- Динамическая память, динамические переменные

Содержание
- 2. Определение, создание и работа с динамическими переменными int x = 15; - Описана статическая переменная x,
- 3. Определение, создание и работа с динамическими переменными Оператор cout Создать динамическую переменную можно двумя способами: описать
- 4. Определение, создание и работа с динамическими переменными x = NULL – говорит о том, что указатель
- 5. работа с динамическими переменными int *x = new int; *x = 15; ………….. delete x; Если
- 6. работа с динамическими переменными Графически это можно представить так. x x x y y y 10
- 7. работа с динамическими переменными 2. Меняем местами значения динамических переменных с помощью статической переменной r. int
- 8. работа с динамическими переменными Меняем местами указатели на динамические области памяти. void main () { int
- 9. Работа с динамическими переменными. ….Зачем нужны динамические переменные?.... Можно создать статический массив записей (структур), но работать
- 10. Абстрактные структуры данных. ….в наборах данных, подлежащих компьютерной обработке, присутствуют важные структурные отношения между элементами данных….
- 11. Абстрактные структуры данных. С линейными списками могут быть выполнены следующие операции: Получить доступ к к-й компоненте
- 12. Линейный связный список (ЛССп) – это конечное множество компонент, каждая из которых состоит из двух частей:
- 13. Двунаправленный список Линейные последовательности данных, связанные с точки зрения программной обработки, можно представить с помощью массива
- 14. Работа со списками Сохранив упорядоченность, нужно две фамилии удалить и одну вставить. Связный список требует дополнительной
- 15. Линейные связные списоки Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп. Список может быть реализован
- 16. Стек Реализация стека. Стек – это настолько популярная структура данных, что во многих ЭВМ она реализуется
- 17. Стек На С++ эти операции реализуются так: 1. stack[sp] = x; // положить x на вершину
- 18. пример использования стека Получение обратной польской записи выражения. Существуют три формы записи выражений: 1) инфиксная, 2)
- 19. пример использования стека Идея алгоритма : операнды из входной строки сразу попадают в выходную строку, а
- 20. Если очередным символом во входной строке является правая скобка, то из стека выталкиваются в выходную строку
- 21. Очередь. Очередь. Очередь – это абстрактная структура данных, которая работает по принципу FIFO (First In First
- 22. Очередь. Инициализация очереди заключается в присваивании начальных значений переменным head и tail. Если очередь пуста, положим
- 23. Очередь. Чтобы отличить пустую очередь от полностью заполненной в очереди, смоделированной с помощью закольцованного массива, приходится
- 24. Очередь. Здесь head указывает на первый элемент в очереди, а tail на ячейку, следующую за последним
- 25. Очередь. добавить элемент в очередь: tail = ((tail+1)% n); if (tail = =head) cout else Queue[tail]
- 26. Деревья. Создание теории деревьев связывают с именами инженера – электрика Г. Кирхгофа и математика А. Кэли,
- 27. Представление деревьев 1) a 2) b c d e f g h i k l 3)
- 28. Опр.2. Дерево – это неориентированный связный граф без циклов. Опр. 3. Дерево – это неориентированный, связный
- 29. Исходя из этого определения, можно сказать, что рисунки 1, 2 и 3 учитывают связи между узлами
- 30. Операции над деревьями, представление массивом Важнейшими операциями над деревьями являются: Построение дерева …. Добавление элемента в
- 31. Представление массивом (a + b / c ) * ( d – e * f )
- 32. Представление дерева массивом Представление дерева массивом позволяет легко находить путь от корня к заданному узлу, если
- 33. АСД. Представление и работа с помощью дин. переменных. Стек. Графически стек: NULL sp struct tstack {int
- 34. Стек с помощью дин. переменных просмотр элемента, расположенного на вершине стека int peek(tstack *sp) {return sp->inf;};
- 35. #include #include "stackint.h" #include using namespace std; void main() { FILE *h = fopen("input_stack.txt”,"r"); // файл
- 36. Очередь Очередь с помощью динамических переменных графически представляется так: tail head Элемент очереди описывается также, как
- 37. Очередь 1. Инициализация очереди: head = NULL; tail = NULL; head tail 2. Добавить элемент в
- 38. 3. Взять элемент из очереди: if (head != NULL) {r = head; x = head->inf; head
- 39. Общие операции со списками. Описание элемента списка в общем виде: struct tnode {int inf; tnode *next}
- 40. 4. Удалить элемент с указателем p. r = first; if (p == first) {first = first->next;
- 41. Бинарные деревья, программирование их с помощью динамических переменных. Дерево – это структура данных, которая может быть
- 42. Построение дерева с n узлами и минимальной высотой Идеально сбалансированное дерево… Пусть информационной частью будут номера
- 43. Идеально сбалансированное дерево. Функция, возвращающая значение: tnode *Tree (int n) { tnode *r; int nr, nl,
- 44. Бинарные деревья Если n = 21 и с клавиатуры введены номера вершин в следующем порядке: 8,9,11,15,
- 45. Обходы бинарного дерева: void Preorder (tnode *&t) //прямой { if (t != NULL) { cout inf
- 46. #include “iostream” // построение и обход дерева мин. высоты using namespace std; struct tnode {int inf;
- 47. Построение бинарного упорядоченного дерева Пусть ключевое поле – это поле inf и мы рассматриваем упорядоченное бинарное
- 48. Построениe бинарного упорядоченного дерева …………………………………………………………………………………… r = NULL; cin >> x; while (x!=0) { Search (x,r);
- 49. Удаление из упорядоченного дерева tnode *q; void Del_node(int x, tnode *&t) { if (t == NULL)
- 50. В функции Del_node первая ветвь оператора if выводит сообщение, что искомого элемента в дереве нет, вторая
- 51. Создание, обход и удаление из дерева поиска #include "iostream" using namespace std; struct tnode {int inf;
- 52. tnode *q; void Del_vs (tnode *&r); // прототип функции void Del_node(int x, tnode *&t) //удаление из
- 53. int main () { tnode *r; int x, n ; r = NULL; cout >x; while
- 54. Сильно ветвящиеся деревья Сильно ветвящиеся деревья - это деревья у узлов которых может быть больше двух
- 55. Графы Граф G = (V,E) состоит из конечного множества вершин V и множества ребер E. Если
- 56. Графы Если в графе G(V,E) ребро {u,v} или дуга є E, то вершины u и v
- 57. Cпособы представления графов Cпособы представления графов: 1)матрица инциденции, 2) матрица смежности, 3) список инцидентности, 4) список
- 58. Cпособы представления графов Для представленного орграфа матрица инциденции: 1 -1 -1 0 0 0 0 0
- 59. Cпособы представления графов На практике ребер в графе бывает обычно больше, чем вершин... Второй способ представления
- 60. Cпособы представления графов Для орграфа 2-я и 4-я строки нулевые, т.к. 2-я и 4-я вершины не
- 61. Cпособы представления графов Четвертый способ представления – список списков снимает ограничение и на количество вершин в
- 62. Способы обхода графа ……Существуют два способа обхода графа: 1) обход графа в глубину и 2) обход
- 63. Обход графа в глубину Существуют рекурсивный и не рекурсивный алгоритмы, реализующие этот метод. Чтобы отличить просмотренную
- 64. Обход графа в глубину Здесь V – множество всех вершин данного графа Spisok[v] – содержит номера
- 65. Обход графа в глубину - не рекурсивный function DFS1 (v); begin stack = 0; v ->
- 66. Нерекурсивный обход графа в глубину function DFS1 (v); begin stack = 0; v -> stack; просмотреть
- 67. Обход графа в ширину (Breadth First Search) Поиск (обход) в графе в ширину, отличается от поиска
- 68. Обход графа в ширину Алгоритм обхода в ширину на псевдокоде можно записать так: function BFS (v)
- 69. Обход графа в ширину Оба алгоритма могут использоваться для нахождения пути между данными вершинами u и
- 70. Представление графов в С/С++ Матрицу инциденции и матрицу смежности можно представить двумерным массивом целых элементов: const
- 72. Скачать презентацию

Определение, создание и работа с динамическими переменными
int x = 15; -
Определение, создание и работа с динамическими переменными
int x = 15; -

Определение, создание и работа с динамическими переменными
Оператор cout << x <<
Определение, создание и работа с динамическими переменными
Оператор cout << x <<

Определение, создание и работа с динамическими переменными
x = NULL – говорит
Определение, создание и работа с динамическими переменными
x = NULL – говорит

работа с динамическими переменными
int *x = new int;
*x = 15;
…………..
delete x;
Если
работа с динамическими переменными
int *x = new int;
*x = 15;
…………..
delete x;
Если
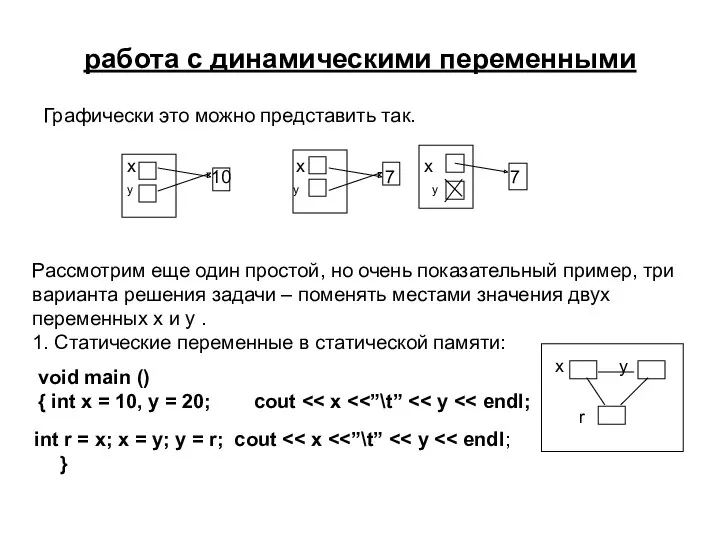
работа с динамическими переменными
Графически это можно представить так.
x x x
работа с динамическими переменными
Графически это можно представить так.
x x x

работа с динамическими переменными
2. Меняем местами значения динамических переменных с помощью
работа с динамическими переменными
2. Меняем местами значения динамических переменных с помощью
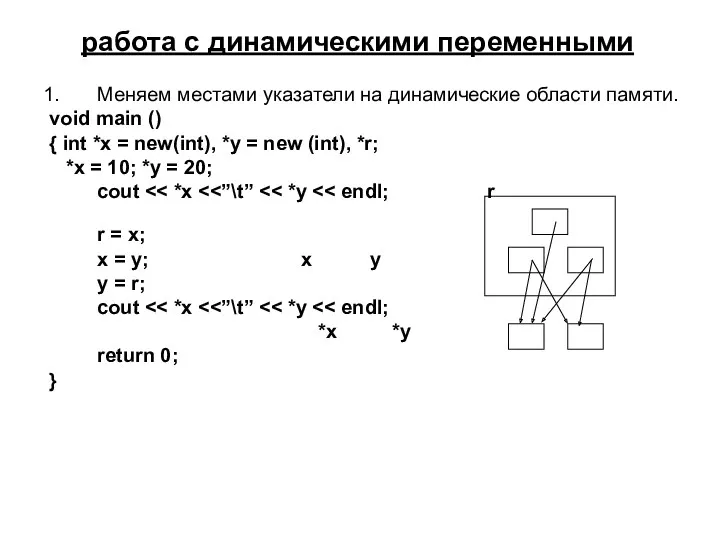
работа с динамическими переменными
Меняем местами указатели на динамические области памяти.
void
работа с динамическими переменными
Меняем местами указатели на динамические области памяти.
void

Работа с динамическими переменными.
….Зачем нужны динамические переменные?....
Можно создать статический массив
Работа с динамическими переменными.
….Зачем нужны динамические переменные?....
Можно создать статический массив

Абстрактные структуры данных.
….в наборах данных, подлежащих компьютерной обработке, присутствуют важные структурные
Абстрактные структуры данных.
….в наборах данных, подлежащих компьютерной обработке, присутствуют важные структурные

Абстрактные структуры данных.
С линейными списками могут быть выполнены следующие операции:
Получить доступ
Абстрактные структуры данных.
С линейными списками могут быть выполнены следующие операции:
Получить доступ

Линейный связный список (ЛССп) – это конечное множество компонент, каждая из
Линейный связный список (ЛССп) – это конечное множество компонент, каждая из
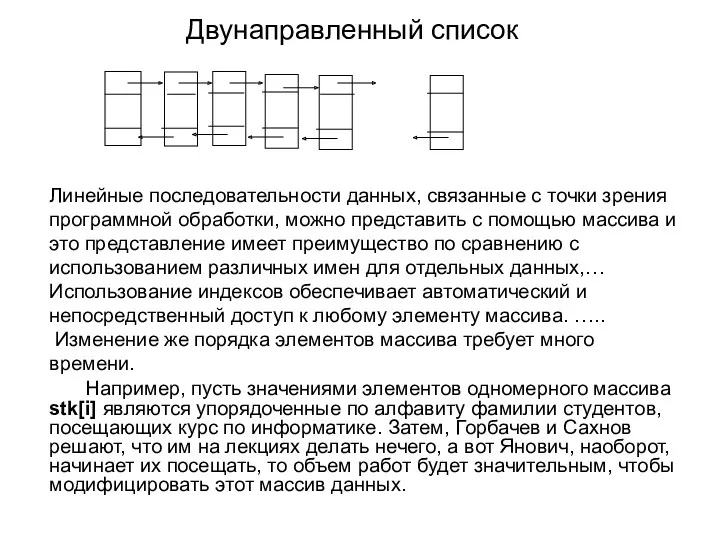
Двунаправленный список
Линейные последовательности данных, связанные с точки зрения программной обработки, можно
Двунаправленный список
Линейные последовательности данных, связанные с точки зрения программной обработки, можно
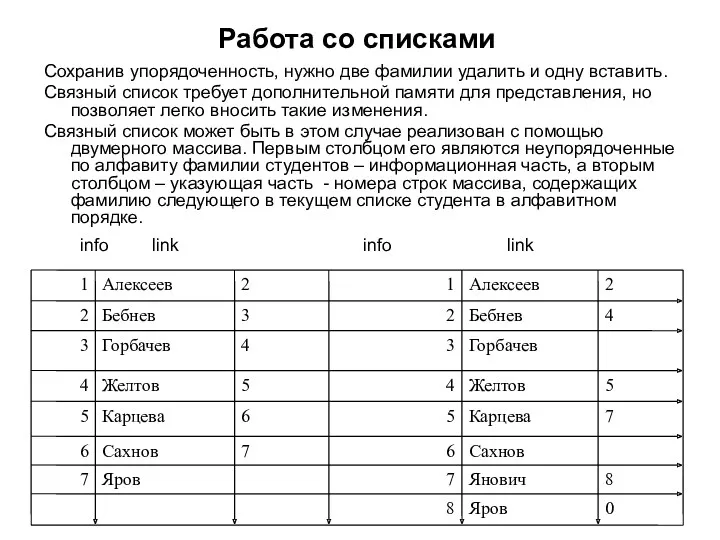
Работа со списками
Сохранив упорядоченность, нужно две фамилии удалить и одну вставить.
Работа со списками
Сохранив упорядоченность, нужно две фамилии удалить и одну вставить.
![Линейные связные списоки Двумерный массив stk{i,j] размером 2*n может работать](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/377415/slide-14.jpg)
Линейные связные списоки
Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп.
Линейные связные списоки
Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп.

Стек
Реализация стека. Стек – это настолько популярная структура данных, что во
Стек
Реализация стека. Стек – это настолько популярная структура данных, что во
![Стек На С++ эти операции реализуются так: 1. stack[sp] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/377415/slide-16.jpg)
Стек
На С++ эти операции реализуются так:
1. stack[sp] = x; // положить
Стек
На С++ эти операции реализуются так:
1. stack[sp] = x; // положить

пример использования стека
Получение обратной польской записи выражения.
Существуют три формы записи
пример использования стека
Получение обратной польской записи выражения.
Существуют три формы записи

пример использования стека
Идея алгоритма : операнды из входной строки сразу попадают
пример использования стека
Идея алгоритма : операнды из входной строки сразу попадают

Если очередным символом во входной строке является правая скобка, то из
Если очередным символом во входной строке является правая скобка, то из

Очередь.
Очередь. Очередь – это абстрактная структура данных, которая работает по принципу
Очередь.
Очередь. Очередь – это абстрактная структура данных, которая работает по принципу

Очередь.
Инициализация очереди заключается в присваивании начальных значений переменным head и tail.
Очередь.
Инициализация очереди заключается в присваивании начальных значений переменным head и tail.

Очередь.
Чтобы отличить пустую очередь от полностью заполненной в очереди, смоделированной
Очередь.
Чтобы отличить пустую очередь от полностью заполненной в очереди, смоделированной

Очередь.
Здесь head указывает на первый элемент в очереди, а tail на
Очередь.
Здесь head указывает на первый элемент в очереди, а tail на

Очередь.
добавить элемент в очередь:
tail = ((tail+1)% n);
if (tail = =head) cout
Очередь.
добавить элемент в очередь:
tail = ((tail+1)% n);
if (tail = =head) cout

Деревья.
Создание теории деревьев связывают с именами инженера – электрика Г.
Деревья.
Создание теории деревьев связывают с именами инженера – электрика Г.
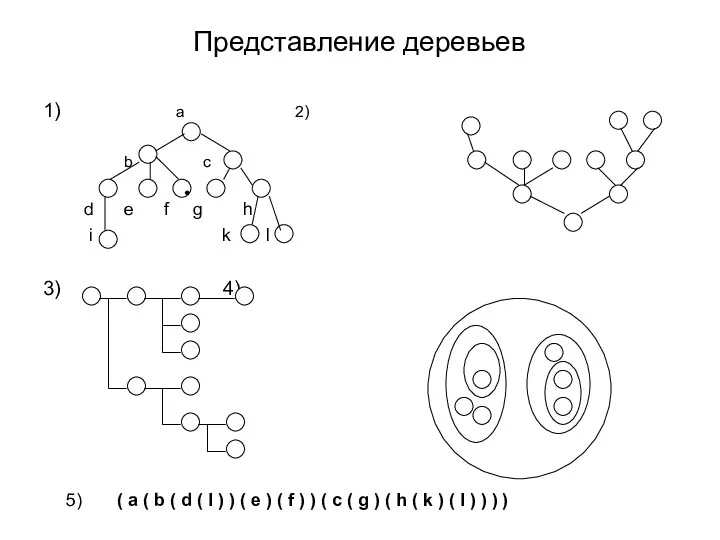
Представление деревьев
1) a 2)
b c
d e f g h
i
Представление деревьев
1) a 2)
b c
d e f g h
i

Опр.2. Дерево – это неориентированный связный граф без циклов.
Опр. 3. Дерево
Опр.2. Дерево – это неориентированный связный граф без циклов.
Опр. 3. Дерево

Исходя из этого определения, можно сказать, что рисунки 1, 2 и
Исходя из этого определения, можно сказать, что рисунки 1, 2 и

Операции над деревьями, представление массивом
Важнейшими операциями над деревьями являются:
Построение дерева
Операции над деревьями, представление массивом
Важнейшими операциями над деревьями являются:
Построение дерева
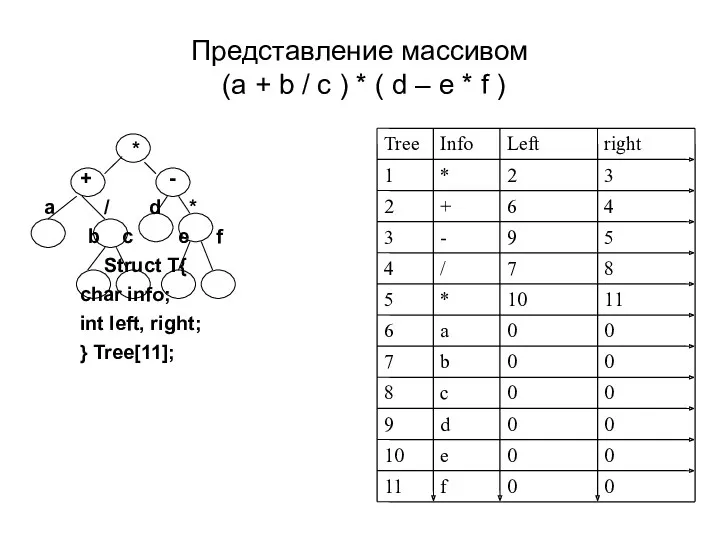
Представление массивом
(a + b / c ) * ( d
Представление массивом (a + b / c ) * ( d

Представление дерева массивом
Представление дерева массивом позволяет легко находить путь от корня
Представление дерева массивом
Представление дерева массивом позволяет легко находить путь от корня
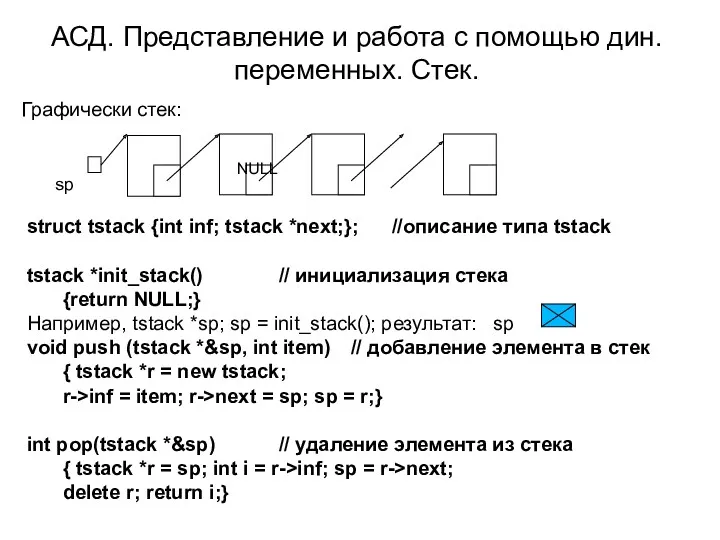
АСД. Представление и работа с помощью дин. переменных. Стек.
Графически стек:
NULL
sp
struct tstack
АСД. Представление и работа с помощью дин. переменных. Стек.
Графически стек:
NULL
sp
struct tstack

Стек с помощью дин. переменных
просмотр элемента, расположенного на вершине стека
int peek(tstack
Стек с помощью дин. переменных
просмотр элемента, расположенного на вершине стека
int peek(tstack

#include
#include "stackint.h"
#include
using namespace std;
void main() {
FILE *h = fopen("input_stack.txt”,"r");
#include
#include "stackint.h"
#include
using namespace std;
void main() {
FILE *h = fopen("input_stack.txt”,"r");
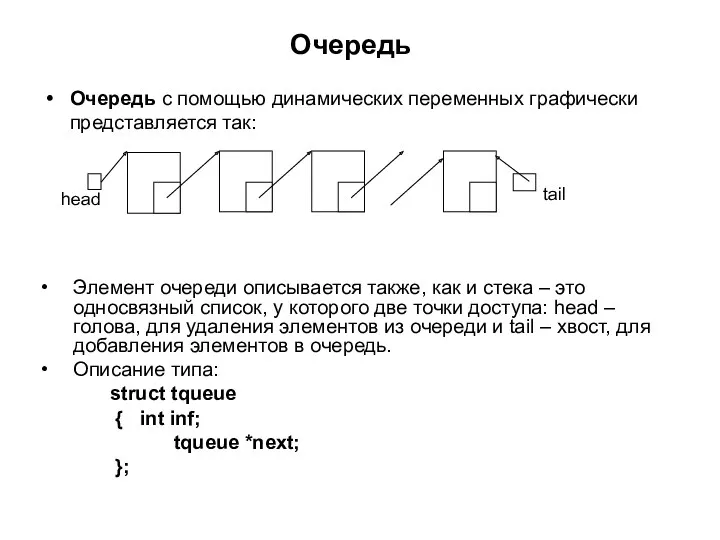
Очередь
Очередь с помощью динамических переменных графически представляется так:
tail
head
Элемент очереди описывается также,
Очередь
Очередь с помощью динамических переменных графически представляется так:
tail
head
Элемент очереди описывается также,
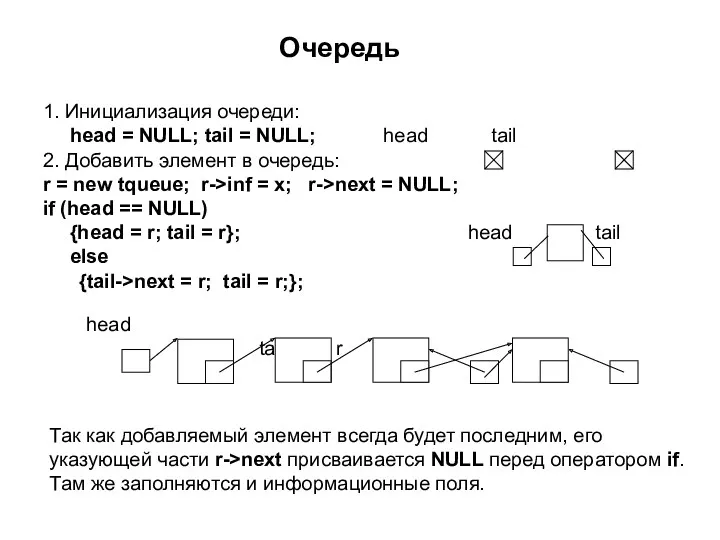
Очередь
1. Инициализация очереди:
head = NULL; tail = NULL; head tail
2.
Очередь
1. Инициализация очереди:
head = NULL; tail = NULL; head tail
2.

3. Взять элемент из очереди:
if (head != NULL)
{r = head;
3. Взять элемент из очереди:
if (head != NULL)
{r = head;
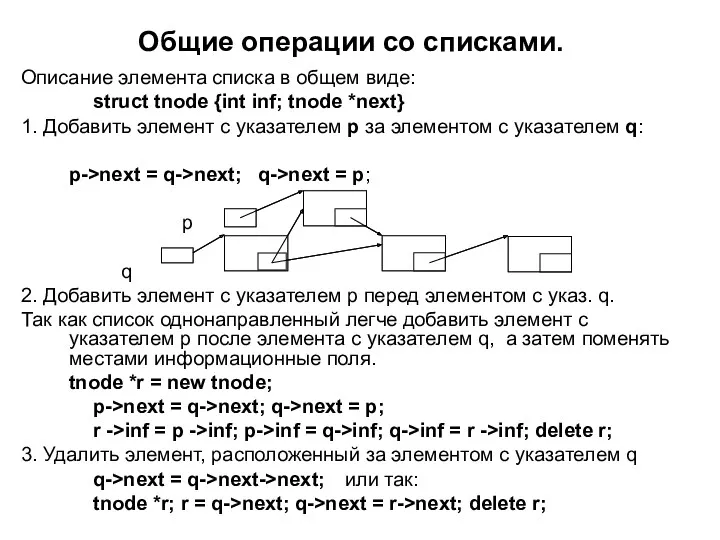
Общие операции со списками.
Описание элемента списка в общем виде:
struct tnode
Общие операции со списками.
Описание элемента списка в общем виде:
struct tnode
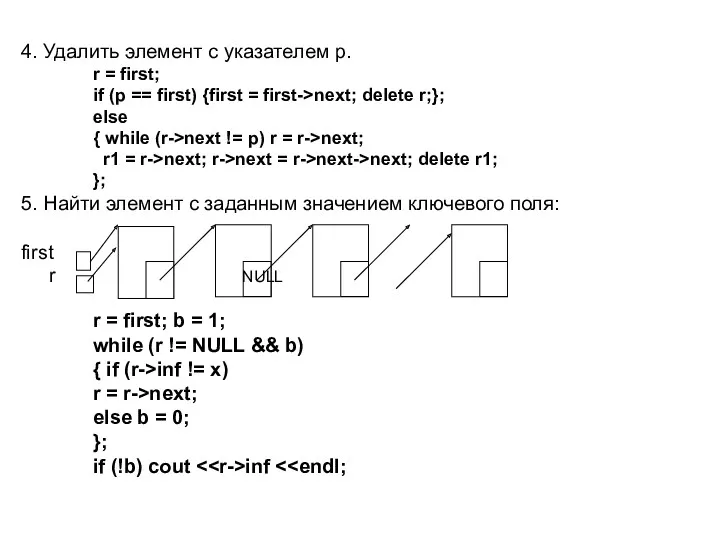
4. Удалить элемент с указателем p.
r = first;
if (p ==
4. Удалить элемент с указателем p.
r = first;
if (p ==

Бинарные деревья, программирование их с помощью динамических переменных.
Дерево – это структура
Бинарные деревья, программирование их с помощью динамических переменных.
Дерево – это структура

Построение дерева с n узлами и минимальной высотой
Идеально сбалансированное дерево…
Построение дерева с n узлами и минимальной высотой
Идеально сбалансированное дерево…

Идеально сбалансированное дерево.
Функция, возвращающая значение:
tnode *Tree (int n)
{ tnode *r;
Идеально сбалансированное дерево.
Функция, возвращающая значение:
tnode *Tree (int n)
{ tnode *r;
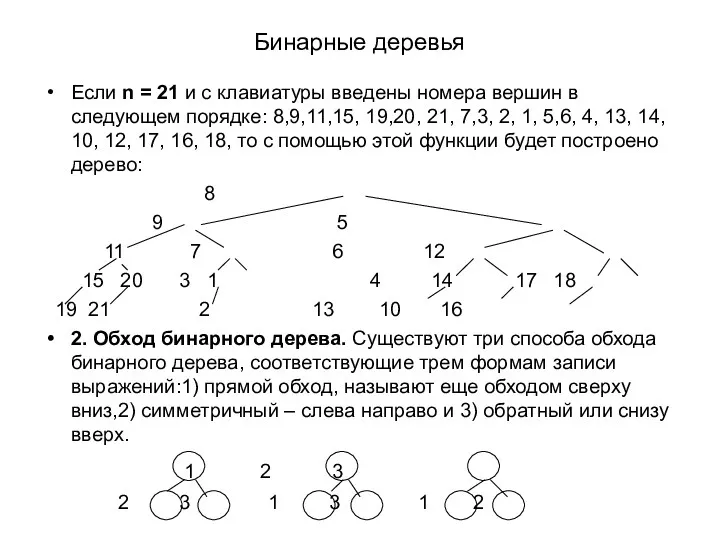
Бинарные деревья
Если n = 21 и с клавиатуры введены номера вершин
Бинарные деревья
Если n = 21 и с клавиатуры введены номера вершин

Обходы бинарного дерева:
void Preorder (tnode *&t) //прямой
{ if (t !=
Обходы бинарного дерева:
void Preorder (tnode *&t) //прямой
{ if (t !=

#include “iostream” // построение и обход дерева мин. высоты
using namespace std;
struct
#include “iostream” // построение и обход дерева мин. высоты
using namespace std;
struct

Построение бинарного упорядоченного дерева
Пусть ключевое поле – это поле inf
Построение бинарного упорядоченного дерева
Пусть ключевое поле – это поле inf
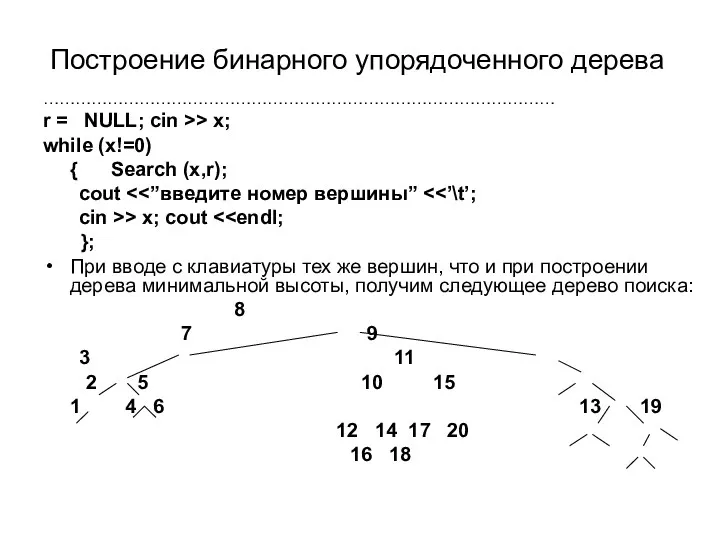
Построениe бинарного упорядоченного дерева
……………………………………………………………………………………
r = NULL; cin >> x;
while
Построениe бинарного упорядоченного дерева
……………………………………………………………………………………
r = NULL; cin >> x;
while

Удаление из упорядоченного дерева
tnode *q;
void Del_node(int x, tnode *&t)
{ if
Удаление из упорядоченного дерева
tnode *q;
void Del_node(int x, tnode *&t)
{ if
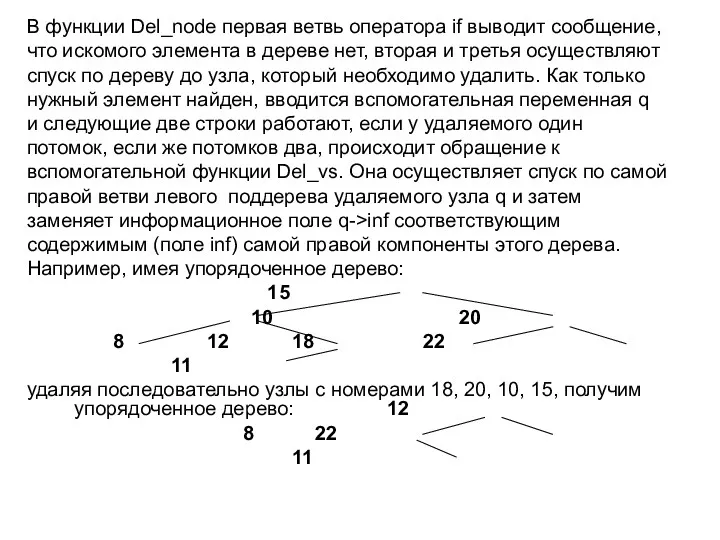
В функции Del_node первая ветвь оператора if выводит сообщение,
что искомого элемента
В функции Del_node первая ветвь оператора if выводит сообщение,
что искомого элемента

Создание, обход и удаление из дерева поиска
#include "iostream"
using namespace std;
struct tnode
Создание, обход и удаление из дерева поиска
#include "iostream"
using namespace std;
struct tnode

tnode *q;
void Del_vs (tnode *&r); // прототип функции
void Del_node(int x,
tnode *q;
void Del_vs (tnode *&r); // прототип функции
void Del_node(int x,

int main ()
{ tnode *r; int x, n ;
r = NULL;
int main ()
{ tnode *r; int x, n ;
r = NULL;

Сильно ветвящиеся деревья
Сильно ветвящиеся деревья - это деревья у узлов
Сильно ветвящиеся деревья
Сильно ветвящиеся деревья - это деревья у узлов
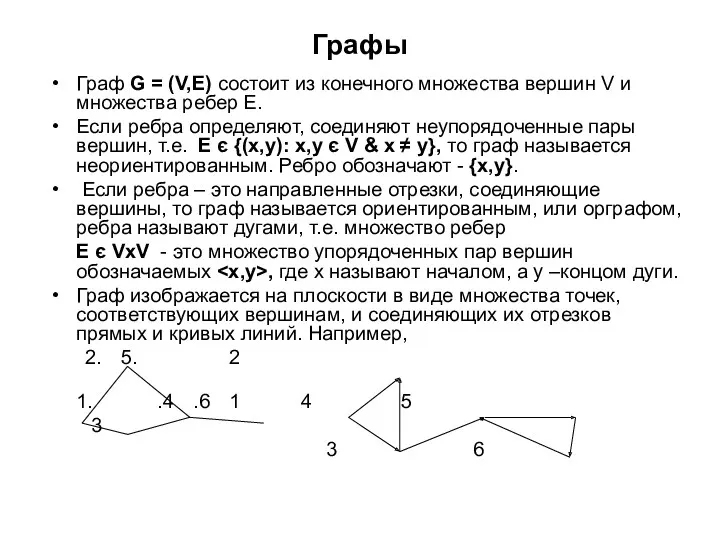
Графы
Граф G = (V,E) состоит из конечного множества вершин V и
Графы
Граф G = (V,E) состоит из конечного множества вершин V и

Графы
Если в графе G(V,E) ребро {u,v} или дуга є E,
Графы
Если в графе G(V,E) ребро {u,v} или дуга
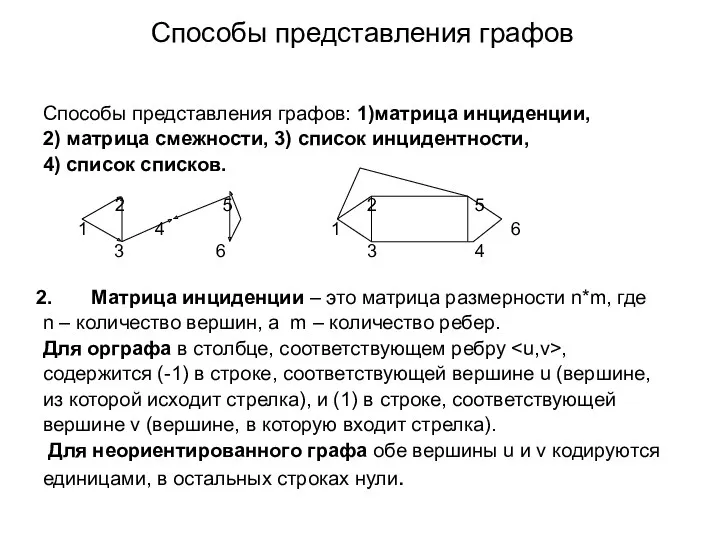
Cпособы представления графов
Cпособы представления графов: 1)матрица инциденции,
2) матрица смежности, 3)
Cпособы представления графов
Cпособы представления графов: 1)матрица инциденции,
2) матрица смежности, 3)

Cпособы представления графов
Для представленного орграфа матрица инциденции:
<1,2> <1,3> <3,2> <3,4>
Cпособы представления графов
Для представленного орграфа матрица инциденции:
<1,2> <1,3> <3,2> <3,4>

Cпособы представления графов
На практике ребер в графе бывает обычно больше, чем
Cпособы представления графов
На практике ребер в графе бывает обычно больше, чем

Cпособы представления графов
Для орграфа 2-я и 4-я строки нулевые, т.к. 2-я
Cпособы представления графов
Для орграфа 2-я и 4-я строки нулевые, т.к. 2-я
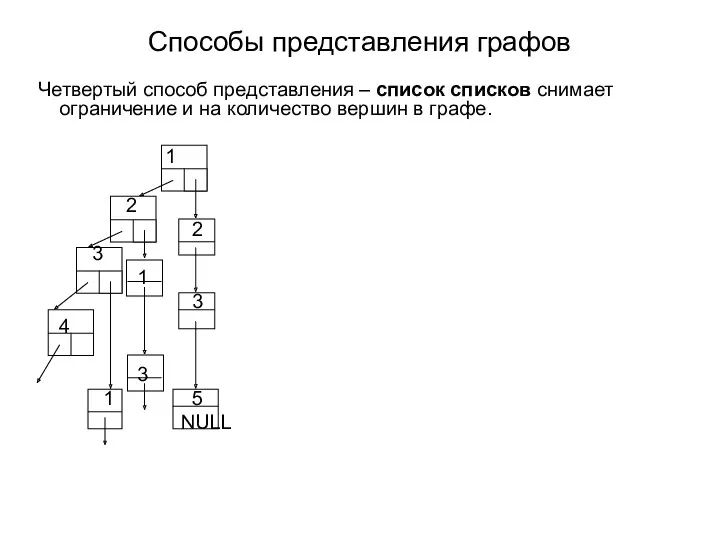
Cпособы представления графов
Четвертый способ представления – список списков снимает ограничение
Cпособы представления графов
Четвертый способ представления – список списков снимает ограничение
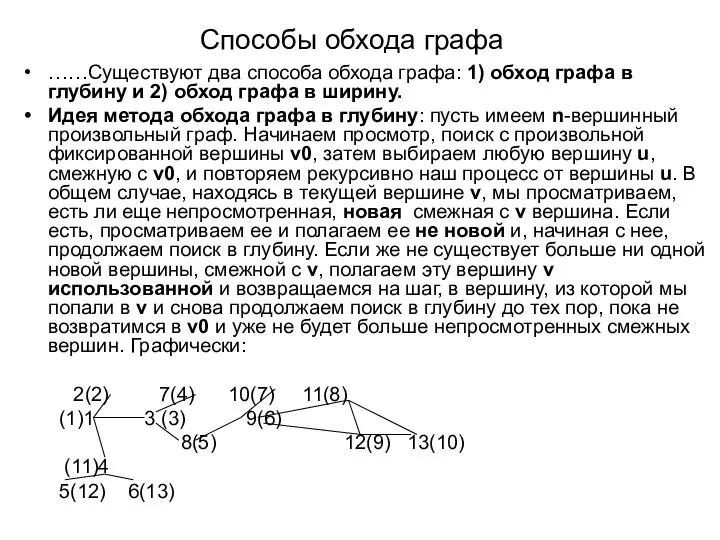
Способы обхода графа
……Существуют два способа обхода графа: 1) обход графа
Способы обхода графа
……Существуют два способа обхода графа: 1) обход графа

Обход графа в глубину
Существуют рекурсивный и не рекурсивный алгоритмы, реализующие этот
Обход графа в глубину
Существуют рекурсивный и не рекурсивный алгоритмы, реализующие этот

Обход графа в глубину
Здесь V – множество всех вершин данного графа
Spisok[v]
Обход графа в глубину
Здесь V – множество всех вершин данного графа
Spisok[v]

Обход графа в глубину - не рекурсивный
function DFS1 (v);
Обход графа в глубину - не рекурсивный
function DFS1 (v);

Нерекурсивный обход графа в глубину
function DFS1 (v);
begin
stack =
Нерекурсивный обход графа в глубину
function DFS1 (v);
begin
stack =
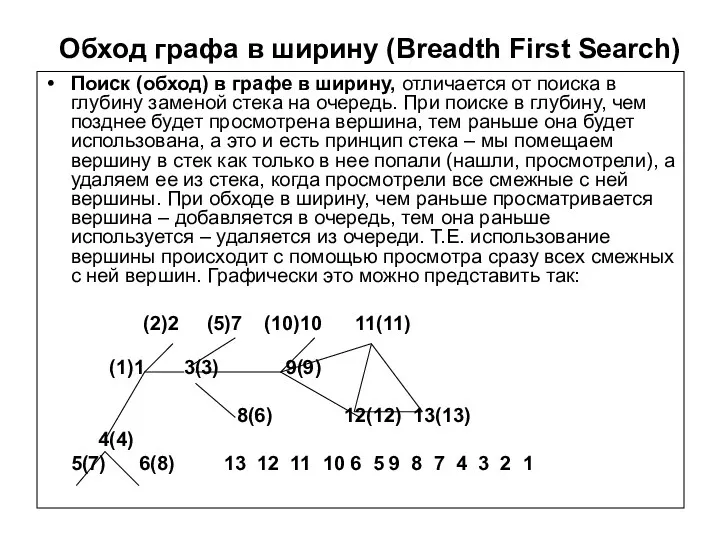
Обход графа в ширину (Breadth First Search)
Поиск (обход) в графе
Обход графа в ширину (Breadth First Search)
Поиск (обход) в графе

Обход графа в ширину
Алгоритм обхода в ширину на псевдокоде можно записать
Обход графа в ширину
Алгоритм обхода в ширину на псевдокоде можно записать

Обход графа в ширину
Оба алгоритма могут использоваться для нахождения пути между
Обход графа в ширину
Оба алгоритма могут использоваться для нахождения пути между

Представление графов в С/С++
Матрицу инциденции и матрицу смежности можно представить двумерным
Представление графов в С/С++
Матрицу инциденции и матрицу смежности можно представить двумерным
 Пособие по плаванию в сети Интернет (родителям)
Пособие по плаванию в сети Интернет (родителям) Методы представления графических изображений
Методы представления графических изображений Android компоненттері
Android компоненттері Ввод изображения
Ввод изображения ОБЪЕКТ И ЕГО ХАРАКТЕРИСТИКА
ОБЪЕКТ И ЕГО ХАРАКТЕРИСТИКА Как заработать 150 000 рублей за месяц на одном товаре
Как заработать 150 000 рублей за месяц на одном товаре HTML құжатында кестелерді қалыптастыру. Кесте параметрлерін тағайындау тегтері
HTML құжатында кестелерді қалыптастыру. Кесте параметрлерін тағайындау тегтері Заполнить таблицу
Заполнить таблицу Информационная система автоматизации обработки информации о реабилитации больных на санаторном этапе
Информационная система автоматизации обработки информации о реабилитации больных на санаторном этапе Changes in society by computing technology
Changes in society by computing technology Назначение и устройство компьютера. Компьютерная память.
Назначение и устройство компьютера. Компьютерная память. Обобщенная линейная модель множественной регрессии с гетероскедастичными остатками. Лекция 8
Обобщенная линейная модель множественной регрессии с гетероскедастичными остатками. Лекция 8 Приятные новости. Hot Talk представляет
Приятные новости. Hot Talk представляет Обработка информации. Информация и информационные процессы
Обработка информации. Информация и информационные процессы Операции и выражения. (Лекция 4)
Операции и выражения. (Лекция 4) Графический редактор Paint
Графический редактор Paint Итоги петровских преобразований. Урок по истории России в 10 класс. Интегрированный урок история + информатика
Итоги петровских преобразований. Урок по истории России в 10 класс. Интегрированный урок история + информатика Связи между классами. Объектно-ориентированное программирование. (Лекция 3)
Связи между классами. Объектно-ориентированное программирование. (Лекция 3) Корпоративные информационные системы
Корпоративные информационные системы Искусственный интеллект
Искусственный интеллект Поколения ЭВМ
Поколения ЭВМ Модуль управления движением автомобиля для системы оценки профессиональной пригодности водителей автотранспорта
Модуль управления движением автомобиля для системы оценки профессиональной пригодности водителей автотранспорта Работа с донорами. Письма донорам: технология и содержание
Работа с донорами. Письма донорам: технология и содержание Mathcad 2000 Professional
Mathcad 2000 Professional Алгоритмы и структуры данных. Алгоритмы сортировки
Алгоритмы и структуры данных. Алгоритмы сортировки Команда и программа
Команда и программа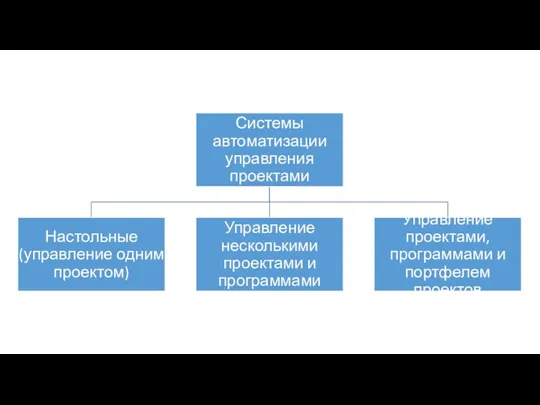 Системы автоматизации управления проектами
Системы автоматизации управления проектами 6 кроків для створення власного логотипу
6 кроків для створення власного логотипу