- Алгоритмы текстового поиска. Алгоритмы точного поиска образца в тексте

Содержание
- 2. Условные обозначения s – количество символов алфавита T – строка, в которой происходит поиск n- длина
- 3. Префикс и суффикс Префикс – любое подслово, начинающееся с 0 Суффикс – окончание слова Префиксы Суффиксы
- 4. Постановка задачи Дан текст T и паттерн p такие, что элементы этих строк — символы из
- 5. Алгоритмы поиска подстроки в строке 1. «Наивный» алгоритм о б а о б о б р
- 6. Алгоритмы поиска подстроки в строке 1. «Наивный» алгоритм public static int simpleSearch(String where, String what) {
- 7. Наивный алгоритм Нет необходимости использовать дополнительную память. Нет дополнительных временных затрат. Худшее время поиска O((n-m)*m)≈O(n*m) Худший
- 8. Алгоритм Рабина – Карпа Использование хеш-функции и сравнение чисел вместо строк. Быстрый пересчет значения хеш-функции для
- 9. Алгоритм Рабина — Карпа о л а р в о и а б и о б
- 10. 2. Алгоритм Рабина – Карпа 2 3 2 3 3 2 4 3 2 3 1
- 11. Алгоритм Рабина — Карпа. Идея состоит в том, чтобы строкам сопоставлять значения хеш-функций и сравнивать не
- 12. Алгоритм Рабина-Карпа Шаг 1 Прикладываем левый край образца к левому краю текста, К = 0 Вычисляем
- 13. Алгоритм Рабина — Карпа (оценка) Если количество холостых срабатываний невелико, то время работы алгоритма будет пропорционально
- 14. Алгоритм Бойера-Мура Алгоритм Бойера — Мура Сравнение с конца образца. Сильное/слабое правило плохого символа. Сильное/слабое правило
- 15. Алгоритм Бойера-Мура Алгоритм Бойера-Мура состоит из следующих шагов: Строится таблица смещений для искомой подстроки. Далее совмещается
- 16. из 69 ТЕКСТ ОБРАЗЕЦ Таблица 2 Таблица 1 Алгоритм Бойера-Мура Пример 1 Если последняя буква образца
- 17. Пример 1 из 69 ТЕКСТ ОБРАЗЕЦ Алгоритм Бойера-Мура
- 18. Пример2 СЧИТАЕМ СДВИГ из 69 ТЕКСТ ОБРАЗЕЦ 1) Если символа с в образце нет, то сдвиг
- 19. из 69 ТЕКСТ ОБРАЗЕЦ Таблица 1 Пример 2
- 20. Алгоритм Боуера-Мура Худшее время работы алгоритма – O(n * m) Среднее – O(n + m) Дополнительные
- 21. ВИДЫ ПРЕПРОЦЕССИНГА: Префикс-функция Z-функция Бор Суффиксы массив
- 22. Z-функция Гасфилда Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. .
- 23. Поиск подстроки в строке с помощью Z-функции n — длина текста. m — длина образца. Образуем
- 25. Поиск подстроки в строке с помощью Z-функции Псевдокод int substringSearch(text : string, pattern : string): int[]
- 26. из 69 Строке «абракадабра» Образец «рак». Конкатенируем строки «рак$абракадабра». Вектор Z-функции выглядит для такой строки так:
- 27. Префикс-функция Определение Дана строка s[0 ..n-1]. Требуется вычислить для неё префикс-функцию, т.е. массив чисел π[0 ..
- 28. Пример Например, для строки "abcabcd" префикс-функция равна: [0, 0, 0, 1, 2, 3, 0], что означает:
- 29. Пример префикс -функции Шаблон "ABABACA” A, нет совпадений 0 AB, нет совпадений 0 ABA, одно совпадение:
- 30. Алгоритм Кнута- Морриса-Пратта Пример: Текст «ababcabсacab» ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так: Все вхождения
- 31. Алгоритм Кнута- Морриса-Пратта Текст b b a b a b a b a a b a
- 32. Алгоритм Кнута- Морриса-Пратта Δ=6-π(6) =2 Δ=5-π(5) =2
- 33. Алгоритм Кнута- Морриса-Пратта Время на препроцессинг + поиск: O(m + n) в худшем случае Проход по
- 34. Выводы Алгоритм Кнута-Мориса-Пратта: Несмотря на лучшую оценку по сравнению с алгоритмом грубой силы, на практике показал
- 35. public static int KnuthMorrisPratt(String where, String what) { int n = where.length(); // Длина строки, в
- 36. public static int RabinKarp(String where, String what) { int n = where.length();// Длина строки, в которой
- 37. private static final int shLen = 256; private static int hash(char c) { return c &
- 39. Скачать презентацию

Условные обозначения
s – количество символов алфавита
T – строка, в которой происходит
Условные обозначения
s – количество символов алфавита
T – строка, в которой происходит

Префикс и суффикс
Префикс – любое подслово, начинающееся с 0
Суффикс –
Префикс и суффикс
Префикс – любое подслово, начинающееся с 0
Суффикс –

Постановка задачи
Дан текст T и паттерн p такие, что элементы этих
Постановка задачи
Дан текст T и паттерн p такие, что элементы этих

Алгоритмы поиска подстроки в строке
1. «Наивный» алгоритм
о
б
а
о
б
о
б
р
а
л
и
о
б
о
и
б
о
б
р
а
Число сравнений
Алгоритмы поиска подстроки в строке
1. «Наивный» алгоритм
о
б
а
о
б
о
б
р
а
л
и
о
б
о
и
б
о
б
р
а
Число сравнений

Алгоритмы поиска подстроки в строке
1. «Наивный» алгоритм
public static int simpleSearch(String where,
Алгоритмы поиска подстроки в строке
1. «Наивный» алгоритм
public static int simpleSearch(String where,

Наивный алгоритм
Нет необходимости использовать дополнительную память.
Нет дополнительных временных затрат.
Худшее время поиска
Наивный алгоритм
Нет необходимости использовать дополнительную память.
Нет дополнительных временных затрат.
Худшее время поиска

Алгоритм Рабина – Карпа
Использование хеш-функции и сравнение чисел вместо строк. Быстрый
Алгоритм Рабина – Карпа
Использование хеш-функции и сравнение чисел вместо строк. Быстрый

Алгоритм Рабина — Карпа
о
л
а
р
в
о
и
а
б
и
о
б
о
и
б
м
о
к
н
и
hash("обои") = 15 + 2 + 15 +
Алгоритм Рабина — Карпа
о
л
а
р
в
о
и
а
б
и
о
б
о
и
б
м
о
к
н
и
hash("обои") = 15 + 2 + 15 +

2. Алгоритм Рабина – Карпа
2
3
2
3
3
2
4
3
2
3
1
5
3
3
2
4
2
3
3
2
2
5
1
Функция:
= 11
Число сравнений символов:
0
+ 3
+ 0
+ 0
+
2. Алгоритм Рабина – Карпа
2
3
2
3
3
2
4
3
2
3
1
5
3
3
2
4
2
3
3
2
2
5
1
Функция:
= 11
Число сравнений символов:
0
+ 3
+ 0
+ 0
+

Алгоритм Рабина — Карпа.
Идея состоит в том, чтобы строкам сопоставлять значения
Алгоритм Рабина — Карпа.
Идея состоит в том, чтобы строкам сопоставлять значения

Алгоритм Рабина-Карпа
Шаг 1
Прикладываем левый край образца к левому краю текста, К =
Алгоритм Рабина-Карпа
Шаг 1
Прикладываем левый край образца к левому краю текста, К =

Алгоритм Рабина — Карпа (оценка)
Если количество холостых срабатываний невелико, то время
Алгоритм Рабина — Карпа (оценка)
Если количество холостых срабатываний невелико, то время

Алгоритм Бойера-Мура
Алгоритм Бойера — Мура Сравнение с конца образца.
Сильное/слабое правило
Алгоритм Бойера-Мура
Алгоритм Бойера — Мура Сравнение с конца образца.
Сильное/слабое правило

Алгоритм Бойера-Мура
Алгоритм Бойера-Мура состоит из следующих шагов:
Строится таблица смещений для
Алгоритм Бойера-Мура
Алгоритм Бойера-Мура состоит из следующих шагов:
Строится таблица смещений для

из 69
ТЕКСТ
ОБРАЗЕЦ
Таблица 2
Таблица 1
Алгоритм Бойера-Мура
Пример 1
Если последняя буква образца не
из 69
ТЕКСТ
ОБРАЗЕЦ
Таблица 2
Таблица 1
Алгоритм Бойера-Мура
Пример 1
Если последняя буква образца не
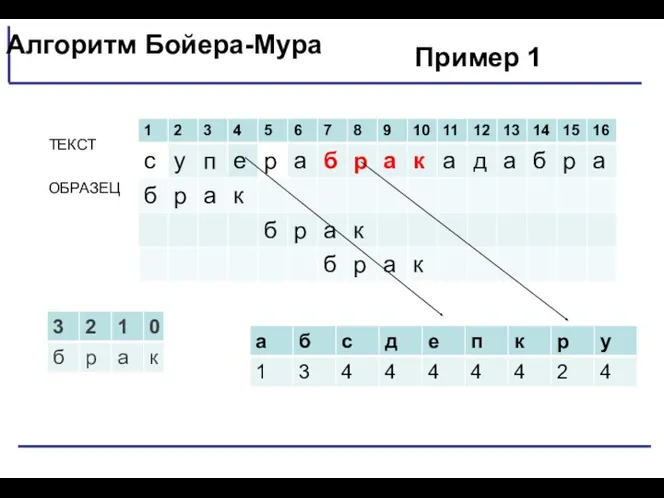
Пример 1
из 69
ТЕКСТ
ОБРАЗЕЦ
Алгоритм Бойера-Мура
Пример 1
из 69
ТЕКСТ
ОБРАЗЕЦ
Алгоритм Бойера-Мура

Пример2 СЧИТАЕМ СДВИГ
из 69
ТЕКСТ
ОБРАЗЕЦ
1) Если символа с в образце нет,
Пример2 СЧИТАЕМ СДВИГ
из 69
ТЕКСТ
ОБРАЗЕЦ
1) Если символа с в образце нет,
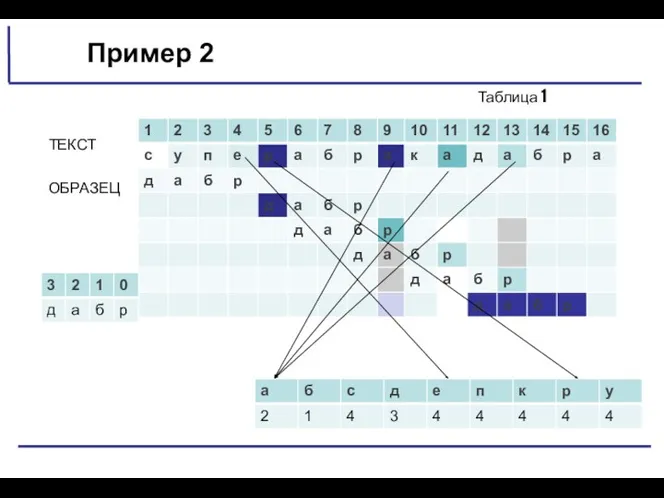
из 69
ТЕКСТ
ОБРАЗЕЦ
Таблица 1
Пример 2
из 69
ТЕКСТ
ОБРАЗЕЦ
Таблица 1
Пример 2

Алгоритм Боуера-Мура
Худшее время работы алгоритма – O(n * m)
Среднее – O(n
Алгоритм Боуера-Мура
Худшее время работы алгоритма – O(n * m)
Среднее – O(n

ВИДЫ ПРЕПРОЦЕССИНГА:
Префикс-функция
Z-функция
Бор
Суффиксы массив
ВИДЫ ПРЕПРОЦЕССИНГА:
Префикс-функция
Z-функция
Бор
Суффиксы массив
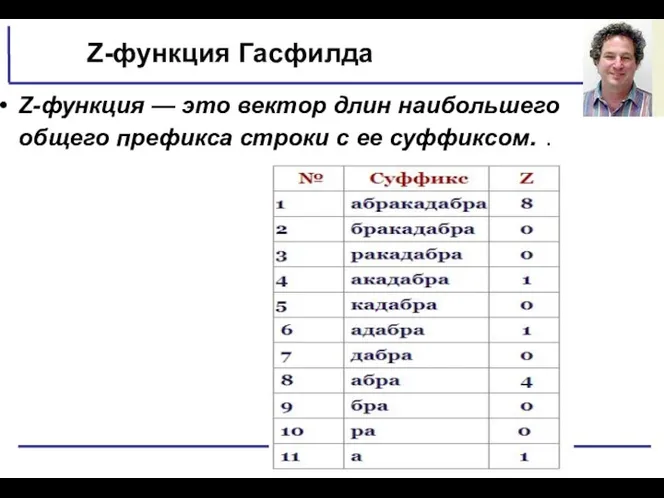
Z-функция Гасфилда
Z-функция — это вектор длин наибольшего общего префикса строки с
Z-функция Гасфилда
Z-функция — это вектор длин наибольшего общего префикса строки с

Поиск подстроки в строке с помощью Z-функции
n — длина текста. m
Поиск подстроки в строке с помощью Z-функции
n — длина текста. m
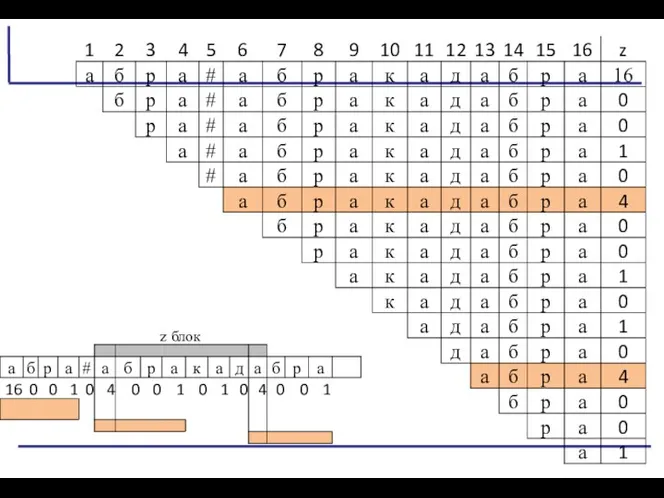

Поиск подстроки в строке с помощью Z-функции
Псевдокод
int substringSearch(text : string,
Поиск подстроки в строке с помощью Z-функции
Псевдокод
int substringSearch(text : string,

из 69
Строке «абракадабра»
Образец «рак».
Конкатенируем строки «рак$абракадабра».
Вектор Z-функции выглядит для такой
из 69
Строке «абракадабра»
Образец «рак».
Конкатенируем строки «рак$абракадабра».
Вектор Z-функции выглядит для такой
![Префикс-функция Определение Дана строка s[0 ..n-1]. Требуется вычислить для неё](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/581138/slide-26.jpg)
Префикс-функция
Определение
Дана строка s[0 ..n-1].
Требуется вычислить для неё префикс-функцию, т.е. массив
Префикс-функция
Определение
Дана строка s[0 ..n-1].
Требуется вычислить для неё префикс-функцию, т.е. массив

Пример
Например, для строки "abcabcd" префикс-функция равна: [0, 0, 0, 1, 2,
Пример
Например, для строки "abcabcd" префикс-функция равна: [0, 0, 0, 1, 2,

Пример префикс -функции
Шаблон "ABABACA”
A, нет совпадений 0
AB, нет совпадений 0
ABA,
Пример префикс -функции
Шаблон "ABABACA”
A, нет совпадений 0
AB, нет совпадений 0
ABA,

Алгоритм Кнута- Морриса-Пратта
Пример:
Текст «ababcabсacab»
ищем «abca».
Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
Алгоритм Кнута- Морриса-Пратта
Пример:
Текст «ababcabсacab»
ищем «abca».
Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:

Алгоритм Кнута- Морриса-Пратта
Текст b b a b a b a
Алгоритм Кнута- Морриса-Пратта
Текст b b a b a b a

Алгоритм Кнута- Морриса-Пратта
Δ=6-π(6) =2
Δ=5-π(5) =2
Алгоритм Кнута- Морриса-Пратта
Δ=6-π(6) =2
Δ=5-π(5) =2

Алгоритм Кнута- Морриса-Пратта
Время на препроцессинг + поиск: O(m + n)
Алгоритм Кнута- Морриса-Пратта
Время на препроцессинг + поиск: O(m + n)

Выводы
Алгоритм Кнута-Мориса-Пратта:
Несмотря на лучшую оценку по сравнению с алгоритмом грубой силы,
Выводы
Алгоритм Кнута-Мориса-Пратта:
Несмотря на лучшую оценку по сравнению с алгоритмом грубой силы,

public static int KnuthMorrisPratt(String where, String what) {
int n =
public static int KnuthMorrisPratt(String where, String what) {
int n =

public static int RabinKarp(String where, String what) {
int n =
public static int RabinKarp(String where, String what) {
int n =

private static final int shLen = 256;
private static int hash(char c)
private static final int shLen = 256;
private static int hash(char c)
 Компьютерная графика (Autodesk 3ds max). Лекция 9.1. Настройка освещения в сцене (Standard, VRay)
Компьютерная графика (Autodesk 3ds max). Лекция 9.1. Настройка освещения в сцене (Standard, VRay) Измерение количества информации. 7 класс
Измерение количества информации. 7 класс Технические средства информатизации
Технические средства информатизации Компьютер и здоровье человека
Компьютер и здоровье человека Числа в памяти компьютера
Числа в памяти компьютера Тесты.Коммуникационные технологии 8кл. Угринович
Тесты.Коммуникационные технологии 8кл. Угринович Презентация урок №20_Редактирование и устройства ввода графического изображения_5класс
Презентация урок №20_Редактирование и устройства ввода графического изображения_5класс Корпоративный документооборот. Организация документооборота на предприятии. (Тема 5)
Корпоративный документооборот. Организация документооборота на предприятии. (Тема 5) Дистанційне навчання
Дистанційне навчання Internet Security
Internet Security Расчет параметров полнодоступных систем РИ с ожиданием
Расчет параметров полнодоступных систем РИ с ожиданием Устройство компьютера. Принципы фон Неймана
Устройство компьютера. Принципы фон Неймана Trees. File systems
Trees. File systems MS Excel в курсовой работе
MS Excel в курсовой работе Что такое QR-код и как его создать, расшифровать
Что такое QR-код и как его создать, расшифровать Скрипты. Урок1
Скрипты. Урок1 ICT NEWS Computer viruses
ICT NEWS Computer viruses Конкурс. Территория детства - моя библиотека. Как Маша стала читателем
Конкурс. Территория детства - моя библиотека. Как Маша стала читателем Индивидуальный практикум по информатике
Индивидуальный практикум по информатике Cloud Basics
Cloud Basics Информатика - ғасыр талабы
Информатика - ғасыр талабы Информация Свойства информации
Информация Свойства информации Ya za kadrom
Ya za kadrom Геоинформационные системы
Геоинформационные системы Способы перевода из одной системы счисления в другую
Способы перевода из одной системы счисления в другую Как сделать свой блог лучше
Как сделать свой блог лучше Успеть за 24 часа: Как грамотно организовать рабочие процессы с помощью сервиса Битрикс24
Успеть за 24 часа: Как грамотно организовать рабочие процессы с помощью сервиса Битрикс24 Сравнительный анализ дизайнов интернет-сайтов
Сравнительный анализ дизайнов интернет-сайтов