- Базовые протоколы TCP/IP

Содержание
- 2. Обзор Протоколы транспортного уровня TCP и UDP 1.1 Порты и сокеты 1.2. Протокол UDP и UDP-дейтаграммы
- 3. Базовые протоколы TCP/IP Протоколы TCP и UDP исполняют посредническую роль между приложениями и транспортной инфраструктурой сети.
- 4. К транспортному уровню стека TCP/IP относятся: протокол управления передачей (Transmission Control Protocol, TCP), описанный в стандарте
- 5. Мультиплексирование и демультиплексирование на транспортном уровне. Существует и обратная задача: данные, генерируемые разными приложениями, работающими на
- 6. Протоколы TCP и UDP ведут для каждого приложения две системные очереди: очередь данных, поступающих к приложению
- 7. Динамические номера являются уникальными в пределах каждого компьютера, но при этом обычной является ситуация совпадения номеров
- 8. Пусть, например, на одном хосте запущены две копии DNS-сервера — DNS-сервер 1, DNS-сервер 2. Демультиплексирование протокола
- 9. При работе на хосте-отправителе данные от приложений поступают протоколу UDP через порт в виде сообщений (см.
- 10. Каждая дейтаграмма переносит отдельное пользовательское сообщение. Сообщения могут иметь различную длину, не превышающую однако длину поля
- 11. Работая на хосте-получателе, протокол UDP принимает от протокола IP извлеченные из пакетов UDP-дейтаграммы. Полученные из IP-заголовка
- 12. Заголовок TCP-сегмента содержит значительно больше полей, чем заголовок UDP, что отражает более развитые возможности протокола TCP.
- 13. Краткие описания большинства полей помещены на рисунке, а более подробно мы их рассмотрим, когда будем изучать
- 14. Основным отличием TCP от UDP является то, что на протокол TCP возложена дополнительная задача — обеспечить
- 15. В протоколе TCP каждая сторона соединения посылает противоположной стороне следующие параметры: максимальный размер сегмента, который она
- 16. Получив запрос, модуль TCP на стороне сервера пытается создать «инфраструктуру» для обслуживания нового клиента. Он обращается
- 17. Соединение может быть разорвано в любой момент по инициативе любой стороны. Для этого клиент и сервер
- 18. А теперь рассмотрим на примере, как протокол TCP выполняет демультиплексирование. Пусть некий поставщик услуг оказывает услугу
- 19. Один из наиболее естественных приемов, используемых для организации надёжной передачи — это квитирование. Отправитель отсылает данные
- 20. Достаточно очевидно, что при использовании данного метода производительность обмена данными ниже потенциально возможной — передатчик мог
- 21. В начальный момент, когда еще не послано ни одного кадра, окно определяет диапазон номеров кадров от
- 22. Алгоритм скользящего окна в протоколе TCP имеет некоторые существенные особенности. В частности, в рассмотренном обобщенном алгоритме
- 23. На рисунке ниже показаны четыре сегмента размером 1460 байт и один — 870 байт. Идентификаторами этих
- 24. Поскольку протокол TCP является дуплексным, каждая сторона одновременно выступает и как отправитель, и как получатель. У
- 25. На рисунке ниже показан поток байтов, поступающий от приложения в выходной буфер модуля TCP. Из потока
- 26. Получатель может послать квитанцию, подтверждающую получение сразу нескольких сегментов, если они образуют непрерывный поток байтов. Например,
- 27. Когда протокол TCP передает в сеть сегмент, он «на всякий случай» помещает его копию в буфер,
- 28. Управление потоком Какой размер окна должен назначить источник приемнику, и наоборот? Точнее, каким на каждой из
- 29. Управление потоком Варьируя величину окна, можно влиять на загрузку сети. Чем больше окно, тем большая порция
- 30. Управление потоком Признаком перегрузки TCP-соединения является возникновение очередей на промежуточных узлах (маршрутизаторах) и на конечных узлах
- 31. Общие свойства и классификация протоколов маршрутизации Протоколы маршрутизации обеспечивают поиск и фиксацию маршрутов продвижения данных через
- 32. Общие свойства и классификация протоколов маршрутизации Тем не менее большинство протоколов маршрутизации нацелено на создание таблиц
- 33. Общие свойства и классификация протоколов маршрутизации Различают протоколы, выполняющие статическую и адаптивную (динамическую) маршрутизацию. При статической
- 34. Общие свойства и классификация протоколов маршрутизации Протоколы адаптивной маршрутизации бывают распределенными и централизованными. При распределенном подходе
- 35. Общие свойства и классификация протоколов маршрутизации Получив от некоторого соседа вектор расстояний (дистанций) до известных тому
- 36. Протокол RIP Построение таблицы маршрутизации Протокол RIP (Routing Information Protocol — протокол маршрутной информации) является внутренним
- 37. Протокол RIP Построение таблицы маршрутизации Этап 1 - создание минимальной таблицы. Данная составная сеть включает восемь
- 38. Протокол RIP Построение таблицы маршрутизации Этап 2 — рассылка минимальной таблицы соседям. После инициализации каждый маршрутизатор
- 39. Протокол RIP Построение таблицы маршрутизации Этап 3 — получение RIP-сообщений от соседей и обработка полученной информации.
- 40. Протокол RIP Построение таблицы маршрутизации Этап 4 — рассылка новой таблицы соседям. Каждый маршрутизатор отсылает новое
- 41. Протокол RIP Построение таблицы маршрутизации Если маршрутизаторы периодически повторяют этапы рассылки и обработки RIP-сообщений, то за
- 42. Адаптация маршрутизаторов RIP к изменениям состояния сети К новым маршрутам маршрутизаторы RIP приспосабливаются просто — они
- 43. Если какой-либо маршрутизатор отказывает, переставая слать своим соседям сообщения о сетях, которые можно достичь через него,
- 44. Пример зацикливания пакетов Рассмотрим случай зацикливания пакетов на примере сети, изображенной на рисунке. Пусть маршрутизатор R1
- 45. Пример зацикливания пакетов Далее маршрутизатор R1 получает новую информацию о сети 201.36.14.0 — эта сеть достижима
- 46. Пример зацикливания пакетов Время 0-180 с. После отказа интерфейса в маршрутизаторах R1 и R2 будут сохраняться
- 47. Пример зацикливания пакетов Ограничение в 15 хопов сужает область применения протокола RIP до сетей, в которых
- 48. Методы борьбы с ложными маршрутами в протоколе RIP Хотя протокол RIP не в состоянии полностью исключить
- 49. Методы борьбы с ложными маршрутами в протоколе RIP Для предотвращения зацикливания пакетов по составным петлям при
- 50. Протокол OSPF. Два этапа построения таблицы маршрутизации Протокол OSPF (Open Shortest Path First — выбор кратчайшего
- 51. Протокол OSPF. Два этапа построения таблицы маршрутизации Для контроля состояния связей и соседних маршрутизаторов OSPF-маршрутизаторы передают
- 52. Протокол OSPF. Два этапа построения таблицы маршрутизации Если состояние связей в сети изменилось и произошла корректировка
- 53. Метрики При поиске оптимальных маршрутов протокол OSPF по умолчанию использует метрику, учитывающую пропускную способность каналов связи.
- 55. Скачать презентацию

Обзор
Протоколы транспортного уровня TCP и UDP
1.1 Порты и сокеты
1.2. Протокол UDP
Обзор
Протоколы транспортного уровня TCP и UDP
1.1 Порты и сокеты
1.2. Протокол UDP

Базовые протоколы TCP/IP
Протоколы TCP и UDP исполняют посредническую роль между
Базовые протоколы TCP/IP
Протоколы TCP и UDP исполняют посредническую роль между

К транспортному уровню стека TCP/IP относятся:
протокол управления передачей (Transmission Control Protocol,
К транспортному уровню стека TCP/IP относятся:
протокол управления передачей (Transmission Control Protocol,
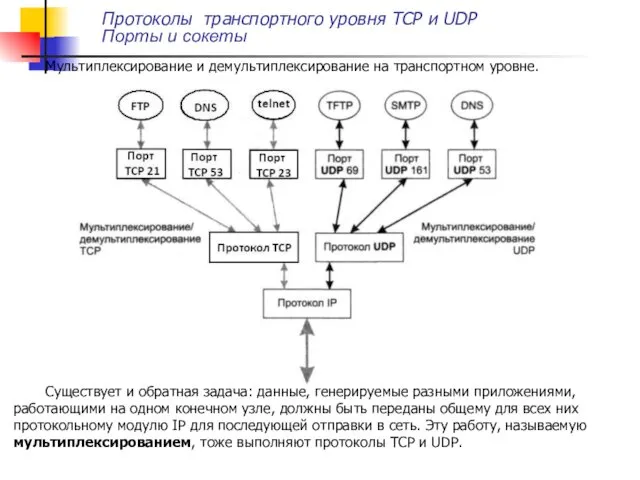
Мультиплексирование и демультиплексирование на транспортном уровне.
Существует и обратная задача: данные, генерируемые
Мультиплексирование и демультиплексирование на транспортном уровне.
Существует и обратная задача: данные, генерируемые

Протоколы TCP и UDP ведут для каждого приложения две системные очереди:
Протоколы TCP и UDP ведут для каждого приложения две системные очереди:

Динамические номера являются уникальными в пределах каждого компьютера, но
Динамические номера являются уникальными в пределах каждого компьютера, но
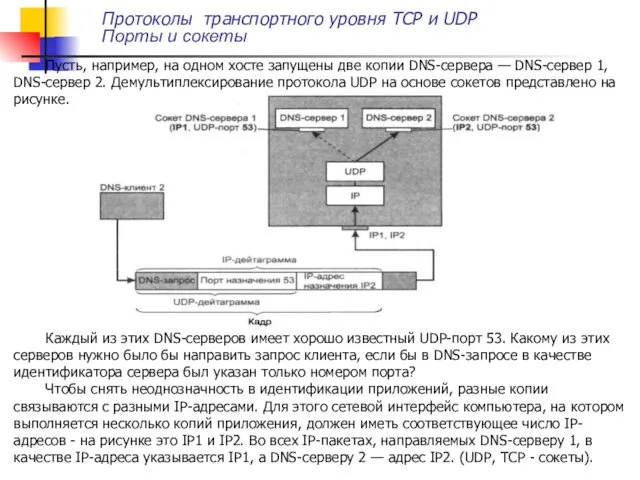
Пусть, например, на одном хосте запущены две копии DNS-сервера — DNS-сервер
Пусть, например, на одном хосте запущены две копии DNS-сервера — DNS-сервер
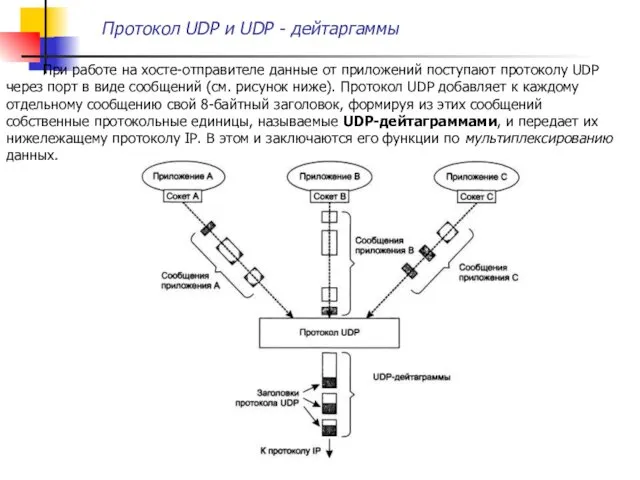
При работе на хосте-отправителе данные от приложений поступают протоколу UDP
При работе на хосте-отправителе данные от приложений поступают протоколу UDP

Каждая дейтаграмма переносит отдельное пользовательское сообщение. Сообщения могут иметь различную длину,
Каждая дейтаграмма переносит отдельное пользовательское сообщение. Сообщения могут иметь различную длину,
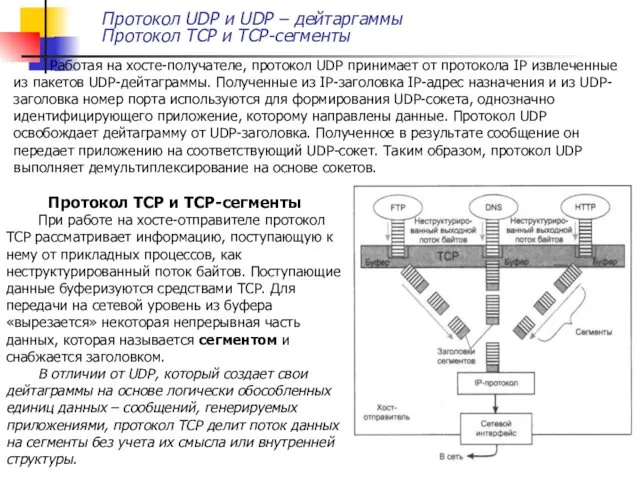
Работая на хосте-получателе, протокол UDP принимает от протокола IP извлеченные
Работая на хосте-получателе, протокол UDP принимает от протокола IP извлеченные

Заголовок TCP-сегмента содержит значительно больше полей, чем заголовок UDP, что
Заголовок TCP-сегмента содержит значительно больше полей, чем заголовок UDP, что

Краткие описания большинства полей помещены на рисунке, а более подробно мы
Краткие описания большинства полей помещены на рисунке, а более подробно мы

Основным отличием TCP от UDP является то, что на протокол
Основным отличием TCP от UDP является то, что на протокол

В протоколе TCP каждая сторона соединения посылает противоположной стороне следующие параметры:
максимальный
В протоколе TCP каждая сторона соединения посылает противоположной стороне следующие параметры:
максимальный
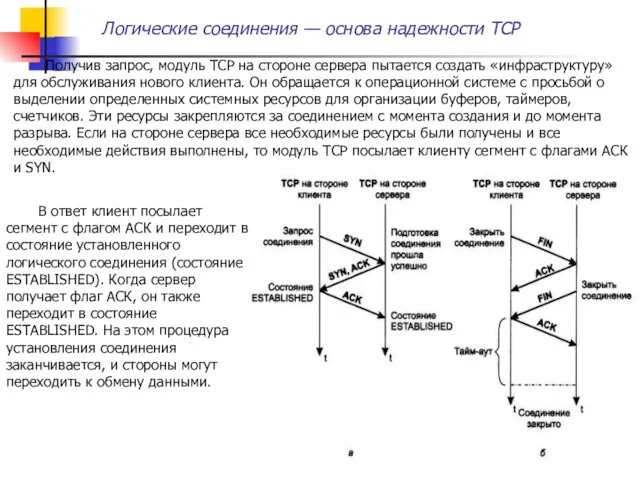
Получив запрос, модуль TCP на стороне сервера пытается создать «инфраструктуру» для
Получив запрос, модуль TCP на стороне сервера пытается создать «инфраструктуру» для
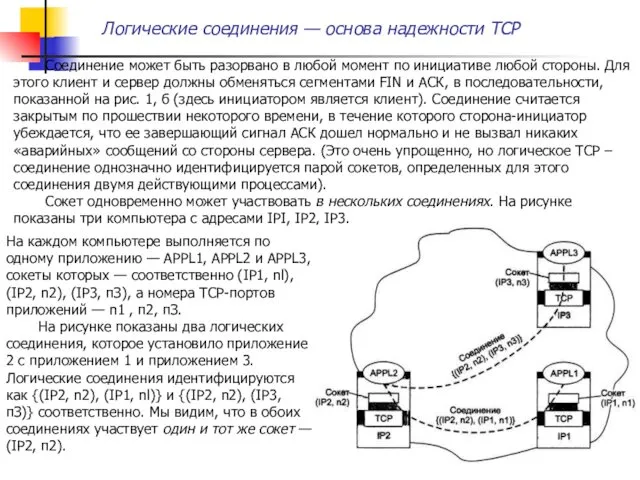
Соединение может быть разорвано в любой момент по инициативе любой стороны.
Соединение может быть разорвано в любой момент по инициативе любой стороны.

А теперь рассмотрим на примере, как протокол TCP выполняет демультиплексирование.
А теперь рассмотрим на примере, как протокол TCP выполняет демультиплексирование.
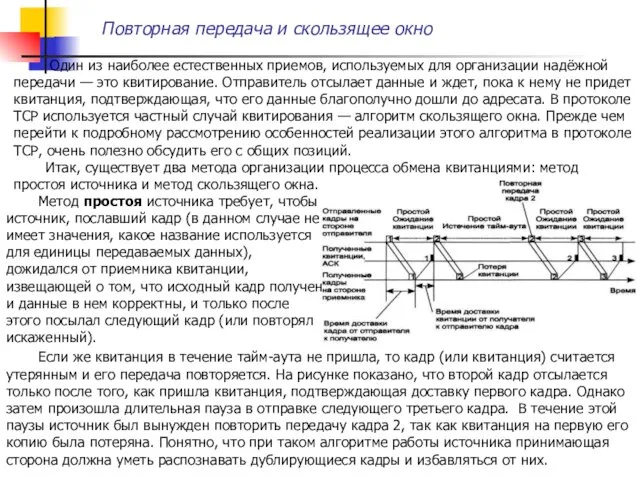
Один из наиболее естественных приемов, используемых для организации надёжной передачи
Один из наиболее естественных приемов, используемых для организации надёжной передачи
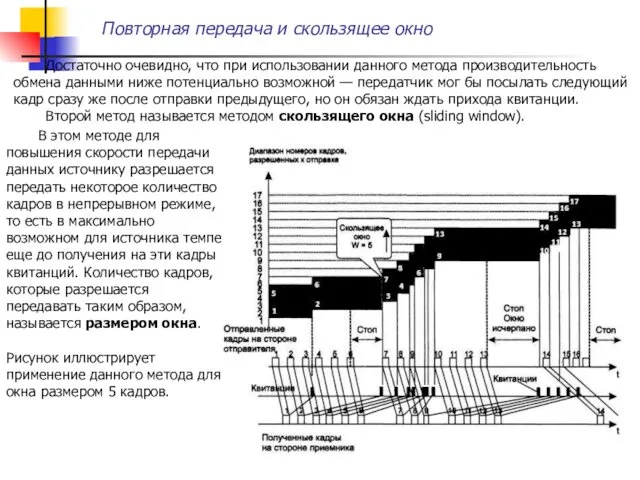
Достаточно очевидно, что при использовании данного метода производительность обмена данными ниже
Достаточно очевидно, что при использовании данного метода производительность обмена данными ниже

В начальный момент, когда еще не послано ни одного кадра,
В начальный момент, когда еще не послано ни одного кадра,

Алгоритм скользящего окна в протоколе TCP имеет некоторые существенные особенности. В
Алгоритм скользящего окна в протоколе TCP имеет некоторые существенные особенности. В

На рисунке ниже показаны четыре сегмента размером 1460 байт и
На рисунке ниже показаны четыре сегмента размером 1460 байт и
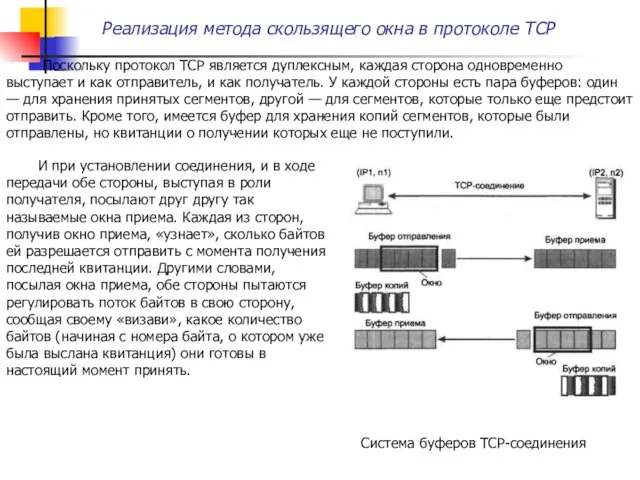
Поскольку протокол TCP является дуплексным, каждая сторона одновременно выступает и
Поскольку протокол TCP является дуплексным, каждая сторона одновременно выступает и

На рисунке ниже показан поток байтов, поступающий от приложения в выходной
На рисунке ниже показан поток байтов, поступающий от приложения в выходной

Получатель может послать квитанцию, подтверждающую получение сразу нескольких сегментов, если они
Получатель может послать квитанцию, подтверждающую получение сразу нескольких сегментов, если они

Когда протокол TCP передает в сеть сегмент, он «на всякий случай»
Когда протокол TCP передает в сеть сегмент, он «на всякий случай»

Управление потоком
Какой размер окна должен назначить источник приемнику, и наоборот?
Управление потоком
Какой размер окна должен назначить источник приемнику, и наоборот?

Управление потоком
Варьируя величину окна, можно влиять на загрузку сети. Чем
Управление потоком
Варьируя величину окна, можно влиять на загрузку сети. Чем

Управление потоком
Признаком перегрузки TCP-соединения является возникновение очередей на промежуточных узлах
Управление потоком
Признаком перегрузки TCP-соединения является возникновение очередей на промежуточных узлах

Общие свойства и классификация протоколов маршрутизации
Протоколы маршрутизации обеспечивают поиск и
Общие свойства и классификация протоколов маршрутизации
Протоколы маршрутизации обеспечивают поиск и

Общие свойства и классификация протоколов маршрутизации
Тем не менее большинство протоколов
Общие свойства и классификация протоколов маршрутизации
Тем не менее большинство протоколов

Общие свойства и классификация протоколов маршрутизации
Различают протоколы, выполняющие статическую и адаптивную
Общие свойства и классификация протоколов маршрутизации
Различают протоколы, выполняющие статическую и адаптивную

Общие свойства и классификация протоколов маршрутизации
Протоколы адаптивной маршрутизации бывают распределенными
Общие свойства и классификация протоколов маршрутизации
Протоколы адаптивной маршрутизации бывают распределенными

Общие свойства и классификация протоколов маршрутизации
Получив от некоторого соседа вектор
Общие свойства и классификация протоколов маршрутизации
Получив от некоторого соседа вектор

Протокол RIP
Построение таблицы маршрутизации
Протокол RIP (Routing Information Protocol —
Протокол RIP
Построение таблицы маршрутизации
Протокол RIP (Routing Information Protocol —

Протокол RIP
Построение таблицы маршрутизации
Этап 1 - создание минимальной таблицы.
Протокол RIP
Построение таблицы маршрутизации
Этап 1 - создание минимальной таблицы.

Протокол RIP
Построение таблицы маршрутизации
Этап 2 — рассылка минимальной таблицы
Протокол RIP
Построение таблицы маршрутизации
Этап 2 — рассылка минимальной таблицы

Протокол RIP
Построение таблицы маршрутизации
Этап 3 — получение RIP-сообщений от
Протокол RIP
Построение таблицы маршрутизации
Этап 3 — получение RIP-сообщений от

Протокол RIP
Построение таблицы маршрутизации
Этап 4 — рассылка новой таблицы соседям.
Протокол RIP
Построение таблицы маршрутизации
Этап 4 — рассылка новой таблицы соседям.

Протокол RIP
Построение таблицы маршрутизации
Если маршрутизаторы периодически повторяют этапы рассылки
Протокол RIP
Построение таблицы маршрутизации
Если маршрутизаторы периодически повторяют этапы рассылки

Адаптация маршрутизаторов RIP
к изменениям состояния сети
К новым маршрутам маршрутизаторы
Адаптация маршрутизаторов RIP
к изменениям состояния сети
К новым маршрутам маршрутизаторы

Если какой-либо маршрутизатор отказывает, переставая слать своим соседям сообщения о сетях,
Если какой-либо маршрутизатор отказывает, переставая слать своим соседям сообщения о сетях,

Пример зацикливания пакетов
Рассмотрим случай зацикливания пакетов на примере сети, изображенной
Пример зацикливания пакетов
Рассмотрим случай зацикливания пакетов на примере сети, изображенной
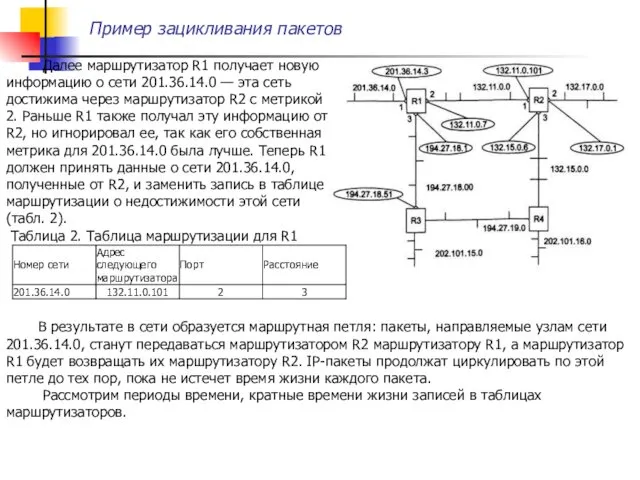
Пример зацикливания пакетов
Далее маршрутизатор R1 получает новую информацию о сети
Пример зацикливания пакетов
Далее маршрутизатор R1 получает новую информацию о сети

Пример зацикливания пакетов
Время 0-180 с. После отказа интерфейса в маршрутизаторах R1
Пример зацикливания пакетов
Время 0-180 с. После отказа интерфейса в маршрутизаторах R1

Пример зацикливания пакетов
Ограничение в 15 хопов сужает область применения протокола
Пример зацикливания пакетов
Ограничение в 15 хопов сужает область применения протокола

Методы борьбы с ложными маршрутами в протоколе RIP
Хотя протокол RIP не
Методы борьбы с ложными маршрутами в протоколе RIP
Хотя протокол RIP не

Методы борьбы с ложными маршрутами в протоколе RIP
Для предотвращения зацикливания пакетов
Методы борьбы с ложными маршрутами в протоколе RIP
Для предотвращения зацикливания пакетов

Протокол OSPF.
Два этапа построения таблицы маршрутизации
Протокол OSPF (Open Shortest Path First
Протокол OSPF.
Два этапа построения таблицы маршрутизации
Протокол OSPF (Open Shortest Path First

Протокол OSPF.
Два этапа построения таблицы маршрутизации
Для контроля состояния связей и соседних
Протокол OSPF.
Два этапа построения таблицы маршрутизации
Для контроля состояния связей и соседних

Протокол OSPF.
Два этапа построения таблицы маршрутизации
Если состояние связей в сети
Протокол OSPF.
Два этапа построения таблицы маршрутизации
Если состояние связей в сети

Метрики
При поиске оптимальных маршрутов протокол OSPF по умолчанию использует метрику,
Метрики
При поиске оптимальных маршрутов протокол OSPF по умолчанию использует метрику,
 Создание и управление потоками
Создание и управление потоками Информационная инфраструктура
Информационная инфраструктура Форматы_графических_файлов
Форматы_графических_файлов NET Framework and C# language
NET Framework and C# language Недетерміновані алгоритми. Лекція 3
Недетерміновані алгоритми. Лекція 3 F#. Деревья. Примеры
F#. Деревья. Примеры Ветвления. Программирование на языке Python
Ветвления. Программирование на языке Python Тренды SMM 2018-2019
Тренды SMM 2018-2019 Adobe Photoshop графикалық бағдарламасы
Adobe Photoshop графикалық бағдарламасы JavaScript. Java-апплет
JavaScript. Java-апплет Перевод чисел из 2 системы счисления в системы счисления с основаниям 2
Перевод чисел из 2 системы счисления в системы счисления с основаниям 2 Системы объектов
Системы объектов Путешествие по интернету
Путешествие по интернету Компьютер. История ВТ
Компьютер. История ВТ Технологии поиска информации в интернете
Технологии поиска информации в интернете Компьютерные преступления и защита от них
Компьютерные преступления и защита от них Нові можливості функцій в мові С++
Нові можливості функцій в мові С++ Тик-ток как инструмент воспитательного влияния
Тик-ток как инструмент воспитательного влияния Системный анализ и моделирование процессов в промышленной безопасности
Системный анализ и моделирование процессов в промышленной безопасности Использование функций в табличном процессоре MS EXCEL
Использование функций в табличном процессоре MS EXCEL Операционные системы
Операционные системы Динамическая память, динамические переменные
Динамическая память, динамические переменные Основы журналистики. Общая информация
Основы журналистики. Общая информация Введение в тестирование ПО
Введение в тестирование ПО Проектирование беспроводной сети в офисе
Проектирование беспроводной сети в офисе КВН по информатике
КВН по информатике Основные типы алгоритмических структур
Основные типы алгоритмических структур Class diagram на диаграмме UML
Class diagram на диаграмме UML