- Алгоритмы и структуры данных. Иерархические структуры данных. Лекция 3

Содержание
- 2. Теоретические сведения ДЕРЕВЬЯ Деревья произвольного (общего) вида. Нелинейные структуры данных отражают более сложные отношения порядка между
- 3. ДЕРЕВЬЯ Как видите, это определение является рекурсивным: дерево определено на основе понятия дерева. Рекурсивный характер деревьев
- 4. Теоретические сведения ДЕРЕВЬЯ
- 5. ДЕРЕВЬЯ Сама природа представления данных в компьютере определяет неявный порядок любого дерева, поэтому в большинстве случаев
- 6. ДЕРЕВЬЯ Основные свойства дерева: корень не имеет предков каждый узел за исключением корня, имеет единственного предка
- 7. Бинарные (двоичные) деревья. Важное значение имеют упорядоченные деревья второй степени – бинарные. Бинарным деревом называется конечное
- 8. Представление бинарных деревьев. В памяти с последовательной организацией. Если известен максимальный размер дерева, т.е. его высота
- 9. Представление бинарных деревьев. Деревом такой структуры является простота доступа по индексам как от предка к потомку,
- 10. Алгоритмы обхода бинарных деревьев Представление бинарного дерева в динамической памяти со связной организацией. Элемент хранения узла
- 11. Представление бинарных деревьев. Обход – алгоритм обработки, при котором узел дерева обрабатывается единственный раз одинаковым образом
- 12. Представление бинарных деревьев Левосторонние алгоритмы: Низходящий (прямой) обход к – л – п(корень левое правое) Обработать
- 13. Представление бинарных деревьев Различные алгоритмы обхода бинарного дерева делают различную линейную расстановку множества информационных полей узлов
- 14. Представление бинарных деревьев
- 15. Деревья цифрового поиска Существует класс задач, которые оперируют с данными, представляющими собой множество слов некоторого языка.
- 16. Деревья цифрового поиска Для рассмотренного выше класса задач используют еще один алгоритм поиска – алгоритм цифрового
- 17. Деревья цифрового поиска На первом уровне этого дерева массив указателей, каждый из которых может быть либо
- 18. Создание дерева цифрового поиска. Рассмотрим процесс формирования дерева цифрового поиска на примере. Пусть задано множество слов
- 19. Поиск в дереве цифрового поиска Алгоритм поиска по бору достаточно очевиден. Первая буква искомого слова ищется
- 20. Поиск в дереве цифрового поиска Для решения этой проблемы необходимо, чтобы каждое заносимое в бор слово
- 22. Скачать презентацию

Теоретические сведения
ДЕРЕВЬЯ
Деревья произвольного (общего) вида.
Нелинейные структуры данных отражают более сложные отношения
Теоретические сведения
ДЕРЕВЬЯ
Деревья произвольного (общего) вида.
Нелинейные структуры данных отражают более сложные отношения

ДЕРЕВЬЯ
Как видите, это определение является рекурсивным: дерево определено на основе понятия
ДЕРЕВЬЯ
Как видите, это определение является рекурсивным: дерево определено на основе понятия
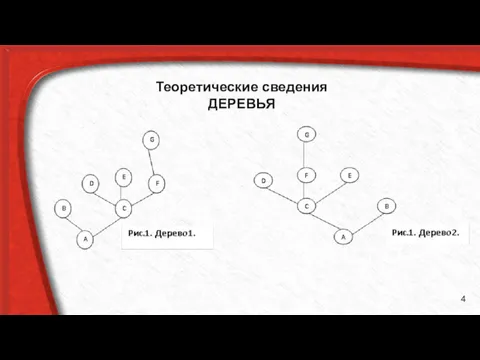
Теоретические сведения
ДЕРЕВЬЯ
Теоретические сведения
ДЕРЕВЬЯ

ДЕРЕВЬЯ
Сама природа представления данных в компьютере определяет неявный порядок любого дерева,
ДЕРЕВЬЯ
Сама природа представления данных в компьютере определяет неявный порядок любого дерева,

ДЕРЕВЬЯ
Основные свойства дерева:
корень не имеет предков
каждый узел за исключением корня, имеет
ДЕРЕВЬЯ
Основные свойства дерева:
корень не имеет предков
каждый узел за исключением корня, имеет

Бинарные (двоичные) деревья.
Важное значение имеют упорядоченные деревья второй степени – бинарные.
Бинарным
Бинарные (двоичные) деревья.
Важное значение имеют упорядоченные деревья второй степени – бинарные.
Бинарным

Представление бинарных деревьев.
В памяти с последовательной организацией.
Если известен максимальный размер дерева,
Представление бинарных деревьев.
В памяти с последовательной организацией.
Если известен максимальный размер дерева,
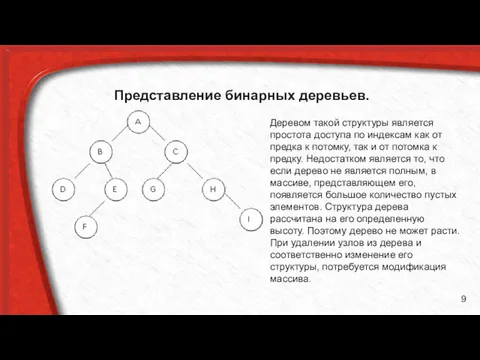
Представление бинарных деревьев.
Деревом такой структуры является простота доступа по индексам как
Представление бинарных деревьев.
Деревом такой структуры является простота доступа по индексам как

Алгоритмы обхода бинарных деревьев
Представление бинарного дерева в динамической памяти со связной
Алгоритмы обхода бинарных деревьев
Представление бинарного дерева в динамической памяти со связной

Представление бинарных деревьев.
Обход – алгоритм обработки, при котором узел дерева обрабатывается
Представление бинарных деревьев.
Обход – алгоритм обработки, при котором узел дерева обрабатывается

Представление бинарных деревьев
Левосторонние алгоритмы:
Низходящий (прямой) обход к – л – п(корень
Представление бинарных деревьев
Левосторонние алгоритмы:
Низходящий (прямой) обход к – л – п(корень

Представление бинарных деревьев
Различные алгоритмы обхода бинарного дерева делают различную линейную расстановку
Представление бинарных деревьев
Различные алгоритмы обхода бинарного дерева делают различную линейную расстановку

Представление бинарных деревьев
Представление бинарных деревьев

Деревья цифрового поиска
Существует класс задач, которые оперируют с данными, представляющими собой
Деревья цифрового поиска
Существует класс задач, которые оперируют с данными, представляющими собой

Деревья цифрового поиска
Для рассмотренного выше класса задач используют еще один алгоритм
Деревья цифрового поиска
Для рассмотренного выше класса задач используют еще один алгоритм

Деревья цифрового поиска
На первом уровне этого дерева массив указателей, каждый из
Деревья цифрового поиска
На первом уровне этого дерева массив указателей, каждый из
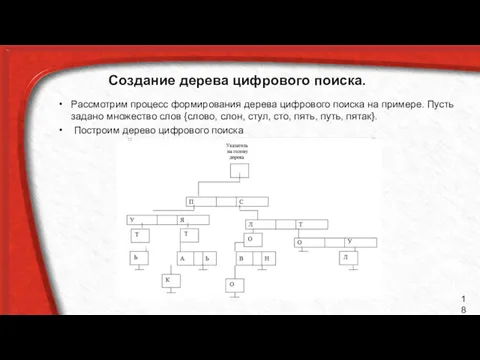
Создание дерева цифрового поиска.
Рассмотрим процесс формирования дерева цифрового поиска на примере.
Создание дерева цифрового поиска.
Рассмотрим процесс формирования дерева цифрового поиска на примере.

Поиск в дереве цифрового поиска
Алгоритм поиска по бору достаточно очевиден. Первая
Поиск в дереве цифрового поиска
Алгоритм поиска по бору достаточно очевиден. Первая

Поиск в дереве цифрового поиска
Для решения этой проблемы необходимо, чтобы каждое
Поиск в дереве цифрового поиска
Для решения этой проблемы необходимо, чтобы каждое
 Графічний редактор Фотошоп
Графічний редактор Фотошоп Графика в Delphi
Графика в Delphi Калькулятор. Запуск программы
Калькулятор. Запуск программы Техническое обслуживание, тестирование и аппаратно-программное конфигурирование компьютерного комплекса сотрудника отдела
Техническое обслуживание, тестирование и аппаратно-программное конфигурирование компьютерного комплекса сотрудника отдела Поиск информации в Интернете
Поиск информации в Интернете Базы данных
Базы данных Електронні таблиці Microsoft Excel
Електронні таблиці Microsoft Excel Относительные и абсолютные ссылки в Microsoft Excel
Относительные и абсолютные ссылки в Microsoft Excel Применение метода проектного обучения и элементов кейс-техологии в преподавании дисциплин Предметно-ориентированное программное обеспечение и Информационные технологии профессиональной деятельности на базе САПР
Применение метода проектного обучения и элементов кейс-техологии в преподавании дисциплин Предметно-ориентированное программное обеспечение и Информационные технологии профессиональной деятельности на базе САПР 1C-Администратор. Новый сервис для продвинутых пользователей
1C-Администратор. Новый сервис для продвинутых пользователей Моделирование в AutoCAD
Моделирование в AutoCAD Пример презентации проекта
Пример презентации проекта Право авторства на произведения, созданные нейросетями
Право авторства на произведения, созданные нейросетями Программирование ветвлений на Паскале (11 класс)
Программирование ветвлений на Паскале (11 класс) Возможности Интернета
Возможности Интернета История создания персонального компьютера и его компоненты
История создания персонального компьютера и его компоненты Графические и табличные информационные модели
Графические и табличные информационные модели Информационные процессы
Информационные процессы Подведение итогов и анализ сайта: rftreid.ru
Подведение итогов и анализ сайта: rftreid.ru История развития ЭВМ
История развития ЭВМ Wedding. Подготовка и организация свадьбы
Wedding. Подготовка и организация свадьбы Сайт-визитка Котельничской районной центральной библиотеки. Правила работы с кнопкой электронный каталог
Сайт-визитка Котельничской районной центральной библиотеки. Правила работы с кнопкой электронный каталог Теория цвета
Теория цвета Измерение информации. Алфавитный подход
Измерение информации. Алфавитный подход Проектирование и реализация дизайн-макета кинотеатра
Проектирование и реализация дизайн-макета кинотеатра Планирование разработки программного обеспечения
Планирование разработки программного обеспечения Сәулет-жоспарлау тапсырмасын беру
Сәулет-жоспарлау тапсырмасын беру Решение задач в Excel
Решение задач в Excel