каждом сравнении отбрасывается 1

Реализация алгоритма поиска
//---------------------------------------
// Функция Search – поиск по дереву
// Вход: Tree
Реализация алгоритма поиска
//---------------------------------------
// Функция Search – поиск по дереву
// Вход: Tree

Как построить дерево поиска?
//---------------------------------------------
// Функция AddToTree – добавить элемент к дереву
//
Как построить дерево поиска?
//---------------------------------------------
// Функция AddToTree – добавить элемент к дереву
//
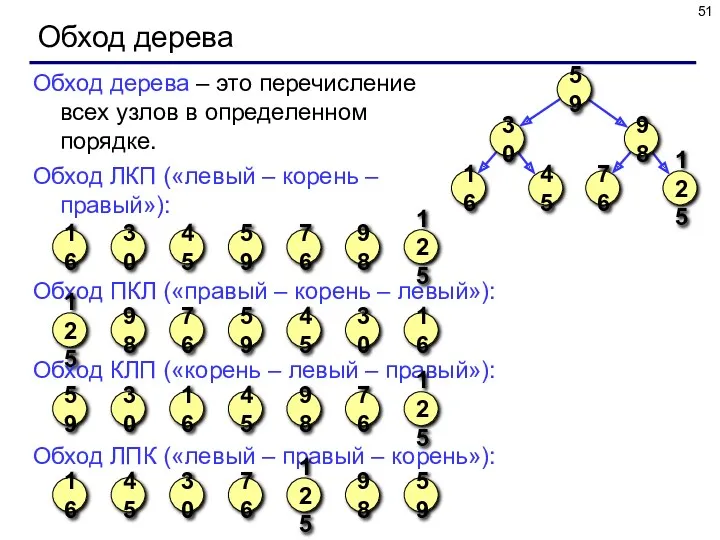
Обход дерева
Обход дерева – это перечисление всех узлов в определенном порядке.
Обход
Обход дерева
Обход дерева – это перечисление всех узлов в определенном порядке.
Обход
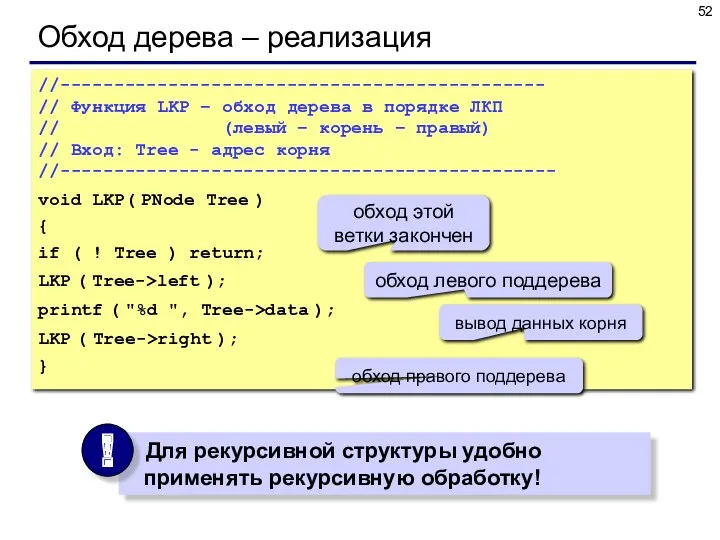
Обход дерева – реализация
//---------------------------------------------
// Функция LKP – обход дерева в порядке
Обход дерева – реализация
//---------------------------------------------
// Функция LKP – обход дерева в порядке
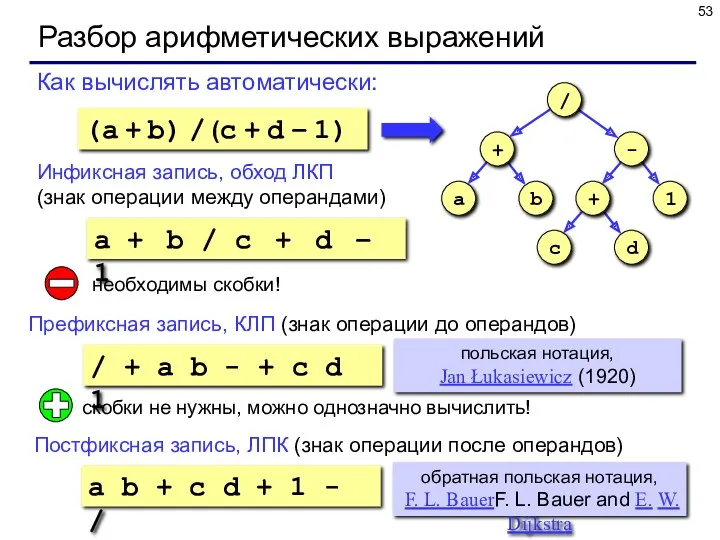
Разбор арифметических выражений
a b + c d + 1 - /
Как
Разбор арифметических выражений
a b + c d + 1 - /
Как
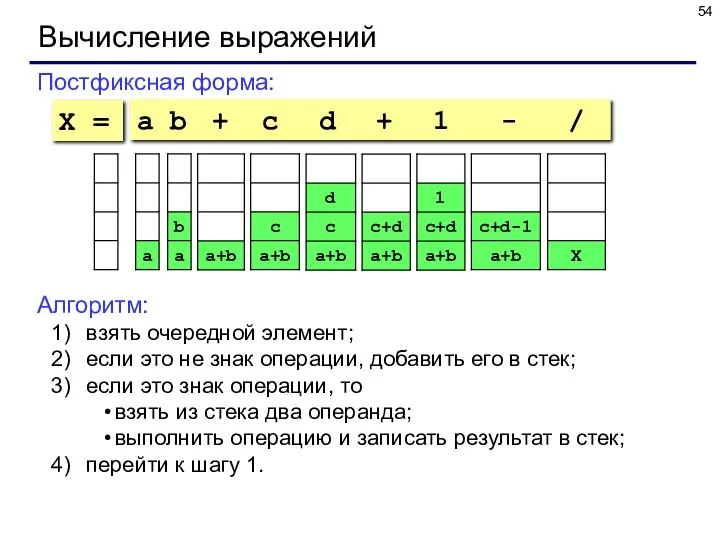
Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /
Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /

Вычисление выражений
Задача: в символьной строке записано правильное арифметическое выражение, которое может
Вычисление выражений
Задача: в символьной строке записано правильное арифметическое выражение, которое может
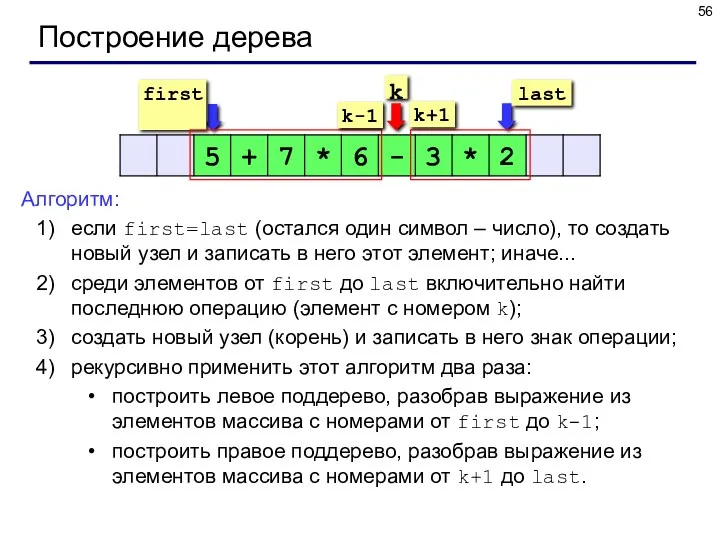
Построение дерева
Алгоритм:
если first=last (остался один символ – число), то создать новый
Построение дерева
Алгоритм:
если first=last (остался один символ – число), то создать новый

Как найти последнюю операцию?
Порядок выполнения операций
умножение и деление;
сложение и вычитание.
Приоритет (старшинство)
Как найти последнюю операцию?
Порядок выполнения операций
умножение и деление;
сложение и вычитание.
Приоритет (старшинство)

Приоритет операции
//--------------------------------------------
// Функция Priority – приоритет операции
// Вход: символ операции
// Выход:
Приоритет операции
//--------------------------------------------
// Функция Priority – приоритет операции
// Вход: символ операции
// Выход:

Номер последней операции
//--------------------------------------------
// Функция LastOperation – номер последней операции
// Вход: строка,
Номер последней операции
//--------------------------------------------
// Функция LastOperation – номер последней операции
// Вход: строка,
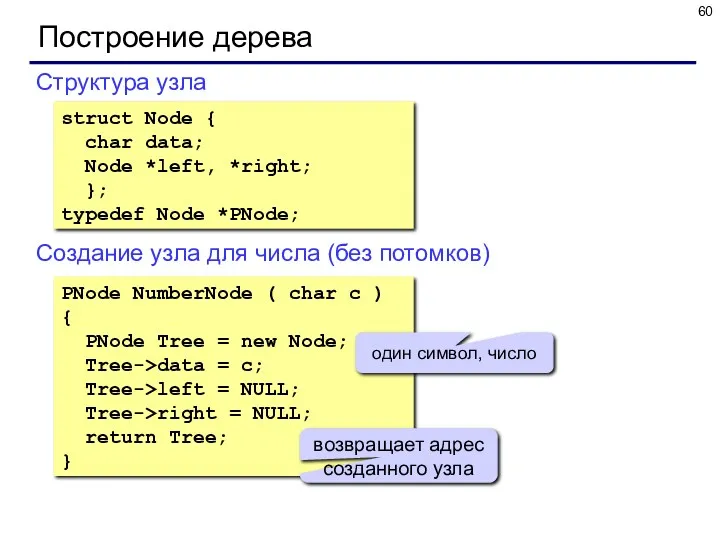
Построение дерева
Структура узла
struct Node {
char data;
Node *left, *right;
};
typedef
Построение дерева
Структура узла
struct Node {
char data;
Node *left, *right;
};
typedef

Построение дерева
//--------------------------------------------
// Функция MakeTree – построение дерева
// Вход: строка, номера первого
Построение дерева
//--------------------------------------------
// Функция MakeTree – построение дерева
// Вход: строка, номера первого

Вычисление выражения по дереву
//--------------------------------------------
// Функция CalcTree – вычисление по дереву
// Вход:
Вычисление выражения по дереву
//--------------------------------------------
// Функция CalcTree – вычисление по дереву
// Вход:

Основная программа
//--------------------------------------------
// Основная программа: ввод и вычисление
// выражения с помощью дерева
//--------------------------------------------
void
Основная программа
//--------------------------------------------
// Основная программа: ввод и вычисление
// выражения с помощью дерева
//--------------------------------------------
void

Дерево игры
Задача.
Перед двумя игроками лежат две кучки камней, в первой
Дерево игры
Задача. Перед двумя игроками лежат две кучки камней, в первой
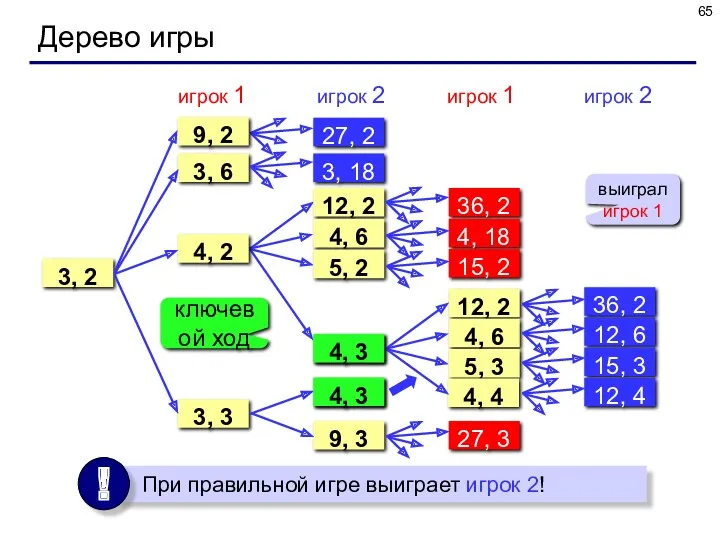
Дерево игры
3, 2
игрок 1
3, 6
27, 2
3, 18
3, 3
4, 2
12, 2
4, 6
5,
Дерево игры
3, 2
игрок 1
3, 6
27, 2
3, 18
3, 3
4, 2
12, 2
4, 6
5,
Графы
Лекция 5.4
Графы
Лекция 5.4
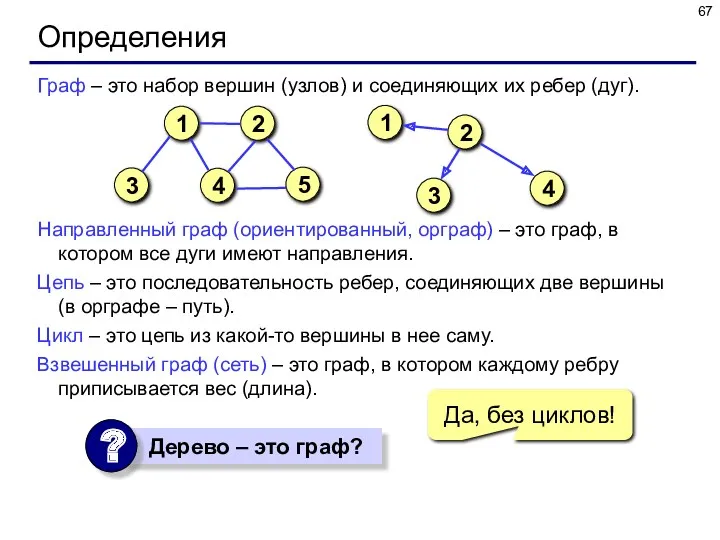
Определения
Граф – это набор вершин (узлов) и соединяющих их ребер (дуг).
Направленный
Определения
Граф – это набор вершин (узлов) и соединяющих их ребер (дуг).
Направленный
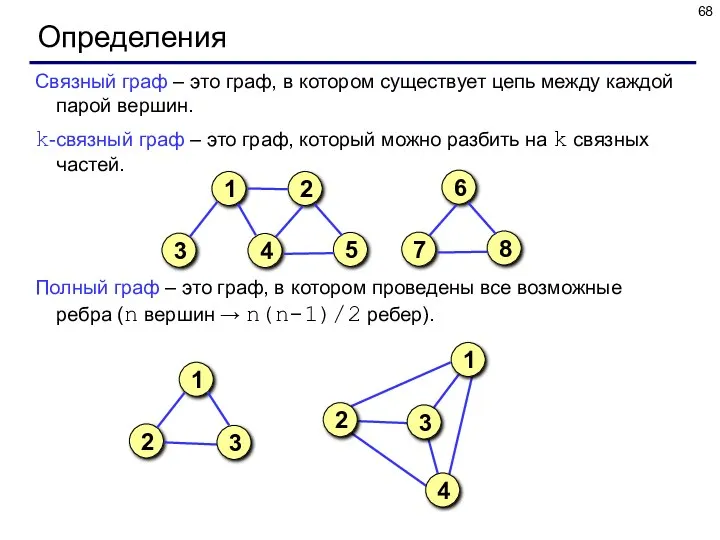
Определения
Связный граф – это граф, в котором существует цепь между каждой
Определения
Связный граф – это граф, в котором существует цепь между каждой
![Описание графа Матрица смежности – это матрица, элемент M[i][j] которой](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/607719/slide-68.jpg)
Описание графа
Матрица смежности – это матрица, элемент M[i][j] которой равен 1,
Описание графа
Матрица смежности – это матрица, элемент M[i][j] которой равен 1,
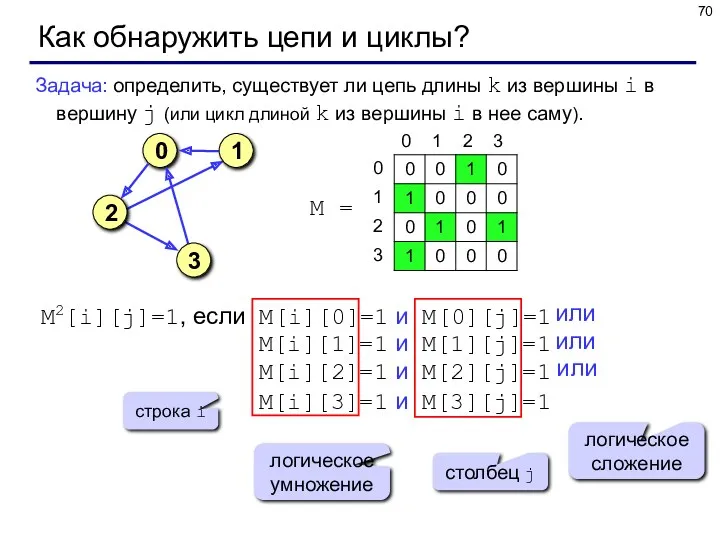
Как обнаружить цепи и циклы?
Задача: определить, существует ли цепь длины k
Как обнаружить цепи и циклы?
Задача: определить, существует ли цепь длины k
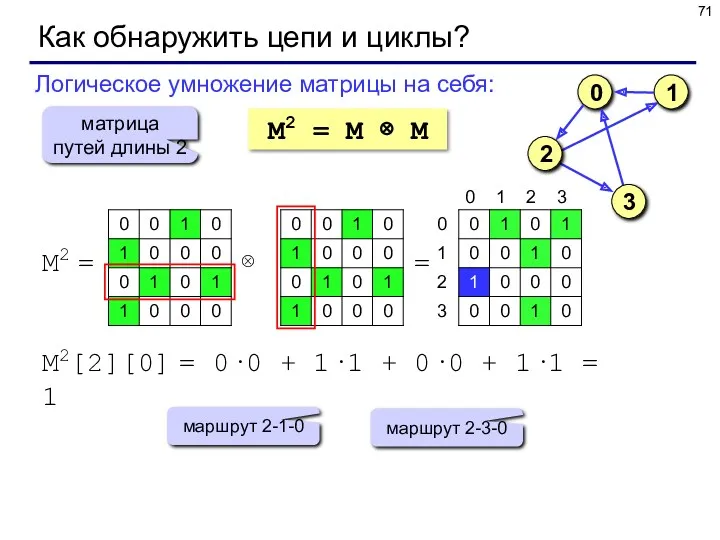
Как обнаружить цепи и циклы?
M2 = M ⊗ M
Логическое умножение матрицы
Как обнаружить цепи и циклы?
M2 = M ⊗ M
Логическое умножение матрицы
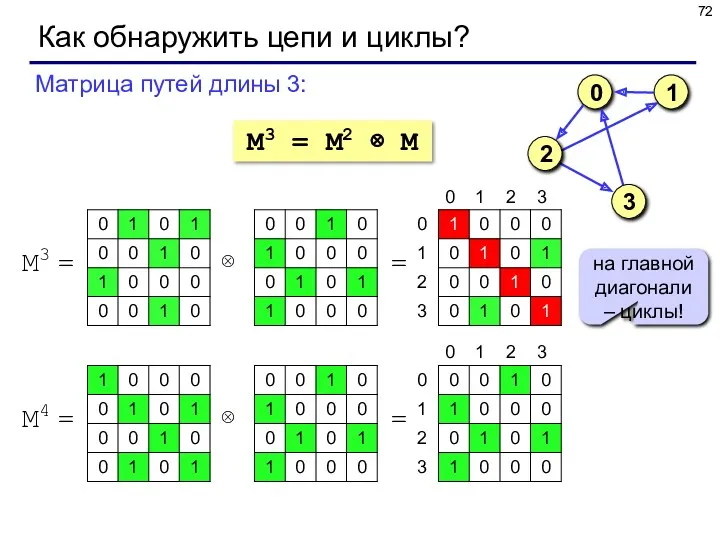
Как обнаружить цепи и циклы?
M3 = M2 ⊗ M
Матрица путей длины
Как обнаружить цепи и циклы?
M3 = M2 ⊗ M
Матрица путей длины
![Весовая матрица Весовая матрица – это матрица, элемент W[i][j] которой](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/607719/slide-72.jpg)
Весовая матрица
Весовая матрица – это матрица, элемент W[i][j] которой равен весу
Весовая матрица
Весовая матрица – это матрица, элемент W[i][j] которой равен весу
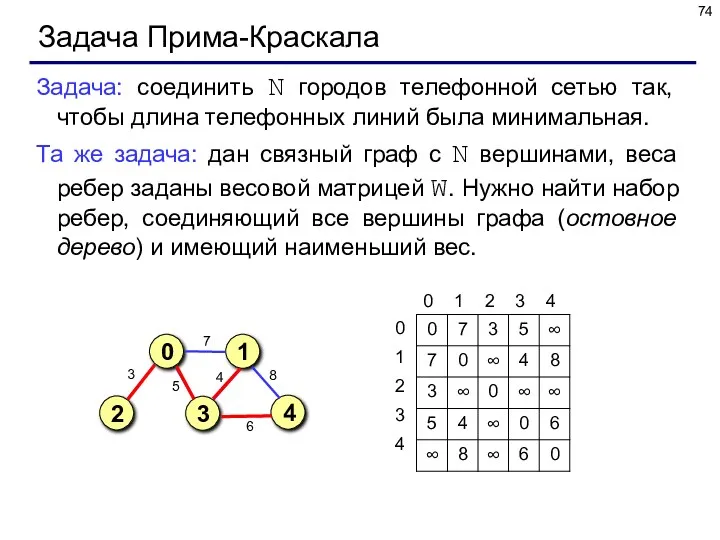
Задача Прима-Краскала
Задача: соединить N городов телефонной сетью так, чтобы длина телефонных
Задача Прима-Краскала
Задача: соединить N городов телефонной сетью так, чтобы длина телефонных
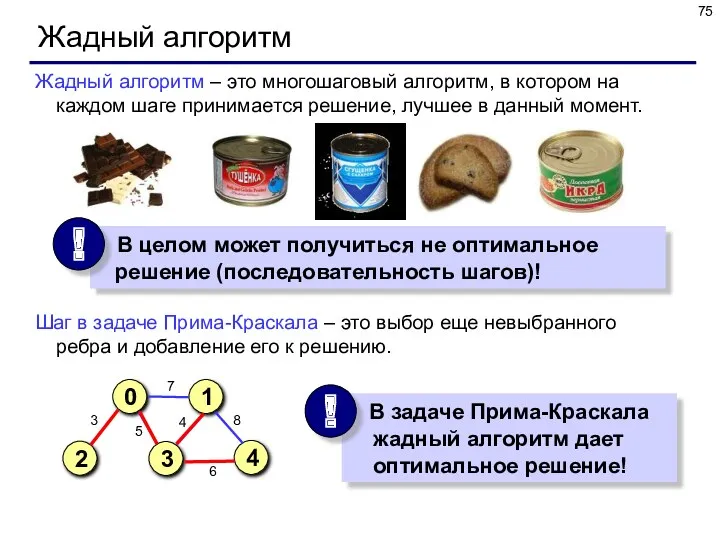
Жадный алгоритм
Жадный алгоритм – это многошаговый алгоритм, в котором на каждом
Жадный алгоритм
Жадный алгоритм – это многошаговый алгоритм, в котором на каждом
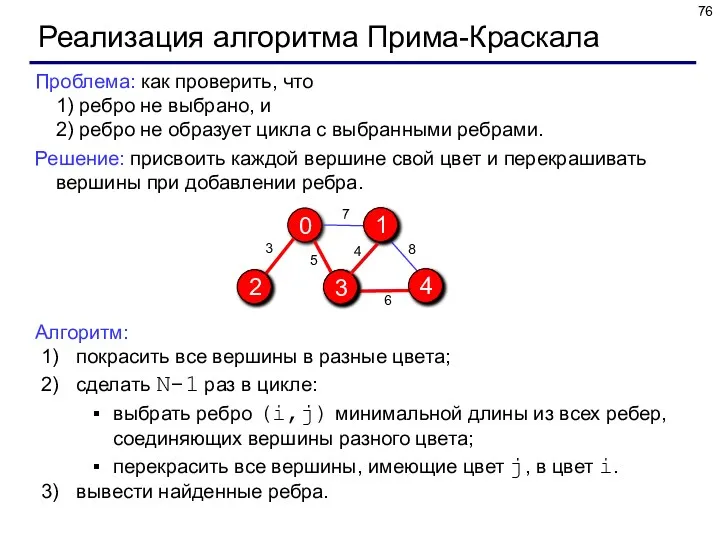
Реализация алгоритма Прима-Краскала
Проблема: как проверить, что
1) ребро не выбрано, и
Реализация алгоритма Прима-Краскала
Проблема: как проверить, что 1) ребро не выбрано, и

Реализация алгоритма Прима-Краскала
Структура «ребро»:
struct rebro {
int i, j; //
Реализация алгоритма Прима-Краскала
Структура «ребро»:
struct rebro {
int i, j; //

Реализация алгоритма Прима-Краскала
for ( k = 0; k < N-1; k
Реализация алгоритма Прима-Краскала
for ( k = 0; k < N-1; k

Сложность алгоритма
Основной цикл:
O(N3)
for ( k = 0; k < N-1; k
Сложность алгоритма
Основной цикл:
O(N3)
for ( k = 0; k < N-1; k
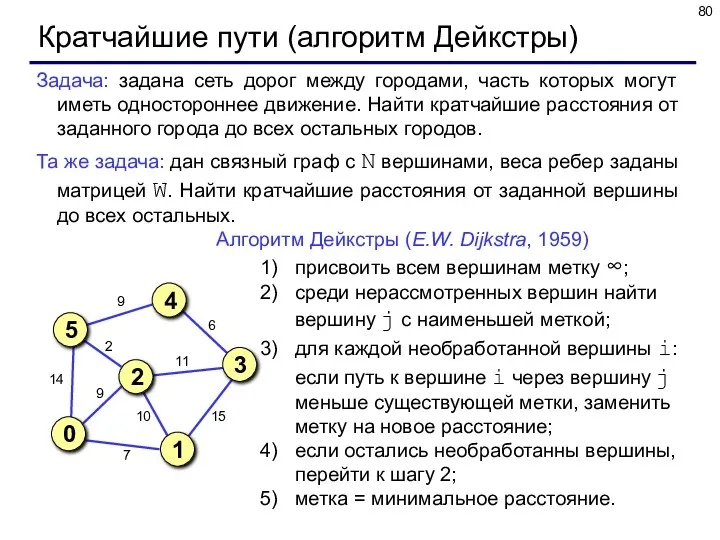
Кратчайшие пути (алгоритм Дейкстры)
Задача: задана сеть дорог между городами, часть которых
Кратчайшие пути (алгоритм Дейкстры)
Задача: задана сеть дорог между городами, часть которых
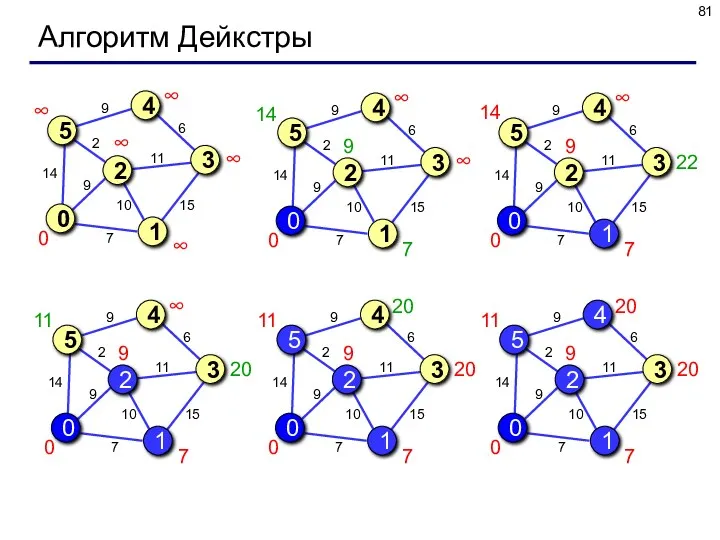
Алгоритм Дейкстры
Алгоритм Дейкстры
![Реализация алгоритма Дейкстры Массивы: массив a, такой что a[i]=1, если](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/607719/slide-81.jpg)
Реализация алгоритма Дейкстры
Массивы:
массив a, такой что a[i]=1, если вершина уже рассмотрена,
Реализация алгоритма Дейкстры
Массивы:
массив a, такой что a[i]=1, если вершина уже рассмотрена,
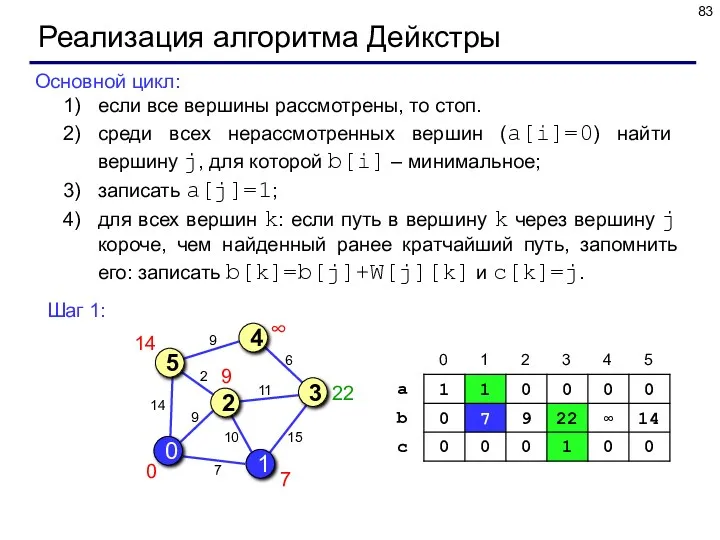
Реализация алгоритма Дейкстры
Основной цикл:
если все вершины рассмотрены, то стоп.
среди всех нерассмотренных
Реализация алгоритма Дейкстры
Основной цикл:
если все вершины рассмотрены, то стоп.
среди всех нерассмотренных
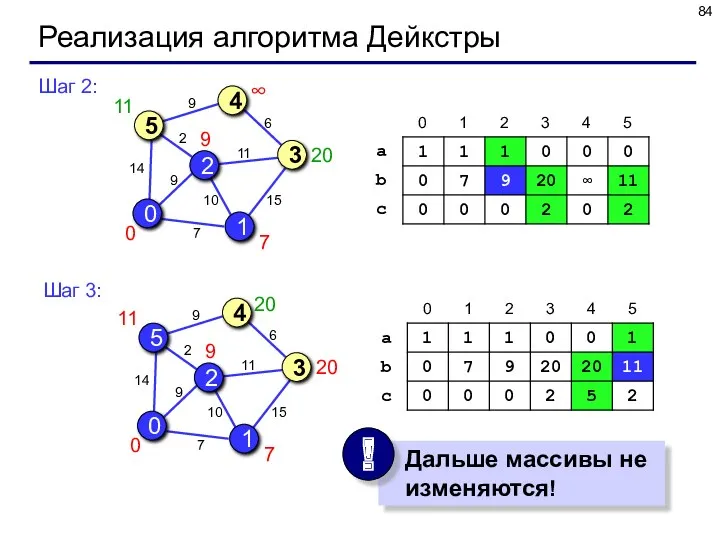
Реализация алгоритма Дейкстры
Шаг 2:
Шаг 3:
Реализация алгоритма Дейкстры
Шаг 2:
Шаг 3:

Как вывести маршрут?
Результат работа алгоритма Дейкстры:
длины путей
Маршрут из вершины 0 в
Как вывести маршрут?
Результат работа алгоритма Дейкстры:
длины путей
Маршрут из вершины 0 в
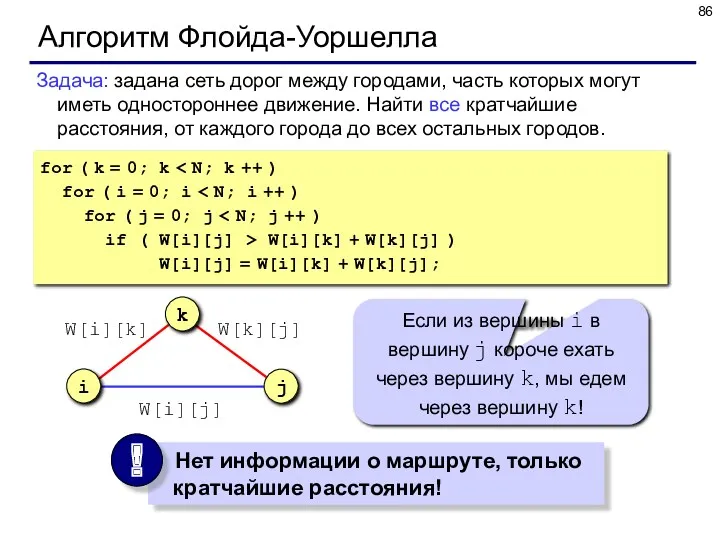
Алгоритм Флойда-Уоршелла
Задача: задана сеть дорог между городами, часть которых могут иметь
Алгоритм Флойда-Уоршелла
Задача: задана сеть дорог между городами, часть которых могут иметь

Алгоритм Флойда-Уоршелла
Версия с запоминанием маршрута:
for ( i = 0; i <
Алгоритм Флойда-Уоршелла
Версия с запоминанием маршрута:
for ( i = 0; i <

Задача коммивояжера
Задача коммивояжера. Коммивояжер (бродячий торговец) должен выйти из первого города
Задача коммивояжера
Задача коммивояжера. Коммивояжер (бродячий торговец) должен выйти из первого города
 SMM для start-up
SMM для start-up Файловый менеджер
Файловый менеджер Команда FevDay. Создание приложения на мобильное устройство
Команда FevDay. Создание приложения на мобильное устройство Эволюция технологий изготовления процессора
Эволюция технологий изготовления процессора Системы счисления
Системы счисления Промышленные ПЛК
Промышленные ПЛК Декоративно-прикладне мистецтво. Підручник
Декоративно-прикладне мистецтво. Підручник ООП 7. Наследование и шаблоны
ООП 7. Наследование и шаблоны Інформаційні процеси та системи
Інформаційні процеси та системи Моделирование бизнес--процессов в управлении и средствами принятии решений графической нотации BPMN
Моделирование бизнес--процессов в управлении и средствами принятии решений графической нотации BPMN Программирование сервера баз данных
Программирование сервера баз данных Программирование на языке Паскаль. §54-61. 10 класс
Программирование на языке Паскаль. §54-61. 10 класс Анализ алгоритмов. (Лекция 16)
Анализ алгоритмов. (Лекция 16) Презентация к уроку Кодирование звуковой информации
Презентация к уроку Кодирование звуковой информации Обзор операций и базовых инструкций языка Си. (Тема 3)
Обзор операций и базовых инструкций языка Си. (Тема 3) Технология Flash в современном интернете
Технология Flash в современном интернете Презентация Ознакомления детей с гжелью
Презентация Ознакомления детей с гжелью Использование электронной доски для развития творческих способностей учащихся начальной школы. Часть 2.
Использование электронной доски для развития творческих способностей учащихся начальной школы. Часть 2. Засоби пошуку інформації в Інтернеті
Засоби пошуку інформації в Інтернеті Технологии построения web-интерфейсов
Технологии построения web-интерфейсов Знецінення як робота з обличчям співрозмовника у соціальних мережах
Знецінення як робота з обличчям співрозмовника у соціальних мережах About RAW sockets
About RAW sockets Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка
Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка Технология проектирования реляционных баз данных. Нормализация и функциональные зависимости
Технология проектирования реляционных баз данных. Нормализация и функциональные зависимости Групповые операции в запросах Access
Групповые операции в запросах Access Проектирование и разработка игрового приложения. Физика и взаимодействие игровых персонажей
Проектирование и разработка игрового приложения. Физика и взаимодействие игровых персонажей Создание альтернативного сайта для ГУО средняя школа №24 г. Гомеля
Создание альтернативного сайта для ГУО средняя школа №24 г. Гомеля Принципи організації розподілених інформаційних систем на основі баз даних та експертних систем в освіті
Принципи організації розподілених інформаційних систем на основі баз даних та експертних систем в освіті