- Архитектура СУБД. Физическая организация данных

Содержание
- 2. ТРЕБОВАНИЯ К СУБД: поддержка целостности данных; согласованное хранение независимых наборов данных; извлечение данных и управление данными
- 3. ЦЕЛОСТНОСТЬ ДАННЫХ Целостность информации — данные не изменяются при передаче, хранении или отображении. Целостность базы данных
- 4. Сетевые протоколы TCP/IP LU6.2 SPX/IPX OSI DECnet Другие Независимость от платформ Оконные менеджеры MS Windows X
- 5. Независимость от архитектуры
- 6. Поддержка стандартов Комитеты ANSI X3H2 X3H2.1 RDA SQL Access Group OMG Стандарты баз данных FIPS 127-2
- 7. История PostgreSQL Свободно распространяемая объектно-реляционная СУБД. 1977-1985гг. Ingres - «тренировочный» проект создания классической реляционной системы управления
- 8. СУБД PostgreSQL наиболее развитая СУБД с открыты кодом; надежность и устойчивость при больших нагрузках; кросс-платформенность: работает
- 9. Архитектура PostgreSQL Архитектура разбита на 3 основные подсистемы: Front End - клиентская часть системы. Серверная часть
- 10. Серверная часть Обработка запроса : Парсер принимает запрос и проверяет его синтаксис. В результате формируется дерево
- 11. Средства управления хранилищем доступ к данным управление хранилищем системные утилиты
- 12. Средства управления хранилищем Взаимодействие с хранилищем: Службы доступа -- связь между процессами Postgres и физическим диском.
- 13. История ORACLE Коммерческая объектно-реляционная универсальная СУБД. 1979 — Oracle v2 первая коммерческая система управления реляционными базами
- 14. История ORACLE 1997 — v8.0: поддержка средств объектно-ориентированной разработки, Oracle становится объектно-реляционной СУБД. 1998 — v8i,
- 15. Файлы. Имеется пять видов файлов, образующих базу данных и поддерживающих экземпляр ‑ файлы параметров, сообщений, данных,
- 16. Пользовательский процесс Серверный процесс PGA База данных и instance (экземпляр) Экземпляр SGA Разделяемый пул DBWR LGWR
- 17. Файлы СУБД В состав базы данных и экземпляра входит шесть типов файлов. С экземпляром связаны файлы
- 18. Взаимосвязь структур хранения и процессов
- 19. Серверные процессы Типовые процессы: ckpt - процесс отвечающий за то, чтобы все изменения данных в памяти
- 20. ЖУРНАЛИРОВАНИЕ И ROLLBACK DB Block Buffers Log Buffer System Global Area Rollback Redo Redo Log Files
- 21. СТРУКТУРА ХРАНИМЫХ ДАННЫХ Единица хранения данных в БД – хранимая запись. Хранимая запись состоит из двух
- 22. СТРУКТУРА ХРАНИМЫХ ДАННЫХ Каждой хранимой записи БД система присваивает внутренний идентификатор, называемый по стандарту CODASYL ключом
- 23. УПРАВЛЕНИЕ ПРОСТРАНСТВОМ ПАМЯТИ Для обеспечения более эффективного управления ресурсами и/или для технологического удобства всё пространство памяти
- 24. Способы управления свободным пространством памяти на страницах: ведение списков свободных участков; динамическая реорганизация страниц. При динамической
- 25. Ведение списков свободных участков. Здесь можно рассмотреть два варианта: Ссылка на первый свободный участок на странице
- 26. ВИДЫ АДРЕСАЦИИ ХРАНИМЫХ ЗАПИСЕЙ: Прямая адресация предусматривает указание непосредственного местоположения записи в пространстве памяти (например, в
- 27. ПРИМЕР КОСВЕННОЙ АДРЕСАЦИИ Часть адресного пространства страницы выделяется под индекс страницы. Число статей (слотов) в нём
- 28. ОСНОВНЫЕ ФИЗИЧЕСКИЕ СТРУКТУРЫ ORACLE TABLESPACE SEGMENT EXTENT BLOCK Файлы – это файлы операционной системы, выделенные для
- 29. ФОРМАТ БЛОКА ДАННЫХ ORACLE Заголовок (общий и переменный) содержит общую информацию блока - адрес блока и
- 31. Скачать презентацию

ТРЕБОВАНИЯ К СУБД:
поддержка целостности данных;
согласованное хранение независимых наборов данных;
извлечение данных и
ТРЕБОВАНИЯ К СУБД:
поддержка целостности данных;
согласованное хранение независимых наборов данных;
извлечение данных и

ЦЕЛОСТНОСТЬ ДАННЫХ
Целостность информации — данные не изменяются при передаче, хранении или
ЦЕЛОСТНОСТЬ ДАННЫХ
Целостность информации — данные не изменяются при передаче, хранении или

Сетевые протоколы
TCP/IP
LU6.2
SPX/IPX
OSI
DECnet
Другие
Независимость от платформ
Оконные менеджеры
MS Windows
X Motif
Macintosh
Другие
Оборудование
Compaq
Sun
HP
IBM
Mac
Другие
NCR
Pyramid
Sequent
Sun
Intel
Операционные системы
OS/390
TRU64
Solaris
AIX
HP Unix
NT
Linux
Другие
Сетевые протоколы
TCP/IP
LU6.2
SPX/IPX
OSI
DECnet
Другие
Независимость от платформ
Оконные менеджеры
MS Windows
X Motif
Macintosh
Другие
Оборудование
Compaq
Sun
HP
IBM
Mac
Другие
NCR
Pyramid
Sequent
Sun
Intel
Операционные системы
OS/390
TRU64
Solaris
AIX
HP Unix
NT
Linux
Другие
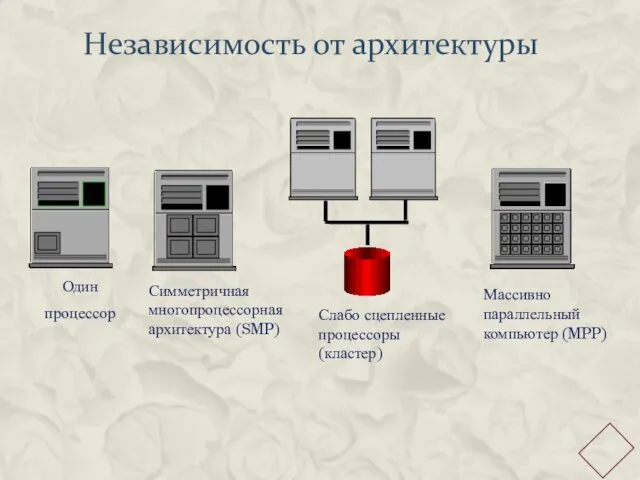
Независимость от архитектуры
Независимость от архитектуры

Поддержка стандартов
Комитеты
ANSI X3H2
X3H2.1 RDA
SQL Access Group
OMG
Стандарты баз данных
FIPS 127-2
ANSI X3-135.1992
Стандарты защиты
Поддержка стандартов
Комитеты
ANSI X3H2
X3H2.1 RDA
SQL Access Group
OMG
Стандарты баз данных
FIPS 127-2
ANSI X3-135.1992
Стандарты защиты

История PostgreSQL
Свободно распространяемая объектно-реляционная СУБД.
1977-1985гг. Ingres - «тренировочный» проект создания
История PostgreSQL
Свободно распространяемая объектно-реляционная СУБД.
1977-1985гг. Ingres - «тренировочный» проект создания

СУБД PostgreSQL
наиболее развитая СУБД с открыты кодом;
надежность и устойчивость при больших
СУБД PostgreSQL
наиболее развитая СУБД с открыты кодом;
надежность и устойчивость при больших
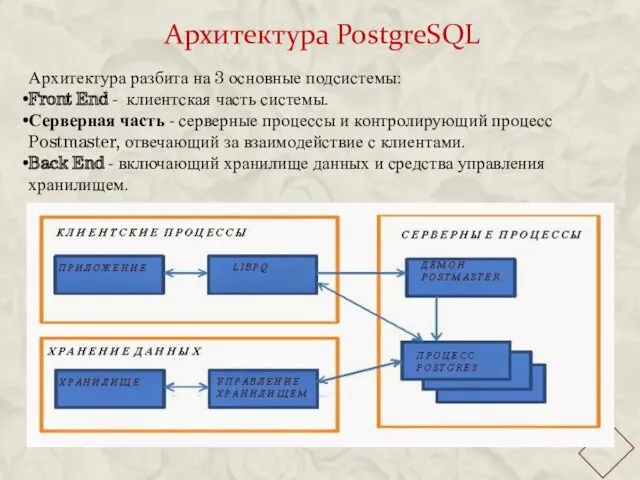
Архитектура PostgreSQL
Архитектура разбита на 3 основные подсистемы:
Front End - клиентская часть
Архитектура PostgreSQL
Архитектура разбита на 3 основные подсистемы:
Front End - клиентская часть
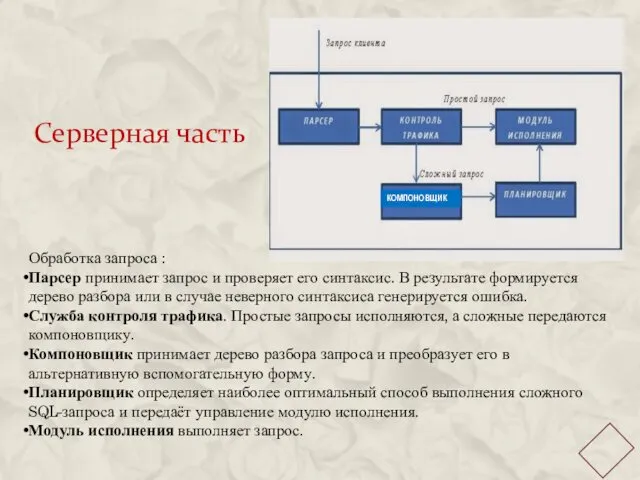
Серверная часть
Обработка запроса :
Парсер принимает запрос и проверяет его синтаксис. В
Серверная часть
Обработка запроса :
Парсер принимает запрос и проверяет его синтаксис. В
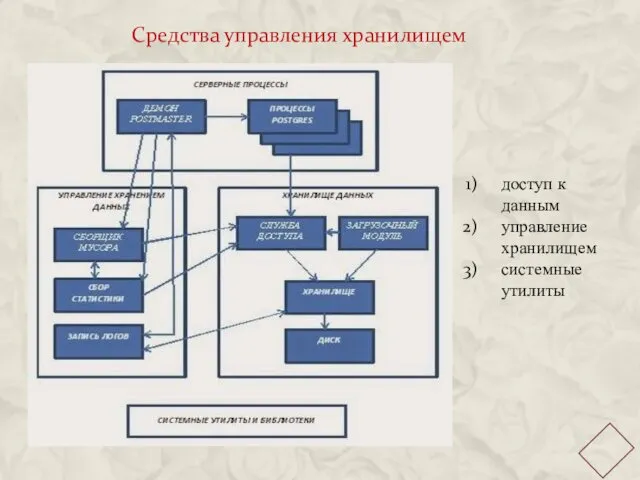
Средства управления хранилищем
доступ к данным
управление хранилищем
системные утилиты
Средства управления хранилищем
доступ к данным
управление хранилищем
системные утилиты

Средства управления хранилищем
Взаимодействие с хранилищем:
Службы доступа -- связь между процессами Postgres
Средства управления хранилищем
Взаимодействие с хранилищем:
Службы доступа -- связь между процессами Postgres

История ORACLE
Коммерческая объектно-реляционная универсальная СУБД.
1979 — Oracle v2 первая коммерческая система
История ORACLE
Коммерческая объектно-реляционная универсальная СУБД.
1979 — Oracle v2 первая коммерческая система

История ORACLE
1997 — v8.0: поддержка средств объектно-ориентированной разработки, Oracle становится объектно-реляционной СУБД.
1998 —
История ORACLE
1997 — v8.0: поддержка средств объектно-ориентированной разработки, Oracle становится объектно-реляционной СУБД.
1998 —

Файлы. Имеется пять видов файлов, образующих базу данных и поддерживающих экземпляр
Файлы. Имеется пять видов файлов, образующих базу данных и поддерживающих экземпляр
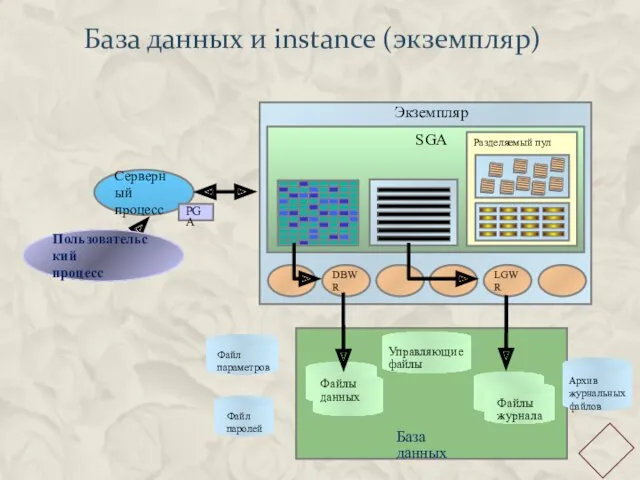
Пользовательский
процесс
Серверный
процесс
PGA
База данных и instance (экземпляр)
Экземпляр
SGA
Разделяемый пул
DBWR
LGWR
База данных
Пользовательский
процесс
Серверный
процесс
PGA
База данных и instance (экземпляр)
Экземпляр
SGA
Разделяемый пул
DBWR
LGWR
База данных

Файлы СУБД
В состав базы данных и экземпляра входит шесть типов файлов.
Файлы СУБД
В состав базы данных и экземпляра входит шесть типов файлов.
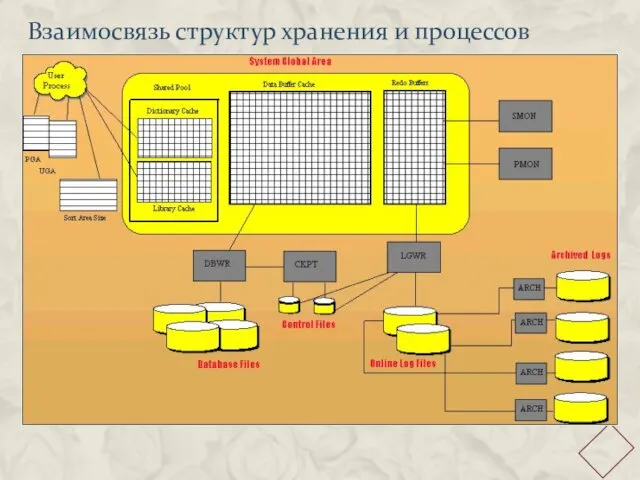
Взаимосвязь структур хранения и процессов
Взаимосвязь структур хранения и процессов

Серверные процессы
Типовые процессы:
ckpt - процесс отвечающий за то, чтобы все изменения
Серверные процессы
Типовые процессы:
ckpt - процесс отвечающий за то, чтобы все изменения

ЖУРНАЛИРОВАНИЕ И ROLLBACK
DB Block Buffers
Log Buffer
System Global Area
Rollback
Redo
Redo Log Files
Журналы используются
ЖУРНАЛИРОВАНИЕ И ROLLBACK
DB Block Buffers
Log Buffer
System Global Area
Rollback
Redo
Redo Log Files
Журналы используются

СТРУКТУРА ХРАНИМЫХ ДАННЫХ
Единица хранения данных в БД – хранимая запись.
СТРУКТУРА ХРАНИМЫХ ДАННЫХ
Единица хранения данных в БД – хранимая запись.

СТРУКТУРА ХРАНИМЫХ ДАННЫХ
Каждой хранимой записи БД система присваивает внутренний идентификатор,
СТРУКТУРА ХРАНИМЫХ ДАННЫХ
Каждой хранимой записи БД система присваивает внутренний идентификатор,

УПРАВЛЕНИЕ ПРОСТРАНСТВОМ ПАМЯТИ
Для обеспечения более эффективного управления ресурсами и/или для технологического
УПРАВЛЕНИЕ ПРОСТРАНСТВОМ ПАМЯТИ
Для обеспечения более эффективного управления ресурсами и/или для технологического

Способы управления свободным пространством памяти на страницах:
ведение списков свободных участков;
динамическая реорганизация
Способы управления свободным пространством памяти на страницах:
ведение списков свободных участков;
динамическая реорганизация

Ведение списков свободных участков.
Здесь можно рассмотреть два варианта:
Ссылка на первый
Ведение списков свободных участков.
Здесь можно рассмотреть два варианта:
Ссылка на первый

ВИДЫ АДРЕСАЦИИ ХРАНИМЫХ ЗАПИСЕЙ:
Прямая адресация предусматривает указание непосредственного местоположения записи в
ВИДЫ АДРЕСАЦИИ ХРАНИМЫХ ЗАПИСЕЙ:
Прямая адресация предусматривает указание непосредственного местоположения записи в
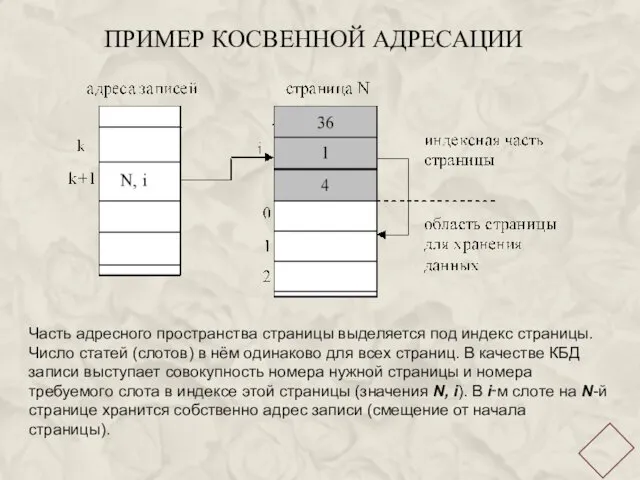
ПРИМЕР КОСВЕННОЙ АДРЕСАЦИИ
Часть адресного пространства страницы выделяется под индекс страницы. Число
ПРИМЕР КОСВЕННОЙ АДРЕСАЦИИ
Часть адресного пространства страницы выделяется под индекс страницы. Число

ОСНОВНЫЕ ФИЗИЧЕСКИЕ СТРУКТУРЫ ORACLE
TABLESPACE
SEGMENT
EXTENT
BLOCK
Файлы – это файлы операционной системы, выделенные для
ОСНОВНЫЕ ФИЗИЧЕСКИЕ СТРУКТУРЫ ORACLE
TABLESPACE
SEGMENT
EXTENT
BLOCK
Файлы – это файлы операционной системы, выделенные для

ФОРМАТ БЛОКА ДАННЫХ ORACLE
Заголовок (общий и переменный) содержит общую информацию
ФОРМАТ БЛОКА ДАННЫХ ORACLE
Заголовок (общий и переменный) содержит общую информацию
 Кодирование информации с помощью знаковых систем. Знаки: форма и значение. Знаковые системы
Кодирование информации с помощью знаковых систем. Знаки: форма и значение. Знаковые системы Многоуровневая компьютерная организация, компиляция, типы данных, основные операторы языка C. Лекция 1
Многоуровневая компьютерная организация, компиляция, типы данных, основные операторы языка C. Лекция 1 9_5.1
9_5.1 Порядок создания автоматизированных систем в защищенном исполнении
Порядок создания автоматизированных систем в защищенном исполнении Информатика. Методическое пособие. Лекция 2
Информатика. Методическое пособие. Лекция 2 Задание №5. Рекомендации по комплексу программных средств для ИС для банка
Задание №5. Рекомендации по комплексу программных средств для ИС для банка Системы счисления
Системы счисления Основные понятия компьютерной графики. Цветовой круг Ньютона
Основные понятия компьютерной графики. Цветовой круг Ньютона Отладка и пуск. Siemens
Отладка и пуск. Siemens Файлы и файловая система
Файлы и файловая система Управління даними (файли і файлові системи)
Управління даними (файли і файлові системи) Системы ввода/вывода. Лекция 11
Системы ввода/вывода. Лекция 11 Функции
Функции Как найти информацию о стажировках
Как найти информацию о стажировках Программы Microsoft Office
Программы Microsoft Office Пользовательский интерфейс. (7 класс)
Пользовательский интерфейс. (7 класс) Сжатие, архивация и разархивация данных. Архиваторы. Работа с архивами. Урок 16
Сжатие, архивация и разархивация данных. Архиваторы. Работа с архивами. Урок 16 Оператор цикла с постусловием
Оператор цикла с постусловием Основы баз данных и SQL. Аналитические функции v2.0
Основы баз данных и SQL. Аналитические функции v2.0 Цифровое видео
Цифровое видео Шифраторы и дешифраторы. Сумматоры и полусумматоры. (Тема 9)
Шифраторы и дешифраторы. Сумматоры и полусумматоры. (Тема 9) Строка - упорядоченная последовательность символов
Строка - упорядоченная последовательность символов Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих
Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих Проект патріотична гра. Краєзнавчий online-етап “Мереживо свят Донеччини”
Проект патріотична гра. Краєзнавчий online-етап “Мереживо свят Донеччини” Информационное обеспечение ИТ управления организацией
Информационное обеспечение ИТ управления организацией Для чего нужны СМИ
Для чего нужны СМИ Импорт и экспорт данных. Лекция 1
Импорт и экспорт данных. Лекция 1 Правовая информатика как отрасль общей информатики и прикладная юридическая наука
Правовая информатика как отрасль общей информатики и прикладная юридическая наука