- ASN and deduplication training

Содержание
- 2. Integration to platform
- 3. Vault without deduplication Storage TIB files format is the same as on unmanaged vault. TIBs are
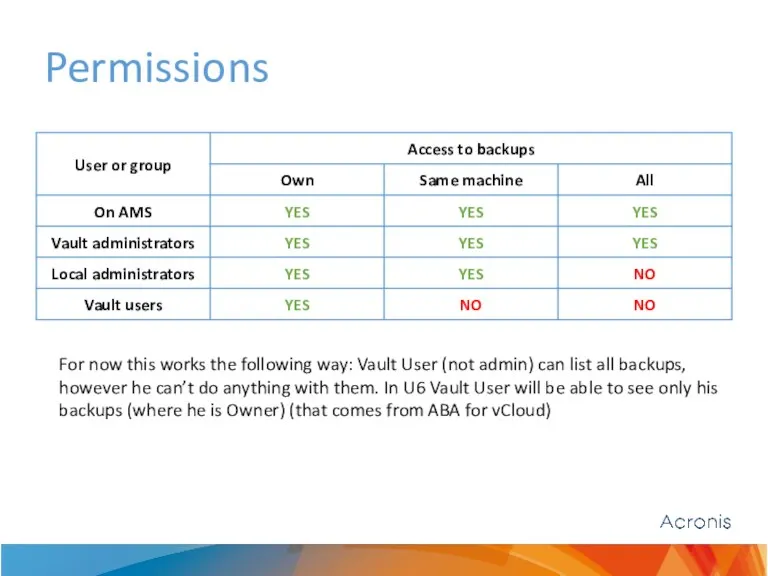
- 4. Permissions For now this works the following way: Vault User (not admin) can list all backups,
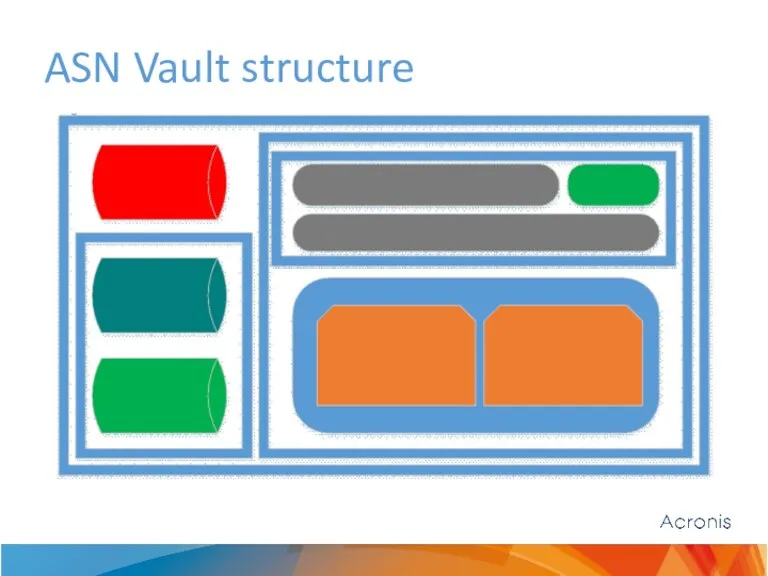
- 5. ASN Vault structure
- 6. Deduplicated vault Recommendations: Put Index (dedup) database on separate storage. Exclude all paths for vault from
- 7. Backup 2 streams (connections): Header/metadata/links are stored in TIB file Actual data Blocks are stored in
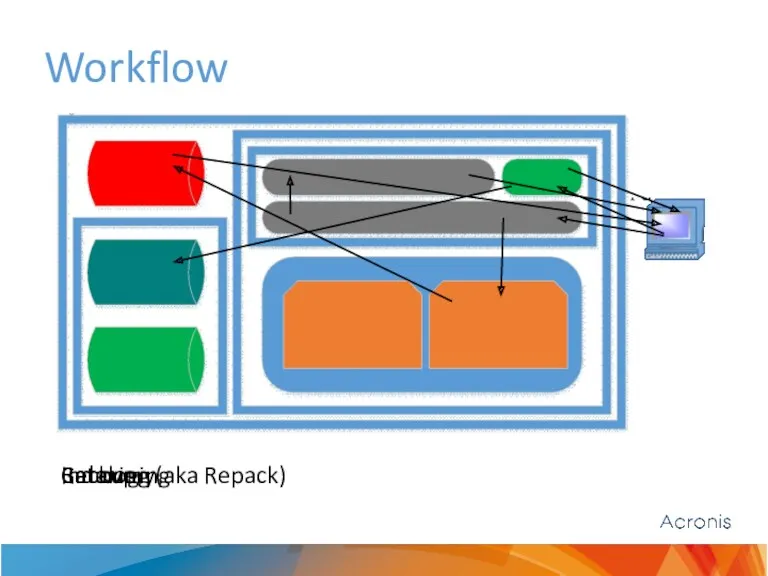
- 8. Workflow Backup Indexing (aka Repack) Cataloging Recovery
- 9. Indexing Indexing moves unique blocks from LDS file (backup contents) to Datastore. Indexing is queued for
- 10. Datastore
- 11. Datastore Datastore stores blocks Single datastore for all backup kinds Blocks are stored in two datastore
- 12. Block size Block size Image backups: 4 Kb File backups: 1b – 256Kb Blocks are compared
- 13. Deduplication Database
- 14. Deduplication Database Dedup DB is required for fast blocks access by fingerprints. It stores HASH of
- 15. Deduplication Database Index is rebuilt after compacting. Rebuilding of index works fast (with disk reading speed).
- 16. Compacting Compacting Compacting: check deleted data size Compacting: validate all backups (mark used blocks) Compacting: Remove
- 17. Compacting Check 1 (fast): Deleted backups size Mark all blocks as not used Mark only used
- 18. Export / Replication Backups are being un-deduplicated Possible to Export to local folder without agent installed
- 19. Validation Validation of backups/archives validates only existence of hashes in Dedup DB (on disk and file
- 20. Attach / detach Detach Vault meta-info db (.fdb) is copied to vault (storage) location. Attach During
- 21. Deduplication at source Faster backups (up to x6) Bandwidth saved (up to x200)
- 22. Compression Normal level – best choice for most cases. When deduplication is provided by Filesystem or
- 23. Vault meta structure Vault meta files are located in: \BackupAndRecovery\ASN\.meta 1 file per vault. There is
- 24. Vault meta files Inside of the vault there is .meta folder. The folder contains meta for
- 25. DML Database ASN DML Database is located in \BackupAndRecovery\ASN\DmlDatabase\asn_dml_objects.db3 It is used for infrastructure integration of
- 26. ASN logs ANS logs are located in \BackupAndRecovery\ASN\Logs And \BackupAndRecovery\ASN\events.db3 For events.db3 use Yalp. It is
- 27. ASN and Tapes ASN is the service that writes to tape. ARSM is responsible for: 1.
- 28. ASN and OB When backing up to ASN and replicating to cloud here is how it
- 29. Metadata Issues Fixing issues: 1. Reindex: acrocmd reindex vault –loc=bsp://ASN_IP/vault 2. Ultimate reindex: Detach vault remove
- 30. Vault is corrupted When ASN says that vault is corrupted check events.db3 .tmp files in .meta
- 31. Storage Node is busy. Usually a deadlock. Most likely caused not by connection limiter itself. If
- 33. Скачать презентацию
Integration to platform
Integration to platform

Vault without deduplication
Storage
TIB files format is the same as on unmanaged
Vault without deduplication
Storage
TIB files format is the same as on unmanaged
Permissions
For now this works the following way: Vault User (not admin)
Permissions
For now this works the following way: Vault User (not admin)
ASN Vault structure
ASN Vault structure

Deduplicated vault
Recommendations:
Put Index (dedup) database on separate storage.
Exclude all paths for
Deduplicated vault
Recommendations:
Put Index (dedup) database on separate storage.
Exclude all paths for

Backup
2 streams (connections):
Header/metadata/links are stored in TIB file
Actual data Blocks are
Backup
2 streams (connections):
Header/metadata/links are stored in TIB file
Actual data Blocks are
Workflow
Backup
Indexing (aka Repack)
Cataloging
Recovery
Workflow
Backup
Indexing (aka Repack)
Cataloging
Recovery

Indexing
Indexing moves unique blocks from LDS file (backup contents) to Datastore.
Indexing
Indexing
Indexing moves unique blocks from LDS file (backup contents) to Datastore.
Indexing
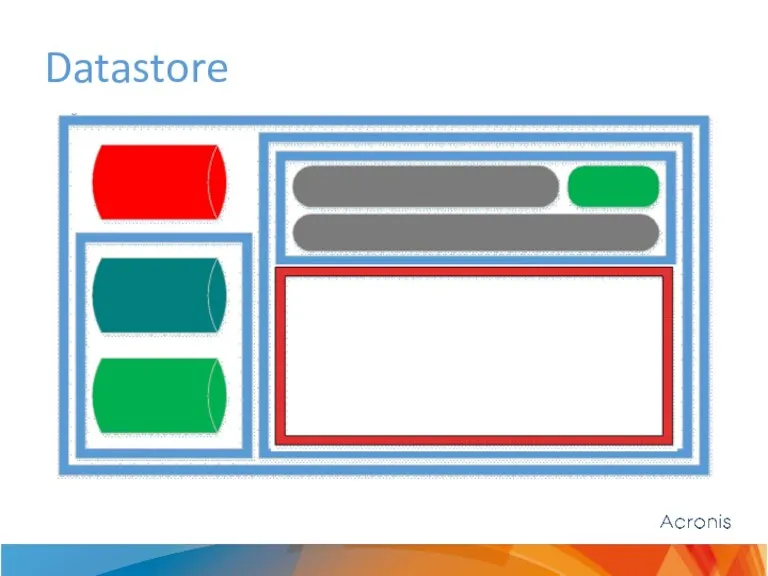
Datastore
Datastore

Datastore
Datastore stores blocks
Single datastore for all backup kinds
Blocks are stored in
Datastore
Datastore stores blocks
Single datastore for all backup kinds
Blocks are stored in

Block size
Block size
Image backups: 4 Kb
File backups: 1b – 256Kb
Blocks are
Block size
Block size
Image backups: 4 Kb
File backups: 1b – 256Kb
Blocks are
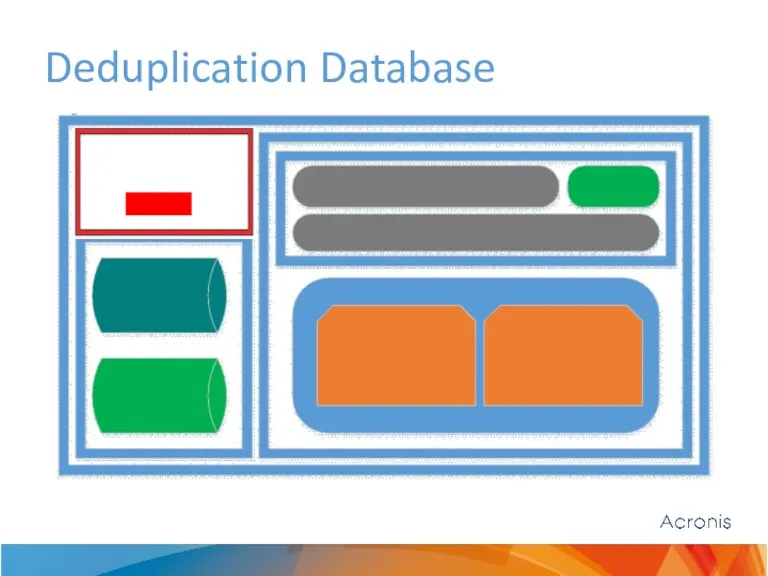
Deduplication Database
Deduplication Database

Deduplication Database
Dedup DB is required for fast blocks access by fingerprints.
Deduplication Database
Dedup DB is required for fast blocks access by fingerprints.

Deduplication Database
Index is rebuilt after compacting. Rebuilding of index works fast
Deduplication Database
Index is rebuilt after compacting. Rebuilding of index works fast
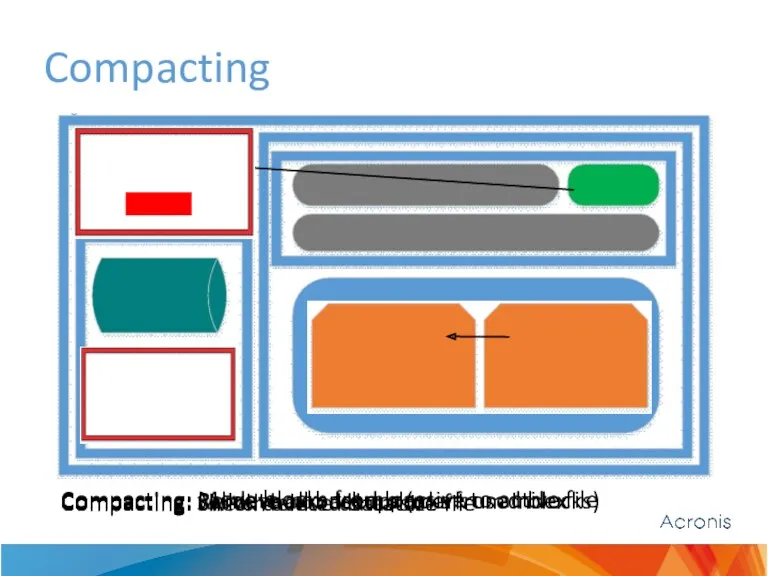
Compacting
Compacting
Compacting: check deleted data size
Compacting: validate all backups (mark used blocks)
Compacting:
Compacting
Compacting
Compacting: check deleted data size
Compacting: validate all backups (mark used blocks)
Compacting:

Compacting
Check 1 (fast): Deleted backups size
Mark all blocks as not used
Mark
Compacting
Check 1 (fast): Deleted backups size
Mark all blocks as not used
Mark

Export / Replication
Backups are being un-deduplicated
Possible to Export to local folder
Export / Replication
Backups are being un-deduplicated
Possible to Export to local folder

Validation
Validation of backups/archives validates only existence of hashes in Dedup DB
Validation
Validation of backups/archives validates only existence of hashes in Dedup DB

Attach / detach
Detach
Vault meta-info db (.fdb) is copied to vault (storage)
Attach / detach
Detach
Vault meta-info db (.fdb) is copied to vault (storage)
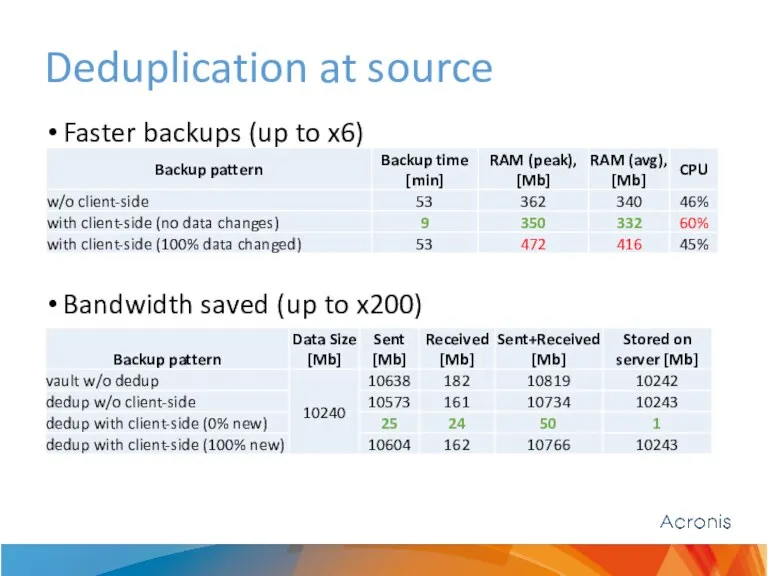
Deduplication at source
Faster backups (up to x6)
Bandwidth saved (up to x200)
Deduplication at source
Faster backups (up to x6)
Bandwidth saved (up to x200)

Compression
Normal level – best choice for most cases.
When deduplication is provided
Compression
Normal level – best choice for most cases.
When deduplication is provided

Vault meta structure
Vault meta files are located in: \BackupAndRecovery\ASN\.meta
1 file per
Vault meta structure
Vault meta files are located in: \BackupAndRecovery\ASN\.meta
1 file per

Vault meta files
Inside of the vault there is .meta folder. The
Vault meta files
Inside of the vault there is .meta folder. The

DML Database
ASN DML Database is located in \BackupAndRecovery\ASN\DmlDatabase\asn_dml_objects.db3
It is used for
DML Database
ASN DML Database is located in \BackupAndRecovery\ASN\DmlDatabase\asn_dml_objects.db3
It is used for

ASN logs
ANS logs are located in
\BackupAndRecovery\ASN\Logs
And
\BackupAndRecovery\ASN\events.db3
For events.db3 use Yalp.
It
ASN logs
ANS logs are located in
\BackupAndRecovery\ASN\Logs
And
\BackupAndRecovery\ASN\events.db3
For events.db3 use Yalp.
It

ASN and Tapes
ASN is the service that writes to tape.
ARSM is
ASN and Tapes
ASN is the service that writes to tape.
ARSM is

ASN and OB
When backing up to ASN and replicating to cloud
ASN and OB
When backing up to ASN and replicating to cloud

Metadata Issues
Fixing issues:
1. Reindex: acrocmd reindex vault –loc=bsp://ASN_IP/vault
2. Ultimate reindex:
Detach
Metadata Issues
Fixing issues:
1. Reindex: acrocmd reindex vault –loc=bsp://ASN_IP/vault
2. Ultimate reindex:
Detach

Vault is corrupted
When ASN says that vault is corrupted check events.db3
.tmp
Vault is corrupted
When ASN says that vault is corrupted check events.db3
.tmp

Storage Node is busy.
Usually a deadlock. Most likely caused not
Storage Node is busy.
Usually a deadlock. Most likely caused not
 Алгоритмы обработки массивов
Алгоритмы обработки массивов Здоровье-сберегающие технологии на уроках информатики
Здоровье-сберегающие технологии на уроках информатики Цифрова обробка сигналів. Лекція 1. Вступ до дисципліни
Цифрова обробка сигналів. Лекція 1. Вступ до дисципліни Штриховое кодирование товаров
Штриховое кодирование товаров Новый стандарт ГОСТ 7.1: 2006 Библиографическая запись. Библиографическое описание. Общие требования и правила составления
Новый стандарт ГОСТ 7.1: 2006 Библиографическая запись. Библиографическое описание. Общие требования и правила составления Система управления в программно - конфигурируемых сетях
Система управления в программно - конфигурируемых сетях Утиліти для роботи з дисками. 9 клас
Утиліти для роботи з дисками. 9 клас Готовим инфографику
Готовим инфографику Прикладные программы Microsoft Office
Прикладные программы Microsoft Office Команды создания графических объектов. Слои
Команды создания графических объектов. Слои PL/SQL API для работы с XMLType (ORACLE)
PL/SQL API для работы с XMLType (ORACLE) Апаратно-програмне забезпечення комп’ютера
Апаратно-програмне забезпечення комп’ютера ФАЙЛОВАЯ СИСТЕМА – хаос или порядок?
ФАЙЛОВАЯ СИСТЕМА – хаос или порядок? Тестування програмного забезпечення
Тестування програмного забезпечення Реализация логических операций в компьютере
Реализация логических операций в компьютере Лекция 25. Пролог. Решение логических задач
Лекция 25. Пролог. Решение логических задач Двумерные массивы
Двумерные массивы Арифметические операциив 2-й системе счисления
Арифметические операциив 2-й системе счисления Качество процесса разработки ПО
Качество процесса разработки ПО Как создать свой YouTube канал
Как создать свой YouTube канал Git: установка
Git: установка Информационное моделирование. Модели объектов и их назначение. Разнообразие информационных моделей. (6 класс)
Информационное моделирование. Модели объектов и их назначение. Разнообразие информационных моделей. (6 класс) Искусство научной иллюстрации
Искусство научной иллюстрации Библиографическое описание
Библиографическое описание Решение задач линейного программирования (симплекс-метод)
Решение задач линейного программирования (симплекс-метод) Алгоритмы с ветвлением
Алгоритмы с ветвлением Steps in Normalization
Steps in Normalization Кодирование графической информации
Кодирование графической информации